

Lösungsvalidierung – validierte Szenarien
 Änderungen vorschlagen
Änderungen vorschlagen
Die FlexPod Lösung für SM-BC von Datacenter schützt Datenservices für verschiedene Single-Point-of-Failure-Szenarien und für einen Standortausfall. Das an jedem Standort implementierte redundante Design sorgt für Hochverfügbarkeit. Die SM-BC Implementierung mit synchroner Datenreplizierung an allen Standorten schützt Datenservices vor einem standortweiten Ausfall. Die implementierte Lösung wurde für die gewünschte Funktionalität der Lösung sowie für verschiedene Ausfallszenarien validiert, bei denen die Lösung zum Schutz entwickelt wurde.
Validierung der Funktionen der Lösung
In verschiedenen Testfällen werden die Funktionen der Lösung überprüft und teilweise oder vollständige Ausfallszenarien am Standort simuliert. Um die Duplizierung durch die bereits in den vorhandenen FlexPod Datacenter-Lösungen im Rahmen des Cisco Validated Design Programms durchgeführten Tests zu minimieren, liegt der Schwerpunkt dieses Berichts auf den SM-BC-bezogenen Aspekten der Lösung. Einige allgemeine FlexPod-Validierungen sind enthalten, damit die Praktizierenden für ihre Umsetzung Validierungen gehen.
Für die Lösungsvalidierung wurde ein Virtual Machine unter Windows 10 pro ESXi Host auf allen ESXi Hosts an beiden Standorten erstellt. Das IOMeter Tool wurde installiert und zur Generierung von I/O-Vorgängen zu zwei virtuellen Datenfestplatten verwendet, die aus den gemeinsam genutzten lokalen iSCSI-Datenspeichern zugeordnet werden. Die konfigurierten IOMeter Workload-Parameter waren 8-KB I/O, 75 % Lesezugriffe und 50 % zufällige Zugriffe, mit 8 ausstehenden I/O-Befehlen für jede Datenfestplatte. Die Fortsetzung der IOMeter I/O-Vorgänge liefert bei den meisten durchgeführten Testszenarien an, dass ein Szenario keinen Ausfall des Datenservice verursacht hat.
Da SM-BC für Business-Applikationen wie Datenbankserver wichtig ist, Die Microsoft SQL Server 2019 Instanz auf einer Windows Server 2022 Virtual Machine wurde auch als Teil der Tests eingeschlossen, um zu bestätigen, dass die Applikation weiter ausgeführt wird, wenn Storage am lokalen Standort nicht verfügbar ist und der Datenservice ohne Applikation am Remote-Standort fortgesetzt wird Unterbrechungen.
Bootstest für ESXi Host iSCSI SAN
Die ESXi-Hosts in der Lösung sind für das Booten über das iSCSI-SAN konfiguriert. Die Verwendung von SAN-Boot vereinfacht das Servermanagement beim Austausch eines Servers, da das Serviceprofil des Servers einem neuen Server zugewiesen werden kann, damit der IT-Server ohne zusätzliche Konfigurationsänderungen gestartet werden kann.
Zusätzlich zum Booten eines ESXi Hosts an einem Standort von seiner lokalen iSCSI-Boot-LUN wurden Tests zum Booten des ESXi Hosts durchgeführt, wenn sich der lokale Storage-Controller im Übernahmemodus befindet oder dessen lokaler Storage-Cluster vollständig nicht verfügbar ist. Mithilfe dieser Validierungsszenarien wird sichergestellt, dass die ESXi Hosts je Design ordnungsgemäß konfiguriert sind und während einer Storage-Wartung oder eines Disaster Recovery-Szenarios hochgefahren werden können, um Business Continuity zu gewährleisten.
Bevor die SM-BC Konsistenzgruppenbeziehung konfiguriert ist, verfügt ein iSCSI-LUN, das von einem Storage Controller HA-Paar gehostet wird, über vier Pfade, zwei über jede iSCSI-Fabric, basierend auf der Implementierung von Best Practices. Ein Host kann über die zwei iSCSI-VLANs/Fabrics zum LUN-Hosting Controller gelangen und über den hochverfügbaren Partner des Controllers zur LUN gelangen.
Nachdem die SM-BC Konsistenzgruppe-Beziehung konfiguriert ist und die gespiegelten LUNs den Initiatoren ordnungsgemäß zugeordnet sind, verdoppelt sich die Pfadanzahl für die LUN. Für diese Implementierung reicht es von zwei aktiven/optimierten Pfaden und zwei aktiv/nicht-optimierte Pfade bis hin zu zwei aktiv/optimierten Pfaden und sechs aktiv/nicht optimierte Pfade.
In der folgenden Abbildung werden die Pfade dargestellt, die ein ESXi Host für den Zugriff auf eine LUN nutzen kann, beispielsweise LUN 0. Da die LUN an den Standort A Controller 01 angeschlossen ist, sind nur die beiden Pfade, die direkt über diesen Controller auf die LUN zugreifen, aktiv/optimiert und alle verbleibenden sechs Pfade sind aktiv/nicht optimiert.
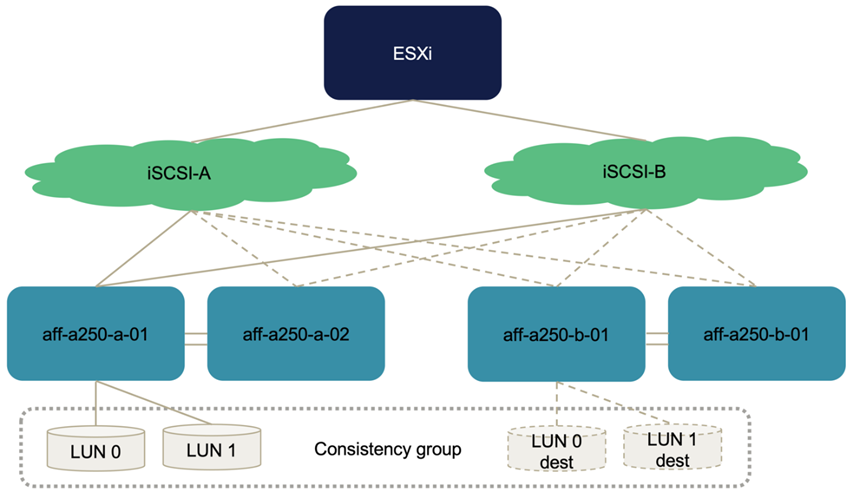
Der folgende Screenshot mit den Informationen zum Pfad für das Storage-Gerät zeigt, wie der ESXi Host die zwei Typen von Gerätepfaden sieht. Die beiden aktiven/optimierten Pfade werden als haben angezeigt active (I/O) Pfadstatus, während die sechs aktiven/nicht optimierten Pfade nur als angezeigt werden active. Beachten Sie außerdem, dass in der Spalte Ziel die beiden iSCSI-Ziele und die entsprechenden iSCSI-LIF-IP-Adressen angezeigt werden, um die Ziele zu erreichen.
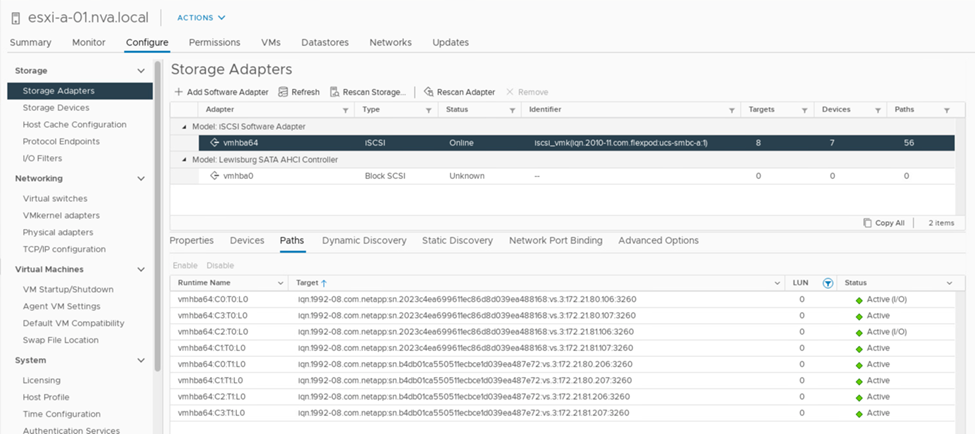
Wenn einer der Storage Controller für Wartungsarbeiten oder Upgrades ausfällt, stehen die beiden Pfade zum Erreichen des heruntergekommen Controllers nicht mehr zur Verfügung und zeigen den Pfadstatus von an dead Stattdessen.
Wenn ein Failover der Konsistenzgruppe auf dem primären Storage Cluster erfolgt, entweder aufgrund von manuellen Failover-Tests oder aufgrund von automatischem Disaster Failover, stellt das sekundäre Storage-Cluster weiterhin Datenservices für die LUNs in der SM-BC-Konsistenzgruppe bereit. Da die LUN-Identitäten erhalten bleiben und die Daten synchron repliziert werden, bleiben alle durch SM-BC-Konsistenzgruppen geschützten ESXi Host-Boot-LUNs über das Remote-Storage-Cluster verfügbar.
VMware vMotion und VM/Host-Affinitätstest
Obwohl eine allgemeine FlexPod VMware Datacenter Lösung Multi-Protokolle wie FC, iSCSI, NVMe und NFS unterstützt, unterstützt die FlexPod SM-BC Lösungsfunktion FC und iSCSI SAN-Protokolle, die üblicherweise für geschäftskritische Lösungen verwendet werden. Diese Validierung verwendet nur iSCSI-protokollbasierte Datenspeicher und iSCSI SAN Boot.
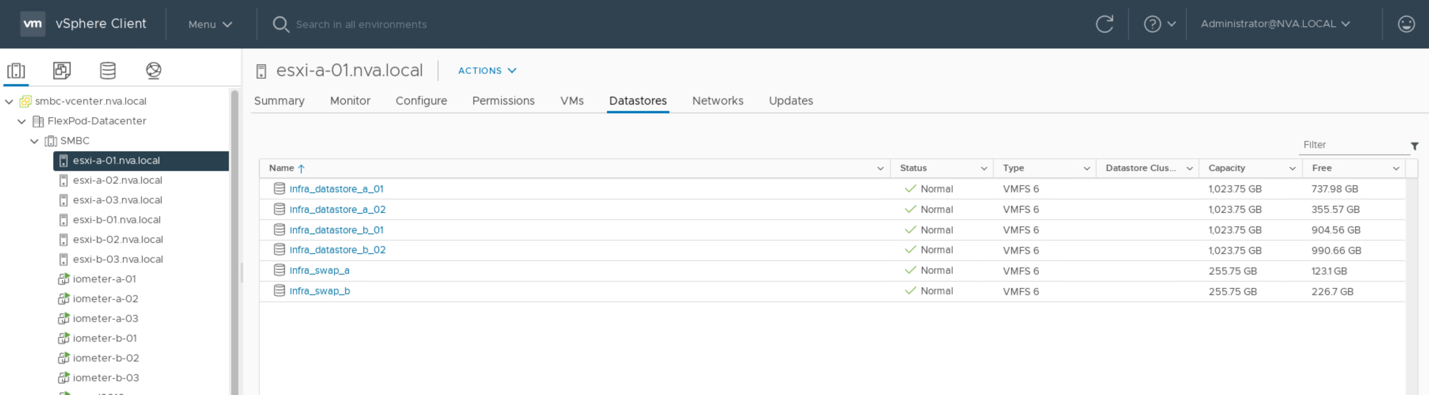
Damit Virtual Machines Storage-Services von einem SM-BC-Standort aus verwenden können, müssen die iSCSI-Datenspeicher beider Standorte von allen Hosts im Cluster gemountet werden, um die Migration von Virtual Machines zwischen beiden Standorten und für Disaster Failover-Szenarien zu ermöglichen.
Für Applikationen, die auf der virtuellen Infrastruktur ausgeführt werden, die über Standorte hinweg keinen SM-BC-Konsistenzgruppenschutz benötigen, können auch NFS-Protokoll und NFS-Datenspeicher verwendet werden. In diesem Fall ist Vorsicht zu beachten, wenn Storage für VMs zugewiesen wird, damit geschäftskritische Applikationen die durch SM-BC Consistency Group geschützten SAN-Datenspeicher ordnungsgemäß verwenden, um Business Continuity zu gewährleisten.
Der folgende Screenshot zeigt, dass Hosts konfiguriert sind, um iSCSI-Datenspeicher von beiden Seiten einzubinden.
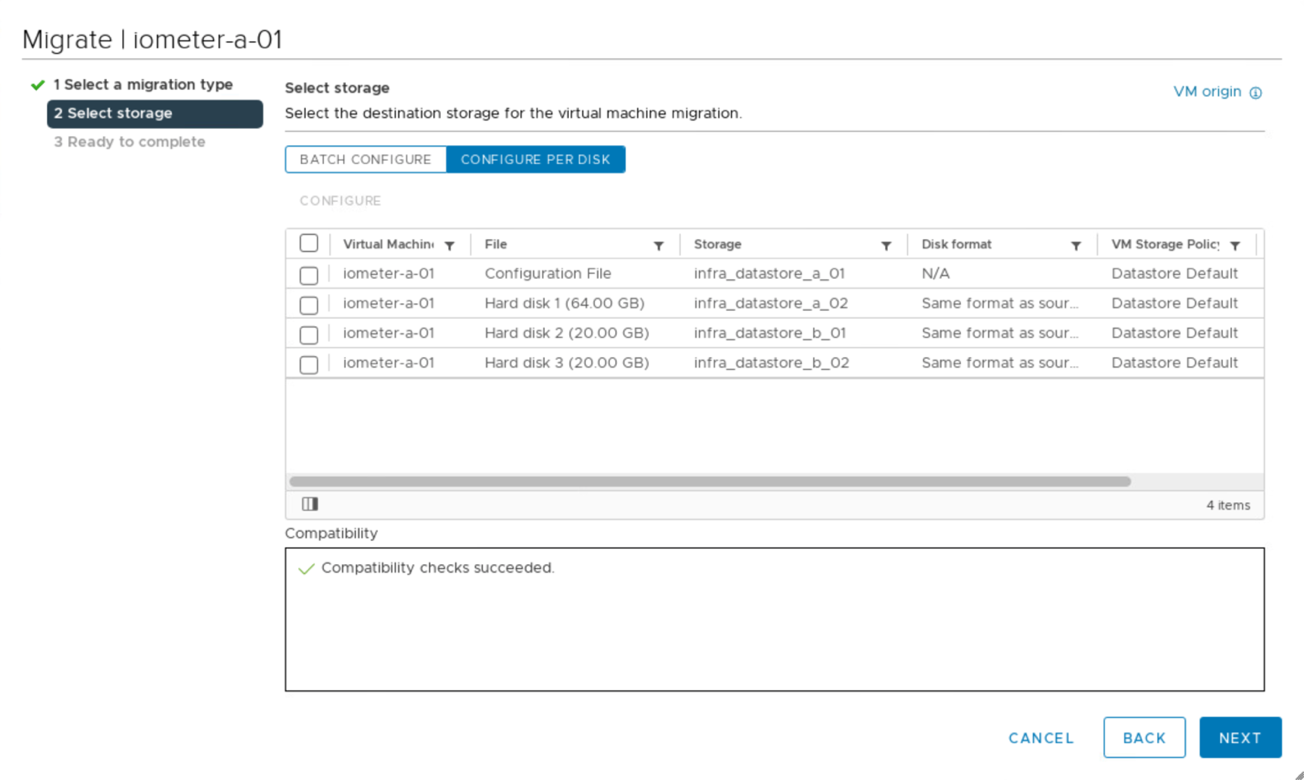
Sie haben die Möglichkeit, Laufwerke von Virtual Machines zwischen verfügbaren iSCSI-Datenspeichern beider Standorte zu migrieren, wie in der folgenden Abbildung dargestellt. Bei Performance-Überlegungen ist es optimal, Virtual Machines zu nutzen, die Storage aus dem lokalen Storage-Cluster verwenden, um die Festplatten-I/O-Latenzen zu verringern. Dies gilt insbesondere, wenn sich beide Standorte aufgrund der physischen Latenz für die hin- und Rückfahrt von ca. 1 ms pro 100 km Entfernung in einigen Entfernungen voneinander unterscheiden.
Tests von vMotion von Virtual Machines auf einem anderen Host an demselben Standort und über mehrere Standorte hinweg wurden durchgeführt und erfolgreich durchgeführt. Nach der manuellen Migration einer virtuellen Maschine über Standorte hinweg wird die Regel für die VM/Hostaffinität aktiviert und die virtuelle Maschine zurück zur Gruppe migriert, in der sie unter dem normalen Zustand gehört.
Geplantes Storage-Failover
Geplante Storage Failover-Vorgänge sollten nach der Erstkonfiguration der Lösung ausgeführt werden, um festzustellen, ob die Lösung nach dem Storage Failover ordnungsgemäß funktioniert. Der Test kann dabei helfen, alle Verbindungs- oder Konfigurationsprobleme zu identifizieren, die zu I/O-Unterbrechungen führen können. Durch regelmäßige Tests und Behebung von Verbindungs- oder Konfigurationsproblemen können im Falle eines wirklichen Standortausfalls unterbrechungsfreie Datenservices bereitgestellt werden. Geplante Storage-Failovers können auch vor geplanten Aktivitäten zur Storage-Wartung verwendet werden, damit Datenservices vom nicht betroffenen Standort bedient werden können.
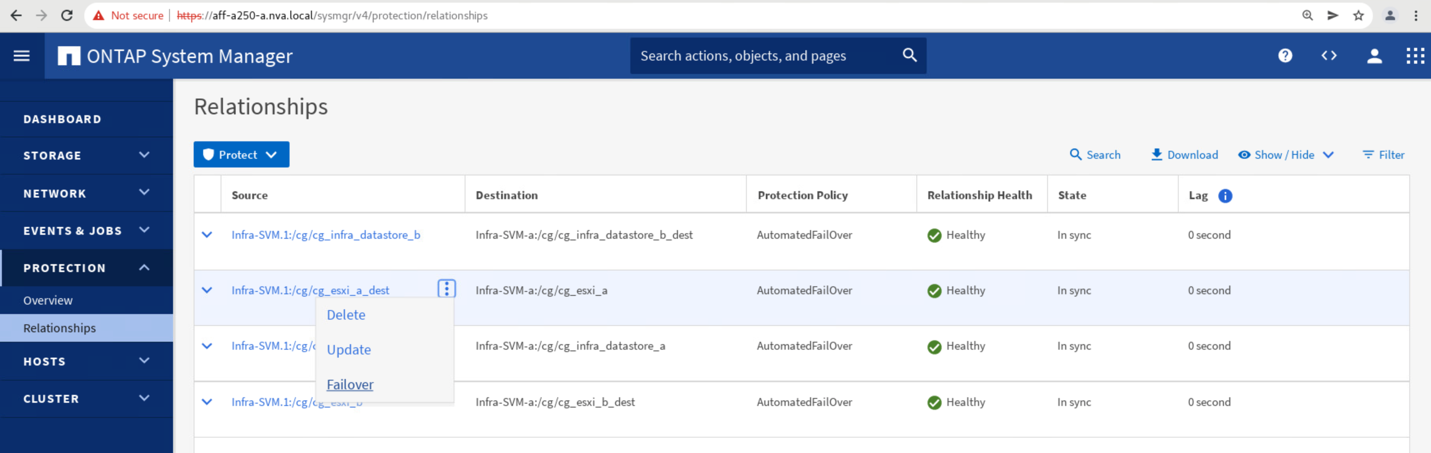
Um einen manuellen Failover von Standort-A-Speicherdatendiensten an Standort B zu initiieren, können Sie die Aktion mithilfe des Standort B ONTAP-System Managers durchführen.
-
Wechseln Sie zum Bildschirm Schutz > Beziehungen, um zu bestätigen, dass der Status der Beziehungen zu Konsistenzgruppen lautet
In Sync. Wenn es noch im istSynchronizingStatus: Warten Sie, bis der Status in lautetIn SyncVor dem Durchführen eines Failover. -
Erweitern Sie die Punkte neben dem Quellnamen, und klicken Sie auf Failover.
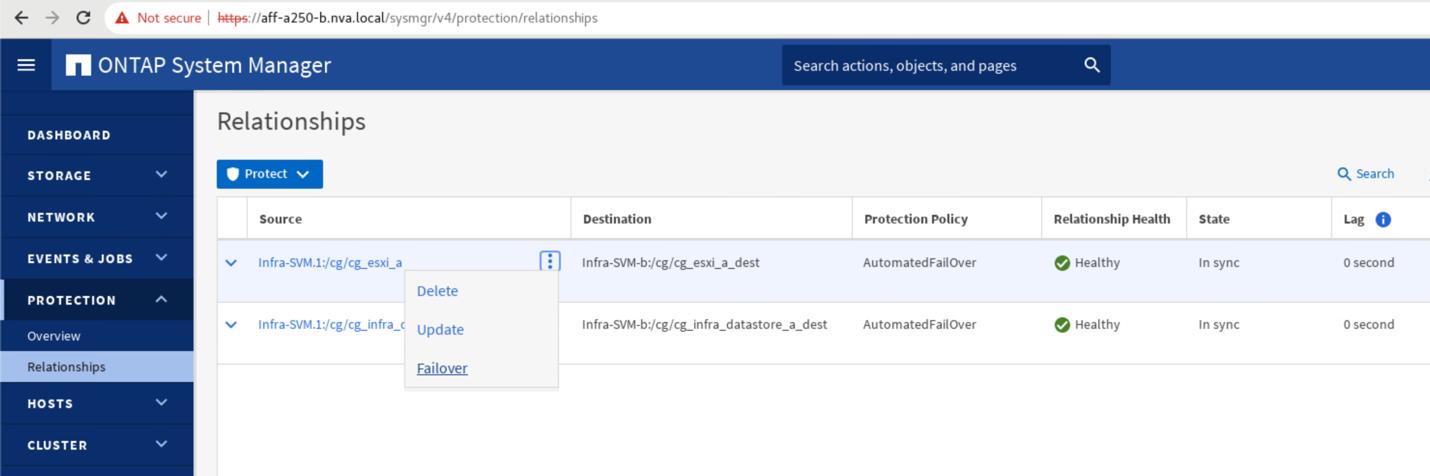
-
Bestätigen Sie das Failover für den Start der Aktion.
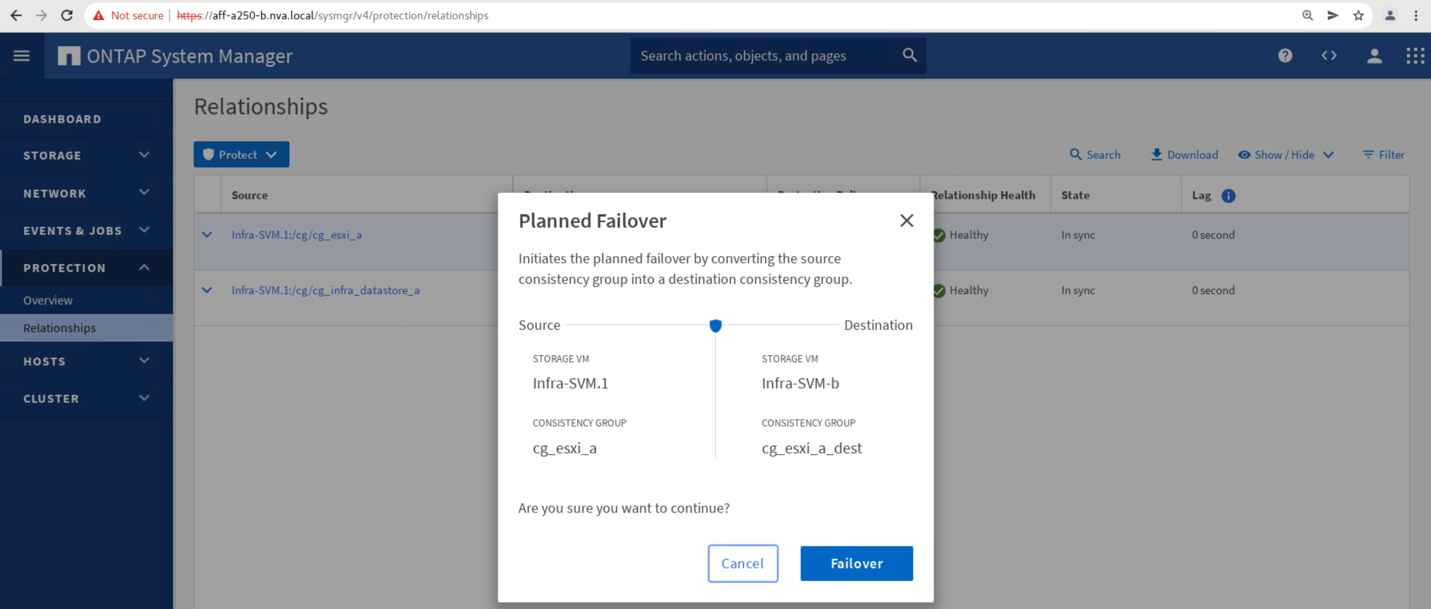
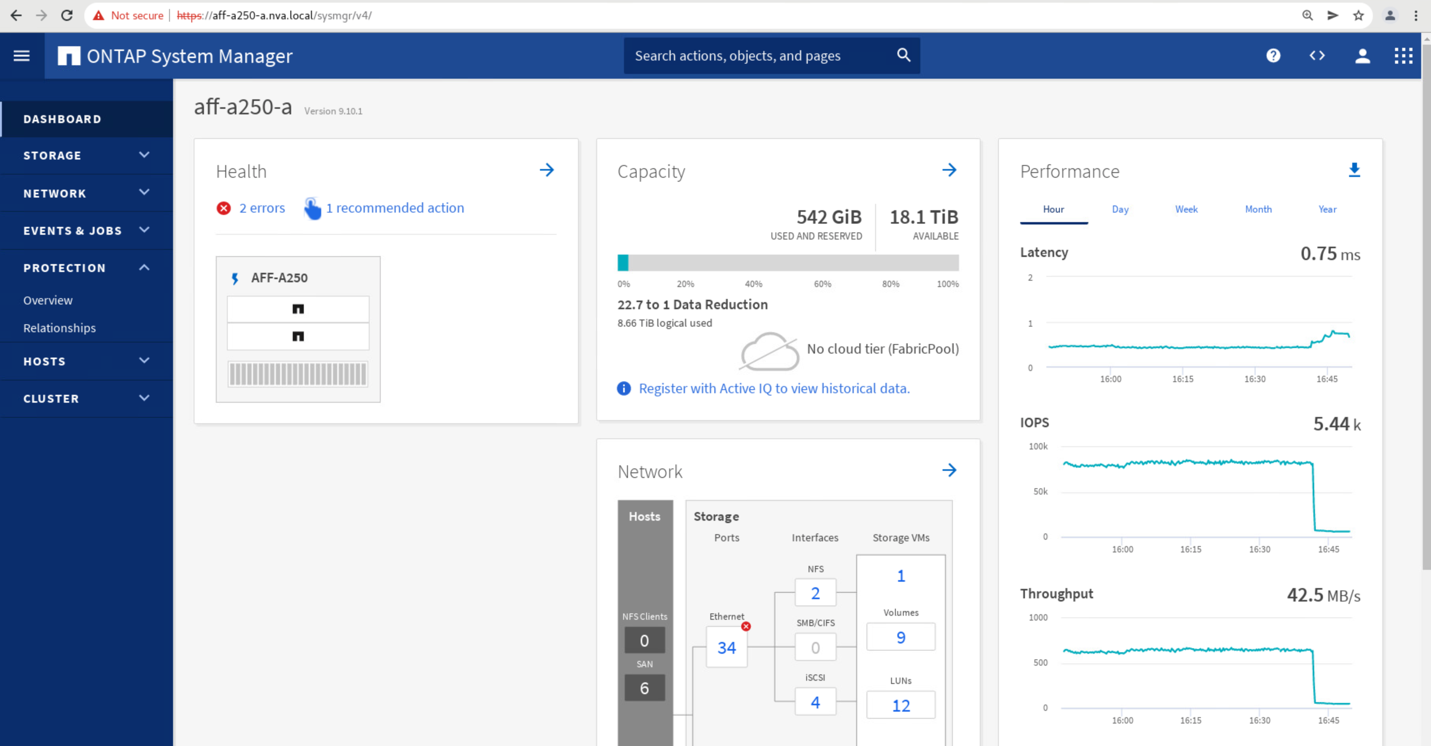
Kurz nach dem Start des Failover der beiden Konsistenzgruppen, cg_esxi_a Und cg_infra_datastore_a, Auf der Website B System Manager GUI ist der Standort A I/O, der die beiden Konsistenzgruppen bereitstellt, auf Standort B. verschoben Dadurch wird die I/O an Standort Erheblich reduziert, wie am Standort Das Performance-Teilfenster „System Manager“ dargestellt.
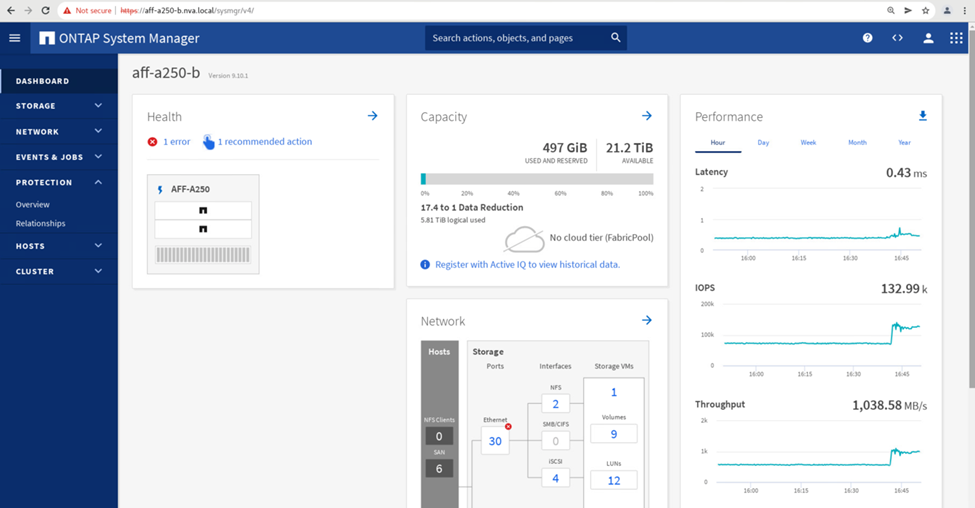
Auf der anderen Seite zeigt das Teilfenster „Performance“ des Dashboards von Standort B System Manager einen deutlich höheren IOPS-Wert, da zusätzliche I/O-Vorgänge von Standort A auf ca. 130.000 IOPS verschoben werden. Und erreichte einen Durchsatz von etwa 1 GB/s bei einer I/O-Latenz von unter 1 Millisekunde.
Wenn die I/O-Vorgänge transparent von Standort A nach Standort B migriert werden, können Storage-Controller an Standort A zu geplanten Wartungsarbeiten heruntergefahren werden. Nachdem die Wartungsarbeiten oder Tests abgeschlossen und ein Storage Cluster wieder betriebsbereit gemacht wurde, prüfen und warten Sie, bis sich der Sicherungsstatus der Konsistenzgruppe wieder in ändert In sync Bevor Sie ein Failover durchführen, um die Failover-I/O von Standort B zurück zu Standort A zurückzugeben Beachten Sie bitte, dass je länger ein Standort zu Wartungszwecken oder für das Testen ausfällt, desto länger dauert es, bis die Daten synchronisiert und die Konsistenzgruppe wieder an den zurückgesendet wird In sync Bundesland.
Ungeplantes Storage-Failover
Wenn ein echter Notfall eintritt oder während einer Disaster Simulation auftritt, kann ein ungeplantes Storage-Failover erfolgen. Die folgende Abbildung zeigt beispielsweise, in der das Storage-System an Standort A einen Stromausfall hat, ein ungeplantes Storage-Failover ausgelöst wird und die Datenservices für Standort A LUNs, die durch die SM-BC-Beziehungen gesichert sind, von Standort B fortgesetzt werden
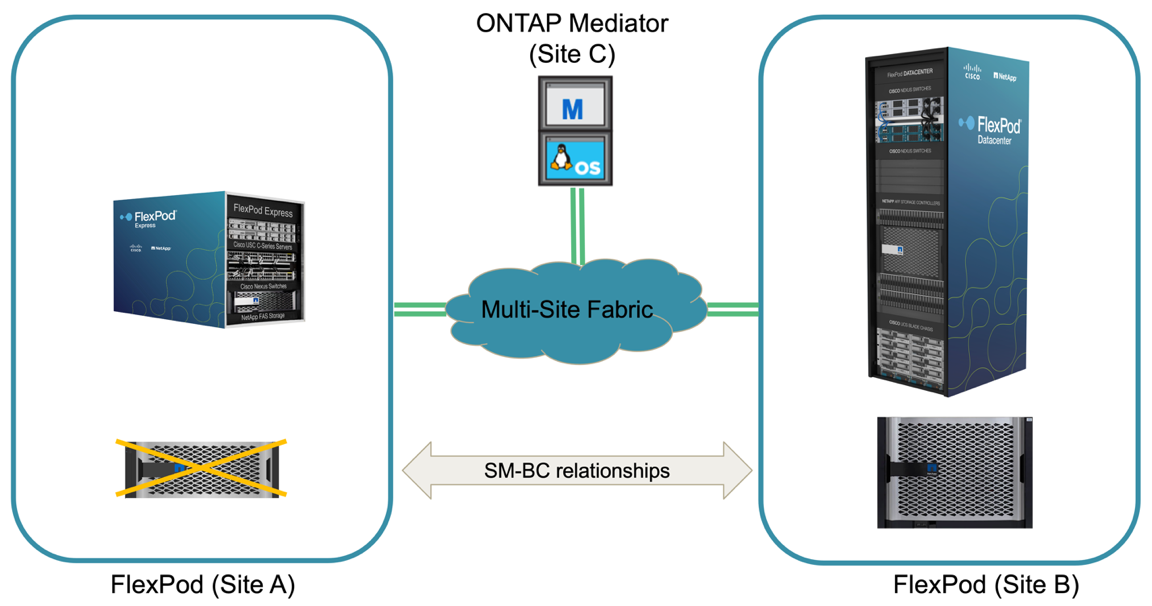
Um einen Storage-Ausfall an Standort A zu simulieren, können beide Storage Controller an Standort A ausgeschaltet werden, indem der Netzschalter deaktiviert wird, um die Stromversorgung der Controller einzustellen, Oder mit dem System Power Management Befehl der Speichercontroller-Prozessoren zum Ausschalten der Controller.
Wenn der Storage Cluster an Standort Mit Strom versorgt wird, findet ein plötzlicher Stopp der Datenservices statt, die von Standort A Storage-Cluster bereitgestellt werden. Anschließend erkennt der ONTAP Mediator, der die SM-BC-Lösung von einem dritten Standort aus überwacht, den Standort Als Storage-Ausfall und ermöglicht der SM-BC-Lösung ein automatisiertes ungeplantes Failover. Dadurch können Standort B Storage Controller Datenservices für die LUNs fortsetzen, die in den SM-BC-Konsistenzgruppenbeziehungen mit Standort A konfiguriert sind
Aus der Applikationsperspektive stehen die Datenservices kurz vor der Pause, während das Betriebssystem den Pfadstatus der LUNs überprüft und mit den verfügbaren Pfaden zu den verbleibenden Storage Controllern am Standort B fortfahren.
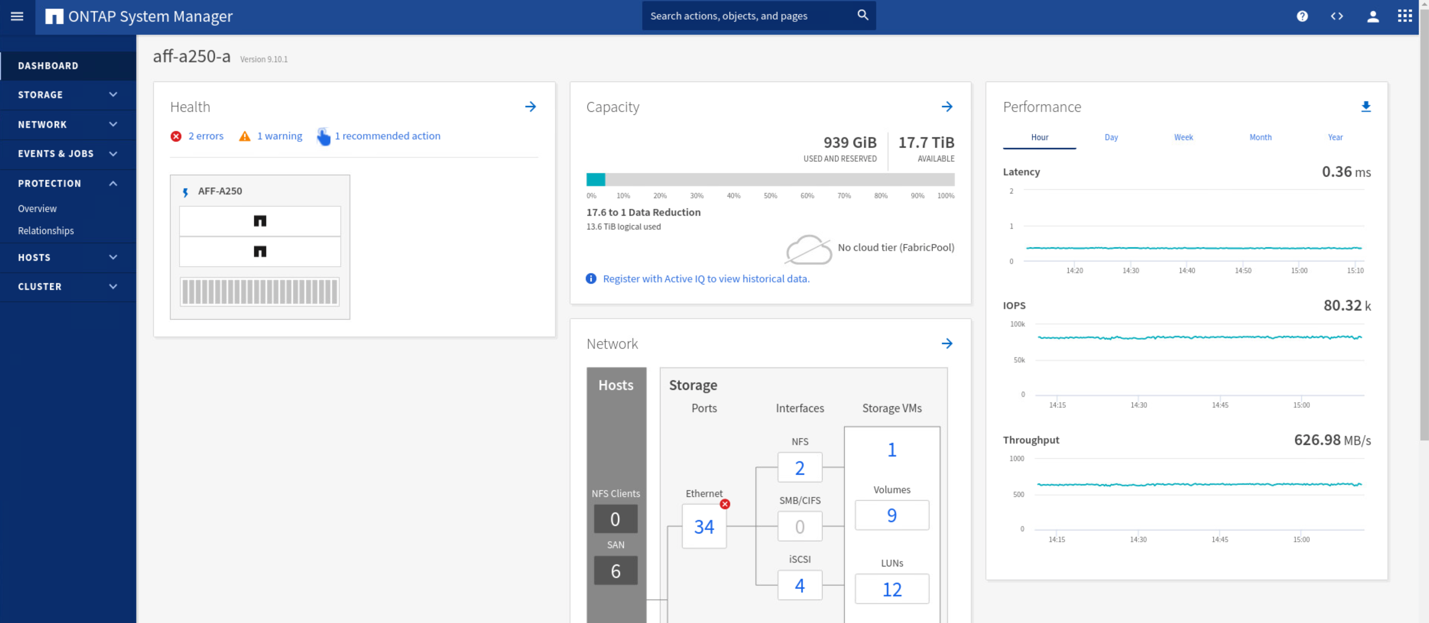
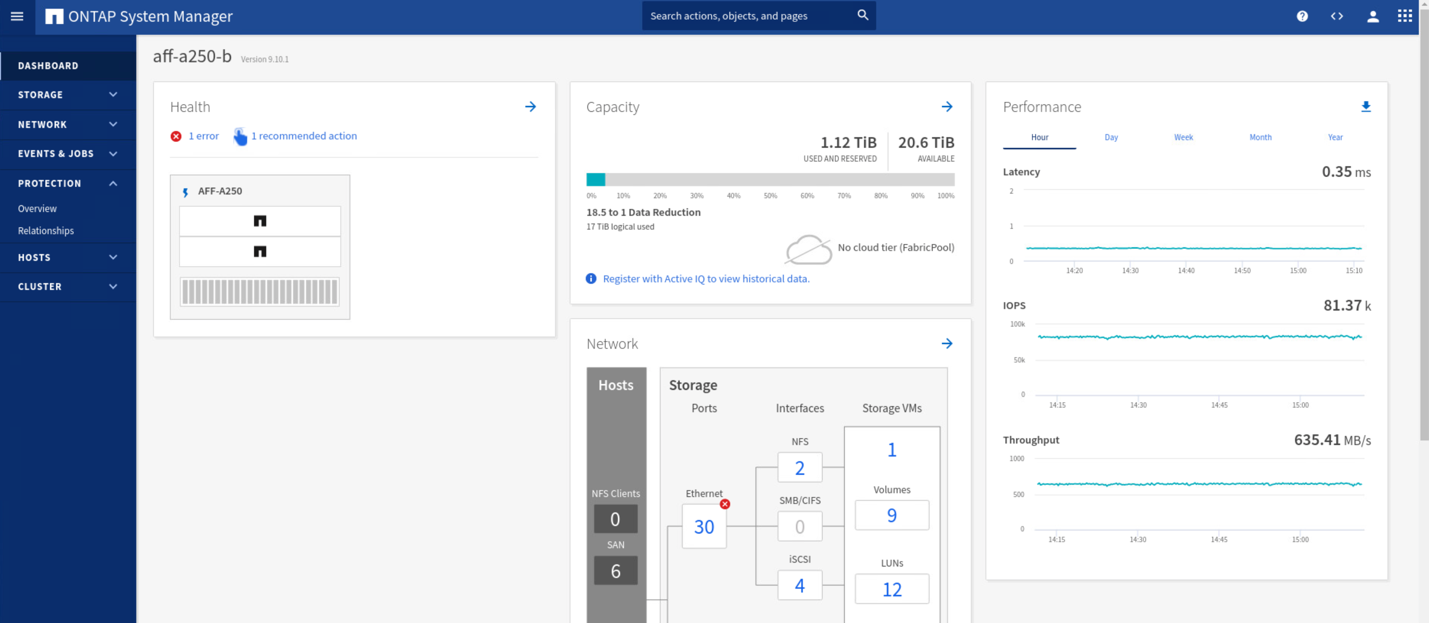
Während der Validierungstests generiert das IOMeter Tool auf den VMs an beiden Standorten I/O-Vorgänge für die lokalen Datenspeicher. Nachdem der Standort Ein Cluster ausgeschaltet war, wurden die I/O-Vorgänge kurz angehalten und danach wieder aufgenommen. In den folgenden beiden Abbildungen sind die Dashboards des Storage-Clusters an Standort A und Standort B bzw. vor dem Desaster dargestellt, die rund 80.000 IOPS und einen Durchsatz von 600 MB/s an jedem Standort zeigen.
Nach dem Ausschalten der Storage-Controller an Standort A können wir visuell validieren, dass der I/O-Wert des Standort B Storage-Controllers stark erhöht wird, um zusätzliche Datenservices für Standort A bereitzustellen (siehe folgende Abbildung). Darüber hinaus zeigte die GUI der IOMeter VMs außerdem, dass die I/O-Vorgänge trotz eines Ausfalls des Standorts Im Storage-Cluster fortgesetzt wurden. Beachten Sie bitte, dass bei einem Storage-Ausfall zusätzliche Datastores, die von LUNs nicht durch SM-BC-Beziehungen gesichert werden, nicht mehr zugänglich sind. Daher ist es wichtig, die geschäftlichen Anforderungen der verschiedenen Applikationsdaten zu bewerten und sie ordnungsgemäß in durch SM-BC-Beziehungen gesicherten Datenspeichern abzulegen, um Business Continuity zu gewährleisten.
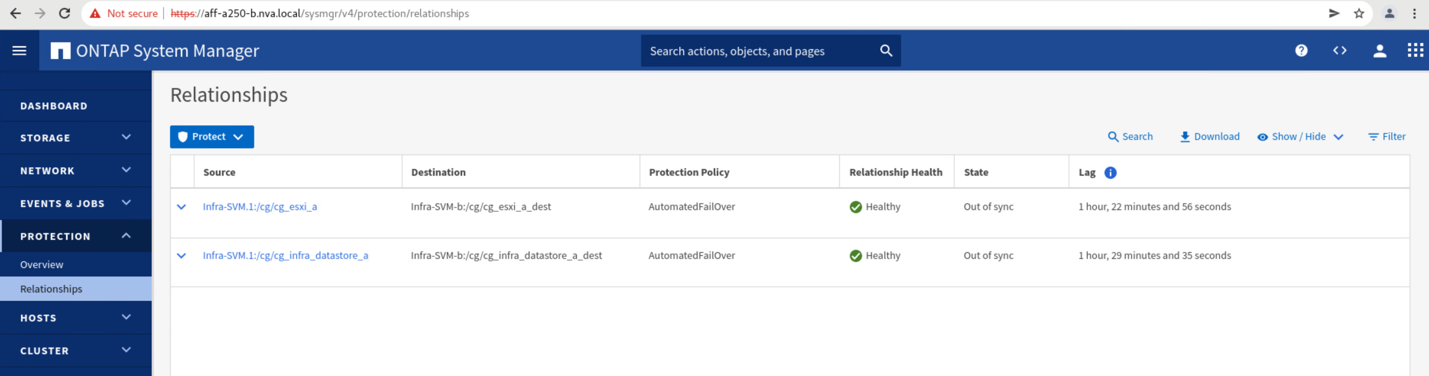
Während der Standort Ein Cluster ausfällt, werden die Beziehungen der konsistenten Gruppen angezeigt Out of sync Status wie in der folgenden Abbildung dargestellt. Nachdem die Stromversorgung für die Storage-Controller an Standort A wieder eingeschaltet ist, startet das Storage-Cluster und die Datensynchronisierung zwischen Standort A und Standort B erfolgt automatisch.
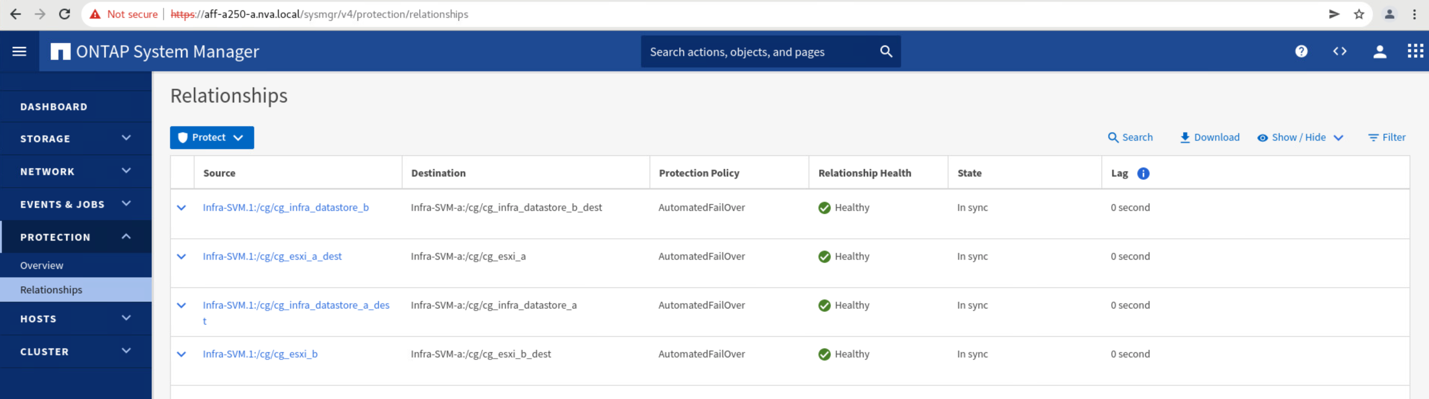
Bevor Sie die Datenservices von Standort B zurück an Standort A zurücksenden, müssen Sie Standort A System Manager überprüfen und sicherstellen, dass die SM-BC-Beziehungen erfasst werden und der Status wieder synchron ist. Nachdem Sie bestätigt haben, dass die Konsistenzgruppen synchron sind, kann ein manueller Failover-Vorgang gestartet werden, um Datendienste in den Beziehungen der Konsistenzgruppen zurück an Standort A zurückzugeben
Komplette Wartung des Standorts oder des Standorts
Möglicherweise müssen Standortwartungsarbeiten durchgeführt, Stromverluste oder Naturkatastrophen wie Hurrikan oder Erdbeben ihre Auswirkungen haben. Daher ist es von entscheidender Bedeutung, dass geplante und ungeplante Standortausfälle angewendet werden, um sicherzustellen, dass Ihre FlexPod SM-BC Lösung richtig konfiguriert ist, damit diese Ausfälle all Ihrer geschäftskritischen Applikationen und Datenservices überleben können. Die folgenden standortbezogenen Szenarien wurden validiert.
-
Geplantes Szenario für die Standortwartung durch Migration von Virtual Machines und wichtigen Datenservices zu einem anderen Standort
-
Szenario mit ungeplanten Standortausfällen durch Ausschalten von Servern und Storage Controllern zur Disaster Simulation
Um einen Standort für die geplante Standortwartung vorbereitet zu sein, sind eine Kombination aus der Migration der betroffenen Virtual Machines vom Standort mit vMotion und ein manuelles Failover der SM-BC Consistency Group-Beziehungen erforderlich, um Virtual Machines und wichtige Datenservices auf einen alternativen Standort zu migrieren. Die Tests wurden in zwei verschiedenen Bestellungen durchgeführt: VMotion, zuerst gefolgt von SM-BC Failover und SM-BC Failover, gefolgt von vMotion, um sicherzustellen, dass die Virtual Machines weiterhin ausgeführt werden und die Datenservices nicht unterbrochen werden.
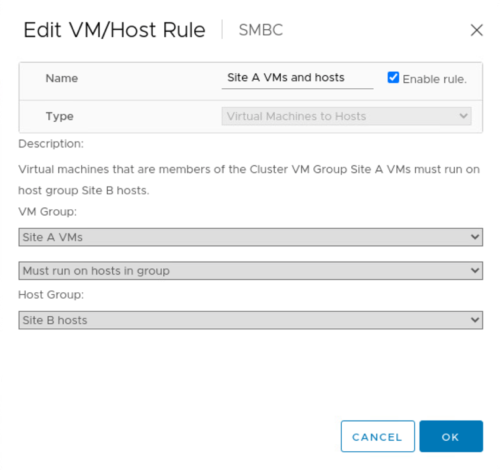
Aktualisieren Sie vor Durchführung der geplanten Migration die VM-/Host-Affinitätsregel, damit die VMs, die aktuell am Standort ausgeführt werden, automatisch von dem Wartungsort migriert werden. Der folgende Screenshot zeigt ein Beispiel für die Änderung der Regel für eine VM/Host-Affinität, die von VMs automatisch von Standort A nach Standort B migriert werden soll. Sie müssen nicht angeben, dass die VMs nun auf Standort B ausgeführt werden müssen, sondern können die Affinitätsregel vorübergehend deaktivieren, sodass die VMs manuell migriert werden können.
Nach der Migration von Virtual Machines und Storage Services können Sie Server, Storage Controller, Platten-Shelves und Switches ausschalten und die erforderlichen Wartungsarbeiten am Standort durchführen. Wenn die Standortwartung abgeschlossen ist und die FlexPod Instanz wieder aufgenommen wird, können Sie die Host-Gruppenaffinität für die VMs ändern, um wieder an den ursprünglichen Standort zurückzukehren. Danach sollten Sie die Regel „muss auf Hosts in Gruppe laufen“ VM/Host Site Affinity zurück zu „sollte auf Hosts in der Gruppe laufen“ ändern, so dass virtuelle Maschinen auf Hosts an dem anderen Standort ausgeführt werden dürfen, sollte eine Katastrophe stattfinden. Für die Validierungstests wurden alle Virtual Machines erfolgreich an den anderen Standort migriert, und die Datenservices werden nach dem Failover für die SM-BC-Beziehungen ohne Probleme fortgesetzt.
Bei der ungeplanten Disaster-Simulation am Standort wurden die Server und Storage Controller ausgeschaltet, um einen Standortausfall zu simulieren. Die VMware HA-Funktion erkennt die heruntergefahrenen Virtual Machines und startet die Virtual Machines am noch intakten Standort neu. Zudem erkennt der ONTAP Mediator, der an einem dritten Standort ausgeführt wird, den Standortausfall und der überlebende Standort initiiert einen Failover und beginnt mit der Bereitstellung von Datenservices für den Down-Standort wie erwartet.
Der folgende Screenshot zeigt, dass die Speicher-Controller Service-Prozessor-CLI verwendet wurden, um den Standort Ein Cluster abrupt auszuschalten, um eine Speicherkatastrophe zu simulieren.
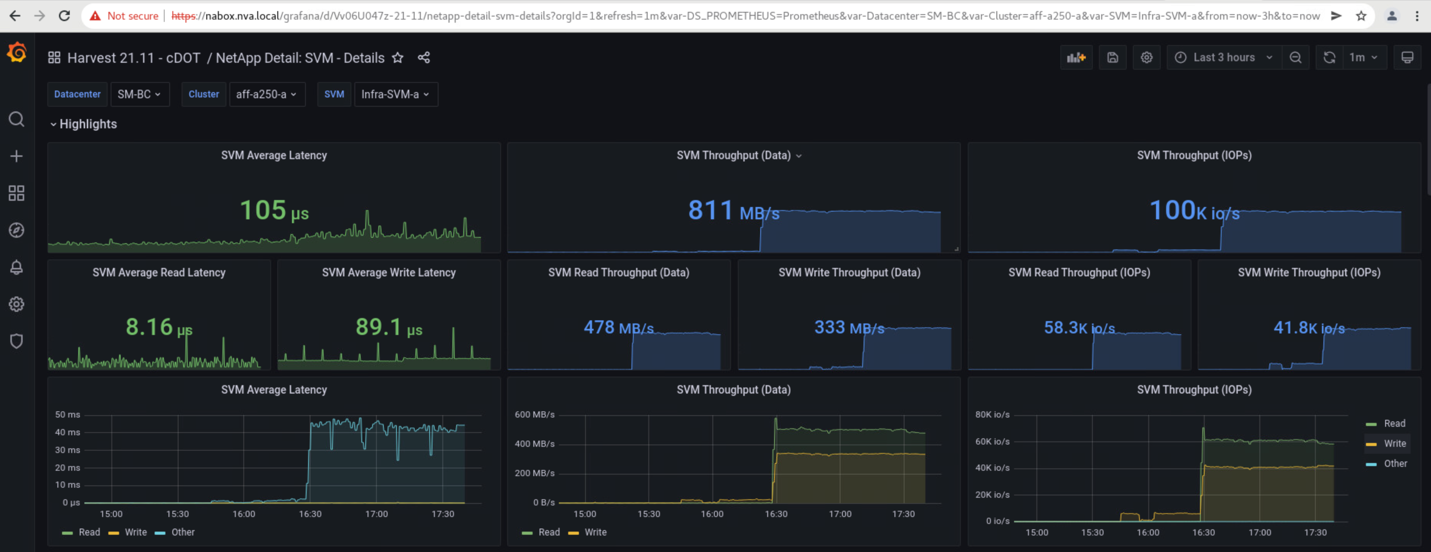
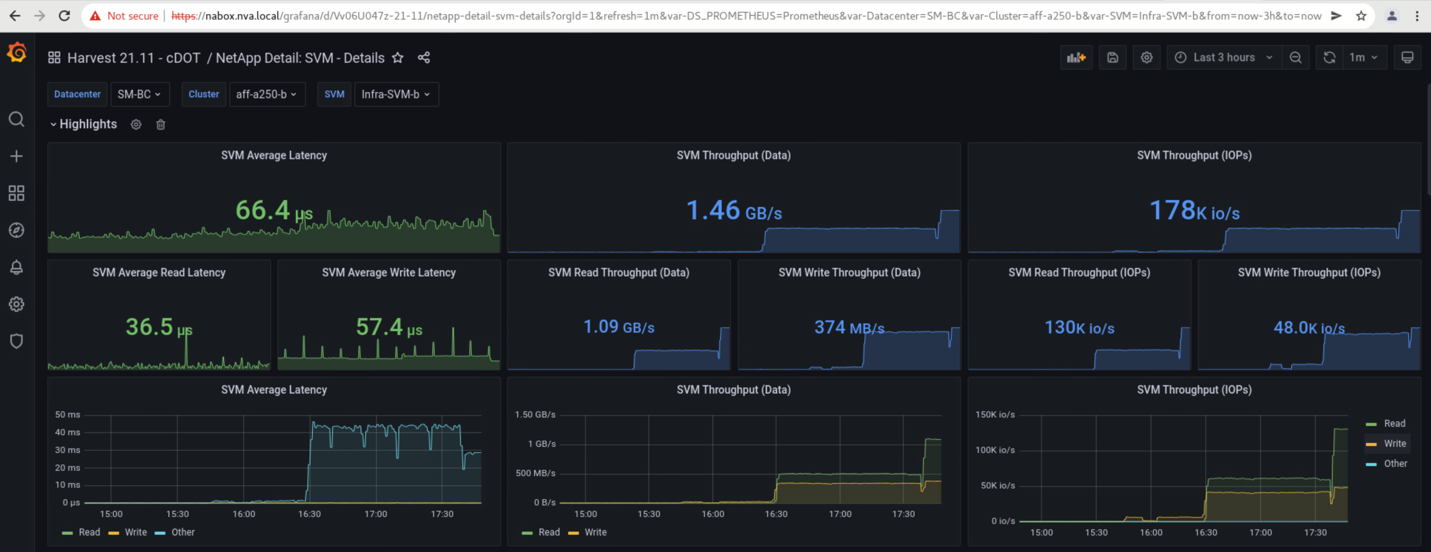
Die Storage Virtual Machine Dashboards von Storage-Clustern, die vom NetApp Harvest Datenerfassungs-Tool erfasst und in Grafana Dashboard im NABox-Monitoring-Tool angezeigt werden, sind in den folgenden zwei Screenshots dargestellt. Wie auf der rechten Seite der IOPS- und Durchsatzdiagramme zu sehen ist, wählt der Cluster B sofort einen Storage-Workload aus, nachdem Standort Ein Cluster ausfällt.
Microsoft SQL Server
Microsoft SQL Server ist eine weit verbreitete und implementierte Datenbankplattform für DIE IT in Unternehmen. Die Version Microsoft SQL Server 2019 enthält zahlreiche neue Funktionen und Verbesserungen für seine relationalen und analytischen Engines. Sie unterstützt Workloads bei Applikationen, die lokal, in der Cloud und bei hybriden Umgebungen über eine Kombination dieser Applikationen ausgeführt werden. Darüber hinaus kann die Lösung auf diversen Plattformen implementiert werden, darunter Windows, Linux und Container.
Im Rahmen der geschäftskritischen Workload-Validierung für die FlexPod SM-BC Lösung wird Microsoft SQL Server 2019 auf einer Windows Server 2022 VM installiert. Außerdem sind die IOMeter VMs für geplante und ungeplante Storage Failover-Tests enthalten. Auf der Windows Server 2022 VM wird SQL Server Management Studio installiert, um den SQL Server zu verwalten. Das Datenbanktool HammerDB wird für Tests zur Generierung von Datenbanktransaktionen eingesetzt.
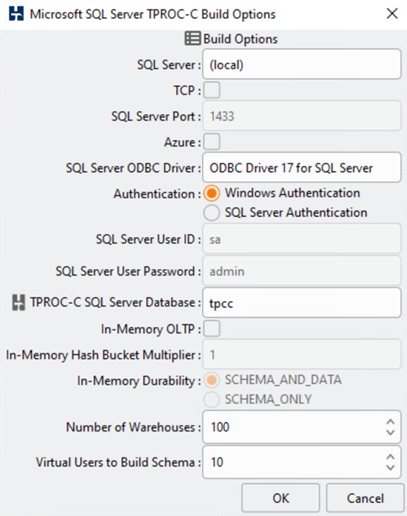
Das HammerDB Datenbank-Testtool wurde für die Prüfung mit dem Microsoft SQL Server TPROC-C Workload konfiguriert. Für die Schemakonfigurationen wurden die Optionen aktualisiert, um 100 Lagerhäuser mit 10 virtuellen Benutzern zu verwenden, wie im folgenden Screenshot dargestellt.
Nachdem die Optionen zum Erstellen des Schemas aktualisiert wurden, wurde der Prozess zum Erstellen des Schemas gestartet. Einige Minuten später wurde ein ungeplanter Storage-Cluster an Standort B durch das gleichzeitige Herunterfahren beider Nodes des AFF A250 Storage-Clusters mit zwei Nodes mithilfe von CLI-Befehlen eingeleitet.
Nach einer kurzen Pause von Datenbanktransaktionen trat das automatisierte Failover zur Disaster-Korrektur ein und die Transaktionen wurden wieder aufgenommen. Der folgende Screenshot zeigt den HammerDB Transaction Counter Screenshot um diese Zeit. Da sich die Datenbank für den Microsoft SQL Server normalerweise im Storage-Cluster vor Ort B befindet, pausierte die Transaktion kurz, als der Storage an Standort B ausfällt und nach dem automatisierten Failover wieder aufgenommen wurde.
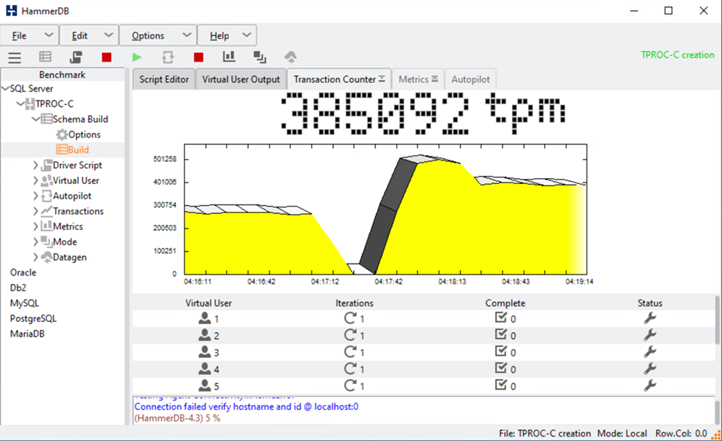
Die Storage Cluster-Kennzahlen wurden mithilfe des NAbox Tools mit dem installierten NetApp Harvest Monitoring Tool erfasst. Die Ergebnisse werden in den vordefinierten Grafana Dashboards für die Storage Virtual Machine und andere Speicherobjekte angezeigt. Das Dashboard bietet Matrizen für Latenz, Durchsatz, IOPS und zusätzliche Details mit Lese- und Schreibstatistiken, die sowohl für Standort B als auch Standort A getrennt sind
Dieser Screenshot zeigt das NAbox Grafana Performance-Dashboard für Storage-Cluster an Standort B.
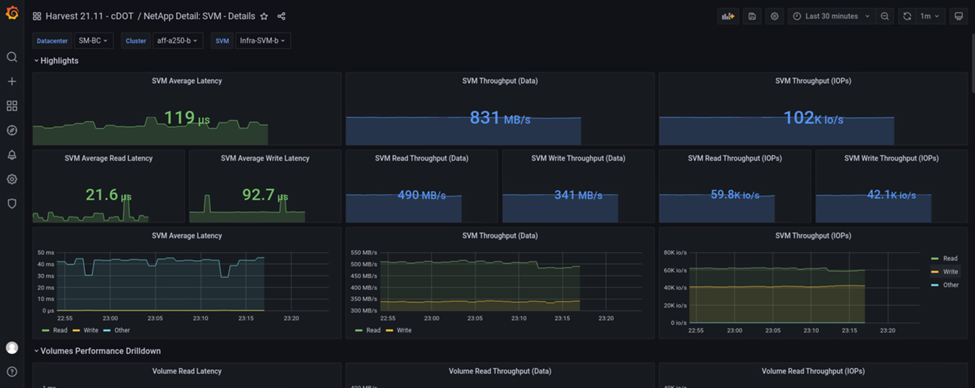
Die IOPS für das Storage-Cluster am Standort B wiesen circa 100.000 IOPS auf, bevor der Ausfall einführte. Anschließend zeigte die Performance-Metriken einen deutlichen Rückgang auf Null auf der rechten Seite der Diagramme aufgrund des Ausfalls. Da der Storage-Cluster Standort B ausgefallen war, konnte nach der Katastrophe kein Storage-Cluster am Standort B gesammelt werden.
Andererseits nahmen die IOPS für den Standort Ein Storage-Cluster die zusätzlichen Workloads von Standort B nach dem automatisierten Failover ab. Der zusätzliche Workload kann im folgenden Screenshot auf der rechten Seite der IOPS- und Durchsatzdiagramme angezeigt werden. Darin wird das NAbox Grafana Performance-Dashboard für Standort A Storage-Cluster angezeigt.
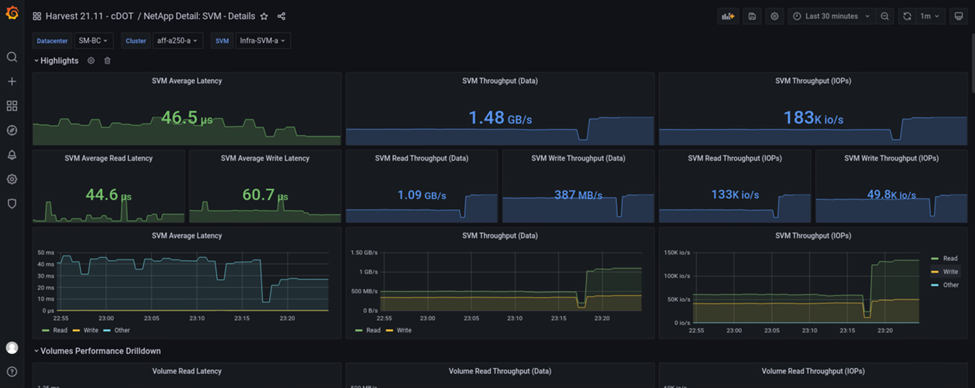
Das oben aufgeführte Szenario für das Storage-Disaster-Test bestätigte, dass der Microsoft SQL Server Workload einen vollständigen Ausfall des Storage-Clusters an Standort B überleben kann, wo sich die Datenbank befindet. Die Applikation verwendete die von dem Standort Einem Storage-Cluster bereitgestellten Datenservices transparent, nachdem ein Ausfall erkannt und der Failover stattgefunden hat.
Wenn auf der Rechenebene die VMs, die an einem bestimmten Standort ausgeführt werden, ein Host-Ausfall auftreten, werden die VMs so konzipiert, dass sie automatisch durch die VMware HA-Funktion neu gestartet werden. Für einen vollständigen Ausfall des Standorts ermöglicht es die VM-/Host-Affinitätsregeln, VMs am noch intakten Standort neu zu starten. Damit eine geschäftskritische Applikation unterbrechungsfreie Services bereitstellen kann, ist jedoch ein applikationsbasiertes Clustering wie Microsoft Failover Cluster oder Container-basierte Applikationsarchitektur für Kubernetes erforderlich, um Ausfallzeiten bei Applikationen zu vermeiden. Bitte lesen Sie das entsprechende Dokument zur Implementierung des applikationsbasierten Clustering. Dieses Dokument übersteigt den Rahmen dieses technischen Berichts.