

Beispiel-Workflow – Trainieren eines Bilderkennungsmodells mit Kubeflow und dem NetApp DataOps Toolkit
 Änderungen vorschlagen
Änderungen vorschlagen
In diesem Abschnitt werden die Schritte zum Trainieren und Bereitstellen eines neuronalen Netzwerks für die Bilderkennung mit Kubeflow und dem NetApp DataOps Toolkit beschrieben. Dies soll als Beispiel für einen Trainingsjob dienen, der NetApp -Speicher einbezieht.
Voraussetzungen
Erstellen Sie eine Docker-Datei mit den erforderlichen Konfigurationen für die Trainings- und Testschritte innerhalb der Kubeflow-Pipeline. Hier ist ein Beispiel für eine Docker-Datei -
FROM pytorch/pytorch:latest
RUN pip install torchvision numpy scikit-learn matplotlib tensorboard
WORKDIR /app
COPY . /app
COPY train_mnist.py /app/train_mnist.py
CMD ["python", "train_mnist.py"]Installieren Sie je nach Ihren Anforderungen alle erforderlichen Bibliotheken und Pakete, die zum Ausführen des Programms erforderlich sind. Bevor Sie das Machine-Learning-Modell trainieren, wird davon ausgegangen, dass Sie bereits über eine funktionierende Kubeflow-Bereitstellung verfügen.
Trainieren Sie ein kleines neuronales Netzwerk anhand von MNIST-Daten mithilfe von PyTorch- und Kubeflow-Pipelines
Wir verwenden das Beispiel eines kleinen neuronalen Netzwerks, das mit MNIST-Daten trainiert wurde. Der MNIST-Datensatz besteht aus handschriftlichen Bildern der Ziffern 0-9. Die Bilder haben eine Größe von 28 x 28 Pixel. Der Datensatz ist in 60.000 Zugbilder und 10.000 Validierungsbilder unterteilt. Das für dieses Experiment verwendete neuronale Netzwerk ist ein zweischichtiges Feedforward-Netzwerk. Das Training wird mithilfe von Kubeflow Pipelines durchgeführt. Weitere Informationen finden Sie in der Dokumentation "hier," für weitere Informationen. Unsere Kubeflow-Pipeline enthält das Docker-Image aus dem Abschnitt „Voraussetzungen“.
Visualisieren Sie Ergebnisse mit Tensorboard
Sobald das Modell trainiert ist, können wir die Ergebnisse mit Tensorboard visualisieren. "Tensorboard" ist als Funktion im Kubeflow-Dashboard verfügbar. Sie können ein benutzerdefiniertes Tensorboard für Ihren Job erstellen. Ein Beispiel unten zeigt die Darstellung der Trainingsgenauigkeit im Vergleich zur Anzahl der Epochen und des Trainingsverlusts im Vergleich zur Anzahl der Epochen.

Experimentieren Sie mit Hyperparametern mit Katib
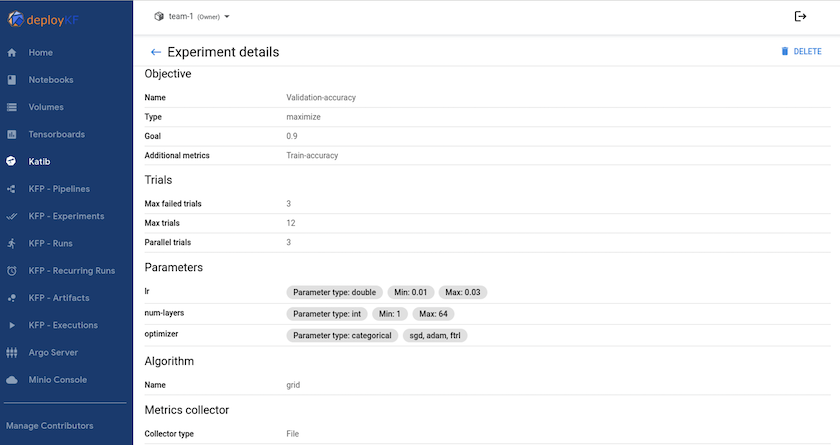
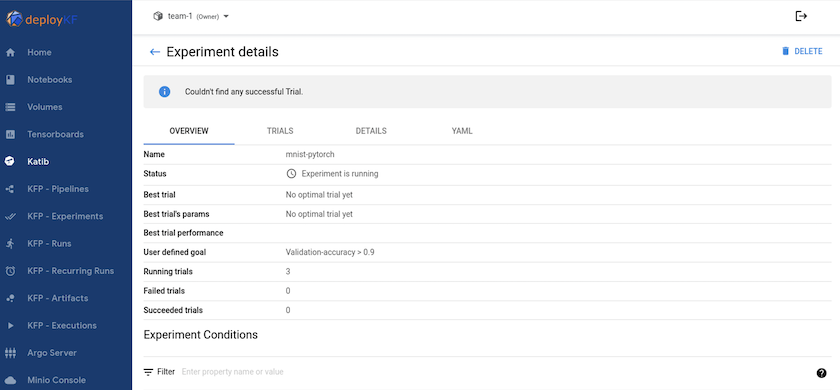
"Katib"ist ein Tool innerhalb von Kubeflow, mit dem mit den Hyperparametern des Modells experimentiert werden kann. Um ein Experiment zu erstellen, definieren Sie zuerst eine gewünschte Metrik/ein gewünschtes Ziel. Dies ist normalerweise die Testgenauigkeit. Sobald die Metrik definiert ist, wählen Sie Hyperparameter aus, mit denen Sie herumspielen möchten (Optimierer/Lernrate/Anzahl der Schichten). Katib führt einen Hyperparameter-Sweep mit den benutzerdefinierten Werten durch, um die beste Parameterkombination zu finden, die die gewünschte Metrik erfüllt. Sie können diese Parameter in jedem Abschnitt der Benutzeroberfläche definieren. Alternativ können Sie eine YAML-Datei mit den erforderlichen Spezifikationen definieren. Unten sehen Sie eine Illustration eines Katib-Experiments -
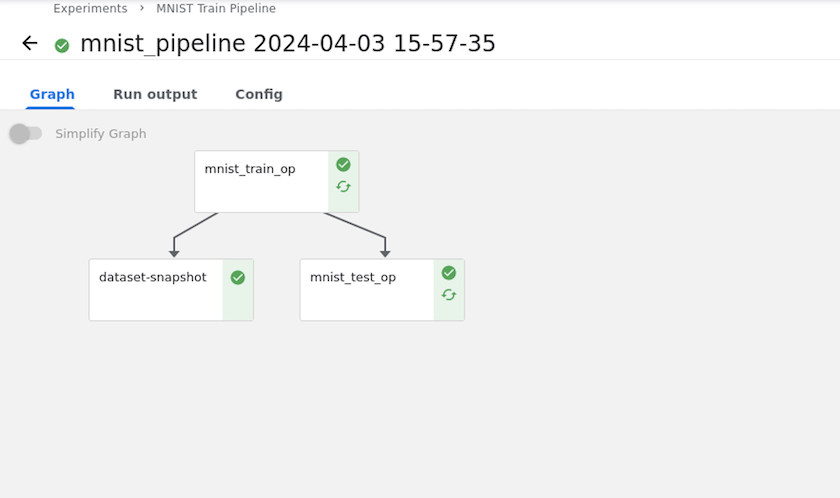
Verwenden Sie NetApp Snapshots zum Speichern von Daten zur Rückverfolgbarkeit
Während des Modelltrainings möchten wir möglicherweise zur Rückverfolgbarkeit einen Snapshot des Trainingsdatensatzes speichern. Dazu können wir der Pipeline einen Snapshot-Schritt hinzufügen, wie unten gezeigt. Um den Snapshot zu erstellen, können wir die "NetApp DataOps Toolkit für Kubernetes" .

Weitere Informationen finden Sie im "NetApp DataOps Toolkit-Beispiel für Kubeflow" für weitere Informationen.