

Validación de la solución: Situaciones validadas
 Sugerir cambios
Sugerir cambios
La solución SM-BC de FlexPod Datacenter protege los servicios de datos para numerosos escenarios de fallo de un único punto, así como para un desastre en el sitio. El diseño redundante implementado en cada sitio proporciona alta disponibilidad, y la implementación de SM-BC con replicación de datos síncrona en sitios protege los servicios de datos de un desastre en todo el sitio de un sitio. La solución puesta en marcha se ha validado para las funciones deseadas y se han utilizado varios escenarios de fallos para los que la solución ha sido diseñada para proteger.
Validación de las funciones de la solución
Se utilizan diversos casos de prueba para verificar las funciones de la solución y simular escenarios de fallo de sitio completos y parciales. Para minimizar la duplicación con las pruebas ya realizadas en las soluciones de centros de datos FlexPod existentes en el programa Cisco Validated Design, este informe se centra en los aspectos relacionados con el SM-BC de la solución. Se incluyen algunas validaciones generales de FlexPod para que los profesionales puedan realizar sus validaciones de implementación.
Para la validación de soluciones, se creó una máquina virtual de Windows 10 por host ESXi en todos los hosts ESXi en ambos sitios. La herramienta Iometer se instaló y se utilizó para generar I/o en dos discos de datos virtuales asignados a partir de los almacenes de datos iSCSI locales compartidos. Los parámetros de carga de trabajo de Iometer configurados eran I/o de 8 KB, 75% de lectura y 50% aleatorio, con 8 comandos de I/o excepcionales para cada disco de datos. En la mayoría de los escenarios de prueba realizados, la continuación de las operaciones de I/o de Iometer sirve como indicador de que el escenario no ha causado una interrupción del servicio de datos.
Dado que SM-BC es fundamental para aplicaciones empresariales como servidores de bases de datos, La instancia de Microsoft SQL Server 2019 en un equipo virtual de Windows Server 2022 también se incluyó como parte de las pruebas para confirmar que la aplicación continúa ejecutándose cuando el almacenamiento de su sitio local no está disponible y el servicio de datos se reanuda en el almacenamiento del centro remoto sin aplicaciones interrupciones.
Prueba de arranque SAN iSCSI del host ESXi
Los hosts ESXi de la solución están configurados para arrancar desde SAN iSCSI. El uso de arranque SAN simplifica la gestión de servidores al sustituir un servidor, ya que el perfil de servicio del servidor puede estar asociado con un nuevo servidor para que arranque sin realizar ningún cambio de configuración adicional.
Además de arrancar un host ESXi ubicado en un sitio desde su LUN de arranque iSCSI local, también se llevaron a cabo pruebas para arrancar el host ESXi cuando la controladora de almacenamiento local está en estado de toma de control o cuando su clúster de almacenamiento local no está completamente disponible. Estos escenarios de validación garantizan que los hosts ESXi estén correctamente configurados por diseño y que puedan arrancar durante un caso de mantenimiento del almacenamiento o de desastre en caso de desastre para la recuperación ante desastres, con el fin de proporcionar continuidad empresarial.
Antes de configurar la relación de grupo de consistencia SM-BC, un LUN iSCSI alojado en un par de alta disponibilidad de controladora de almacenamiento tiene cuatro rutas, dos a través de cada estructura iSCSI, según la implementación de las prácticas recomendadas. Un host se puede llegar a la LUN a través de las dos VLAN/estructuras de iSCSI hasta la controladora que aloja LUN, así como a través del partner de alta disponibilidad de la controladora.
Después de configurar la relación del grupo de consistencia SM-BC y de asignar correctamente las LUN reflejadas a los iniciadores, el número de rutas de la LUN se duplica. Para esta implementación, pasa de tener dos rutas activo/optimizado y dos rutas activo/no optimizadas a tener dos rutas activas/optimizadas y seis rutas activas/no optimizadas.
La siguiente figura muestra las rutas que un host ESXi puede tener para acceder a una LUN, por ejemplo, LUN 0. Como la LUN está conectada al sitio una controladora 01, solo las dos rutas de acceso directamente al LUN a través de dicha controladora están activas/optimizadas y las restantes seis rutas están activas/no optimizadas.
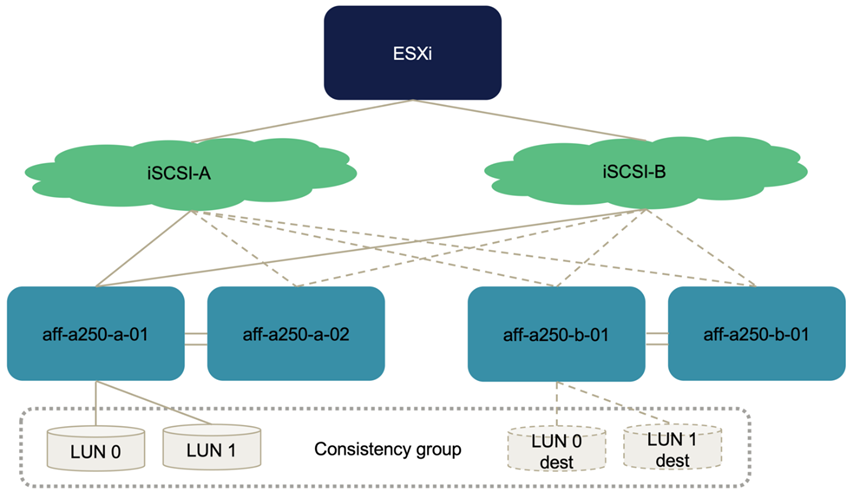
La siguiente captura de pantalla de la información de la ruta del dispositivo de almacenamiento muestra cómo el host ESXi ve los dos tipos de rutas del dispositivo. Las dos rutas activas/optimizadas se muestran como tienen active (I/O) estado de ruta, mientras que las seis rutas activas/no optimizadas sólo se muestran como active. Tenga también en cuenta que la columna destino muestra los dos destinos iSCSI y las respectivas direcciones IP de LIF iSCSI para llegar a los destinos.
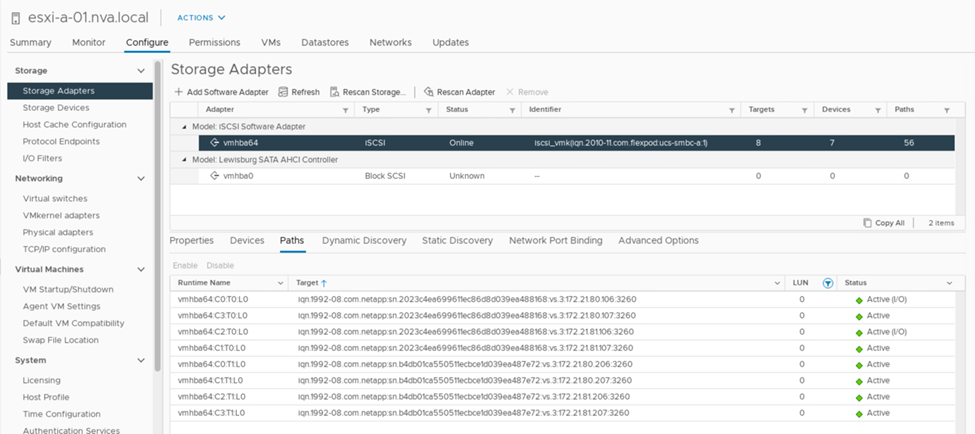
Cuando una de las controladoras de almacenamiento se desactiva para realizar tareas de mantenimiento o actualización, las dos rutas que llegan a la controladora inactivo ya no están disponibles y se muestran con un estado de ruta de dead en su lugar.
Si se produce una conmutación por error del grupo de consistencia en el clúster de almacenamiento principal, ya sea debido a pruebas de conmutación por error manuales o a una conmutación por error automática ante desastres, el clúster de almacenamiento secundario sigue proporcionando servicios de datos para las LUN del grupo de consistencia SM-BC. Dado que las identidades de LUN se conservan y los datos se han replicado de forma síncrona, todos los LUN de arranque de host ESXi protegidos por los grupos de coherencia de SM-BC siguen estando disponibles en el clúster de almacenamiento remoto.
Prueba de afinidad de VMware vMotion y VM/host
Aunque una solución genérica VMware Datacenter de FlexPod admite varios protocolos, como FC, iSCSI, NVMe y NFS, la función de solución FlexPod SM-BC admite los protocolos SAN FC e iSCSI que se suelen utilizar para soluciones vitales para el negocio. Esta validación solo utiliza almacenes de datos basados en protocolo iSCSI y arranque SAN iSCSI.
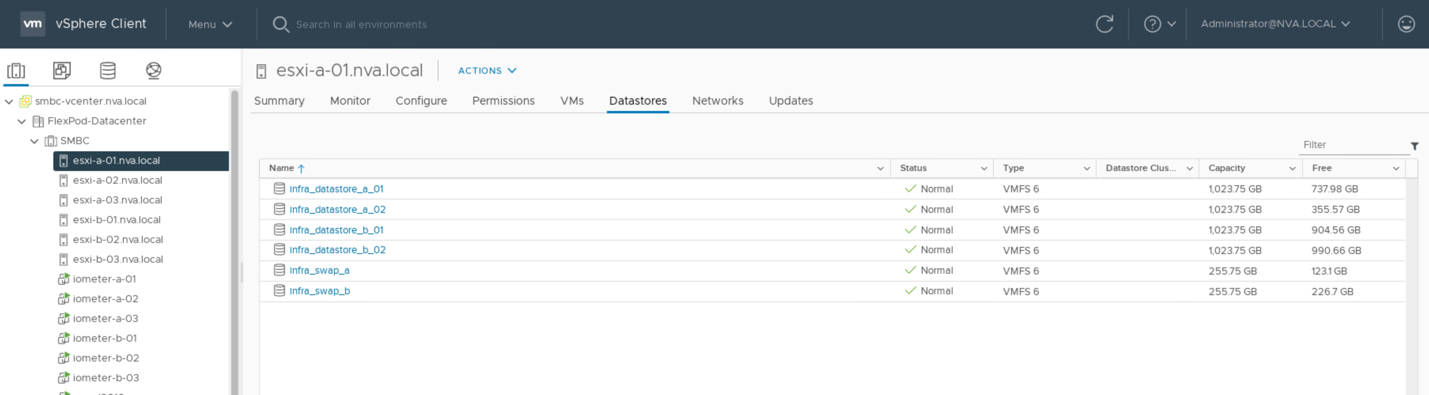
Para que las máquinas virtuales puedan usar servicios de almacenamiento desde un sitio de SM-BC, todos los hosts del clúster deben montar los almacenes de datos iSCSI de ambos sitios para permitir la migración de máquinas virtuales entre los dos sitios y en casos de conmutación por error en caso de desastre.
Para aplicaciones que se ejecuten en la infraestructura virtual que no requieran la protección de grupos de coherencia de SM-BC en todos los sitios, también pueden usarse el protocolo NFS y almacenes de datos NFS. En este caso, se debe prestar especial atención a la hora de asignar almacenamiento a equipos virtuales para que las aplicaciones vitales para el negocio utilicen correctamente los almacenes de datos SAN protegidos por el grupo de consistencia SM-BC para proporcionar continuidad empresarial.
La siguiente captura de pantalla muestra que los hosts están configurados para montar almacenes de datos iSCSI de ambos sitios.
Existe la opción de migrar discos de máquinas virtuales entre almacenes de datos iSCSI disponibles de ambos sitios, como se muestra en la siguiente figura. Por cuestiones de rendimiento, es óptimo disponer de máquinas virtuales que utilicen almacenamiento de su clúster de almacenamiento local para reducir las latencias de I/o de disco. Esto es especialmente cierto cuando los dos sitios están ubicados a ciertas distancias separadas debido a la latencia de distancia física de ida y vuelta de aproximadamente 1 ms por 100 km de distancia.
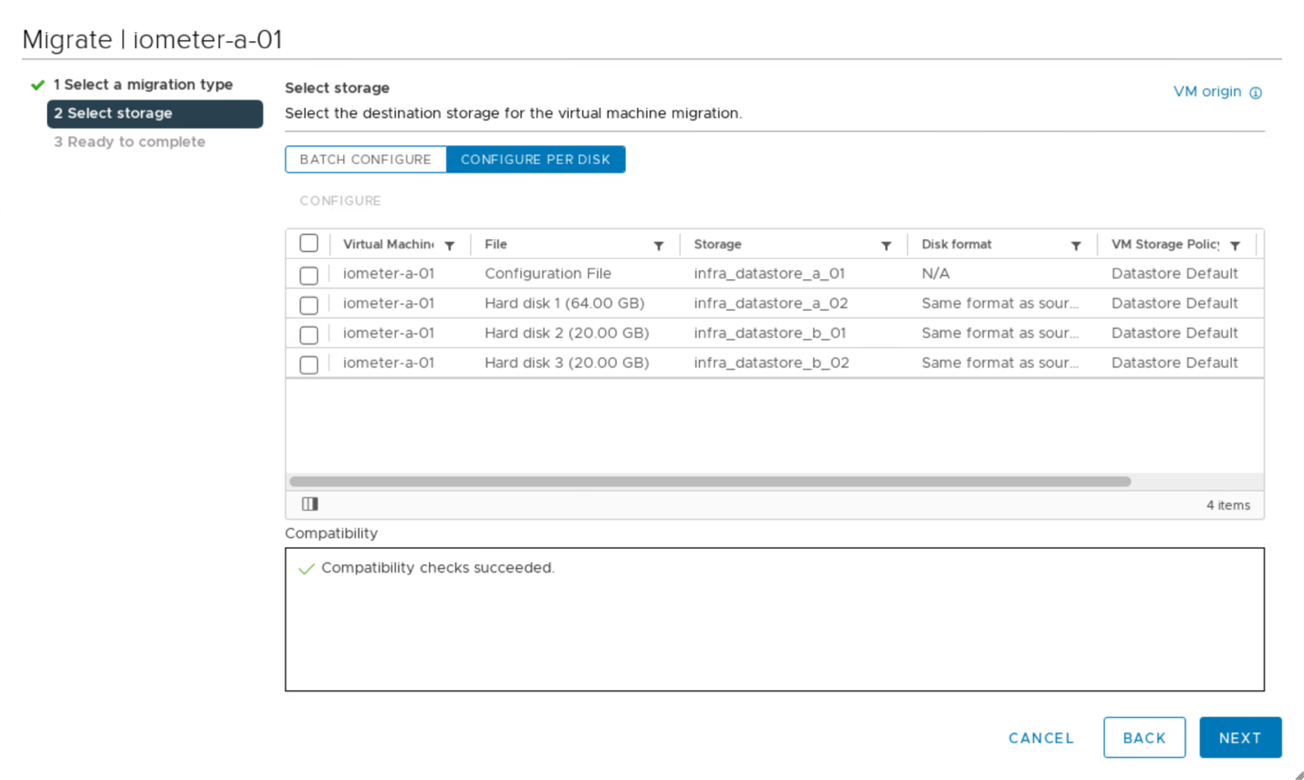
Se llevaron a cabo pruebas de vMotion de máquinas virtuales en un diferente host en el mismo sitio, así como en varios sitios, que se realizaron con éxito. Después de migrar manualmente una máquina virtual entre sitios, la regla de afinidad VM/Host activa y migra la máquina virtual de nuevo al grupo al que pertenece bajo la condición normal.
Recuperación tras fallos planificada de almacenamiento
Las operaciones planificadas de conmutación por error del almacenamiento se deben realizar en la solución después de la configuración inicial para determinar si la solución funciona correctamente después de la conmutación por error del almacenamiento. Las pruebas pueden ayudar a identificar cualquier problema de conectividad o configuración que pueda provocar interrupciones de I/O. Probar y solucionar con regularidad cualquier problema de conectividad o configuración ayuda a proporcionar servicios de datos sin interrupciones cuando se produce un desastre en el sitio real. La conmutación por error planificada de almacenamiento también se puede utilizar antes de llevar a cabo una actividad de mantenimiento de almacenamiento programada, de modo que los servicios de datos puedan ofrecerse del sitio no afectado.
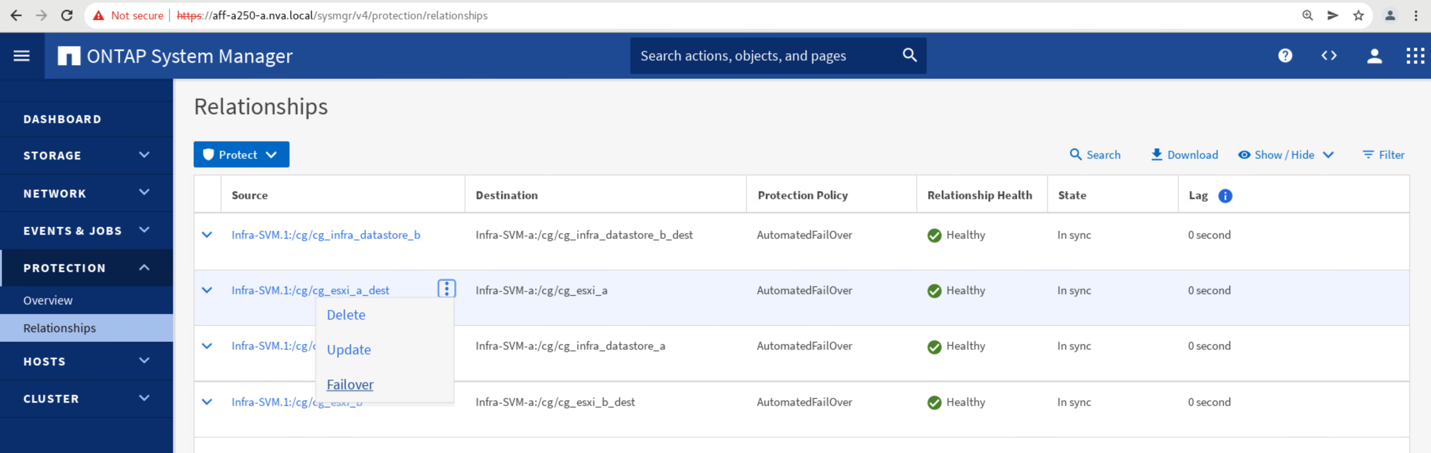
Para iniciar una conmutación por error manual del sitio A los servicios de datos de almacenamiento en el sitio B, puede usar el Administrador del sistema ONTAP del sitio B para realizar la acción.
-
Vaya a la pantalla Protection > Relationships para confirmar que el estado de la relación del grupo de coherencia es
In Sync. Si todavía está en elSynchronizingestado, espere a que el estado se conviertaIn Syncantes de realizar una conmutación al respaldo. -
Expanda los puntos junto al nombre del origen y haga clic en conmutación por error.
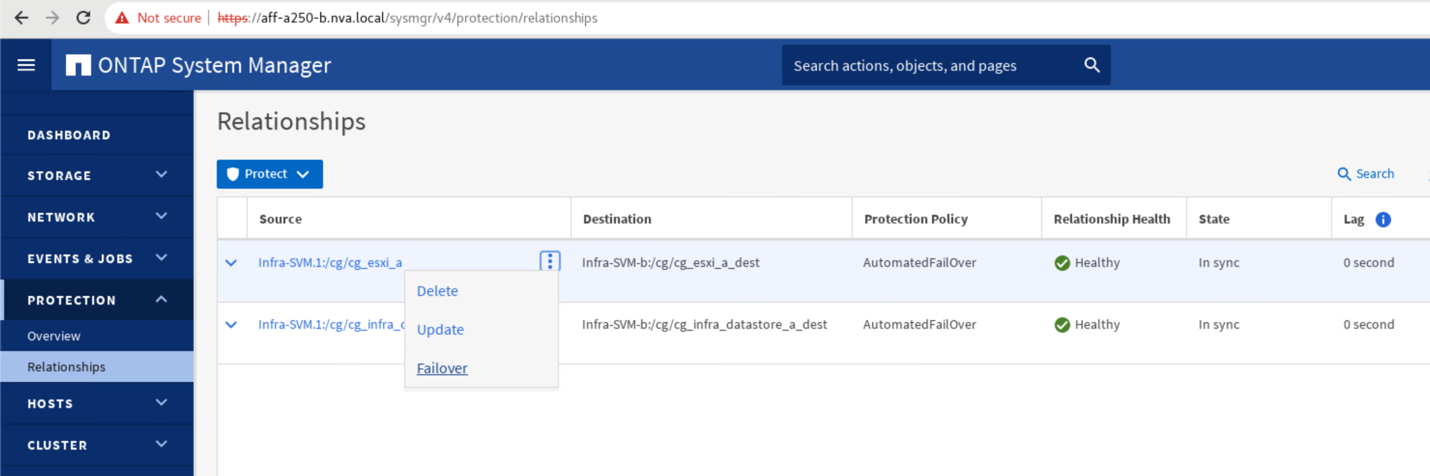
-
Confirme la conmutación por error para el inicio de la acción.
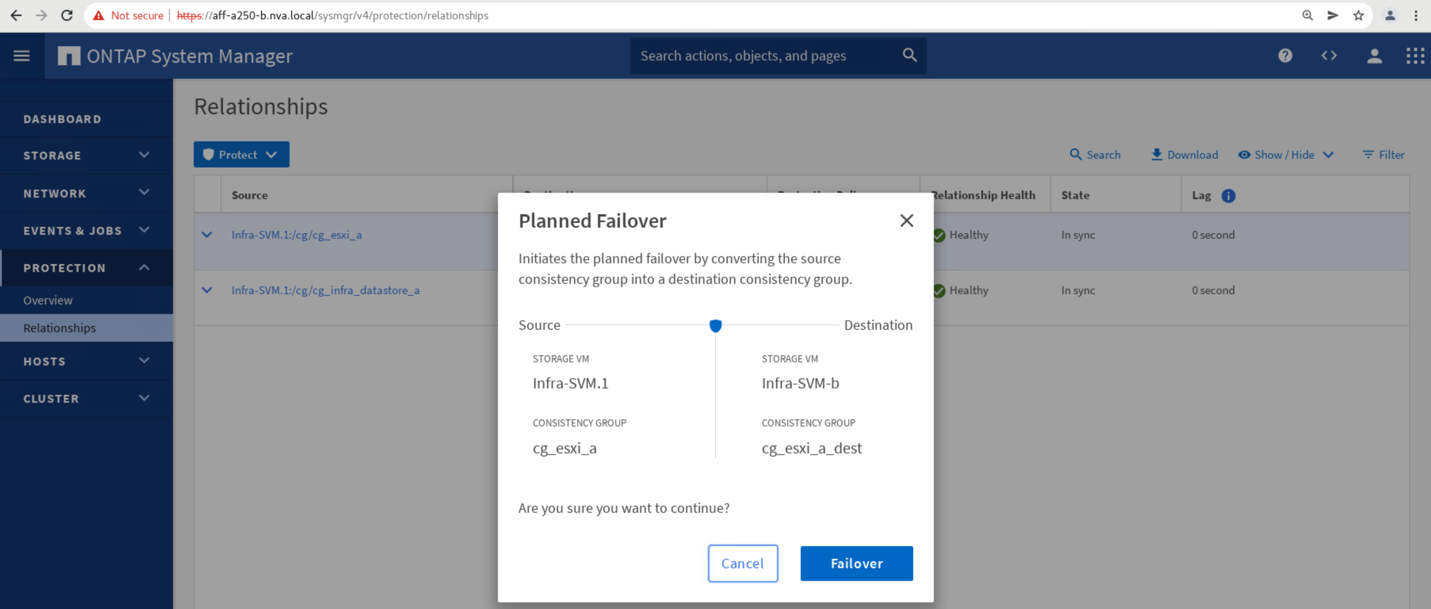
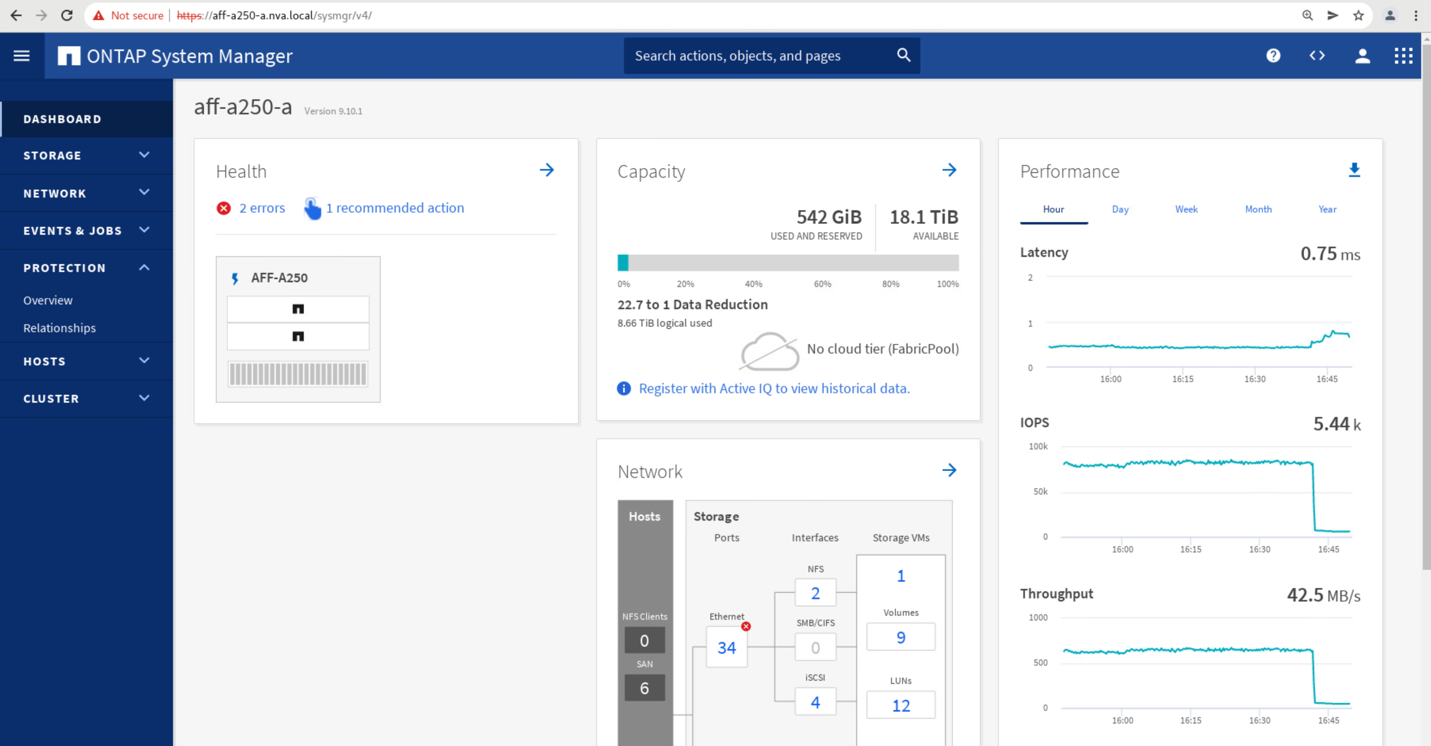
Poco después de iniciar la conmutación por error de los dos grupos de consistencia, cg_esxi_a y.. cg_infra_datastore_a, En la GUI del Administrador del sistema del sitio B, el sitio a E/S que sirve a esos dos grupos de consistencia movidos al sitio B. Como resultado, la actividad de I/o del sitio se reduce significativamente como se muestra en El panel de rendimiento De System Manager Del sitio.
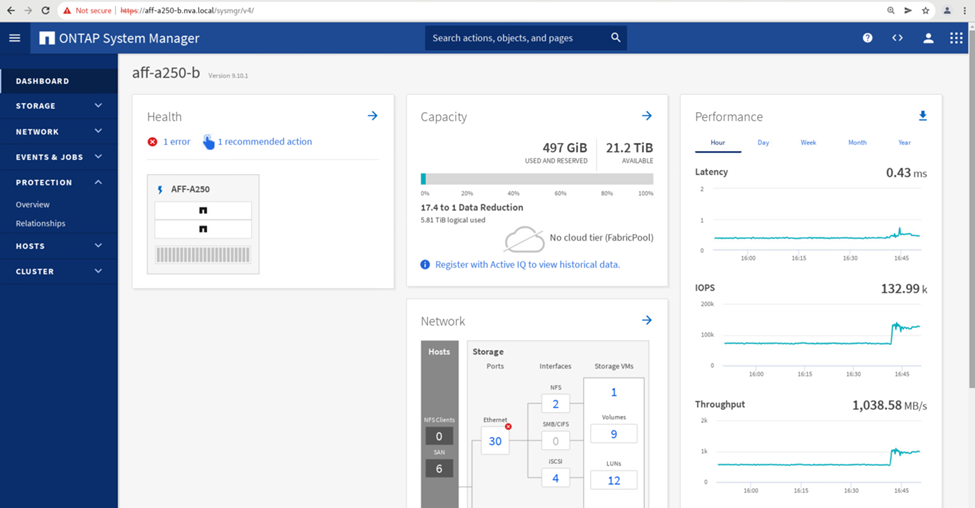
Por otro lado, el panel rendimiento de la consola del administrador del sistema del sitio B muestra un aumento significativo en IOPS, debido al servicio de I/o adicional trasladado desde la instalación A, a aproximadamente 130.000 IOPS, Y llegó a un rendimiento de aproximadamente 1 GB/s, a la vez que mantiene una latencia de I/o inferior a 1 milésima de segundo.
Con la migración transparente de las operaciones De I/o del sitio A al sitio B, ahora es posible desconectar las controladoras De almacenamiento para tareas de mantenimiento programadas. Una vez que se hayan completado el trabajo de mantenimiento o las pruebas y el sitio en el que se cree un clúster de almacenamiento en un backup y en funcionamiento, compruebe y espere a que el estado de protección del grupo de consistencia vuelva a cambiar a. In sync Antes de realizar una conmutación al nodo de respaldo para devolver las operaciones de I/o de conmutación al nodo de respaldo del sitio B al sitio A. Tenga en cuenta que cuanto más tiempo se tarda un sitio en realizarse tareas de mantenimiento o prueba, más tiempo se tarda en sincronizar los datos y el grupo de consistencia se vuelve a la In sync estado.
Recuperación no planificada tras fallos de almacenamiento
Se puede producir una conmutación al nodo de respaldo no planificada del almacenamiento cuando se produce un desastre real o durante una simulación de desastre. Por ejemplo, consulte la siguiente figura en la que el sistema de almacenamiento del sitio A experimenta una interrupción del suministro eléctrico, se activa una conmutación por error del almacenamiento no planificada y los servicios de datos de las LUN del sitio A, que están protegidas por las relaciones de SM-BC, continúan en el sitio B.
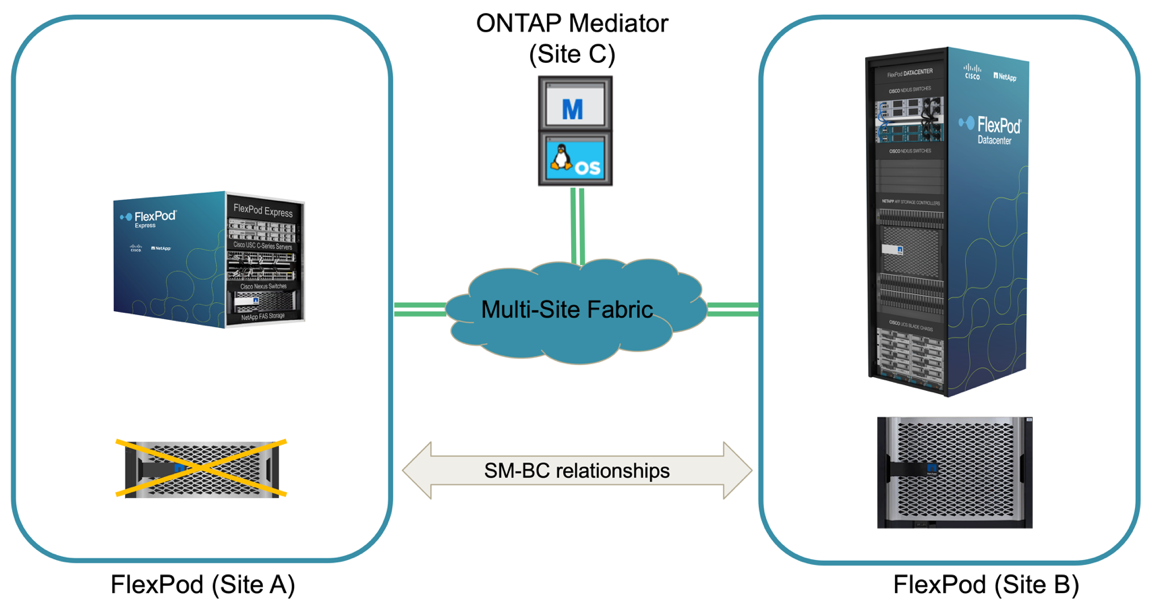
Para simular un desastre de almacenamiento en el centro A, ambas controladoras de almacenamiento en el sitio A pueden apagarse físicamente el switch de alimentación para interrumpir el suministro de alimentación de las controladoras, o mediante el uso del comando de administración de energía del sistema del procesador de servicio de la controladora de almacenamiento para apagar las controladoras.
Cuando el clúster de almacenamiento del centro a pierde potencia, hay una parada repentina de los servicios de datos proporcionados por el sitio Un clúster de almacenamiento. Posteriormente, el Mediator de ONTAP, que supervisa la solución SM-BC desde un tercer sitio, detecta el sitio una condición De fallo de almacenamiento y permite que la solución SM-BC realice una conmutación por error automatizada no planificada. Esto permite que las controladoras de almacenamiento del sitio B continúen los servicios de datos para las LUN configuradas en las relaciones del grupo de consistencia de SM-BC con el sitio A.
Desde la perspectiva de la aplicación, los servicios de datos se hacen una pausa brevemente mientras el sistema operativo comprueba el estado de la ruta de las LUN y, a continuación, reanuda las operaciones de I/o de las rutas disponibles a las controladoras de almacenamiento del sitio B supervivientes.
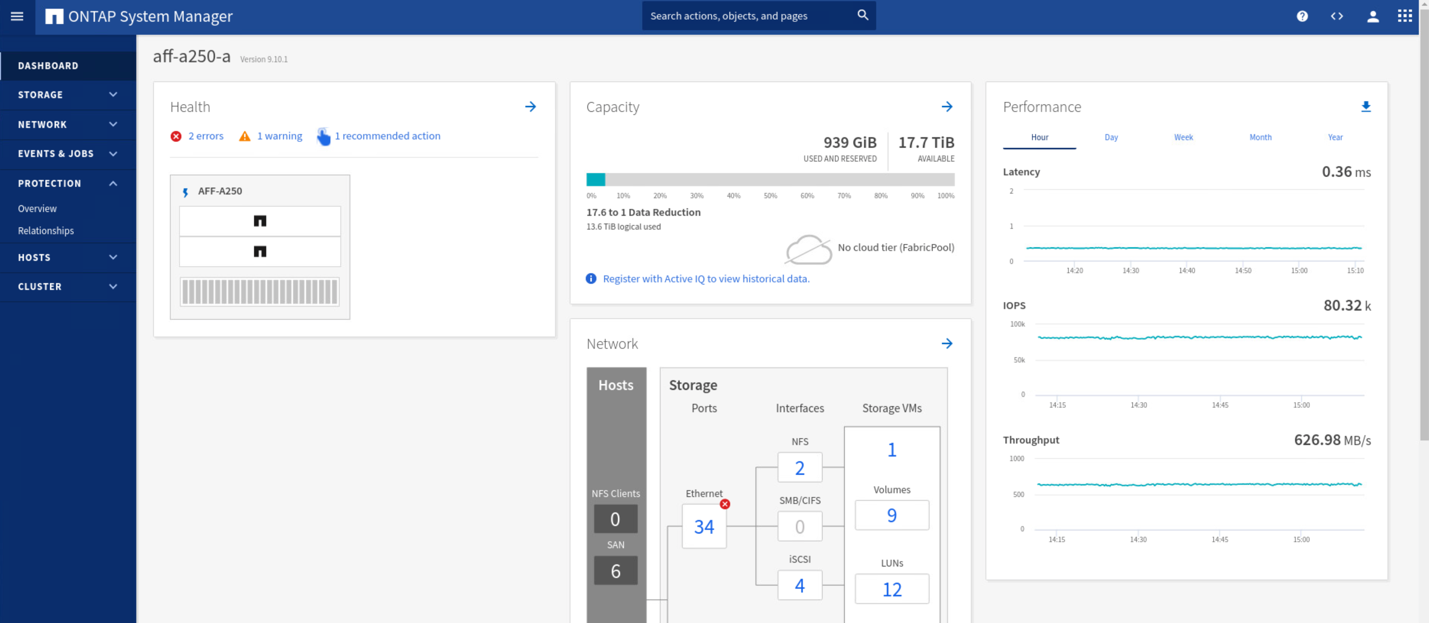
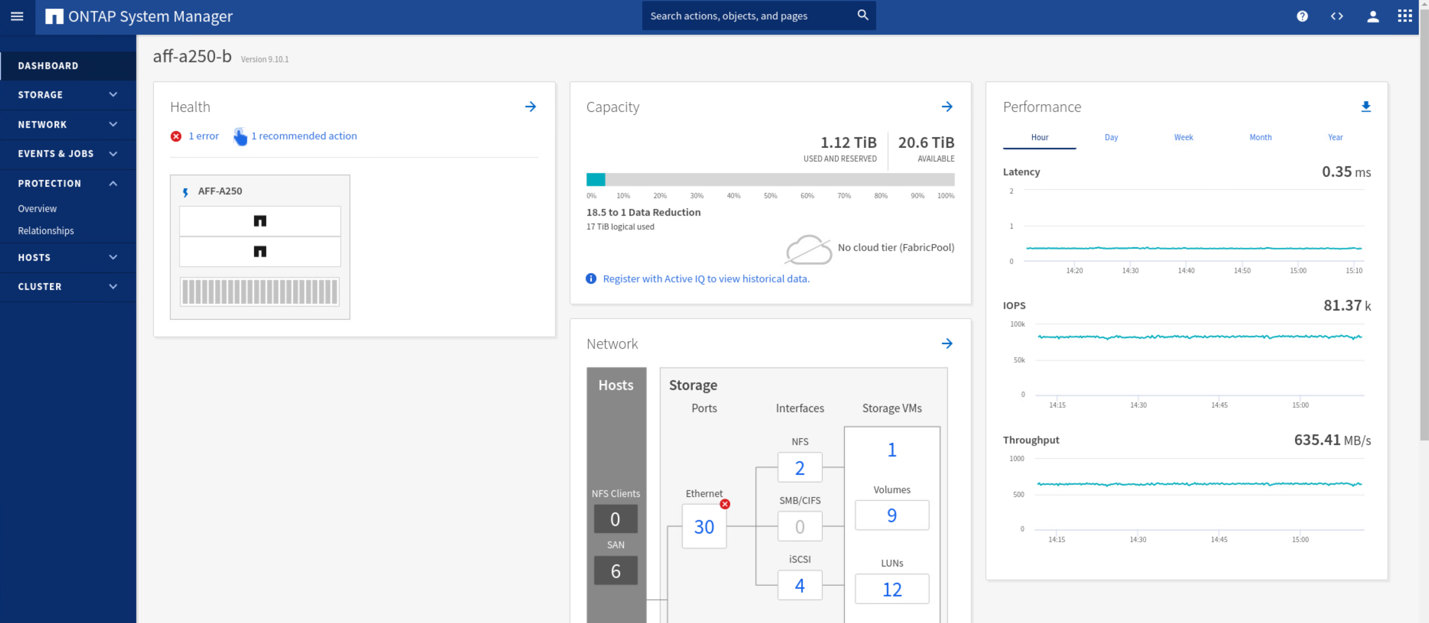
Durante las pruebas de validación, la herramienta de Iometer en los equipos virtuales de ambos sitios genera I/o en sus almacenes de datos locales. Una vez apagado El sitio a un clúster, las operaciones de I/o se pausaron brevemente y, a continuación, se reanudaron. Consulte las dos figuras siguientes para ver los paneles del clúster de almacenamiento en el sitio A y el sitio B respectivamente antes del desastre, que muestran unos 80 000 IOPS y un rendimiento de 600 MB/s en cada centro.
Tras apagar las controladoras de almacenamiento en el sitio A, podemos validar visualmente que las I/o de la controladora de almacenamiento del sitio B aumentaron enormemente para ofrecer servicios de datos adicionales en nombre del sitio A (consulte la siguiente figura). Además, la interfaz gráfica de usuario de los equipos virtuales de Iometer también mostró que la I/o continúa a pesar de la interrupción del servicio en el clúster De almacenamiento del sitio. Tenga en cuenta que si hay otros almacenes de datos respaldados por LUN no protegidos mediante relaciones SM-BC, dichos almacenes de datos ya no serán accesibles cuando se produzca un desastre de almacenamiento. Por lo tanto, es importante evaluar las necesidades empresariales de los distintos datos de aplicaciones y colocarlos correctamente en almacenes de datos que estén protegidos por relaciones de SM-BC para proporcionar continuidad de negocio.
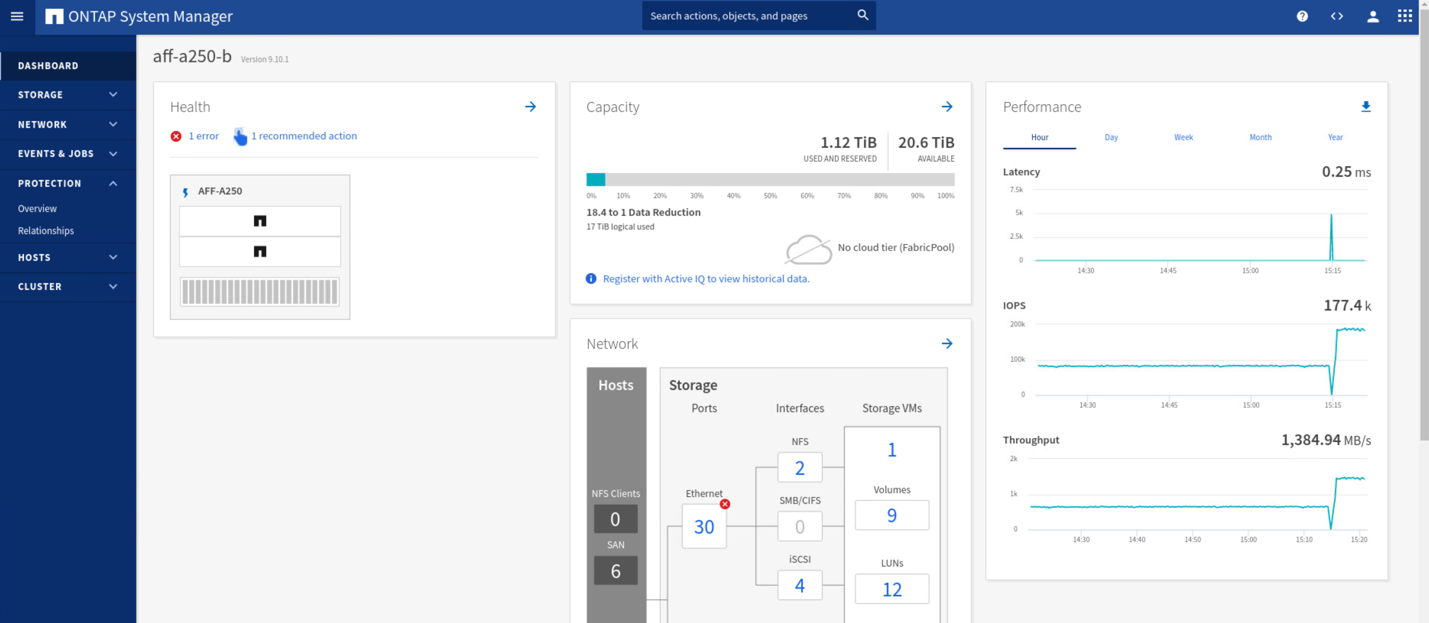
Mientras el sitio un clúster está inactivo, se muestran las relaciones de los grupos coherentes Out of sync estado como se muestra en la siguiente figura. Una vez que se vuelve a encender la alimentación de las controladoras de almacenamiento en el sitio A, el clúster de almacenamiento se arranca y la sincronización de datos entre el sitio A y el sitio B se produce de forma automática.
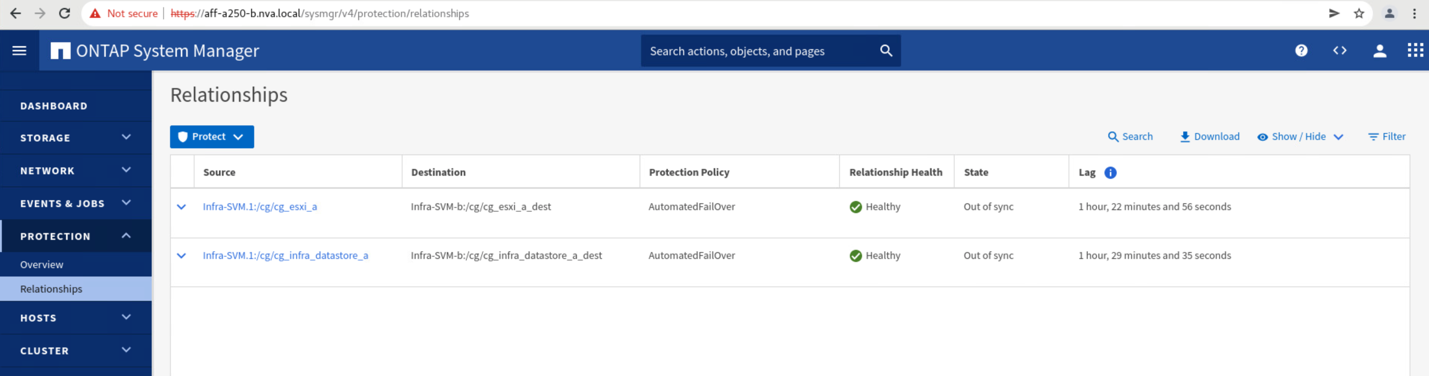
Antes de devolver los servicios de datos del sitio B al sitio A, debe comprobar el sitio a con System Manager y asegurarse de que las relaciones de SM-BC se han vuelto a sincronizar y que el estado ha vuelto a estar sincronizado. Después de confirmar que los grupos de consistencia están sincronizados, se puede iniciar una operación manual de conmutación por error para devolver los servicios de datos en las relaciones del grupo de consistencia de nuevo al sitio A.
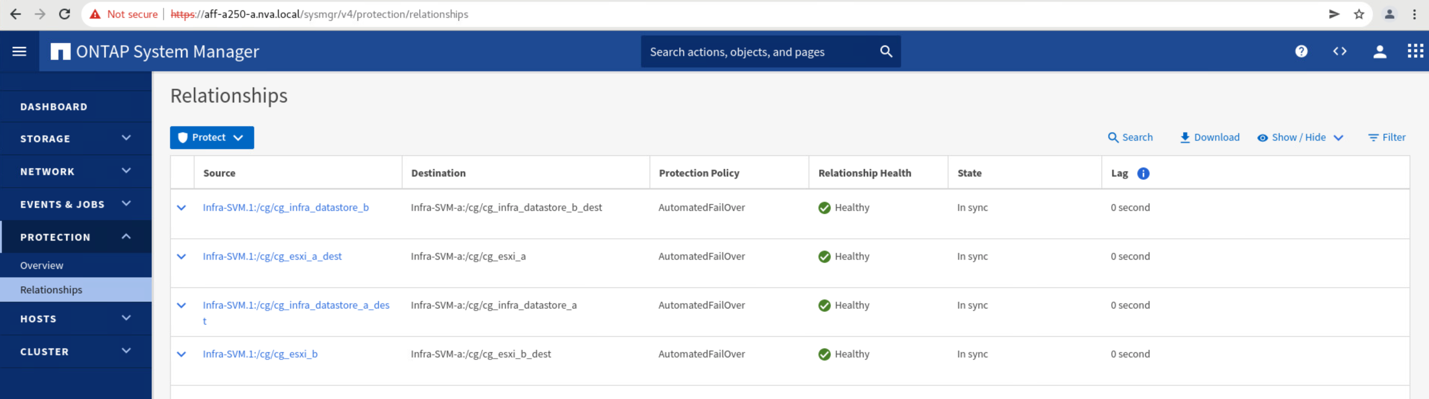
Mantenimiento de sitio completo o errores en el sitio
Un sitio podría necesitar mantenimiento del sitio, experimentar pérdida de energía, o podría ser afectado por un desastre natural como un huracán o un terremoto. Por lo tanto, es crucial que ejercite escenarios de fallos del sitio planificados y no planificados para ayudar a garantizar que su solución FlexPod SM-BC esté correctamente configurada para sobrevivir a estos fallos en todas sus aplicaciones y servicios de datos vitales para el negocio. Se validaron los siguientes escenarios relacionados con el sitio.
-
Escenario de mantenimiento planificado del sitio mediante la migración de máquinas virtuales y servicios de datos críticos al otro sitio
-
Escenario de interrupción del sitio no planificado apagando servidores y controladoras de almacenamiento para simulación de desastre
Para conseguir que un sitio esté listo para realizar un mantenimiento programado, se necesita una combinación de máquinas virtuales afectadas migradas fuera del sitio con vMotion y una recuperación manual tras fallos de las relaciones de grupos de consistencia de SM-BC para migrar máquinas virtuales y servicios de datos críticos al sitio alternativo. La prueba se realizó en dos pedidos diferentes: VMotion primero seguido de conmutación por error de SM-BC y conmutación por error de SM-BC primero seguido de vMotion, para confirmar que las máquinas virtuales siguen ejecutándose y que los servicios de datos no se interrumpen.
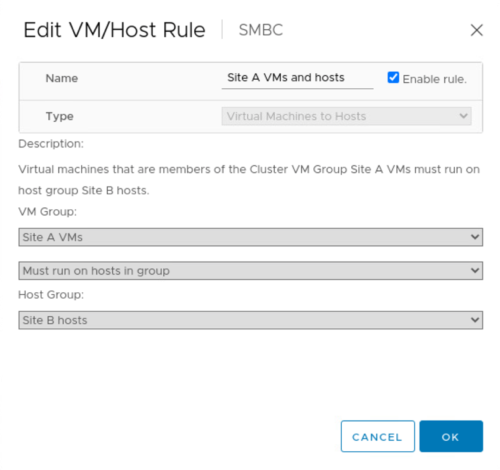
Antes de realizar la migración planificada, actualice la regla de afinidad de equipo virtual/host para que los equipos virtuales que se ejecutan actualmente en el sitio se migren automáticamente fuera del sitio que está experimentando mantenimiento. La siguiente captura de pantalla muestra un ejemplo de cómo modificar el sitio una regla de afinidad de VM/host para que los equipos virtuales migren de la instalación A al sitio B automáticamente. En lugar de especificar que los equipos virtuales ahora deben ejecutarse en el centro B, también puede optar por deshabilitar la regla de afinidad temporalmente para que los equipos virtuales se puedan migrar manualmente.
Después de migrar las máquinas virtuales y los servicios de almacenamiento, puede apagar los servidores, las controladoras de almacenamiento, las bandejas de discos y los switches, y realizar las actividades de mantenimiento del sitio que necesite. Cuando se completa el mantenimiento del sitio y se devuelve la instancia de FlexPod, se puede cambiar la afinidad del grupo de hosts para que los equipos virtuales regresen a su sitio original. Después, debe cambiar la regla de afinidad del sitio VM/host “debe ejecutarse en los hosts del grupo” a “debería ejecutarse en los hosts del grupo”, de modo que se permita que las máquinas virtuales se ejecuten en los hosts del otro sitio en caso de que ocurra un desastre. Para las pruebas de validación, todas las máquinas virtuales se migraron correctamente al otro sitio y los servicios de datos continuaron sin problemas después de realizar una conmutación por error para las relaciones de SM-BC.
Para la simulación imprevista de desastres del sitio, los servidores y las controladoras de almacenamiento se apagaron para simular un desastre en el sitio. La función de alta disponibilidad de VMware detecta las máquinas virtuales caídos y reinicia esas máquinas virtuales en el sitio superviviente. Además, el Mediador de ONTAP que se ejecuta en un tercer sitio detecta el fallo del sitio y el sitio superviviente inicia una conmutación por error y comienza a proporcionar servicios de datos para el centro según lo esperado.
La siguiente captura de pantalla muestra que la CLI del procesador de servicio de los controladores de almacenamiento se utilizó para apagar el sitio un clúster de forma abrupta para simular un desastre de almacenamiento en el sitio.
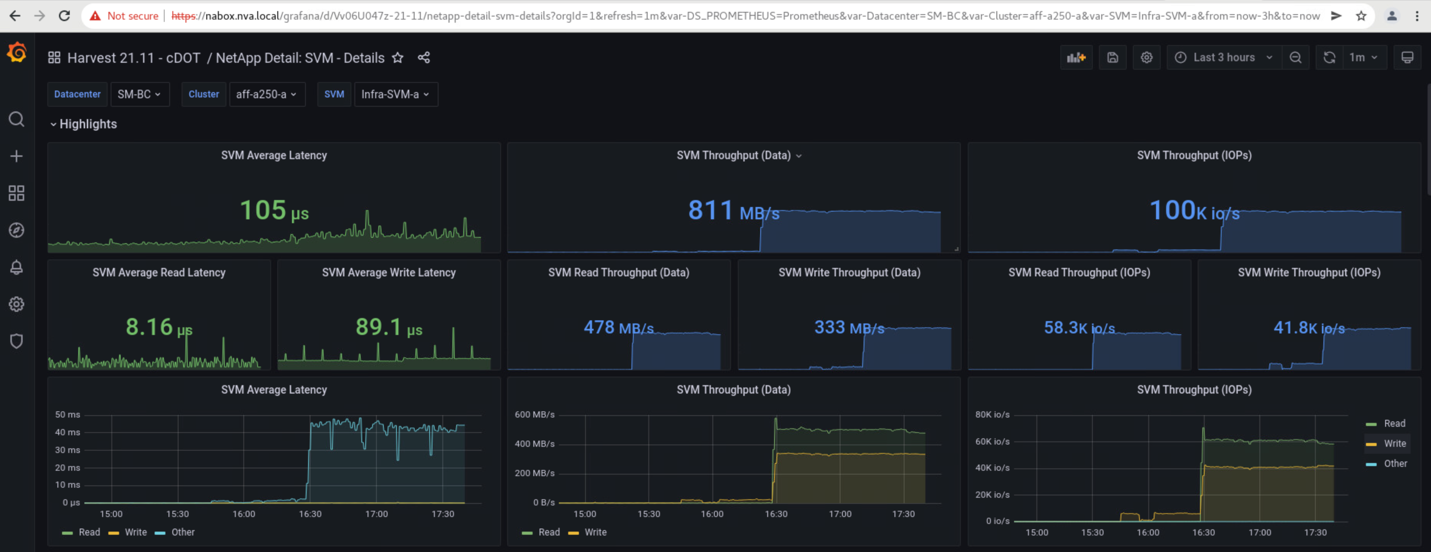
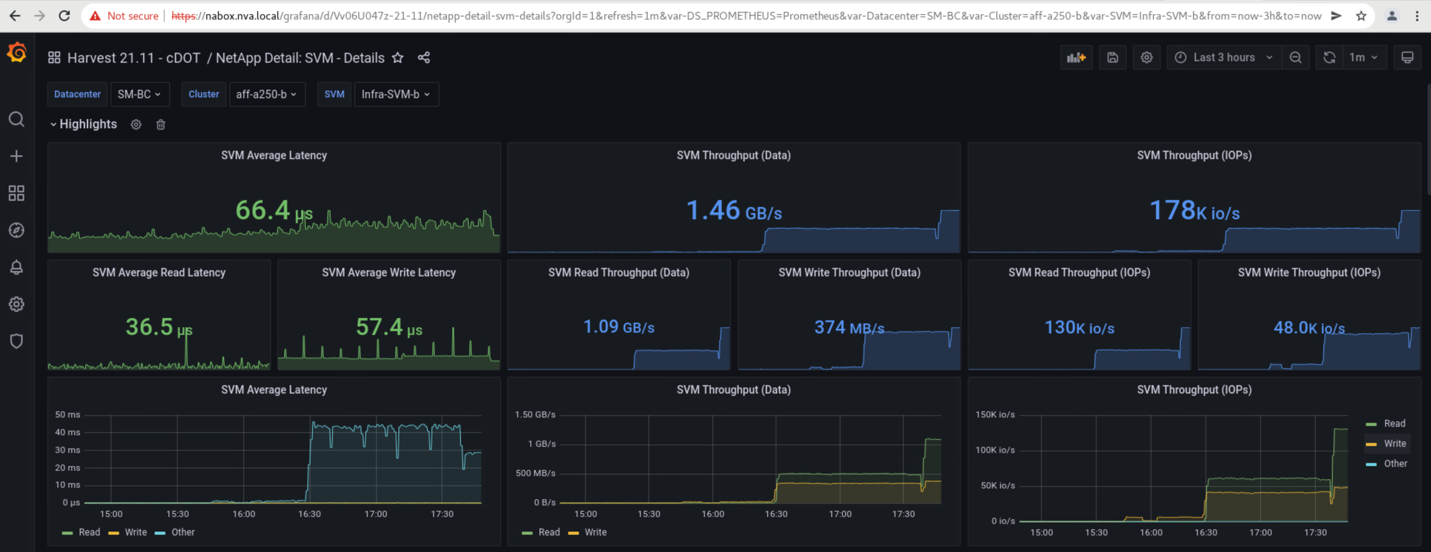
Los paneles de la máquina virtual de almacenamiento de los clústeres de almacenamiento tal y como capturan la herramienta de recogida de datos Harvest de NetApp y se muestran en la consola de Grafana en la herramienta de supervisión de NAbox se muestran en las dos capturas de pantalla siguientes. Como se puede observar en el lado derecho de los gráficos de IOPS y rendimiento, el clúster del sitio B elige Al clúster Una carga de trabajo de almacenamiento inmediatamente después de que el sitio un clúster deja de funcionar.
Microsoft SQL Server
Microsoft SQL Server es una plataforma de bases de datos ampliamente adoptada e implementada para LOS departamentos DE TI de las empresas. La versión de Microsoft SQL Server 2019 aporta muchas características y mejoras nuevas a sus motores relacionales y analíticos. Admite cargas de trabajo con aplicaciones que se ejecutan en las instalaciones, en el cloud y en entornos híbridos usando una combinación de ambos. Además, se puede poner en marcha en múltiples plataformas, como Windows, Linux y contenedores.
Como parte de la validación de carga de trabajo crítica para el negocio de la solución FlexPod SM-BC, se incluye Microsoft SQL Server 2019 instalado en un equipo virtual de Windows Server 2022 junto con los equipos virtuales de Iometer para pruebas de conmutación al nodo de respaldo del almacenamiento planificadas y no planificadas de SM-BC. En el equipo virtual de Windows Server 2022, SQL Server Management Studio está instalado para administrar SQL Server. Para realizar pruebas, se utiliza la herramienta de base de datos HammerDB para generar transacciones de base de datos.
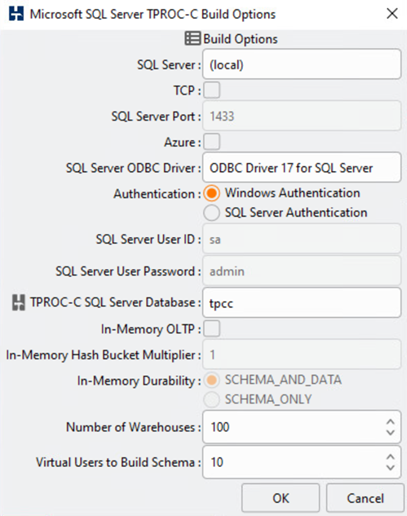
La herramienta de pruebas de bases de datos de HammerDB se configuró para pruebas con la carga de trabajo TPROC-C de Microsoft SQL Server. Para las configuraciones de creación de esquemas, las opciones se actualizaron para utilizar 100 almacenes con 10 usuarios virtuales, como se muestra en la siguiente captura de pantalla.
Después de actualizar las opciones de creación de esquemas, se inició el proceso de creación de esquemas. Unos minutos más tarde, se introdujo un fallo imprevisto del clúster de almacenamiento del centro B simulado apagando ambos nodos del clúster de almacenamiento A250 de AFF de dos nodos aproximadamente al mismo tiempo mediante los comandos de CLI del procesador del sistema.
Tras una breve pausa de las transacciones de la base de datos, se pateó la conmutación por error automatizada para la corrección de desastre y se reanudaron las transacciones. La siguiente captura de pantalla muestra la captura de pantalla del contador de transacciones de HammerDB en ese momento. Como la base de datos de Microsoft SQL Server normalmente se encuentra en el clúster de almacenamiento del sitio B, la transacción se pausó brevemente cuando el almacenamiento del centro B se interrumpió y, a continuación, se reanudó una vez realizada la conmutación automática al respaldo.
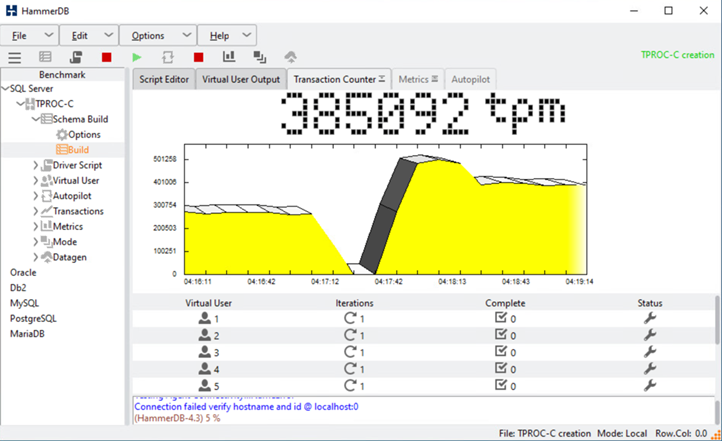
Las medidas del clúster de almacenamiento se obtuvieron utilizando la herramienta NAbox con la herramienta de supervisión Harvest de NetApp instalada. Los resultados se muestran en los paneles predefinidos de Grafana para la máquina virtual de almacenamiento y otros objetos de almacenamiento. El panel proporciona metricas para latencia, rendimiento, IOPS y detalles adicionales con estadísticas de lectura y escritura separadas para el sitio B y el sitio A.
Esta captura de pantalla muestra la consola de rendimiento de NAbox Grafana para el clúster de almacenamiento del sitio B.
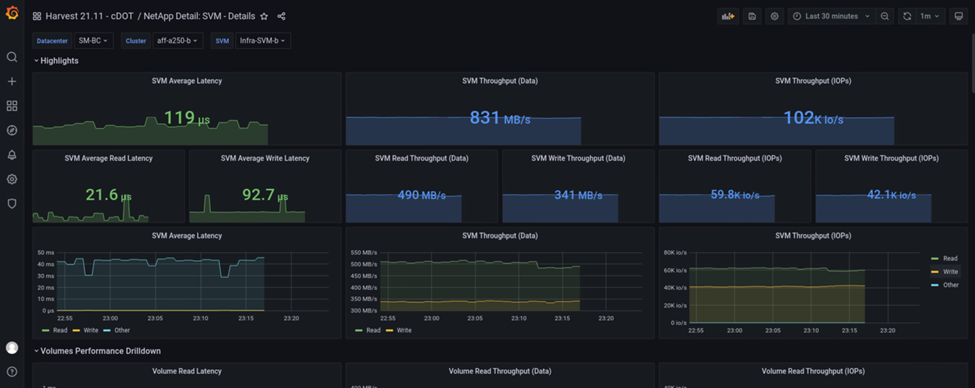
La tasa de IOPS del clúster de almacenamiento del sitio B era de aproximadamente 100 000 IOPS antes de que se introdujera el desastre. Luego, las métricas de rendimiento mostraron una caída brusca de cero en el lado derecho de los gráficos debido al desastre. Dado que el cluster de almacenamiento del sitio B estaba inactivo, no se pudo recopilar nada del cluster del sitio B después de que se introdujera el desastre.
Por otro lado, la tasa de IOPS del sitio que un clúster de almacenamiento recogió las cargas de trabajo adicionales del sitio B después de la conmutación automática al respaldo. La carga de trabajo adicional se puede ver con facilidad en el lado derecho de los gráficos IOPS y rendimiento de la siguiente captura de pantalla, que muestra la consola de rendimiento de NAbox Grafana para ubicar Un clúster de almacenamiento.
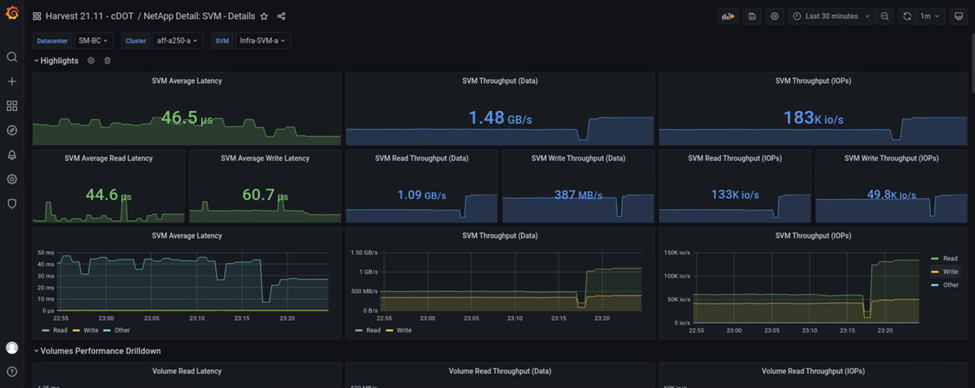
El supuesto de prueba de desastre de almacenamiento anterior confirmó que la carga de trabajo de Microsoft SQL Server puede sobrevivir a una interrupción completa del clúster de almacenamiento en el sitio B donde reside la base de datos. La aplicación utilizaba con transparencia los servicios de datos proporcionados por el sitio, un clúster de almacenamiento después de detectar el desastre y de producirse la conmutación por error.
En la capa informática, cuando las máquinas virtuales que se ejecutan en un sitio determinado sufren un fallo del host, las máquinas virtuales están diseñadas para reiniciarse automáticamente con la función de alta disponibilidad de VMware. Para que se produzca una interrupción completa de la tecnología del centro, las reglas de afinidad de VM/host permiten reiniciar los equipos virtuales en el sitio superviviente. Sin embargo, para que una aplicación vital para el negocio proporcione servicios sin interrupciones, se necesita clustering basado en aplicaciones como Microsoft Failover Cluster o la arquitectura de aplicaciones basadas en contenedores de Kubernetes para evitar tiempos de inactividad de las aplicaciones. Consulte el documento pertinente para la implementación de la agrupación en clústeres basada en aplicaciones, que está más allá del alcance de este informe técnico.