

Descripción general
 Sugerir cambios
Sugerir cambios
Comprender cómo afecta el almacenamiento por niveles FabricPool a Oracle y otras bases de datos requiere comprender la arquitectura de FabricPool de bajo nivel.
Arquitectura
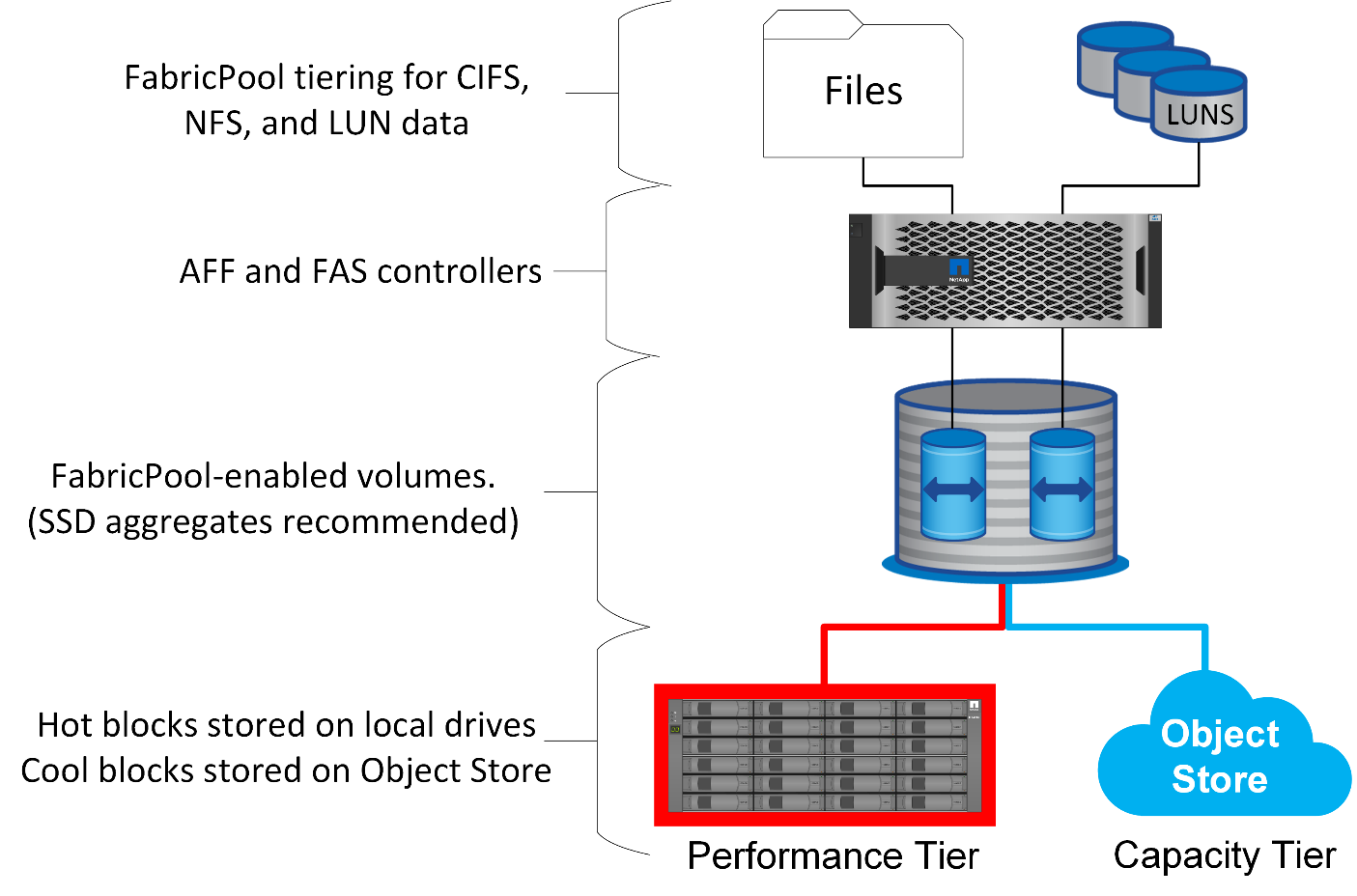
FabricPool es una tecnología de organización en niveles que clasifica los bloques como activos o inactivos y los coloca en el nivel de almacenamiento más adecuado. El nivel de rendimiento con mayor frecuencia se encuentra en el almacenamiento SSD y aloja los bloques de datos activos. El nivel de capacidad está ubicado en un almacén de objetos y aloja los bloques de datos inactivos. La compatibilidad de almacenamiento de objetos incluye NetApp StorageGRID, ONTAP S3, almacenamiento Microsoft Azure Blob, servicio de almacenamiento de objetos en el cloud de Alibaba, almacenamiento de objetos de IBM Cloud, almacenamiento de Google Cloud y Amazon AWS S3.
Existen varias políticas de organización en niveles disponibles que controlan la clasificación de los bloques como activos o inactivos, y las políticas se pueden establecer por volumen y modificar según sea necesario. Solo se mueven los bloques de datos entre los niveles de rendimiento y capacidad. Los metadatos que definen la LUN y la estructura del sistema de archivos siempre permanecen en el nivel de rendimiento. Como resultado, la gestión se centraliza en ONTAP. Los archivos y los LUN no aparecen diferentes de los datos almacenados en cualquier otra configuración de ONTAP. La controladora NetApp AFF o FAS aplica las políticas definidas para mover datos al nivel adecuado.
Proveedores de almacenes de objetos
Los protocolos de almacenamiento de objetos utilizan solicitudes HTTP o HTTPS sencillas para almacenar grandes cantidades de objetos de datos. El acceso al almacenamiento de objetos debe ser fiable, porque el acceso a los datos desde ONTAP depende de atender solicitudes rápidamente. Entre las opciones se incluyen las opciones de acceso estándar y poco frecuente de Amazon S3, y Microsoft Azure Hot and Cool Blob Storage, IBM Cloud y Google Cloud. No se admiten opciones de archivado como Amazon Glacier y Amazon Archive porque el tiempo necesario para recuperar los datos puede superar las tolerancias de las aplicaciones y los sistemas operativos del host.
También se ofrece compatibilidad con NetApp StorageGRID y es una solución empresarial óptima. Es un sistema de almacenamiento de objetos de alto rendimiento, escalable y altamente seguro que puede proporcionar redundancia geográfica para los datos de FabricPool, así como otras aplicaciones de almacenamiento de objetos que tienen cada vez más probabilidades de formar parte de entornos de aplicaciones empresariales.
StorageGRID también puede reducir los costes al evitar los cargos por salida que imponen muchos proveedores de cloud público por leer los datos de sus servicios.
Los datos y metadatos
Tenga en cuenta que el término «datos» aquí se aplica a los bloques de datos reales, no a los metadatos. Solo los bloques de datos se organizan en niveles, mientras que los metadatos permanecen en el nivel de rendimiento. Además, el estado de un bloque como activo o inactivo solo se ve afectado por la lectura del bloque de datos real. La simple lectura del nombre, la marca de tiempo o los metadatos de propiedad de un archivo no afecta a la ubicación de los bloques de datos subyacentes.
Completos
Aunque FabricPool puede reducir significativamente el espacio físico de almacenamiento, no es por sí misma una solución de backup. Los metadatos de NetApp WAFL siempre permanecen en el nivel de rendimiento. Si un desastre catastrófico destruye el nivel de rendimiento, no se puede crear un nuevo entorno con los datos del nivel de capacidad porque no contiene metadatos de WAFL.
Sin embargo, FabricPool puede formar parte de una estrategia de backup. Por ejemplo, FabricPool se puede configurar con la tecnología de replicación SnapMirror de NetApp. Cada mitad del reflejo puede tener su propia conexión con un destino de almacenamiento de objetos. El resultado es dos copias independientes de los datos. La copia primaria consiste en los bloques del nivel de rendimiento y los bloques asociados del nivel de capacidad, y la réplica es un segundo conjunto de bloques de rendimiento y capacidad.