

Überblick
 Änderungen vorschlagen
Änderungen vorschlagen
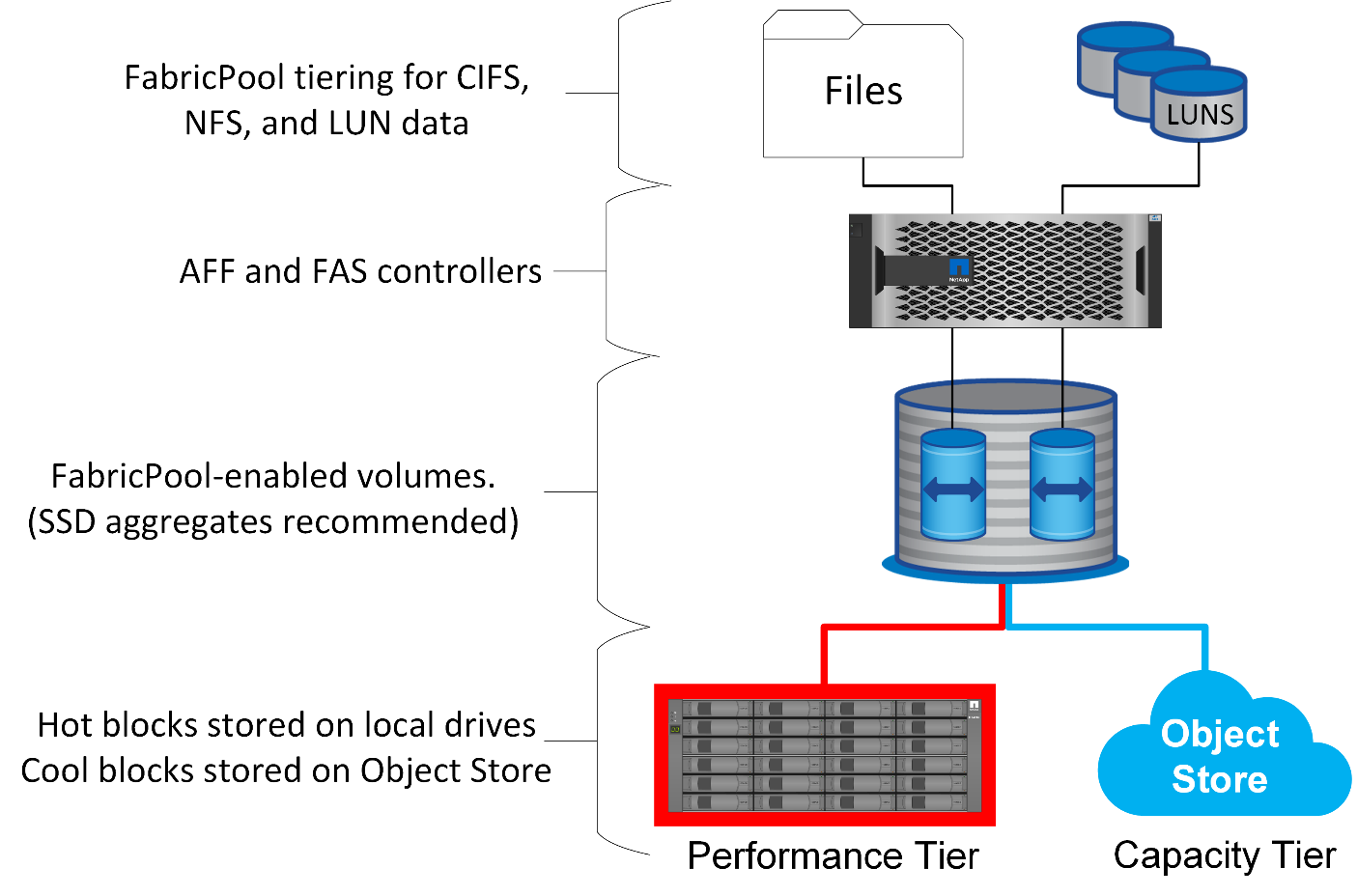
Um zu verstehen, wie sich FabricPool Tiering auf Oracle und andere Datenbanken auswirkt, benötigen Sie ein Verständnis der Low-Level-FabricPool-Architektur.
Der Netapp Architektur Sind
FabricPool ist eine Tiering-Technologie, mit der Blöcke als „heiß“ oder „kalt“ klassifiziert werden und in dem Storage Tier platziert werden, der am besten geeignet ist. Die Performance-Tier befindet sich am häufigsten auf SSD-Storage und hostet die wichtigen Datenblöcke. Die Kapazitäts-Tier befindet sich in einem Objektspeicher und hostet die kühlen Datenblöcke. Unterstützung für Objekt-Storage: NetApp StorageGRID, ONTAP S3, Microsoft Azure Blob Storage, Alibaba Cloud Object Storage-Service, IBM Cloud Object Storage, Google Cloud Storage und Amazon AWS S3
Es stehen mehrere Tiering-Richtlinien zur Verfügung, die steuern, wie Blöcke als „heiß“ oder „kalt“ klassifiziert werden. Die Richtlinien lassen sich für einzelne Volumes festlegen und bei Bedarf ändern. Es werden nur die Datenblöcke zwischen den Performance- und Kapazitäts-Tiers verschoben. Die Metadaten, die die Struktur der LUN und des File-Systems definieren, verbleiben immer auf der Performance-Tier. Dadurch wird das Management auf ONTAP zentralisiert. Dateien und LUNs unterscheiden sich offenbar nicht von Daten, die auf einer anderen ONTAP-Konfiguration gespeichert sind. Der NetApp AFF oder FAS Controller wendet die definierten Richtlinien an, um Daten auf die entsprechende Tier zu verschieben.
Objektspeicher-Anbieter
Bei Objekt-Storage-Protokollen werden einfache HTTP- oder HTTPS-Anfragen zum Speichern einer großen Anzahl von Datenobjekten verwendet. Der Zugriff auf den Objektspeicher muss zuverlässig sein, da der Datenzugriff von ONTAP von der umgehende Erfüllung von Anfragen abhängt. Zu den Optionen gehören Amazon S3 Standard und infrequent Access sowie Microsoft Azure Hot and Cool Blob Storage, IBM Cloud und Google Cloud. Archivierungsoptionen wie Amazon Glacier und Amazon Archive werden nicht unterstützt, da die zum Abrufen von Daten erforderliche Zeit die Toleranzen der Host-Betriebssysteme und -Applikationen überschreiten kann.
Zudem wird NetApp StorageGRID unterstützt und stellt eine optimale Lösung der Enterprise-Klasse dar. Es ist ein hochperformantes, skalierbares und hochsicheres Objekt-Storage-System, das geografische Redundanz für FabricPool Daten und andere Objektspeicher-Applikationen bietet, die zunehmend Teil von Enterprise-Applikationsumgebungen sind.
StorageGRID kann zudem die Kosten senken, indem es die Egress-Gebühren vermeidet, die viele Public-Cloud-Provider beim Lesen der Daten aus ihren Services auferlegen.
Daten und Metadaten
Beachten Sie, dass der Begriff „Daten“ hier für die tatsächlichen Datenblöcke gilt, nicht für die Metadaten. Es werden nur Datenblöcke als Tiering übertragen, wobei die Metadaten in der Performance-Tier verbleiben. Darüber hinaus wird der Status eines Blocks als „heiß“ oder „kalt“ nur beeinflusst, wenn der eigentliche Datenblock gelesen wird. Das einfache Lesen des Namens, des Zeitstempels oder der Eigentümermetadaten einer Datei hat keine Auswirkung auf den Speicherort der zugrunde liegenden Datenblöcke.
Backups
Obwohl FabricPool den Storage-Platzbedarf deutlich reduzieren kann, ist es nicht für sich genommen eine Backup-Lösung. NetApp WAFL Metadaten bleiben immer auf der Performance-Tier. Falls ein schwerwiegender Ausfall die Performance-Tier zerstört, kann keine neue Umgebung aus den Daten auf der Kapazitäts-Tier erstellt werden, da sie keine WAFL-Metadaten enthält.
FabricPool kann jedoch Teil einer Backup-Strategie werden. FabricPool lässt sich beispielsweise mit der Replizierungstechnologie NetApp SnapMirror konfigurieren. Jede Hälfte der Spiegelung kann über eine eigene Verbindung mit einem Objekt-Storage-Ziel verfügen. Daraus ergeben sich zwei unabhängige Kopien der Daten. Die primäre Kopie besteht aus den Blöcken auf der Performance-Tier und den zugehörigen Blöcken auf der Kapazitäts-Tier, während das Replikat einen zweiten Satz von Performance- und Kapazitätsblöcken darstellt.