

Descripción general de la alta disponibilidad de SAP HANA
 Sugerir cambios
Sugerir cambios
Este capítulo ofrece una descripción general de las opciones de alta disponibilidad para SAP HANA que compara la replicación en la capa de aplicaciones con la replicación de almacenamiento.
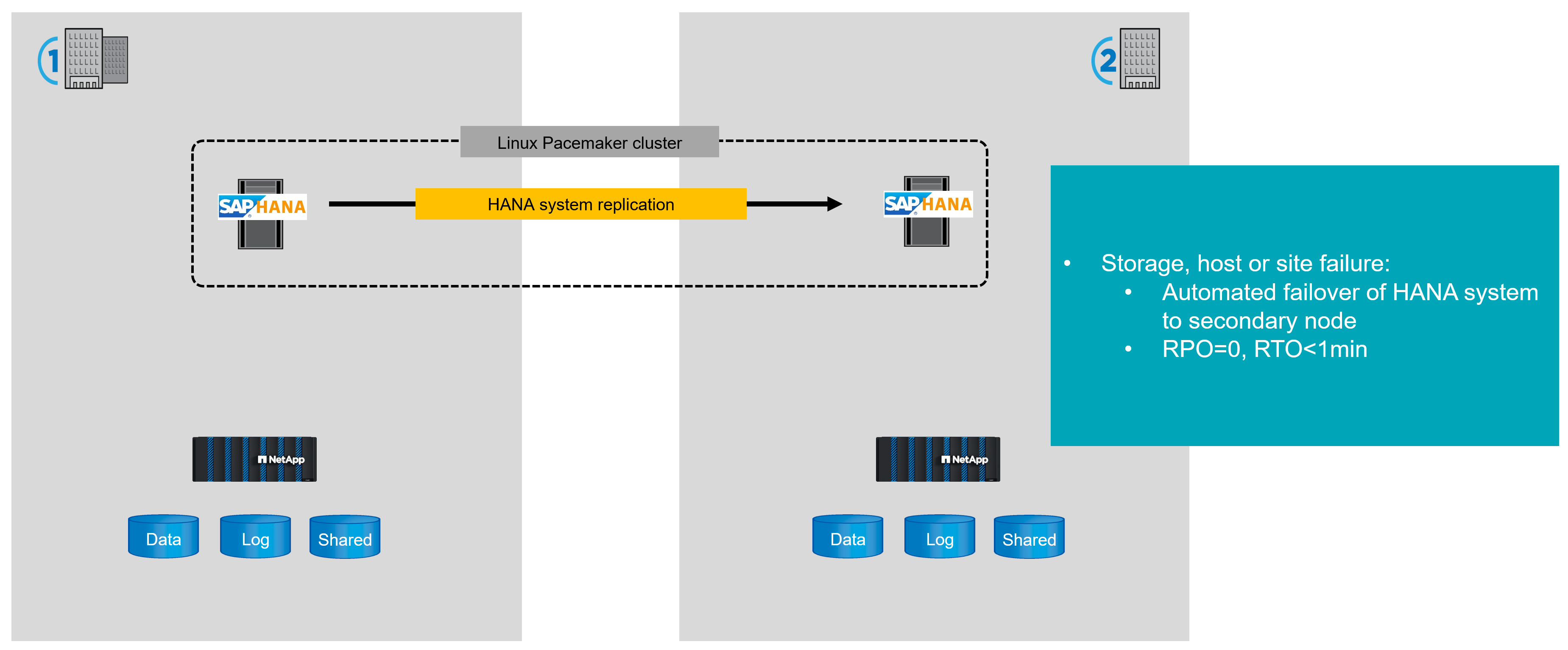
Replicación de sistemas SAP HANA (HSR)
La replicación del sistema SAP HANA ofrece un modo de operación en el que los datos se replican de forma síncrona, se cargan previamente en la memoria y se actualizan continuamente en el host secundario. Este modo permite valores de RTO muy bajos, aproximadamente 1 minuto o menos, pero también requiere un servidor dedicado que solo se usa para recibir los datos de replicación del sistema de origen. Debido al bajo tiempo de conmutación al respaldo, la replicación de sistemas SAP HANA también se utiliza a menudo en operaciones de mantenimiento de casi cero tiempo de inactividad, como las actualizaciones de software HANA. Las soluciones de clúster Linux Pacemaker se utilizan normalmente para automatizar las operaciones de conmutación por error.
En caso de producirse algún fallo en el sitio principal, el almacenamiento, el host o el sitio completo, el sistema HANA conmuta automáticamente al sitio secundario controlado por el clúster Linux Pacemaker.
Para obtener una descripción completa de todas las opciones de configuración y escenarios de replicación, consulte "Portal de ayuda de SAP HANA System Replication | SAP".
Sincronización activa de NetApp SnapMirror
La sincronización activa de SnapMirror permite que los servicios empresariales continúen funcionando incluso si se produce un fallo completo del sitio, lo que permite a las aplicaciones conmutar por error de forma transparente mediante una copia secundaria. No se requiere intervención manual ni secuencias de comandos personalizadas para activar una conmutación por error con SnapMirror Active Sync. La sincronización activa de SnapMirror se admite en clústeres AFF, clústeres de cabinas All Flash SAN (ASA) y C-Series (AFF o ASA). La sincronización activa de SnapMirror protege las aplicaciones con LUN iSCSI o FCP.
A partir de ONTAP 9.15.1, SnapMirror active sync admite una funcionalidad activo-activo simétrica. Activo-activo simétrico permite operaciones de I/O de lectura y escritura desde ambas copias de una LUN protegida con replicación síncrona bidireccional. De este modo, ambas copias LUN pueden servir operaciones de I/O localmente.
Puede encontrar más información en "Información general sobre la sincronización activa de SnapMirror en ONTAP".
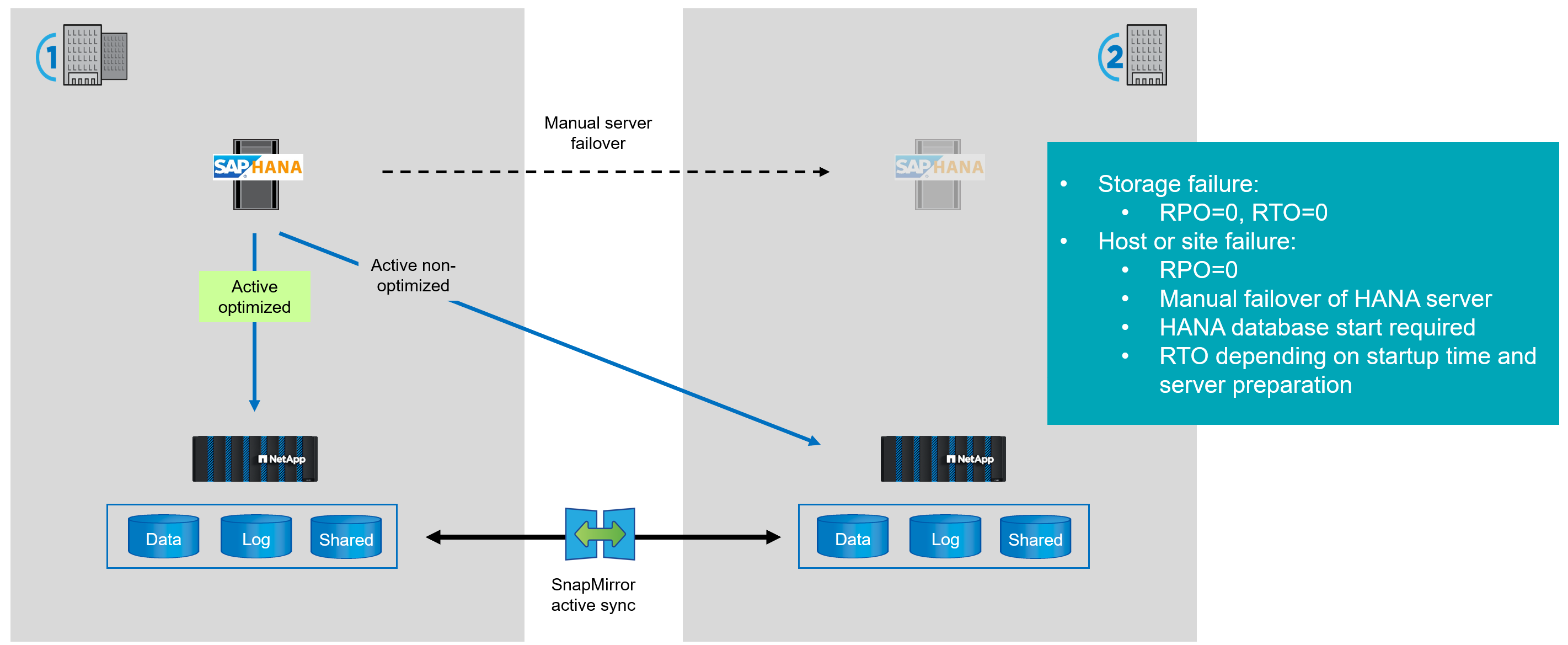
Hardware nativo de HANA
Al ejecutar SAP HANA en un servidor con configuración básica, puede utilizar la sincronización activa de SnapMirror para proporcionar una solución de almacenamiento de alta disponibilidad. Los datos se replican de forma síncrona, por lo que proporcionan un objetivo de punto de recuperación=0.
En caso de producirse un fallo de almacenamiento, el sistema HANA accederá de forma transparente a la copia duplicada en el sitio secundario mediante la segunda ruta FCP proporcionando un objetivo de tiempo de recuperación=0.
En caso de un fallo de host o de un sitio completo, se debe proporcionar un nuevo servidor del sitio secundario para acceder a los datos del host fallido. Normalmente se trata de un sistema de prueba o control de calidad del mismo tamaño que en producción, que se cerrará y se utilizará para ejecutar el sistema de producción. Después de que las LUN del sitio secundario se hayan conectado al nuevo host, se debe iniciar la base de datos de HANA. Por lo tanto, el objetivo de tiempo de recuperación total depende del tiempo necesario para aprovisionar el host y del tiempo de inicio de la base de datos de HANA.
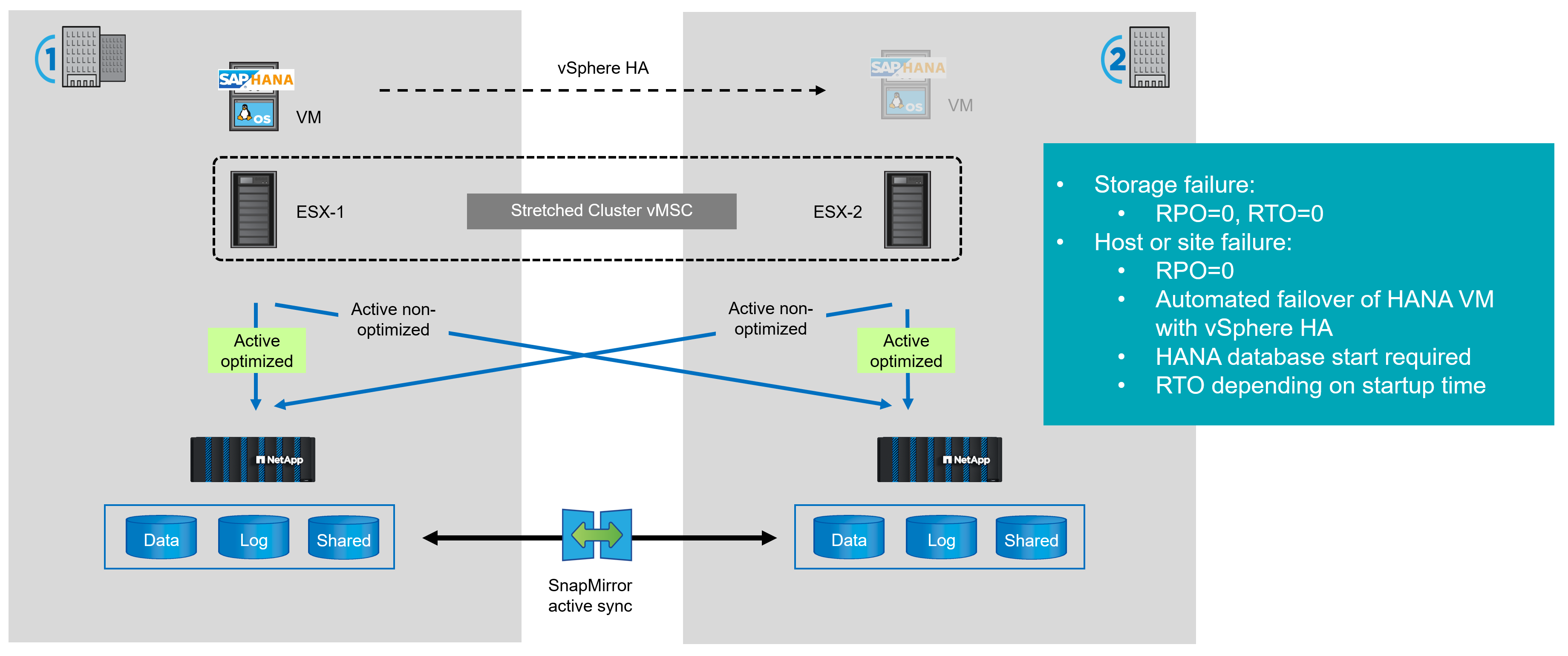
Clúster de almacenamiento Metro de vSphere (VMSC)
Al ejecutar SAP HANA en un entorno VMware mediante almacenes de datos conectados a FCP, puede utilizar la sincronización activa de SnapMirror para crear un clúster de almacenamiento de VMware Metro. En esta configuración, los almacenes de datos que utiliza el sistema HANA se replican de manera sincrónica en el sitio secundario.
En caso de un fallo de almacenamiento, el host ESX accederá automáticamente a la copia duplicada en el sitio secundario proporcionando un objetivo de tiempo de recuperación=0.
En caso de un fallo de host o del sitio completo, se usa vSphere HA para iniciar la máquina virtual de HANA en el host ESX secundario. Cuando la máquina virtual de HANA se está ejecutando, se debe iniciar la base de datos HANA. Por lo tanto, el objetivo de tiempo de recuperación total depende principalmente del momento de inicio de la base de datos de HANA.
Comparación de soluciones
La siguiente tabla ofrece un resumen de las características clave de las soluciones descritas anteriormente.
| Replicación de sistemas HANA | Sincronización activa de SnapMirror: Nativo | Sincronización activa de SnapMirror – VMware VMSC | |
|---|---|---|---|
RPO con cualquier fallo |
RPO=0 + replicación síncrona |
||
Objetivo de tiempo de recuperación con fallo de almacenamiento |
Objetivo de tiempo de recuperación < 1min |
Objetivo de tiempo de recuperación tras fallos de almacenamiento transparente=0 + |
|
Objetivo de tiempo de recuperación + con fallo del sitio o del host |
Objetivo de tiempo de recuperación < 1min |
Objetivo de tiempo de recuperación: En función del tiempo necesario para preparar el servidor y el inicio de la base de datos de HANA. |
Objetivo de tiempo de recuperación: Depende del tiempo necesario para el inicio de la base de datos de HANA. |
Automatización de la conmutación al respaldo |
Sí, Conmutación automática por error al host HSR secundario controlado por el grupo de marcapasos. |
Sí, en caso de un fallo de almacenamiento No, por fallos en el host o el sitio (Aprovisionamiento de host, conectar recursos de almacenamiento, iniciar la base de datos HANA) |
Sí, en caso de un fallo de almacenamiento Sí, en caso de fallo del host o del sitio (Conmutación al respaldo de la máquina virtual a otro sitio automatizada con vSphere HA, inicio de las bases de datos de HANA) |
Se requiere un servidor dedicado en el sitio secundario |
Sí, necesario para precargar los datos en la memoria y activar la conmutación por error rápida sin iniciar la base de datos. |
No, el servidor sólo es necesario en caso de recuperación tras fallos. Normalmente, el servidor utilizado para QA se utilizaría para la producción. |
No, Los recursos en el host ESX solo son necesarios en caso de recuperación tras fallos. Normalmente, los recursos de control de calidad se utilizarían para la producción. |