

Preparar el origen y el destino en NetApp Copy and Sync
 Sugerir cambios
Sugerir cambios
Verifique que su origen y sus destinos cumplan con los siguientes requisitos en NetApp Copy and Sync.
Redes
-
El origen y el destino deben tener una conexión de red al grupo de intermediarios de datos.
Por ejemplo, si un servidor NFS está en su centro de datos y un agente de datos está en AWS, entonces necesita una conexión de red (VPN o Conexión directa) desde su red a la VPC.
-
NetApp recomienda configurar el origen, el destino y los intermediarios de datos para utilizar un servicio de Protocolo de tiempo de red (NTP). La diferencia de tiempo entre los tres componentes no debe exceder los 5 minutos.
Directorio de destino
Cuando crea una relación de sincronización, Copiar y sincronizar le permite seleccionar un directorio de destino existente y luego, opcionalmente, crear una nueva carpeta dentro de ese directorio. Así que asegúrese de que su directorio de destino preferido ya exista.
Permisos para leer directorios
Para mostrar cada directorio o carpeta en un origen o destino, Copiar y sincronizar necesita permisos de lectura en el directorio o carpeta.
- Sistema Nacional de Archivos
-
Los permisos deben definirse en el origen/destino con uid/gid en archivos y directorios.
- Almacenamiento de objetos
-
-
Para AWS y Google Cloud, un agente de datos debe tener permisos de objetos de lista (estos permisos se proporcionan de forma predeterminada si sigue los pasos de instalación del agente de datos).
-
Para Azure, StorageGRID e IBM, las credenciales que ingrese al configurar una relación de sincronización deben tener permisos de objeto de lista.
-
- SMB
-
Las credenciales SMB que ingrese al configurar una relación de sincronización deben tener permisos de carpeta de lista.

|
El agente de datos ignora los siguientes directorios de forma predeterminada: .snapshot, ~snapshot, .copy-offload |
|
|
Al copiar datos de SMB en Cloud Volumes ONTAP mediante Copiar y sincronizar, no se conserva la propiedad de los archivos y las carpetas del sistema de origen. Este comportamiento se produce porque Copy and Sync utiliza un cliente SMB de Linux, que asigna propiedad al usuario o a la cuenta de servicio utilizada para autenticar la transferencia. Si bien se pueden conservar las listas de control de acceso, la información de propiedad y auditoría puede diferir del sistema de origen. Este es el comportamiento esperado. |
Requisitos del bucket de Amazon S3
Asegúrese de que su bucket de Amazon S3 cumpla con los siguientes requisitos.
Ubicaciones de agentes de datos compatibles con Amazon S3
Las relaciones de sincronización que incluyen almacenamiento S3 requieren un agente de datos implementado en AWS o en sus instalaciones. En cualquier caso, Copy and Sync le solicitará que asocie el agente de datos con una cuenta de AWS durante la instalación.
Regiones de AWS compatibles
Se admiten todas las regiones excepto la de China.
Permisos necesarios para los buckets S3 en otras cuentas de AWS
Al configurar una relación de sincronización, puede especificar un bucket S3 que resida en una cuenta de AWS que no esté asociada con un agente de datos.
"Los permisos incluidos en este archivo JSON"debe aplicarse a ese bucket S3 para que un agente de datos pueda acceder a él. Estos permisos permiten al agente de datos copiar datos hacia y desde el depósito y enumerar los objetos en el depósito.
Tenga en cuenta lo siguiente sobre los permisos incluidos en el archivo JSON:
-
<BucketName> es el nombre del depósito que reside en la cuenta de AWS que no está asociada con un agente de datos.
-
<RoleARN> debe reemplazarse por uno de los siguientes:
-
Si se instaló manualmente un agente de datos en un host Linux, RoleARN debe ser el ARN del usuario de AWS para el que proporcionó las credenciales de AWS al implementar un agente de datos.
-
Si se implementó un agente de datos en AWS mediante la plantilla CloudFormation, RoleARN debe ser el ARN del rol de IAM creado por la plantilla.
Puede encontrar el ARN del rol yendo a la consola EC2, seleccionando la instancia del agente de datos y luego seleccionando el rol IAM en la pestaña Descripción. Luego debería ver la página Resumen en la consola IAM que contiene el ARN del rol.

-
Requisitos de almacenamiento de blobs de Azure
Asegúrese de que su almacenamiento de blobs de Azure cumpla con los siguientes requisitos.
Ubicaciones de agentes de datos compatibles con Azure Blob
Un agente de datos puede residir en cualquier ubicación cuando una relación de sincronización incluye almacenamiento de blobs de Azure.
Regiones de Azure compatibles
Se admiten todas las regiones, excepto las de China, Gobierno de EE. UU. y Departamento de Defensa de EE. UU.
Cadena de conexión para relaciones que incluyen Azure Blob y NFS/SMB
Al crear una relación de sincronización entre un contenedor de blobs de Azure y un servidor NFS o SMB, debe proporcionar Copiar y sincronizar con la cadena de conexión de la cuenta de almacenamiento:
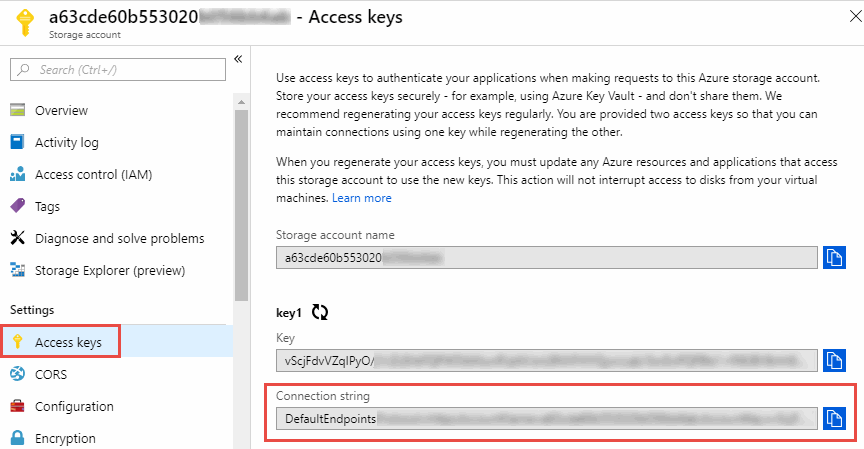
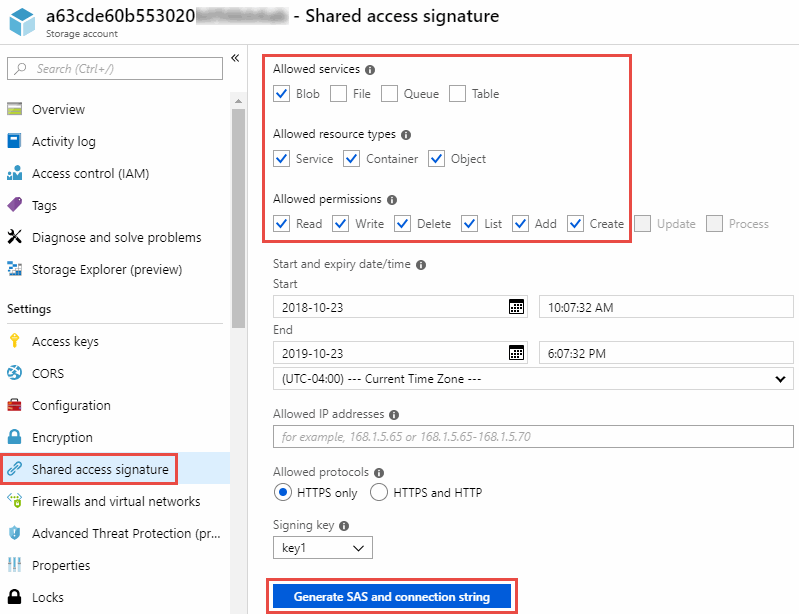
Si desea sincronizar datos entre dos contenedores de blobs de Azure, la cadena de conexión debe incluir un "firma de acceso compartido" (SAS). También tiene la opción de utilizar un SAS al sincronizar entre un contenedor Blob y un servidor NFS o SMB.
El SAS debe permitir el acceso al servicio Blob y a todos los tipos de recursos (servicio, contenedor y objeto). El SAS también debe incluir los siguientes permisos:
-
Para el contenedor Blob de origen: Leer y Listar
-
Para el contenedor Blob de destino: Leer, Escribir, Listar, Agregar y Crear
|
|
Si elige implementar una relación de sincronización continua que incluya un contenedor de blobs de Azure, puede usar una cadena de conexión normal o una cadena de conexión SAS. Si se utiliza una cadena de conexión SAS, no debe configurarse para que caduque en el futuro cercano. |
Almacenamiento de Azure Data Lake Gen2
Al crear una relación de sincronización que incluya Azure Data Lake, debe proporcionar Copiar y sincronizar con la cadena de conexión de la cuenta de almacenamiento. Debe ser una cadena de conexión normal, no una firma de acceso compartido (SAS).
Requisito de Azure NetApp Files
Utilice el nivel de servicio Premium o Ultra cuando sincronice datos hacia o desde Azure NetApp Files. Es posible que experimente fallas y problemas de rendimiento si el nivel de servicio del disco es Estándar.

|
Consulte con un arquitecto de soluciones si necesita ayuda para determinar el nivel de servicio adecuado. El tamaño del volumen y el nivel del volumen determinan el rendimiento que puede obtener. |
Requisitos de la caja
-
Para crear una relación de sincronización que incluya Box, deberá proporcionar las siguientes credenciales:
-
ID de cliente
-
Secreto del cliente
-
Clave privada
-
ID de clave pública
-
Frase de contraseña
-
ID de empresa
-
-
Si crea una relación de sincronización de Amazon S3 a Box, debe utilizar un grupo de agentes de datos que tenga una configuración unificada donde las siguientes configuraciones estén establecidas en 1:
-
Concurrencia del escáner
-
Límite de procesos del escáner
-
Concurrencia del transferente
-
Límite de procesos de transferencia
-
Requisitos del depósito de Google Cloud Storage
Asegúrese de que su depósito de Google Cloud Storage cumpla con los siguientes requisitos.
Ubicaciones de intermediarios de datos compatibles con Google Cloud Storage
Las relaciones de sincronización que incluyen Google Cloud Storage requieren un agente de datos implementado en Google Cloud o en sus instalaciones. Copiar y sincronizar lo guía a través del proceso de instalación del agente de datos cuando crea una relación de sincronización.
Regiones de Google Cloud compatibles
Se admiten todas las regiones.
Permisos para depósitos en otros proyectos de Google Cloud
Al configurar una relación de sincronización, puede elegir entre depósitos de Google Cloud en diferentes proyectos, si proporciona los permisos necesarios a la cuenta de servicio del agente de datos. "Aprenda a configurar la cuenta de servicio" .
Permisos para un destino SnapMirror
Si la fuente de una relación de sincronización es un destino SnapMirror (que es de solo lectura), los permisos de "lectura/lista" son suficientes para sincronizar datos desde la fuente a un destino.
Cómo cifrar un depósito de Google Cloud
Puedes cifrar un depósito de Google Cloud de destino con una clave KMS administrada por el cliente o con la clave predeterminada administrada por Google. Si el depósito ya tiene un cifrado KMS agregado, anulará el cifrado predeterminado administrado por Google.
Para agregar una clave KMS administrada por el cliente, deberá utilizar un agente de datos con la "permisos correctos" , y la clave debe estar en la misma región que el depósito.
Google Drive
Cuando configure una relación de sincronización que incluya Google Drive, deberá proporcionar lo siguiente:
-
La dirección de correo electrónico de un usuario que tiene acceso a la ubicación de Google Drive donde desea sincronizar datos
-
La dirección de correo electrónico de una cuenta de servicio de Google Cloud que tiene permisos para acceder a Google Drive
-
Una clave privada para la cuenta de servicio
Para configurar la cuenta de servicio, siga las instrucciones de la documentación de Google:
Cuando edite el campo Ámbitos de OAuth, ingrese los siguientes ámbitos:
Requisitos del servidor NFS
-
El servidor NFS puede ser un sistema NetApp o un sistema que no sea NetApp .
-
El servidor de archivos debe permitir que un host de agente de datos acceda a las exportaciones a través de los puertos requeridos.
-
111 TCP/UDP
-
2049 TCP/UDP
-
5555 TCP/UDP
-
-
Se admiten las versiones 3, 4.0, 4.1 y 4.2 de NFS.
La versión deseada debe estar habilitada en el servidor.
-
Si desea sincronizar datos NFS desde un sistema ONTAP , asegúrese de que el acceso a la lista de exportación NFS para una SVM esté habilitado (vserver nfs modify -vserver svm_name -showmount enabled).
La configuración predeterminada para showmount está habilitada a partir de ONTAP 9.2.
Requisitos de ONTAP
Si la relación de sincronización incluye Cloud Volumes ONTAP o un clúster ONTAP local y seleccionó NFSv4 o posterior, deberá habilitar las ACL de NFSv4 en el sistema ONTAP . Esto es necesario para copiar las ACL.
Requisitos de almacenamiento de ONTAP S3
Cuando se configura una relación de sincronización que incluye "Almacenamiento ONTAP S3" , deberá proporcionar lo siguiente:
-
La dirección IP del LIF que está conectado a ONTAP S3
-
La clave de acceso y la clave secreta que ONTAP está configurado para usar
Requisitos del servidor SMB
-
El servidor SMB puede ser un sistema NetApp o un sistema que no sea NetApp .
-
Debe proporcionar Copiar y sincronizar con credenciales que tengan permisos en el servidor SMB.
-
Para un servidor SMB de origen, se requieren los siguientes permisos: lista y lectura.
Los miembros del grupo Operadores de respaldo reciben soporte de un servidor SMB de origen.
-
Para un servidor SMB de destino, se requieren los siguientes permisos: lista, lectura y escritura.
-
-
El servidor de archivos debe permitir que un host de agente de datos acceda a las exportaciones a través de los puertos requeridos.
-
139 TCP
-
445 TCP
-
137-138 UDP
-
-
Se admiten las versiones 1.0, 2.0, 2.1, 3.0 y 3.11 de SMB.
-
Otorgue al grupo "Administradores" permisos de "Control total" sobre las carpetas de origen y de destino.
Si no concede este permiso, es posible que el agente de datos no tenga permisos suficientes para obtener las ACL en un archivo o directorio. Si esto ocurre, recibirá el siguiente error: "getxattr error 95"
Limitación de SMB para directorios y archivos ocultos
Una limitación de SMB afecta a los directorios y archivos ocultos al sincronizar datos entre servidores SMB. Si alguno de los directorios o archivos en el servidor SMB de origen se ocultó a través de Windows, el atributo oculto no se copia al servidor SMB de destino.
Comportamiento de sincronización SMB debido a la limitación de no distinguir entre mayúsculas y minúsculas
El protocolo SMB no distingue entre mayúsculas y minúsculas, lo que significa que las letras mayúsculas y minúsculas se tratan como si fueran iguales. Este comportamiento puede generar archivos sobrescritos y errores de copia de directorio, si una relación de sincronización incluye un servidor SMB y ya existen datos en el destino.
Por ejemplo, digamos que hay un archivo llamado "a" en el origen y un archivo llamado "A" en el destino. Cuando Copiar y sincronizar copia el archivo llamado "a" al destino, el archivo "A" se sobrescribe con el archivo "a" del origen.
En el caso de los directorios, digamos que hay un directorio llamado "b" en el origen y un directorio llamado "B" en el destino. Cuando Copy and Sync intenta copiar el directorio llamado "b" al destino, Copy and Sync recibe un error que indica que el directorio ya existe. Como resultado, Copiar y sincronizar siempre falla al copiar el directorio llamado “b”.
La mejor manera de evitar esta limitación es asegurarse de sincronizar los datos en un directorio vacío.