

Procedimientos de implementación de Oracle paso a paso en AWS EC2 y FSx
 Sugerir cambios
Sugerir cambios
En esta sección se describen los procedimientos de implementación de la base de datos personalizada de Oracle RDS con almacenamiento FSx.
Implementar una instancia EC2 Linux para Oracle a través de la consola EC2
Si es nuevo en AWS, primero debe configurar un entorno de AWS. La pestaña de documentación en la página de inicio del sitio web de AWS proporciona enlaces de instrucciones de EC2 sobre cómo implementar una instancia EC2 de Linux que se puede usar para alojar su base de datos Oracle a través de la consola EC2 de AWS. La siguiente sección es un resumen de estos pasos. Para obtener más detalles, consulte la documentación específica de AWS EC2 vinculada.
Configuración de su entorno AWS EC2
Debe crear una cuenta de AWS para aprovisionar los recursos necesarios para ejecutar su entorno Oracle en el servicio EC2 y FSx. La siguiente documentación de AWS proporciona los detalles necesarios:
Temas clave:
-
Regístrese en AWS.
-
Crear un par de claves.
-
Crear un grupo de seguridad.
Habilitación de múltiples zonas de disponibilidad en los atributos de la cuenta de AWS
Para una configuración de alta disponibilidad de Oracle como se muestra en el diagrama de arquitectura, debe habilitar al menos cuatro zonas de disponibilidad en una región. Las zonas de disponibilidad múltiple también pueden ubicarse en diferentes regiones para cumplir con las distancias requeridas para la recuperación ante desastres.

Creación y conexión a una instancia EC2 para alojar una base de datos Oracle
Ver el tutorial"Comience a utilizar las instancias de Linux de Amazon EC2" para procedimientos de implementación paso a paso y mejores prácticas.
Temas clave:
-
Descripción general.
-
Prerrequisitos.
-
Paso 1: Iniciar una instancia.
-
Paso 2: Conéctese a su instancia.
-
Paso 3: Limpia tu instancia.
Las siguientes capturas de pantalla demuestran la implementación de una instancia de Linux tipo m5 con la consola EC2 para ejecutar Oracle.
-
Desde el panel de EC2, haga clic en el botón amarillo Iniciar instancia para iniciar el flujo de trabajo de implementación de la instancia EC2.

-
En el paso 1, seleccione "Red Hat Enterprise Linux 8 (HVM), tipo de volumen SSD: ami-0b0af3577fe5e3532 (64 bits x86) / ami-01fc429821bf1f4b4 (Arm de 64 bits)".

-
En el paso 2, seleccione un tipo de instancia m5 con la asignación de CPU y memoria adecuada según la carga de trabajo de su base de datos Oracle. Haga clic en "Siguiente: Configurar detalles de la instancia".

-
En el paso 3, elija la VPC y la subred donde se debe ubicar la instancia y habilite la asignación de IP pública. Haga clic en "Siguiente: Agregar almacenamiento".

-
En el paso 4, asigne suficiente espacio para el disco raíz. Es posible que necesites espacio para agregar un intercambio. De forma predeterminada, la instancia EC2 asigna cero espacio de intercambio, lo que no es óptimo para ejecutar Oracle.

-
En el paso 5, agregue una etiqueta para identificación de instancia si es necesario.

-
En el paso 6, seleccione un grupo de seguridad existente o cree uno nuevo con la política de entrada y salida deseada para la instancia.

-
En el paso 7, revise el resumen de configuración de la instancia y haga clic en Iniciar para iniciar la implementación de la instancia. Se le solicitará que cree un par de claves o seleccione un par de claves para acceder a la instancia.


-
Inicie sesión en la instancia EC2 utilizando un par de claves SSH. Realice cambios en el nombre de su clave y en la dirección IP de la instancia según corresponda.
ssh -i ora-db1v2.pem ec2-user@54.80.114.77
Debe crear dos instancias EC2 como servidores Oracle principal y en espera en su zona de disponibilidad designada como se muestra en el diagrama de arquitectura.
Aprovisionar sistemas de archivos FSx ONTAP para el almacenamiento de bases de datos Oracle
La implementación de la instancia EC2 asigna un volumen raíz EBS para el sistema operativo. Los sistemas de archivos FSx ONTAP proporcionan volúmenes de almacenamiento de bases de datos de Oracle, incluidos los volúmenes binarios, de datos y de registro de Oracle. Los volúmenes NFS de almacenamiento de FSx se pueden aprovisionar desde la consola de AWS FSx o desde la instalación de Oracle y la automatización de la configuración que asigna los volúmenes a medida que el usuario configura en un archivo de parámetros de automatización.
Creación de sistemas de archivos FSx ONTAP
Se remitió a esta documentación "Administración de sistemas de archivos de FSx ONTAP" para crear sistemas de archivos FSx ONTAP .
Consideraciones clave:
-
Capacidad de almacenamiento SSD. Mínimo 1024 GiB, máximo 192 TiB.
-
IOPS de SSD aprovisionadas. Según los requisitos de carga de trabajo, un máximo de 80 000 IOPS SSD por sistema de archivos.
-
Capacidad de rendimiento.
-
Establecer la contraseña de administrador fsxadmin/vsadmin. Necesario para la automatización de la configuración de FSx.
-
Copia de seguridad y mantenimiento. Deshabilite las copias de seguridad diarias automáticas; la copia de seguridad del almacenamiento de la base de datos se ejecuta a través de la programación de SnapCenter .
-
Recupere la dirección IP de administración de SVM así como las direcciones de acceso específicas del protocolo desde la página de detalles de SVM. Necesario para la automatización de la configuración de FSx.
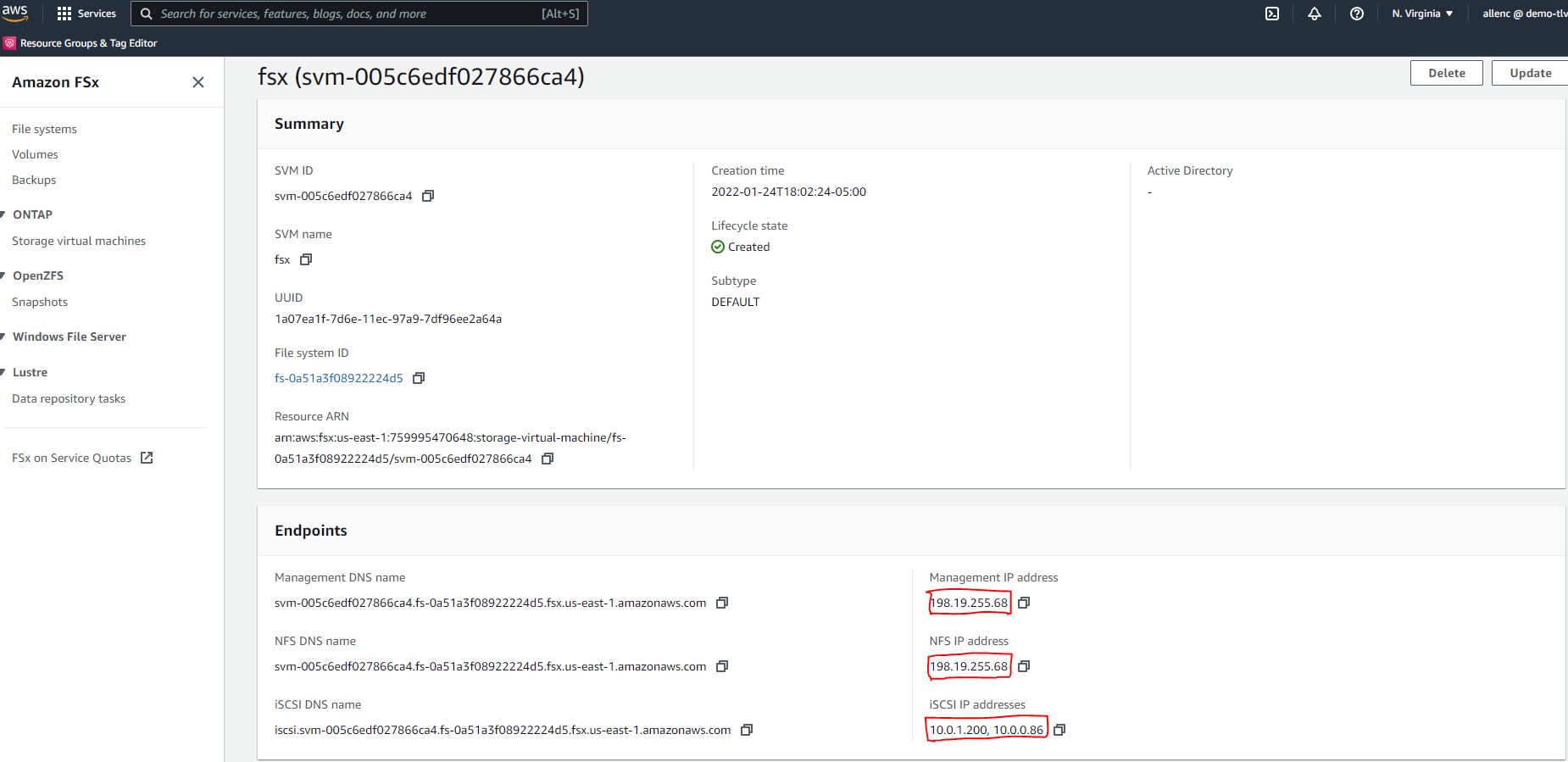
Consulte los siguientes procedimientos paso a paso para configurar un clúster HA FSx principal o en espera.
-
Desde la consola FSx, haga clic en Crear sistema de archivos para iniciar el flujo de trabajo de aprovisionamiento de FSx.

-
Seleccione Amazon FSx ONTAP. Luego haga clic en Siguiente.

-
Seleccione Crear estándar y, en Detalles del sistema de archivos, nombre su sistema de archivos, Multi-AZ HA. Según la carga de trabajo de su base de datos, elija IOPS automáticas o aprovisionadas por el usuario hasta 80 000 IOPS SSD. El almacenamiento FSx viene con un almacenamiento en caché NVMe de hasta 2 TiB en el backend que puede ofrecer IOPS medidos incluso más altos.

-
En la sección Red y seguridad, seleccione la VPC, el grupo de seguridad y las subredes. Estos deben crearse antes de la implementación de FSx. Según la función del clúster FSx (principal o en espera), coloque los nodos de almacenamiento FSx en las zonas adecuadas.

-
En la sección Seguridad y cifrado, acepte el valor predeterminado e ingrese la contraseña fsxadmin.

-
Introduzca el nombre de SVM y la contraseña de vsadmin.

-
Deje la configuración del volumen en blanco; no es necesario crear un volumen en este momento.

-
Revise la página Resumen y haga clic en Crear sistema de archivos para completar la provisión del sistema de archivos FSx.

Aprovisionamiento de volúmenes de bases de datos para bases de datos Oracle
Ver"Administrar volúmenes de FSx ONTAP : creación de un volumen" Para más detalles.
Consideraciones clave:
-
Dimensionar adecuadamente los volúmenes de la base de datos.
-
Deshabilitar la política de niveles de capacidad del grupo para la configuración del rendimiento.
-
Habilitación de Oracle dNFS para volúmenes de almacenamiento NFS.
-
Configuración de múltiples rutas para volúmenes de almacenamiento iSCSI.
Crear un volumen de base de datos desde la consola FSx
Desde la consola de AWS FSx, puede crear tres volúmenes para el almacenamiento de archivos de base de datos de Oracle: uno para el binario de Oracle, uno para los datos de Oracle y uno para el registro de Oracle. Asegúrese de que el nombre del volumen coincida con el nombre de host de Oracle (definido en el archivo de hosts en el kit de herramientas de automatización) para una identificación adecuada. En este ejemplo, utilizamos db1 como nombre de host de Oracle EC2 en lugar de un nombre de host basado en dirección IP típico para una instancia EC2.




|
La consola FSx actualmente no admite la creación de LUN iSCSI. Para la implementación de LUN iSCSI para Oracle, los volúmenes y LUN se pueden crear mediante la automatización para ONTAP con NetApp Automation Toolkit. |
Instalar y configurar Oracle en una instancia EC2 con volúmenes de base de datos FSx
El equipo de automatización de NetApp proporciona un kit de automatización para ejecutar la instalación y configuración de Oracle en instancias EC2 de acuerdo con las mejores prácticas. La versión actual del kit de automatización es compatible con Oracle 19c en NFS con el parche RU predeterminado 19.8. El kit de automatización se puede adaptar fácilmente para otros parches RU si es necesario.
Preparar un controlador Ansible para ejecutar la automatización
Siga las instrucciones de la sección "Creación y conexión a una instancia EC2 para alojar una base de datos Oracle " para aprovisionar una pequeña instancia EC2 Linux para ejecutar el controlador Ansible. En lugar de utilizar RedHat, Amazon Linux t2.large con 2vCPU y 8G RAM debería ser suficiente.
Recuperar el kit de herramientas de automatización de implementación de Oracle de NetApp
Inicie sesión en la instancia del controlador Ansible de EC2 aprovisionada en el paso 1 como ec2-user y, desde el directorio de inicio de ec2-user, ejecute el comando git clone Comando para clonar una copia del código de automatización.
git clone https://github.com/NetApp-Automation/na_oracle19c_deploy.gitgit clone https://github.com/NetApp-Automation/na_rds_fsx_oranfs_config.gitEjecute la implementación automatizada de Oracle 19c utilizando el kit de herramientas de automatización
Vea estas instrucciones detalladas"Implementación de CLI de la base de datos Oracle 19c" para implementar Oracle 19c con automatización CLI. Hay un pequeño cambio en la sintaxis del comando para la ejecución del libro de estrategias porque está utilizando un par de claves SSH en lugar de una contraseña para la autenticación del acceso al host. La siguiente lista es un resumen de alto nivel:
-
De forma predeterminada, una instancia EC2 utiliza un par de claves SSH para la autenticación de acceso. Desde los directorios raíz de automatización del controlador Ansible
/home/ec2-user/na_oracle19c_deploy, y/home/ec2-user/na_rds_fsx_oranfs_config, haz una copia de la clave SSHaccesststkey.pempara el host Oracle implementado en el paso "Creación y conexión a una instancia EC2 para alojar una base de datos Oracle . " -
Inicie sesión en el host de base de datos de la instancia EC2 como ec2-user e instale la biblioteca python3.
sudo yum install python3 -
Cree un espacio de intercambio de 16G desde la unidad de disco raíz. De forma predeterminada, una instancia EC2 crea cero espacio de intercambio. Siga esta documentación de AWS:"¿Cómo asigno memoria para que funcione como espacio de intercambio en una instancia de Amazon EC2 mediante un archivo de intercambio?" .
-
Regresar al controlador Ansible(
cd /home/ec2-user/na_rds_fsx_oranfs_config), y ejecutar el manual de preclonación con los requisitos adecuados ylinux_configetiquetas.ansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t requirements_configansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t linux_config -
Cambiar a la
/home/ec2-user/na_oracle19c_deploy-masterdirectorio, lea el archivo README y complete el directorio globalvars.ymlarchivo con los parámetros globales relevantes. -
Rellene el
host_name.ymlarchivo con los parámetros relevantes en elhost_varsdirectorio. -
Ejecute el playbook para Linux y presione Entrar cuando se le solicite la contraseña de vsadmin.
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t linux_config -e @vars/vars.yml -
Ejecute el libro de jugadas para Oracle y presione Enter cuando se le solicite la contraseña de vsadmin.
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t oracle_config -e @vars/vars.yml
Cambie el bit de permiso en el archivo de clave SSH a 400 si es necesario. Cambiar el host de Oracle(ansible_host en el host_vars archivo) Dirección IP a la dirección pública de su instancia EC2.
Configuración de SnapMirror entre el clúster FSx HA principal y el de respaldo
Para lograr una alta disponibilidad y recuperación ante desastres, puede configurar la replicación de SnapMirror entre el clúster de almacenamiento FSx principal y el de respaldo. A diferencia de otros servicios de almacenamiento en la nube, FSx permite al usuario controlar y administrar la replicación del almacenamiento con la frecuencia y el rendimiento de replicación deseados. También permite a los usuarios probar HA/DR sin ningún efecto en la disponibilidad.
Los siguientes pasos muestran cómo configurar la replicación entre un clúster de almacenamiento FSx principal y uno en espera.
-
Configurar el peering del clúster principal y en espera. Inicie sesión en el clúster principal como usuario fsxadmin y ejecute el siguiente comando. Este proceso de creación recíproco ejecuta el comando de creación tanto en el clúster principal como en el clúster en espera. Reemplazar
standby_cluster_namecon el nombre apropiado para su entorno.cluster peer create -peer-addrs standby_cluster_name,inter_cluster_ip_address -username fsxadmin -initial-allowed-vserver-peers * -
Configure el peering de vServer entre el clúster principal y el de reserva. Inicie sesión en el clúster principal como usuario vsadmin y ejecute el siguiente comando. Reemplazar
primary_vserver_name,standby_vserver_name,standby_cluster_namecon los nombres apropiados para su entorno.vserver peer create -vserver primary_vserver_name -peer-vserver standby_vserver_name -peer-cluster standby_cluster_name -applications snapmirror -
Verifique que los emparejamientos del clúster y del servidor virtual estén configurados correctamente.

-
Cree volúmenes NFS de destino en el clúster FSx en espera para cada volumen de origen en el clúster FSx principal. Reemplace el nombre del volumen según corresponda a su entorno.
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -type DPvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -type DPvol create -volume dr_db1_log -aggregate aggr1 -size 250G -state online -policy default -type DP -
También puede crear volúmenes iSCSI y LUN para el binario de Oracle, los datos de Oracle y el registro de Oracle si se utiliza el protocolo iSCSI para el acceso a los datos. Deje aproximadamente un 10% de espacio libre en los volúmenes para las instantáneas.
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_bin/dr_db1_bin_01 -size 45G -ostype linuxvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_data/dr_db1_data_01 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_02 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_03 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_04 -size 100G -ostype linuxvol create -volume dr_db1_log -agregado aggr1 -tamaño 250G -estado en línea -política predeterminada -permisos-unix ---rwxr-xr-x -tipo RW
lun create -path /vol/dr_db1_log/dr_db1_log_01 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_02 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_03 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_04 -size 45G -ostype linux -
Para los LUN iSCSI, cree una asignación para el iniciador de host de Oracle para cada LUN, utilizando el LUN binario como ejemplo. Reemplace el igroup con un nombre apropiado para su entorno e incremente el lun-id para cada LUN adicional.
lun mapping create -path /vol/dr_db1_bin/dr_db1_bin_01 -igroup ip-10-0-1-136 -lun-id 0lun mapping create -path /vol/dr_db1_data/dr_db1_data_01 -igroup ip-10-0-1-136 -lun-id 1 -
Cree una relación SnapMirror entre los volúmenes de base de datos principal y en espera. Reemplace el nombre de SVM apropiado para su entorno.
snapmirror create -source-path svm_FSxOraSource:db1_bin -destination-path svm_FSxOraTarget:dr_db1_bin -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_data -destination-path svm_FSxOraTarget:dr_db1_data -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_log -destination-path svm_FSxOraTarget:dr_db1_log -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DP
Esta configuración de SnapMirror se puede automatizar con un kit de herramientas de automatización de NetApp para volúmenes de bases de datos NFS. El kit de herramientas está disponible para descargar desde el sitio público de GitHub de NetApp .
git clone https://github.com/NetApp-Automation/na_ora_hadr_failover_resync.gitLea atentamente las instrucciones README antes de intentar realizar la configuración y las pruebas de conmutación por error.
|
|
La replicación del binario de Oracle desde el clúster principal a uno en espera podría tener implicaciones en la licencia de Oracle. Comuníquese con su representante de licencias de Oracle para obtener más información. La alternativa es tener Oracle instalado y configurado en el momento de la recuperación y la conmutación por error. |
Implementación de SnapCenter
Instalación de SnapCenter
Seguir"Instalación del servidor SnapCenter" para instalar el servidor SnapCenter . Esta documentación cubre cómo instalar un servidor SnapCenter independiente. Una versión SaaS de SnapCenter se encuentra en revisión beta y podría estar disponible en breve. Consulte con su representante de NetApp la disponibilidad si es necesario.
Configurar el complemento SnapCenter para el host EC2 Oracle
-
Después de la instalación automatizada de SnapCenter , inicie sesión en SnapCenter como usuario administrativo del host de Windows en el que está instalado el servidor de SnapCenter .

-
En el menú del lado izquierdo, haga clic en Configuración y luego en Credencial y Nuevo para agregar las credenciales de usuario ec2 para la instalación del complemento SnapCenter .
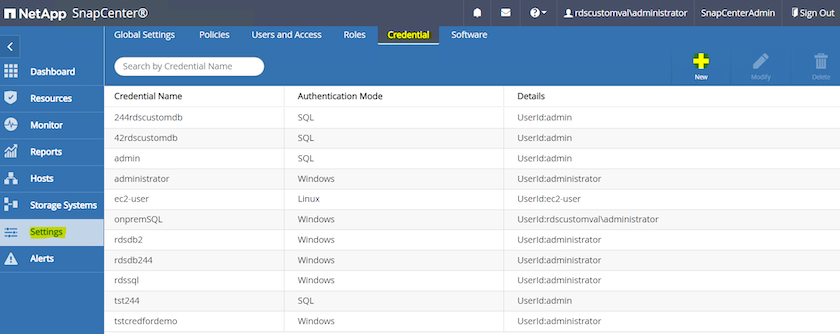
-
Restablezca la contraseña del usuario ec2 y habilite la autenticación SSH de contraseña editando el archivo
/etc/ssh/sshd_configarchivo en el host de la instancia EC2. -
Verifique que la casilla de verificación "Usar privilegios de sudo" esté seleccionada. Acabas de restablecer la contraseña del usuario ec2 en el paso anterior.
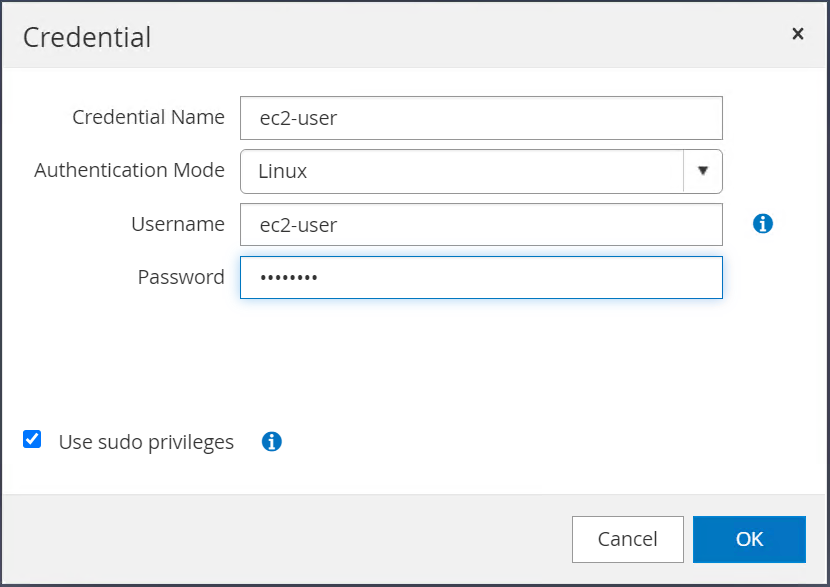
-
Agregue el nombre del servidor SnapCenter y la dirección IP al archivo de host de la instancia EC2 para la resolución del nombre.
[ec2-user@ip-10-0-0-151 ~]$ sudo vi /etc/hosts [ec2-user@ip-10-0-0-151 ~]$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.0.1.233 rdscustomvalsc.rdscustomval.com rdscustomvalsc
-
En el host de Windows del servidor SnapCenter , agregue la dirección IP del host de la instancia EC2 al archivo de host de Windows
C:\Windows\System32\drivers\etc\hosts.10.0.0.151 ip-10-0-0-151.ec2.internal
-
En el menú del lado izquierdo, seleccione Hosts > Hosts administrados y luego haga clic en Agregar para agregar el host de la instancia EC2 a SnapCenter.
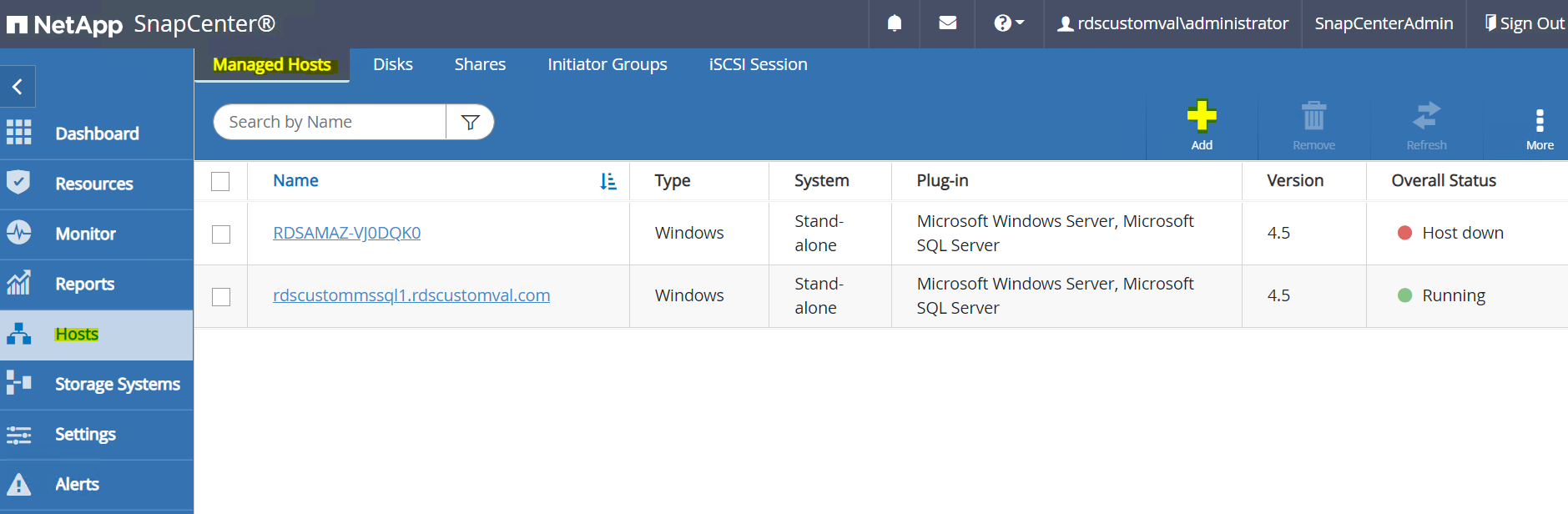
Verifique la base de datos Oracle y, antes de enviar, haga clic en Más opciones.

Marque la opción Omitir comprobaciones de preinstalación. Confirme la omisión de comprobaciones de preinstalación y, a continuación, haga clic en Enviar después de guardar.
Se le solicitará que confirme su huella digital; a continuación, haga clic en Confirmar y enviar.

Después de la configuración exitosa del complemento, el estado general del host administrado se muestra como En ejecución.

Configurar la política de respaldo para la base de datos de Oracle
Consulte esta sección"Configurar la política de copia de seguridad de la base de datos en SnapCenter" para obtener detalles sobre la configuración de la política de copia de seguridad de la base de datos de Oracle.
Generalmente es necesario crear una política para la copia de seguridad de la base de datos Oracle de instantánea completa y una política para la copia de seguridad de instantánea de solo registro de archivo de Oracle.
|
|
Puede habilitar la poda del registro de archivo de Oracle en la política de respaldo para controlar el espacio de archivo de registro. Marque "Actualizar SnapMirror después de crear una copia de instantánea local" en "Seleccionar opción de replicación secundaria", ya que necesita replicar en una ubicación en espera para HA o DR. |
Configurar la copia de seguridad y la programación de la base de datos de Oracle
La copia de seguridad de la base de datos en SnapCenter es configurable por el usuario y se puede realizar de forma individual o como grupo en un grupo de recursos. El intervalo de copia de seguridad depende de los objetivos RTO y RPO. NetApp recomienda ejecutar una copia de seguridad completa de la base de datos cada pocas horas y archivar la copia de seguridad del registro con una frecuencia mayor, por ejemplo, cada 10 a 15 minutos, para una recuperación rápida.
Consulte la sección de Oracle de"Implementar una política de respaldo para proteger la base de datos" Para obtener un proceso detallado paso a paso para implementar la política de respaldo creada en la secciónConfigurar la política de respaldo para la base de datos de Oracle y para programar trabajos de respaldo.
La siguiente imagen proporciona un ejemplo de los grupos de recursos que están configurados para realizar copias de seguridad de una base de datos de Oracle.
