

Konfigurieren von SQL Server Always On-Verfügbarkeitsgruppen mit Google Cloud NetApp Volumes
 Änderungen vorschlagen
Änderungen vorschlagen
Konfigurieren Sie SQL Server Always On-Verfügbarkeitsgruppen auf Google Compute Engine-Instanzen innerhalb eines einzelnen Subnetzes mithilfe von Google Cloud NetApp Volumes iSCSI-Blockspeicher. Erfahren Sie, wie Sie Compute-Instanzen einrichten, NetApp Volumes konfigurieren, Failover-Clustering erstellen und Verfügbarkeitsgruppen für Hochverfügbarkeit und Notfallwiederherstellung bereitstellen.
Voraussetzungen
Bevor Sie fortfahren, führen Sie die Konfigurationsvoraussetzungsschritte in der Google Cloud-Dokumentation aus:
Bevor Sie beginnen
Stellen Sie sicher, dass Sie die folgenden Anforderungen erfüllt haben:
-
Google Cloud project mit Administratorrechten für Compute, Netzwerk, IAM und Storage
-
VPC-Netzwerk mit Subnetz für eine Region-Setup
-
Active Directory und DNS-Einrichtung in einer Region verfügbar
-
Firewall-Regeln so konfiguriert, dass die erforderlichen Ports zugelassen werden
-
Kenntnisse im Umgang mit SQL Server Always On availability groups und Failover Clustering

|
Neue Google Cloud-Nutzer könnten für "kostenlose Testguthaben" berechtigt sein. |
Ziele
Die Konfiguration der SQL Server Always On availability group umfasst die folgenden übergeordneten Aufgaben:
-
Compute Engine-Instanzen und NetApp-Speichervolumes einrichten
-
Richten Sie SQL Server auf beiden Knoten ein
-
Windows Server Failover Cluster einrichten
-
Cluster-Quorum mit Dateifreigabe-Witness einrichten
-
SQL Server-Verfügbarkeitsgruppen einrichten
-
Distributed Network Name (DNN) für den Listener-Zugriff einrichten
Kostenüberlegungen
Dieses Tutorial verwendet kostenpflichtige Komponenten von Google Cloud, einschließlich "Compute Engine-Instanzen" und "Google Cloud NetApp Volumes" Speicher.
Verwenden Sie das "Preisrechner" , um einen Kostenvoranschlag basierend auf Ihren Rechen- und Speicheranforderungen zu erstellen. Die Beispielkonfiguration verwendet N4-SKU-Compute-Instanzen und NetApp Flex-Service-Level-Speicher für die Einrichtung der SQL Server Always On Availability Group.
Domänenkonten konfigurieren
Konfigurieren Sie zwei Konten in Active Directory: ein Installationskonto (Ihr Admin-Konto) und ein Dienstkonto für beide SQL Server VMs.
Verwenden Sie beispielsweise die Werte in der folgenden Tabelle für die Konten:
|
|
In diesem Beispiel wird cvsdemo als Domainname verwendet. Ersetzen Sie cvsdemo im gesamten Verfahren durch Ihren tatsächlichen Domainnamen.
|
| Konto | VM | Vollständiger Domainname | Beschreibung |
|---|---|---|---|
<your account> |
Beide (sqlnode1 und sqlnode2) |
cvsdemo\DomainAdmin |
Administratorkonto zum Anmelden an einer der VMs und zum Konfigurieren des Clusters und der Verfügbarkeitsgruppe |
sqlsvc |
Beide (sqlnode1 und sqlnode2) |
cvsdemo\sqlsvc |
Dienstkonto für SQL Server und SQL Server Agent auf beiden SQL Server-VMs |
Compute Engine-VMs für SQL Server erstellen
Erstellen Sie zwei Google Compute Engine VM-Instanzen mit vorinstalliertem SQL Server 2022 Enterprise auf Windows Server 2025, um die Verfügbarkeitsgruppen-Replikate zu hosten.
-
Gehen Sie in der Google Cloud Console zur "Instanz erstellen" Seite.
Weitere Informationen finden Sie in der "Google Cloud-Dokumentation".
-
Für Name geben Sie
sqlnode1ein. -
Im Abschnitt Machine configuration:
-
Allgemeiner Zweck auswählen
-
Wählen Sie in der Liste Series die Option N4 aus.
-
Wählen Sie in der Liste Maschinentyp die Option n4-highmem-8 (8 vCPU, 64 GB memory) aus.
-
-
Wählen Sie die Region aus, in der Sie Ihre VPC erstellt haben (zum Beispiel region=us-west1, zone=us-west1-a).
-
Klicken Sie im Abschnitt Boot disk auf Change:
-
Auf der Registerkarte Public images wählen Sie in der Liste Operating system die Option SQL Server on Windows Server aus.
-
Wählen Sie in der Liste Version SQL Server 2022 Enterprise on Windows Server 2025 Datacenter aus.
-
Wählen Sie in der Liste Boot disk type die Option Hyperdisk Balanced.
-
Geben Sie im Feld Größe (GB) 50 GB ein.
-
Klicken Sie auf Select, um die Boot-Disk-Konfiguration zu speichern.
-
-
Im Abschnitt Networking bearbeiten Sie die Netzwerkschnittstelle, um die richtige VPC und das richtige Subnetz auszuwählen. Wenn Sie nur eine VPC haben, wird diese standardmäßig ausgewählt.
-
Wählen Sie auf der Netzwerkkarte gVNIC aus.
-
Für "Netzwerkdienstebene" wählen Sie Premium für unternehmenskritische Workloads oder Standard zur Kostenoptimierung.
-
-
Klicken Sie auf Create, um die VM zu erstellen.
-
Wiederholen Sie diese Schritte, um
sqlnode2zu erstellen.
Server der Domäne hinzufügen
Nachdem die VMs erstellt wurden, fügen Sie sie der Active Directory Domain hinzu und installieren Sie die erforderlichen Windows-Funktionen für Failover-Clustering und iSCSI-Konnektivität.
-
Stellen Sie mit dem lokalen Administratorkonto eine Remoteverbindung zur virtuellen Maschine her.
-
Wählen Sie im Server-Manager Lokaler Server aus.
-
Wählen Sie den Link WORKGROUP aus.
-
Im Abschnitt Computer Name wählen Sie Change.
-
Wählen Sie das Kontrollkästchen Domain aus und geben Sie Ihre Domain (for example,
cvsdemo.internal) in das Textfeld ein. -
Klicken Sie auf OK.
-
Im Dialogfeld Windows-Sicherheit geben Sie die Anmeldeinformationen für das Standarddomänenadministratorkonto an (zum Beispiel
cvsdemo\DomainAdmin). -
Wenn die Meldung „Welcome to the cvsdemo.internal domain“ angezeigt wird, klicken Sie auf OK.
-
Klicken Sie auf Schließen und wählen Sie dann Jetzt neu starten im Dialog aus.
-
Nach dem Neustart des Servers fügen Sie das
sqlsvcKonto zur Gruppe „Administratoren“ hinzu.
|
|
Ihre SQL-Instanz wird unter Verwendung des sqlsvc account ausgeführt, das für die Einrichtung von Clustering und Failover erforderlich ist. |
Installieren Sie die erforderlichen Windows-Features
Installieren Sie Failover Clustering und MPIO auf beiden SQL Server VMs entweder mit Server-Manager oder PowerShell.
-
Im Server-Manager wählen Sie Verwalten > Rollen und Features hinzufügen.
-
Wählen Sie Role-based or feature-based installation und klicken Sie auf Weiter.
-
Wählen Sie Ihren Server aus und klicken Sie auf Next.
-
Wählen Sie auf der Seite Features die Optionen Failover Clustering und Multipath I/O aus.
-
Klicken Sie auf Funktionen hinzufügen, wenn Sie dazu aufgefordert werden, Verwaltungstools einzubeziehen.
-
Schließen Sie den Assistenten ab und starten Sie das System neu, wenn Sie dazu aufgefordert werden.
Führen Sie PowerShell als Administrator aus und führen Sie die folgenden Befehle aus:
# Install Failover Clustering and tools
Install-WindowsFeature Failover-Clustering, RSAT-Clustering-PowerShell, RSAT-Clustering-CmdInterface -IncludeAllSubFeature -IncludeManagementTools
# Install/enable MPIO
Install-WindowsFeature -Name Multipath-IO
Enable-MSDSMAutomaticClaim -BusType "iSCSI"
# Install .NET and other SQL prerequisites (if not already installed)
Install-WindowsFeature NET-Framework-45-Core, NET-Framework-45-Features
Install-WindowsFeature RSAT-AD-PowerShelliSCSI-Initiatornamen abrufen
Ermitteln Sie den iSCSI-qualifizierten Namen (IQN) für jede SQL Server-VM, die in die Hostgruppe aufgenommen werden soll, entweder über die iSCSI-Initiator-GUI oder PowerShell.
-
Drücken Sie Win+R oder verwenden Sie die Windows-Suchleiste, um
iscsicplzu öffnen. -
Wechseln Sie im Dialogfeld „iSCSI Initiator Properties“ zur Registerkarte Configuration.
-
Kopieren Sie den Wert Initiator Name und fügen Sie ihn in die Hostgruppe ein.
Beispiel:
iqn.1991-05.com.microsoft:sqlnode1.cvsdemo.internal
Führen Sie den folgenden Befehl in PowerShell aus:
Get-InitiatorPort | Select-Object NodeAddressErstellen Sie NetApp Block-Speichervolumes
Erstellen Sie iSCSI-Blockspeichervolumes mit Google Cloud NetApp Volumes, um hochperformanten, gemeinsam genutzten Speicher für SQL Server-Datenbanken bereitzustellen. Dieser Prozess umfasst die Erstellung einer Hostgruppe, eines Speicherpools und einzelner Volumes für Daten, Protokolle, Temp und Backup.
Erstellen Sie die Hostgruppe
-
Erstellen Sie eine Hostgruppe, die die iSCSI-Initiatoren von beiden SQL-Knoten enthält.
gcloud beta netapp host-groups create HOST_GROUP_NAME \ --location=LOCATION \ --type=ISCSI_INITIATOR \ --hosts=HOSTS \ --os-type=OS_TYPE \ --description=DESCRIPTIONWeitere Einzelheiten finden Sie in der "Erstellen Sie eine Hostgruppe" Dokumentation.
-
Ersetzen Sie die folgenden Werte:
-
HOST_GROUP_NAME: Name der Hostgruppe (zum Beispiel,demosql) -
LOCATION: Region (zum Beispiel,us-west1) -
HOSTS: Durch Kommas getrennte Liste von IQNs sowohl von sqlnode1 als auch von sqlnode2Beispiel:
iqn.1991-05.com.microsoft:sqlnode1.cvsdemo.internal,iqn.1991-05.com.microsoft:sqlnode2.cvsdemo.internal -
OS_TYPE: Betriebssystemtyp (zum Beispiel,WINDOWS) -
DESCRIPTION: Optionale Beschreibung für die Gastgebergruppe
-
Speicherpool erstellen
-
Erstellen Sie einen Speicherpool mit angemessener Kapazität und Leistung.
gcloud netapp storage-pools create POOL_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --service-level=Flex \ --type=Unified \ --capacity=1024 \ --total-throughput=64 \ --total-iops=1024 \ --network=name=VPC_NAME,psa-range=PSA_RANGEWeitere Einzelheiten finden Sie in der "Erstellen eines Speicherpools" Dokumentation.
-
Ersetzen Sie die folgenden Werte:
-
POOL_NAME: Name des Pools (zum Beispiel,sqltest) -
PROJECT_ID: Ihr Google Cloud-Projektname -
LOCATION: Gleicher Standort wie Ihre Compute-Instanzen (zum Beispielus-west1-b) -
CAPACITY: Poolkapazität in GiB (zum Beispiel,1024) -
SERVICE_LEVEL: Servicelevel (zum Beispiel,Flex) -
VPC_NAME: Ihr VPC-Netzwerkname -
PSA_RANGE: Private Services Access-Bereich (zum Beispielxx.xxx.xxx.0/20) -
THROUGHPUT: Optionaler Durchsatz in MiBps (zum Beispiel64) -
IOPS: Optionale IOPS (zum Beispiel,1024)
-
Volumes erstellen
-
Erstellen Sie Volumes für Daten, Protokolle, temporäre Dateien und Backups. Führen Sie den folgenden Befehl für jeden Volume-Typ aus:
gcloud beta netapp volumes create VOLUME_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --storage-pool=POOL_NAME \ --capacity=CAPACITY \ --protocols=ISCSI \ --block-devices="name=VOLUME_NAME,host-groups=HOST_GROUP_PATH,os-type=WINDOWS" \ --snapshot-directory=falseWeitere Einzelheiten finden Sie in der "Erstellen eines Volumes" documentation.
-
Ersetzen Sie die folgenden Werte:
-
VOLUME_NAME: Eindeutiger Name für jedes Volume (zum Beispiel,node1data,node1log,node1temp,node1backup) -
PROJECT_ID: Ihr Google Cloud-Projektname -
LOCATION: Gleicher Speicherort wie der Speicherpool (zum Beispiel,us-west1-b) -
POOL_NAME: Name des Speicherpools (zum Beispiel,sqltest) -
CAPACITY: Speicherkapazität in GiB (zum Beispiel200) -
HOST_GROUP_PATH: Vollständiger Ressourcenpfad zur Hostgruppe (zum Beispielprojects/PROJECT_ID/locations/us-west1/hostGroups/demosql)
-

|
Mehrere Hostgruppen können mit einem #-Zeichen getrennt angegeben werden. |
|
|
Wiederholen Sie diesen Schritt für jeden Volume-Typ: data, log, temp und backup. |
iSCSI-Volumes einbinden
Mounten Sie die nicht gemeinsam genutzten iSCSI-Volumes auf jeder SQL-Instanz:
-
Navigieren Sie in der Google Cloud Console zu NetApp volumes > Volumes.
-
Wählen Sie das für die SQL-Instanz erstellte Volume aus (zum Beispiel
node1data). -
Kopieren Sie beide IP-Adressen für das iSCSI-Ziel (zum Beispiel
10.165.128.216und10.165.128.217). -
Führen Sie auf sqlnode1
iscsicplaus oder verwenden Sie PowerShell: -
Klicken Sie auf die Registerkarte Discover und dann auf Discover Portal.
-
Fügen Sie jede erhaltene IP-Adresse hinzu; lassen Sie den Standardport 3260.
"10.165.128.216","10.165.128.217" | % { New-IscsiTargetPortal -TargetPortalAddress $_ }
-
Aktivieren Sie im Dialogfeld Mit Ziel verbinden die Option Mehrwegezugriff aktivieren, wenn Sie Multipathing verwenden.
-
Klicken Sie auf Erweitert und wählen Sie die Zielportal-IP aus der Dropdown-Liste aus.
-
Klicken Sie auf OK, um die Verbindung herzustellen.
-
MPIO für iSCSI-Geräte konfigurieren
-
Öffnen Sie MPIO über die Systemsteuerung oder den Server-Manager.
-
Klicken Sie auf die Registerkarte Discover Multi-Paths.
-
Aktivieren Sie Add support for iSCSI devices und klicken Sie auf Add.
-
Starten Sie neu, wenn Sie dazu aufgefordert werden.
-
Überprüfen Sie die Multipath-Konfiguration im Geräte-Manager unter Disk drives.
-
-
Volumes initialisieren und formatieren
-
Starten Sie die Computerverwaltung (
compmgmt.mscund wählen Sie Datenträgerverwaltung. -
Initialisieren, partitionieren und formatieren Sie jede Festplatte mit 64K Zuordnungseinheit:
Format-Volume -DriveLetter <DriveLetter> -FileSystem NTFS -NewFileSystemLabel <Label> -AllocationUnitSize 65536 -Confirm:$false -
Weisen Sie Laufwerksbuchstaben zu (zum Beispiel D: für Data, E: für Log, F: für Backup, G: für Temp).
-
Erstellen Sie die Verzeichnisstruktur für SQL Server:
$paths = "D:\MSSQL\DATA","E:\MSSQL\Log","F:\MSSQL\Backup","G:\MSSQL\Temp" $paths | % { New-Item -ItemType Directory -Path $_ -Force }
-
SQL Server konfigurieren
Konfigurieren Sie SQL Server auf beiden Knoten so, dass das Domänendienstkonto verwendet wird, aktualisieren Sie die Standardpfade, um NetApp Volumes zu verwenden, und verschieben Sie die Systemdatenbanken an die neuen Speicherorte.
-
Aktualisieren Sie die SQL Server- und SQL Server Agent-Dienste, damit sie unter dem Domänendienstkonto für die Cluster-Authentifizierung und Failover-Unterstützung ausgeführt werden.
-
Öffnen Sie auf jeder SQL-Instanz
services.msc. -
Aktualisieren Sie Anmelden als
domain\sqlsvcfür SQL Server- und SQL Server Agent-Dienste. -
Öffnen Sie SQL Server Management Studio (SSMS) und verbinden Sie sich mit Ihrem Domänenkonto.
Falls die Verbindung fehlschlägt, starten Sie SSMS als
<local computer>\Administrator. Stellen Sie sicher, dass das Administrator-Konto in Benutzer & Gruppen mit dem entsprechenden Passwort aktiviert ist.
-
-
Erstellen Sie die Domänenkonto-Logins mit den erforderlichen Berechtigungen.
Ersetzen Sie CVSDEMOdurch Ihren tatsächlichen Domänennamen in den folgenden SQL-Befehlen.USE [master] GO -- Create login for SQL service account CREATE LOGIN [CVSDEMO\sqlsvc] FROM WINDOWS WITH DEFAULT_DATABASE=[master], DEFAULT_LANGUAGE=[us_english] GO -- Add to sysadmin role ALTER SERVER ROLE [sysadmin] ADD MEMBER [CVSDEMO\sqlsvc] GO -- Create user in master and assign role USE [master] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO -- Repeat for model, msdb, and tempdb databases USE [model] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO USE [msdb] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO USE [tempdb] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO -
Aktualisieren Sie die Standardpfade, um die NetApp Volumes anstelle des OS-Laufwerks zu verwenden:
USE [master] GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'BackupDirectory', REG_SZ, N'F:\MSSQL\Backup' GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'DefaultData', REG_SZ, N'D:\MSSQL\DATA' GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'DefaultLog', REG_SZ, N'E:\MSSQL\Log' GO -
Verschieben Sie die Systemdatenbanken (model, msdb, tempdb und master) vom Betriebssystemlaufwerk auf die NetApp Volumes, um eine bessere Leistung und Verwaltung zu gewährleisten.
-
Aktuelle Pfade überprüfen:
-- Check current paths SELECT name, physical_name FROM sys.master_files WHERE database_id IN (DB_ID('model'), DB_ID('msdb')); -
Aktualisierung auf neue Standorte:
-- Move model database ALTER DATABASE model MODIFY FILE (NAME = modeldev, FILENAME = 'D:\MSSQL\Data\model.mdf'); ALTER DATABASE model MODIFY FILE (NAME = modellog, FILENAME = 'E:\MSSQL\Log\modellog.ldf'); -- Move msdb database ALTER DATABASE msdb MODIFY FILE (NAME = MSDBData, FILENAME = 'D:\MSSQL\Data\MSDBData.mdf'); ALTER DATABASE msdb MODIFY FILE (NAME = MSDBLog, FILENAME = 'E:\MSSQL\Log\MSDBLog.ldf'); GO -
Stoppen Sie SQL Server, verschieben Sie die Dateien manuell vom alten Speicherort in die neuen Pfade, dann starten Sie SQL Server neu.
-
Verschieben Sie die tempdb Datenbank
USE master; GO -- Check current tempdb files SELECT name, physical_name FROM sys.master_files WHERE database_id = DB_ID('tempdb'); -- Change paths for tempdb ALTER DATABASE tempdb MODIFY FILE (NAME = tempdev, FILENAME = 'G:\MSSQL\Temp\tempdb.mdf'); ALTER DATABASE tempdb MODIFY FILE (NAME = templog, FILENAME = 'G:\MSSQL\Temp\templog.ldf'); GO -
Starten Sie SQL Server neu, damit die Änderungen wirksam werden:
Restart-Service -Name "MSSQLSERVER" -Force
-
-
Verschieben Sie die Master-Datenbank
-
Öffnen Sie den SQL Server Configuration Manager.
-
Navigieren Sie zu SQL Server Services, klicken Sie mit der rechten Maustaste auf SQL Server (MSSQLSERVER) und wählen Sie Properties.
-
Klicken Sie auf die Registerkarte Startup Parameters.
-
Suchen Sie unter Vorhandene Parameter die Parameter, die mit
-d,-eund-lbeginnen. -
Entfernen Sie die alten Parameter und fügen Sie neue hinzu:
-dD:\MSSQL\Data\master.mdf -lE:\MSSQL\Log\mastlog.ldf -eE:\MSSQL\Log\ERRORLOG

-
Klicken Sie auf OK.
-
-
SQL Server-Dienst anhalten.
-
Verschieben Sie
master.mdfundmastlog.ldfmanuell vom alten Standort zu den neuen Pfaden. -
Wenn Sie den Pfad zum Fehlerprotokoll aktualisiert haben, verschieben Sie die
ERRORLOGDatei ebenfalls. -
Starten Sie den SQL Server service.
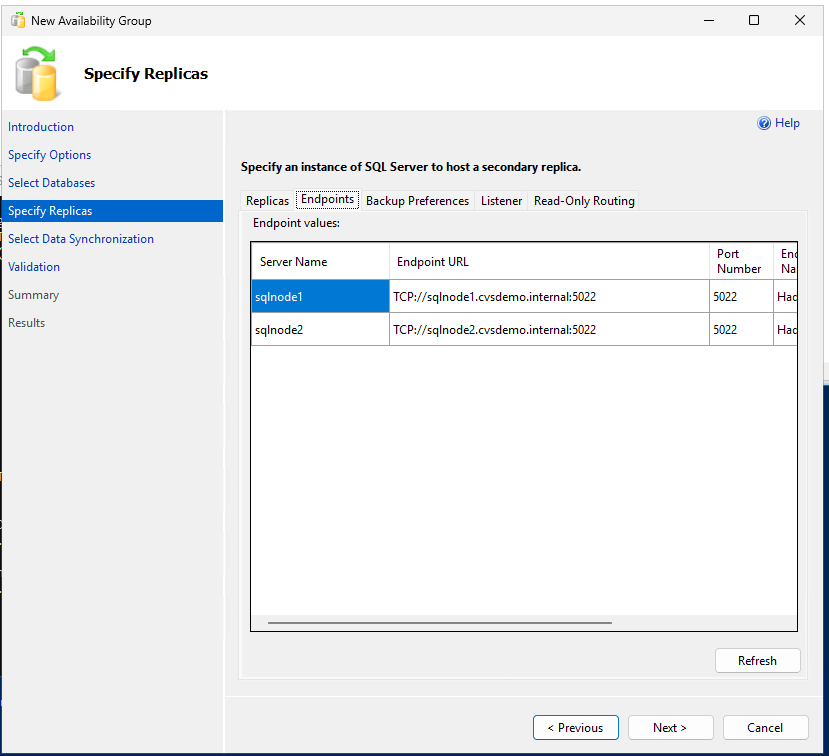
Failovercluster einrichten
Richten Sie Windows Server Failover Clustering ein, um eine hohe Verfügbarkeit für SQL Server zu gewährleisten. Weitere Informationen finden Sie unter "Windows Server Failover Clustering-Dokumentation".
Firewall-Regeln konfigurieren
Öffnen Sie die erforderlichen Netzwerkports auf beiden SQL-Knoten, um die Clusterkommunikation, die SQL Server-Konnektivität und die Verfügbarkeitsgruppenreplikation zu ermöglichen.
-
Öffnen Sie die erforderlichen Ports auf beiden SQL-Knoten für die Clusterkommunikation.
Erforderliche Ports sind: UDP 3343, TCP 3343, TCP 1433, TCP 5022, TCP 135, TCP 445, TCP 49152-65535 (dynamic RPC).
-
Führen Sie den folgenden Checkpoint auf beiden Servern aus, um SQL Server und die Clusterkommunikation durch die Firewall zuzulassen.
Passen Sie die Portnummern an, wenn Sie benutzerdefinierte Konfigurationen haben.
# Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022Detaillierte Informationen zu den Firewall-Anforderungen finden Sie unter "Anforderungen an Windows Server-Dienste und Netzwerkports".
-
Führen Sie Validierungsprüfungen auf beiden Knoten durch, bevor Sie den Cluster erstellen:
Test-Connection servername Resolve-DnsName servername Get-NetAdapterBinding -ComponentID ms_tcpip6
Erstellen Sie den Failover-Cluster
Erstellen Sie einen Windows Server Failover Cluster mit beiden SQL Server-Knoten, um Hochverfügbarkeit und automatische Failover-Funktionen zu ermöglichen.
-
Führen Sie
cluadmin.mscaus oder öffnen Sie den Failover-Cluster-Manager über den Server-Manager.
-
Wählen Sie Create Cluster.
-
Fügen Sie beide SQL-Nodes (sqlnode1, sqlnode2) hinzu.
-
Führen Sie Validierungstests durch und stellen Sie sicher, dass alle Prüfungen erfolgreich sind. Überprüfen und beheben Sie alle Warnungen, bevor Sie fortfahren.
-
Geben Sie einen Clusternamen an (zum Beispiel
sqlcluwest1). -
Schließen Sie die Clustererstellung ab.

Cluster-Quorum mit File Share Witness konfigurieren
Konfigurieren Sie einen Dateifreigabezeugen, um das Quorum in einer Zwei-Node-Cluster-Konfiguration aufrechtzuerhalten. Der Zeuge stellt eine zusätzliche Stimme bereit, um Split-Brain-Szenarien zu verhindern und die Clusterverfügbarkeit sicherzustellen.
Dateifreigabe erstellen
Erstellen Sie eine Dateifreigabe auf einer VM in einer anderen Zone oder Region, die über Netzwerkverbindung verfügt und sich innerhalb derselben Active Directory-Domäne befindet.
-
Stellen Sie eine Verbindung zur Datei-Freigabe-Zeugenserver-VM her.
-
Im Server-Manager wählen Sie Tools > Computer Management.
-
Wählen Sie Freigegebene Ordner, klicken Sie mit der rechten Maustaste auf Freigaben und wählen Sie Neue Freigabe.

-
Verwenden Sie den Assistenten zum Erstellen eines freigegebenen Ordners, um eine Freigabe zu erstellen
\\servername\share. -
Auf der Seite Ordnerpfad wählen Sie Durchsuchen aus.
-
Suchen oder erstellen Sie einen Pfad für den freigegebenen Ordner und wählen Sie dann Weiter.
-
Überprüfen Sie auf der Seite Name, Beschreibung und Einstellungen den Freigabenamen und den Pfad und wählen Sie dann Weiter.
-
Wählen Sie auf der Seite Berechtigungen für freigegebene Ordner die Option Berechtigungen anpassen und klicken Sie auf Benutzerdefiniert
-
Im Dialogfeld Berechtigungen anpassen wählen Sie Hinzufügen, um das Clusterkonto hinzuzufügen.
Stellen Sie sicher, dass das Konto, das zum Erstellen des Clusters verwendet wird (sqlcluwest1$), über vollständige Kontrolle verfügt.
-
Klicken Sie auf OK, um die Berechtigungen zu speichern.
-
Wählen Sie auf der Seite Berechtigungen für freigegebene Ordner Fertig stellen und dann erneut Fertig stellen aus.
Quorum-Einstellungen konfigurieren
Konfigurieren Sie den Cluster so, dass er den Dateifreigabezeugen für die Quorumsabstimmung verwendet.
-
Klicken Sie im Failover Cluster Manager mit der rechten Maustaste auf den Cluster und wählen Sie Weitere Aktionen > Cluster-Quorumeinstellungen konfigurieren.

-
Klicken Sie im Assistenten zum Konfigurieren des Cluster-Quorums auf Next.
-
Auf der Seite Select Quorum Configuration wählen Sie Select the quorum witness und klicken Sie auf Next.
-
Wählen Sie auf der Seite Quorumzeuge auswählen die Option Dateifreigabezeugen konfigurieren.
-
Wählen Sie auf der Seite Dateifreigabezeuge konfigurieren die Option Dateifreigabezeuge konfigurieren.
-
Geben Sie den Pfad zu der von Ihnen erstellten Freigabe ein (zum Beispiel
\\servername\share) und klicken Sie auf Weiter. -
Überprüfen Sie die Einstellungen auf der Bestätigungsseite und klicken Sie auf Next.
-
Klicken Sie auf Finish.
Die Cluster-Kernressourcen sind jetzt mit einem Dateifreigabezeugen konfiguriert.
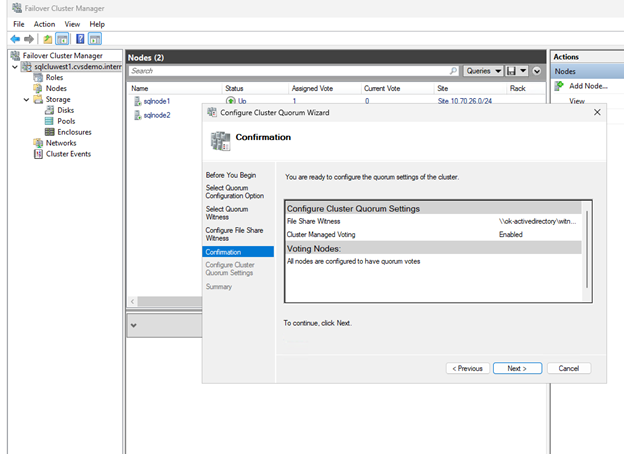
Always On-Verfügbarkeitsgruppen aktivieren
Aktivieren Sie Always On availability groups auf beiden SQL Server-VMs:
-
Öffnen Sie über das Startmenü den SQL Server Configuration Manager.
-
Wählen Sie im Browserbaum SQL Server Services aus.
-
Klicken Sie mit der rechten Maustaste auf SQL Server (MSSQLSERVER) und wählen Sie Properties.
-
Wählen Sie die Registerkarte Always On High Availability aus.
-
Aktivieren Sie Enable Always On availability groups.
-
Klicken Sie auf Anwenden und starten Sie dann den SQL Server-Dienst neu, wenn Sie dazu aufgefordert werden.
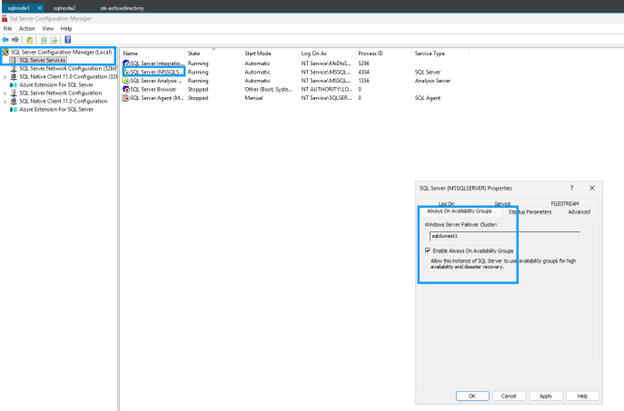
-
Wiederholen Sie den Vorgang für die zweite SQL Server instance.
Erstellen Sie eine Datenbank auf der ersten SQL Server-Instanz
Erstellen Sie eine Datenbank auf der ersten SQL Server Instanz.
-
Stellen Sie eine Verbindung zur ersten SQL Server VM mit einem Domänenkonto her, das Mitglied der festen Server-Rolle ist.
-
Öffnen Sie SQL Server Management Studio und stellen Sie eine Verbindung zur ersten SQL Server instance her.
-
Klicken Sie im Object Explorer mit der rechten Maustaste auf Databases und wählen Sie New Database.
-
Geben Sie einen Datenbanknamen (zum Beispiel
MyDB1) ein und klicken Sie auf OK. -
Stellen Sie den Datenbank-Recovery-Modus auf Voll ein:
ALTER DATABASE MyDB1 SET RECOVERY FULL; GO
Verfügbarkeitsgruppe erstellen und konfigurieren
Erstellen Sie eine Always On-Verfügbarkeitsgruppe mit synchronem Commit und automatischem Failover, um eine hohe Verfügbarkeit Ihrer SQL Server-Datenbanken zu gewährleisten.
-
Erstellen Sie sowohl ein vollständiges Backup als auch ein Transaktionsprotokoll-Backup der Datenbank.
-- Full backup BACKUP DATABASE MyDB1 TO DISK = 'F:\MSSQL\Backup\MyDB1_Full.bak' WITH INIT, COMPRESSION; -- Transaction log backup BACKUP LOG MyDB1 TO DISK = 'F:\MSSQL\Backup\MyDB1_Log.trn' WITH INIT, COMPRESSION; -
Kopieren Sie die Sicherungsdateien auf die zweite SQL Server-Instanz und stellen Sie sie mit NORECOVERY wieder her.
-- Restore full backup RESTORE DATABASE MyDB1 FROM DISK = 'F:\MSSQL\Backup\MyDB1_Full.bak' WITH NORECOVERY; -- Restore log backup RESTORE LOG MyDB1 FROM DISK = 'F:\MSSQL\Backup\MyDB1_Log.trn' WITH NORECOVERY; -
Erstellen Sie die Verfügbarkeitsgruppe mit synchronem Commit, automatischem Failover und lesbaren sekundären Replikaten:
-- Run on primary replica CREATE AVAILABILITY GROUP sqlagwest1 WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY) FOR DATABASE MyDB1 REPLICA ON N'SQLNODE1' WITH ( ENDPOINT_URL = N'TCP://sqlnode1.cvsdemo.internal:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = YES) ), N'SQLNODE2' WITH ( ENDPOINT_URL = N'TCP://sqlnode2.cvsdemo.internal:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = YES) ); GO -
Erstellen Sie die Verfügbarkeitsgruppe mithilfe des Availability Group Wizard.
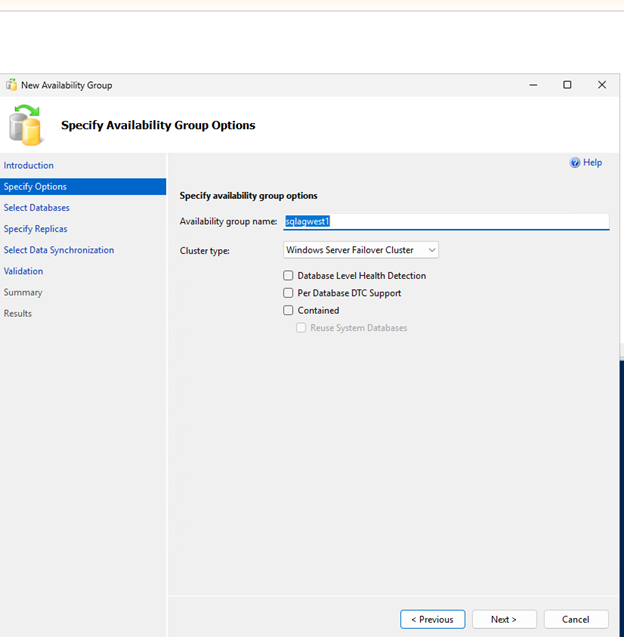


Stellen Sie sicher, dass Firewall-Port 5022 auf beiden SQL-Knoten freigegeben ist. 
DNN-Listenerressource erstellen
Erstellen Sie einen Distributed Network Name (DNN)-Listener, um den Datenverkehr ohne Load Balancer an die entsprechende Clusterressource weiterzuleiten.
Verwenden Sie PowerShell, um die DNN-Ressource zu erstellen:
$Ag = "sqlagwest1"
$Dns = "AOAGDNN"
$Port = "1433"
# Add DNN resource
Add-ClusterResource -Name $Dns -ResourceType "Distributed Network Name" -Group $Ag
# Set DNN properties
Get-ClusterResource -Name $Dns | Set-ClusterParameter -Name DnsName -Value $Dns
Get-ClusterResource -Name $Dns | Set-ClusterParameter -Name Port -Value $Port
# Start DNN resource
Start-ClusterResource -Name $Dns
# Add dependency
$AagResource = Get-ClusterResource | Where-Object {$_.ResourceType -eq "SQL Server Availability Group" -and $_.OwnerGroup -eq $Ag}
Set-ClusterResourceDependency -Resource $AagResource -Dependency "[$Dns]"Mögliche Besitzer konfigurieren
Standardmäßig bindet der Cluster den DNN-DNS-Namen an alle Knoten. Schließen Sie Knoten aus, die nicht an der Verfügbarkeitsgruppe teilnehmen:
-
Suchen Sie im Failover Cluster Manager die DNN-Ressource.
-
Klicken Sie mit der rechten Maustaste auf die DNN resource und wählen Sie Properties.

-
Deaktivieren Sie das Kontrollkästchen für alle Knoten, die nicht an der Verfügbarkeitsgruppe teilnehmen.

-
Klicken Sie auf OK, um die Einstellungen zu speichern.
Anwendungsverbindungszeichenfolgen aktualisieren
Aktualisieren Sie die Verbindungszeichenfolgen, um den DNN-Listenernamen zu verwenden und den MultiSubnetFailover=True Parameter einzuschließen:
Server=AOAGDNN,1433;Database=MyDB1;MultiSubnetFailover=True;
|
|
Wenn Ihr Client den MultiSubnetFailover Parameter nicht unterstützt, ist er nicht mit DNN kompatibel. |
Failover testen
Überprüfen Sie die Konfiguration der Verfügbarkeitsgruppe und testen Sie das Failover, um sicherzustellen, dass das automatische Failover korrekt zwischen den Nodes funktioniert.
-
Führen Sie den folgenden Befehl auf einer beliebigen Replik aus, um die Konfiguration der Availability Group zu überprüfen.
Beide Replikate sollten
SYNCHRONOUS_COMMITfür den Verfügbarkeitsmodus undAUTOMATICfür den Failover-Modus anzeigen, was einen Datenverlust bei automatischem Failover ausschließt.SELECT ag.name AS AG_Name, ars.primary_replica FROM sys.dm_hadr_availability_group_states AS ars JOIN sys.availability_groups AS ag ON ag.group_id = ars.group_id; -- Check replica configuration SELECT replica_server_name, availability_mode_desc, failover_mode_desc FROM sys.availability_replicas WHERE group_id = (SELECT group_id FROM sys.availability_groups WHERE name = N'sqlagwest1');
-
Führen Sie den folgenden Befehl auf dem sekundären Knoten aus, um den Failover zu initiieren:
ALTER AVAILABILITY GROUP sqlagwest1 FAILOVER; GO -
Prüfen Sie, ob das Verbindungsziel auf das neue primäre Ziel umgeschaltet wurde:
-- SELECT @@SERVERNAME AS NowPrimary;Erweitern Sie in SSMS den Knoten der Verfügbarkeitsgruppe, klicken Sie mit der rechten Maustaste auf Always On High Availability und wählen Sie Show Dashboard.
Das Dashboard sollte beide Knoten mit gesundem Status anzeigen und das Failover bestätigen.

Ressourcen bereinigen
Nach Abschluss des Tutorials löschen Sie die erstellten Ressourcen, um zusätzliche Kosten zu vermeiden:
-
Compute Engine-Instanzen (sqlnode1, sqlnode2) löschen
-
Google Cloud NetApp Volumes löschen (Volumes, Storage-Pools, Host-Gruppen)
-
Löschen Sie VPC- und Netzwerkressourcen, wenn sie speziell für dieses Tutorial erstellt wurden
-
Löschen Sie den Dateifreigabe-Zeugenserver, falls zutreffend
Siehe "Google Cloud NetApp Volumes-Dokumentation" und "Google Compute Engine-Dokumentation" für detaillierte Schritte zum Löschen von Ressourcen.
Wo Sie weitere Informationen finden
Weitere Informationen zu SQL Server auf Google Cloud mit NetApp storage finden Sie in der folgenden Dokumentation: