

Conmute por error aplicaciones a un sitio remoto con NetApp Disaster Recovery
 Sugerir cambios
Sugerir cambios
En caso de desastre, conmute su sitio local principal de VMware a otro sitio local de VMware o VMware Cloud en AWS. Puede probar el proceso de conmutación por error para garantizar el éxito cuando lo necesite.
Rol de NetApp Console requerido Administrador de organización, Administrador de carpeta o proyecto, Administrador de recuperación ante desastres o Administrador de conmutación por error de recuperación ante desastres.
"Obtenga información sobre los roles y permisos de usuario en NetApp Disaster Recovery". "Obtenga información sobre los roles de acceso a la NetApp Console para todos los servicios".
Acerca de esta tarea
Durante una conmutación por error, Disaster Recovery utiliza de manera predeterminada la copia de instantánea de SnapMirror más reciente, aunque puede seleccionar una instantánea específica de una instantánea de un punto en el tiempo (según la política de retención de SnapMirror). Utilice la opción de punto en el tiempo si las réplicas más recientes están comprometidas, como durante un ataque de ransomware.
Este proceso difiere dependiendo de si el sitio de producción está en buen estado y si está realizando una conmutación por error al sitio de recuperación ante desastres por motivos distintos a una falla crítica de la infraestructura:
-
Falla crítica del sitio de producción donde el vCenter de origen o el clúster ONTAP no son accesibles: NetApp Disaster Recovery le permite seleccionar cualquier instantánea disponible desde la cual restaurar.
-
El entorno de producción está en buen estado: puede "Tomar una instantánea ahora" o seleccionar una instantánea creada previamente.
Este procedimiento rompe la relación de replicación, coloca las máquinas virtuales de origen de vCenter fuera de línea, registra los volúmenes como almacenes de datos en el vCenter de recuperación ante desastres, reinicia las máquinas virtuales protegidas utilizando las reglas de conmutación por error del plan y habilita la lectura/escritura en el sitio de destino.
Probar el proceso de conmutación por error
Antes de iniciar la conmutación por error, puede probar el proceso. La prueba no coloca las máquinas virtuales fuera de línea.
Durante una prueba de conmutación por error, Disaster Recovery crea temporalmente máquinas virtuales. Risaster Recovery asigna un almacén de datos temporal que respalda el volumen FlexClone a los hosts ESXi.
Este proceso no consume capacidad física adicional en el almacenamiento ONTAP local ni en FSx para el almacenamiento ONTAP de NetApp en AWS. El volumen de origen original no se modifica y los trabajos de réplica pueden continuar incluso durante la recuperación ante desastres.
Cuando finalice la prueba, deberá reiniciar las máquinas virtuales con la opción Limpiar prueba. Si bien esto se recomienda, no es obligatorio.
Una operación de conmutación por error de prueba no afecta las cargas de trabajo de producción, la relación SnapMirror utilizada en el sitio de prueba y las cargas de trabajo protegidas que deben seguir funcionando normalmente.
Para una conmutación por error de prueba, Disaster Recovery realiza las siguientes operaciones:
-
Realice comprobaciones previas en el clúster de destino y la relación SnapMirror .
-
Cree un nuevo volumen FlexClone a partir de la instantánea seleccionada para cada volumen ONTAP protegido en el clúster ONTAP del sitio de destino.
-
Si alguno de los almacenes de datos es VMFS, cree y asigne un iGroup a cada LUN.
-
Registre las máquinas virtuales de destino dentro de vCenter como nuevos almacenes de datos.
-
Encienda las máquinas virtuales de destino según el orden de arranque capturado en la página Grupos de recursos.
-
Desactive cualquier aplicación de base de datos compatible en las máquinas virtuales indicadas como "compatibles con la aplicación".
-
Si los clústeres de origen vCenter y ONTAP aún están activos, cree una relación SnapMirror en dirección inversa para replicar cualquier cambio mientras esté en estado de conmutación por error en el sitio de origen original.
-
Iniciar sesión en el "NetApp Console" .
-
Desde el panel de navegación izquierdo de la NetApp Console , seleccione Protección > Recuperación ante desastres.
-
En el menú NetApp Disaster Recovery , seleccione Planes de replicación.
-
Seleccione el plan de replicación.
-
A la derecha, seleccione la opción Acciones*
 y seleccione *Probar conmutación por error.
y seleccione *Probar conmutación por error. -
En la página de Conmutación por error de prueba, ingrese “Conmutación por error de prueba” y seleccione Conmutación por error de prueba.
-
Una vez finalizada la prueba, limpie el entorno de prueba.
Limpiar el entorno de prueba después de una prueba de conmutación por error
Una vez finalizada la prueba de conmutación por error, debe limpiar el entorno de prueba. Este proceso elimina las máquinas virtuales temporales de la ubicación de prueba, los FlexClones y los almacenes de datos temporales.
-
En el menú NetApp Disaster Recovery , seleccione Planes de replicación.
-
Seleccione el plan de replicación.
-
A la derecha, seleccione la opción Acciones
Luego Limpiar prueba de conmutación por error. -
En la página de prueba de conmutación por error, ingrese "Limpiar conmutación por error" y luego seleccione Limpiar prueba de conmutación por error.
Conmutar por error el sitio de origen a un sitio de recuperación ante desastres
En caso de desastre, conmute su sitio local principal de VMware a pedido a otro sitio local de VMware o VMware Cloud en AWS con FSx para NetApp ONTAP.
El proceso de conmutación por error implica las siguientes operaciones:
-
Disaster Recovery realiza comprobaciones previas en el clúster de destino y en la relación SnapMirror .
-
Si seleccionó la última instantánea, se realiza la actualización de SnapMirror para replicar los últimos cambios.
-
Las máquinas virtuales de origen están apagadas.
-
La relación SnapMirror se rompe y el volumen de destino pasa a ser de lectura y escritura.
-
Según la selección de la instantánea, el sistema de archivos activo se restaura a la instantánea especificada (la más reciente o la seleccionada).
-
Los almacenes de datos se crean y se montan en el clúster o host VMware o VMC según la información capturada en el plan de replicación. Si alguno de los almacenes de datos es VMFS, cree y asigne un iGroup a cada LUN.
-
Las máquinas virtuales de destino se registran en vCenter como nuevos almacenes de datos.
-
Las máquinas virtuales de destino se encienden según el orden de arranque capturado en la página Grupos de recursos.
-
Si el vCenter de origen aún está activo, apague todas las máquinas virtuales del lado de origen que se están conmutando por error.
-
Desactive cualquier aplicación de base de datos compatible en las máquinas virtuales indicadas como "compatibles con la aplicación".
-
Si los clústeres de origen vCenter y ONTAP aún están activos, cree una relación SnapMirror en dirección inversa para replicar cualquier cambio mientras se encuentre en estado de conmutación por error en el sitio de origen original. La relación de SnapMirror se invierte de la máquina virtual de destino a la de origen.

|
En el caso de los planes de replicación basados en almacenes de datos, si agregó y descubrió máquinas virtuales pero no proporcionó detalles de mapeo, esas máquinas virtuales se incluyen en la conmutación por error. La conmutación por error fallará con una notificación en los trabajos. Debe proporcionar los detalles de asignación para completar la conmutación por error con éxito. |

|
Una vez iniciada la conmutación por error, podrá ver las máquinas virtuales recuperadas en el vCenter del sitio de recuperación ante desastres (máquinas virtuales, redes y almacenes de datos). De forma predeterminada, las máquinas virtuales se recuperan en la carpeta Carga de trabajo. |
-
En el menú NetApp Disaster Recovery , seleccione Planes de replicación.
-
Seleccione el plan de replicación.
-
A la derecha, seleccione la opción Acciones*
y seleccione *Conmutación por error.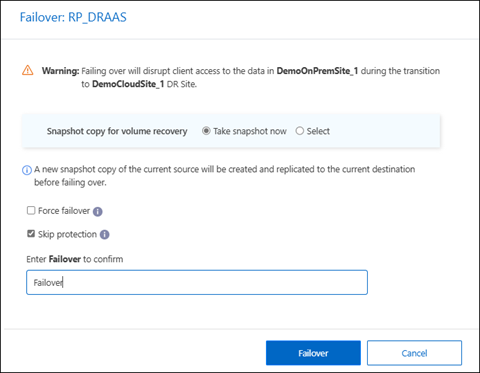
-
En la página Conmutación por error, cree una nueva instantánea ahora o elija una instantánea existente para que el almacén de datos la utilice como base para la recuperación. El valor predeterminado es el más reciente.
Se tomará una instantánea de la fuente actual y se replicará en el destino actual antes de que se produzca la conmutación por error.
-
De manera opcional, seleccione Forzar conmutación por error si desea que la conmutación por error se produzca incluso si se detecta un error que normalmente evitaría que se produzca la conmutación por error.
-
De manera opcional, seleccione Omitir protección si desea que el servicio no cree automáticamente una relación de protección SnapMirror inversa después de una conmutación por error del plan de replicación. Esto es útil si desea realizar operaciones adicionales en el sitio restaurado antes de volver a ponerlo en línea dentro de NetApp Disaster Recovery.
Puede establecer protección inversa seleccionando Proteger recursos en el menú Acciones del plan de replicación. Esto intenta crear una relación de replicación inversa para cada volumen del plan. Puede ejecutar este trabajo repetidamente hasta que se restablezca la protección. Cuando se restablezca la protección, puede iniciar una conmutación por error de la forma habitual. -
Escriba "conmutación por error" en el cuadro.
-
Seleccione Conmutación por error.
-
Para comprobar el progreso, en el menú, seleccione Monitorización de trabajos.