

Data Mover-Lösung
 Änderungen vorschlagen
Änderungen vorschlagen
In einem Big-Data-Cluster werden Daten in HDFS oder HCFS gespeichert, beispielsweise in MapR-FS, dem Windows Azure Storage Blob, S3 oder dem Google-Dateisystem. Wir haben Tests mit HDFS, MapR-FS und S3 als Quelle durchgeführt, um Daten mit Hilfe von NIPAM in den NetApp ONTAP NFS-Export zu kopieren, indem wir die hadoop distcp Befehl von der Quelle.
Das folgende Diagramm veranschaulicht die typische Datenbewegung von einem Spark-Cluster mit HDFS-Speicher zu einem NetApp ONTAP NFS-Volume, damit NVIDIA KI-Operationen verarbeiten kann.
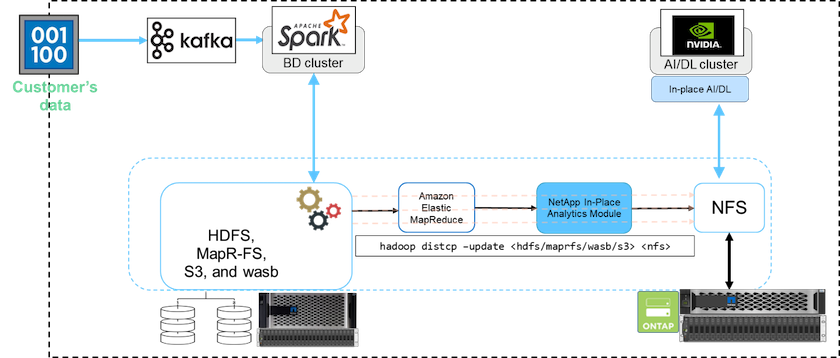
Der hadoop distcp Der Befehl verwendet das MapReduce-Programm zum Kopieren der Daten. NIPAM arbeitet mit MapReduce zusammen, um beim Kopieren von Daten als Treiber für den Hadoop-Cluster zu fungieren. NIPAM kann eine Last für einen einzelnen Export auf mehrere Netzwerkschnittstellen verteilen. Dieser Prozess maximiert den Netzwerkdurchsatz, indem die Daten beim Kopieren von HDFS oder HCFS nach NFS auf mehrere Netzwerkschnittstellen verteilt werden.

|
NIPAM wird von MapR weder unterstützt noch zertifiziert. |