

Allgemeines zum Performance-Dashboard
 Änderungen vorschlagen
Änderungen vorschlagen
Das Unified Manager Performance Dashboard bietet einen allgemeinen Überblick über den Performance-Status aller Cluster, die in Ihrer Umgebung überwacht werden. Cluster, die Performance-Probleme haben, werden oben auf der Seite nach Schweregrad geordnet. Die Informationen auf dem Dashboard werden automatisch zu jedem fünf-Minuten-Zeitraum der Performance-Erfassung aktualisiert.
Das folgende Bild zeigt ein Beispiel eines Unified Manager Performance-Dashboards für die Überwachung von zwei Clustern:
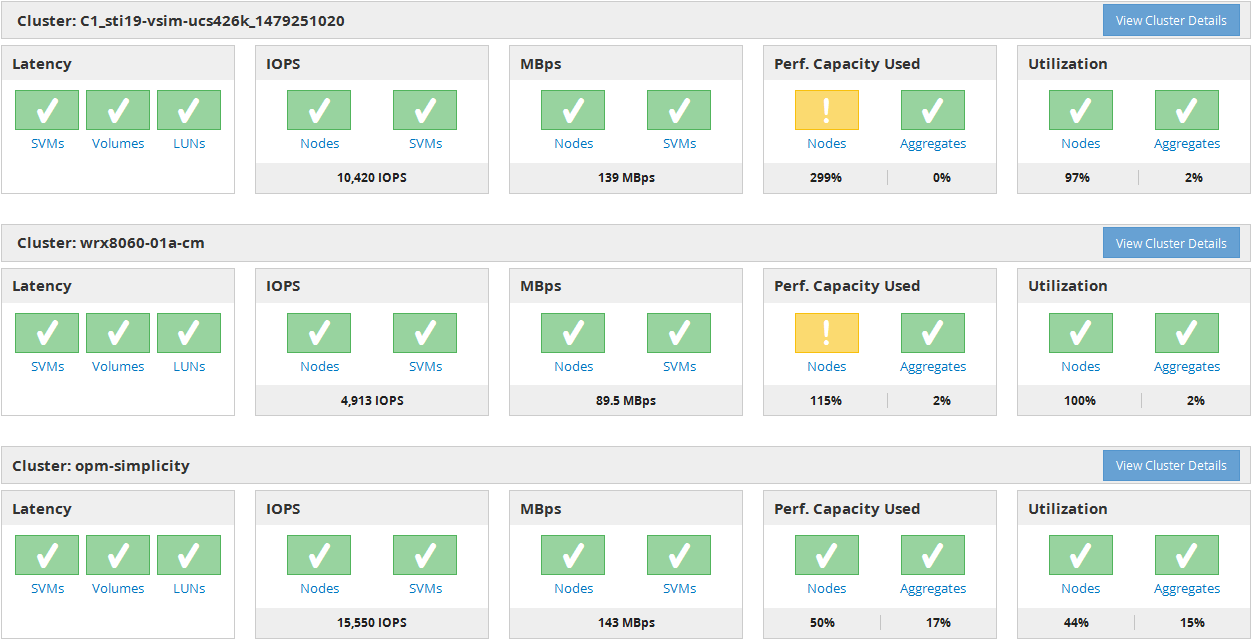
Die Statussymbole, die die Storage-Objekte darstellen, können den folgenden Status aufweisen und vom höchsten Schweregrad bis den niedrigsten Schweregrad sortiert sein:
-
Kritisch (
 ): Ein oder mehrere neue kritische Performanceereignisse wurden für das Objekt gemeldet.
): Ein oder mehrere neue kritische Performanceereignisse wurden für das Objekt gemeldet. -
Warnung (
 ): Für das Objekt wurden mindestens ein neues Warnungsleistungsereignis gemeldet.
): Für das Objekt wurden mindestens ein neues Warnungsleistungsereignis gemeldet. -
Normal (
 ): Für das Objekt wurden keine neuen Performanceereignisse gemeldet.
): Für das Objekt wurden keine neuen Performanceereignisse gemeldet.

|
Die Farbe gibt an, ob neue Ereignisse für das Objekt vorhanden sind. Ereignisse, die nicht mehr aktiv sind, die als veraltete Ereignisse bezeichnet werden, haben keinen Einfluss auf die Farbe des Symbols. |
Cluster-Performance-Zähler
Für jedes Cluster werden die folgenden Performance-Kategorien angezeigt:
-
Latenz
Zeigt, wie schnell das Cluster auf Client-Applikationsanforderungen reagiert, in Millisekunden pro Vorgang.
-
IOPS
Zeigt die Betriebsgeschwindigkeit des Clusters unter der Anzahl der ein-/Ausgabevorgänge pro Sekunde an.
-
MB/Sek.
Zeigt an, wie viele Daten in das und aus dem Cluster in Megabyte pro Sekunde übertragen werden.
-
Verwendete Performance-Kapazität
Zeigt, ob Nodes oder Aggregate die verfügbare Performance-Kapazität überbeanspruchen.
-
Auslastung
Zeigt, ob die Ressourcen auf beliebigen Nodes oder Aggregaten überlastet sind.
Um die Performance Ihres Clusters und Ihrer Storage-Objekte zu analysieren, können Sie eine der folgenden Aktionen durchführen:
-
Sie können auf Cluster-Details anzeigen klicken, um die Cluster-Startseite anzuzeigen. Dort werden detaillierte Performance- und Ereignisinformationen für die ausgewählten Cluster- und Speicherobjekte angezeigt.
-
Sie können auf eines der roten oder gelben Statussymbole eines Objekts klicken, um die Inventarseite für dieses Objekt anzuzeigen. Dort können Sie Details zum Speicherobjekt anzeigen.
Beispielsweise wird durch Klicken auf ein Volume-Symbol die Seite „Performance/Volume-Inventar“ mit einer Liste aller Volumes im ausgewählten Cluster angezeigt, die nach der schlechtesten Performance bis zur besten Performance sortiert ist.