

Configura los grupos de disponibilidad Always On de SQL Server con Google Cloud NetApp Volumes
 Sugerir cambios
Sugerir cambios
Configura grupos de disponibilidad Always On de SQL Server en instancias de Google Compute Engine dentro de una sola subred usando el almacenamiento en bloques iSCSI de Google Cloud NetApp Volumes. Aprende cómo configurar instancias de cómputo, configurar volúmenes de NetApp, establecer clústeres de conmutación por error y desplegar grupos de disponibilidad para alta disponibilidad y recuperación ante desastres.
Prerrequisitos
Antes de continuar, completa los pasos previos de configuración en la documentación de Google Cloud:
Antes de empezar
Asegúrate de haber cumplido los siguientes requisitos:
-
Proyecto de Google Cloud con permisos de administrador para compute, network, IAM y storage
-
Red VPC con subred para una región
-
Configuración de Active Directory y DNS disponible en una región
-
Reglas de firewall configuradas para permitir los puertos necesarios
-
Familiaridad con SQL Server Always On availability groups y failover clustering

|
Los nuevos usuarios de Google Cloud podrían ser elegibles para "créditos de prueba gratuitos". |
Objetivos
Configurar el grupo de disponibilidad Always On de SQL Server incluye las siguientes tareas a grandes rasgos:
-
Configura instancias de Compute Engine y volúmenes de almacenamiento NetApp
-
Configura SQL Server en ambos nodos
-
Configura Windows Server Failover Cluster
-
Configura el quórum del clúster con un testigo de recurso compartido de archivos
-
Configura grupos de disponibilidad de SQL Server
-
Configura el nombre de red distribuida (DNN) para el acceso de listener
Consideraciones de costes
Este tutorial utiliza componentes facturables de Google Cloud, incluidos "Instancias de Compute Engine" y "Google Cloud NetApp Volumes" almacenamiento.
Usa "Calculadora de precios" para generar una estimación de costes basada en tus requisitos de computación y almacenamiento. La configuración de ejemplo usa instancias de computación N4-SKU y almacenamiento de nivel de servicio NetApp Flex para la configuración del grupo de disponibilidad Always On de SQL Server.
Configura cuentas de dominio
Configura dos cuentas en Active Directory: una cuenta de instalación (tu cuenta de admin) y una cuenta de servicio para ambas VMs de SQL Server.
Por ejemplo, usa los valores de la siguiente tabla para las cuentas:
|
|
Este ejemplo usa cvsdemo como nombre de dominio. Reemplaza cvsdemo por tu nombre de dominio real en todo este procedimiento.
|
| Cuenta | VM | Nombre de dominio completo | Descripción |
|---|---|---|---|
<your account> |
Ambos (sqlnode1 y sqlnode2) |
cvsdemo\DomainAdmin |
Cuenta de administrador para iniciar sesión en cualquiera de las VM y configurar el clúster y el grupo de disponibilidad |
sqlsvc |
Ambos (sqlnode1 y sqlnode2) |
cvsdemo\sqlsvc |
Cuenta de servicio para SQL Server y SQL Server Agent en ambas SQL Server VMs |
Crea máquinas virtuales Compute Engine para SQL Server
Crea dos instancias de VM de Google Compute Engine con SQL Server 2022 Enterprise preinstalado en Windows Server 2025 para alojar las réplicas del grupo de disponibilidad.
-
En la consola de Google Cloud, ve a la página "Crear una instancia".
Consulta el "Documentación de Google Cloud" para más información.
-
Para Nombre, ingresa
sqlnode1. -
En la sección Machine configuration:
-
Selecciona General Purpose
-
En la lista Series, selecciona N4
-
En la lista Tipo de máquina, selecciona n4-highmem-8 (8 vCPU, 64 GB de memoria)
-
-
Selecciona la región donde creaste tu VPC (por ejemplo, region=us-west1, zone=us-west1-a).
-
En la sección Disco de arranque, haz clic en Cambiar:
-
En la pestaña Imágenes públicas, en la lista Sistema operativo, selecciona SQL Server en Windows Server.
-
En la lista Versión, selecciona SQL Server 2022 Enterprise en Windows Server 2025 Datacenter.
-
En la lista Tipo de disco de arranque, selecciona Hyperdisk Balanced.
-
En el campo Tamaño (GB), introduce 50 GB.
-
Haz clic en Select para guardar la configuración del disco de arranque.
-
-
En la sección Red, edita la interfaz de red para seleccionar la VPC y la subred correctas. Si solo tienes una red VPC, se seleccionará por defecto.
-
En la tarjeta de interfaz de red, selecciona gVNIC.
-
Para "Nivel de servicio de red", selecciona Premium para cargas de trabajo de misión crítica o Standard para optimizar costes.
-
-
Haz clic en Crear para crear la máquina virtual.
-
Repite estos pasos para crear
sqlnode2.
Unir servidores al dominio
Después de crear las máquinas virtuales, únelas al dominio de Active Directory e instala las funciones de Windows necesarias para la agrupación en clústeres de conmutación por error y la conectividad iSCSI.
-
Conéctate remotamente a la máquina virtual con la cuenta de administrador local.
-
En Administrador de servidores, selecciona Servidor local.
-
Selecciona el enlace WORKGROUP.
-
En la sección Nombre del ordenador, selecciona Cambiar.
-
Selecciona la casilla Dominio e ingresa tu dominio (por ejemplo,
cvsdemo.internal) en el cuadro de texto. -
Haz clic en OK.
-
En el cuadro de diálogo Seguridad de Windows, especifica las credenciales de la cuenta de administrador de dominio predeterminada (por ejemplo,
cvsdemo\DomainAdmin). -
Cuando veas el mensaje "Welcome to the cvsdemo.internal domain", haz clic en OK.
-
Haz clic en Cerrar y luego selecciona Reiniciar ahora en el cuadro de diálogo.
-
Después de reiniciar el servidor, añade la cuenta
sqlsvcal grupo de Administradores.
|
|
Tu instancia de SQL se ejecutará usando la cuenta sqlsvc, que es necesaria para la configuración de clustering y failover. |
Instala las funciones de Windows necesarias
Instala Failover Clustering y MPIO en ambas máquinas virtuales SQL Server usando Administrador de servidores o PowerShell.
-
En Administrador de servidores, selecciona Administrar > Agregar roles y características.
-
Selecciona Instalación basada en roles o en funciones y haz clic en Siguiente.
-
Selecciona tu servidor y haz clic en Siguiente.
-
En la página Features, selecciona Failover Clustering y Multipath I/O.
-
Haz clic en Add Features cuando se te pida que incluyas herramientas de gestión.
-
Completa el asistente y reinicia si se te solicita.
Ejecuta PowerShell como administrador y ejecuta los siguientes comandos:
# Install Failover Clustering and tools
Install-WindowsFeature Failover-Clustering, RSAT-Clustering-PowerShell, RSAT-Clustering-CmdInterface -IncludeAllSubFeature -IncludeManagementTools
# Install/enable MPIO
Install-WindowsFeature -Name Multipath-IO
Enable-MSDSMAutomaticClaim -BusType "iSCSI"
# Install .NET and other SQL prerequisites (if not already installed)
Install-WindowsFeature NET-Framework-45-Core, NET-Framework-45-Features
Install-WindowsFeature RSAT-AD-PowerShellObtener nombres de iniciadores iSCSI
Obtén el nombre cualificado iSCSI (IQN) para cada máquina virtual de SQL Server que quieras incluir en el grupo de hosts usando la GUI de iSCSI Initiator o PowerShell.
-
Pulsa Win+R o usa la barra de búsqueda de Windows para abrir
iscsicpl. -
En el cuadro de diálogo Propiedades del iniciador iSCSI, ve a la pestaña Configuración.
-
Copia el valor Initiator Name e inclúyelo en el grupo de hosts.
Ejemplo:
iqn.1991-05.com.microsoft:sqlnode1.cvsdemo.internal
Ejecuta el siguiente comando en PowerShell:
Get-InitiatorPort | Select-Object NodeAddressCrear NetApp volúmenes de almacenamiento en bloque
Crea volúmenes de almacenamiento en bloque iSCSI usando Google Cloud NetApp Volumes para proporcionar almacenamiento compartido de alto rendimiento para bases de datos de SQL Server. Este proceso incluye crear un grupo de hosts, un grupo de almacenamiento y volúmenes individuales para datos, registros, temp y backup.
Crea el grupo de hosts
-
Crea un grupo de hosts que contenga los iniciadores iSCSI de ambos nodos SQL.
gcloud beta netapp host-groups create HOST_GROUP_NAME \ --location=LOCATION \ --type=ISCSI_INITIATOR \ --hosts=HOSTS \ --os-type=OS_TYPE \ --description=DESCRIPTIONPara más detalles, consulta la documentación de "Crear un grupo de hosts".
-
Reemplaza los siguientes valores:
-
HOST_GROUP_NAME: nombre del grupo de host (por ejemplo,demosql) -
LOCATION: región (por ejemplo,us-west1) -
HOSTS: lista separada por comas de IQNs de sqlnode1 y sqlnode2Ejemplo:
iqn.1991-05.com.microsoft:sqlnode1.cvsdemo.internal,iqn.1991-05.com.microsoft:sqlnode2.cvsdemo.internal -
OS_TYPE: tipo de sistema operativo (por ejemplo,WINDOWS) -
DESCRIPTION: descripción opcional del grupo de hosts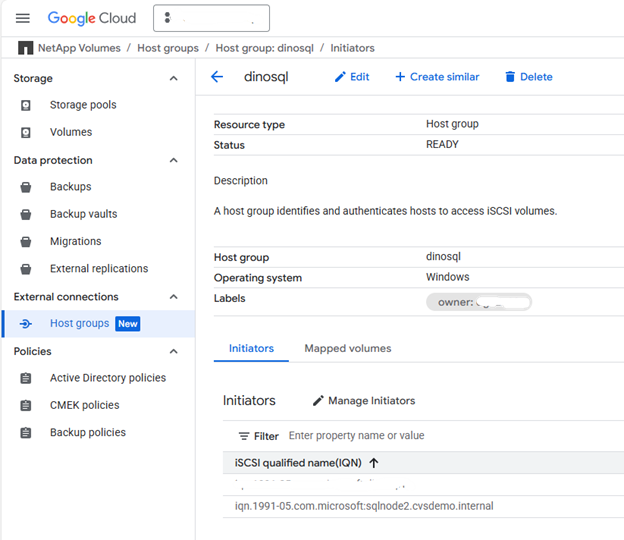
-
Crear grupo de almacenamiento
-
Crea un grupo de almacenamiento con la capacidad y el rendimiento adecuados.
gcloud netapp storage-pools create POOL_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --service-level=Flex \ --type=Unified \ --capacity=1024 \ --total-throughput=64 \ --total-iops=1024 \ --network=name=VPC_NAME,psa-range=PSA_RANGEPara más detalles, consulta la documentación de "Crear un grupo de almacenamiento".
-
Reemplaza los siguientes valores:
-
POOL_NAME: nombre del pool (por ejemplo,sqltest) -
PROJECT_ID: el nombre de tu proyecto de Google Cloud -
LOCATION: la misma ubicación que tus instancias de computación (por ejemplo,us-west1-b) -
CAPACITY: capacidad del pool en GiB (por ejemplo,1024) -
SERVICE_LEVEL: nivel de servicio (por ejemplo,Flex) -
VPC_NAME: el nombre de tu red VPC -
PSA_RANGE: rango de Private Services Access (por ejemplo,xx.xxx.xxx.0/20) -
THROUGHPUT: rendimiento opcional en MiBps (por ejemplo,64) -
IOPS: IOPS opcionales (por ejemplo,1024)
-
Crear volúmenes
-
Crea volúmenes para datos, registros, temporales y copias de seguridad. Ejecuta el siguiente comando para cada tipo de volumen:
gcloud beta netapp volumes create VOLUME_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --storage-pool=POOL_NAME \ --capacity=CAPACITY \ --protocols=ISCSI \ --block-devices="name=VOLUME_NAME,host-groups=HOST_GROUP_PATH,os-type=WINDOWS" \ --snapshot-directory=falsePara más detalles, consulta la documentación de "Crear un volumen".
-
Reemplaza los siguientes valores:
-
VOLUME_NAME: Nombre único para cada volumen (por ejemplo,node1data,node1log,node1temp,node1backup) -
PROJECT_ID: el nombre de tu proyecto de Google Cloud -
LOCATION: misma ubicación que el grupo de almacenamiento (por ejemplo,us-west1-b) -
POOL_NAME: nombre del grupo de almacenamiento (por ejemplo,sqltest) -
CAPACITY: capacidad de volumen en GiB (por ejemplo,200) -
HOST_GROUP_PATH: Ruta completa del recurso al grupo de hosts (por ejemplo,projects/PROJECT_ID/locations/us-west1/hostGroups/demosql)
-

|
Se pueden especificar varios grupos de hosts con el signo # separando cada grupo de hosts. |
|
|
Repite este paso para cada tipo de volumen: data, log, temp y backup. |
Montar volúmenes iSCSI
Monta los volúmenes iSCSI no compartidos en cada instancia SQL:
-
En la consola de Google Cloud, ve a NetApp volumes > Volumes.
-
Selecciona el volumen creado para la instancia de SQL (por ejemplo,
node1data). -
Copia las dos direcciones IP del destino iSCSI (por ejemplo,
10.165.128.216y10.165.128.217). -
En sqlnode1, ejecuta
iscsicplo usa PowerShell: -
Haz clic en la pestaña Discover y luego en Discover Portal.
-
Agrega cada dirección IP obtenida; deja el puerto predeterminado 3260.
"10.165.128.216","10.165.128.217" | % { New-IscsiTargetPortal -TargetPortalAddress $_ }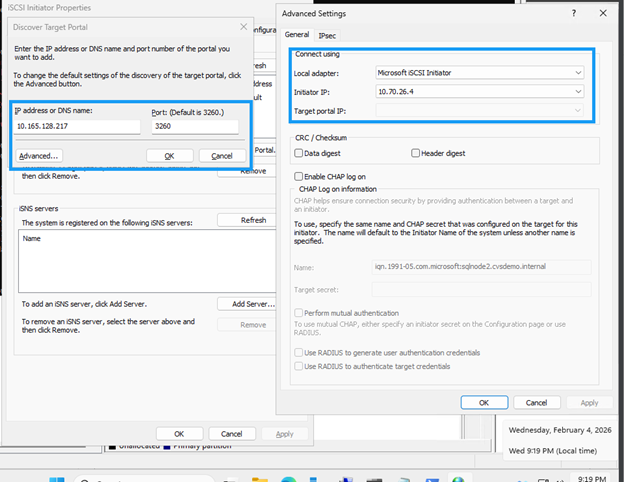
-
En el cuadro de diálogo Connect to Target, marca Enable multi-path si usas multivía.
-
Haz clic en Avanzado y selecciona la dirección IP del portal de destino en el menú desplegable.
-
Haz clic en OK para conectarte.
-
Configura MPIO para dispositivos iSCSI
-
Abre MPIO desde el Panel de control o el Administrador de servidores.
-
Haz clic en la pestaña Descubrir rutas múltiples.
-
Marca Add support for iSCSI devices y haz clic en Add.
-
Reinicia si se te solicita.
-
Verifica la configuración de multivía en Device Manager en Disk drives.
-
-
Inicializar y formatear volúmenes
-
Lanza Administración de equipos (
compmgmt.msc) y selecciona Administración de discos. -
Inicializa, particiona y formatea cada disco con una unidad de asignación de 64K:
Format-Volume -DriveLetter <DriveLetter> -FileSystem NTFS -NewFileSystemLabel <Label> -AllocationUnitSize 65536 -Confirm:$false -
Asigna letras de unidad (por ejemplo, D: para datos, E: para log, F: para backup, G: para temp).
-
Crea la estructura de directorios para SQL Server:
$paths = "D:\MSSQL\DATA","E:\MSSQL\Log","F:\MSSQL\Backup","G:\MSSQL\Temp" $paths | % { New-Item -ItemType Directory -Path $_ -Force }
-
Configura SQL Server
Configura SQL Server en ambos nodos para usar la cuenta de servicio de dominio, actualiza las rutas predeterminadas para usar los volúmenes de NetApp y mueve las bases de datos del sistema a las nuevas ubicaciones de almacenamiento.
-
Actualiza los servicios SQL Server y SQL Server Agent para que se ejecuten bajo la cuenta de servicio de dominio para la autenticación del clúster y el soporte de conmutación por error.
-
En cada instancia SQL, abre
services.msc. -
Actualiza Log on as a
domain\sqlsvcpara los servicios SQL Server y SQL Server Agent. -
Abre SQL Server Management Studio (SSMS) y conéctate con tu cuenta de dominio.
Si la conexión falla, inicia SSMS como
<local computer>\Administrator. Asegúrate de que la cuenta de Administrador está habilitada en Usuarios y Grupos con la contraseña apropiada.
-
-
Crea los inicios de sesión de la cuenta de dominio con los permisos necesarios.
Reemplaza CVSDEMOpor tu nombre de dominio real en los siguientes comandos SQL.USE [master] GO -- Create login for SQL service account CREATE LOGIN [CVSDEMO\sqlsvc] FROM WINDOWS WITH DEFAULT_DATABASE=[master], DEFAULT_LANGUAGE=[us_english] GO -- Add to sysadmin role ALTER SERVER ROLE [sysadmin] ADD MEMBER [CVSDEMO\sqlsvc] GO -- Create user in master and assign role USE [master] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO -- Repeat for model, msdb, and tempdb databases USE [model] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO USE [msdb] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO USE [tempdb] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO -
Actualiza las rutas por defecto para usar los volúmenes de NetApp en vez de la unidad del sistema operativo:
USE [master] GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'BackupDirectory', REG_SZ, N'F:\MSSQL\Backup' GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'DefaultData', REG_SZ, N'D:\MSSQL\DATA' GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'DefaultLog', REG_SZ, N'E:\MSSQL\Log' GO -
Mueve las bases de datos del sistema (model, msdb, tempdb y master) de la unidad del sistema operativo a los volúmenes de NetApp para un mejor rendimiento y gestión.
-
Verifica las rutas actuales:
-- Check current paths SELECT name, physical_name FROM sys.master_files WHERE database_id IN (DB_ID('model'), DB_ID('msdb')); -
Actualiza a nuevas ubicaciones:
-- Move model database ALTER DATABASE model MODIFY FILE (NAME = modeldev, FILENAME = 'D:\MSSQL\Data\model.mdf'); ALTER DATABASE model MODIFY FILE (NAME = modellog, FILENAME = 'E:\MSSQL\Log\modellog.ldf'); -- Move msdb database ALTER DATABASE msdb MODIFY FILE (NAME = MSDBData, FILENAME = 'D:\MSSQL\Data\MSDBData.mdf'); ALTER DATABASE msdb MODIFY FILE (NAME = MSDBLog, FILENAME = 'E:\MSSQL\Log\MSDBLog.ldf'); GO -
Detén SQL Server, mueve manualmente los archivos de la ubicación antigua a las nuevas rutas y luego reinicia SQL Server.
-
Mover la base de datos tempdb
USE master; GO -- Check current tempdb files SELECT name, physical_name FROM sys.master_files WHERE database_id = DB_ID('tempdb'); -- Change paths for tempdb ALTER DATABASE tempdb MODIFY FILE (NAME = tempdev, FILENAME = 'G:\MSSQL\Temp\tempdb.mdf'); ALTER DATABASE tempdb MODIFY FILE (NAME = templog, FILENAME = 'G:\MSSQL\Temp\templog.ldf'); GO -
Reinicia SQL Server para que los cambios surtan efecto:
Restart-Service -Name "MSSQLSERVER" -Force
-
-
Mueve la base de datos maestra
-
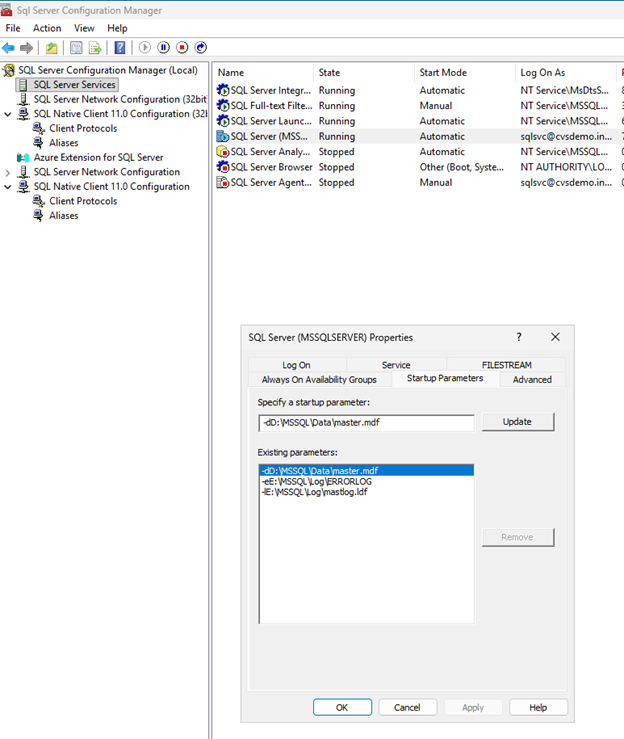
Abre SQL Server Configuration Manager.
-
Ve a SQL Server Services, haz clic derecho en SQL Server (MSSQLSERVER) y selecciona Properties.
-
Haz clic en la pestaña Parámetros de inicio.
-
En Parámetros existentes, localiza los parámetros que empiezan por
-d,-ey-l. -
Elimina los parámetros antiguos y añade los nuevos:
-dD:\MSSQL\Data\master.mdf -lE:\MSSQL\Log\mastlog.ldf -eE:\MSSQL\Log\ERRORLOG
-
Haz clic en OK.
-
-
Detén el servicio SQL Server.
-
Mueve manualmente
master.mdfymastlog.ldfde la ubicación anterior a las nuevas rutas. -
Si actualizaste la ruta del registro de errores, mueve también el archivo
ERRORLOG. -
Inicia el servicio SQL Server.
Configura el clúster de conmutación por error
Configura Windows Server Failover Clustering para proporcionar alta disponibilidad para SQL Server. Para más detalles, consulta "Documentación de Windows Server Failover Clustering".
Configura las reglas del cortafuegos
Abre los puertos de red necesarios en ambos nodos SQL para permitir la comunicación del clúster, la conectividad de SQL Server y la replicación del grupo de disponibilidad.
-
Abre los puertos necesarios en ambos nodos SQL para la comunicación del clúster.
Los puertos necesarios incluyen: UDP 3343, TCP 3343, TCP 1433, TCP 5022, TCP 135, TCP 445, TCP 49152-65535 (RPC dinámico).
-
Ejecuta el siguiente punto de comprobación en ambos servidores para permitir la comunicación entre SQL Server y el clúster a través del cortafuegos.
Ajusta los números de puerto si tienes configuraciones personalizadas.
# Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022Para conocer los requisitos detallados del cortafuegos, consulta "Requisitos de servicio y de puerto de red de Windows Server".
-
Ejecuta comprobaciones de validación en ambos nodos antes de crear el clúster:
Test-Connection servername Resolve-DnsName servername Get-NetAdapterBinding -ComponentID ms_tcpip6
Crea el clúster de conmutación por error
Crea un clúster de conmutación por error de Windows Server con ambos nodos de SQL Server para habilitar la alta disponibilidad y la conmutación por error automática.
-
Ejecuta
cluadmin.msco abre Failover Cluster Manager desde Administrador de servidores.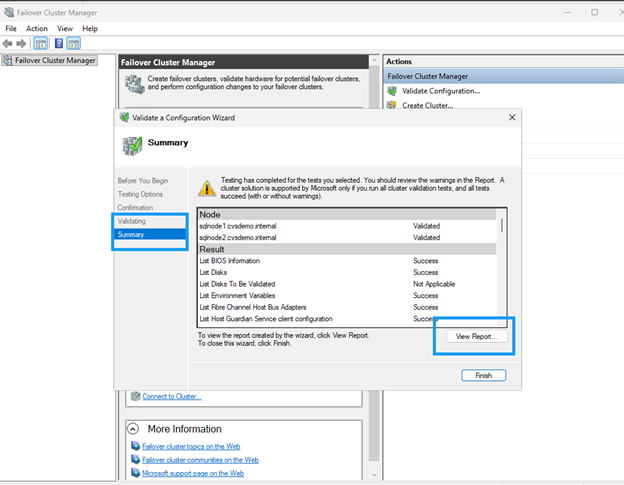
-
Selecciona Create Cluster.
-
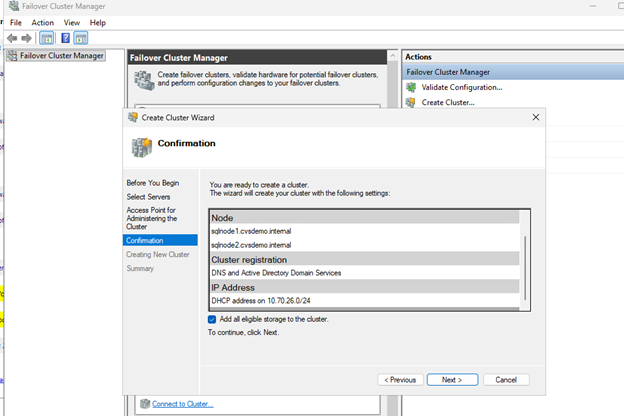
Agrega ambos nodos SQL (sqlnode1, sqlnode2).
-
Ejecuta las pruebas de validación y asegúrate de que todas las comprobaciones se superen. Revisa y corrige cualquier advertencia antes de continuar.
-
Proporciona un nombre para el clúster (por ejemplo,
sqlcluwest1). -
Completa la creación del clúster.
Configura el quórum del clúster con testigo de recurso compartido de archivos
Configura un testigo de compartición de archivos para mantener el quórum en una configuración de clúster de dos nodos. El testigo proporciona un voto adicional para evitar escenarios de split-brain y asegurar la disponibilidad del clúster.
Crear recurso compartido de archivos
Crea un recurso compartido de archivos en una máquina virtual en una zona o región diferente que tenga conectividad de red y esté dentro del mismo dominio de Active Directory.
-
Conéctate a la VM del servidor testigo de archivos compartidos.
-
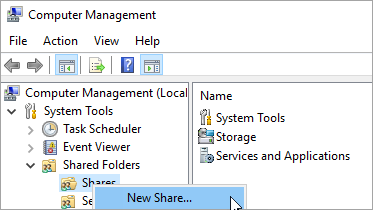
En Administrador de servidores, selecciona Herramientas > Computer Management.
-
Selecciona Carpetas compartidas, haz clic derecho en Shares y selecciona New Share.
-
Usa el Asistente para crear una carpeta compartida para crear un recurso compartido
\\servername\share. -
En la página Ruta de carpeta, selecciona Buscar.
-
Localiza o crea una ruta para la carpeta compartida y luego selecciona Siguiente.
-
En la página Nombre, descripción y configuración, verifica el nombre y la ruta del recurso compartido y luego selecciona Siguiente.
-
En la página Permisos de la carpeta compartida, selecciona Personalizar permisos y haz clic en Personalizar
-
En el cuadro de diálogo Personalizar permisos, selecciona Add para añadir la cuenta de clúster.
Asegúrate de que la cuenta que se usa para crear el clúster (sqlcluwest1$) tiene control total.
-
Haz clic en Aceptar para guardar los permisos.
-
En la página Permisos para carpetas compartidas, selecciona Finalizar y luego selecciona Finalizar otra vez.
Configura la configuración de quórum
Configura el clúster para usar el testigo de compartición de archivos para la votación de quórum.
-
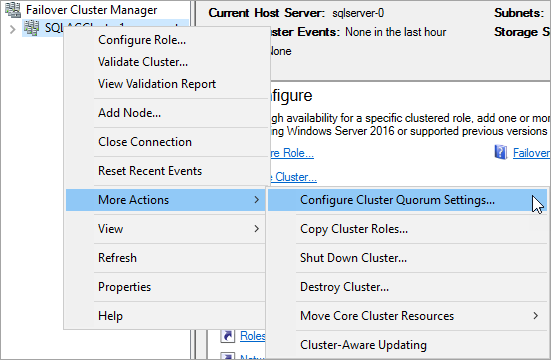
En Failover Cluster Manager, haz clic con el botón derecho en el clúster y selecciona More Actions > Configure Cluster Quorum Settings.
-
En el Asistente para configurar el quórum del clúster, haz clic en Siguiente.
-
En la página Select Quorum Configuration, elige Select the quorum witness y haz clic en Next.
-
En la página Select Quorum Witness, selecciona Configure a file share witness.
-
En la página Configure File Share Witness, selecciona Configure a file share witness.
-
Introduce la ruta al recurso compartido que creaste (por ejemplo,
\\servername\share) y haz clic en Siguiente. -
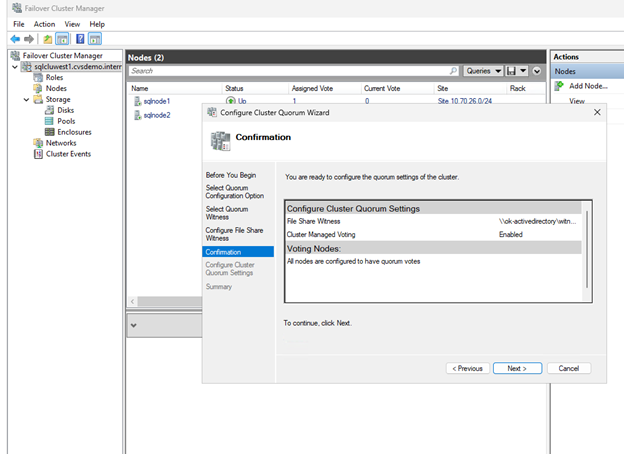
Verifica la configuración en la página de confirmación y haz clic en Siguiente.
-
Haz clic en Finalizar.
Los recursos del núcleo del clúster ahora están configurados con un testigo de uso compartido de archivos.
Habilitar Always On availability groups
Habilita los grupos de disponibilidad Always On en ambas máquinas virtuales de SQL Server:
-
En el menú Inicio, abre SQL Server Configuration Manager.
-
En el árbol del navegador, selecciona SQL Server Services.
-
Haz clic con el botón derecho en SQL Server (MSSQLSERVER) y selecciona Properties.
-
Selecciona la pestaña Always On High Availability.
-
Marca Enable Always On availability groups.
-
Haz clic en Aplicar y luego reinicia el servicio SQL Server cuando se te pida.
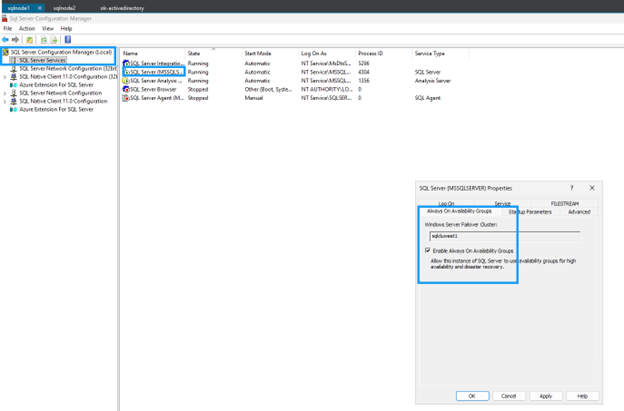
-
Repite el proceso para la segunda instancia de SQL Server.
Crear una base de datos en la primera instancia de SQL Server
Crea una base de datos en la primera instancia de SQL Server.
-
Conéctate a la primera máquina virtual de SQL Server con una cuenta de dominio que sea miembro del rol del servidor fijo sysadmin.
-
Abre SQL Server Management Studio y conéctate a la primera instancia de SQL Server.
-
En Object Explorer, haz clic derecho en Bases de datos y selecciona Nueva base de datos.
-
Introduce un nombre para la base de datos (por ejemplo,
MyDB1) y haz clic en OK. -
Establece el modo de recuperación de bases de datos en completo:
ALTER DATABASE MyDB1 SET RECOVERY FULL; GO
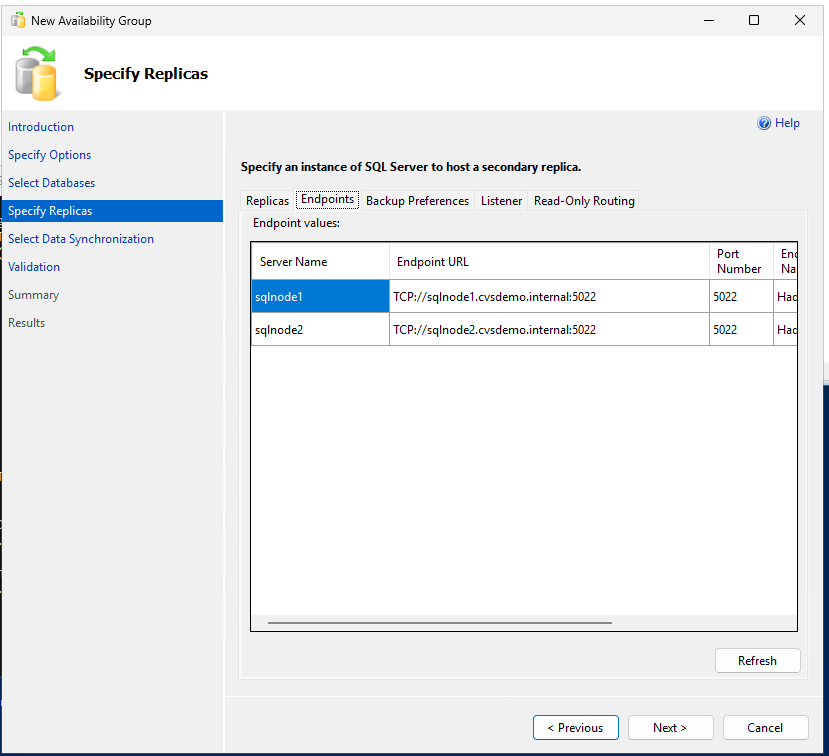
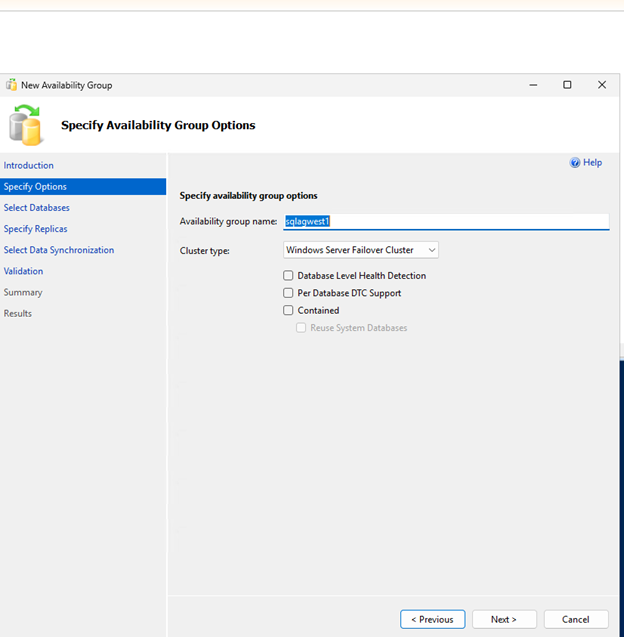
Crear y configurar grupo de disponibilidad
Crea un grupo de disponibilidad Always On con commit síncrono y conmutación por error automática para proporcionar alta disponibilidad para tus bases de datos SQL Server.
-
Haz tanto un backup completo como un backup del registro de transacciones de la base de datos.
-- Full backup BACKUP DATABASE MyDB1 TO DISK = 'F:\MSSQL\Backup\MyDB1_Full.bak' WITH INIT, COMPRESSION; -- Transaction log backup BACKUP LOG MyDB1 TO DISK = 'F:\MSSQL\Backup\MyDB1_Log.trn' WITH INIT, COMPRESSION; -
Copia los archivos de backup en la segunda instancia de SQL Server y restáuralos con NORECOVERY.
-- Restore full backup RESTORE DATABASE MyDB1 FROM DISK = 'F:\MSSQL\Backup\MyDB1_Full.bak' WITH NORECOVERY; -- Restore log backup RESTORE LOG MyDB1 FROM DISK = 'F:\MSSQL\Backup\MyDB1_Log.trn' WITH NORECOVERY; -
Crea el grupo de disponibilidad con commit síncrono, conmutación por error automática y réplicas secundarias legibles:
-- Run on primary replica CREATE AVAILABILITY GROUP sqlagwest1 WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY) FOR DATABASE MyDB1 REPLICA ON N'SQLNODE1' WITH ( ENDPOINT_URL = N'TCP://sqlnode1.cvsdemo.internal:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = YES) ), N'SQLNODE2' WITH ( ENDPOINT_URL = N'TCP://sqlnode2.cvsdemo.internal:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = YES) ); GO -
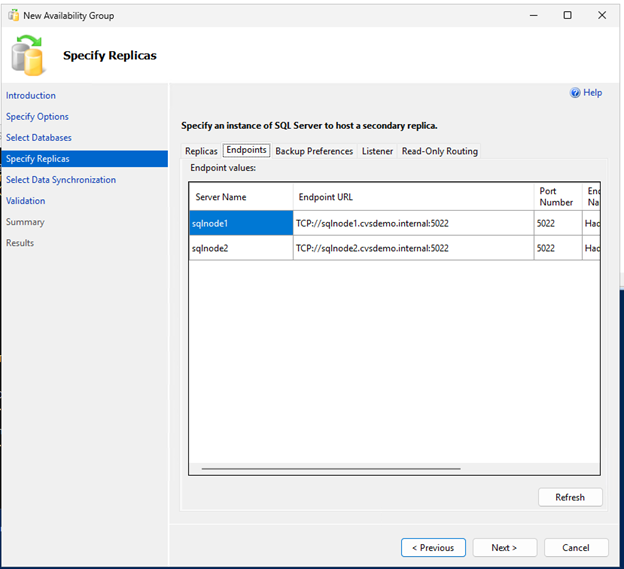
Crea el grupo de disponibilidad usando el Asistente para grupos de disponibilidad.


Asegúrate de que el puerto 5022 del firewall esté permitido en ambos nodos SQL. 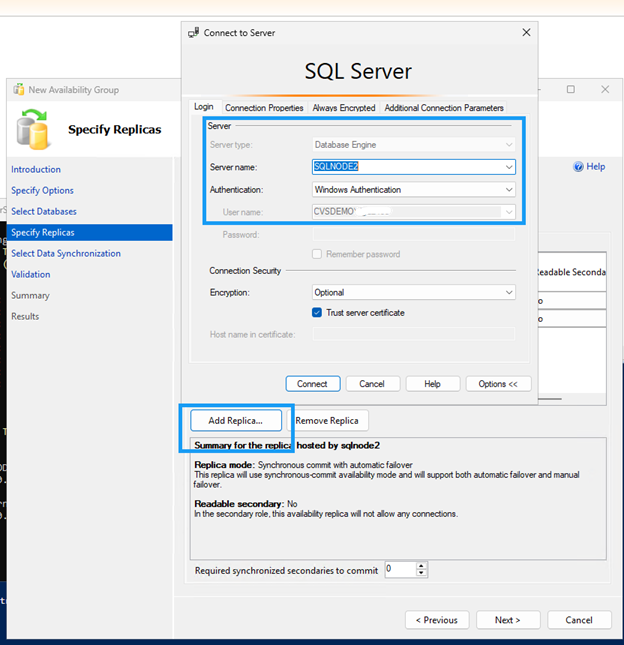
Crear recurso de escucha DNN
Crea un oyente de nombre de red distribuido (DNN) para dirigir el tráfico al recurso agrupado adecuado sin necesidad de un equilibrador de carga.
Usa PowerShell para crear el recurso DNN:
$Ag = "sqlagwest1"
$Dns = "AOAGDNN"
$Port = "1433"
# Add DNN resource
Add-ClusterResource -Name $Dns -ResourceType "Distributed Network Name" -Group $Ag
# Set DNN properties
Get-ClusterResource -Name $Dns | Set-ClusterParameter -Name DnsName -Value $Dns
Get-ClusterResource -Name $Dns | Set-ClusterParameter -Name Port -Value $Port
# Start DNN resource
Start-ClusterResource -Name $Dns
# Add dependency
$AagResource = Get-ClusterResource | Where-Object {$_.ResourceType -eq "SQL Server Availability Group" -and $_.OwnerGroup -eq $Ag}
Set-ClusterResourceDependency -Resource $AagResource -Dependency "[$Dns]"Configura posibles propietarios
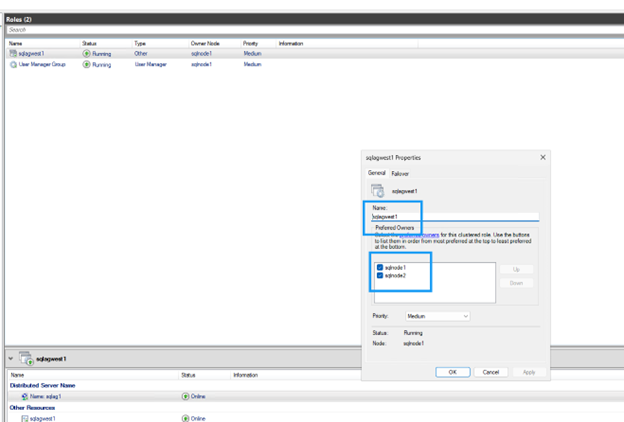
Por defecto, el clúster vincula el nombre DNN DNS a todos los nodos. Excluye los nodos que no participan en el grupo de disponibilidad:
-
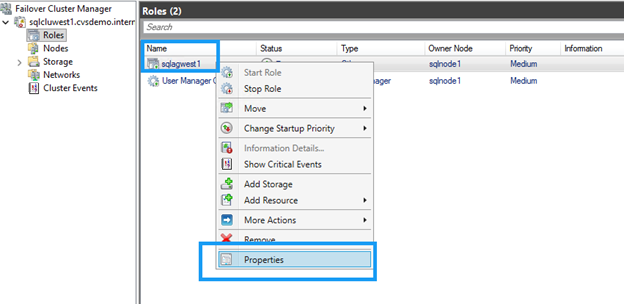
En Failover Cluster Manager, localiza el recurso DNN.
-
Haz clic con el botón derecho en el recurso DNN y selecciona Propiedades.
-
Desactiva la casilla de los nodos que no participen en el grupo de disponibilidad.
-
Haz clic en OK para guardar la configuración.
Actualiza las cadenas de conexión de la aplicación
Actualiza las cadenas de conexión para que usen el nombre de oyente de DNN e incluyan el parámetro MultiSubnetFailover=True:
Server=AOAGDNN,1433;Database=MyDB1;MultiSubnetFailover=True;
|
|
Si tu cliente no admite el parámetro MultiSubnetFailover, no es compatible con DNN. |
Prueba de conmutación por error
Verifica la configuración del grupo de disponibilidad y prueba la conmutación por error para asegurarte de que la conmutación por error automática funciona correctamente entre nodos.
-
Ejecuta el siguiente comando en cualquier réplica para verificar la configuración del grupo de disponibilidad.
Ambas réplicas deben mostrar
SYNCHRONOUS_COMMITpara el modo de disponibilidad yAUTOMATICpara el modo de conmutación por error, lo que garantiza cero pérdida de datos durante la conmutación automática por error.SELECT ag.name AS AG_Name, ars.primary_replica FROM sys.dm_hadr_availability_group_states AS ars JOIN sys.availability_groups AS ag ON ag.group_id = ars.group_id; -- Check replica configuration SELECT replica_server_name, availability_mode_desc, failover_mode_desc FROM sys.availability_replicas WHERE group_id = (SELECT group_id FROM sys.availability_groups WHERE name = N'sqlagwest1');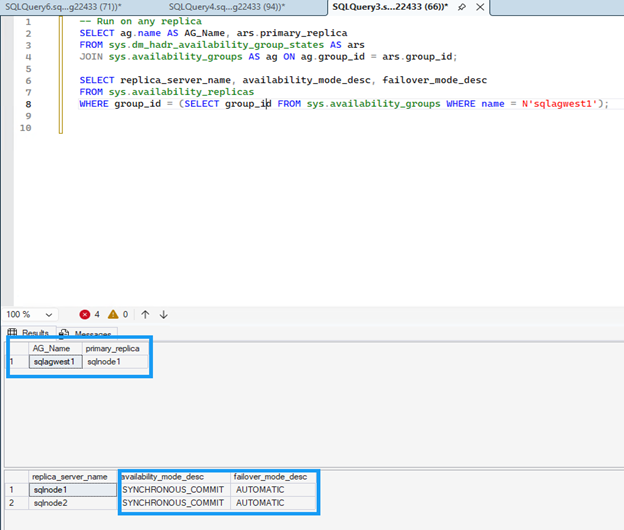
-
Ejecuta el siguiente comando en el nodo secundario para iniciar la conmutación por error:
ALTER AVAILABILITY GROUP sqlagwest1 FAILOVER; GO -
Verifica que el objetivo de conectividad cambió al nuevo primario:
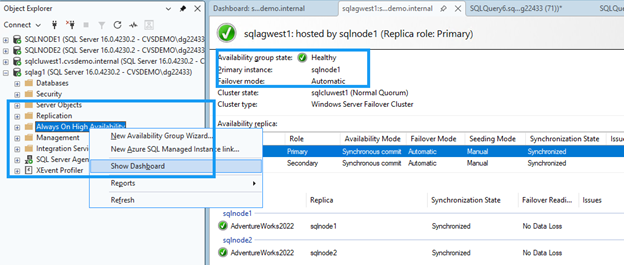
-- SELECT @@SERVERNAME AS NowPrimary;En SSMS, expande el nodo del grupo de disponibilidad, haz clic derecho en Always On High Availability y selecciona Show Dashboard.
El panel de control debería mostrar ambos nodos en estado saludable y confirmar la conmutación por error.
Limpia los recursos
Después de completar el tutorial, elimina los recursos que creaste para evitar incurrir en cargos adicionales:
-
Eliminar instancias de Compute Engine (sqlnode1, sqlnode2)
-
Eliminar Google Cloud NetApp Volumes (volúmenes, storage pools, grupos de hosts)
-
Elimina la VPC y los recursos de red si se crearon específicamente para este tutorial
-
Eliminar el servidor testigo de archivos compartidos si aplica
Consulta "Google Cloud NetApp Volumes documentación" y "Documentación de Google Compute Engine" para ver los pasos detallados para eliminar recursos.
Dónde encontrar información adicional
Para obtener más información sobre SQL Server en Google Cloud con almacenamiento de NetApp, consulta la siguiente documentación: