

Arquitectura de Splunk
 Sugerir cambios
Sugerir cambios
Esta sección describe la arquitectura de Splunk, incluidas las definiciones clave, las implementaciones distribuidas de Splunk, Splunk SmartStore, el flujo de datos, los requisitos de hardware y software, los requisitos de sitios únicos y múltiples, etc.
Definiciones clave
Las siguientes dos tablas enumeran los componentes de Splunk y NetApp utilizados en la implementación distribuida de Splunk.
Esta tabla enumera los componentes de hardware de Splunk para la configuración distribuida de Splunk Enterprise.
| Componente de Splunk | Tarea |
|---|---|
Indexador |
Repositorio de datos de Splunk Enterprise |
Reenvío universal |
Responsable de ingerir datos y enviarlos a los indexadores. |
Cabezal de búsqueda |
La interfaz de usuario utilizada para buscar datos en los indexadores |
Maestro del clúster |
Administra la instalación de indexadores y cabezales de búsqueda de Splunk |
Consola de monitoreo |
Herramienta de monitoreo centralizada utilizada en toda la implementación |
Maestro de licencias |
El administrador de licencias gestiona las licencias de Splunk Enterprise |
Servidor de implementación |
Actualiza las configuraciones y distribuye aplicaciones al componente de procesamiento |
Componente de almacenamiento |
Tarea |
AFF de NetApp |
Almacenamiento totalmente flash utilizado para administrar datos de nivel activo. También conocido como almacenamiento local. |
StorageGRID en NetApp |
Almacenamiento de objetos S3 utilizado para administrar datos de nivel cálido. SmartStore lo utiliza para mover datos entre el nivel caliente y el nivel templado. También conocido como almacenamiento remoto. |
Esta tabla enumera los componentes de la arquitectura de almacenamiento de Splunk.
| Componente de Splunk | Tarea | Componente responsable |
|---|---|---|
Tienda inteligente |
Proporciona a los indexadores la capacidad de organizar datos en niveles desde el almacenamiento local hasta el almacenamiento de objetos. |
Splunk |
Caliente |
El lugar de aterrizaje donde los reenvíos universales colocan los datos recién escritos. El almacenamiento se puede escribir y los datos se pueden buscar. Este nivel de datos normalmente está compuesto por SSD o discos duros rápidos. |
ONTAP |
Administrador de caché |
Administra el caché local de datos indexados, recupera datos confidenciales del almacenamiento remoto cuando se realiza una búsqueda y expulsa del caché los datos menos utilizados. |
Tienda inteligente |
Cálido |
Los datos se transfieren de manera lógica al depósito y se renombran primero al nivel cálido desde el nivel caliente. Los datos dentro de este nivel están protegidos y, al igual que el nivel activo, pueden estar compuestos por SSD o HDD de mayor capacidad. Se admiten copias de seguridad incrementales y completas mediante soluciones de protección de datos comunes. |
StorageGRID |
Implementaciones distribuidas de Splunk
Para dar soporte a entornos más grandes en los que los datos se originan en muchas máquinas, es necesario procesar grandes volúmenes de datos. Si muchos usuarios necesitan buscar datos, puede escalar la implementación distribuyendo instancias de Splunk Enterprise en varias máquinas. Esto se conoce como una implementación distribuida.
En una implementación distribuida típica, cada instancia de Splunk Enterprise realiza una tarea especializada y reside en uno de los tres niveles de procesamiento correspondientes a las funciones de procesamiento principales.
La siguiente tabla enumera los niveles de procesamiento de Splunk Enterprise.
| Nivel | Componente | Descripción |
|---|---|---|
Entrada de datos |
Promotor |
Un reenvío consume datos y luego los reenvía a un grupo de indexadores. |
Indexación |
Indexador |
Un indexador indexa los datos entrantes que normalmente recibe de un grupo de reenvíos. El indexador transforma los datos en eventos y almacena los eventos en un índice. El indexador también busca los datos indexados en respuesta a las solicitudes de búsqueda de un cabezal de búsqueda. |
Gestión de búsquedas |
Cabezal de búsqueda |
Un cabezal de búsqueda sirve como recurso central para la búsqueda. Los cabezales de búsqueda de un clúster son intercambiables y tienen acceso a las mismas búsquedas, paneles, objetos de conocimiento, etc., desde cualquier miembro del clúster de cabezales de búsqueda. |
En la siguiente tabla se enumeran los componentes importantes que se utilizan en un entorno distribuido de Splunk Enterprise.
| Componente | Descripción | Responsabilidad |
|---|---|---|
Maestro del clúster de índices |
Coordina actividades y actualizaciones de un clúster de indexadores |
Gestión de índices |
Clúster de índices |
Grupo de indexadores de Splunk Enterprise que están configurados para replicar datos entre sí |
Indexación |
Desplegador de cabezal de búsqueda |
Maneja la implementación y las actualizaciones del maestro del clúster. |
Gestión de cabezales de búsqueda |
Grupo de búsqueda de cabezas |
Grupo de cabezales de búsqueda que sirve como recurso central para la búsqueda |
Gestión de búsquedas |
Balanceadores de carga |
Lo utilizan los componentes agrupados para gestionar la creciente demanda de los cabezales de búsqueda, los indexadores y el destino S3 para distribuir la carga entre los componentes agrupados. |
Gestión de carga para componentes agrupados |
Vea los siguientes beneficios de las implementaciones distribuidas de Splunk Enterprise:
-
Acceder a fuentes de datos diversas o dispersas
-
Proporcionar funcionalidad para gestionar las necesidades de datos de empresas de cualquier tamaño y complejidad.
-
Logre alta disponibilidad y garantice la recuperación ante desastres con replicación de datos e implementación en múltiples sitios
Tienda inteligente de Splunk
SmartStore es una capacidad de indexación que permite que los almacenes de objetos remotos, como Amazon S3, almacenen datos indexados. A medida que aumenta el volumen de datos de una implementación, la demanda de almacenamiento generalmente supera la demanda de recursos computacionales. SmartStore le permite administrar su almacenamiento de indexador y sus recursos computacionales de manera rentable al escalar esos recursos por separado.
SmartStore presenta un nivel de almacenamiento remoto y un administrador de caché. Estas características permiten que los datos residan localmente en indexadores o en el nivel de almacenamiento remoto. El administrador de caché administra el movimiento de datos entre el indexador y el nivel de almacenamiento remoto, que está configurado en el indexador.
Con SmartStore, puede reducir el espacio de almacenamiento del indexador al mínimo y elegir recursos informáticos optimizados para E/S. La mayoría de los datos residen en el almacenamiento remoto. El indexador mantiene un caché local que contiene una cantidad mínima de datos: buckets activos, copias de buckets cálidos que participan en búsquedas activas o recientes y metadatos de buckets.
Flujo de datos de Splunk SmartStore
Cuando los datos provenientes de varias fuentes llegan a los indexadores, estos se indexan y se guardan localmente en un contenedor activo. El indexador también replica los datos del contenedor activo en los indexadores de destino. Hasta ahora, el flujo de datos es idéntico al flujo de datos de los índices que no son SmartStore.
Cuando el cubo caliente se calienta demasiado, el flujo de datos diverge. El indexador de origen copia el depósito cálido en el almacén de objetos remoto (nivel de almacenamiento remoto) mientras deja la copia existente en su caché, porque las búsquedas tienden a ejecutarse en datos indexados recientemente. Sin embargo, los indexadores de destino eliminan sus copias porque el almacén remoto proporciona alta disponibilidad sin mantener múltiples copias locales. La copia maestra del depósito ahora reside en el almacén remoto.
La siguiente imagen muestra el flujo de datos de Splunk SmartStore.
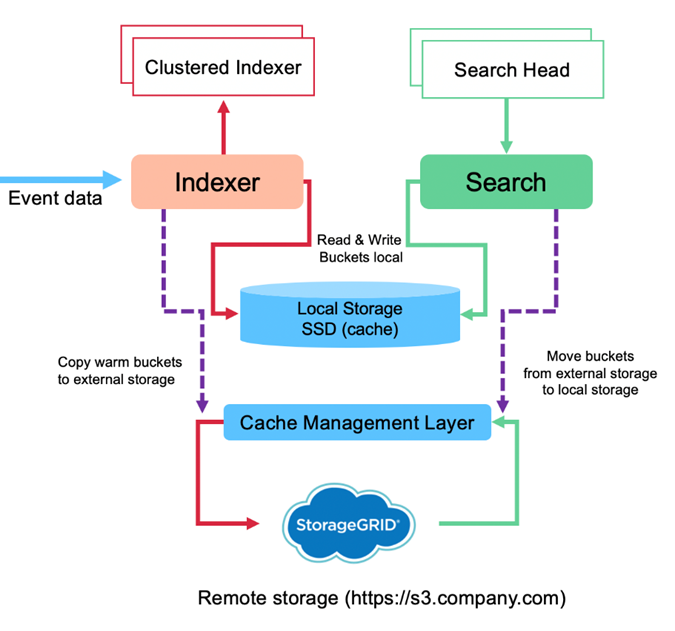
El administrador de caché del indexador es fundamental para el flujo de datos de SmartStore. Obtiene copias de depósitos del almacén remoto según sea necesario para manejar solicitudes de búsqueda. También expulsa del caché copias de los buckets más antiguas o menos buscadas, porque la probabilidad de que participen en búsquedas disminuye con el tiempo.
El trabajo del administrador de caché es optimizar el uso del caché disponible y garantizar que las búsquedas tengan acceso inmediato a los segmentos que necesitan.
Requisitos de software
La siguiente tabla enumera los componentes de software necesarios para implementar la solución. Los componentes de software que se utilizan en cualquier implementación de la solución pueden variar según los requisitos del cliente.
| Familia de productos | Nombre del producto | Versión del producto | Sistema operativo |
|---|---|---|---|
StorageGRID en NetApp |
Almacenamiento de objetos StorageGRID |
11,6 |
n / A |
CentOS |
CentOS |
8,1 |
CentOS 7.x |
Splunk Enterprise |
Splunk Enterprise con SmartStore |
8.0.3 |
CentOS 7.x |
Requisitos de un solo sitio y de varios sitios
En un entorno de Splunk empresarial (implementaciones medianas y grandes) donde los datos se originan en muchas máquinas y donde muchos usuarios necesitan buscar los datos, puede escalar su implementación distribuyendo instancias de Splunk Enterprise en sitios únicos y múltiples.
Vea los siguientes beneficios de las implementaciones distribuidas de Splunk Enterprise:
-
Acceder a fuentes de datos diversas o dispersas
-
Proporcionar funcionalidad para gestionar las necesidades de datos de empresas de cualquier tamaño y complejidad.
-
Logre alta disponibilidad y garantice la recuperación ante desastres con replicación de datos e implementación en múltiples sitios
En la siguiente tabla se enumeran los componentes utilizados en un entorno distribuido de Splunk Enterprise.
| Componente | Descripción | Responsabilidad |
|---|---|---|
Maestro del clúster de índices |
Coordina actividades y actualizaciones de un clúster de indexadores |
Gestión de índices |
Clúster de índices |
Grupo de indexadores de Splunk Enterprise que están configurados para replicar los datos de los demás |
Indexación |
Desplegador de cabezal de búsqueda |
Maneja la implementación y las actualizaciones del maestro del clúster. |
Gestión de cabezales de búsqueda |
Grupo de búsqueda de cabezas |
Grupo de cabezales de búsqueda que sirve como recurso central para la búsqueda |
Gestión de búsquedas |
Balanceadores de carga |
Lo utilizan los componentes agrupados para gestionar la creciente demanda de los cabezales de búsqueda, los indexadores y el destino S3 para distribuir la carga entre los componentes agrupados. |
Gestión de carga para componentes agrupados |
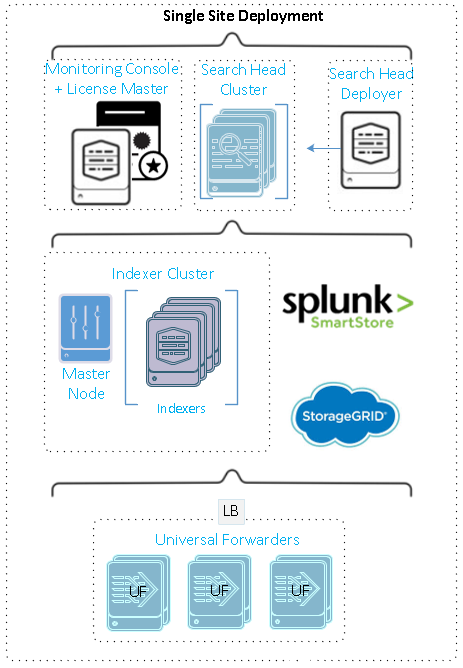
Esta figura muestra un ejemplo de una implementación distribuida en un solo sitio.
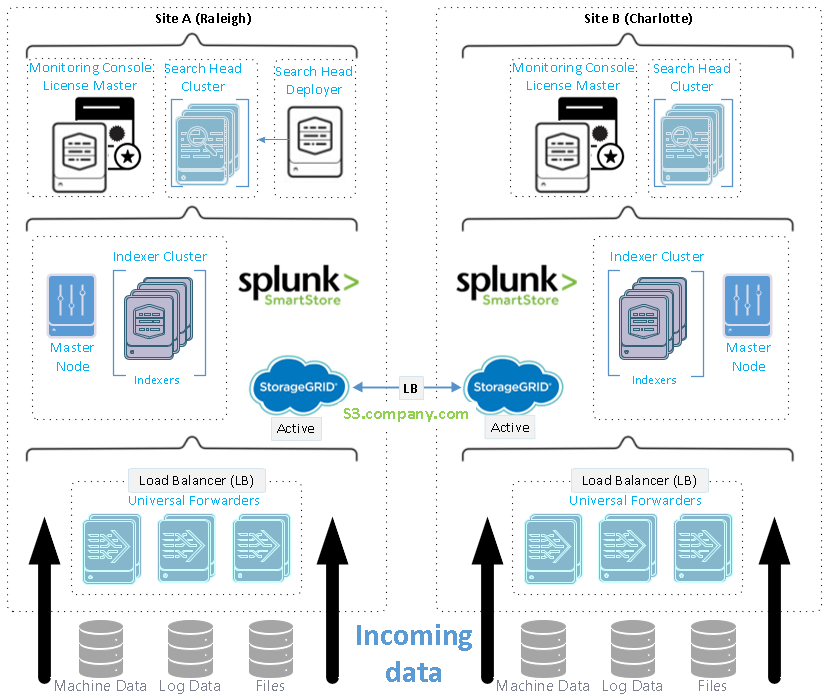
Esta figura muestra un ejemplo de una implementación distribuida en múltiples sitios.
Requisitos de hardware
Las siguientes tablas enumeran el número mínimo de componentes de hardware necesarios para implementar la solución. Los componentes de hardware que se utilizan en implementaciones específicas de la solución pueden variar según los requisitos del cliente.

|
Independientemente de si ha implementado Splunk SmartStore y StorageGRID en un solo sitio o en varios, todos los sistemas se administran desde StorageGRID GRID Manager en un único panel. Consulte la sección "Administración simple con Grid Manager" para obtener más detalles. |
Esta tabla enumera el hardware utilizado para un solo sitio.
| Hardware | Cantidad | Disco | Capacidad utilizable | Nota |
|---|---|---|---|---|
StorageGRID SG1000 |
1 |
n / A |
n / A |
Nodo de administración y balanceador de carga |
StorageGRID SG6060 |
4 |
x48, 8 TB (disco duro NL-SAS) |
1PB |
Almacenamiento remoto |
Esta tabla enumera el hardware utilizado para una configuración multisitio (por sitio).
| Hardware | Cantidad | Disco | Capacidad utilizable | Nota |
|---|---|---|---|---|
StorageGRID SG1000 |
2 |
n / A |
n / A |
Nodo de administración y balanceador de carga |
StorageGRID SG6060 |
4 |
x48, 8 TB (disco duro NL-SAS) |
1PB |
Almacenamiento remoto |
Balanceador de carga NetApp StorageGRID : SG1000
El almacenamiento de objetos requiere el uso de un equilibrador de carga para presentar el espacio de nombres de almacenamiento en la nube. StorageGRID admite balanceadores de carga de terceros de proveedores líderes como F5 y Citrix, pero muchos clientes eligen el balanceador StorageGRID de nivel empresarial por su simplicidad, resiliencia y alto rendimiento. El balanceador de carga StorageGRID está disponible como una máquina virtual, un contenedor o un dispositivo especialmente diseñado.
StorageGRID SG1000 facilita el uso de grupos de alta disponibilidad (HA) y equilibrio de carga inteligente para conexiones de rutas de datos S3. Ningún otro sistema de almacenamiento de objetos local proporciona un equilibrador de carga personalizado.
El aparato SG1000 ofrece las siguientes características:
-
Un equilibrador de carga y, opcionalmente, funciones de nodo de administración para un sistema StorageGRID
-
El instalador del dispositivo StorageGRID para simplificar la implementación y configuración de nodos
-
Configuración simplificada de puntos finales S3 y SSL
-
Ancho de banda dedicado (en comparación con compartir un balanceador de carga de terceros con otras aplicaciones)
-
Ancho de banda Ethernet agregado de hasta 4 x 100 Gbps
La siguiente imagen muestra el dispositivo SG1000 Gateway Services.

SG6060
El dispositivo StorageGRID SG6060 incluye un controlador de cómputo (SG6060) y un estante de controlador de almacenamiento (E-Series E2860) que contiene dos controladores de almacenamiento y 60 unidades. Este aparato ofrece las siguientes características:
-
Escala hasta 400 PB en un solo espacio de nombres.
-
Ancho de banda Ethernet agregado de hasta 4 x 25 Gbps.
-
Incluye el instalador de dispositivos StorageGRID para simplificar la implementación y configuración de nodos.
-
Cada dispositivo SG6060 puede tener uno o dos estantes de expansión adicionales para un total de 180 unidades.
-
Dos controladores E-Series E2800 (configuración dúplex) para brindar soporte de conmutación por error del controlador de almacenamiento.
-
Estante de unidad de cinco cajones que admite sesenta unidades de 3,5 pulgadas (dos unidades de estado sólido y 58 unidades NL-SAS).
La siguiente imagen muestra el dispositivo SG6060.

Diseño de Splunk
La siguiente tabla enumera la configuración de Splunk para un solo sitio.
| Componente de Splunk | Tarea | Cantidad | Núcleos | Memoria | Sistema operativo |
|---|---|---|---|---|---|
Reenvío universal |
Responsable de ingerir datos y enviarlos a los indexadores. |
4 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Indexador |
Gestiona los datos del usuario |
10 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Cabezal de búsqueda |
La interfaz de usuario busca datos en los indexadores |
3 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Desplegador de cabezal de búsqueda |
Maneja actualizaciones para grupos de encabezados de búsqueda |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Maestro del clúster |
Administra la instalación y los indexadores de Splunk. |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Consola de monitoreo y maestro de licencias |
Realiza una supervisión centralizada de toda la implementación de Splunk y administra las licencias de Splunk. |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Las siguientes tablas describen la configuración de Splunk para configuraciones multisitio.
Esta tabla enumera la configuración de Splunk para una configuración multisitio (sitio A).
| Componente de Splunk | Tarea | Cantidad | Núcleos | Memoria | Sistema operativo |
|---|---|---|---|---|---|
Reenvío universal |
Responsable de ingerir datos y enviarlos a los indexadores. |
4 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Indexador |
Gestiona los datos del usuario |
10 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Cabezal de búsqueda |
La interfaz de usuario busca datos en los indexadores |
3 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Desplegador de cabezal de búsqueda |
Maneja actualizaciones para grupos de encabezados de búsqueda |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Maestro del clúster |
Administra la instalación y los indexadores de Splunk. |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Consola de monitoreo y maestro de licencias |
Realiza la supervisión centralizada de toda la implementación de Splunk y administra las licencias de Splunk. |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Esta tabla enumera la configuración de Splunk para una configuración multisitio (sitio B).
| Componente de Splunk | Tarea | Cantidad | Núcleos | Memoria | Sistema operativo |
|---|---|---|---|---|---|
Reenvío universal |
Responsable de ingerir datos y enviarlos a los indexadores. |
4 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Indexador |
Gestiona los datos del usuario |
10 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Cabezal de búsqueda |
La interfaz de usuario busca datos en los indexadores |
3 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Maestro del clúster |
Administra la instalación y los indexadores de Splunk. |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Consola de monitoreo y maestro de licencias |
Realiza una supervisión centralizada de toda la implementación de Splunk y administra las licencias de Splunk. |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |