

Caso de uso 4: Protección de datos y conectividad multicloud
 Sugerir cambios
Sugerir cambios
Este caso de uso es relevante para un socio de servicios en la nube encargado de brindar conectividad multicloud para los datos de análisis de big data de los clientes.
Guión
En este escenario, los datos de IoT recibidos en AWS desde diferentes fuentes se almacenan en una ubicación central en NPS. El almacenamiento NPS está conectado a clústeres Spark/Hadoop ubicados en AWS y Azure, lo que permite que las aplicaciones de análisis de big data que se ejecutan en múltiples nubes accedan a los mismos datos.
Requisitos y desafíos
Los principales requisitos y desafíos para este caso de uso incluyen:
-
Los clientes quieren ejecutar trabajos de análisis en los mismos datos utilizando múltiples nubes.
-
Los datos deben recibirse de diferentes fuentes, como las instalaciones locales y la nube, a través de diferentes sensores y concentradores.
-
La solución debe ser eficiente y rentable.
-
El principal desafío es construir una solución rentable y eficiente que brinde servicios de análisis híbridos entre las instalaciones locales y en diferentes nubes.
Solución
Esta imagen ilustra la solución de protección de datos y conectividad multicloud.
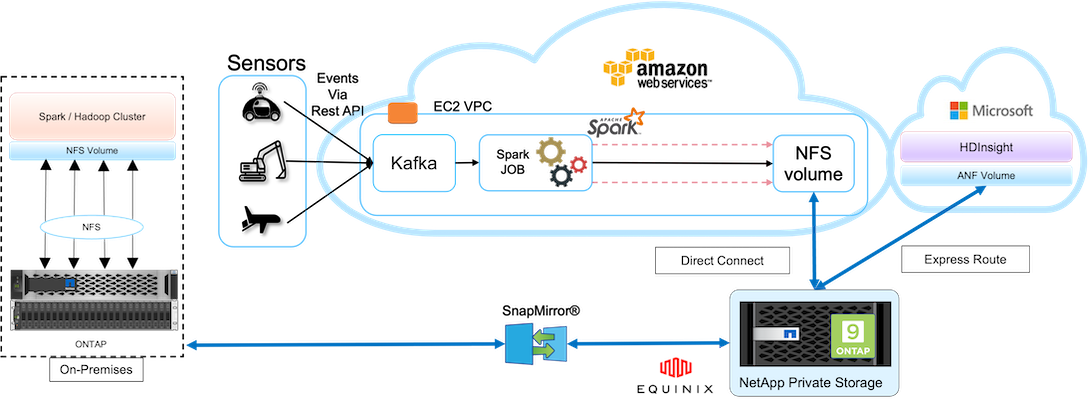
Como se muestra en la figura anterior, los datos de los sensores se transmiten y se incorporan al clúster de AWS Spark a través de Kafka. Los datos se almacenan en un recurso compartido NFS que reside en NPS, que se encuentra fuera del proveedor de la nube dentro de un centro de datos de Equinix. Dado que NetApp NPS está conectado a Amazon AWS y Microsoft Azure a través de conexiones Direct Connect y Express Route, respectivamente, los clientes pueden acceder a los datos NFS desde los clústeres de análisis de Amazon y AWS. Este enfoque resuelve el problema de tener análisis en la nube en múltiples hiperescaladores.
En consecuencia, debido a que tanto el almacenamiento local como el NPS ejecutan el software ONTAP , SnapMirror puede reflejar los datos de NPS en el clúster local, lo que proporciona análisis de nube híbrida en las instalaciones locales y en múltiples nubes.
Para obtener el mejor rendimiento, NetApp generalmente recomienda utilizar múltiples interfaces de red y conexiones directas/exprés para acceder a los datos desde las instancias de la nube.