

TR-4955: Recuperación ante desastres con FSx ONTAP y VMC (AWS VMware Cloud)
 Sugerir cambios
Sugerir cambios
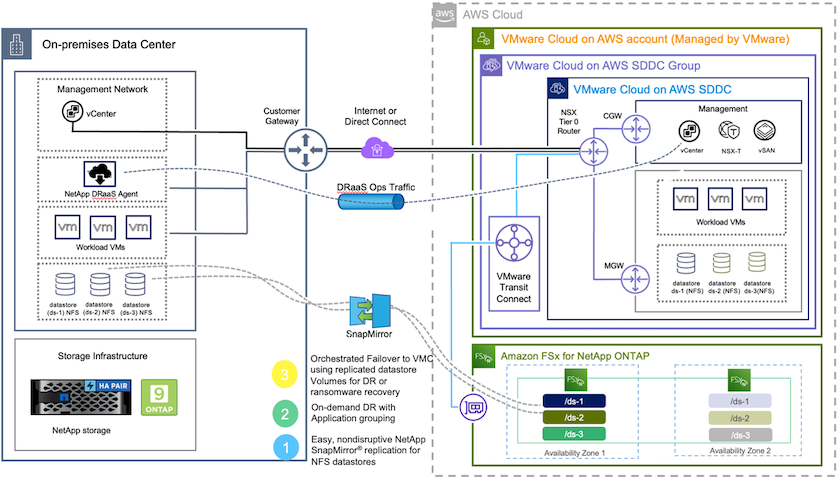
Disaster Recovery Orchestrator (DRO, una solución con script e interfaz de usuario) se puede utilizar para recuperar sin problemas cargas de trabajo replicadas desde las instalaciones locales a FSx ONTAP. DRO automatiza la recuperación desde el nivel de SnapMirror , mediante el registro de máquinas virtuales en VMC, hasta las asignaciones de red directamente en NSX-T. Esta función está incluida en todos los entornos VMC.
Niyaz Mohamed, NetApp
Descripción general
La recuperación ante desastres en la nube es una forma resiliente y rentable de proteger las cargas de trabajo contra interrupciones del sitio y eventos de corrupción de datos (por ejemplo, ransomware). Con la tecnología NetApp SnapMirror , las cargas de trabajo locales de VMware se pueden replicar en FSx ONTAP que se ejecuta en AWS.
Disaster Recovery Orchestrator (DRO, una solución con script e interfaz de usuario) se puede utilizar para recuperar sin problemas cargas de trabajo replicadas desde las instalaciones locales a FSx ONTAP. DRO automatiza la recuperación desde el nivel de SnapMirror , mediante el registro de máquinas virtuales en VMC, hasta las asignaciones de red directamente en NSX-T. Esta función está incluida en todos los entornos VMC.
Empezando
Implementar y configurar VMware Cloud en AWS
"VMware Cloud en AWS"Proporciona una experiencia nativa de la nube para cargas de trabajo basadas en VMware en el ecosistema de AWS. Cada centro de datos definido por software (SDDC) de VMware se ejecuta en una nube privada virtual (VPC) de Amazon y proporciona una pila VMware completa (incluido vCenter Server), redes definidas por software NSX-T, almacenamiento definido por software vSAN y uno o más hosts ESXi que proporcionan recursos informáticos y de almacenamiento a las cargas de trabajo. Para configurar un entorno VMC en AWS, siga los pasos a continuación"enlace" . También se puede utilizar un conjunto de luces piloto para fines de DR.

|
En la versión inicial, DRO admite un grupo de luces piloto existente. La creación de SDDC a pedido estará disponible en una próxima versión. |
Aprovisionar y configurar FSx ONTAP
Amazon FSx ONTAP es un servicio completamente administrado que proporciona almacenamiento de archivos altamente confiable, escalable, de alto rendimiento y rico en funciones, creado sobre el popular sistema de archivos NetApp ONTAP . Siga los pasos a continuación"enlace" para aprovisionar y configurar FSx ONTAP.
Implementar y configurar SnapMirror en FSx ONTAP
El siguiente paso es usar NetApp BlueXP y descubrir la instancia FSx ONTAP en AWS aprovisionada y replicar los volúmenes de almacén de datos deseados desde un entorno local a FSx ONTAP con la frecuencia adecuada y la retención de copias Snapshot de NetApp :
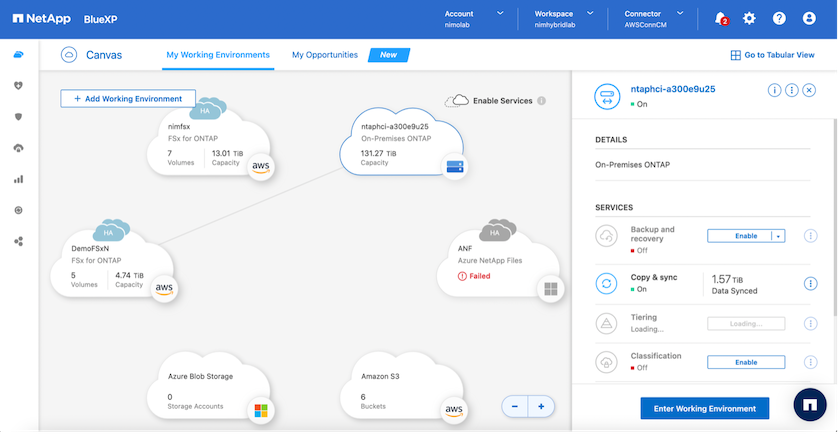
Siga los pasos de este enlace para configurar BlueXP. También puede utilizar la CLI de NetApp ONTAP para programar la replicación siguiendo este enlace.
|
|
Una relación SnapMirror es un requisito previo y debe crearse de antemano. |
Instalación de DRO
Para comenzar a utilizar DRO, utilice el sistema operativo Ubuntu en una instancia EC2 o máquina virtual designada para asegurarse de cumplir con los requisitos previos. Luego instala el paquete.
Prerrequisitos
-
Asegúrese de que exista conectividad con los sistemas de almacenamiento y vCenter de origen y destino.
-
La resolución de DNS debe estar implementada si está utilizando nombres DNS. De lo contrario, debe utilizar direcciones IP para vCenter y los sistemas de almacenamiento.
-
Crea un usuario con permisos de root. También puedes usar sudo con una instancia EC2.
Requisitos de OS
-
Ubuntu 20.04 (LTS) con un mínimo de 2 GB y 4 vCPU
-
Los siguientes paquetes deben instalarse en la máquina virtual del agente designado:
-
Docker
-
Docker-compose
-
Jq
-
Cambiar permisos en docker.sock : sudo chmod 666 /var/run/docker.sock .
|
|
El deploy.sh El script ejecuta todos los requisitos previos necesarios.
|
Instalar el paquete
-
Descargue el paquete de instalación en la máquina virtual designada:
git clone https://github.com/NetApp/DRO-AWS.git
El agente se puede instalar localmente o dentro de una VPC de AWS. -
Descomprima el paquete, ejecute el script de implementación e ingrese la IP del host (por ejemplo, 10.10.10.10).
tar xvf DRO-prereq.tar
-
Navegue hasta el directorio y ejecute el script de implementación de la siguiente manera:
sudo sh deploy.sh
-
Acceda a la interfaz de usuario mediante:
https://<host-ip-address>
con las siguientes credenciales predeterminadas:
Username: admin Password: admin
|
|
La contraseña se puede cambiar utilizando la opción “Cambiar contraseña”. |

Configuración de DRO
Una vez que FSx ONTAP y VMC se hayan configurado correctamente, puede comenzar a configurar DRO para automatizar la recuperación de cargas de trabajo locales en VMC mediante el uso de copias SnapMirror de solo lectura en FSx ONTAP.
NetApp recomienda implementar el agente DRO en AWS y también en la misma VPC donde se implementa FSx ONTAP (también se puede conectar entre pares), de modo que el agente DRO pueda comunicarse a través de la red con sus componentes locales, así como con los recursos FSx ONTAP y VMC.
El primer paso es descubrir y agregar los recursos locales y en la nube (tanto vCenter como almacenamiento) a DRO. Abra DRO en un navegador compatible y use el nombre de usuario y la contraseña predeterminados (admin/admin) y agregue sitios. También se pueden agregar sitios usando la opción Descubrir. Agregue las siguientes plataformas:
-
En las instalaciones
-
vCenter local
-
Sistema de almacenamiento ONTAP
-
-
Nube
-
Centro de VMC
-
FSx ONTAP
-
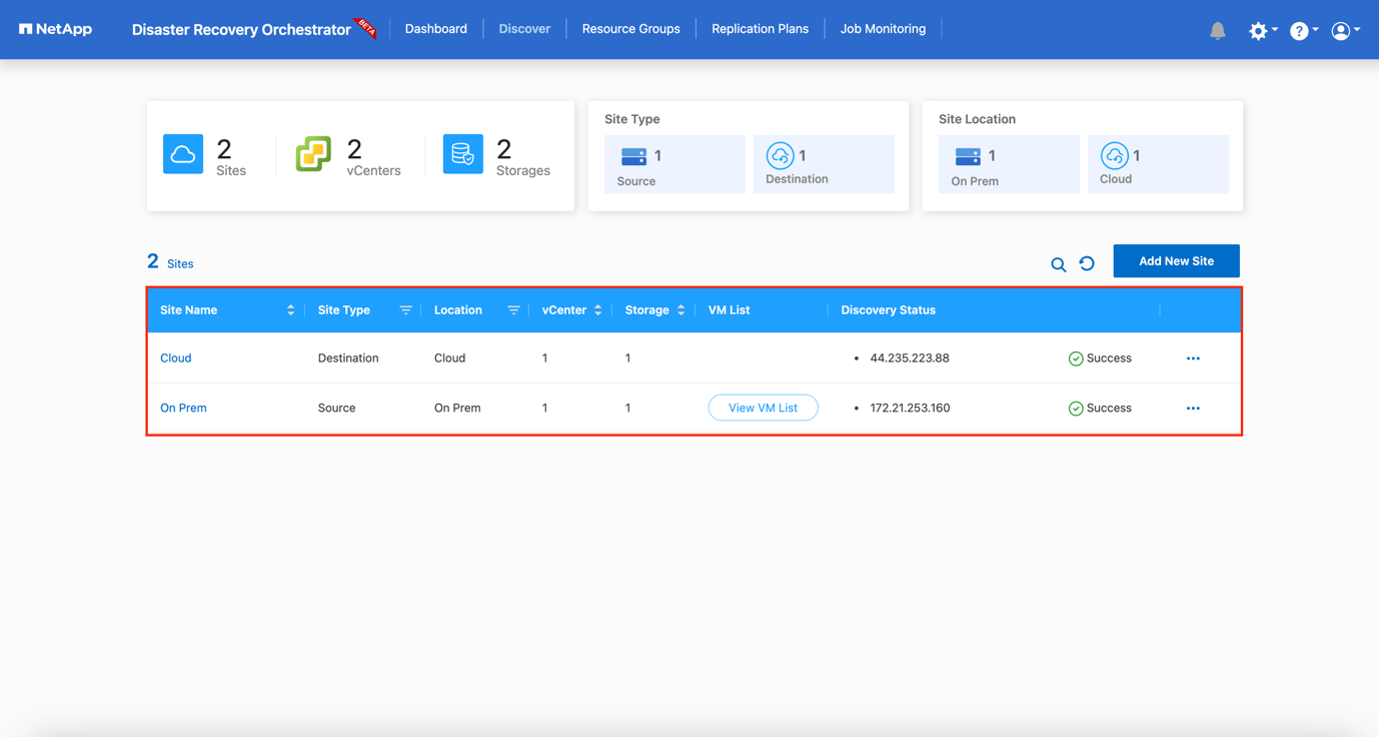
Una vez agregado, DRO realiza un descubrimiento automático y muestra las máquinas virtuales que tienen réplicas SnapMirror correspondientes desde el almacenamiento de origen a FSx ONTAP. DRO detecta automáticamente las redes y los grupos de puertos utilizados por las máquinas virtuales y los completa.
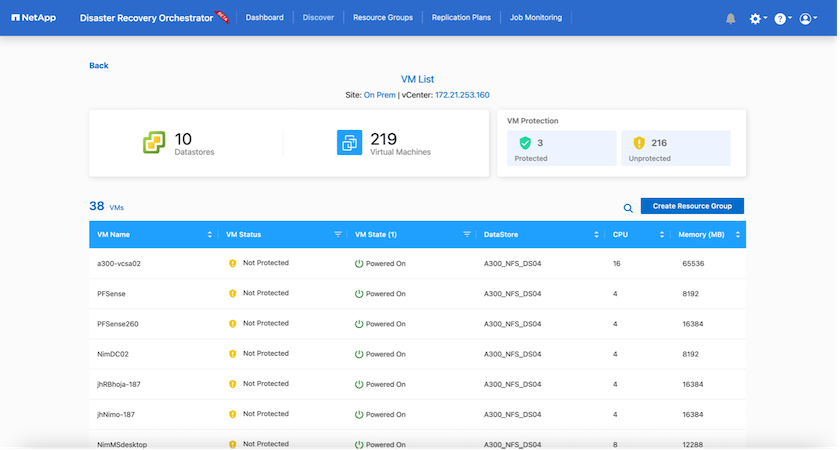
El siguiente paso es agrupar las máquinas virtuales necesarias en grupos funcionales para que sirvan como grupos de recursos.
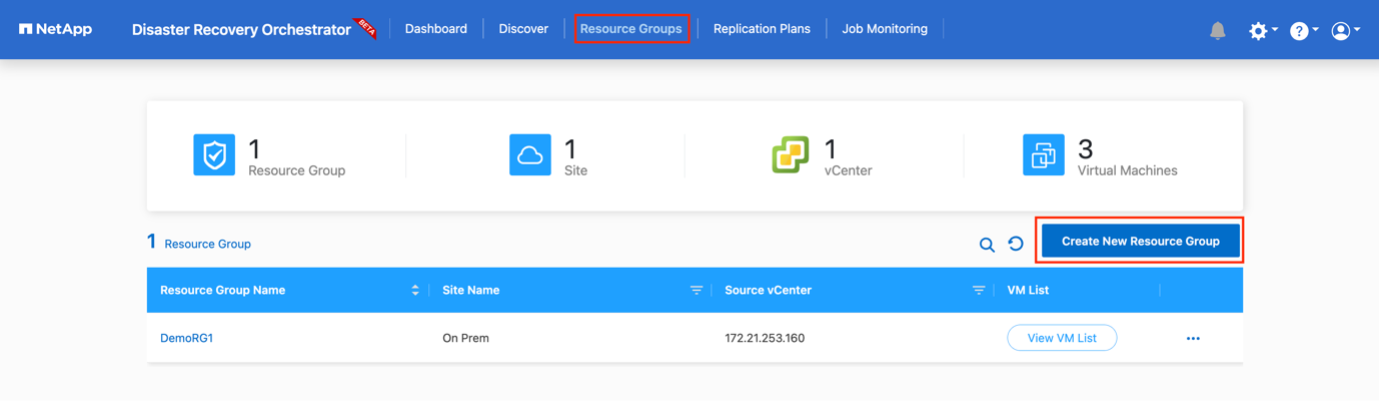
Agrupaciones de recursos
Una vez agregadas las plataformas, puedes agrupar las máquinas virtuales que deseas recuperar en grupos de recursos. Los grupos de recursos DRO le permiten agrupar un conjunto de máquinas virtuales dependientes en grupos lógicos que contienen sus órdenes de arranque, retrasos de arranque y validaciones de aplicaciones opcionales que se pueden ejecutar durante la recuperación.
Para comenzar a crear grupos de recursos, complete los siguientes pasos:
-
Acceda a Grupos de recursos y haga clic en Crear nuevo grupo de recursos.
-
En Nuevo grupo de recursos, seleccione el sitio de origen en el menú desplegable y haga clic en Crear.
-
Proporcione Detalles del grupo de recursos y haga clic en Continuar.
-
Seleccione las máquinas virtuales adecuadas mediante la opción de búsqueda.
-
Seleccione el orden de arranque y el retraso de arranque (segundos) para las máquinas virtuales seleccionadas. Establezca el orden de la secuencia de encendido seleccionando cada VM y configurando su prioridad. Tres es el valor predeterminado para todas las máquinas virtuales.
Las opciones son las siguientes:
1 – La primera máquina virtual en encenderse 3 – Predeterminado 5 – La última máquina virtual en encenderse
-
Haga clic en Crear grupo de recursos.
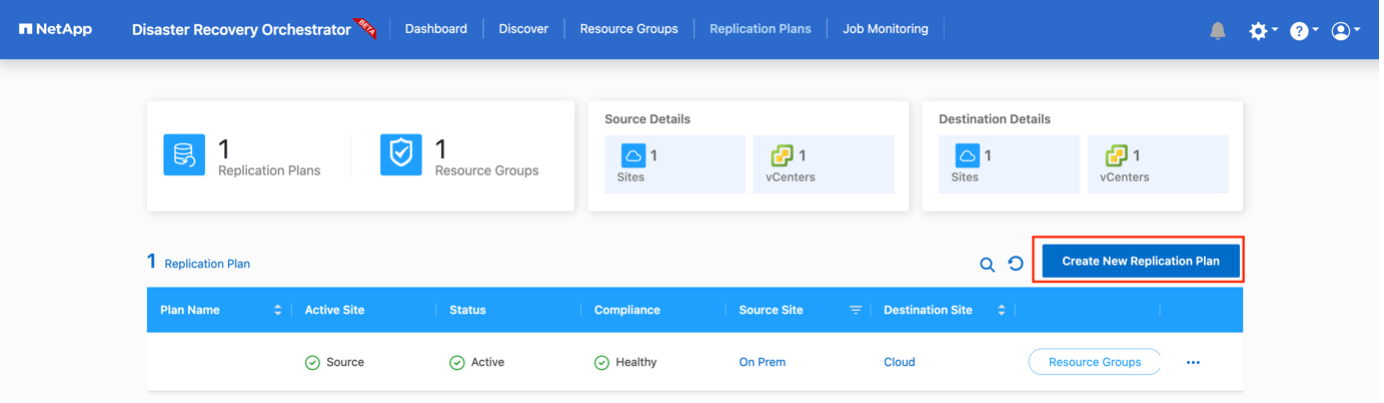
Planes de replicación
Necesita un plan para recuperar aplicaciones en caso de desastre. Seleccione las plataformas de vCenter de origen y destino del menú desplegable y elija los grupos de recursos que se incluirán en este plan, junto con la agrupación de cómo se deben restaurar y encender las aplicaciones (por ejemplo, controladores de dominio, luego nivel 1, luego nivel 2, y así sucesivamente). A estos planes a veces también se les llama planos. Para definir el plan de recuperación, navegue a la pestaña Plan de replicación y haga clic en Nuevo plan de replicación.
Para comenzar a crear un plan de replicación, complete los siguientes pasos:
-
Acceda a Planes de replicación y haga clic en Crear nuevo plan de replicación.
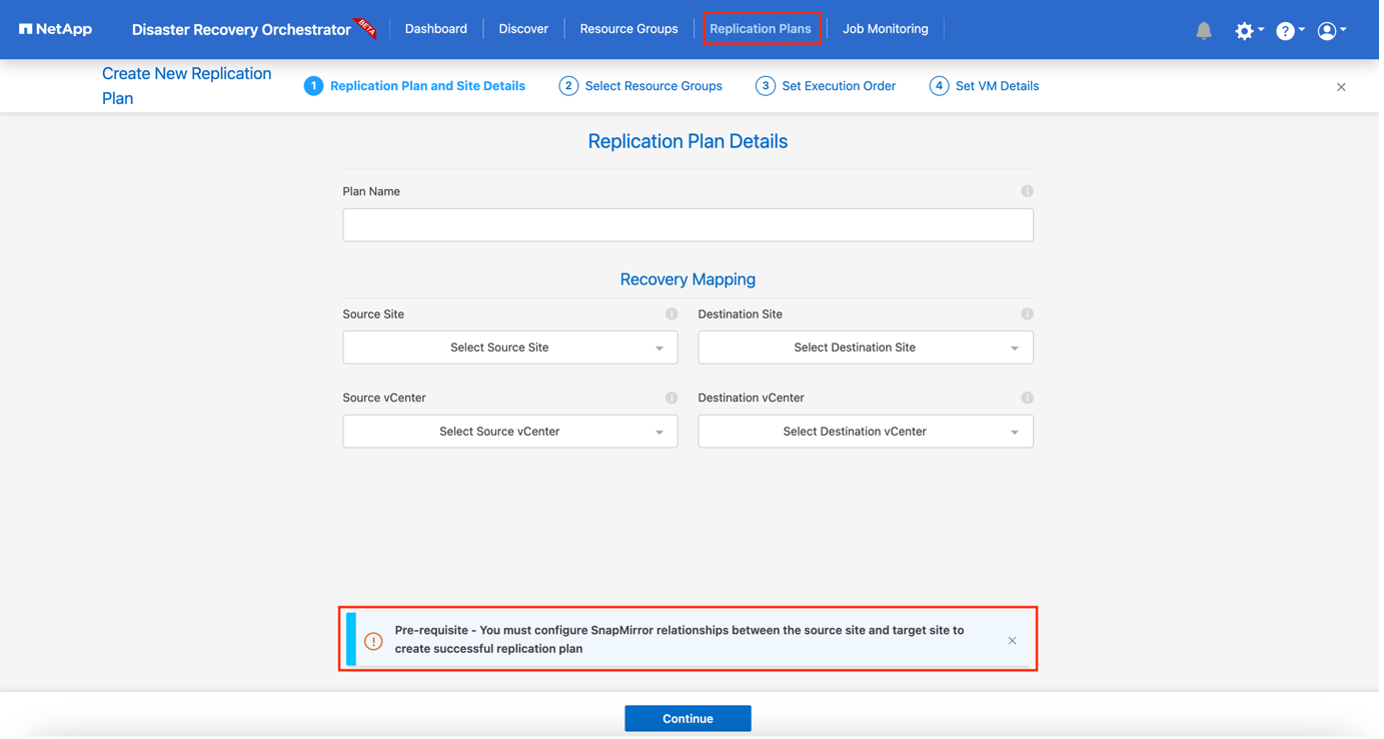
-
En Nuevo plan de replicación, proporcione un nombre para el plan y agregue asignaciones de recuperación seleccionando el sitio de origen, el vCenter asociado, el sitio de destino y el vCenter asociado.
-
Una vez completado el mapeo de recuperación, seleccione el mapeo de clúster.
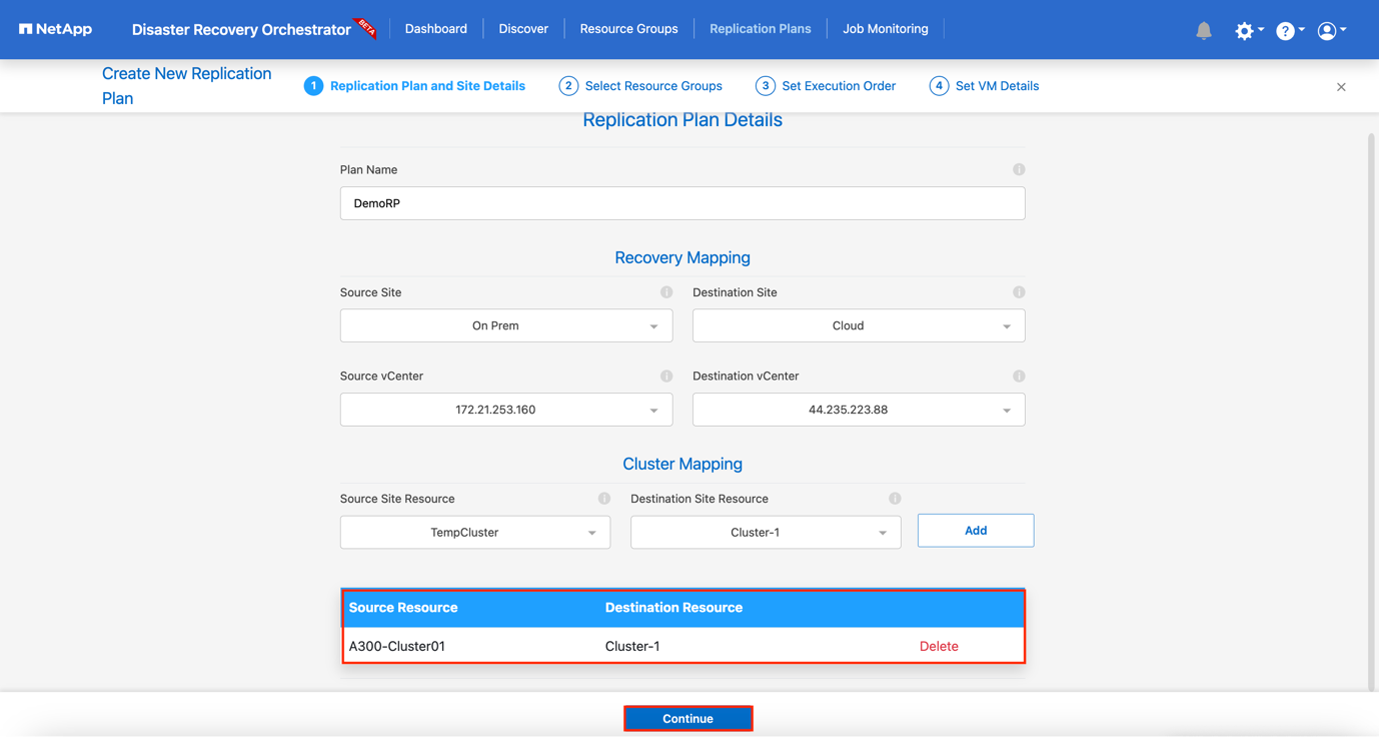
-
Seleccione Detalles del grupo de recursos y haga clic en Continuar.
-
Establecer el orden de ejecución para el grupo de recursos. Esta opción le permite seleccionar la secuencia de operaciones cuando existen múltiples grupos de recursos.
-
Una vez que haya terminado, seleccione la asignación de red al segmento apropiado. Los segmentos ya deberían estar aprovisionados dentro de VMC, así que seleccione el segmento apropiado para mapear la VM.
-
Según la selección de máquinas virtuales, las asignaciones de almacenes de datos se seleccionan automáticamente.
SnapMirror está en el nivel de volumen. Por lo tanto, todas las máquinas virtuales se replican en el destino de replicación. Asegúrese de seleccionar todas las máquinas virtuales que forman parte del almacén de datos. Si no se seleccionan, solo se procesan las máquinas virtuales que forman parte del plan de replicación. 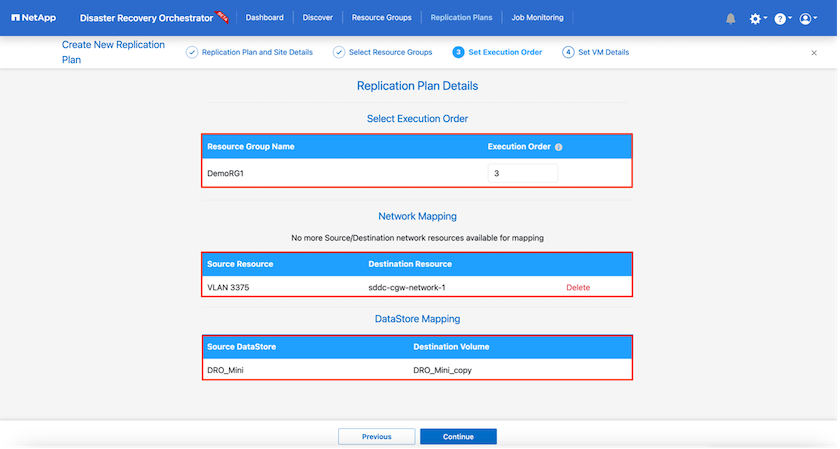
-
En los detalles de la máquina virtual, puede modificar opcionalmente el tamaño de los parámetros de CPU y RAM de la máquina virtual; esto puede ser muy útil al recuperar entornos grandes en clústeres de destino más pequeños o para realizar pruebas de recuperación ante desastres sin tener que aprovisionar una infraestructura VMware física uno a uno. Además, puede modificar el orden de arranque y el retraso de arranque (segundos) para todas las máquinas virtuales seleccionadas en los grupos de recursos. Hay una opción adicional para modificar el orden de arranque si se requieren cambios en los seleccionados durante la selección del orden de arranque del grupo de recursos. De forma predeterminada, se utiliza el orden de arranque seleccionado durante la selección del grupo de recursos; sin embargo, cualquier modificación se puede realizar en esta etapa.
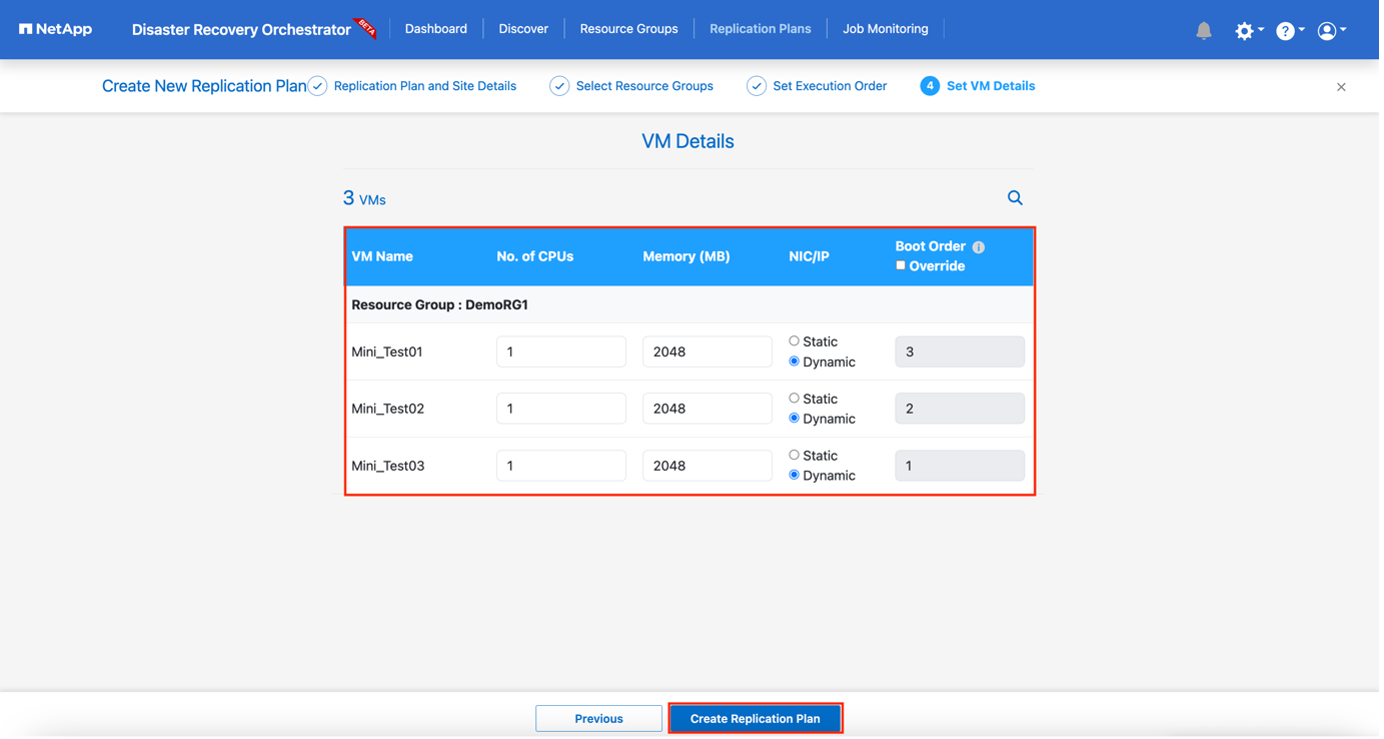
-
Haga clic en Crear plan de replicación.
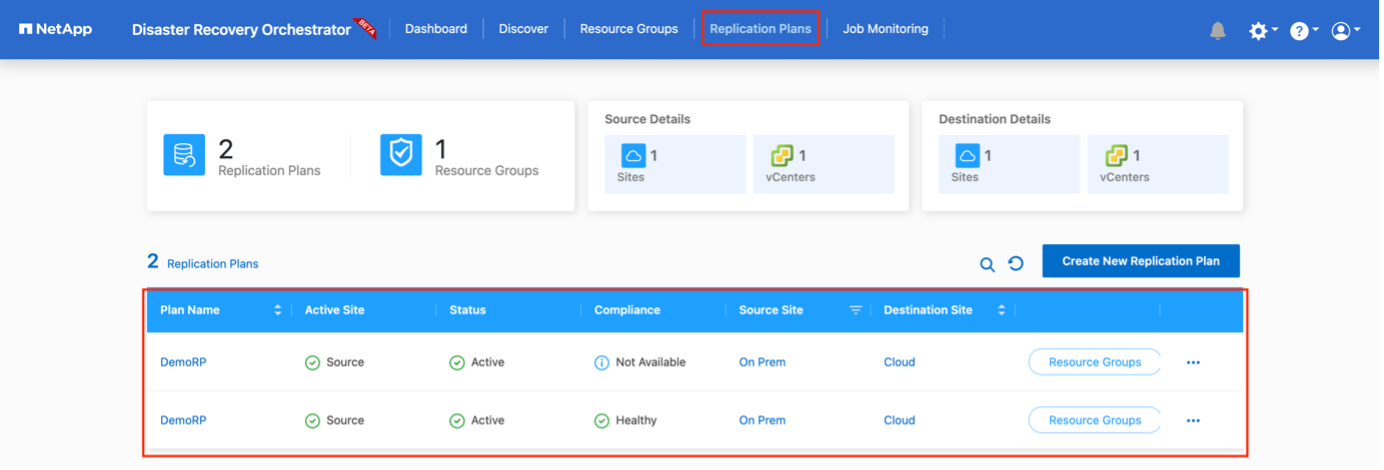
Una vez creado el plan de replicación, se pueden utilizar la opción de conmutación por error, la opción de conmutación por error de prueba o la opción de migración según los requisitos. Durante las opciones de conmutación por error y conmutación por error de prueba, se utiliza la copia de instantánea de SnapMirror más reciente o se puede seleccionar una copia de instantánea específica de una copia de instantánea de un punto en el tiempo (según la política de retención de SnapMirror). La opción de punto en el tiempo puede ser muy útil si se enfrenta a un evento de corrupción como ransomware, donde las réplicas más recientes ya están comprometidas o cifradas. DRO muestra todos los puntos disponibles en el tiempo. Para activar o probar la conmutación por error con la configuración especificada en el plan de replicación, puede hacer clic en Conmutación por error o Probar conmutación por error.
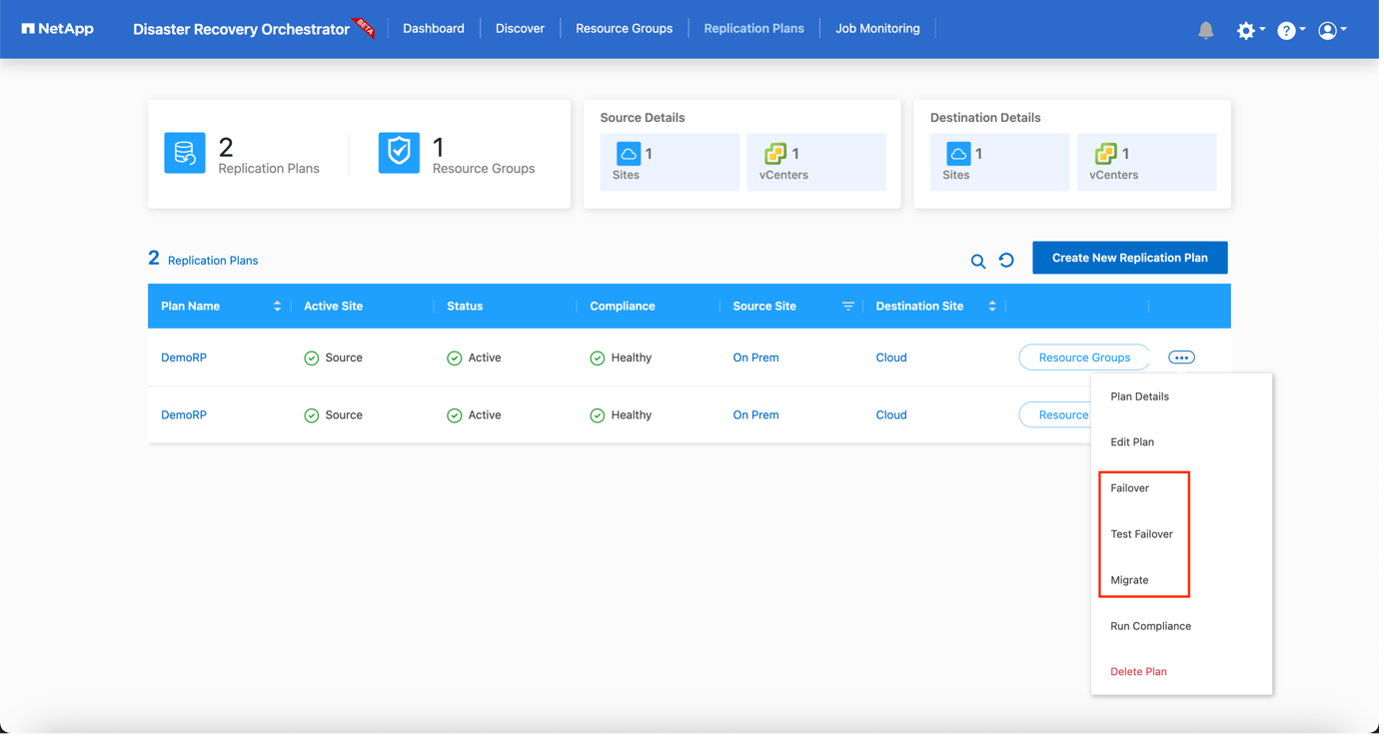
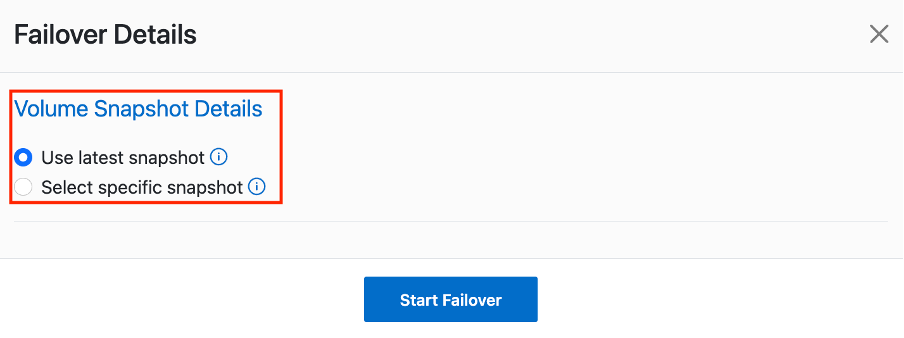
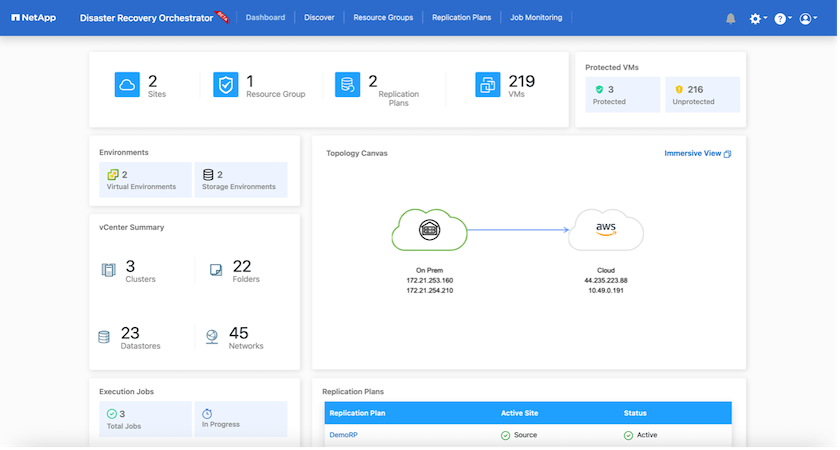
El plan de replicación se puede supervisar en el menú de tareas:
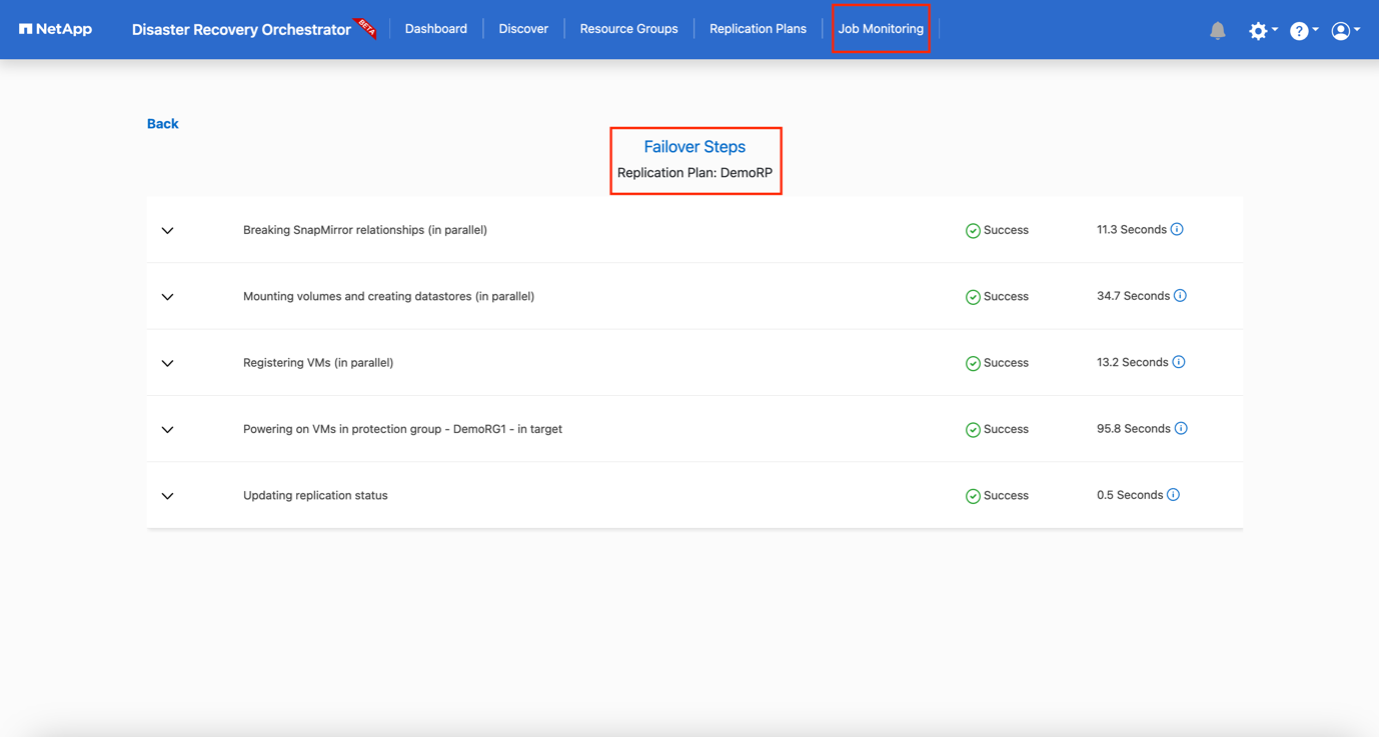
Una vez activada la conmutación por error, los elementos recuperados se pueden ver en el vCenter de VMC (máquinas virtuales, redes, almacenes de datos). De forma predeterminada, las máquinas virtuales se recuperan en la carpeta de carga de trabajo.
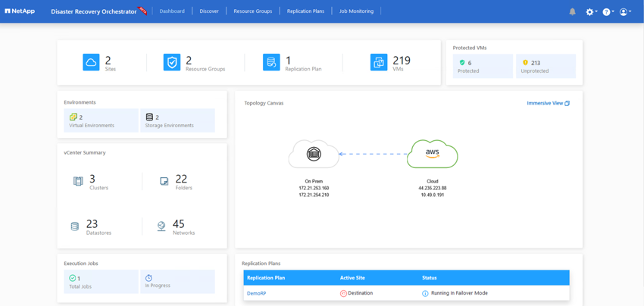
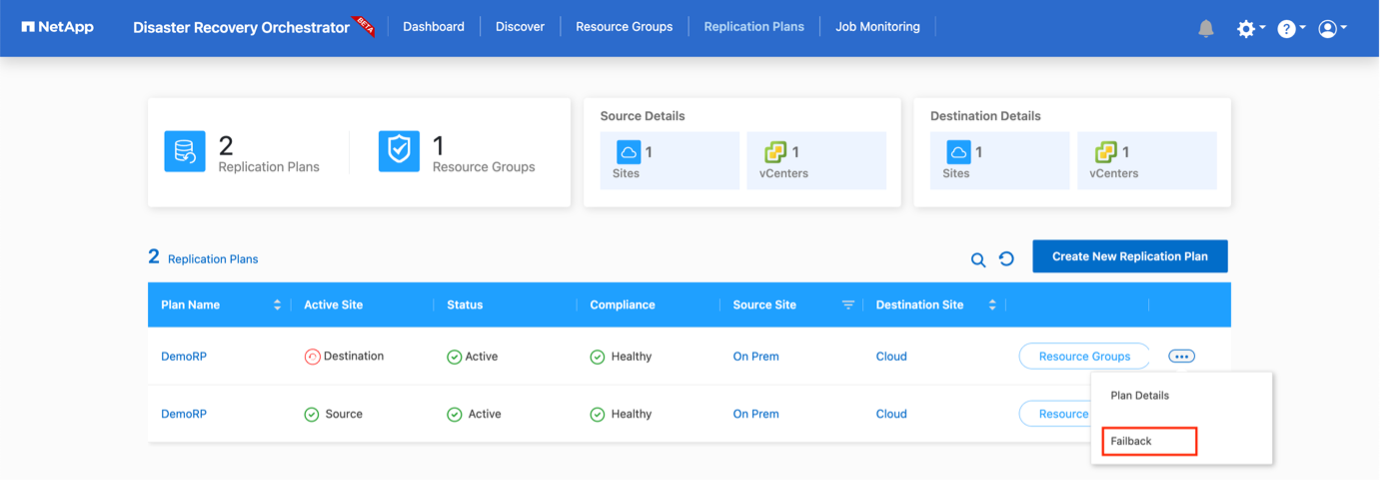
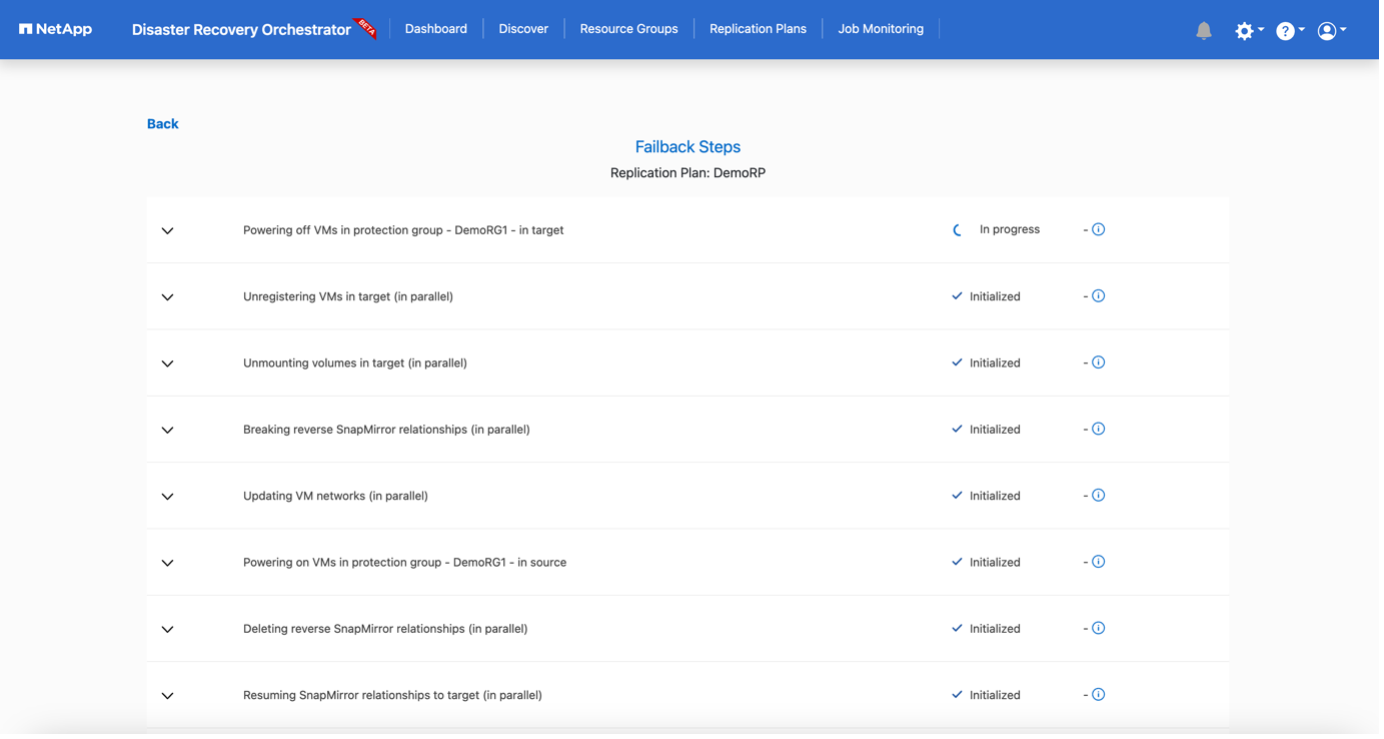
La conmutación por recuperación se puede activar en el nivel del plan de replicación. Para una conmutación por error de prueba, se puede utilizar la opción de desmantelamiento para revertir los cambios y eliminar la relación FlexClone . La recuperación relacionada con la conmutación por error es un proceso de dos pasos. Seleccione el plan de replicación y seleccione Sincronización inversa de datos.
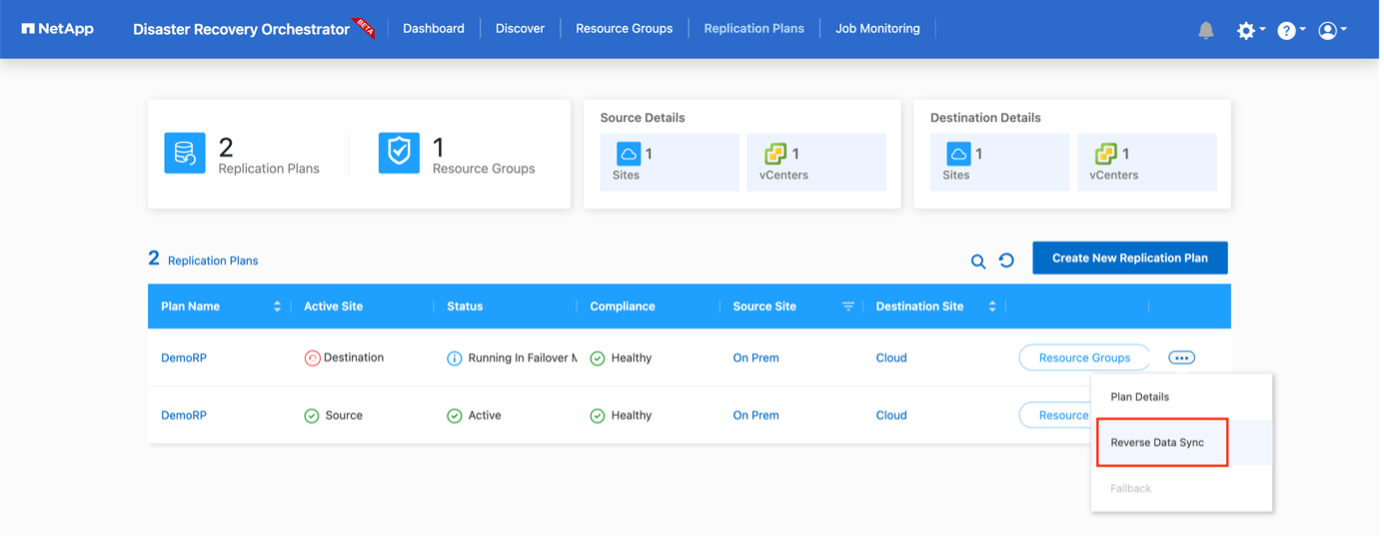
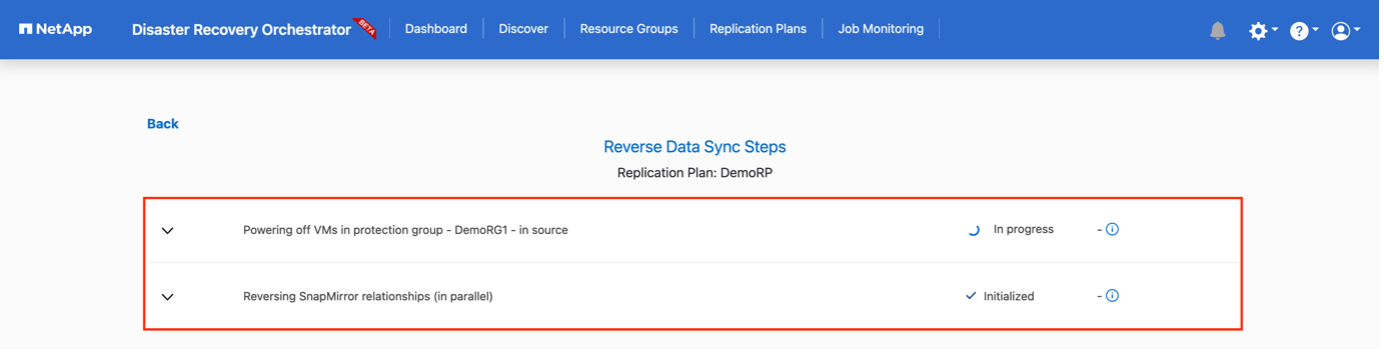
Una vez completado, puede activar la conmutación por error para regresar al sitio de producción original.
Desde NetApp BlueXP, podemos ver que la salud de la replicación se ha interrumpido para los volúmenes apropiados (aquellos que fueron asignados a VMC como volúmenes de lectura y escritura). Durante la conmutación por error de prueba, DRO no asigna el volumen de destino ni de réplica. En su lugar, realiza una copia FlexClone de la instancia de SnapMirror (o Snapshot) requerida y expone la instancia FlexClone , que no consume capacidad física adicional para FSx ONTAP. Este proceso garantiza que el volumen no se modifique y que los trabajos de réplica puedan continuar incluso durante las pruebas de recuperación ante desastres o los flujos de trabajo de clasificación. Además, este proceso garantiza que, si ocurren errores o se recuperan datos dañados, la recuperación se puede limpiar sin el riesgo de que se destruya la réplica.
Recuperación de ransomware
Recuperarse de un ransomware puede ser una tarea abrumadora. En concreto, puede resultar difícil para las organizaciones de TI determinar con precisión dónde está el punto de retorno seguro y, una vez determinado, proteger las cargas de trabajo recuperadas de ataques recurrentes, por ejemplo, de malware inactivo o aplicaciones vulnerables.
DRO aborda estos problemas permitiéndole recuperar su sistema desde cualquier momento disponible. También es posible recuperar cargas de trabajo en redes funcionales pero aisladas para que las aplicaciones puedan funcionar y comunicarse entre sí en una ubicación donde no estén expuestas al tráfico de norte a sur. Esto le brinda a su equipo de seguridad un lugar seguro para realizar análisis forenses y asegurarse de que no haya malware oculto o inactivo.
Beneficios
-
Uso de la replicación eficiente y resistente SnapMirror .
-
Recuperación a cualquier punto disponible en el tiempo con retención de copia instantánea.
-
Automatización completa de todos los pasos necesarios para recuperar cientos a miles de máquinas virtuales de los pasos de almacenamiento, computación, red y validación de aplicaciones.
-
Recuperación de carga de trabajo con tecnología ONTAP FlexClone utilizando un método que no cambia el volumen replicado.
-
Evita el riesgo de corrupción de datos en volúmenes o copias instantáneas.
-
Evita interrupciones de replicación durante los flujos de trabajo de prueba de DR.
-
Uso potencial de datos de DR con recursos de computación en la nube para flujos de trabajo más allá de DR, como DevTest, pruebas de seguridad, pruebas de parches o actualizaciones y pruebas de remediación.
-
-
Optimización de CPU y RAM para ayudar a reducir los costos de la nube al permitir la recuperación a clústeres de cómputo más pequeños.