

Rendimiento de SmartStore en un solo sitio
 Sugerir cambios
Sugerir cambios
Esta sección describe el rendimiento de Splunk SmartStore en un controlador NetApp StorageGRID . Splunk SmartStore mueve datos cálidos al almacenamiento remoto, que en este caso es el almacenamiento de objetos StorageGRID en la validación del rendimiento.
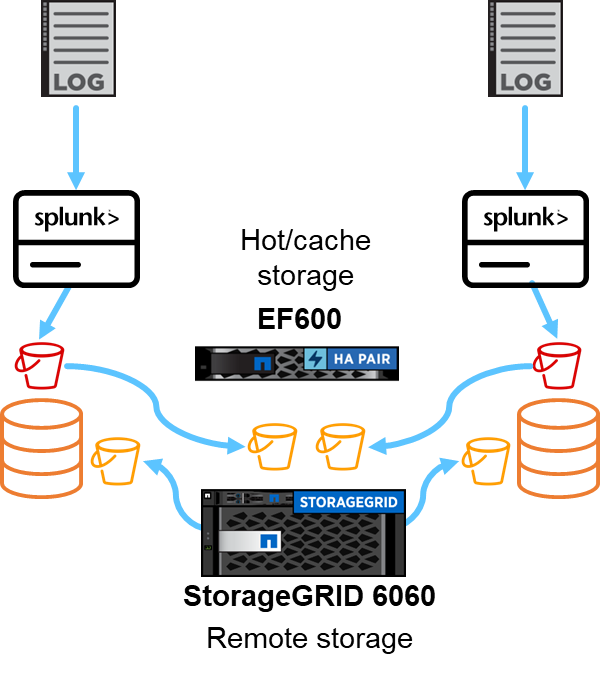
Utilizamos EF600 para almacenamiento en caché/activo y StorageGRID 6060 para almacenamiento remoto. Utilizamos la siguiente arquitectura para la validación del rendimiento. Utilizamos dos cabezales de búsqueda, cuatro reenvíos pesados para enviar los datos a los indexadores, siete generadores de eventos Splunk (Eventgens) para generar los datos en tiempo real y 18 indexadores para almacenar los datos.
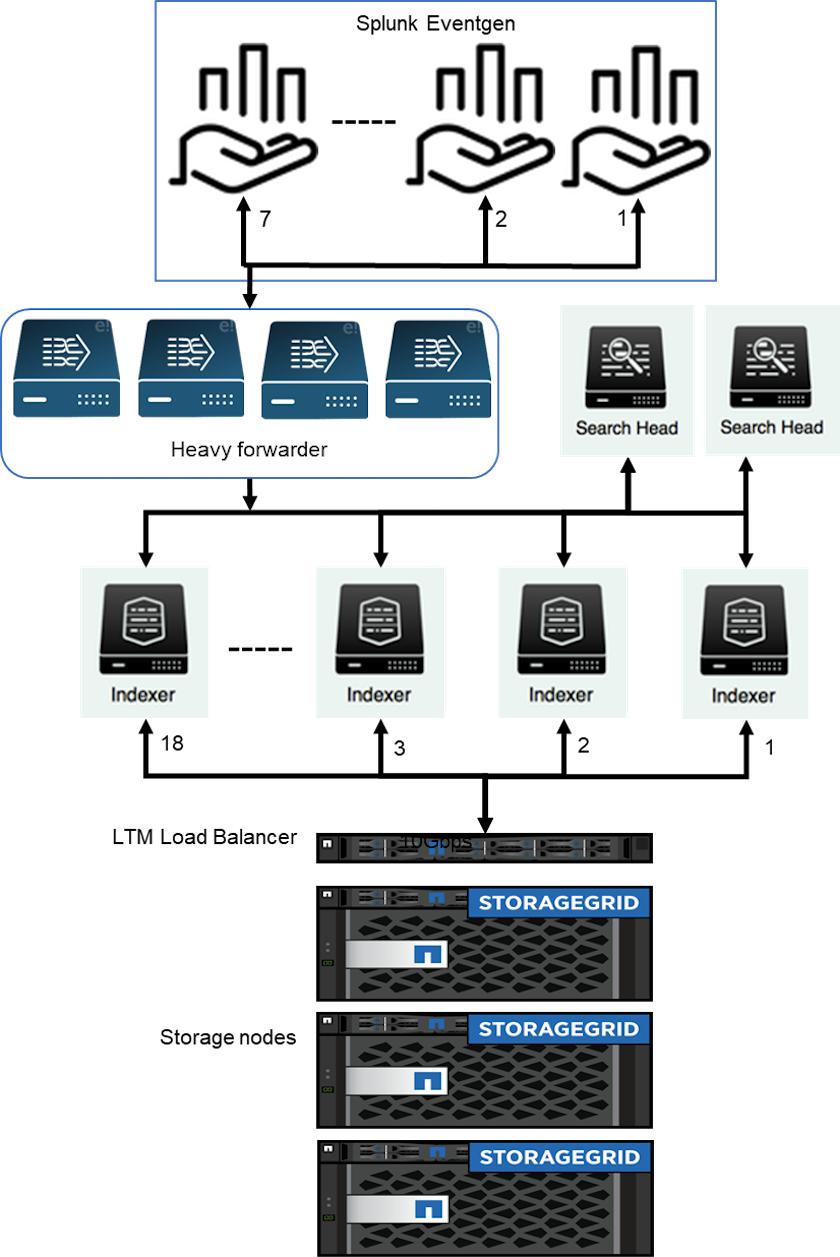
Configuración
Esta tabla enumera el hardware utilizado para la validación del rendimiento de SmartStorage.
| Componente de Splunk | Tarea | Cantidad | Núcleos | Memoria | Sistema operativo |
|---|---|---|---|---|---|
Transportador pesado |
Responsable de ingerir datos y enviarlos a los indexadores. |
4 |
16 núcleos |
32 GB de RAM |
TRINEO 15 SP2 |
Indexador |
Gestiona los datos del usuario |
18 |
16 núcleos |
32 GB de RAM |
TRINEO 15 SP2 |
Cabezal de búsqueda |
El frontend del usuario busca datos en los indexadores |
2 |
16 núcleos |
32 GB de RAM |
TRINEO 15 SP2 |
Desplegador de cabezal de búsqueda |
Maneja actualizaciones para grupos de encabezados de búsqueda |
1 |
16 núcleos |
32 GB de RAM |
TRINEO 15 SP2 |
Maestro del clúster |
Administra la instalación y los indexadores de Splunk. |
1 |
16 núcleos |
32 GB de RAM |
TRINEO 15 SP2 |
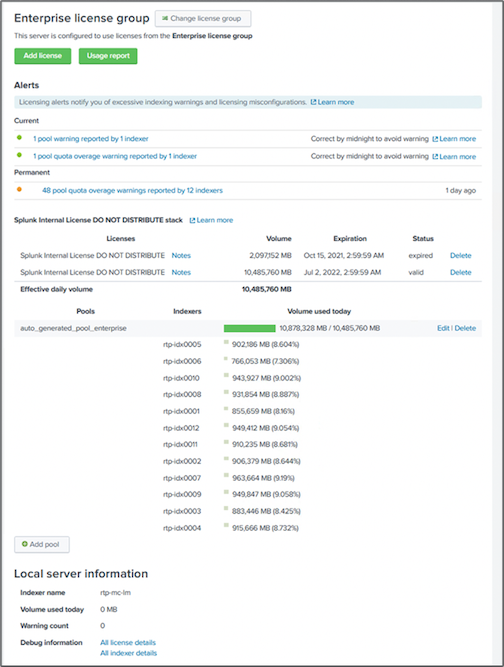
Consola de monitoreo y maestro de licencias |
Realiza una supervisión centralizada de toda la implementación de Splunk y administra las licencias de Splunk. |
1 |
16 núcleos |
32 GB de RAM |
TRINEO 15 SP2 |
Validación del rendimiento de la tienda remota SmartStore
En esta validación de rendimiento, configuramos el caché SmartStore en el almacenamiento local en todos los indexadores para 10 días de datos. Hemos habilitado el maxDataSize=auto (tamaño de depósito de 750 MB) en el administrador de clústeres de Splunk y envió los cambios a todos los indexadores. Para medir el rendimiento de carga, ingerimos 10 TB por día durante 10 días y transferimos todos los buckets activos a cálidos al mismo tiempo y capturamos el rendimiento máximo y promedio por instancia y en toda la implementación desde el panel de control de la consola de monitoreo de SmartStore.
Esta imagen muestra los datos ingeridos en un día.
Ejecutamos el siguiente comando desde el clúster maestro (el nombre del índice es eventgen-test ). Luego, capturamos el rendimiento de carga máximo y promedio por instancia y en toda la implementación a través de los paneles de control de la consola de monitoreo de SmartStore.
for i in rtp-idx0001 rtp-idx0002 rtp-idx0003 rtp-idx0004 rtp-idx0005 rtp-idx0006 rtp-idx0007 rtp-idx0008 rtp-idx0009 rtp-idx0010 rtp-idx0011 rtp-idx0012 rtp-idx0013011 rtdx0014 rtp-idx0015 rtp-idx0016 rtp-idx0017 rtp-idx0018 ; do ssh $i "hostname; date; /opt/splunk/bin/splunk _internal call /data/indexes/eventgen-test/roll-hot-buckets -auth admin:12345678; sleep 1 "; done

|
El maestro del clúster tiene autenticación sin contraseña para todos los indexadores (rtp-idx0001…rtp-idx0018). |
Para medir el rendimiento de la descarga, eliminamos todos los datos de la memoria caché ejecutando la CLI de desalojo dos veces usando el siguiente comando.
|
|
Ejecutamos el siguiente comando desde el clúster maestro y ejecutamos la búsqueda desde el cabezal de búsqueda sobre 10 días de datos del almacén remoto de StorageGRID. Luego capturamos el rendimiento de carga máximo y promedio por instancia y en toda la implementación a través de los paneles de control de la consola de monitoreo de SmartStore. |
for i in rtp-idx0001 rtp-idx0002 rtp-idx0003 rtp-idx0004 rtp-idx0005 rtp-idx0006 rtp-idx0007 rtp-idx0008 rtp-idx0009 rtp-idx0010 rtp-idx0011 rtp-idx0012 rtp-idx0013 rtp-idx0014 rtp-idx0015 rtp-idx0016 rtp-idx0017 rtp-idx0018 ; do ssh $i " hostname; date; /opt/splunk/bin/splunk _internal call /services/admin/cacheman/_evict -post:mb 1000000000 -post:path /mnt/EF600 -method POST -auth admin:12345678; "; done
Las configuraciones del indexador se enviaron desde el maestro del clúster SmartStore. El maestro del clúster tenía la siguiente configuración para el indexador.
Rtp-cm01:~ # cat /opt/splunk/etc/master-apps/_cluster/local/indexes.conf [default] maxDataSize = auto #defaultDatabase = eventgen-basic defaultDatabase = eventgen-test hotlist_recency_secs = 864000 repFactor = auto [volume:remote_store] storageType = remote path = s3://smartstore2 remote.s3.access_key = U64TUHONBNC98GQGL60R remote.s3.secret_key = UBoXNE0jmECie05Z7iCYVzbSB6WJFckiYLcdm2yg remote.s3.endpoint = 3.sddc.netapp.com:10443 remote.s3.signature_version = v2 remote.s3.clientCert = [eventgen-basic] homePath = $SPLUNK_DB/eventgen-basic/db coldPath = $SPLUNK_DB/eventgen-basic/colddb thawedPath = $SPLUNK_DB/eventgen-basic/thawed [eventgen-migration] homePath = $SPLUNK_DB/eventgen-scale/db coldPath = $SPLUNK_DB/eventgen-scale/colddb thawedPath = $SPLUNK_DB/eventgen-scale/thaweddb [main] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb thawedPath = $SPLUNK_DB/$_index_name/thaweddb [history] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb thawedPath = $SPLUNK_DB/$_index_name/thaweddb [summary] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb thawedPath = $SPLUNK_DB/$_index_name/thaweddb [remote-test] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb #for storagegrid config remotePath = volume:remote_store/$_index_name thawedPath = $SPLUNK_DB/$_index_name/thaweddb [eventgen-test] homePath = $SPLUNK_DB/$_index_name/db maxDataSize=auto maxHotBuckets=1 maxWarmDBCount=2 coldPath = $SPLUNK_DB/$_index_name/colddb #for storagegrid config remotePath = volume:remote_store/$_index_name thawedPath = $SPLUNK_DB/$_index_name/thaweddb [eventgen-evict-test] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb #for storagegrid config remotePath = volume:remote_store/$_index_name thawedPath = $SPLUNK_DB/$_index_name/thaweddb maxDataSize = auto_high_volume maxWarmDBCount = 5000 rtp-cm01:~ #
Ejecutamos la siguiente consulta de búsqueda en el encabezado de búsqueda para recopilar la matriz de rendimiento.
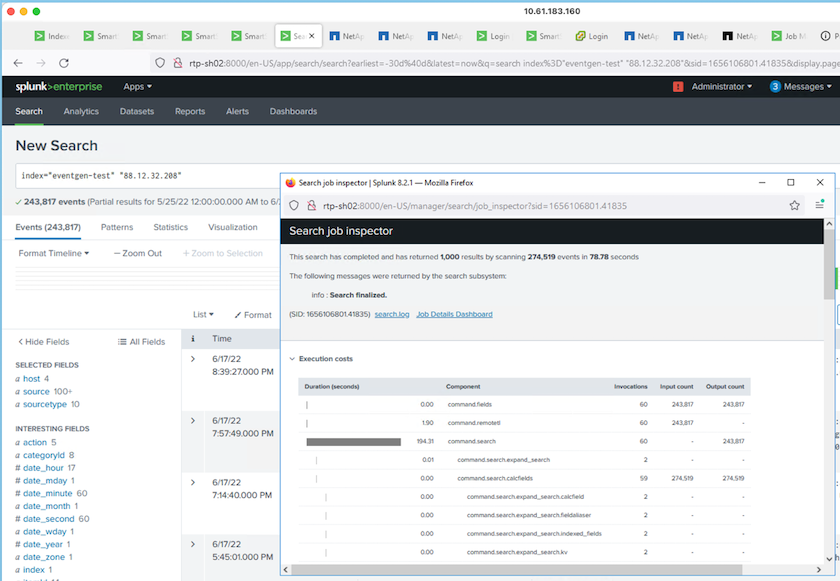
Recopilamos la información de rendimiento del clúster maestro. El rendimiento máximo fue de 61,34 GBps.
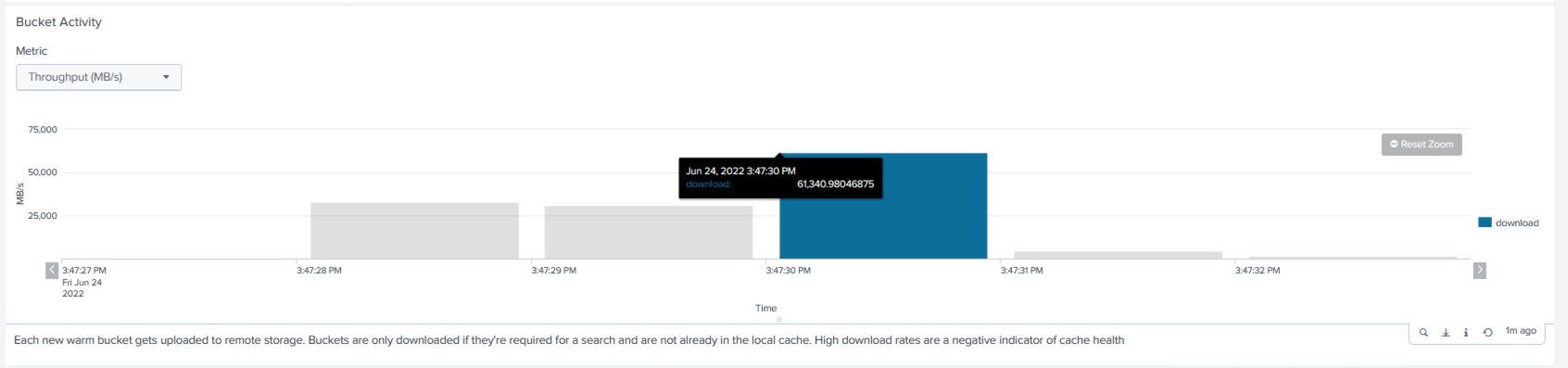
El rendimiento promedio fue de aproximadamente 29 GBps.
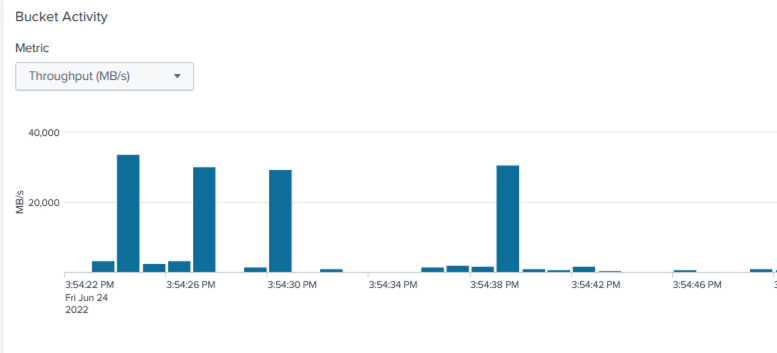
Rendimiento de StorageGRID
El rendimiento de SmartStore se basa en la búsqueda de patrones y cadenas específicos entre grandes cantidades de datos. En esta validación, los eventos se generan utilizando "Eventgen" en un índice de Splunk específico (eventgen-test) a través del cabezal de búsqueda y la solicitud se dirige a StorageGRID para la mayoría de las consultas. La siguiente imagen muestra los aciertos y errores de los datos de la consulta. Los datos de aciertos provienen del disco local y los datos de errores provienen del controlador StorageGRID .
|
|
El color verde muestra los datos de aciertos y el color naranja muestra los datos de errores. |
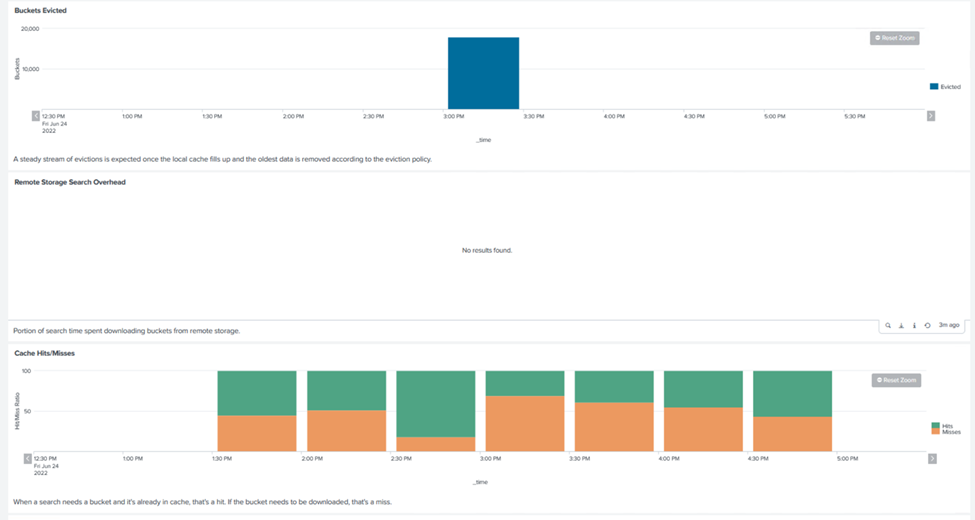
Cuando se ejecuta la consulta para la búsqueda en StorageGRID, el tiempo de recuperación de S3 de StorageGRID se muestra en la siguiente imagen.
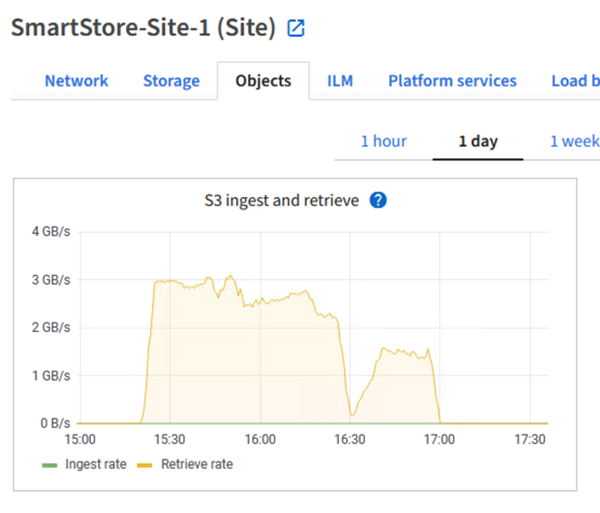
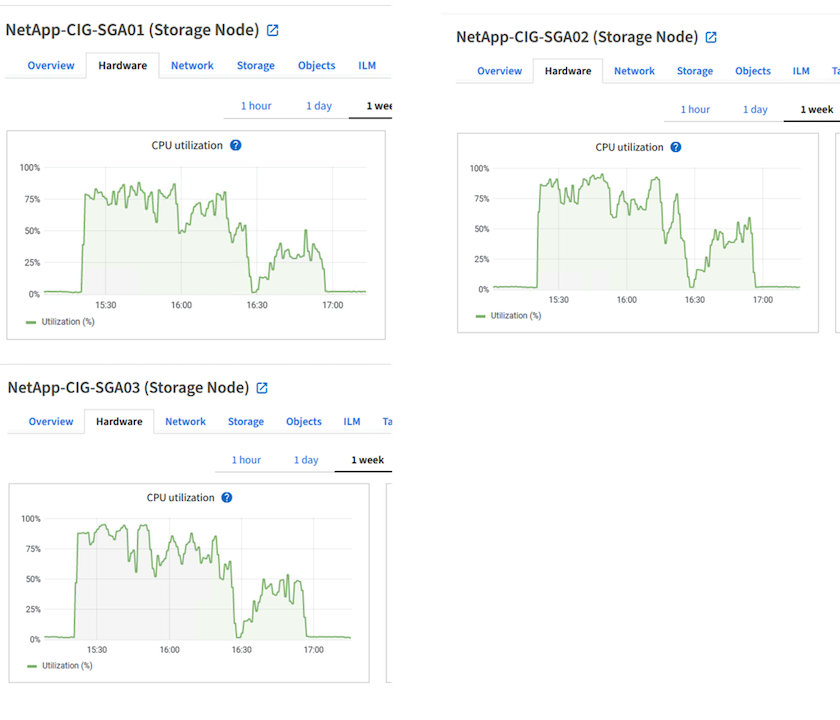
Uso del hardware de StorageGRID
La instancia de StorageGRID tiene un equilibrador de carga y tres controladores StorageGRID . La utilización de la CPU para los tres controladores es del 75% al 100%.
SmartStore con controlador de almacenamiento NetApp : beneficios para el cliente
-
Desacoplamiento entre computación y almacenamiento. Splunk SmartStore desacopla el procesamiento y el almacenamiento, lo que le ayuda a escalarlos de forma independiente.
-
Datos bajo demanda. SmartStore acerca los datos al procesamiento a pedido y brinda elasticidad de procesamiento y almacenamiento y eficiencia de costos para lograr una retención de datos más prolongada a escala.
-
Compatible con API AWS S3. SmartStore utiliza la API de AWS S3 para comunicarse con el almacenamiento de restauración, que es un almacén de objetos compatible con AWS S3 y la API de S3, como StorageGRID.
-
Reduce los requisitos y costos de almacenamiento. SmartStore reduce los requisitos de almacenamiento para datos antiguos (cálidos/fríos). Solo necesita una única copia de datos porque el almacenamiento de NetApp brinda protección de datos y se encarga de las fallas y la alta disponibilidad.
-
Fallo de hardware. La falla de un nodo en una implementación de SmartStore no hace que los datos sean inaccesibles y tiene una recuperación del indexador mucho más rápida en caso de falla de hardware o desequilibrio de datos.
-
Caché consciente de aplicaciones y datos.
-
Agregar y quitar indexadores y configurar y desmontar clústeres a pedido.
-
El nivel de almacenamiento ya no está vinculado al hardware.