

Ejemplo de caso de uso: trabajo de capacitación de TensorFlow
 Sugerir cambios
Sugerir cambios
Esta sección describe las tareas que deben realizarse para ejecutar un trabajo de entrenamiento de TensorFlow dentro de un entorno de NVIDIA AI Enterprise.
Prerrequisitos
Antes de realizar los pasos que se describen en esta sección, asumimos que ya ha creado una plantilla de máquina virtual invitada siguiendo las instrucciones que se describen en la"Configuración" página.
Crear una máquina virtual invitada a partir de una plantilla
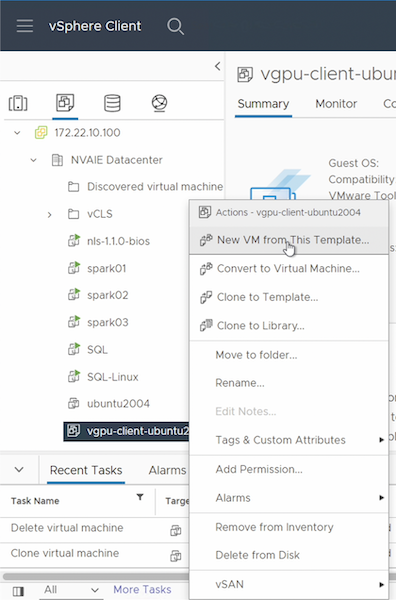
Primero, debes crear una nueva VM invitada a partir de la plantilla que creaste en la sección anterior. Para crear una nueva VM invitada a partir de su plantilla, inicie sesión en VMware vSphere, haga clic derecho en el nombre de la plantilla, seleccione "Nueva VM a partir de esta plantilla…" y luego siga el asistente.
Crear y montar un volumen de datos
A continuación, debe crear un nuevo volumen de datos en el que almacenar su conjunto de datos de entrenamiento. Puede crear rápidamente un nuevo volumen de datos utilizando el kit de herramientas NetApp DataOps. El comando de ejemplo que sigue muestra la creación de un volumen llamado 'imagenet' con una capacidad de 2 TB.
$ netapp_dataops_cli.py create vol -n imagenet -s 2TB
Antes de poder rellenar su volumen de datos con datos, debe montarlo dentro de la máquina virtual invitada. Puede montar rápidamente un volumen de datos utilizando el kit de herramientas NetApp DataOps. El comando de ejemplo que sigue muestra el montaje del volumen que se creó en el paso anterior.
$ sudo -E netapp_dataops_cli.py mount vol -n imagenet -m ~/imagenet
Rellenar volumen de datos
Una vez aprovisionado y montado el nuevo volumen, se puede recuperar el conjunto de datos de entrenamiento de la ubicación de origen y colocarlo en el nuevo volumen. Por lo general, esto implicará extraer los datos de un lago de datos S3 o Hadoop y, a veces, requerirá la ayuda de un ingeniero de datos.
Ejecutar trabajo de entrenamiento de TensorFlow
Ahora, está listo para ejecutar su trabajo de entrenamiento de TensorFlow. Para ejecutar su trabajo de entrenamiento de TensorFlow, realice las siguientes tareas.
-
Extraiga la imagen del contenedor TensorFlow empresarial NVIDIA NGC.
$ sudo docker pull nvcr.io/nvaie/tensorflow-2-1:22.05-tf1-nvaie-2.1-py3
-
Inicie una instancia del contenedor TensorFlow empresarial NVIDIA NGC. Utilice la opción '-v' para adjuntar su volumen de datos al contenedor.
$ sudo docker run --gpus all -v ~/imagenet:/imagenet -it --rm nvcr.io/nvaie/tensorflow-2-1:22.05-tf1-nvaie-2.1-py3
-
Ejecute su programa de entrenamiento de TensorFlow dentro del contenedor. El siguiente comando de ejemplo muestra la ejecución de un programa de entrenamiento ResNet-50 de ejemplo que está incluido en la imagen del contenedor.
$ python ./nvidia-examples/cnn/resnet.py --layers 50 -b 64 -i 200 -u batch --precision fp16 --data_dir /imagenet/data