

TR-5000: Sicherung, Wiederherstellung und Klonen von PostgreSQL-Datenbanken auf ONTAP mit SnapCenter
 Änderungen vorschlagen
Änderungen vorschlagen
Allen Cao, Niyaz Mohamed, NetApp
Die Lösung bietet eine Übersicht und Details zum Sichern, Wiederherstellen und Klonen von PostgreSQL-Datenbanken auf ONTAP -Speicher in der öffentlichen Cloud oder vor Ort über das NetApp SnapCenter -UI-Tool zur Datenbankverwaltung.
Zweck
Die NetApp SnapCenter software ist eine benutzerfreundliche Unternehmensplattform zur sicheren Koordination und Verwaltung des Datenschutzes über Anwendungen, Datenbanken und Dateisysteme hinweg. Es vereinfacht die Lebenszyklusverwaltung für Sicherung, Wiederherstellung und Klonen, indem diese Aufgaben an die Anwendungseigentümer ausgelagert werden, ohne dass die Möglichkeit zur Überwachung und Regulierung der Aktivitäten auf den Speichersystemen verloren geht. Durch die Nutzung speicherbasierter Datenverwaltung werden eine höhere Leistung und Verfügbarkeit sowie kürzere Test- und Entwicklungszeiten ermöglicht.
In dieser Dokumentation demonstrieren wir den Schutz und die Verwaltung von PostgreSQL-Datenbanken auf NetApp ONTAP -Speicher in der öffentlichen Cloud oder vor Ort mit einem sehr benutzerfreundlichen SnapCenter -UI-Tool.
Diese Lösung ist für die folgenden Anwendungsfälle geeignet:
-
Sicherung und Wiederherstellung der auf NetApp ONTAP -Speicher in der öffentlichen Cloud oder vor Ort bereitgestellten PostgreSQL-Datenbank.
-
Verwalten Sie Snapshots und Klonkopien von PostgreSQL-Datenbanken, um die Anwendungsentwicklung zu beschleunigen und das Datenlebenszyklusmanagement zu verbessern.
Publikum
Diese Lösung ist für folgende Personen gedacht:
-
Ein DBA, der PostgreSQL-Datenbanken auf NetApp ONTAP -Speicher bereitstellen möchte.
-
Ein Datenbanklösungsarchitekt, der PostgreSQL-Workloads auf NetApp ONTAP -Speicher testen möchte.
-
Ein Speicheradministrator, der PostgreSQL-Datenbanken auf NetApp ONTAP -Speicher bereitstellen und verwalten möchte.
-
Ein Anwendungsbesitzer, der eine PostgreSQL-Datenbank auf NetApp ONTAP Speicher einrichten möchte.
Test- und Validierungsumgebung für Lösungen
Die Tests und Validierungen dieser Lösung wurden in einer Laborumgebung durchgeführt, die möglicherweise nicht der endgültigen Bereitstellungsumgebung entspricht. Siehe den AbschnittWichtige Faktoren für die Bereitstellungsüberlegungen für weitere Informationen.
Architektur
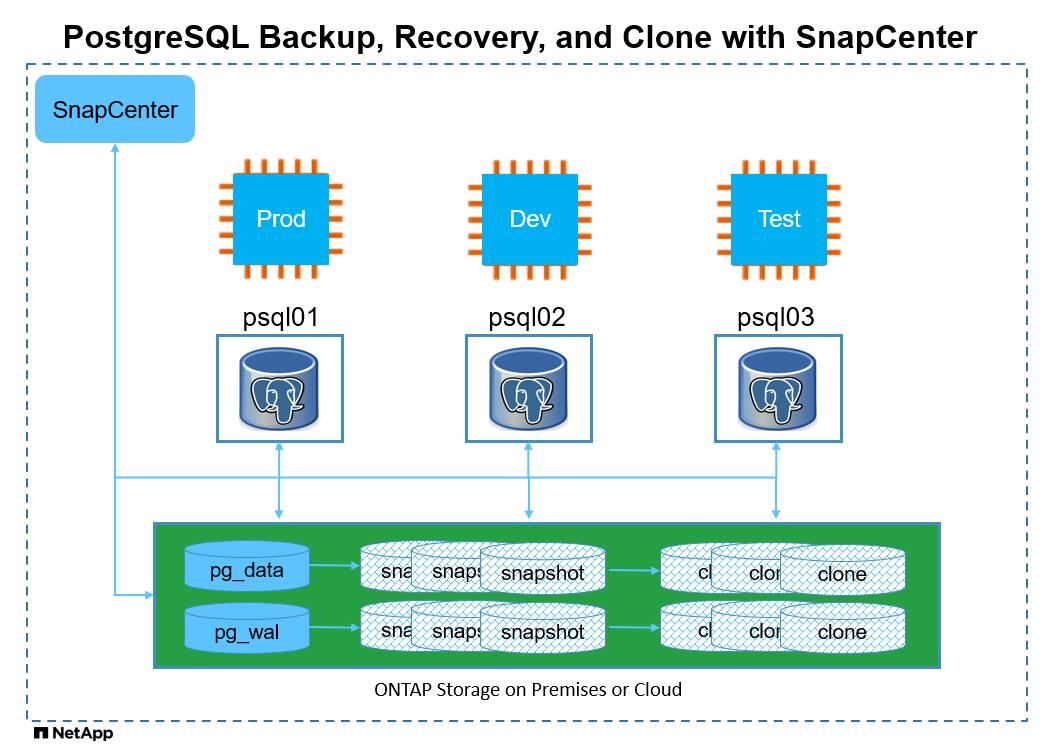
Hardware- und Softwarekomponenten
Hardware |
||
NetApp AFF A220 |
Version 9.12.1P2 |
Festplattenregal DS224-12, IOM12E-Modul, 24 Festplatten / 12 TiB Kapazität |
VMware vSphere-Cluster |
Version 6.7 |
4 NetApp HCI H410C-Rechen-ESXi-Knoten |
Software |
||
RedHat Linux |
RHEL Linux 8.6 (LVM) – x64 Gen2 |
RedHat-Abonnement zum Testen bereitgestellt |
Windows Server |
2022 DataCenter; AE Hotpatch – x64 Gen2 |
Hosten des SnapCenter -Servers |
PostgreSQL-Datenbank |
Version 14.13 |
Befüllter PostgreSQL-DB-Cluster mit HammerDB-tpcc-Schema |
SnapCenter Server |
Version 6.0 |
Arbeitsgruppenbereitstellung |
Öffnen Sie JDK |
Version java-11-openjdk |
SnapCenter -Plugin-Anforderung für DB-VMs |
NFS |
Version 3.0 |
Trennen Sie Daten und Protokolle an verschiedenen Einhängepunkten |
Ansible |
Kern 2.16.2 |
Python 3.6.8 |
PostgreSQL-Datenbankkonfiguration in der Laborumgebung
Server |
Datenbank |
DB-Speicher |
psql01 |
Primärer Datenbankserver |
/pgdata, /pglogs NFS-Volume-Mounts auf ONTAP -Speicher |
psql02 |
Datenbankserver klonen |
/pgdata_clone, /pglogs_clone NFS-Thin-Clone-Volume-Mounts auf ONTAP Speicher |
Wichtige Faktoren für die Bereitstellungsüberlegungen
-
* SnapCenter -Bereitstellung.* SnapCenter kann in einer Windows-Domäne oder Arbeitsgruppenumgebung bereitgestellt werden. Bei einer domänenbasierten Bereitstellung muss das Domänenbenutzerkonto ein Domänenadministratorkonto sein oder der Domänenbenutzer muss zur lokalen Administratorgruppe auf dem SnapCenter -Hostingserver gehören.
-
Namensauflösung. Der SnapCenter -Server muss den Namen für jeden verwalteten Zieldatenbankserver-Host in die IP-Adresse auflösen. Jeder Zieldatenbankserver-Host muss den SnapCenter -Servernamen in die IP-Adresse auflösen. Wenn kein DNS-Server verfügbar ist, fügen Sie zur Auflösung den lokalen Hostdateien Namen hinzu.
-
Ressourcengruppenkonfiguration. Eine Ressourcengruppe in SnapCenter ist eine logische Gruppierung ähnlicher Ressourcen, die gemeinsam gesichert werden können. Dadurch werden die Sicherungsaufträge in einer großen Datenbankumgebung vereinfacht und die Anzahl reduziert.
-
Separate vollständige Datenbank- und Archivprotokollsicherung. Die vollständige Datenbanksicherung umfasst konsistente Gruppen-Snapshots von Datenvolumes und Protokollvolumes. Ein häufiger vollständiger Datenbank-Snapshot führt zu einem höheren Speicherverbrauch, verbessert jedoch die RTO. Eine Alternative besteht darin, weniger häufig vollständige Datenbank-Snapshots und häufigere Sicherungen der Archivprotokolle durchzuführen. Dies verbraucht weniger Speicherplatz und verbessert das RPO, kann aber das RTO verlängern. Berücksichtigen Sie beim Einrichten des Sicherungsschemas Ihre RTO- und RPO-Ziele. Es gibt auch eine Begrenzung (1023) für die Anzahl der Snapshot-Backups auf einem Volume.
-
* Delegation von Privileges .* Nutzen Sie die in die SnapCenter -Benutzeroberfläche integrierte rollenbasierte Zugriffskontrolle, um bei Bedarf Berechtigungen an Anwendungs- und Datenbankteams zu delegieren.
Lösungsbereitstellung
Die folgenden Abschnitte enthalten schrittweise Anleitungen für die Bereitstellung, Konfiguration und Sicherung, Wiederherstellung und das Klonen von SnapCenter -Datenbanken auf NetApp ONTAP -Speicher in der öffentlichen Cloud oder vor Ort.
Voraussetzungen für die Bereitstellung
Details
-
Für die Bereitstellung sind zwei vorhandene PostgreSQL-Datenbanken erforderlich, die auf ONTAP Speicher ausgeführt werden, eine als primärer DB-Server und die andere als Klon-DB-Server. Als Referenz zur Bereitstellung einer PostgreSQL-Datenbank auf ONTAP siehe TR-4956:"Automatisierte Bereitstellung von PostgreSQL mit hoher Verfügbarkeit und Notfallwiederherstellung in AWS FSx/EC2" , auf der Suche nach dem Playbook zur automatisierten Bereitstellung von PostgreSQL auf der primären Instanz.
-
Stellen Sie einen Windows-Server bereit, um das NetApp SnapCenter UI-Tool mit der neuesten Version auszuführen. Weitere Einzelheiten finden Sie unter folgendem Link:"Installieren des SnapCenter -Servers" .
Installation und Einrichtung von SnapCenter
Details
Wir empfehlen, online zu gehen"SnapCenter -Softwaredokumentation" bevor Sie mit der Installation und Konfiguration von SnapCenter fortfahren: . Im Folgenden finden Sie eine allgemeine Zusammenfassung der Schritte zur Installation und Einrichtung der SnapCenter software für PostgreSQL auf ONTAP.
-
Laden Sie vom SnapCenter Windows-Server das neueste Java JDK herunter und installieren Sie es von"Holen Sie sich Java für Desktopanwendungen" . Schalten Sie die Windows-Firewall aus.
-
Laden Sie vom SnapCenter Windows-Server die Windows-Voraussetzungen für SnapCenter 6.0 herunter und installieren oder aktualisieren Sie sie: PowerShell – PowerShell-7.4.3-win-x64.msi und .Net-Hosting-Paket – dotnet-hosting-8.0.6-win.
-
Laden Sie vom SnapCenter Windows-Server die neueste Version (derzeit 6.0) der ausführbaren SnapCenter -Installationsdatei von der NetApp Supportsite herunter und installieren Sie sie:"NetApp | Unterstützung" .
-
Aktivieren Sie von Datenbank-DB-VMs aus die kennwortlose SSH-Authentifizierung für den Administratorbenutzer
adminund seine Sudo-Berechtigungen ohne Passwort. -
Stoppen und deaktivieren Sie den Linux-Firewall-Dämon von den Datenbank-DB-VMs aus. Installieren Sie java-11-openjdk.
-
Starten Sie vom SnapCenter Windows-Server aus den Browser, um sich mit den Anmeldeinformationen des lokalen Windows-Administratorbenutzers oder Domänenbenutzers über Port 8146 bei SnapCenter anzumelden.
-
Rezension
Get StartedOnline-Menü.
-
In
Settings-Global Settings, überprüfenHypervisor Settingsund klicken Sie auf Aktualisieren.
-
Passen Sie bei Bedarf
Session Timeoutfür die SnapCenter -Benutzeroberfläche auf das gewünschte Intervall.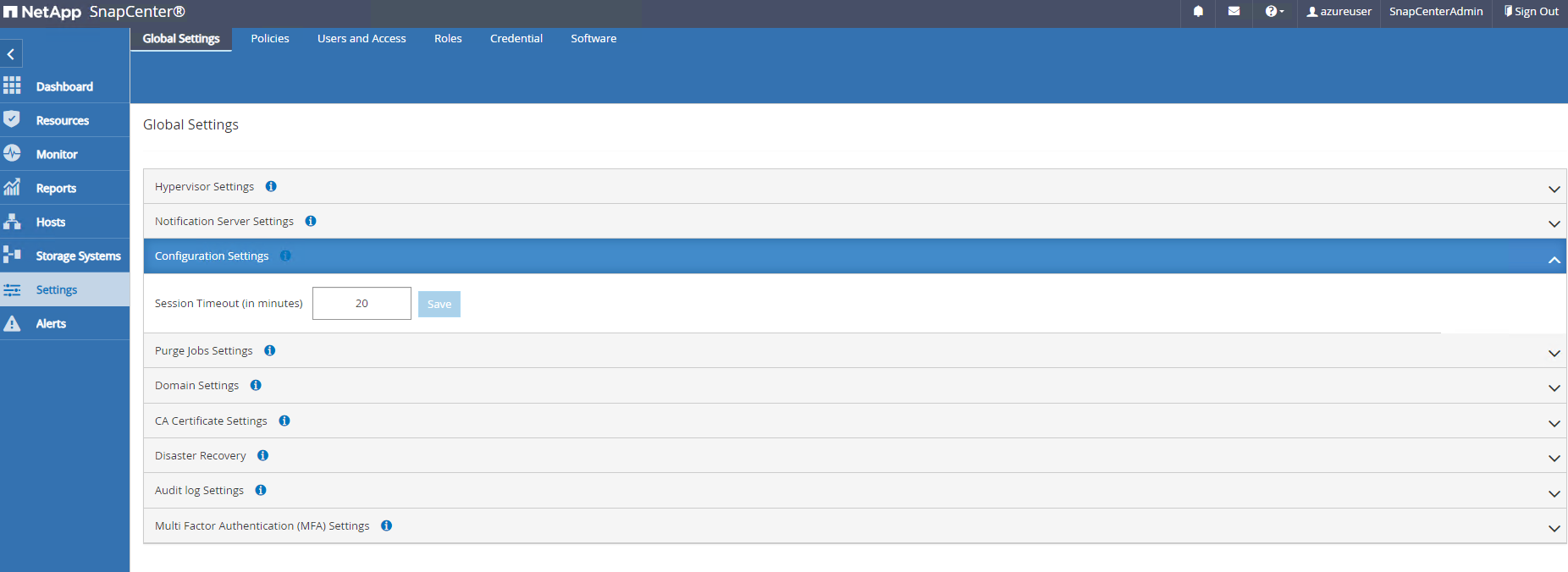
-
Fügen Sie bei Bedarf weitere Benutzer zu SnapCenter hinzu.
-
Der
RolesAuf der Registerkarte „Liste“ werden die integrierten Rollen aufgelistet, die verschiedenen SnapCenter Benutzern zugewiesen werden können. Benutzerdefinierte Rollen können auch von Administratorbenutzern mit den gewünschten Berechtigungen erstellt werden.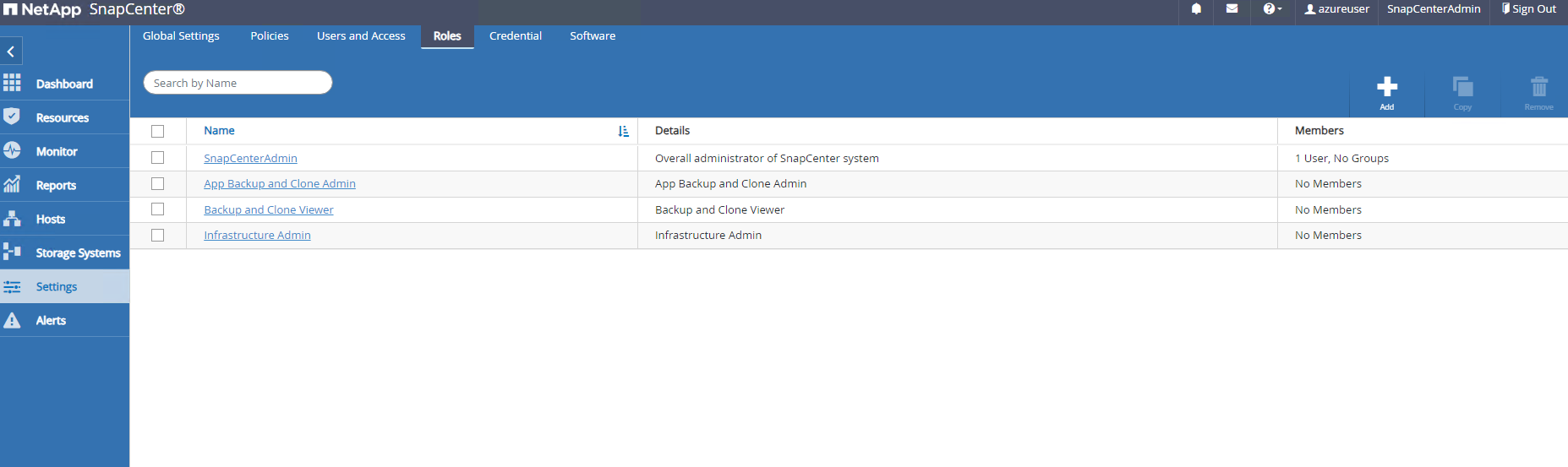
-
Aus
Settings-Credential, erstellen Sie Anmeldeinformationen für SnapCenter -Verwaltungsziele. In diesem Demo-Anwendungsfall handelt es sich um den Linux-Benutzer „Admin“ für die Anmeldung bei der DB-Server-VM und um Postgres-Anmeldeinformationen für den PostgreSQL-Zugriff.

Setzen Sie das PostgreSQL-Benutzerkennwort „postgres“ zurück, bevor Sie die Anmeldeinformationen erstellen. -
Aus
Storage SystemsRegisterkarte, HinzufügenONTAP clustermit ONTAP Cluster-Administratoranmeldeinformationen. Für Azure NetApp Files müssen Sie spezielle Anmeldeinformationen für den Zugriff auf den Kapazitätspool erstellen.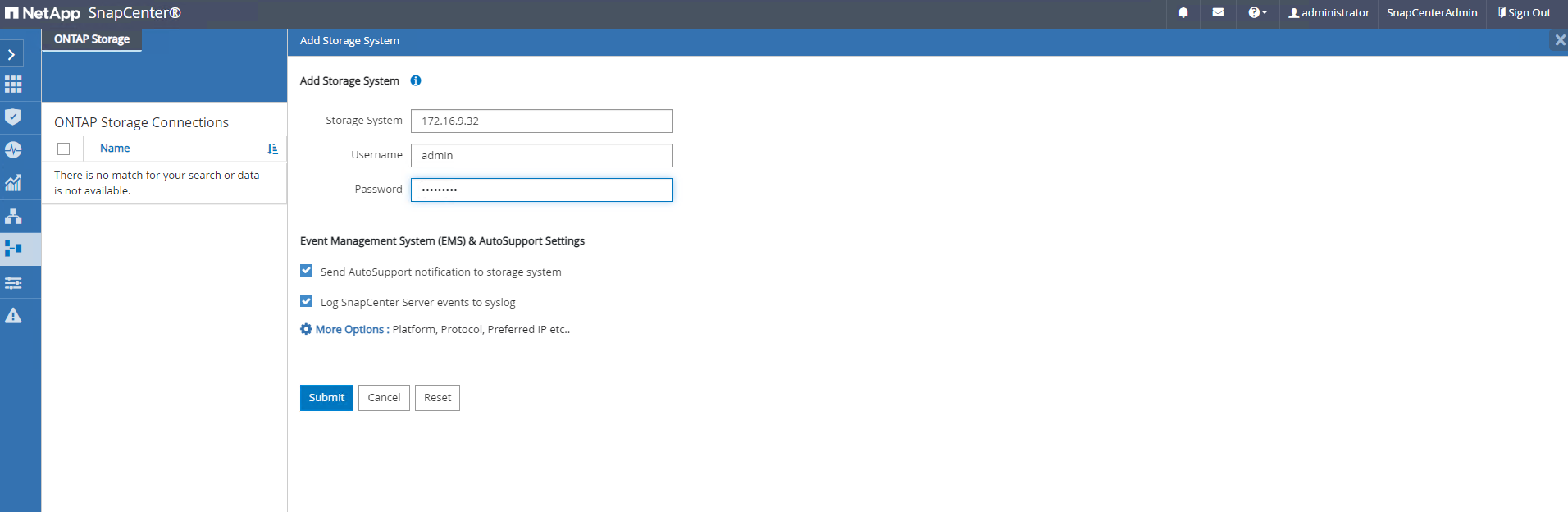
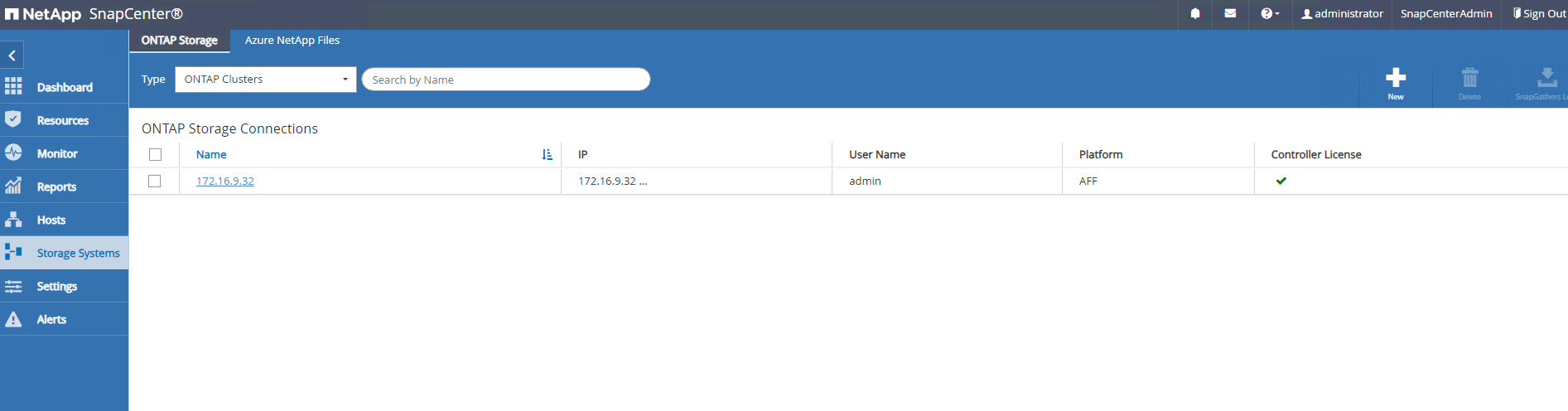
-
Aus
HostsFügen Sie auf der Registerkarte „PostgreSQL DB VMs“ hinzu, wodurch das SnapCenter Plugin für PostgreSQL unter Linux installiert wird.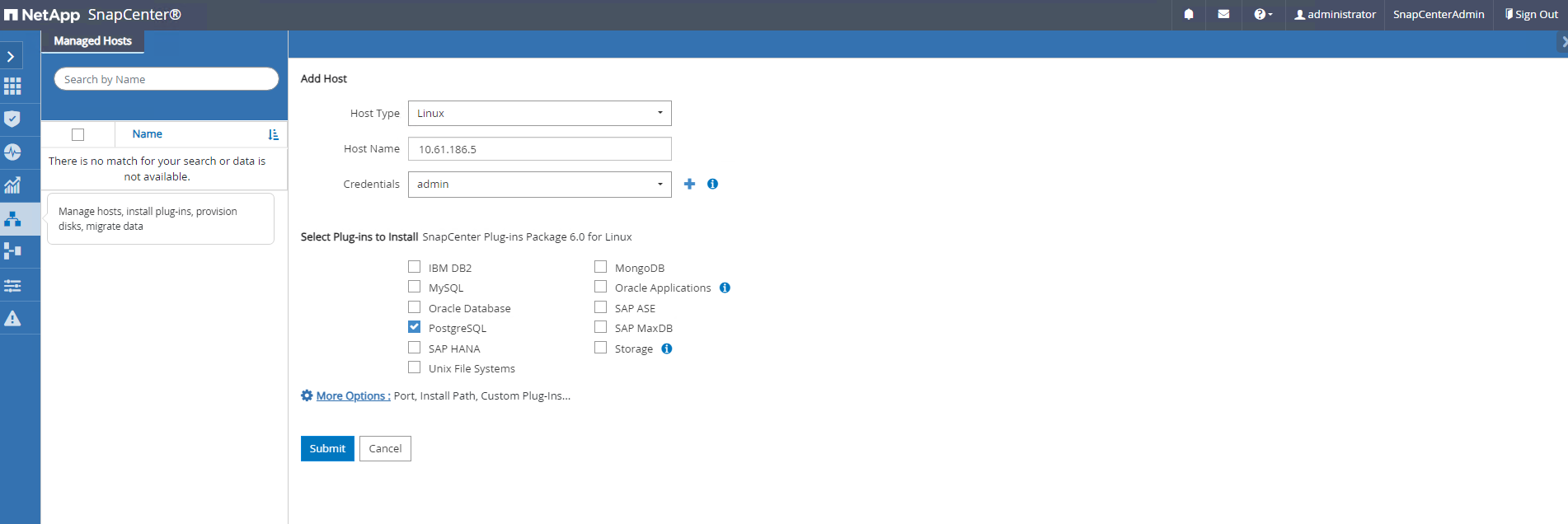
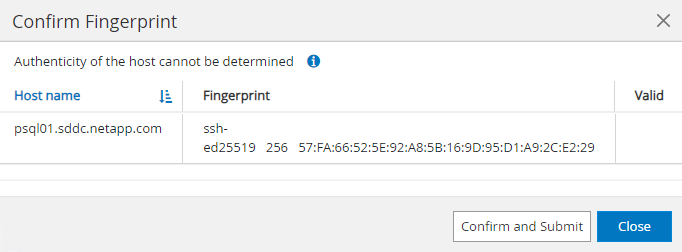
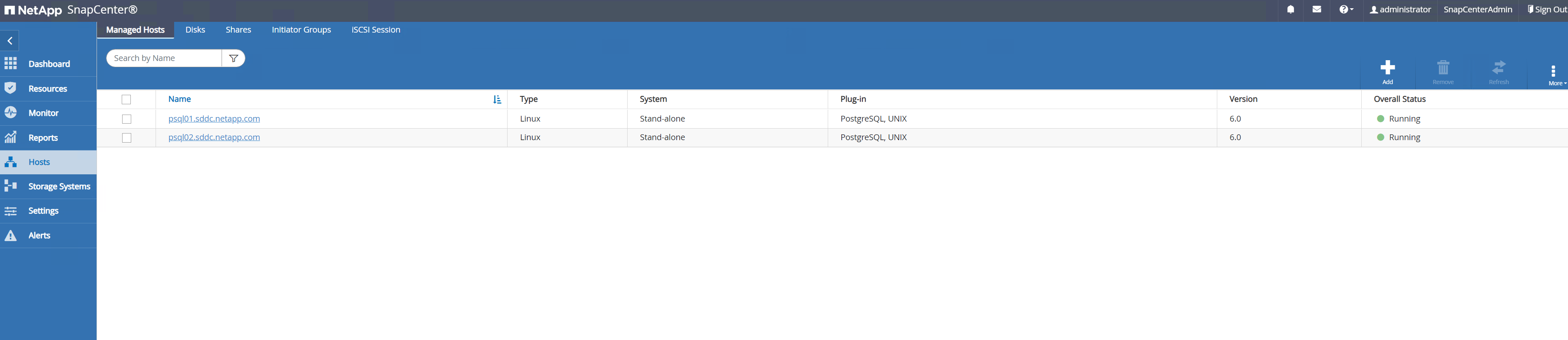
-
Sobald das Host-Plugin auf der DB-Server-VM installiert ist, werden Datenbanken auf dem Host automatisch erkannt und sind sichtbar in
ResourcesTab.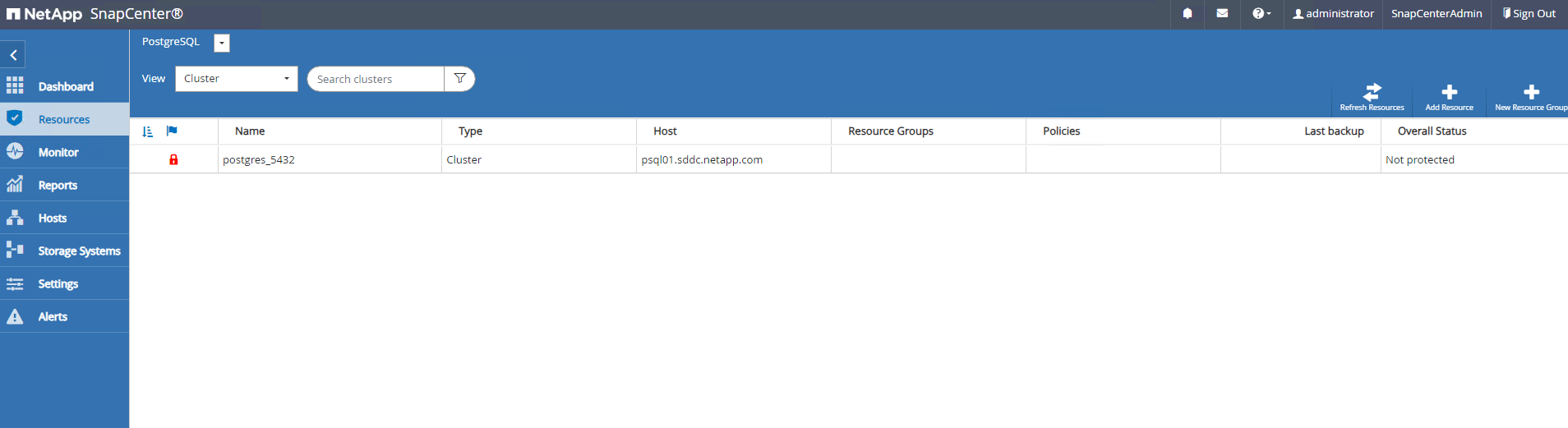
Datenbanksicherung
Details
Der anfänglich automatisch erkannte PostgreSQL-Cluster zeigt neben seinem Clusternamen ein rotes Schloss an. Es muss mit den Anmeldeinformationen der PostgreSQL-Datenbank entsperrt werden, die während der SnapCenter -Einrichtung im vorherigen Abschnitt erstellt wurden. Anschließend müssen Sie eine Sicherungsrichtlinie erstellen und anwenden, um die Datenbank zu schützen. Führen Sie abschließend die Sicherung entweder manuell oder mithilfe eines Planers aus, um eine SnapShot-Sicherung zu erstellen. Der folgende Abschnitt zeigt die schrittweise Vorgehensweise.
-
Entsperren Sie den PostgreSQL-Cluster.
-
Navigieren zu
ResourcesRegisterkarte, die den PostgreSQL-Cluster auflistet, der nach der Installation des SnapCenter -Plugins auf der Datenbank-VM erkannt wurde. Zunächst ist es gesperrt und dieOverall Statusdes Datenbankclusters wird angezeigt alsNot protected. -
Klicken Sie auf den Clusternamen und dann
Configure Credentialsum die Seite zur Anmeldeinformationskonfiguration zu öffnen.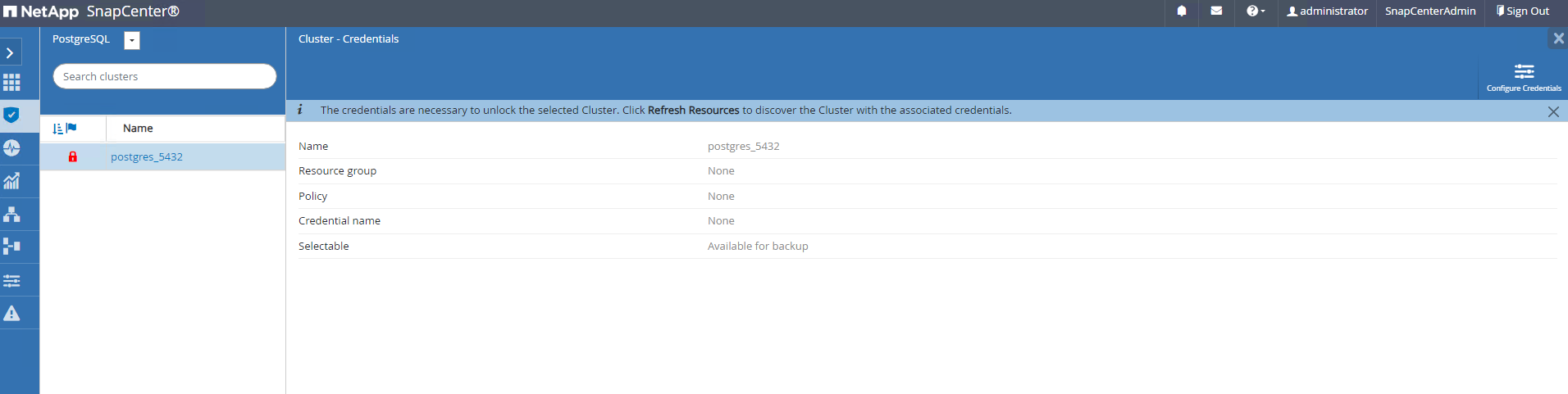
-
Wählen
postgresAnmeldeinformationen, die während der vorherigen SnapCenter -Einrichtung erstellt wurden.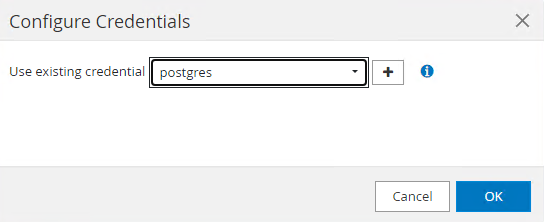
-
Sobald die Anmeldeinformationen angewendet wurden, wird der Cluster entsperrt.

-
-
Erstellen Sie eine PostgreSQL-Sicherungsrichtlinie.
-
Navigieren Sie zu
Setting-Policesund klicken Sie aufNewum eine Sicherungsrichtlinie zu erstellen.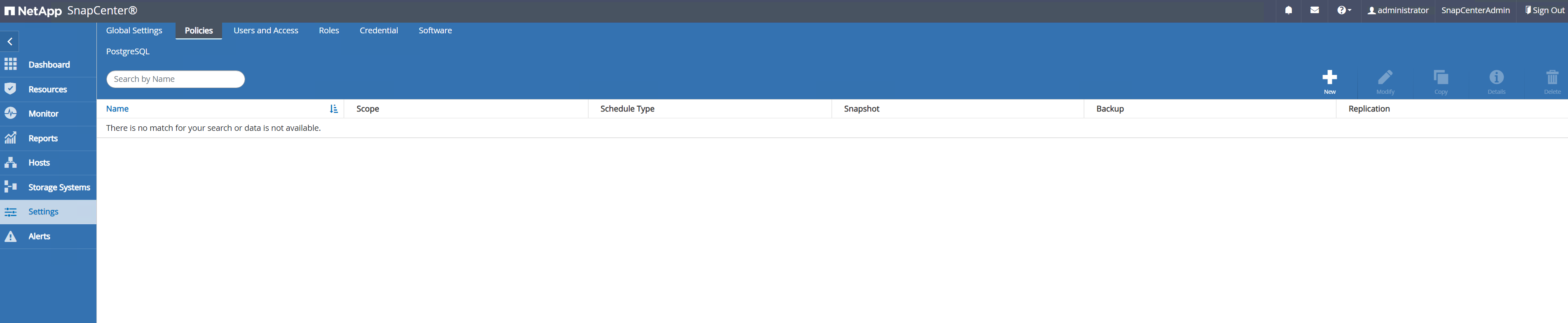
-
Benennen Sie die Sicherungsrichtlinie.
-
Wählen Sie den Speichertyp. Die Standard-Sicherungseinstellungen sollten für die meisten Szenarien ausreichend sein.
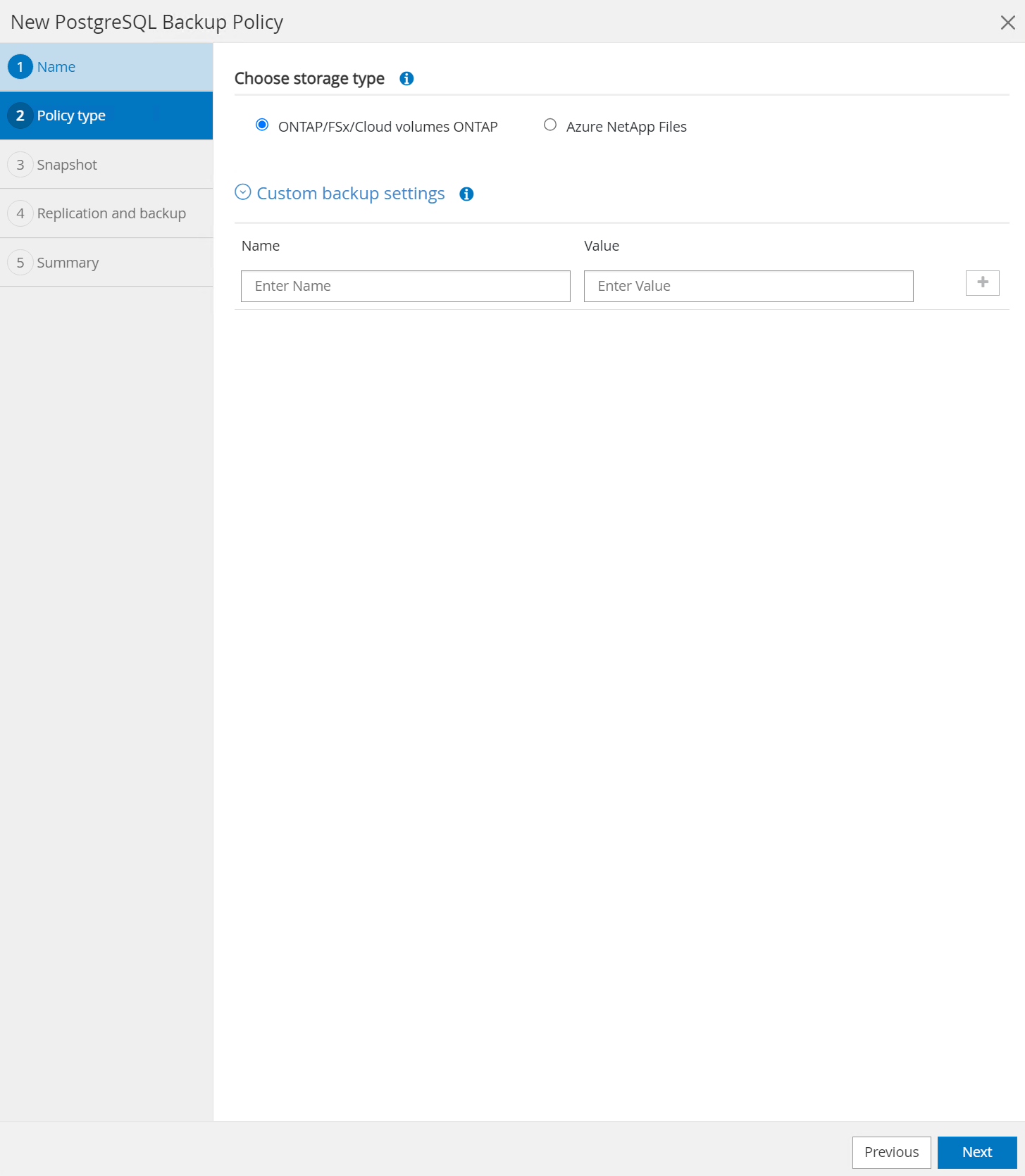
-
Definieren Sie die Sicherungshäufigkeit und die SnapShot-Aufbewahrung.
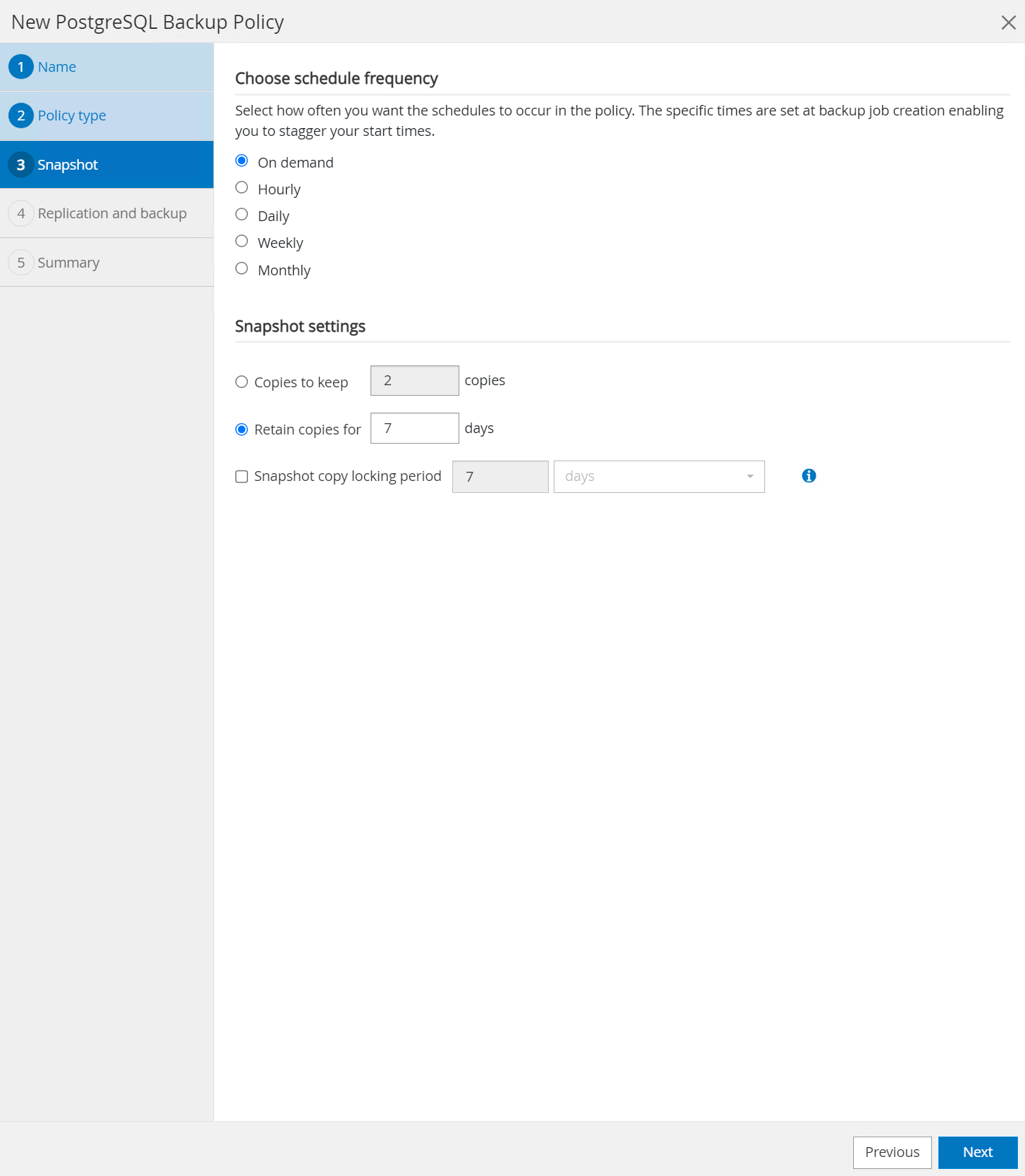
-
Option zur Auswahl der sekundären Replikation, wenn Datenbankvolumes an einen sekundären Standort repliziert werden.
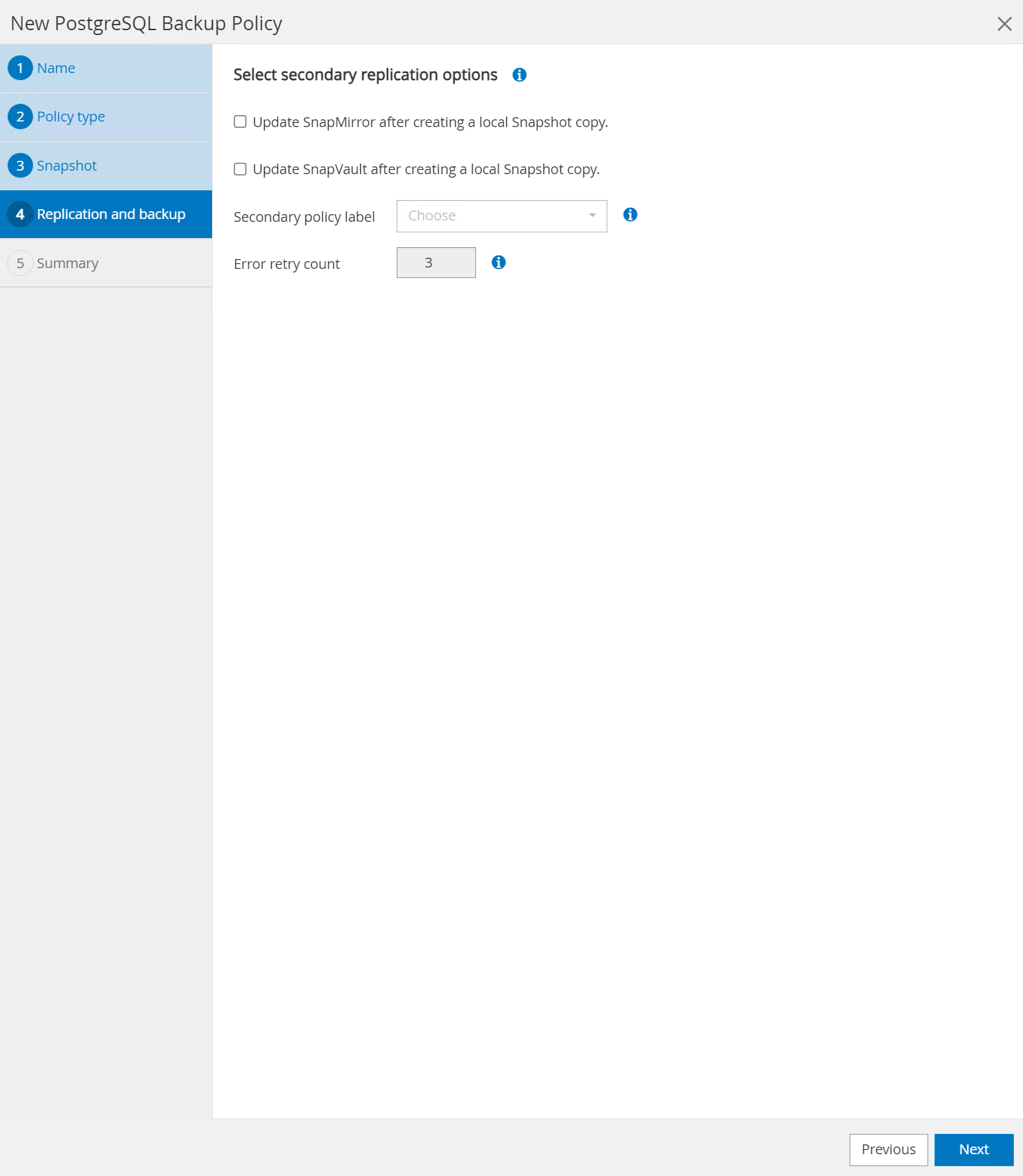
-
Überprüfen Sie die Zusammenfassung und
Finishum die Sicherungsrichtlinie zu erstellen.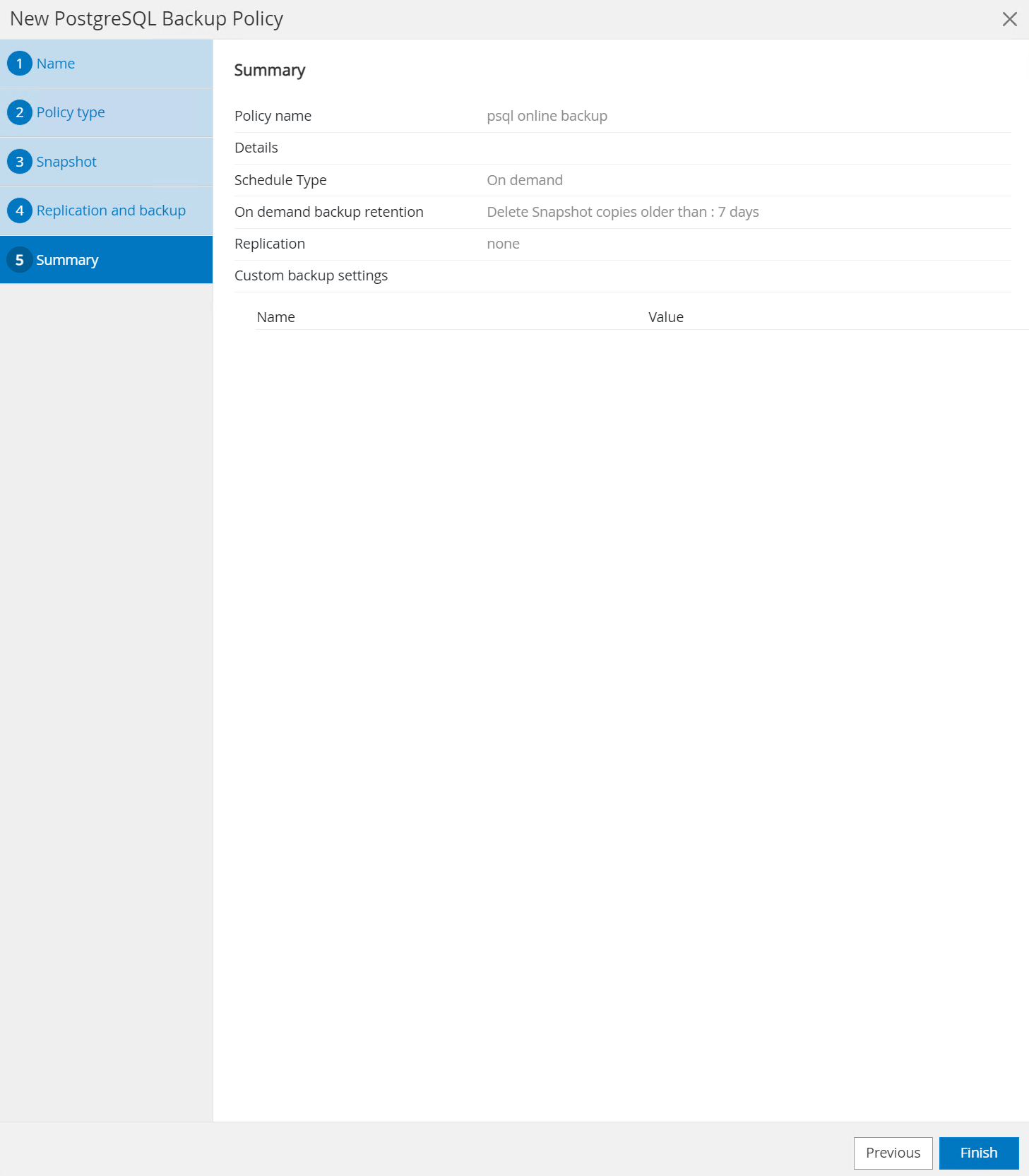
-
-
Wenden Sie eine Sicherungsrichtlinie an, um die PostgreSQL-Datenbank zu schützen.
-
Navigieren Sie zurück zu
ResourceKlicken Sie auf der Registerkarte auf den Clusternamen, um den PostgreSQL-Clusterschutz-Workflow zu starten.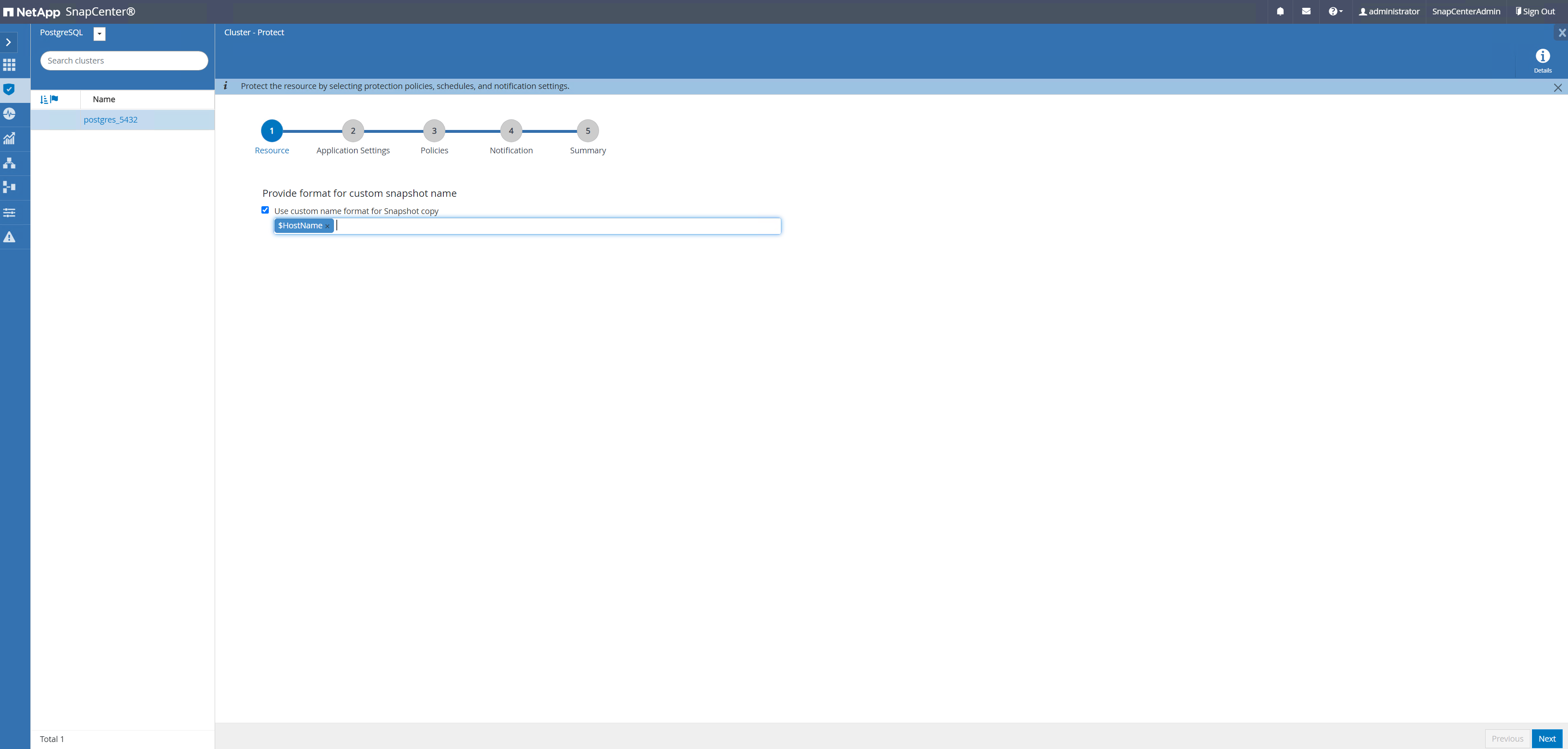
-
Standard akzeptieren
Application Settings. Viele der Optionen auf dieser Seite gelten nicht für automatisch erkannte Ziele.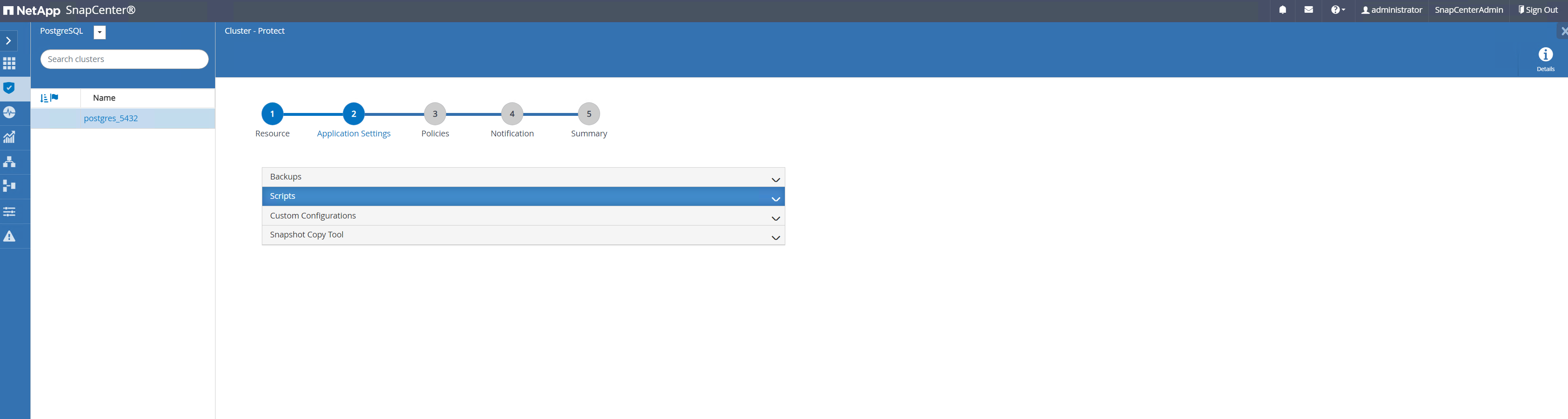
-
Wenden Sie die gerade erstellte Sicherungsrichtlinie an. Fügen Sie bei Bedarf einen Sicherungszeitplan hinzu.
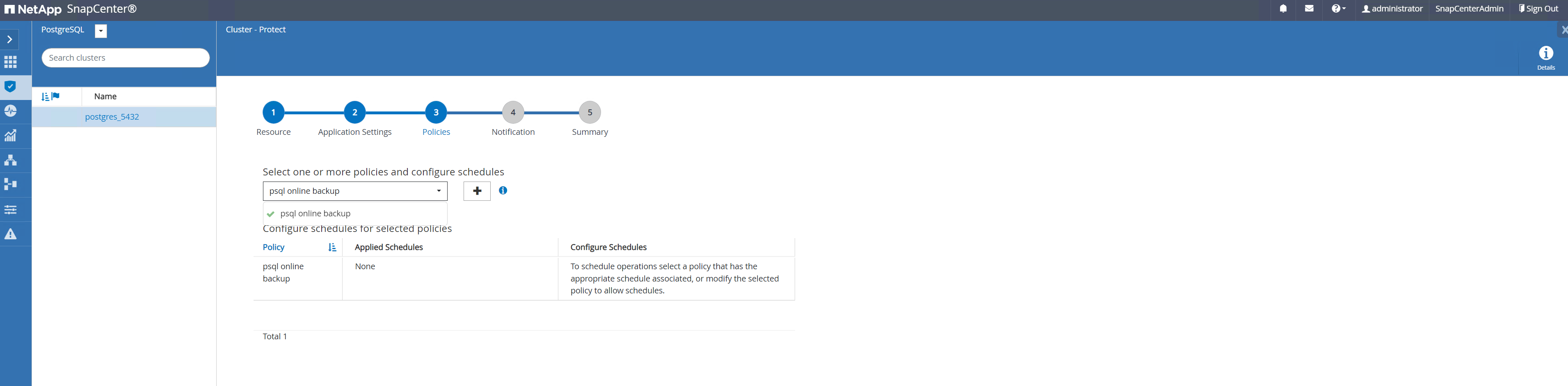
-
Geben Sie die E-Mail-Einstellungen an, wenn eine Sicherungsbenachrichtigung erforderlich ist.
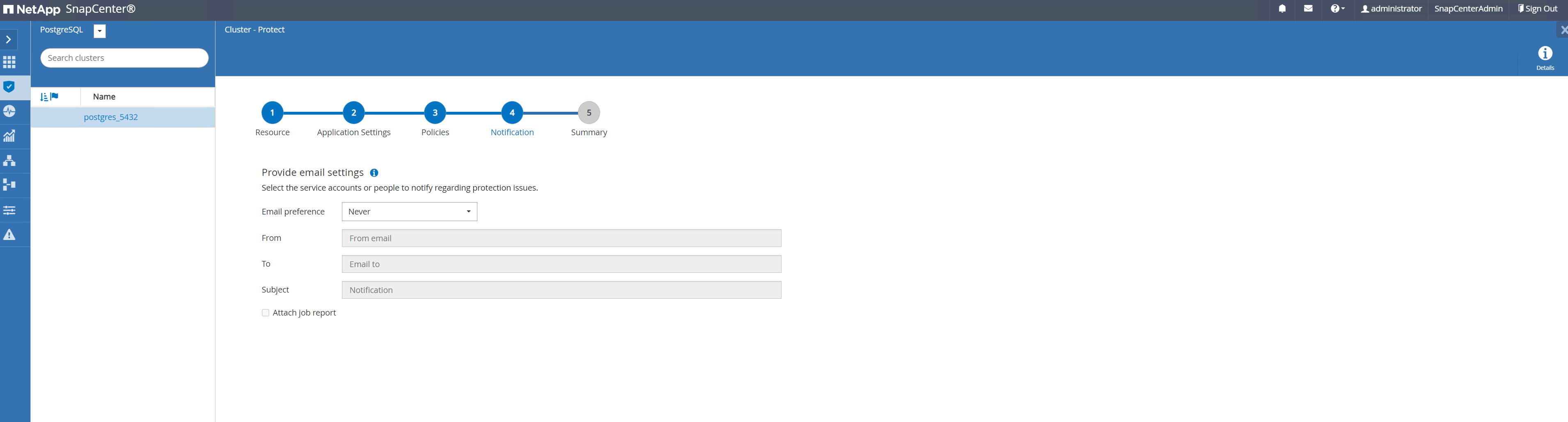
-
Zusammenfassung der Rezension und
Finishum die Sicherungsrichtlinie zu implementieren. Jetzt ist der PostgreSQL-Cluster geschützt.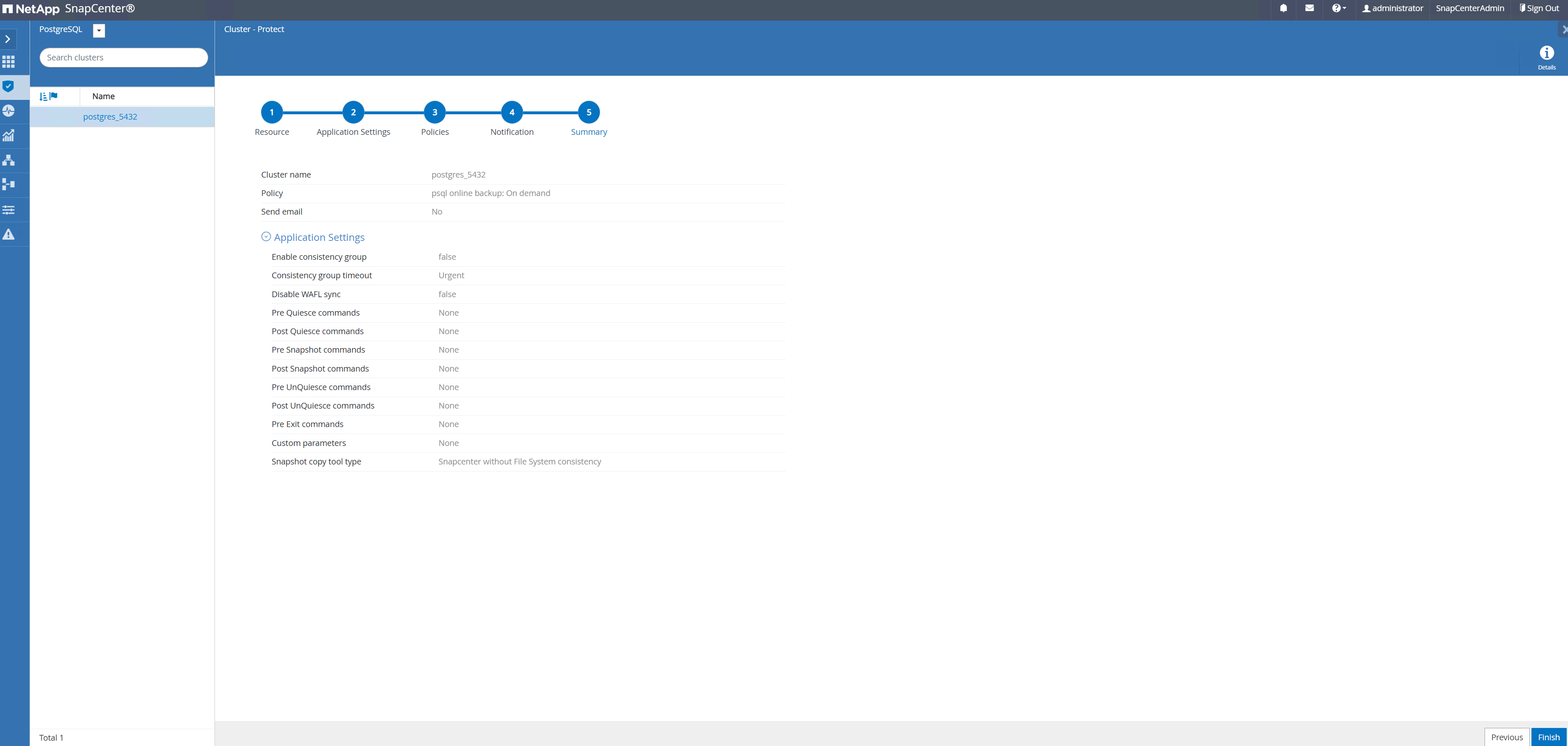
-
Die Sicherung wird gemäß dem Sicherungszeitplan oder aus der Cluster-Sicherungstopologie ausgeführt. Klicken Sie auf
Backup Nowum eine manuelle On-Demand-Sicherung auszulösen.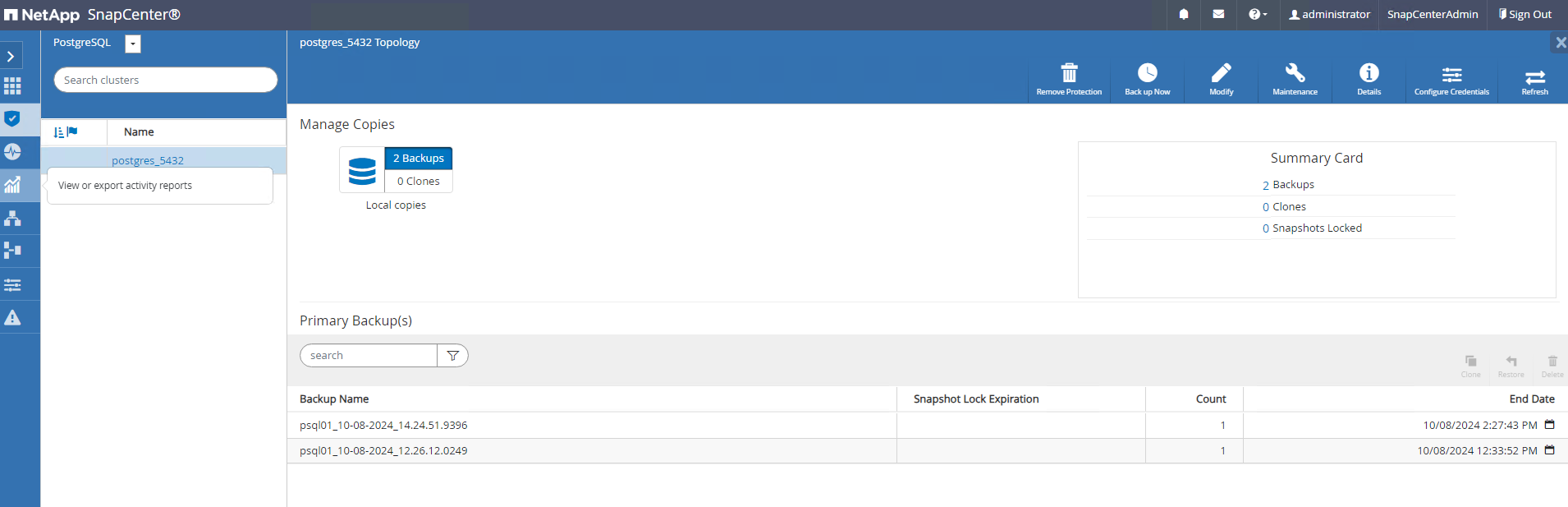
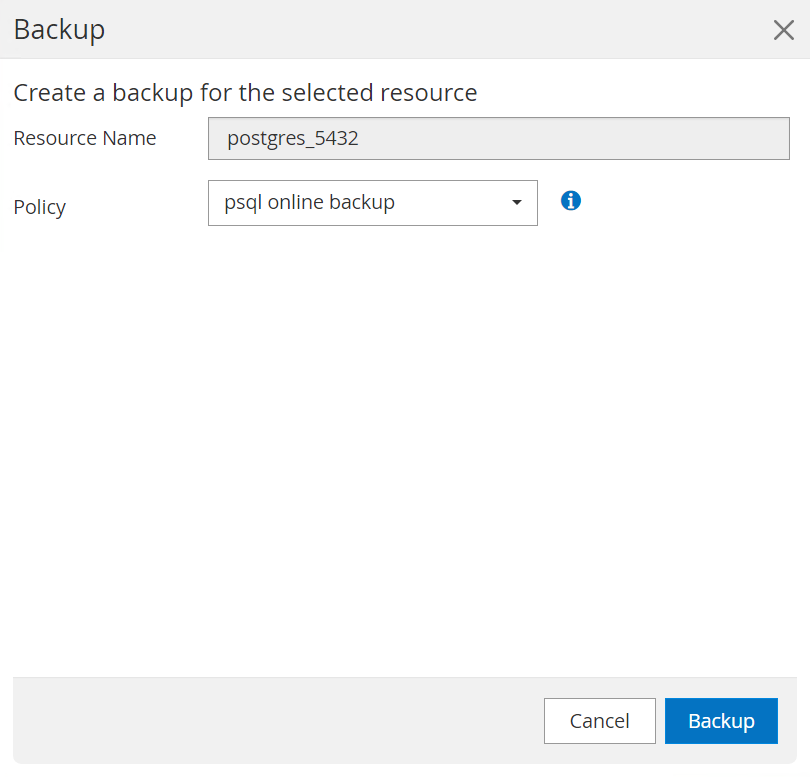
-
Überwachen Sie den Sicherungsauftrag von
MonitorTab. Das Sichern einer großen Datenbank dauert im Allgemeinen nur wenige Minuten. In unserem Testfall dauerte das Sichern von Datenbankvolumina von fast 1 TB etwa 4 Minuten.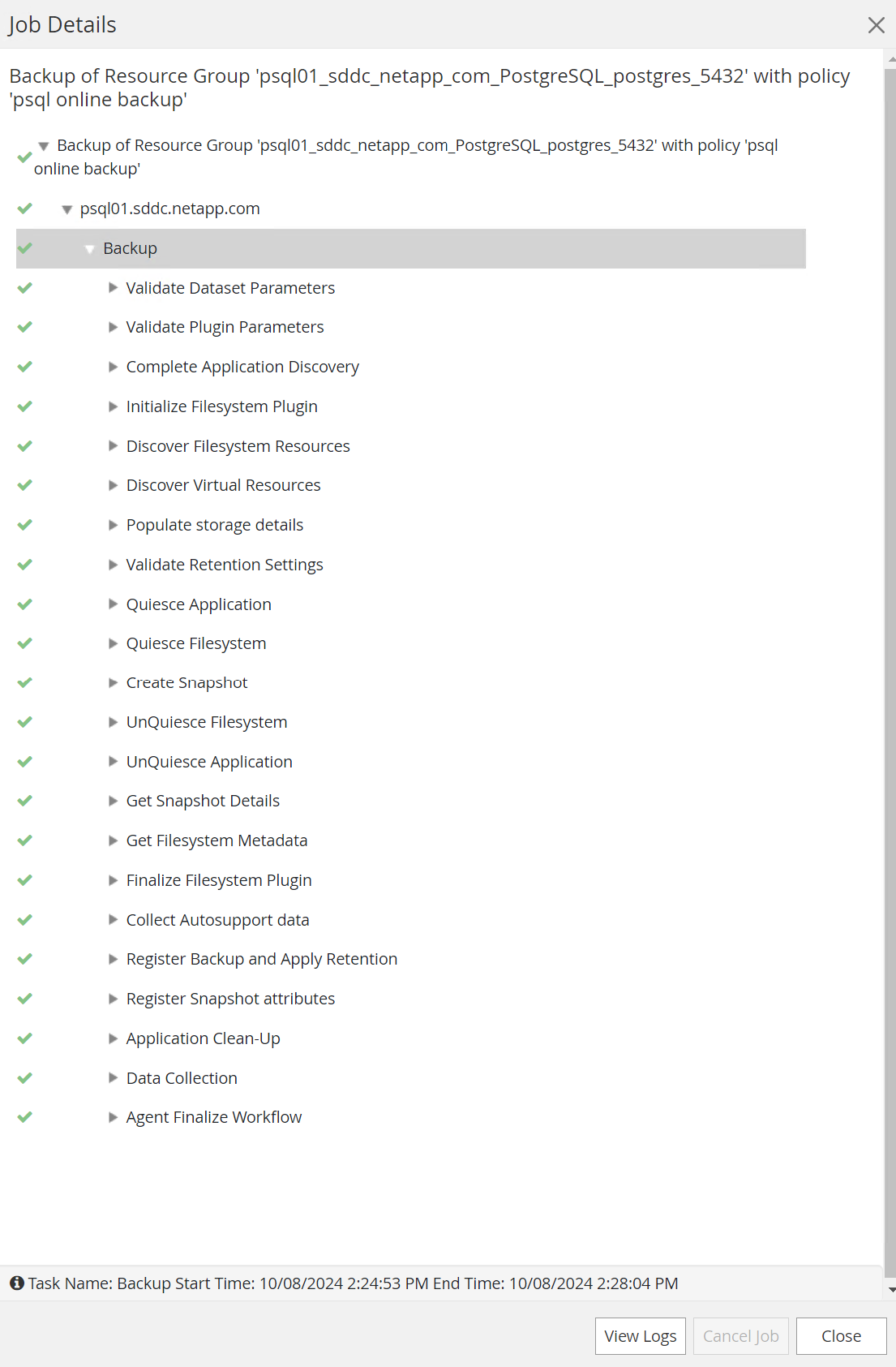
-
Datenbankwiederherstellung
Details
In dieser Demonstration zur Datenbankwiederherstellung zeigen wir eine zeitpunktbezogene Wiederherstellung des PostgreSQL-Datenbankclusters. Erstellen Sie zunächst mit SnapCenter eine SnapShot-Sicherung des Datenbankvolumes auf dem ONTAP -Speicher. Melden Sie sich dann bei der Datenbank an, erstellen Sie eine Testtabelle, notieren Sie den Zeitstempel und löschen Sie die Testtabelle. Starten Sie nun eine Wiederherstellung aus der Sicherung bis zum Zeitstempel, wenn die Testtabelle erstellt wird, um die gelöschte Tabelle wiederherzustellen. Im Folgenden werden die Details des Workflows und der Validierung der zeitpunktbezogenen Wiederherstellung der PostgreSQL-Datenbank mit der SnapCenter -Benutzeroberfläche erfasst.
-
Melden Sie sich bei PostgreSQL an als
postgresBenutzer. Erstellen und löschen Sie eine Testtabelle.postgres=# \dt Did not find any relations. postgres=# create table test (id integer, dt timestamp, event varchar(100)); CREATE TABLE postgres=# \dt List of relations Schema | Name | Type | Owner --------+------+-------+---------- public | test | table | postgres (1 row) postgres=# insert into test values (1, now(), 'test PostgreSQL point in time recovery with SnapCenter'); INSERT 0 1 postgres=# select * from test; id | dt | event ----+----------------------------+-------------------------------------------------------- 1 | 2024-10-08 17:55:41.657728 | test PostgreSQL point in time recovery with SnapCenter (1 row) postgres=# drop table test; DROP TABLE postgres=# \dt Did not find any relations. postgres=# select current_time; current_time -------------------- 17:59:20.984144+00 -
Aus
ResourcesÖffnen Sie die Seite zur Datenbanksicherung. Wählen Sie das wiederherzustellende SnapShot-Backup aus. Klicken Sie dann aufRestoreSchaltfläche, um den Datenbankwiederherstellungs-Workflow zu starten. Beachten Sie den Zeitstempel der Sicherung, wenn Sie eine Point-in-Time-Wiederherstellung durchführen.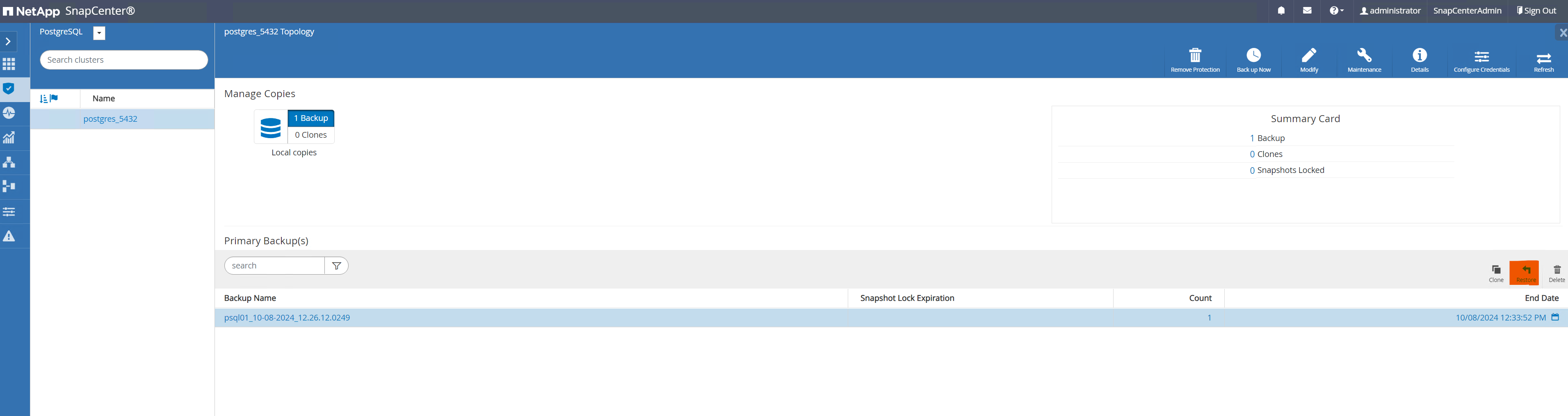
-
Wählen
Restore scope. Derzeit ist eine vollständige Ressource die einzige Option.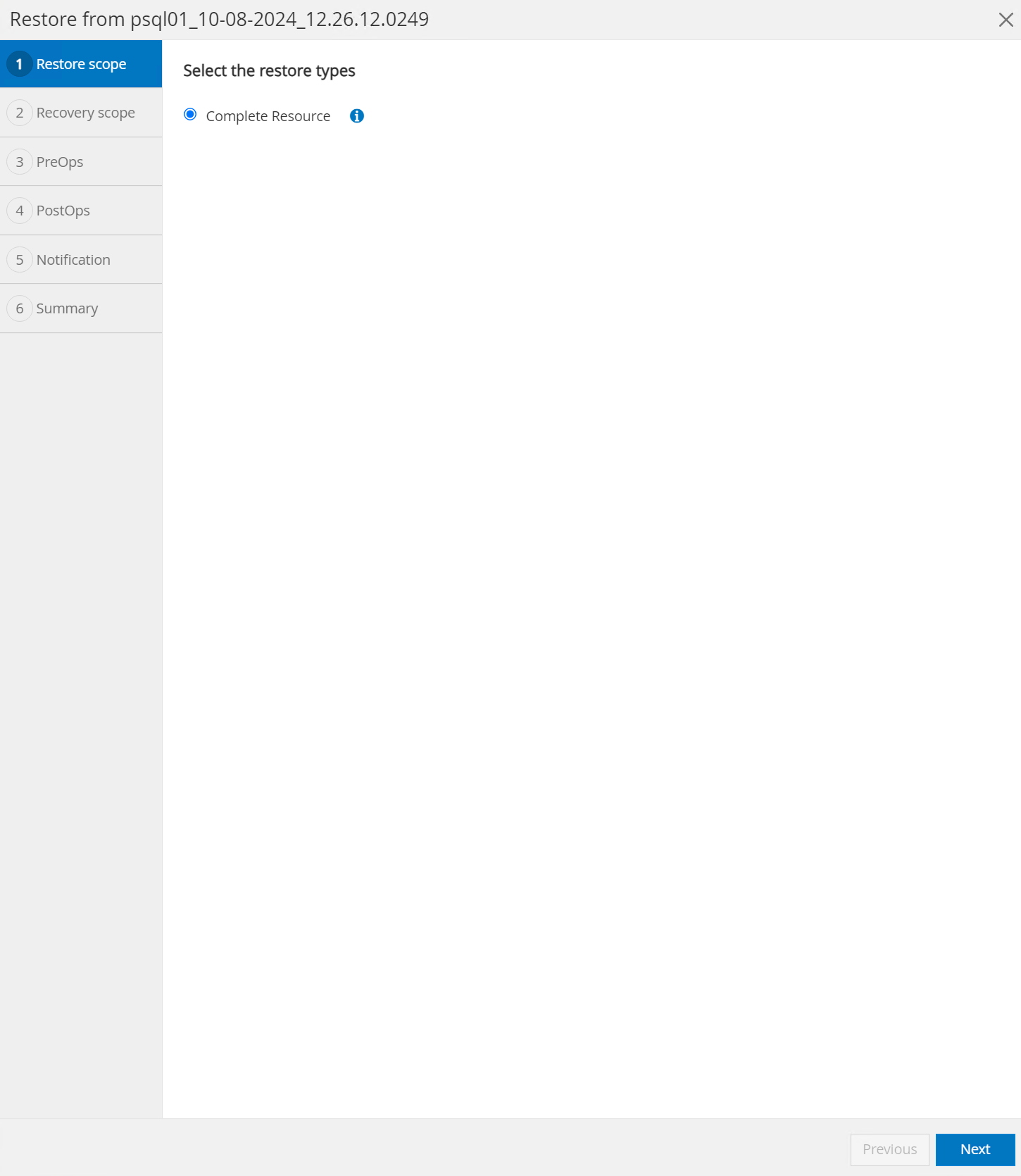
-
Für
Recovery Scope, wählenRecover to point in timeund geben Sie den Zeitstempel ein, bis zu dem die Wiederherstellung fortgesetzt wird.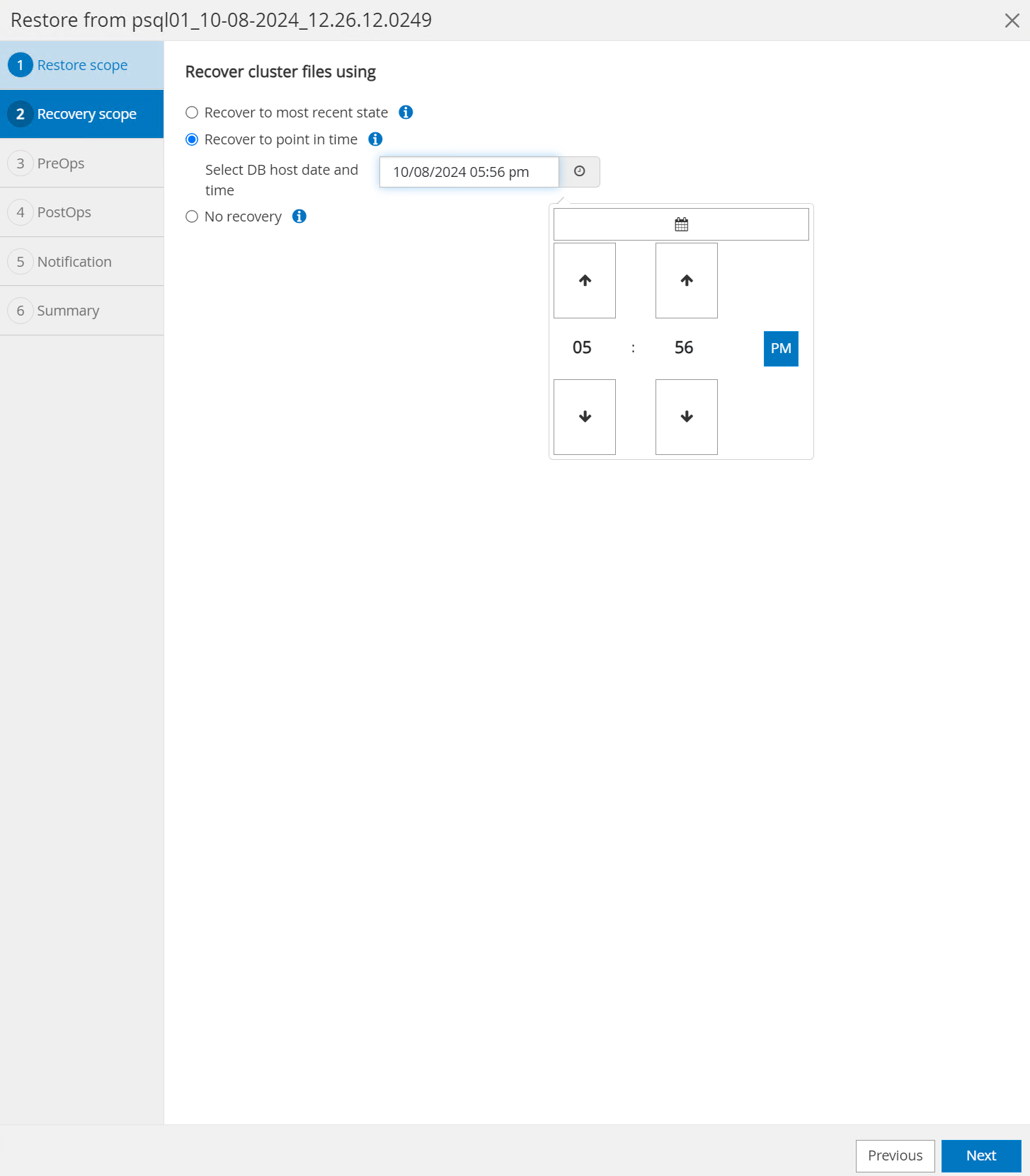
-
Der
PreOpsermöglicht die Ausführung von Skripten für die Datenbank vor dem Wiederherstellungsvorgang oder lässt es einfach schwarz.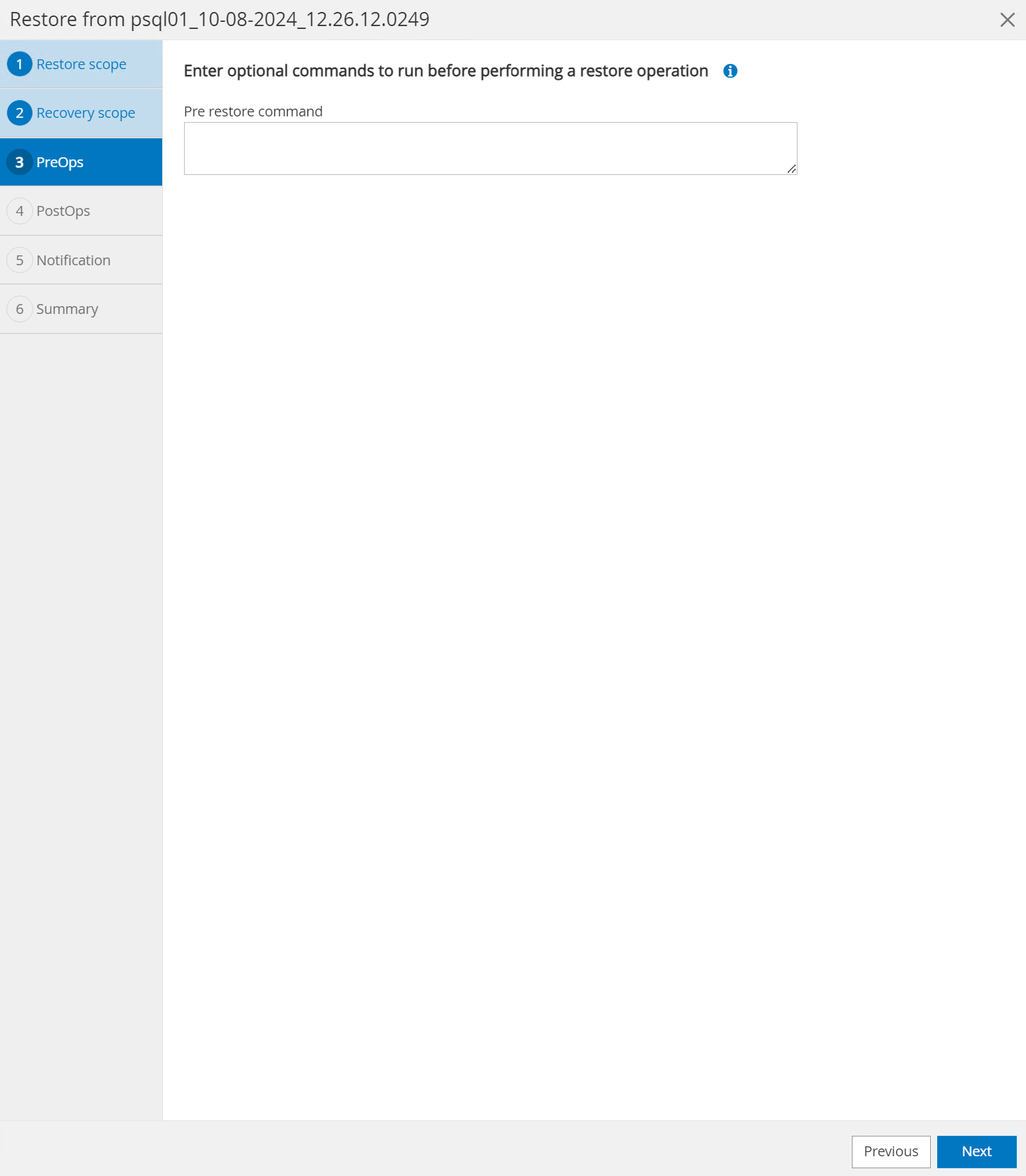
-
Der
PostOpsermöglicht die Ausführung von Skripten für die Datenbank nach dem Wiederherstellungsvorgang oder lässt es einfach schwarz.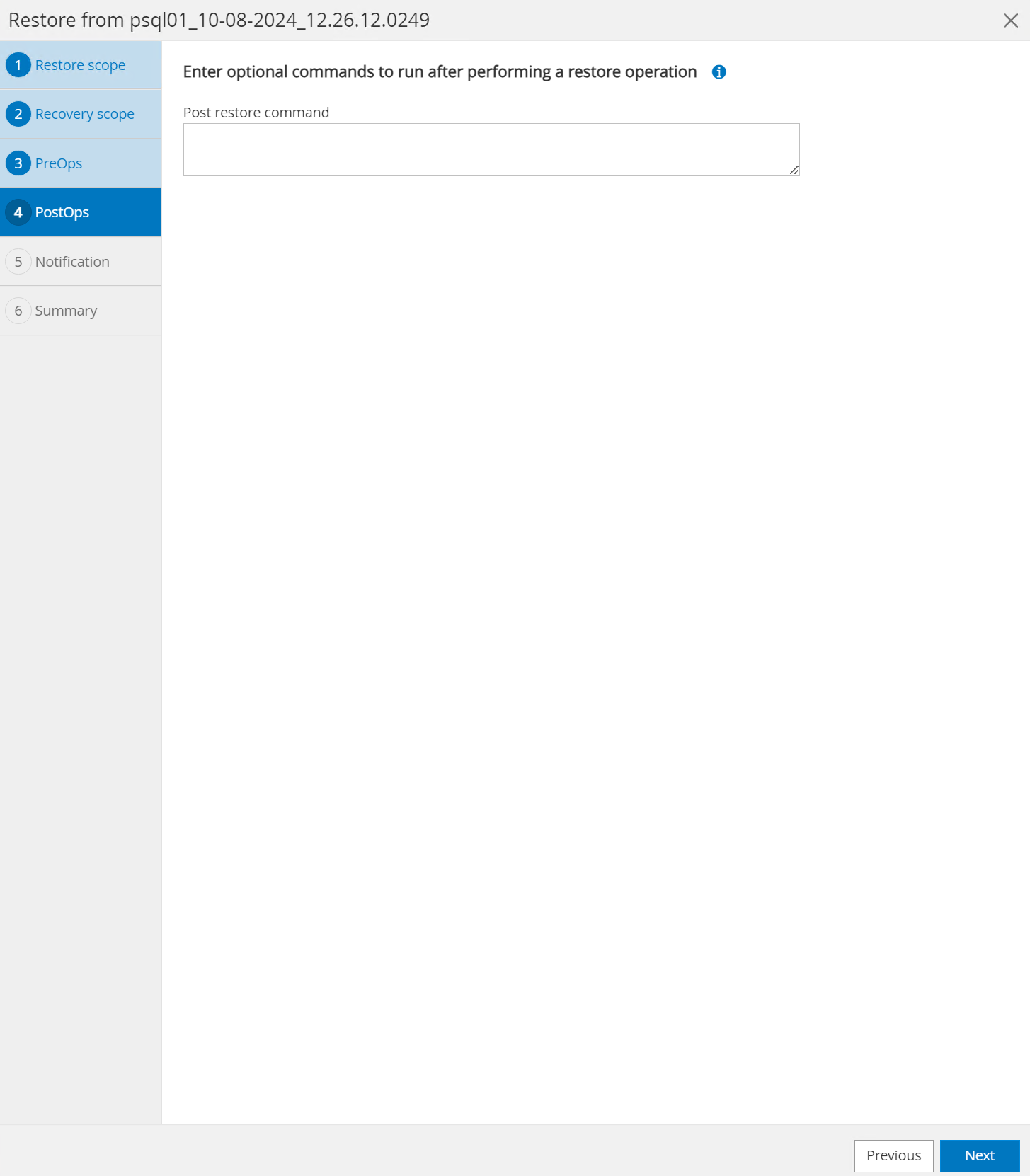
-
Benachrichtigung auf Wunsch per E-Mail.
-
Überprüfen Sie die Jobzusammenfassung und
Finishum den Wiederherstellungsjob zu starten.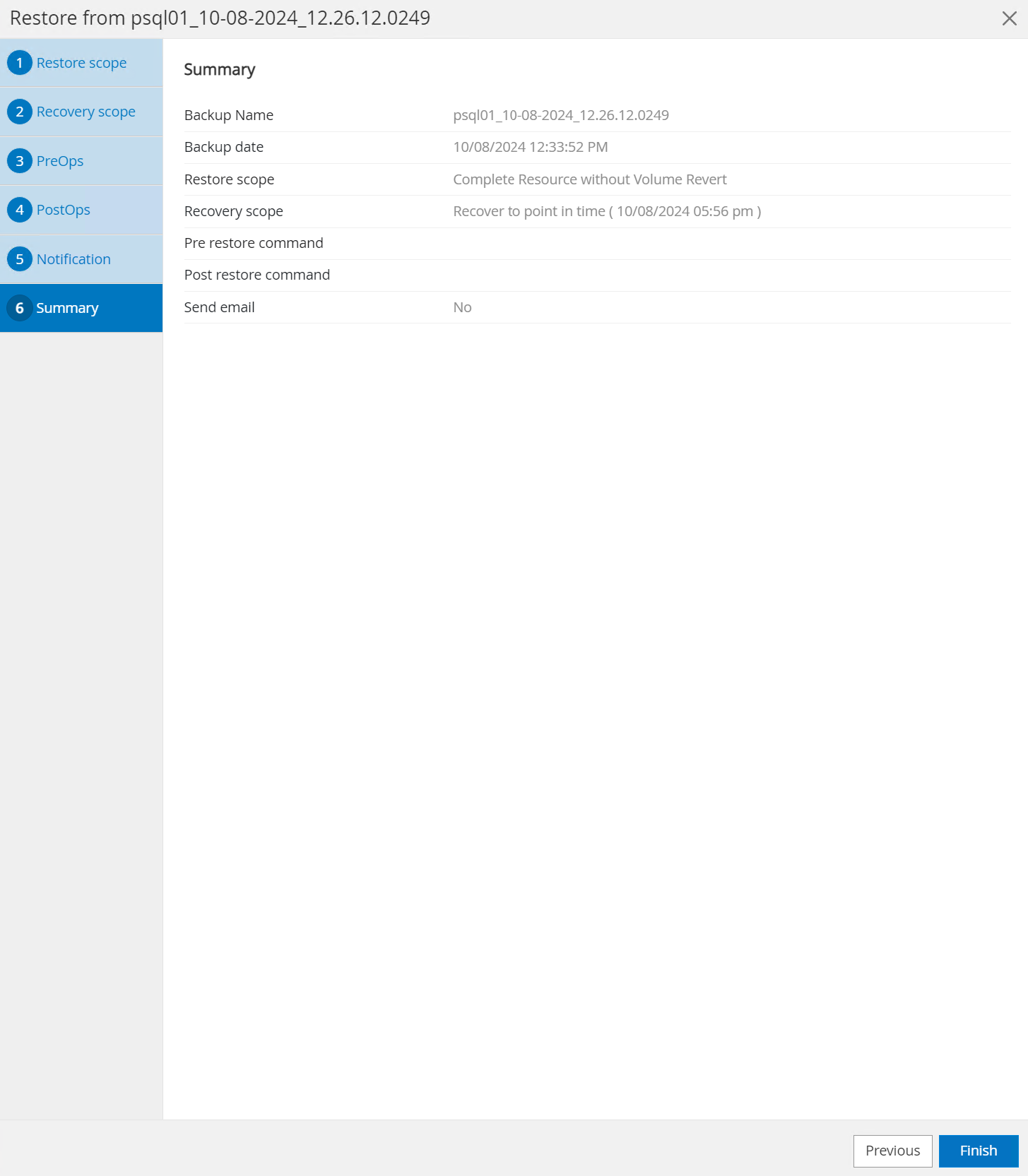
-
Klicken Sie zum Öffnen auf den laufenden Job
Job DetailsFenster. Der Auftragsstatus kann auch geöffnet und angezeigt werden von derMonitorTab.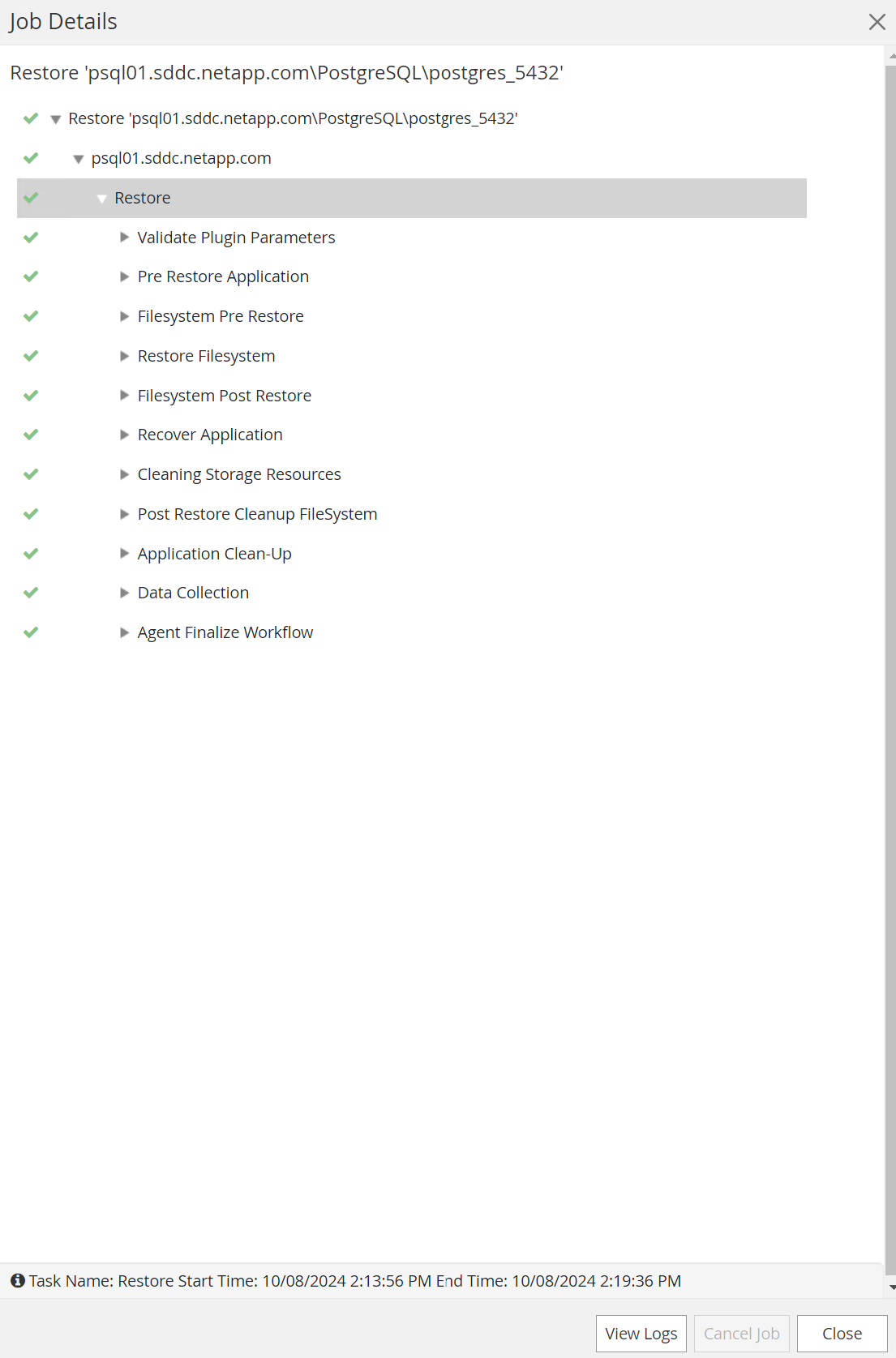
-
Melden Sie sich bei PostgreSQL an als
postgresBenutzer und bestätigen Sie, dass die Testtabelle wiederhergestellt wurde.[postgres@psql01 ~]$ psql psql (14.13) Type "help" for help. postgres=# \dt List of relations Schema | Name | Type | Owner --------+------+-------+---------- public | test | table | postgres (1 row) postgres=# select * from test; id | dt | event ----+----------------------------+-------------------------------------------------------- 1 | 2024-10-08 17:55:41.657728 | test PostgreSQL point in time recovery with SnapCenter (1 row) postgres=# select now(); now ------------------------------- 2024-10-08 18:22:33.767208+00 (1 row)
Datenbankklon
Details
Durch das Klonen eines PostgreSQL-Datenbankclusters über SnapCenter wird aus einer Snapshot-Sicherung eines Quelldatenbank-Datenvolumes ein neues Thin-Clone-Volume erstellt. Noch wichtiger ist, dass es im Vergleich zu anderen Methoden schnell (wenige Minuten) und effizient ist, eine geklonte Kopie der Produktionsdatenbank zu erstellen, um die Entwicklung oder Tests zu unterstützen. Dadurch werden die Speicherkosten drastisch reduziert und das Lebenszyklusmanagement Ihrer Datenbankanwendungen verbessert. Der folgende Abschnitt demonstriert den Arbeitsablauf des PostgreSQL-Datenbankklons mit der SnapCenter -Benutzeroberfläche.
-
Um den Klonvorgang zu validieren. Fügen Sie erneut eine Zeile in die Testtabelle ein. Führen Sie dann eine Sicherung durch, um die Testdaten zu erfassen.
postgres=# insert into test values (2, now(), 'test PostgreSQL clone to a different DB server host'); INSERT 0 1 postgres=# select * from test; id | dt | event ----+----------------------------+----------------------------------------------------- 2 | 2024-10-11 20:15:04.252868 | test PostgreSQL clone to a different DB server host (1 row)
-
Aus
ResourcesÖffnen Sie die Seite zur Sicherung des Datenbankclusters. Wählen Sie den Snapshot der Datenbanksicherung aus, der die Testdaten enthält. Klicken Sie dann aufcloneSchaltfläche, um den Datenbankklon-Workflow zu starten.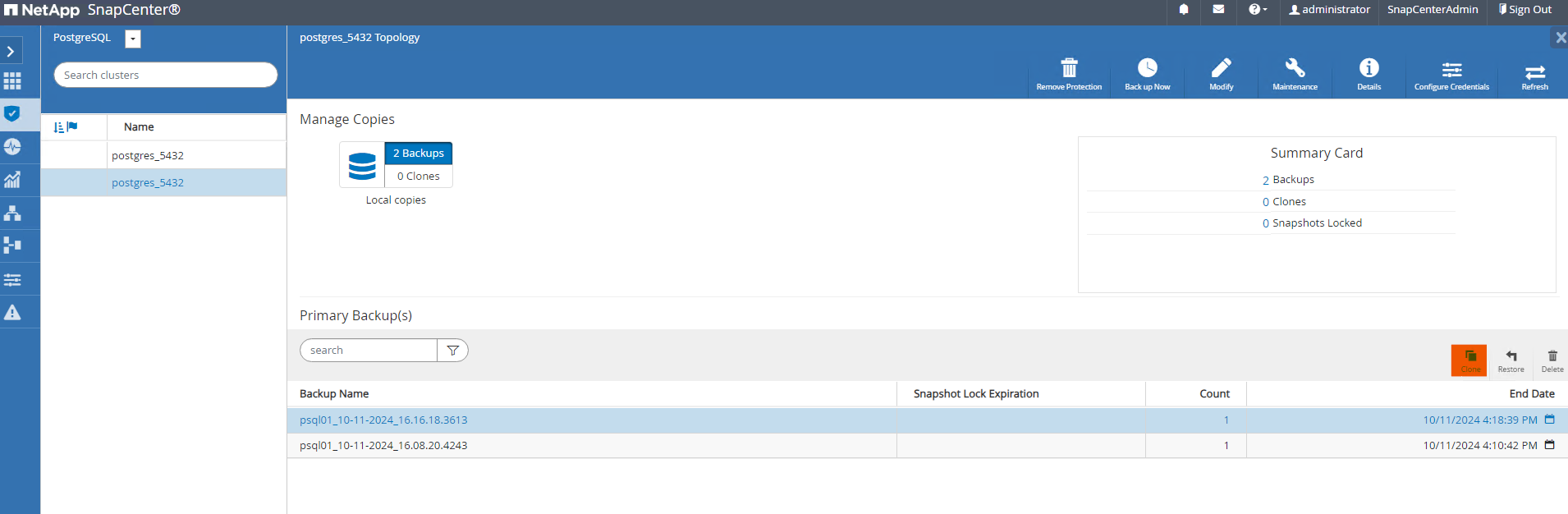
-
Wählen Sie einen anderen DB-Server-Host als den Quell-DB-Server. Wählen Sie einen ungenutzten TCP-Port 543x auf dem Zielhost.
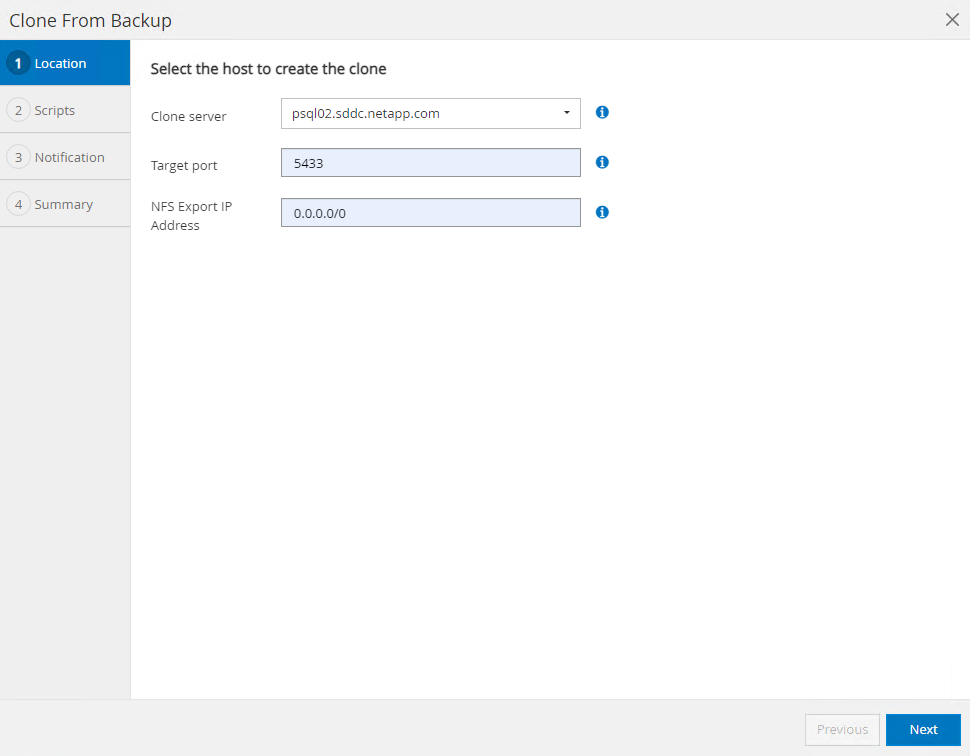
-
Geben Sie alle Skripts ein, die vor oder nach dem Klonvorgang ausgeführt werden sollen.
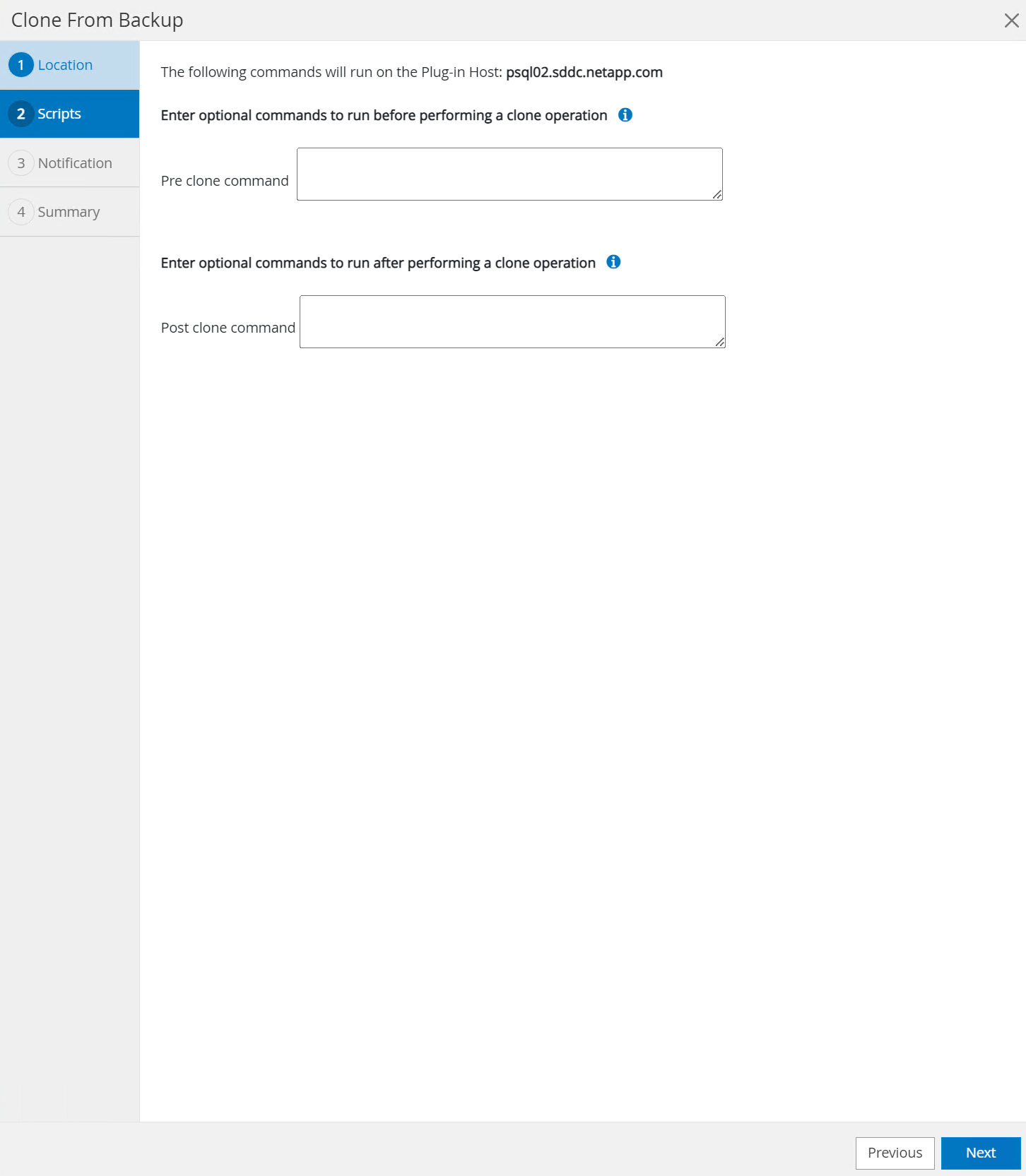
-
Benachrichtigung auf Wunsch per E-Mail.
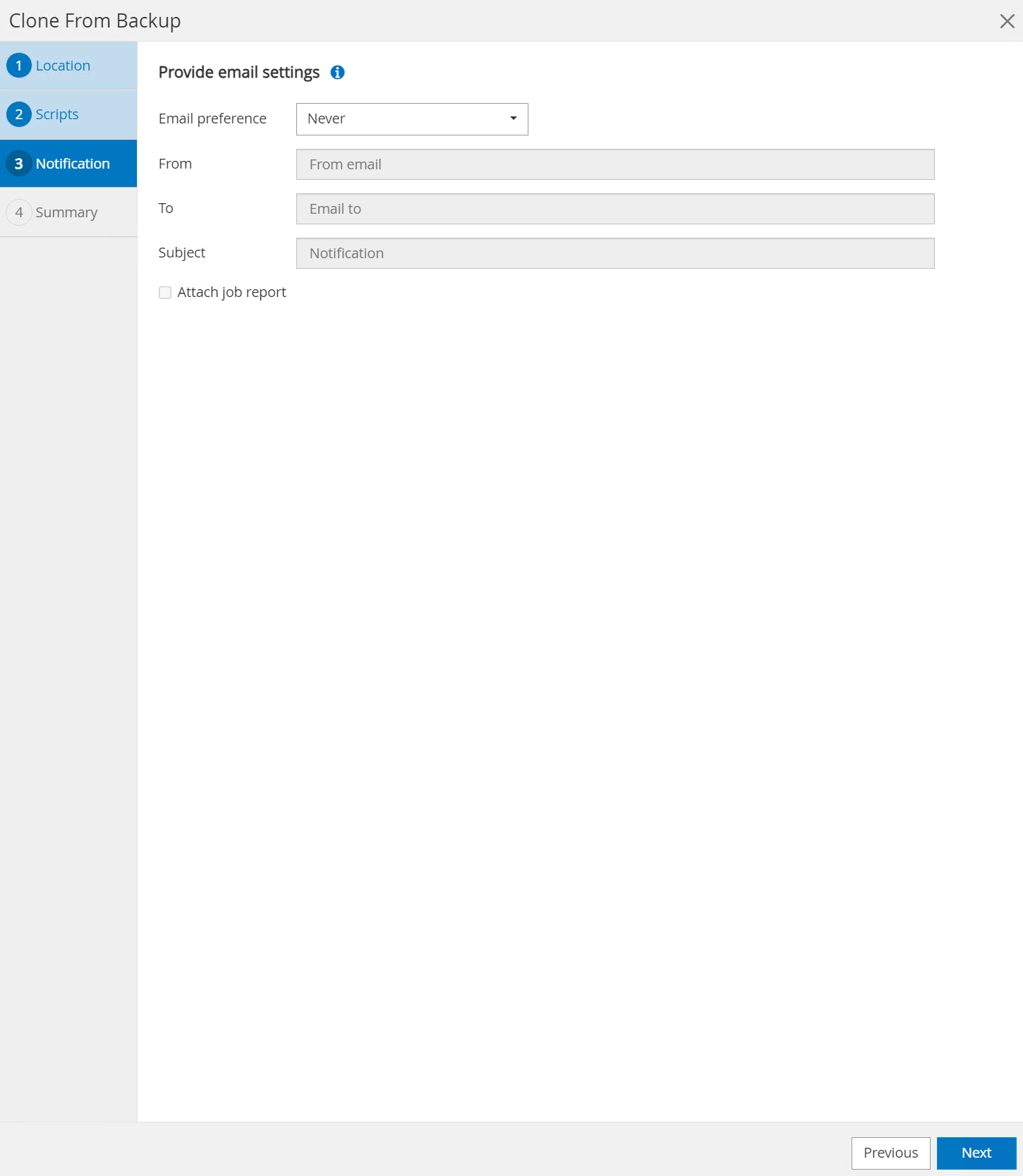
-
Zusammenfassung der Rezension und
Finishum den Klonvorgang zu starten.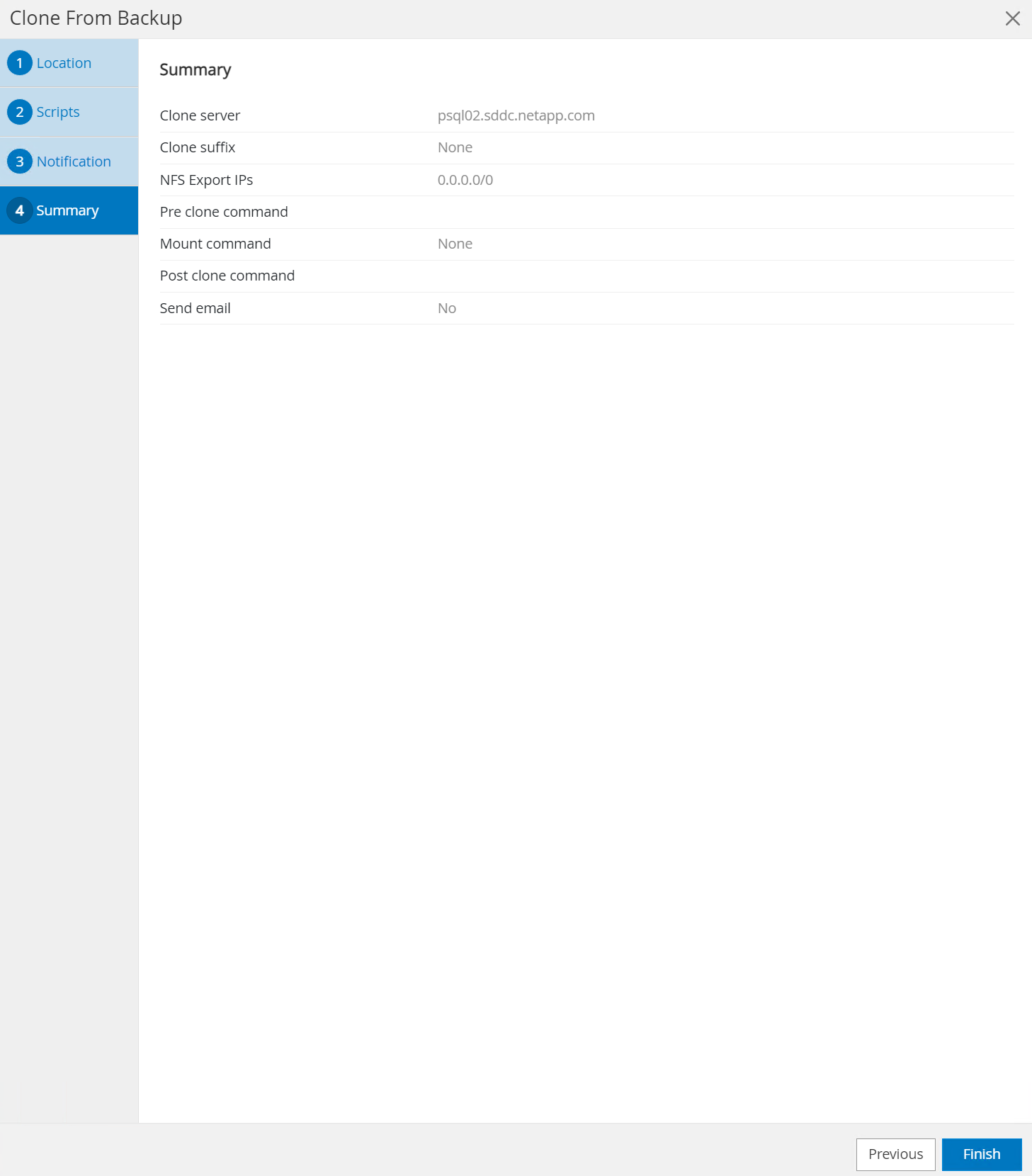
-
Klicken Sie zum Öffnen auf den laufenden Job
Job DetailsFenster. Der Auftragsstatus kann auch geöffnet und angezeigt werden von derMonitorTab.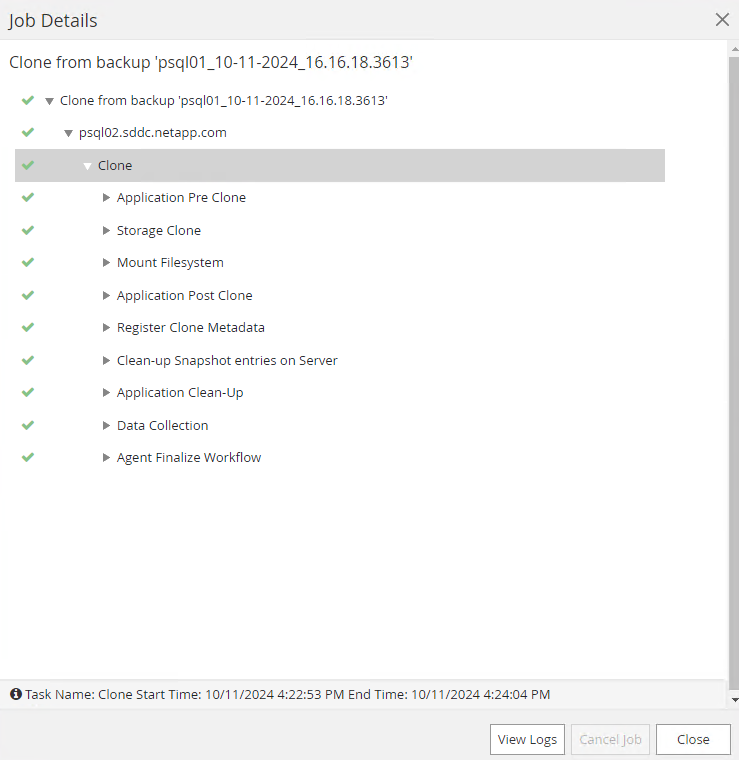
-
Die geklonte Datenbank wird sofort bei SnapCenter registriert.
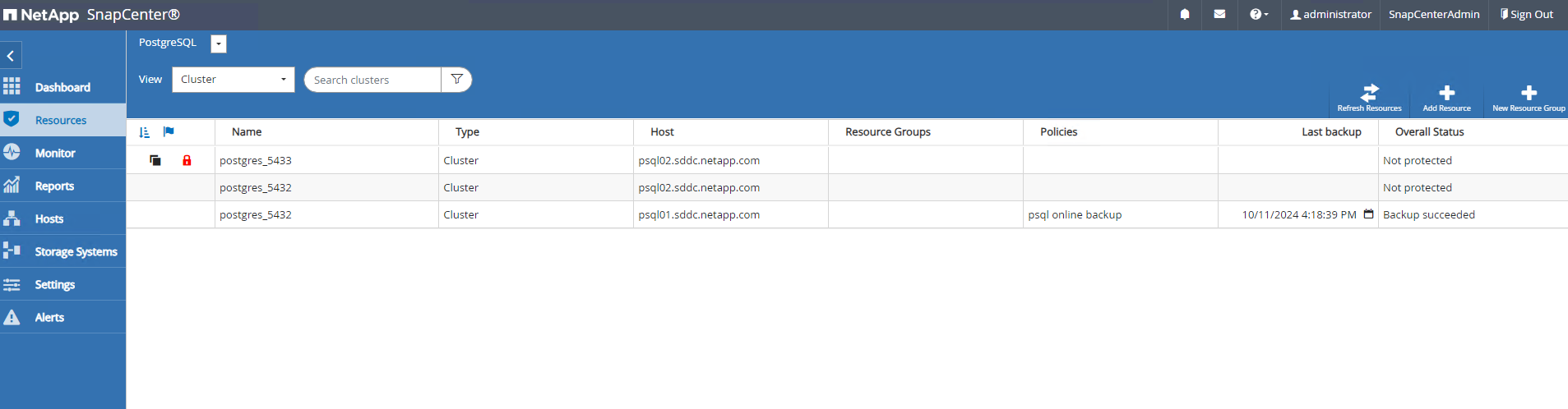
-
Validieren Sie den geklonten Datenbankcluster auf dem Ziel-DB-Serverhost.
[postgres@psql01 ~]$ psql -d postgres -h 10.61.186.7 -U postgres -p 5433 Password for user postgres: psql (14.13) Type "help" for help. postgres=# select * from test; id | dt | event ----+----------------------------+----------------------------------------------------- 2 | 2024-10-11 20:15:04.252868 | test PostgreSQL clone to a different DB server host (1 row) postgres=# select pg_read_file('/etc/hostname') as hostname; hostname ---------- psql02 + (1 row)
Wo Sie weitere Informationen finden
Weitere Informationen zu den in diesem Dokument beschriebenen Informationen finden Sie in den folgenden Dokumenten und/oder auf den folgenden Websites:
-
SnapCenter -Softwaredokumentation
-
TR-4956: Automatisierte Bereitstellung von PostgreSQL mit hoher Verfügbarkeit und Notfallwiederherstellung in AWS FSx/EC2