

Uso de Veeam Replication y el almacén de datos de Azure NetApp Files para la recuperación ante desastres en Azure VMware Solution
 Sugerir cambios
Sugerir cambios
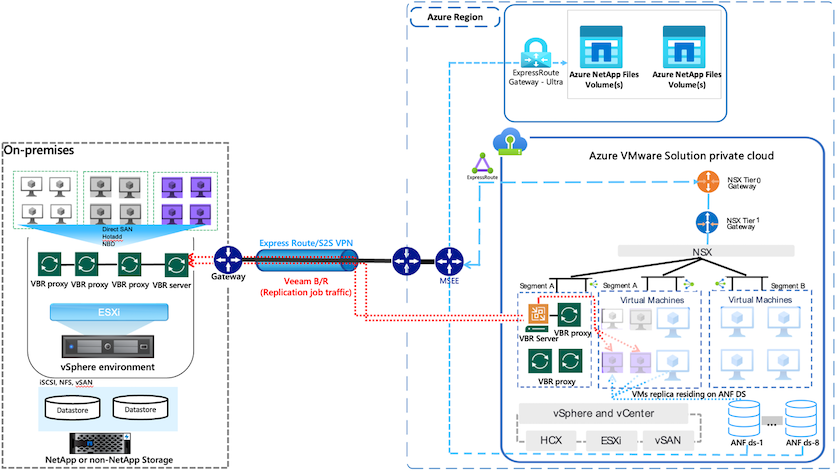
Los almacenes de datos de Azure NetApp Files (ANF) desacoplan el almacenamiento del procesamiento y liberan la flexibilidad necesaria para que cualquier organización lleve sus cargas de trabajo a la nube. Proporciona a los clientes una infraestructura de almacenamiento flexible y de alto rendimiento que escala independientemente de los recursos computacionales. El almacén de datos de Azure NetApp Files simplifica y optimiza la implementación junto con Azure VMware Solution (AVS) como un sitio de recuperación ante desastres para entornos VMWare locales.
Descripción general
Los almacenes de datos NFS basados en volúmenes de Azure NetApp Files (ANF) se pueden usar para replicar datos desde instalaciones locales mediante cualquier solución de terceros validada que proporcione capacidad de replicación de máquinas virtuales. Al agregar almacenes de datos de Azure NetApp Files , se permitirá una implementación con costos optimizados en comparación con la creación de un SDDC de Azure VMware Solution con una enorme cantidad de hosts ESXi para acomodar el almacenamiento. Este enfoque se denomina "grupo de luces piloto". Un clúster de luz piloto es una configuración de host AVS mínima (3 nodos AVS) junto con la capacidad del almacén de datos de Azure NetApp Files .
El objetivo es mantener una infraestructura de bajo costo con todos los componentes básicos para manejar una conmutación por error. Un clúster de luz piloto puede escalar horizontalmente y aprovisionar más hosts AVS si ocurre una conmutación por error. Y una vez que se completa la conmutación por error y se restablecen las operaciones normales, el grupo de luces piloto puede volver a un modo de operaciones de bajo costo.
Propósitos de este documento
En este artículo se describe cómo usar el almacén de datos de Azure NetApp Files con Veeam Backup and Replication para configurar la recuperación ante desastres de las máquinas virtuales VMware locales (AVS) mediante la funcionalidad del software de replicación de máquinas virtuales de Veeam.
Veeam Backup & Replication es una aplicación de backup y replicación para entornos virtuales. Cuando se replican máquinas virtuales, Veeam Backup & Replication se replica desde AVS, el software creará una copia exacta de las máquinas virtuales en el formato nativo de VMware vSphere en el clúster SDDC de AVS de destino. Veeam Backup & Replication mantendrá la copia sincronizada con la VM original. La replicación proporciona el mejor objetivo de tiempo de recuperación (RTO) ya que hay una copia montada de una máquina virtual en el sitio de recuperación ante desastres en un estado listo para iniciarse.
Este mecanismo de replicación garantiza que las cargas de trabajo puedan iniciarse rápidamente en un SDDC de AVS en caso de un desastre. El software Veeam Backup & Replication también optimiza la transmisión de tráfico para la replicación a través de WAN y conexiones lentas. Además, también filtra bloques de datos duplicados, bloques de datos cero, archivos de intercambio y "archivos del sistema operativo invitado de VM excluidos". El software también comprimirá el tráfico de réplicas. Para evitar que los trabajos de replicación consuman todo el ancho de banda de la red, se pueden utilizar aceleradores de WAN y reglas de limitación de red.
El proceso de replicación en Veeam Backup & Replication está impulsado por trabajos, lo que significa que la replicación se realiza mediante la configuración de trabajos de replicación. En el caso de un evento de desastre, se puede activar la conmutación por error para recuperar las máquinas virtuales mediante la conmutación por error a su copia de réplica. Cuando se realiza una conmutación por error, una VM replicada asume el rol de la VM original. La conmutación por error se puede realizar al último estado de una réplica o a cualquiera de sus puntos de restauración conocidos. Esto permite la recuperación de ransomware o pruebas aisladas según sea necesario. Veeam Backup & Replication ofrece múltiples opciones para gestionar diferentes escenarios de recuperación ante desastres.
Implementación de la solución
Pasos de alto nivel
-
El software Veeam Backup and Replication se ejecuta en un entorno local con conectividad de red adecuada.
-
"Implementar Azure VMware Solution (AVS)"nube privada y"Adjuntar almacenes de datos de Azure NetApp Files" a los hosts de Azure VMware Solution.
Se puede utilizar un entorno de luz piloto configurado con una configuración mínima para fines de recuperación ante desastres. Las máquinas virtuales conmutarán a este clúster en caso de un incidente y se podrán agregar nodos adicionales).
-
Configure el trabajo de replicación para crear réplicas de máquinas virtuales mediante Veeam Backup and Replication.
-
Cree un plan de conmutación por error y realice la conmutación por error.
-
Vuelva a las máquinas virtuales de producción una vez que se complete el evento de desastre y el sitio principal esté activo.
Requisitos previos para la replicación de máquinas virtuales de Veeam en almacenes de datos AVS y ANF
-
Asegúrese de que la máquina virtual de respaldo de Veeam Backup & Replication esté conectada a los clústeres AVS SDDC de origen y de destino.
-
El servidor de respaldo debe poder resolver nombres cortos y conectarse a los vCenter de origen y de destino.
-
El almacén de datos de destino de Azure NetApp Files debe tener suficiente espacio libre para almacenar los VMDK de las máquinas virtuales replicadas.
Para obtener información adicional, consulte el apartado "Consideraciones y limitaciones""aquí" .
Detalles de la implementación
Paso 1: replicar máquinas virtuales
Veeam Backup & Replication aprovecha las capacidades de instantáneas de VMware vSphere. Durante la replicación, Veeam Backup & Replication solicita a VMware vSphere que cree una instantánea de la máquina virtual. La instantánea de VM es la copia puntual de una VM que incluye discos virtuales, estado del sistema, configuración y metadatos. Veeam Backup & Replication utiliza la instantánea como fuente de datos para la replicación.
Para replicar máquinas virtuales, siga los pasos a continuación:
-
Abra la consola de Veeam Backup & Replication.
-
En la vista de inicio. Haga clic con el botón derecho en el nodo de trabajos y seleccione Trabajo de replicación > Máquina virtual.
-
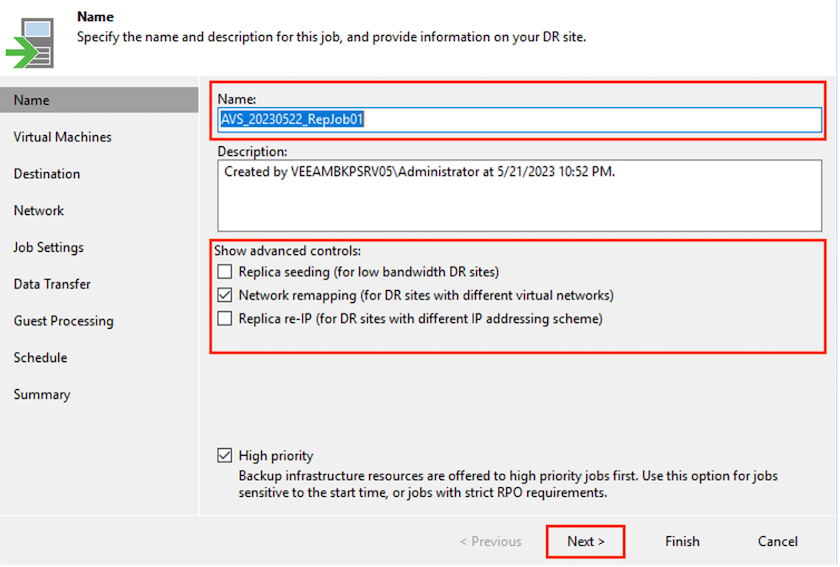
Especifique un nombre de trabajo y seleccione la casilla de verificación de control avanzado adecuada. Haga clic en Siguiente.
-
Seleccione la casilla de verificación Siembra de réplicas si la conectividad entre las instalaciones locales y Azure tiene un ancho de banda restringido. *Seleccione la casilla de verificación Reasignación de red (para sitios AVS SDDC con redes diferentes) si los segmentos en Azure VMware Solution SDDC no coinciden con los de las redes del sitio local.
-
Si el esquema de direccionamiento IP en el sitio de producción local difiere del esquema en el sitio AVS de destino, seleccione la casilla de verificación Re-IP de réplica (para sitios DR con esquema de direccionamiento IP diferente).
-
-
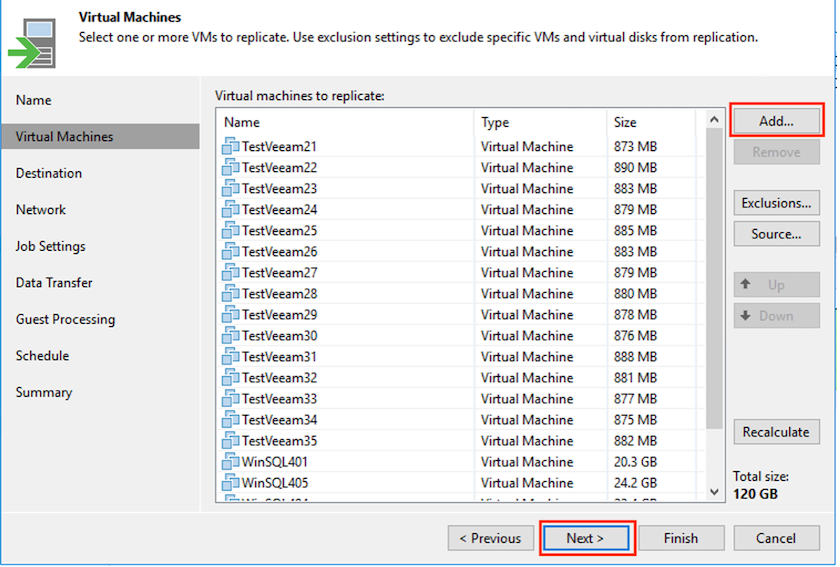
Seleccione las máquinas virtuales que se replicarán en el almacén de datos de Azure NetApp Files conectado a un SDDC de Azure VMware Solution en el paso Máquinas virtuales. Las máquinas virtuales se pueden colocar en vSAN para llenar la capacidad del almacén de datos de vSAN disponible. En un clúster de luz piloto, la capacidad utilizable de un clúster de 3 nodos será limitada. El resto de los datos se pueden colocar fácilmente en almacenes de datos de Azure NetApp Files para que las máquinas virtuales se puedan recuperar y el clúster se pueda expandir para cumplir con los requisitos de CPU/memoria. Haga clic en Agregar, luego en la ventana Agregar objeto seleccione las máquinas virtuales o los contenedores de máquinas virtuales necesarios y haga clic en Agregar. Haga clic en Siguiente.
-
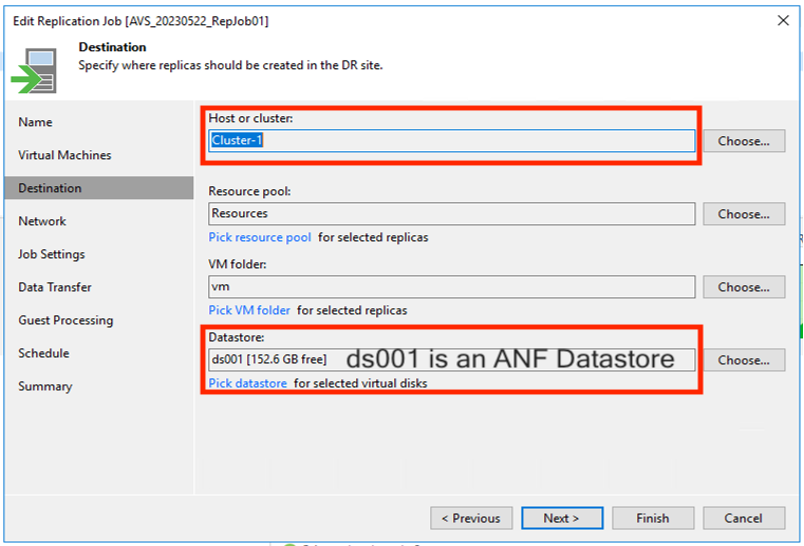
Después de eso, seleccione el destino como clúster/host SDDC de Azure VMware Solution y el grupo de recursos adecuado, la carpeta de VM y el almacén de datos FSx ONTAP para las réplicas de VM. Luego haga clic en Siguiente.
-
En el siguiente paso, cree la asignación entre la red virtual de origen y de destino según sea necesario.
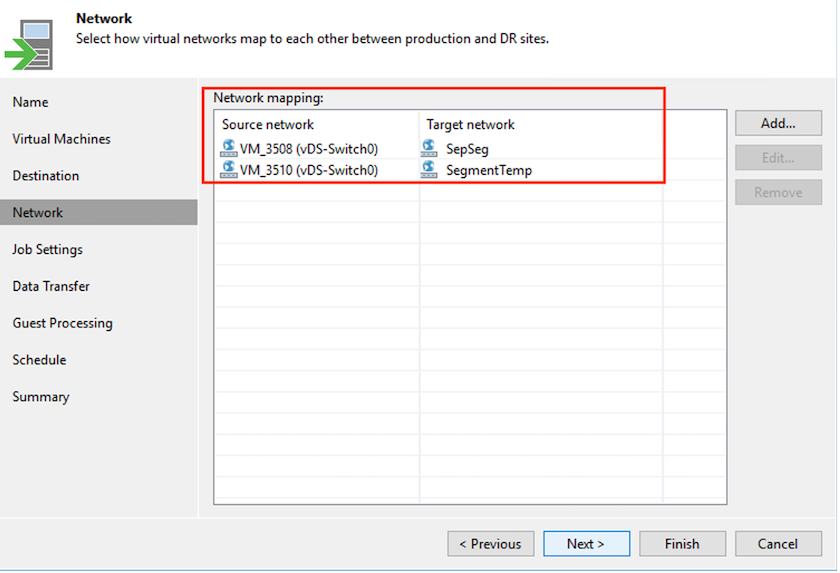
-
En el paso Configuración del trabajo, especifique el repositorio de respaldo que almacenará metadatos para las réplicas de VM, la política de retención, etc.
-
Actualice los servidores proxy Origen y Destino en el paso Transferencia de datos y deje la selección Automática (predeterminada) y mantenga seleccionada la opción Directa y haga clic en Siguiente.
-
En el paso Procesamiento de invitado, seleccione la opción Habilitar procesamiento consciente de la aplicación según sea necesario. Haga clic en Siguiente.
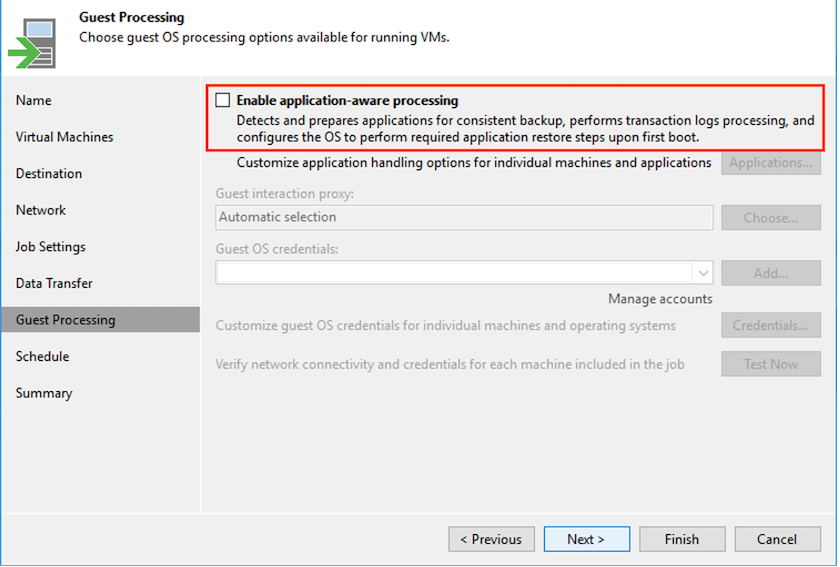
-
Seleccione la programación de replicación para ejecutar el trabajo de replicación de manera periódica.
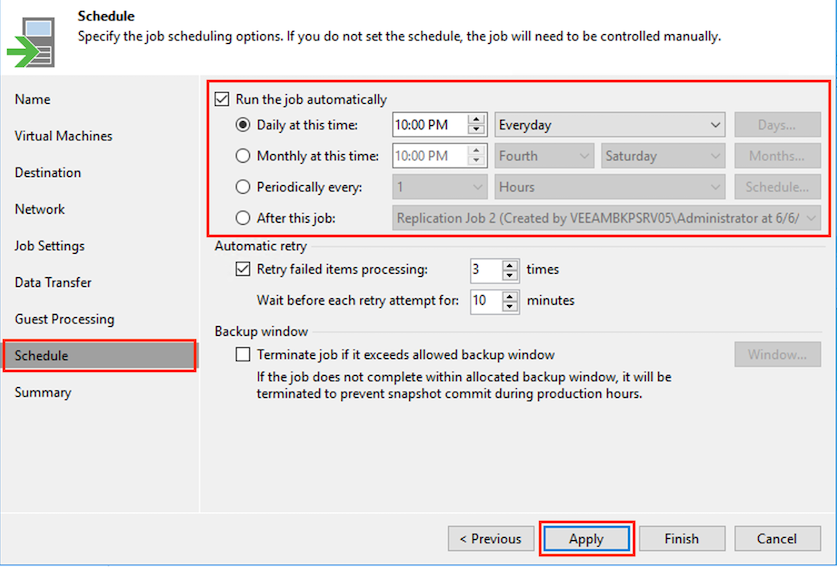
-
En el paso Resumen del asistente, revise los detalles del trabajo de replicación. Para iniciar el trabajo inmediatamente después de cerrar el asistente, seleccione la casilla de verificación Ejecutar el trabajo al hacer clic en Finalizar; de lo contrario, deje la casilla de verificación sin seleccionar. Luego haga clic en Finalizar para cerrar el asistente.
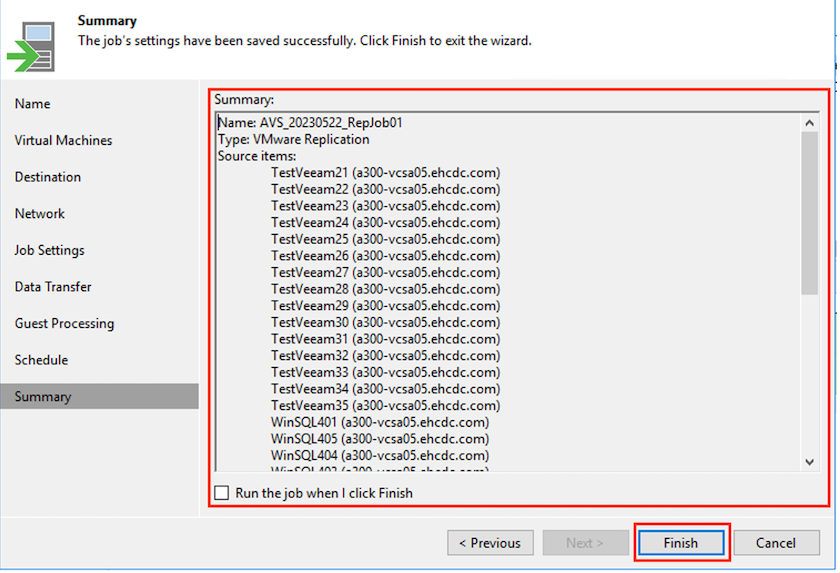
Una vez que se inicia el trabajo de replicación, las máquinas virtuales con el sufijo especificado se completarán en el clúster/host de AVS SDDC de destino.
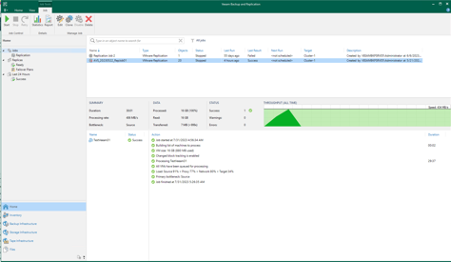
Para obtener información adicional sobre la replicación de Veeam, consulte"Cómo funciona la replicación"
Paso 2: Crear un plan de conmutación por error
Cuando se complete la replicación o siembra inicial, cree el plan de conmutación por error. El plan de conmutación por error ayuda a realizar la conmutación por error de las máquinas virtuales dependientes una por una o como grupo de manera automática. El plan de conmutación por error es el modelo para el orden en que se procesan las máquinas virtuales, incluidos los retrasos en el arranque. El plan de conmutación por error también ayuda a garantizar que las máquinas virtuales dependientes críticas ya estén en ejecución.
Para crear el plan, navegue a la nueva subsección llamada Réplicas y seleccione Plan de conmutación por error. Seleccione las máquinas virtuales adecuadas. Veeam Backup & Replication buscará los puntos de restauración más cercanos a este punto en el tiempo y los utilizará para iniciar réplicas de máquinas virtuales.

|
El plan de conmutación por error solo se puede agregar una vez que se completa la replicación inicial y las réplicas de la máquina virtual están en estado Listo. |
|
|
La cantidad máxima de máquinas virtuales que se pueden iniciar simultáneamente cuando se ejecuta un plan de conmutación por error es 10 |
|
|
Durante el proceso de conmutación por error, las máquinas virtuales de origen no se apagarán |
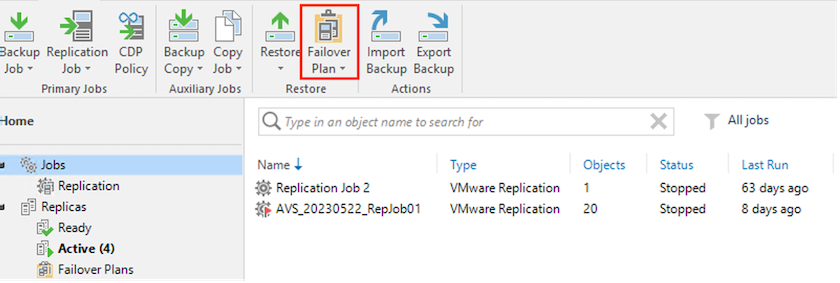
Para crear el Plan de conmutación por error, haga lo siguiente:
-
En la vista de inicio. Haga clic con el botón derecho en el nodo Réplicas y seleccione Planes de conmutación por error > Plan de conmutación por error > VMware vSphere.
-
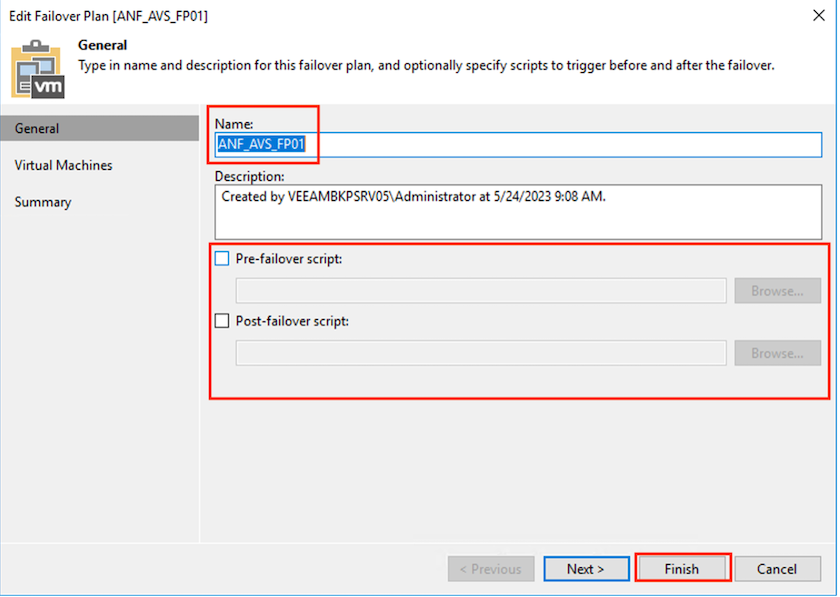
A continuación, proporcione un nombre y una descripción al plan. Se pueden agregar scripts previos y posteriores a la conmutación por error según sea necesario. Por ejemplo, ejecute un script para apagar las máquinas virtuales antes de iniciar las máquinas virtuales replicadas.
-
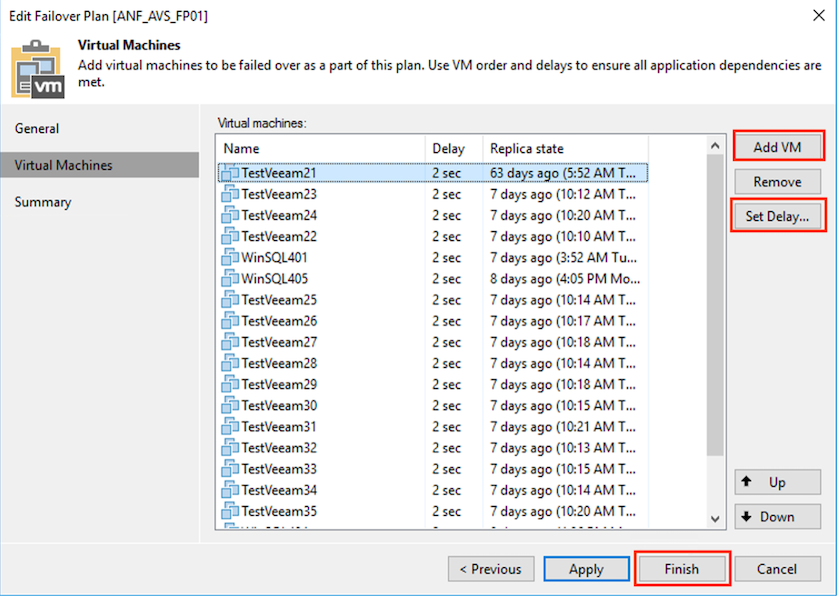
Agregue las máquinas virtuales al plan y modifique el orden de arranque de las máquinas virtuales y los retrasos de arranque para cumplir con las dependencias de la aplicación.
Para obtener información adicional sobre la creación de trabajos de replicación, consulte"Creación de trabajos de replicación" .
Paso 3: Ejecutar el plan de conmutación por error
Durante la conmutación por error, la máquina virtual de origen en el sitio de producción se cambia a su réplica en el sitio de recuperación ante desastres. Como parte del proceso de conmutación por error, Veeam Backup & Replication restaura la réplica de la máquina virtual al punto de restauración requerido y mueve todas las actividades de E/S de la máquina virtual de origen a su réplica. Las réplicas se pueden utilizar no sólo en caso de desastre, sino también para simular simulacros de recuperación ante desastres. Durante la simulación de conmutación por error, la máquina virtual de origen permanece en ejecución. Una vez que se hayan realizado todas las pruebas necesarias, puede deshacer la conmutación por error y volver a las operaciones normales.
|
|
Asegúrese de que la segmentación de la red esté implementada para evitar conflictos de IP durante la conmutación por error. |
Para iniciar el plan de conmutación por error, simplemente haga clic en la pestaña Planes de conmutación por error y haga clic derecho en su plan de conmutación por error. Seleccione *Inicio. Esto conmutará por error utilizando los últimos puntos de restauración de las réplicas de VM. Para conmutar por error a puntos de restauración específicos de réplicas de máquinas virtuales, seleccione Iniciar en.
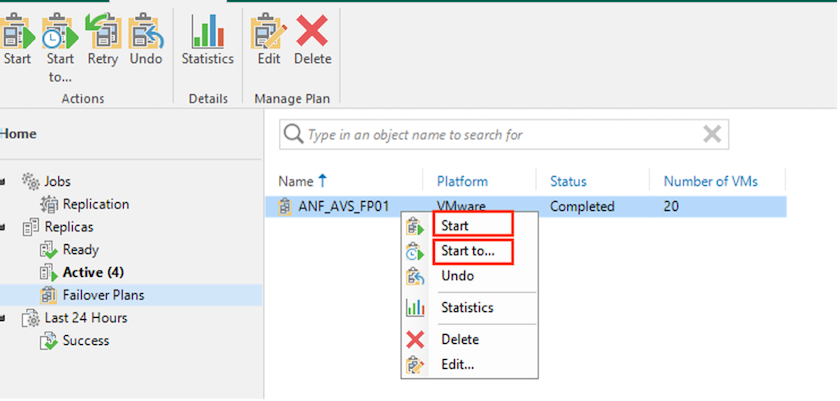
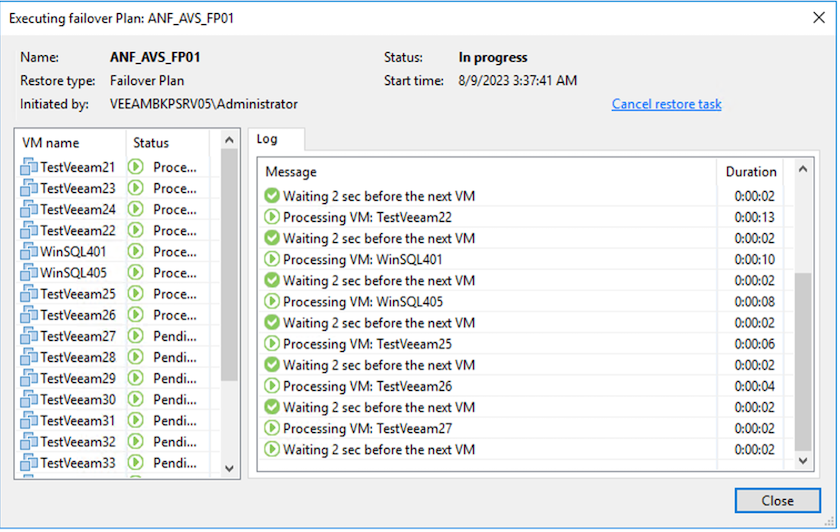
El estado de la réplica de la máquina virtual cambia de Listo a Conmutación por error y las máquinas virtuales se iniciarán en el host/clúster SDDC de Azure VMware Solution (AVS) de destino.
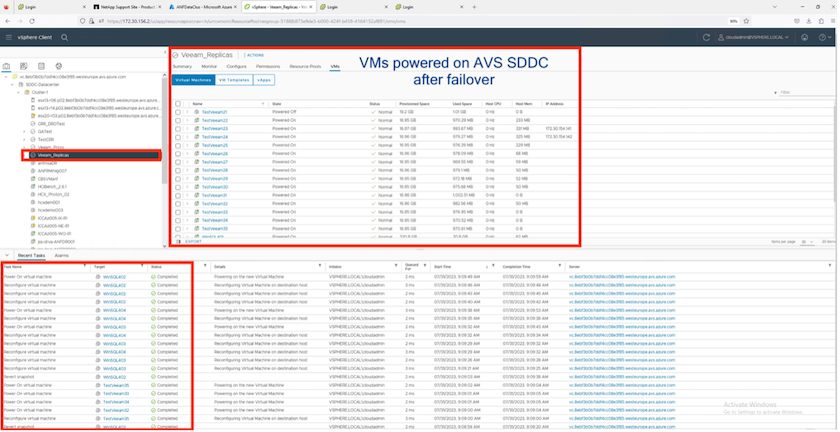
Una vez completada la conmutación por error, el estado de las máquinas virtuales cambiará a "Conmutación por error".
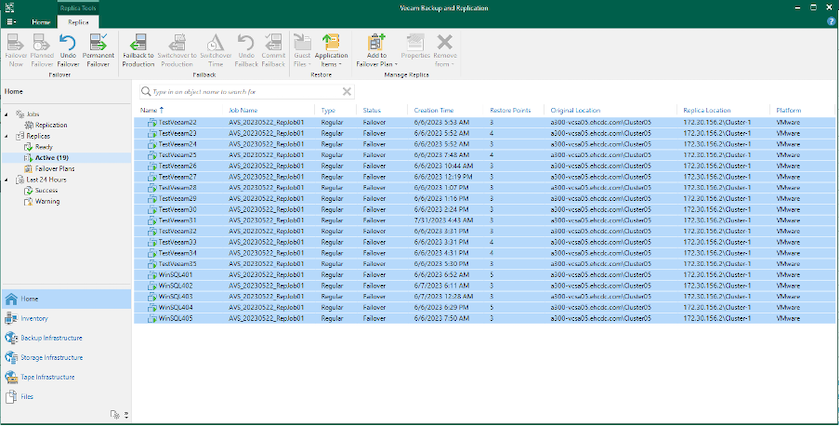
|
|
Veeam Backup & Replication detiene todas las actividades de replicación de la máquina virtual de origen hasta que su réplica vuelva al estado Listo. |
Para obtener información detallada sobre los planes de conmutación por error, consulte"Planes de conmutación por error" .
Paso 4: Retorno al sitio de producción
Cuando se ejecuta el plan de conmutación por error, se lo considera un paso intermedio y debe finalizarse según el requisito. Las opciones incluyen lo siguiente:
-
Retorno a producción: vuelve a la máquina virtual original y transfiere todos los cambios que tuvieron lugar mientras la réplica de la máquina virtual estaba en ejecución a la máquina virtual original.
|
|
Al realizar una conmutación por error, los cambios solo se transfieren, pero no se publican. Seleccione Confirmar conmutación por error (una vez que se confirme que la VM original funciona como se espera) o Deshacer conmutación por error para volver a la réplica de la VM si la VM original no funciona como se espera. |
-
Deshacer conmutación por error: vuelve a la máquina virtual original y descarta todos los cambios realizados en la réplica de la máquina virtual mientras estaba en ejecución.
-
Conmutación por error permanente: cambia de forma permanente de la máquina virtual original a una réplica de máquina virtual y utiliza esta réplica como la máquina virtual original.
En esta demostración, se eligió Failback a producción. Se seleccionó la opción de retorno a la máquina virtual original durante el paso Destino del asistente y se habilitó la casilla de verificación "Encender la máquina virtual después de restaurar".
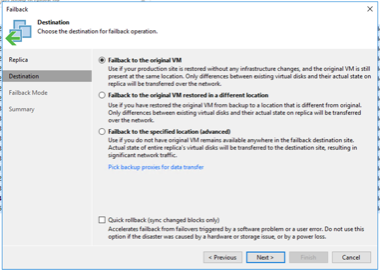
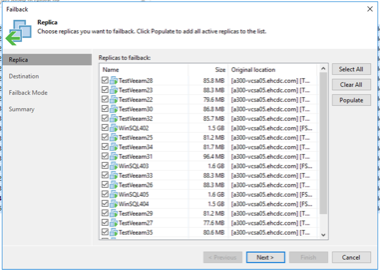
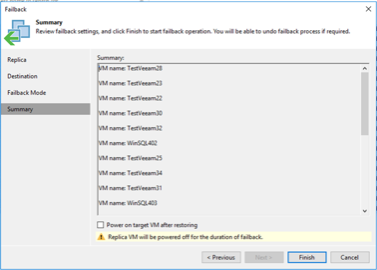
La confirmación de conmutación por error es una de las formas de finalizar la operación de conmutación por error. Cuando se confirma la conmutación por error, se confirma que los cambios enviados a la máquina virtual que se conmutó (la máquina virtual de producción) funcionan como se esperaba. Después de la operación de confirmación, Veeam Backup & Replication reanuda las actividades de replicación para la máquina virtual de producción.
Para obtener información detallada sobre el proceso de conmutación por error, consulte la documentación de Veeam."Conmutación por error y recuperación para replicación" .
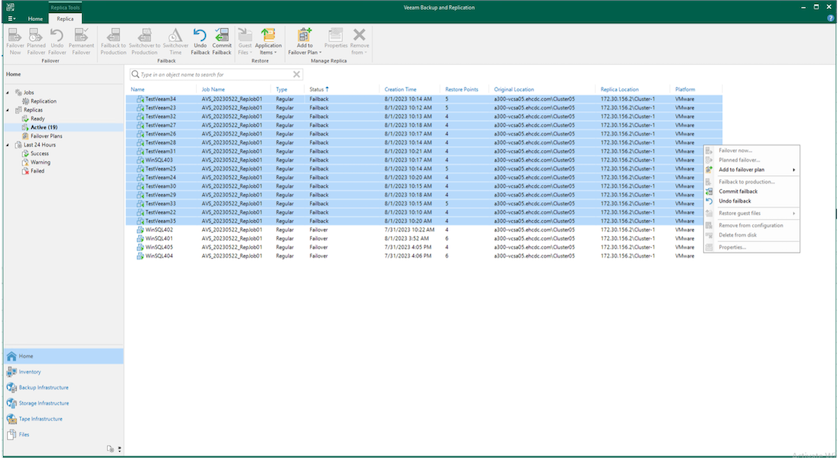
Una vez que la conmutación a producción es exitosa, todas las máquinas virtuales se restauran al sitio de producción original.
Conclusión
La capacidad de almacenamiento de datos de Azure NetApp Files permite que Veeam o cualquier herramienta de terceros validada proporcione una solución de recuperación ante desastres de bajo costo al aprovechar clústeres Pilot Light en lugar de crear un clúster grande solo para acomodar réplicas de máquinas virtuales. Esto proporciona una manera eficaz de gestionar un plan de recuperación ante desastres personalizado y adaptado, y de reutilizar los productos de respaldo existentes internamente para DR, lo que permite una recuperación ante desastres basada en la nube al salir de los centros de datos de DR locales. Es posible realizar una conmutación por error haciendo clic en un botón en caso de desastre o realizar una conmutación por error automáticamente si ocurre un desastre.
Para obtener más información sobre este proceso, no dude en seguir el video tutorial detallado.