

Performance
 Änderungen vorschlagen
Änderungen vorschlagen
NetApp AFX wurde mit Blick auf Leistung und Skalierbarkeit entwickelt – speziell ausgerichtet auf Workloads, die einen hohen Lese- und Schreibdurchsatz erfordern und eine einfache, lineare Skalierung ermöglichen.
Leistung pro Knoten
Jeder NetApp AFX-Speicherknoten bietet einen bestimmten Durchsatz für Lese- und Schreibvorgänge. Mit dem Hinzufügen weiterer Knoten zum Cluster erhöht sich diese Leistung linear, wie im Abschnitt „Lineare Skalierung der Knotenleistung“ dieses Dokuments beschrieben.
Aktuell sind die Knotentypen "AFX 1K" und bieten einen Durchsatz für Lese- und Schreibvorgänge in etwa in den unten aufgeführten Mengen. Da neuere Hardware für NetApp AFX verfügbar ist, können sich diese Grenzwerte ändern. HINWEIS: Die maximale Leistung wurde durch den Einsatz mehrerer Clients beim Lesen und Schreiben mehrerer Dateien erreicht, wie im Abschnitt „Benchmark-Ergebnisse“ unten dargestellt.
Leistungsschätzungen pro Knoten
| Knotentyp | Leseleistung max | maximale Schreibleistung |
|---|---|---|
AFX 1K |
~35GB/s |
~10GB/s |

|
Die aktuellsten Leistungsschätzungen erhalten Sie von Ihrem NetApp Vertriebsteam. |
Leistung pro Regal
Jedes Shelf enthält Hochleistungs-Shelf-Module mit 16 x 100-GB-Ethernet-Ports, die RoCEv2-Kommunikation für eine hohe Bandbreite beim Datenaustausch mit den Rechenknoten im Cluster nutzen. Wie jede physische Ressource haben auch diese Shelfs Maximalwerte, die erreicht werden können – insbesondere, da NetApp AFX mehrere Knoten bereitstellen kann, die auf denselben Satz von Festplatten zugreifen. Die folgende Tabelle zeigt die geschätzte maximale Lese- und Schreibleistung für ein einzelnes Shelf für TLC- und QLC-Laufwerke. Weitere Informationen zu den Unterschieden zwischen TLC und QLC finden Sie hier "TLC vs. QLC".
Schätzungen der Leistung pro Regal
| Regalmodul-Typ | Leseleistung max | maximale Schreibleistung |
|---|---|---|
NSM 140 |
140GB/s (TLC und QLC) |
70GB/s TLC 35GB/s QLC |
|
|
Die aktuellsten Leistungsschätzungen erhalten Sie von Ihrem NetApp Vertriebsteam. |
Leistungsdichte
Durch die Entkopplung der Speicherknoten von den Regalen in der disaggregierten ONTAP-Architektur können mehr Knoten den Datenverkehr auf weniger Regale leiten, was dazu beiträgt, den gesamten Platzbedarf des Rechenzentrums zu reduzieren, um mit nur der benötigten Kapazität maximale Performance zu erzielen.
Dieses Konzept der „Leistungsdichte“ ermöglicht es Speicheradministratoren, das Beste aus der vorhandenen Hardware herauszuholen, ohne ihre Speicherumgebung jemals überdimensionieren zu müssen.
In einem einheitlichen ONTAP Cluster, da jeder Knoten über einen eigenen Satz von Festplatten verfügt, wird die Leistung nur auf die Festplatten konzentriert, die dem jeweiligen Knoten gehören, und da nur ein Knoten auf einen Satz von Festplatten zugreifen kann, kann er die verfügbaren Festplatten nicht unbedingt auslasten und seine maximale Leistung erreichen.
Unified ONTAP – Wie die Leistung aufgeteilt wird
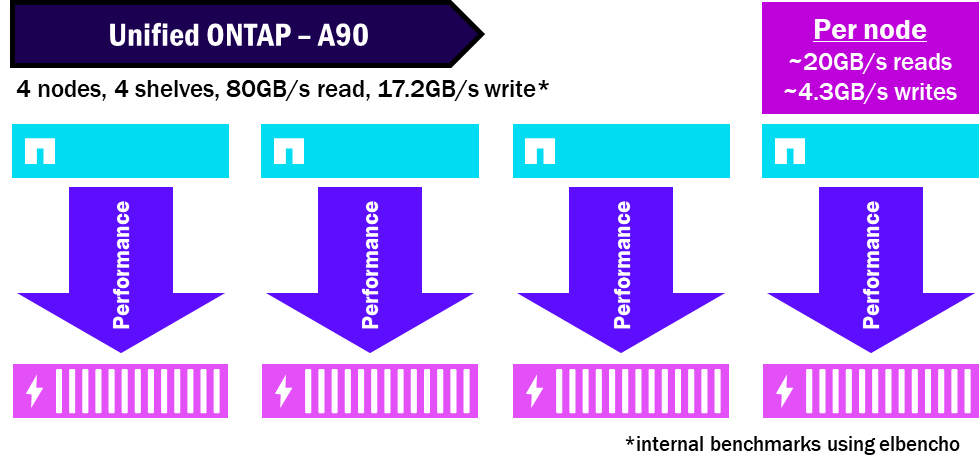
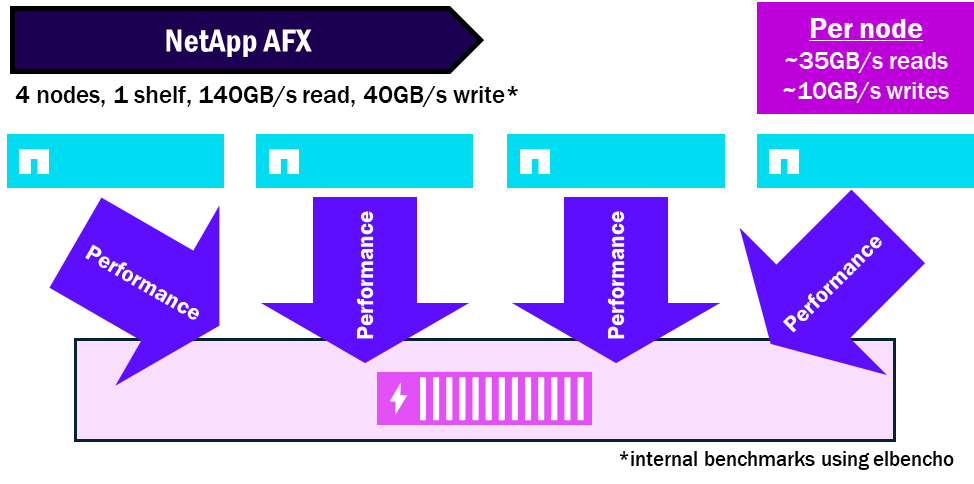
NetApp AFX bündelt alle Festplatten in einer einzigen Storage Availability Zone, sodass alle Knoten alle Festplatten nutzen können. Und da die Festplatten und Knoten entkoppelt sind, benötigen Sie nicht so viele Shelfs, um die gleiche Performance zu erzielen. Dies verdichtet die Performance und maximiert das maximale Leistungspotenzial des Shelfs.
NetApp AFX – Leistungsdichte
Knoten-zu-Regal-Verhältnisse
Unified ONTAP-Knoten benötigen mindestens einen Festplattensatz pro Knoten und können mehrere Shelfs an einen einzelnen Knoten anschließen. Dadurch können Leistungsengpässe an einem einzelnen Knoten auftreten, da dieser möglicherweise seine eigenen Festplatten nicht vollständig auslasten kann.
NetApp AFX stellt allen Knoten alle Festplattengehäuse zur Verfügung. Jedes Gehäuse enthält Module mit 16 x 100GB RoCE-fähigen Schnittstellen, um die maximale Leistung pro Gehäuse zu erhöhen. Dadurch können mehrere Knoten ein einzelnes Gehäuse vollständig auslasten, indem sie auf dieselben Festplatten lesen und schreiben.
Ab ONTAP 9.19.1 beträgt das node:shelf Sättigungsverhältnis etwa 4:1.
Benchmark-Ergebnisse
Im folgenden Abschnitt werden Benchmark-Ergebnisse mit einem NetApp AFX-Cluster und den folgenden Konfigurationsparametern dargestellt.
-
4 Knoten, 4 Datenschnittstellen
-
2 Regale (7,6-TB-Festplatten)
-
ONTAP 9.19.1
-
NFSv4.2 (pNFS, Session Trunking)
-
FlexGroup-Volume
-
"ElBencho"Benchmark
-
Schreibvorgänge: elbencho --hosts=x.x.x.[y-z] -d -w -b 1M -t 80 --iodepth 1 --direct -s 600g /fio_vol1/
-
Lesevorgänge: elbencho --hosts=x.x.x.[y-z] -r -b 256k -t 80 --lat --iodepth 2 --direct -s 600g --infloop /fio_vol1/
-
4 Cisco C240 M8 Server, 2 Port * 200GbE CX-7 Karten, 80 Threads
-
NFS-Mountoptionen: rw,vers=4.2,rsize=1048576,wsize=1048576,trunkdiscovery,proto=tcp
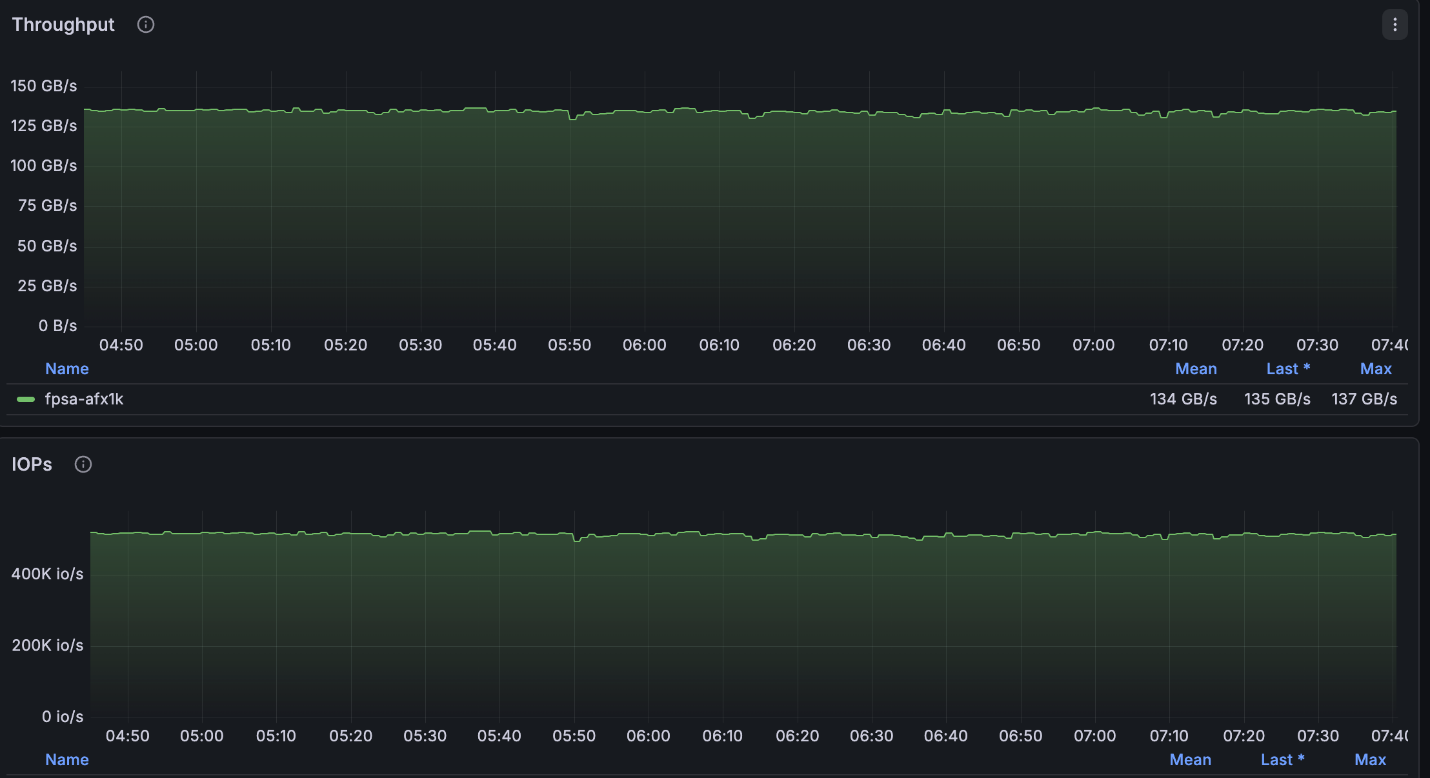
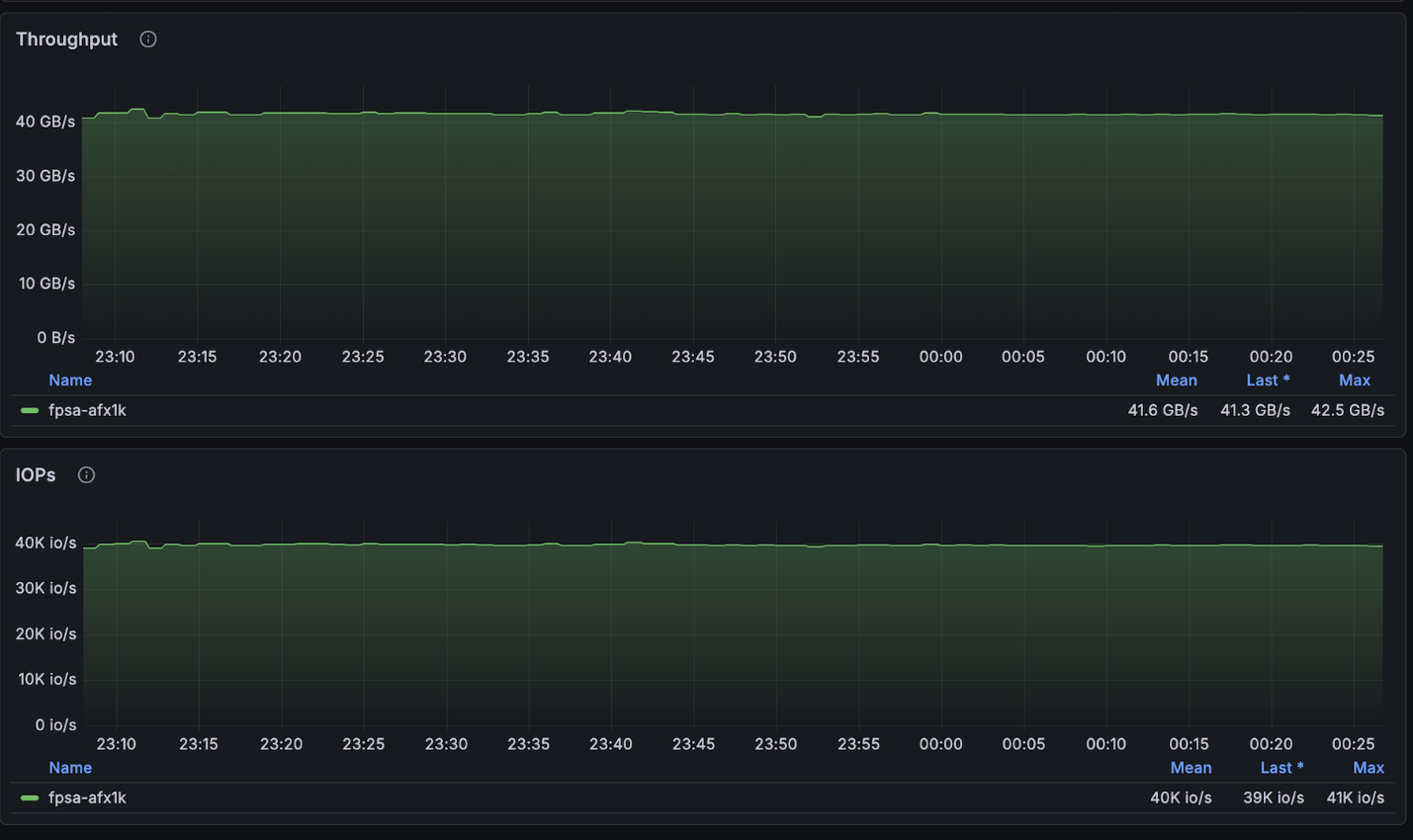
Die oben genannte Konfiguration erreichte nahezu die maximal verfügbaren Lesevorgänge des 4-Knoten-Clusters (~134GB/s) und lag genau an den maximal zulässigen Schreibvorgängen pro Knoten (40GB/s).
NetApp AFX – ElBencho Leseleistung, 4 Knoten
NetApp AFX – ElBencho Schreibleistung, 4 Knoten
Aggressives Read-Ahead
Bei Medienstreaming-Workloads wird ein 4K-Film oft in Zehntausende von Dateien aufgeteilt, die jeweils typischerweise 50 MB bis 250 MB groß sind. Jede Datei repräsentiert ein Frame, und die Anwendung liest ein komplettes Frame in einer einzigen Anfrage. Um einen flüssigen, unterbrechungsfreien Stream ohne sichtbare Pufferung zu gewährleisten, müssen diese Frame-Lesevorgänge ohne Aussetzer abgeschlossen werden.
ONTAP bietet eine Option auf Volume-Ebene (-aggressive-readahead-mode) zur Optimierung dieser Workloads. Ab ONTAP 9.19.1 wurde auf AFX ein neuer cross_file_sequential_read Modus für aggressives Vorlesen eingeführt, um Workloads mit vorhersehbaren E/A-Mustern bei ähnlichen Dateitypen (z. B. Medienrendering und Streaming) zu beschleunigen.
cross_file_sequential_read sagt die nächste zu lesende Datei anhand ihres Namens voraus und beginnt mit dem Vorabruf dieser Dateien, bevor der Client den Leseaufruf ausführt. Die Vorhersagelogik geht davon aus, dass alle Dateien in einem Verzeichnis einem Namensmuster mit monoton steigender numerischer Endung folgen (z. B. Datei1, Datei2, Datei3). Alle Dateien im Verzeichnis müssen diesem Muster entsprechen, wobei entweder die Dezimal- oder die Hexadezimalnummerierung verwendet wird. Dateinamen dürfen bis zu 255 Zeichen lang sein. Die Logik ist unabhängig von der Dateinamenerweiterung und generiert die nächsten Dateinamen im aktuellen Verzeichnis ausschließlich anhand des aktuellen Dateinamens. Existiert ein zuvor mit Dezimalzahlen generierter Dateiname nicht im Verzeichnis, werden die Namen mit Hexadezimalzahlen neu generiert. Existiert keiner der generierten Dateinamen, wird für diese Gruppe kein Vorabruf durchgeführt. Der Vorabruf wird fortgesetzt, sobald der nächste Leseaufruf des Clients erfolgt.
Mit diesen aktivierten Optionen "Frametest" konnten Leistungsbenchmarks 30.000 4K-Frames mit 30 Bildern pro Sekunde mit 30 Clients (NFSv3 und SMB3) und 34 Clients (NFSv4.1) lesen, ohne dass ein einziger Frame verloren ging.
Während sequenzielles Lesen über mehrere Dateien hinweg primär für Medien-Workloads konzipiert ist, können auch andere leseintensive Workloads mit vorhersehbaren Zugriffsmustern und Dateinamen – wie beispielsweise AI-Training und -Inference – davon profitieren.
Überlegungen und Vorbehalte
-
Gemeinsamer Puffer-Cache – Aggressives Vorlesen nutzt denselben Puffer-Cache wie andere Volumes auf dem Knoten. Die Aktivierung kann die Leseleistung anderer Volumes auf diesem Knoten beeinträchtigen.
-
Zugrundeliegende Speicherleistung – Wenn Dateien nicht schnell genug gelesen werden können (z. B. auf HDD-basierten FAS-Systemen), können zwischengespeicherte Daten verdrängt werden, bevor der Client-Lesevorgang stattfindet, wodurch die Vorteile des sequenziellen Lesens zunichte gemacht werden.
-
Anforderungen an das Zugriffsmuster – Wenn das Lesemuster der Arbeitslast nicht sequenziell ist oder wenn die Dateien in einem Verzeichnis nicht in aufsteigender sequenzieller Reihenfolge benannt sind, bietet der aggressive Lesevorlaufmodus cross_file_sequential_read keine nennenswerten Vorteile.
Leistungsverbesserungen in NFSv4.x
NFS Version 3 gilt seit Jahrzehnten als Goldstandard für NFS-Anwendungen – seit seiner offiziellen Veröffentlichung im Jahr 1995. Die Kombination aus Leistung und Ausfallsicherheit macht einen Wechsel zu neueren NFS-Versionen aus gutem Grund schwierig.
NFSv3 hat jedoch auch seine Grenzen. Die Zustandslosigkeit des Protokolls ist zwar vorteilhaft für die Leistung und minimiert Unterbrechungen bei einem Speicherausfall, aber weniger vorteilhaft für die Datenkonsistenz und das Sperrenmanagement. Ein NFS-Server speichert keine Sperrzustände, daher kann der NFS-Server im Fehlerfall die Sperren freigeben oder auch nicht, und der NFS-Client weiß möglicherweise nicht, ob eine Datei gesperrt ist oder nicht.
Security for NFSv3 is also a bit lacking. The protocol requires multiple open firewall ports to function properly and numeric IDs are sent in plaintext over the wire. Furthermore, NFS does not have robust ACL support, and does not include native file and folder auditing. As a result of these limitations, NFSv4 was created in 2003 via link:https://datatracker.ietf.org/doc/html/rfc3530[RFC-3530^] (obsoleted in 2015 by link:https://datatracker.ietf.org/doc/html/rfc7530[RFC-7530^]). Obwohl NFSv4.x schon seit über 20 Jahren existiert, hat es aus verschiedenen Gründen noch keine breite Akzeptanz gefunden.
-
Komplexität des Identitätsmanagements: In vielen Umgebungen ist keine Namensdienstinfrastruktur vorhanden, um die Namenszeichenfolge und die Kerberos-Sicherheitsanforderungen in NFSv4.x richtig nutzen zu können.
-
Bedarf an neueren NFS-Clients: Dieses Problem ist in modernen NFS-Umgebungen heutzutage weniger dringlich, je weiter wir uns vom ursprünglichen Veröffentlichungsdatum von NFSv4 entfernen. Fast alle aktuell verwendeten Betriebssysteme beinhalten NFS-Clients mit vollständiger NFSv4-Unterstützung, aber es gibt noch ältere Systeme, denen die notwendigen NFSv4.x-Pakete fehlen. Tatsächlich benötigen einige Anwendungen weiterhin ältere NFS-Versionen.
-
Die Mentalität „Was nicht kaputt ist, muss man nicht reparieren“: IT-Organisationen in Unternehmen sind bekanntermaßen sehr konservativ, wenn es um die Einführung neuerer Technologien geht – selbst solcher, die schon seit über 20 Jahren existieren. Und wenn die aktuelle NFS-Version einwandfrei funktioniert, warum ändern?
-
Leistungsbedenken: Die Leistung eines zustandsbehafteten Protokolls wie NFSv4.x blieb in den letzten 20 Jahren weitgehend hinter der des zustandslosen NFSv3 zurück. In der Vergangenheit überwogen die Leistungseinbußen oft die Vorteile von NFSv4.x.
NFSv4.x-Verbesserungen in ONTAP 9.18.1 mit AFX
Einige architektonische Änderungen an ONTAP haben der NFS-Performance im Allgemeinen einen dringend benötigten Schub gegeben und zu einer deutlichen Verbesserung der NFSv4.x-Performance im Allgemeinen beigetragen.
Nachfolgend eine kurze Zusammenfassung einiger dieser Änderungen.
Verbesserung des sequenziellen Lesens: NFSv4.1 30 % besser als NFSv3
ONTAP 9.18.1 führt die Unterstützung für Multipath-IO mit NFSv4.1 ein. Anstatt Lesevorgänge vom WAFL-Dateisystem zu verarbeiten, verlagert MPIO diese in eine Netzwerkdomäne, um sie multipath-sicher zu bedienen. Dieser Ansatz reduziert Kontextwechsel, ermöglicht eine höhere Parallelität im sequenziellen Leseverkehr und verringert den Aufwand für die Pufferverwaltung durch Umgehung von WAFL.
Verbesserung der zufälligen Lesegeschwindigkeit für FlexGroup volumes: NFSv4.1 innerhalb von 7 % von NFSv3
FlexGroup Volumes sind Volumes, die aus mehreren Teilvolumes zusammengesetzt sind und diese als einen einzigen, einheitlichen Namensraum darstellen. In AFX sind bei FlexGroup Volumes die erweiterte Kapazitätsverteilung standardmäßig aktiviert, wodurch Dateien, die größer als 10 GB sind, als Multipart-Dateien auf mehrere Teilvolumes verteilt werden. Aufgrund der räumlichen Trennung dieser Dateiteile war die Leistung bei zufälligen Lesezugriffen mit NFSv4.x traditionell etwas geringer (ca. 18 % weniger als mit NFSv3). ONTAP 9.18.1 führt die Unterstützung für zwischengespeicherte IO bei Multipart-Lesezugriffen mit NFSv4.x ein, um dieses Problem zu beheben. HINWEIS: Diese Änderung betrifft nicht FlexVol Volumes.
Sequenzielles Schreiben: +10 % Verbesserung gegenüber früheren Versionen
Eine Verbesserung der Replikation von NVLOG-Daten, die für die HA-Failover-Funktionalität verwendet werden, steigerte die gesamte sequenzielle Schreibperformance von NetApp AFX-Systemen.
Metadatenoperationen: Innerhalb von 15 % der Leistung von NFSv3 bei EDA-Benchmarks
NFSv4.1 serialisiert traditionell alle OPEN- und CLOSE-Operationen, wobei ein Clusterknoten sie nacheinander verarbeitet, bevor sie vom Netzwerk an WAFL gesendet werden. ONTAP 9.18.1 führt Concurrent Open Close (COC) ein, wodurch die Netzwerkserialisierung durch eine geänderte Behandlung von Race Conditions entfällt, was die in früheren Versionen aufgetretenen OPEN/CLOSE-Engpässe beseitigt.
All diese Änderungen – zusammen mit den in AFX vorgenommenen Architekturänderungen – haben es ermöglicht, die Gesamtleistung von NFSv4.1 in ONTAP 9.18.1 zu verbessern.
Ergebnisse sequenzieller Ein-/Ausgabe
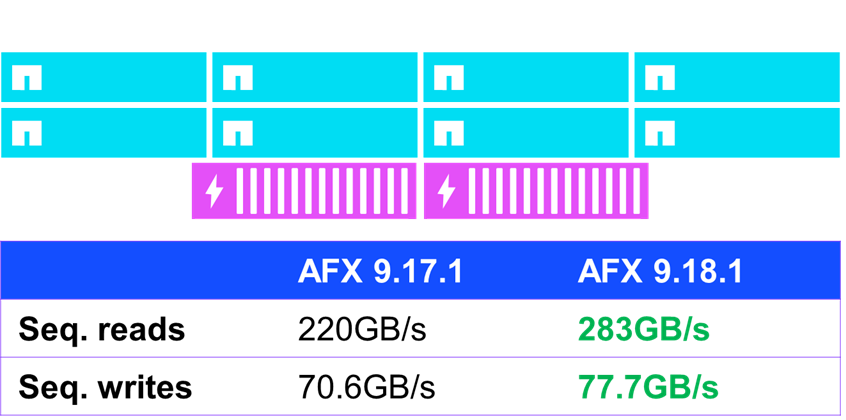
Einer der Bereiche, in denen einige moderate Leistungsverbesserungen festgestellt wurden, war bei sequenzieller IO (d. h. IO, die vorhersehbar ist und nacheinander ausgeführt wird). In Standard-Leistungstests mit fio verbesserte AFX unter ONTAP 9.18.1 die sequenzielle Leseleistung um fast 30 % und die sequenzielle Schreibleistung um 10 %.
NetApp AFX – NFSv4.1 sequenzielle IO-Leistung in ONTAP 9.18.1
Ergebnisse von Arbeitslasten mit hohem Metadatenaufkommen
Noch beeindruckender sind die Verbesserungen bei einem der größten Leistungsengpässe von NFSv4.x – den Metadaten. Dabei handelt es sich um zufällige IOs, üblicherweise im 4K-Bereich, die zur Verwaltung von Dateibesitzern und -attributen, zum Erstellen und Auflisten von Dateien usw. verwendet werden. Aufgrund der Zustandsabhängigkeit von NFSv4.x sind diese Arten von Operationen tendenziell rechenintensiver und latenzbehafteter, was wiederum die insgesamt mögliche Leistung reduziert.
Mit den Änderungen in AFX ONTAP 9.18.1 hat sich die Leistung von NFSv4.x für diese Art von Arbeitslasten erheblich verbessert und die Lücke zur Leistung von NFSv3 (innerhalb von 15%) geschlossen.
Unsere Performance-Engineering-Teams verglichen die Leistung von Standard-Benchmarks für KI-Bild, EDA und Software-Builds und stellten massive Verbesserungen gegenüber der vorherigen ONTAP Version fest.
NetApp AFX – NFSv4.1 Metadaten-IO-Leistung in ONTAP 9.18.1
