

Cómo la arquitectura NetApp AFX difiere de ONTAP unificado
 Sugerir cambios
Sugerir cambios
NetApp AFX introduce diferencias arquitectónicas significativas respecto a ONTAP unificado en cómo se presenta el almacenamiento, cómo interactúan los nodos con los discos y cómo se gestiona la capacidad.
Anteriormente, mostramos una imagen general de cómo la arquitectura unificada de ONTAP proporciona almacenamiento de archivos, objetos y bloques de datos a través de pares de HA conectados directamente que poseen sus propios conjuntos de discos y presentan capacidad física a través de agregados de discos. En esta sección, analizaremos con más detalle algunas de las principales diferencias entre las arquitecturas unificadas de ONTAP y NetApp AFX.
Cómo saber si un sistema está ejecutando NetApp AFX
La principal forma de ver si tu sistema está ejecutando NetApp AFX es ejecutar el siguiente comando:
AFX::> node show -fields personality node personality ---------------- ----------- afx-01 AFX afx-02 AFX
Otra pista es la nueva Storage Availability Zone, pero ese también es un concepto disponible en NetApp All-SAN Arrays (ASA). Puedes ver tu capacidad a través de ese comando.
AFX::> storage availability-zone show
Availability Zone Name: storage_availability_zone_0
Availability Zone UUID: 545cb59f-32e9-11f1-a2f5-d039eabdd925
Total Size: 69.59TB
Physical Used: 837.1GB
Physical Used Percent: 1%
Available: 68.77TB
Metadata Used: 837.1GB
Log and Recovery Metadata: 834.6GB
Delayed Frees: 2.50GB
Physical User Data Without Snapshot Copies: 17.24MB
Logical User Data Without Snapshot Copies: 17.24MB
Efficiency Ratio Without Snapshot Copies: 1.00:1
Space Full Threshold Percent: 98%
Space Nearly Full Threshold Percent: 95%
Relaciones entre nodos y discos
En la arquitectura unificada de ONTAP, las lecturas y escrituras se dirigen a un subconjunto específico de discos. Así que, aunque tengas 24 estanterías de discos en un clúster de 24 nodos (una estantería por nodo), en cualquier momento cada nodo solo puede acceder directamente a una estantería de discos, lo que limita la capacidad y el rendimiento disponibles en el clúster.

Además, como la NVRAM está conectada directamente entre pares de HA, los nodos deben residir físicamente uno al lado del otro y están más estrechamente acoplados como objetivos de conmutación por error. Por ejemplo, cuando un nodo conmuta por error a su nodo asociado, los únicos discos a los que tiene acceso físico son los discos del dominio del par de HA.
Clúster ONTAP unificado durante la conmutación por error de HA

En NetApp AFX, hay algunos cambios importantes en la forma en que los discos se presentan a los nodos de cálculo.
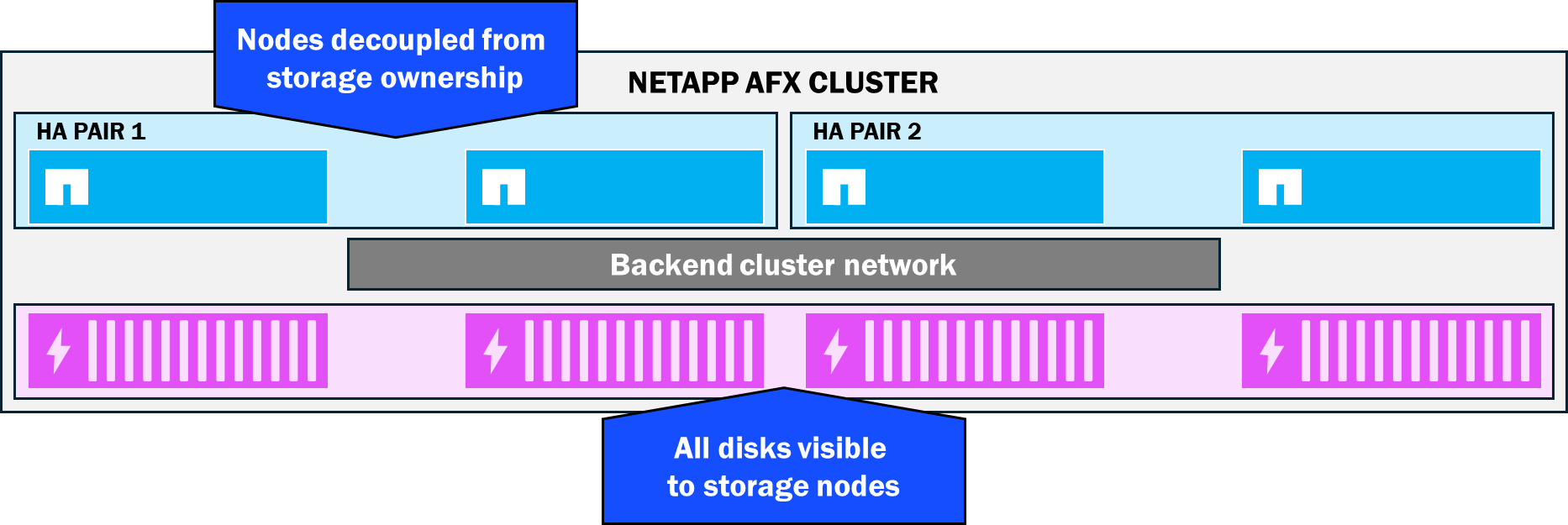
Todos los discos son visibles para todos los nodos de almacenamiento—sin propiedad de disco
En NetApp AFX, los nodos y las estanterías están todos conectados al mismo switch backend, lo que hace posible que ONTAP amplíe el dominio de visibilidad global de los discos a toda la pila. Como resultado, ningún nodo posee discos específicos. En su lugar, todos los discos participan en un único pool de capacidad llamado Storage Availability Zone, que proporciona una gestión de capacidad más sencilla y un mayor potencial de rendimiento (más discos disponibles significa más rendimiento disponible).
NetApp Zona de disponibilidad de almacenamiento AFX
No más agregados físicos
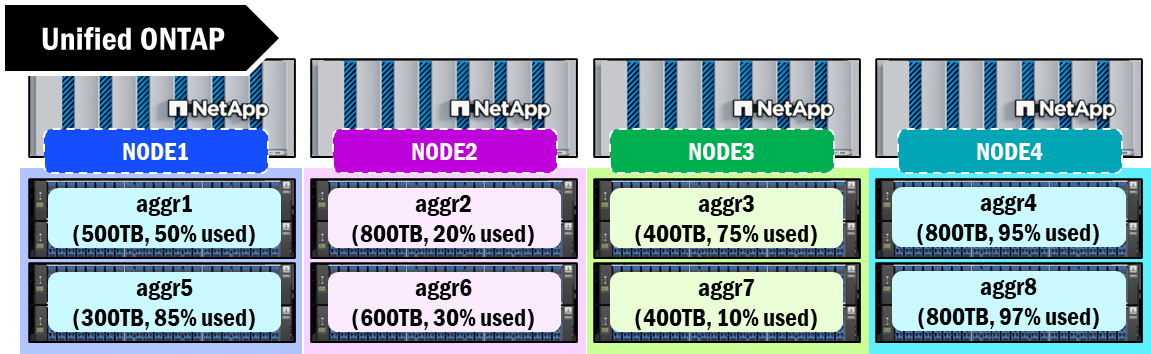
Unified ONTAP agrupa los discos en grupos RAID y luego los combina en una construcción de capacidad conocida como agregado. Este agregado es la forma en que la capacidad física se presenta al almacenamiento y es el límite de espacio disponible para crear volúmenes para servir datos a los usuarios finales. Cada nodo debe tener al menos un agregado asignado y estos agregados tienen un límite actual de 800TB. Una vez alcanzado ese límite, no hay más espacio disponible para escrituras adicionales.
Los agregados físicos también pueden presentar algunos desafíos de gestión de capacidad, ya que los administradores de almacenamiento a veces tendrán que mover manualmente los volúmenes para mantener un equilibrio de capacidad entre los nodos del clúster. Estos desafíos también pueden magnificarse cuando se aprovecha una arquitectura de volumen de escalado horizontal (como un volumen FlexGroup). Los agregados también pueden variar en tamaño, cantidad de discos, tipos de disco, etc., lo que también puede crear algunas diferencias de rendimiento a medida que atraviesas los nodos.
Agregados en ONTAP unificado
NetApp AFX toma el concepto de un agregado físico y lo virtualiza, lo convierte en un agregado gestionado por ONTAP y, a continuación, traslada la gestión de la capacidad física de una metodología por nodo a otra por clúster a través de la nueva Storage Availability Zone. Este grupo único de capacidad proporciona un enfoque de gestión de espacio del tipo "lo que ves es lo que hay".
NetApp Zona de disponibilidad de almacenamiento AFX

La NVRAM pasa de la conexión directa a la replicación conmutada
ONTAP utiliza NVRAM como una etapa intermedia para proteger las escrituras entrantes en un clúster. Cada nodo en un clúster ONTAP tiene una tarjeta NVRAM respaldada por batería. Cuando se envía una escritura a un volumen desde un cliente, primero se almacena en NVRAM. Luego, el contenido de la NVRAM se vuelca al disco cuando la NVRAM se llena o cuando expira un temporizador de 10s (lo que ocurra primero). Esto se conoce como punto de coherencia.
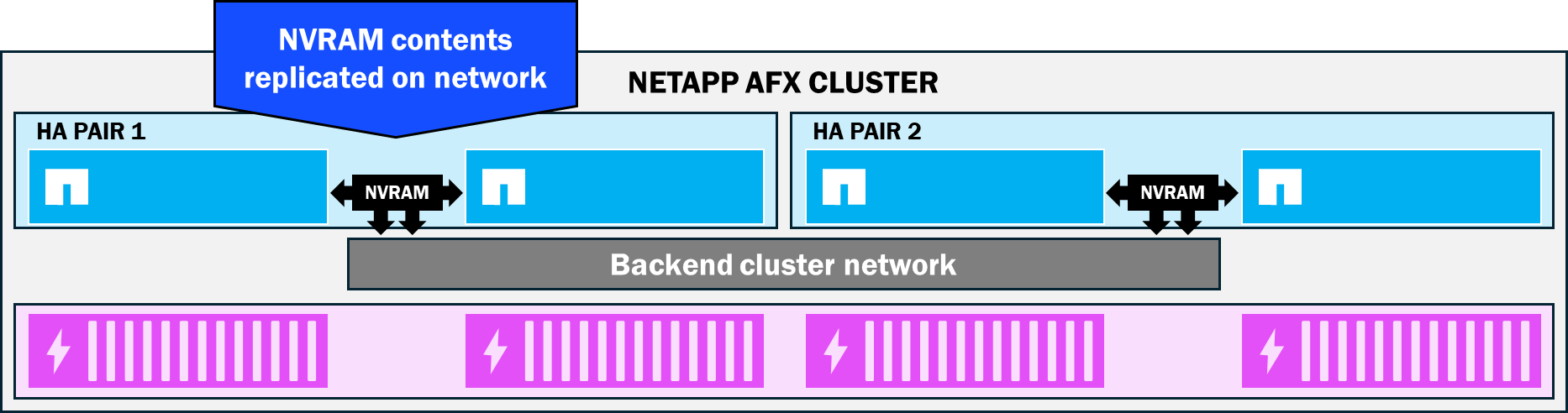
El contenido de la NVRAM también se replica constantemente entre los pares de HA, lo que ayuda aún más a proteger la coherencia de los datos, porque en caso de fallo de un nodo, el contenido de la NVRAM se conservará en el nodo superviviente y se comprometerá al disco.
En los clústeres ONTAP unificados, las tarjetas NVRAM entre pares de HA están conectadas directamente entre sí. NetApp AFX traslada la replicación de NVRAM a la red backend del clúster. Como resultado, los nodos asociados de HA no tienen un requisito de distancia entre nodos tan estricto. En su lugar, los pares de HA pueden separarse hasta la distancia máxima de ethernet.
NetApp AFX NVRAM replicación
Datos escritos en cualquiera (y todos) los discos de la zona de disponibilidad
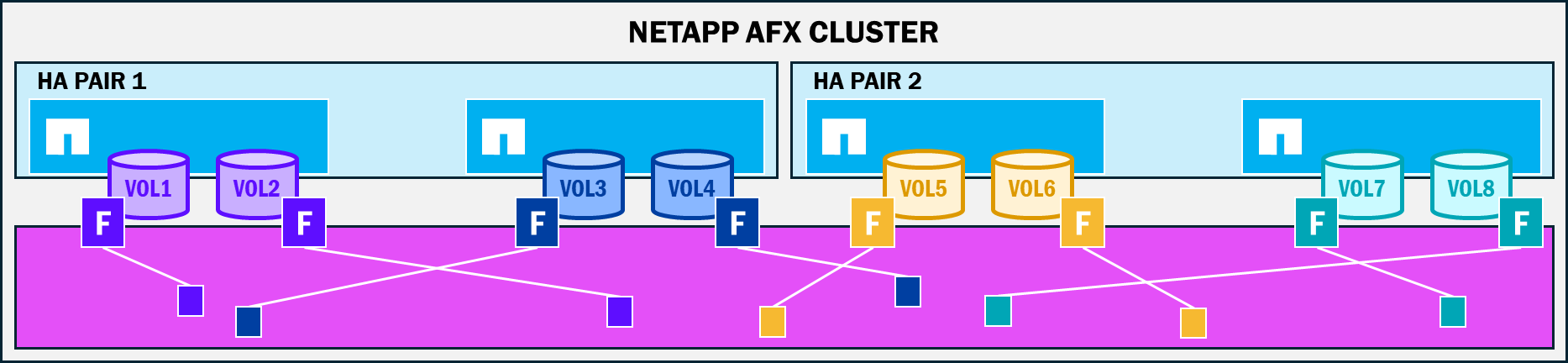
NetApp AFX elimina el concepto de propiedad del disco y traslada la construcción física agregada a un enfoque virtualizado gestionado por ONTAP, donde la capacidad adquirida para el clúster está disponible para todos los nodos conectados al clúster. Con AFX, todos los nodos tienen la capacidad de escribir en todos y cada uno de los discos de la zona de disponibilidad de almacenamiento, independientemente de cuál sea la propiedad del nodo:volumen. Los nodos siguen teniendo un concepto de propiedad de volumen, ya que las escrituras siguen teniendo una ruta a través de la NVRAM, pero esos datos pueden aterrizar en cualquier lugar de la capacidad disponible. Esto significa que un mayor número de discos puede participar en una sola carga de trabajo, lo que proporciona beneficios de rendimiento.
Cómo se ubican los datos en una Storage Availability Zone
Escalado independiente de capacidad y nodos de cómputo
Con los recursos de hardware desacoplados en la arquitectura NetApp AFX, los nodos ya no necesitan que se añadan discos asociados unos junto a otros. Cuando un clúster se está quedando sin recursos relacionados con el rendimiento, como RAM, CPU o el rendimiento de red, solo es necesario añadir nodos de almacenamiento al clúster y se puede aprovechar la Storage Availability Zone existente. Por el contrario, si lo que se necesita es capacidad, solo habría que añadir shelves a la mezcla. Esta flexibilidad asegura que solo compres los recursos que vas a necesitar, evitando así el sobreaprovisionamiento.
NetApp AFX – escala independiente
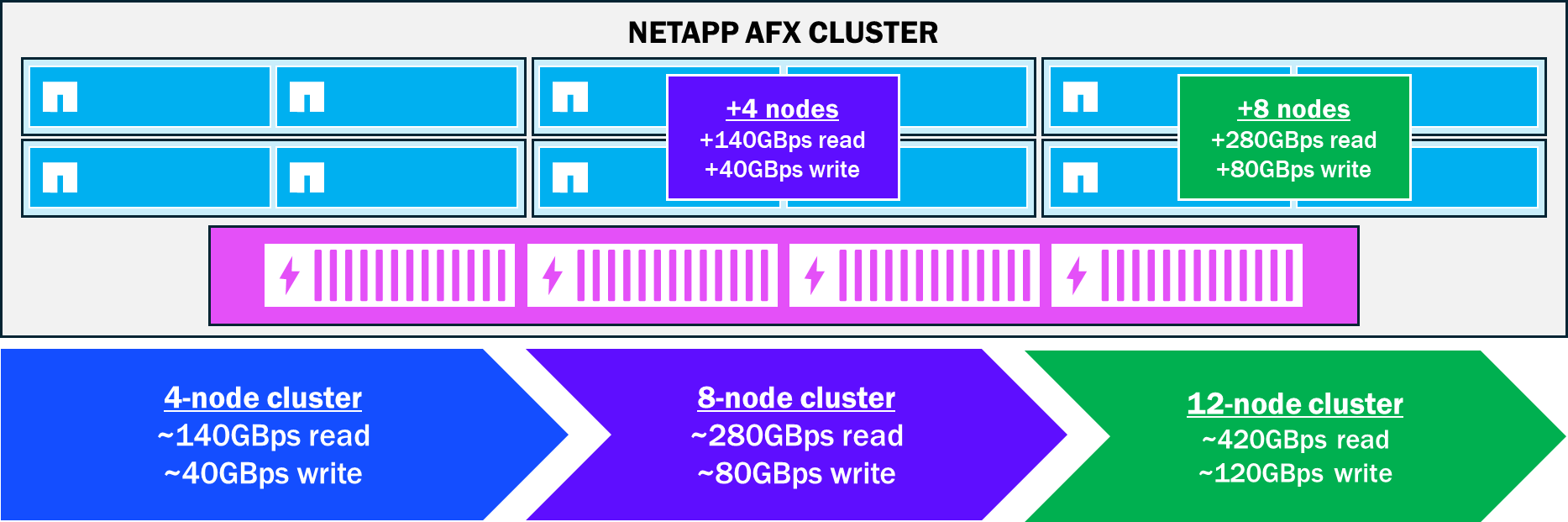
Escalado lineal del rendimiento de los nodos
A medida que se añaden nodos a un clúster AFX, se introducen más CPU, RAM y recursos de red en la carga de trabajo. A medida que estos recursos se incorporan al entorno, los aumentos de rendimiento son lineales por naturaleza. El gráfico siguiente muestra cómo aumentaría ese rendimiento a medida que se añaden nodos.
Aumento lineal del rendimiento al añadir nodos AFX a NetApp
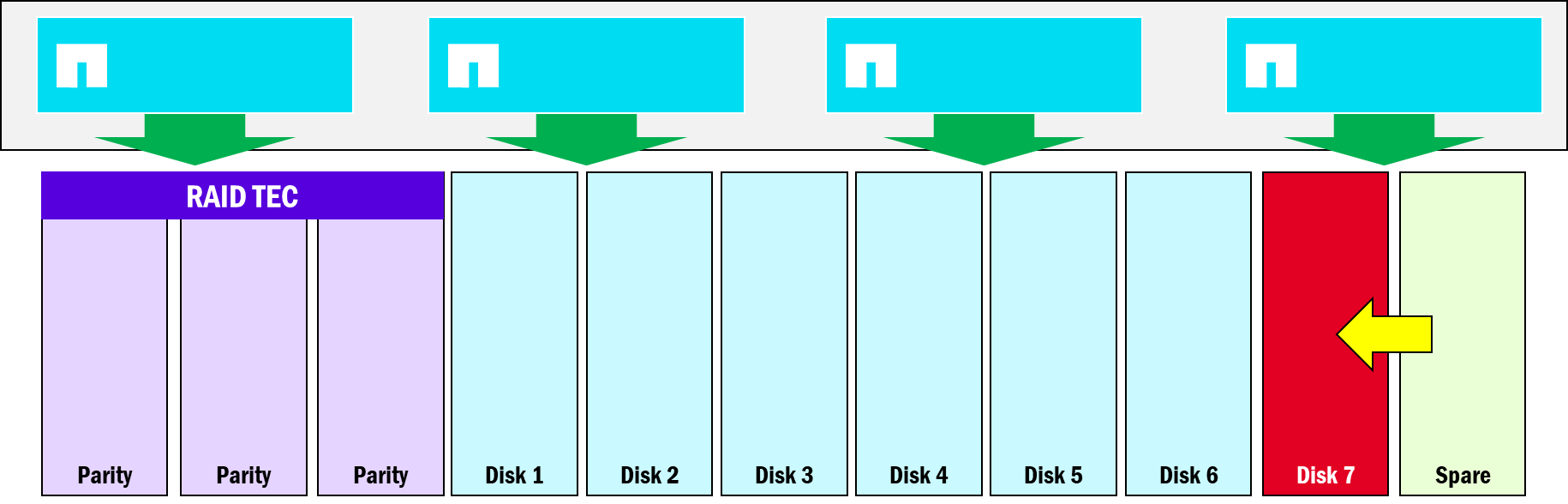
Grupos RAID más grandes, menos unidades de paridad
ONTAP ofrece una combinación de protección de datos y rendimiento para discos a través de grupos RAID, en concreto RAID-TEC, que ofrece protección de triple paridad en caso de fallos de disco. RAID-TEC puede sobrevivir hasta a tres fallos de disco simultáneos en un grupo RAID. En ONTAP unificado, los grupos RAID tienen un número máximo de discos de 28, donde 3 unidades se gastan en paridad y 1 unidad se reserva como repuesto. Como resultado, 24 de las 28 unidades se utilizan para operaciones de datos/RAID stripes.
Grupos RAID unificados de ONTAP

NetApp AFX sigue aprovechando RAID-TEC, pero aumenta el tamaño del grupo RAID a 96 unidades y solo requiere 3 unidades de paridad y 1 de repuesto. Los grupos RAID más grandes ofrecen un mayor rendimiento general, mientras que la exposición a fallo de unidad se minimiza gracias a una combinación de bajas tasas de fallo de las SSD, una distribución más uniforme de las operaciones entre un conjunto más grande de unidades, así como mejoras en las reconstrucciones de las unidades de datos a partir de la paridad en NetApp AFX.
Grupo RAID de zona de disponibilidad de almacenamiento AFX de NetApp

La siguiente tabla aproxima la cantidad de capacidad utilizable en bruto para 84 discos en ONTAP unificado y NetApp AFX con distintos tamaños de unidad.
Comparación aproximada de capacidad bruta, 84 unidades – Unified ONTAP y NetApp AFX
| Tamaño de la unidad | Capacidad bruta aproximada (Unificada) | Capacidad bruta aproximada (AFX) |
|---|---|---|
7,6 TB |
~547,2TB |
~608TB (+60,8TB) |
15,3 TB |
~1101,6TB |
~1224TB (+122.4TB) |
30,6 TB |
~2203,2TB |
~2448TB (+244,7TB) |
60,1 TB |
~4327,2TB |
~4808TB (+480.8TB) |
Tiempos de reconstrucción de fallos de disco más rápidos
En ONTAP unificado, cada nodo es propietario de un subconjunto de discos de la pila de almacenamiento. Esto significa que ese nodo solo escribe en esos discos, pero también que las reconstrucciones de disco solo las gestiona un único nodo en caso de fallo de unidad.
NetApp AFX evita la necesidad de la propiedad del disco. Como resultado, todas las unidades se pueden escribir desde un solo nodo si es necesario. Eso también significa que cuando una unidad necesita ser reconstruida a partir de la paridad, todos los nodos en el clúster participan, así que las reconstrucciones de unidades pueden ocurrir más rápido que si un solo nodo tuviera que hacerlo solo.
Reconstrucción de discos en NetApp AFX
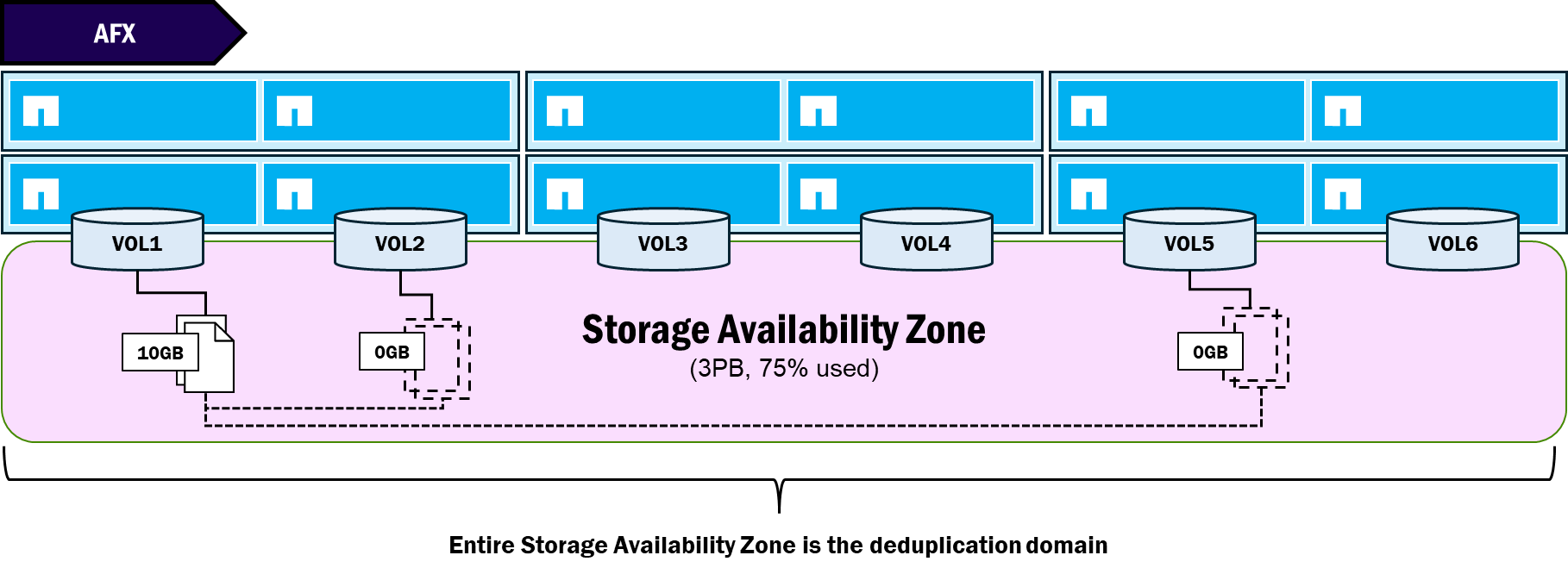
Dominios de deduplicación
La deduplicación permite a un sistema de almacenamiento encontrar bloques duplicados en su sistema de archivos y luego crear punteros a un único bloque para reducir la cantidad total de capacidad utilizada. En unified ONTAP, la deduplicación sigue un límite específico para los bloques que se pueden reducir. Esos límites dependen del tipo de deduplicación en uso. En general:
-
Deduplicación basada en volumen → Límite de volumen
-
Deduplicación cruzada de volúmenes → Límite de agregado
Dominios de deduplicación unificados de ONTAP

La siguiente tabla muestra los comportamientos de capacidad para datos duplicados en diferentes escenarios en ONTAP unificado. A medida que las copias de archivos abarcan nodos y agregados (y, por tanto, dominios de deduplicación), el ahorro de espacio se reduce.
Comportamientos de deduplicación en diferentes escenarios para archivos idénticos de 10GB – ONTAP unificado
| Escenario | Espacio utilizado |
|---|---|
Cuatro copias del mismo archivo de 10GB, mismo volumen (deduplicación de volumen) |
10 GB |
Cuatro copias del mismo archivo de 10 GB, volúmenes diferentes, mismo agregado (deduplicación entre volúmenes activada) |
10 GB |
Cuatro copias del mismo archivo de 10GB, 4 volúmenes diferentes, 4 agregados diferentes (deduplicación entre volúmenes activada) |
40 GB |
Dado que NetApp AFX elimina los agregados físicos y traslada la gestión de la capacidad a la nueva Storage Availability Zone, los límites del dominio de deduplicación también cambian. En AFX, el dominio de deduplicación se encuentra en el nivel de volumen (como ONTAP unificado) y en el nodo (en lugar del agregado) antes de 9.19.1.
A partir de ONTAP 9.19.1, AFX admite un dominio de deduplicación global a nivel de Storage Availability Zone, por lo que todos los bloques duplicados del storage pool del clúster reciben el mismo tratamiento.
NetApp AFX – Dominio de deduplicación global (ONTAP 9.19.1)
La siguiente tabla muestra los comportamientos de capacidad para datos duplicados en diferentes escenarios en NetApp AFX.
Comportamiento de la deduplicación en distintos escenarios para archivos idénticos de 10 GB – NetApp AFX
| Escenario | Espacio utilizado |
|---|---|
Cuatro copias del mismo archivo de 10GB, mismo volumen (deduplicación de volumen) |
10GB (9.18.1) 10GB (9.19.1) |
Cuatro copias del mismo archivo de 10GB, volúmenes diferentes, mismo nodo (deduplicación entre volúmenes activada) |
10GB (9.18.1) 10GB (9.19.1) |
Cuatro copias del mismo archivo de 10 GB, 4 volúmenes diferentes, 4 nodos diferentes (deduplicación entre volúmenes activada) |
40GB (9.18.1) 10GB (9.19.1) |
Funciones eliminadas/no compatibles
NetApp AFX está diseñado para cargas de trabajo NAS y de objetos de alto rendimiento, en particular (pero no exclusivamente) las del espacio de entrenamiento e inferencia de IA. Con el diseño de NetApp AFX, se tomaron algunas decisiones para desactivar algunas de las funciones de ONTAP.
-
Debido al enfoque en NAS de alto rendimiento y objetos, las cargas de trabajo de bloque se han eliminado de la solución NetApp AFX. No hay soporte para protocolos de datos FCP, iSCSI o NVMe y no hay planes para añadir protocolos de bloque.
-
Disaggregated es sinónimo de de-aggregated, lo que significa que se han eliminado los agregados (al menos como concepto de administración de almacenamiento físico). La eliminación del agregado físico no solo simplifica la gestión de la capacidad en ONTAP, sino que también proporciona el mecanismo que permite disponer de un único pool de capacidad.
-
La eliminación de los agregados significa que también se eliminan las funciones específicas de los agregados. Metrocluster, por ejemplo, aprovecha la duplicación a nivel de agregado para sus funciones de conmutación por error de sitio. Por lo tanto, Metrocluster también se elimina de NetApp AFX. En su lugar, la funcionalidad de conmutación por error de sitio será proporcionada por la nueva función SnapMirror Active-Sync para NAS ofrecida en ONTAP 9.19.1GA.
-
La función de jerarquización de datos en frío denominada FabricPool tampoco está disponible actualmente para NetApp AFX, ya que también es específica de cada agregado.
-
Los movimientos de volumen basados en copias ya no son necesarios en NetApp AFX, debido a la nueva arquitectura de capacidad. Para obtener más información, consulta Movimientos de volúmenes con copia cero.
-
La eliminación de funciones también implica algunos cambios en la CLI/GUI/API de REST, por lo que también se eliminarán los comandos o las llamadas a la API de las funciones que ya no sean compatibles.
-
ZAPI no está disponible actualmente para NetApp AFX.
-
Descarga de copia de datos NFS para virtualización (volúmenes FlexGroup con distribución granular de datos solamente)
Cambios en la gestión de ONTAP
En general, la gestión de NetApp AFX no cambia los mecanismos utilizados para gestionar un clúster. Los administradores pueden seguir utilizando la CLI, la GUI y las API de REST para iniciar sesión y configurar un clúster. Pero NetApp AFX sí presentó una oportunidad para mejorar algunos aspectos de cómo se llevan a cabo las operaciones de gestión del almacenamiento.
Gestión más sencilla de la capacidad
La NetApp AFX Storage Availability Zone reduce los puntos finales de gestión de un enfoque basado en nodos y agregados a un único pool de capacidad disponible para todo el clúster. A medida que los volúmenes crecen y se reducen, ONTAP toma y devuelve capacidad automáticamente a y desde la Storage Availability Zone.
Gracias a ello, los administradores de almacenamiento ya no tienen que preocuparse de localizar y gestionar el espacio libre disponible en hasta 24 nodos y, potencialmente, cientos de agregados. En su lugar, solo hay un lugar donde se gestiona y visualiza la capacidad.
Por ejemplo, en la CLI de ONTAP unificado, si quieres ver la información sobre la capacidad física total de un clúster, usarías “aggregate show-space”, que luego mostraría cada entrada de aggregate. En NetApp AFX, tienes “cluster space show”, que mostrará solo la Storage Availability Zone.
Comparación lado a lado de los comandos CLI de capacidad en ONTAP unificado y NetApp AFX

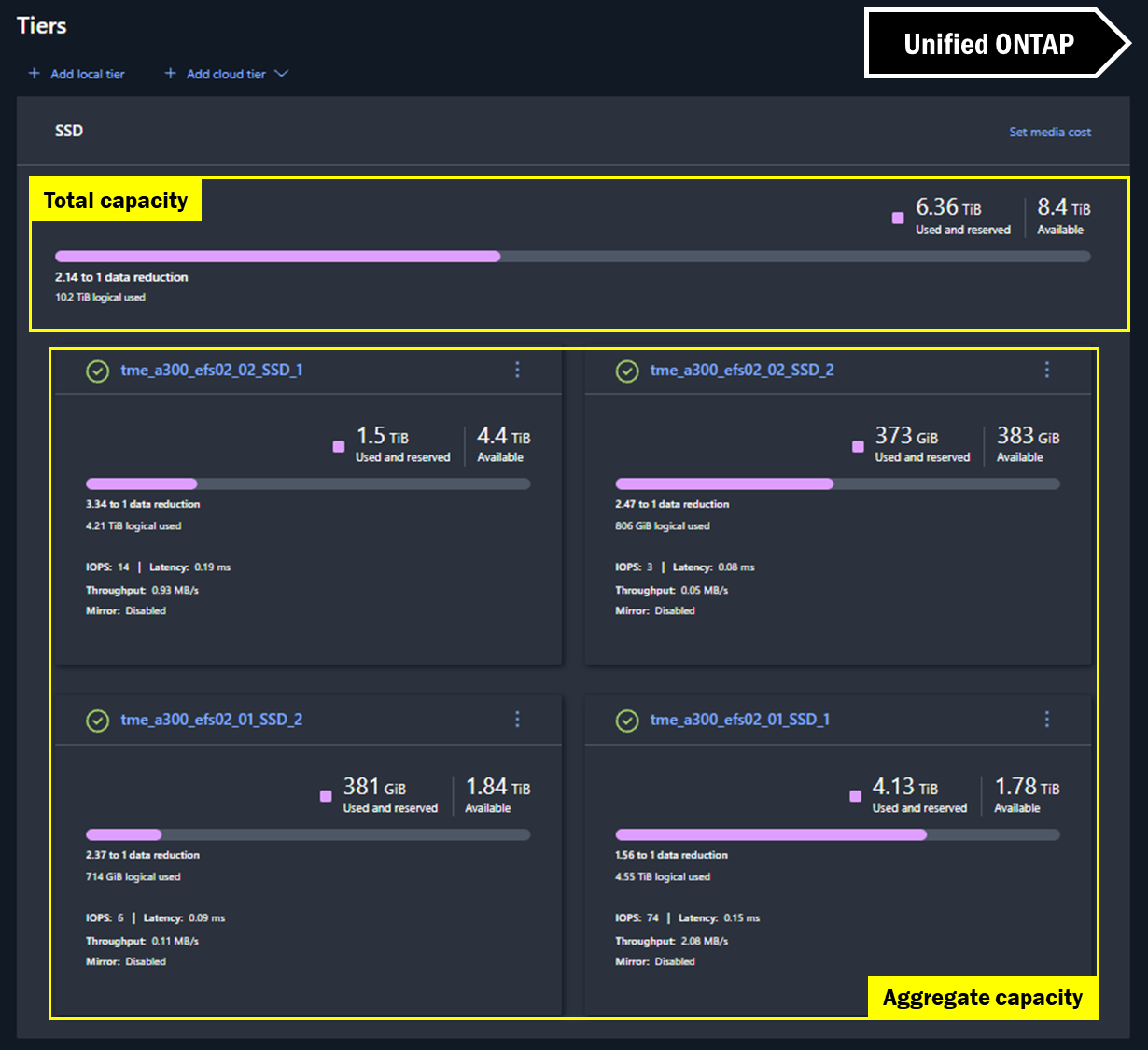
En la interfaz gráfica de usuario de Unified ONTAP System Manager, los niveles se utilizan para mostrar la capacidad. De hecho, la interfaz gráfica de usuario intenta mostrar la capacidad global del clúster sumando los totales, pero sigue mostrando el uso general por agregado.
Vistas de capacidad de System Manager – Unified ONTAP
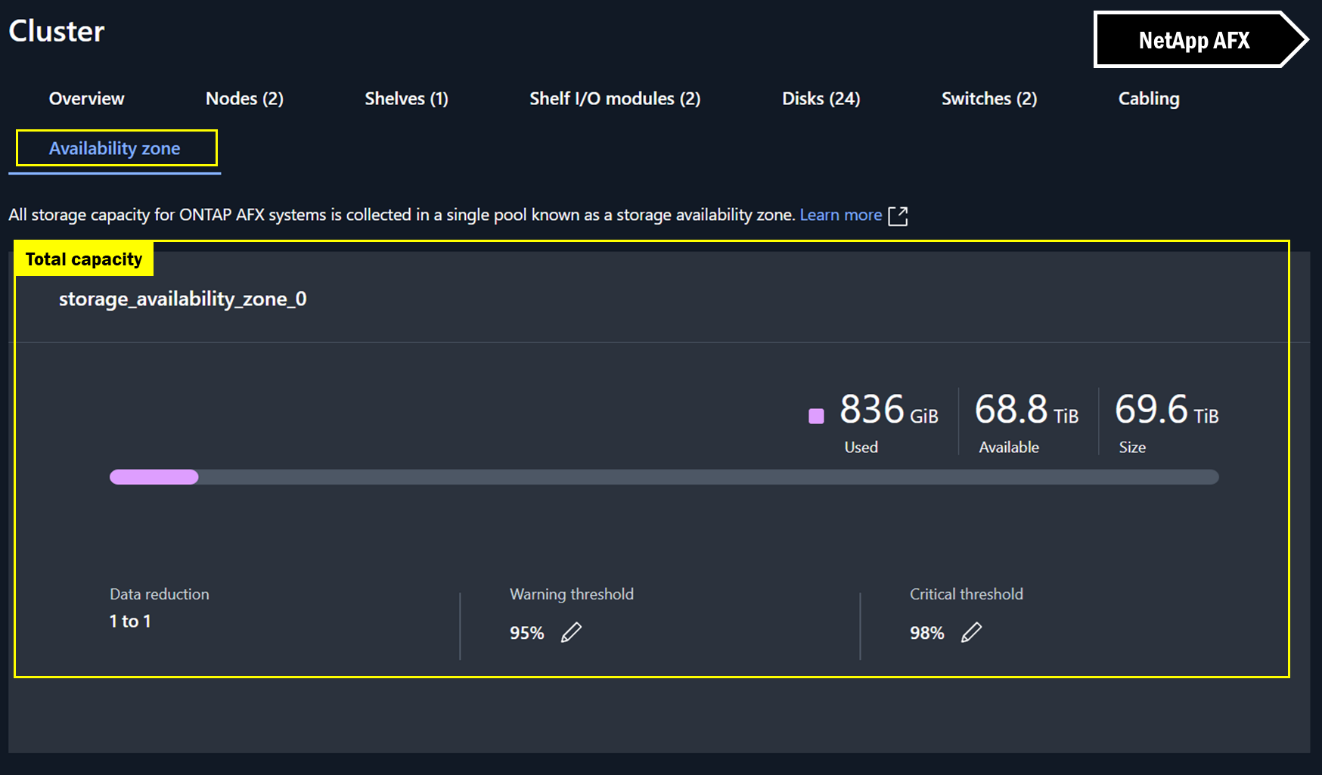
En NetApp AFX System Manager, la vista es prácticamente la misma para el espacio de clúster, pero como no hay agregados, no hay que hacer cálculos adicionales. La capacidad que ves es la capacidad que obtienes.
Vistas de capacidad de System Manager – NetApp AFX
FlexGroup mejoras en la gestión de volúmenes
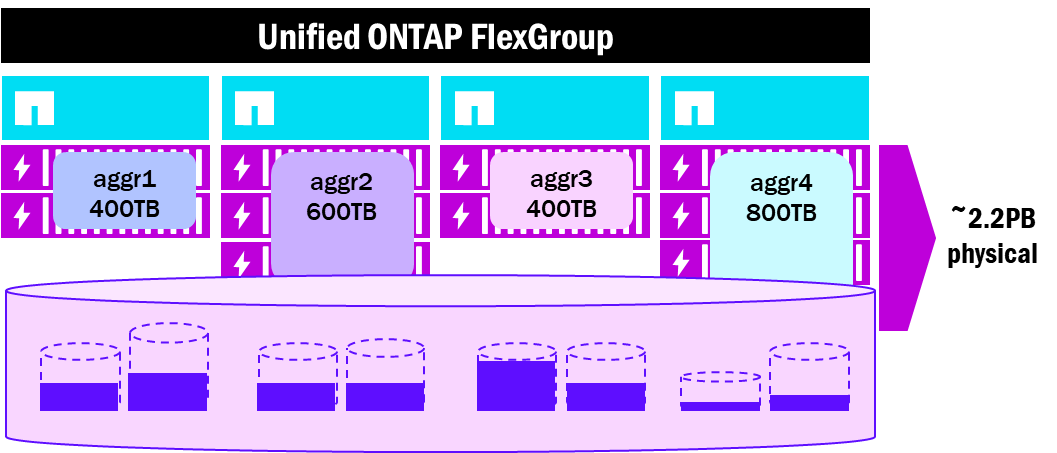
Un volumen FlexGroup consta de varios volúmenes constituyentes subyacentes FlexVol creados a través de varios nodos y agregados en el clúster y presentados como un único espacio de nombres grande a los clientes NAS. Los volúmenes FlexGroup proporcionan ventajas de rendimiento, escala, equilibrio de carga y recuento de archivos a las cargas de trabajo de alto rendimiento. Sin embargo, debido a que se coordinan a través de nodos y agregados, ocasionalmente se encuentran con algunas limitaciones físicas cuando la capacidad comienza a llenarse, ya que los sistemas de archivos independientes proporcionados por los agregados también tienen un uso y límites de capacidad independientes. Por ejemplo, si un agregado con volúmenes constituyentes FlexGroup comienza a llenarse antes que otros agregados en el clúster, entonces todo el FlexGroup podría estar sujeto a problemas de capacidad o rendimiento.
Como resultado, los administradores de almacenamiento pueden preocuparse demasiado por la infraestructura subyacente de FlexGroup y centrarse menos en el mantenimiento de otros aspectos del entorno.
FlexGroup distribución de volúmenes - agregados unificados de ONTAP
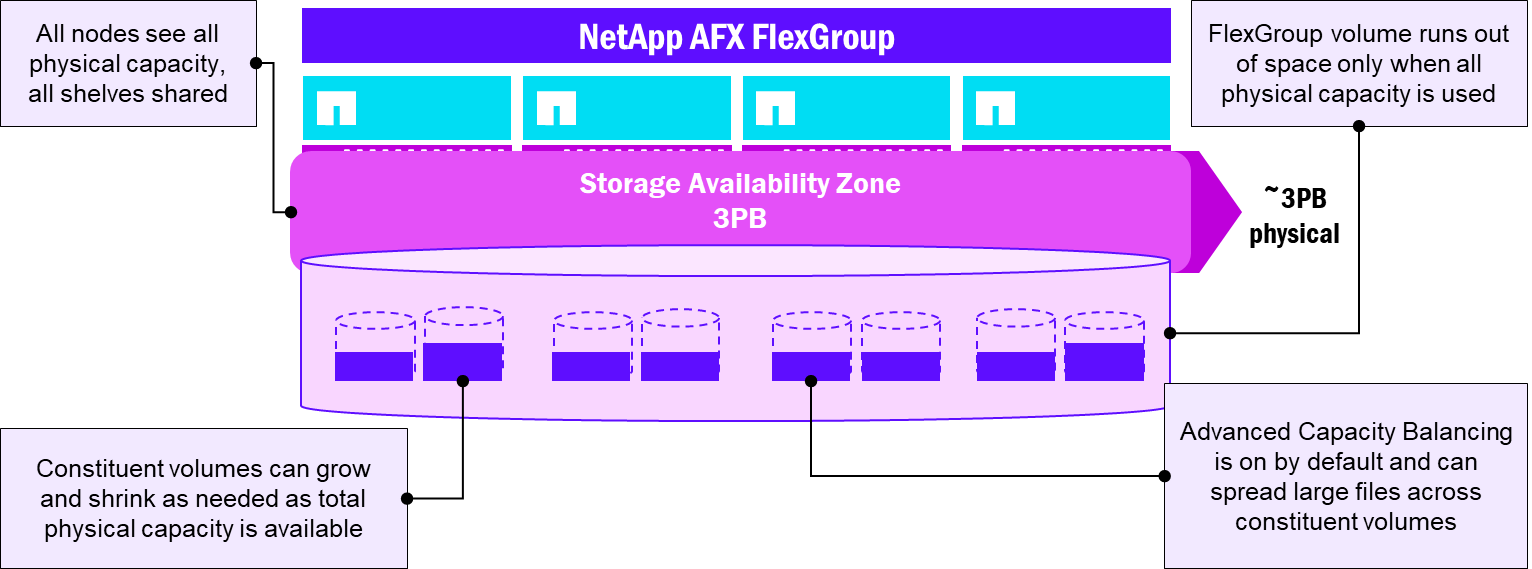
NetApp AFX presenta la capacidad en una única Storage Availability Zone, lo que refleja más fielmente la forma en que se pretende que funcionen los volúmenes FlexGroup. En lugar de múltiples volúmenes constituyentes a través de múltiples agregados dispares de tamaños potencialmente variables, todos los volúmenes residen en el mismo pool de capacidad, lo que simplifica en gran medida la sobrecarga de gestión global al usar un volumen FlexGroup.
Además, AFX habilita por defecto Advanced Capacity Balancing para los volúmenes de FlexGroup, lo que ayuda a distribuir mejor los archivos de mayor tamaño en el volumen. Ahora, los constituyentes del volumen de FlexGroup pasan a ser menos un concepto de gestión y, en su lugar, hacen su trabajo silenciosamente en segundo plano.
Disposición del volumen FlexGroup - NetApp AFX
Tareas automatizadas de administración del almacenamiento
Con la zona de disponibilidad de almacenamiento en NetApp AFX, toda la capacidad se comparte entre todos los nodos. Aunque los nodos siguen siendo propietarios de los volúmenes, ONTAP gestiona el uso de la capacidad de cada nodo automáticamente tomando prestada y liberando capacidad en función de lo que cada nodo necesite en cada momento. Esto significa que los administradores de almacenamiento ya no tienen que preocuparse de cómo equilibrar mejor el espacio utilizable.
Además, ONTAP automatiza la gestión de los grupos RAID, donde los nuevos discos se añaden a los grupos RAID existentes o nuevos sin intervención del administrador. ONTAP también gestiona los movimientos de volúmenes entre nodos sin necesidad de copia de datos.
Movimientos de volúmenes con copia cero
Unified ONTAP proporciona una forma de mover volúmenes de forma no disruptiva entre nodos o agregados como forma de gestionar el rendimiento y el uso de la capacidad en todo el clúster.
Cuando se inicia un movimiento de volumen, ocurre lo siguiente:
-
Se crea un nuevo volumen vacío en el agregado de destino especificado
-
Los metadatos del volumen (como la información sobre la eficiencia del almacenamiento, los identificadores de archivos, etc.) se replican en el nuevo volumen de destino
-
Los datos de volumen se replican en el volumen de destino a través de la red de clústeres de backend mediante la tecnología SnapMirror: el agregado de destino debe disponer de espacio libre para la transición o el trabajo de transición fallará
-
La replicación de volúmenes se realiza de nuevo para garantizar que ambos volúmenes son coherentes con cualquier cambio en los datos
-
Se inicia un proceso de transición para desconectar el volumen de origen y promover el volumen de destino como nuevo volumen de origen para los clientes
-
La E/S del cliente experimenta una breve pausa durante la transición, pero no se requieren remontajes
En NetApp AFX, la zona de disponibilidad de almacenamiento presenta toda la capacidad a todos los nodos, y todos los nodos pueden escribir en cualquier disco de ese pool. Una vez colocados los datos, permanecen donde están, incluso si se mueve el volumen. Esto significa que no es necesario copiar los datos. El proceso de movimiento del volumen es idéntico al de ONTAP unificado, menos la necesidad de replicar los datos a través de SnapMirror. No se requiere capacidad adicional.
Movimientos de volúmenes de copia cero en NetApp AFX
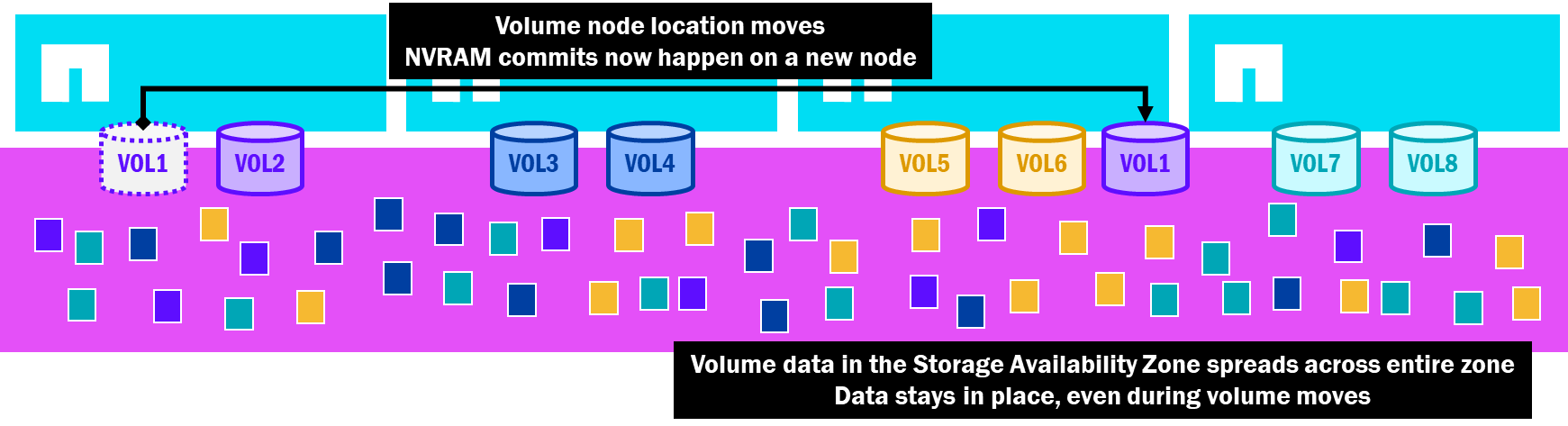
Disponer de una movilidad de volúmenes ligera permite a AFX automatizar muchas de las tareas de administración sin las limitaciones de rendimiento o capacidad, y estos movimientos de volúmenes se utilizan en algunas funciones nuevas que ofrece NetApp AFX, como se describe en los temas que se ven a continuación.
Comportamiento de conmutación por error en HA
En ONTAP unificado, los nodos son propietarios de discos y agregados, donde los datos se sirven a través de volúmenes. Las escrituras se realizan utilizando la NVRAM de un nodo local para volcarse a los discos que posee el nodo. Cuando un nodo se reinicia o falla, ONTAP activará una toma de control de los recursos del nodo fallido, donde la propiedad del disco y del agregado se transfiere al nodo asociado. Las interfaces de red también se transfieren a los puertos del espacio IP y, dado que el contenido de la NVRAM se replica constantemente en el par de HA, el nodo vaciará el contenido de la NVRAM para transferir las escrituras del nodo que ha fallado a los discos. Después de eso, el nodo superviviente será el propietario de los agregados y volúmenes del nodo fallido hasta que se produzca la recuperación del nodo. Esto significa que todo el tráfico de esos volúmenes, así como los volúmenes que ya son propiedad del nodo superviviente, se procesarán en un único nodo hasta que se resuelva el problema de la recuperación.
Como parte del despliegue inicial del clúster ONTAP unificado, se recomienda planificar con antelación las conmutaciones por error para evitar que un solo nodo sobrecargue a su compañero. Eso en sí mismo supone un reto, ya que es difícil predecir qué volúmenes pueden ser los agresores del rendimiento, pero funciones como el movimiento de volumen no disruptivo y las políticas de calidad de servicio de volumen pueden ayudar a mitigarlo.
Las siguientes imágenes muestran cómo los clusters ONTAP unificados pueden incurrir en un balance de rendimiento desigual entre nodos, así como cómo un failover puede crear una degradación del rendimiento en algunos casos.
ONTAP unificado: posibles desequilibrios en la utilización de nodos
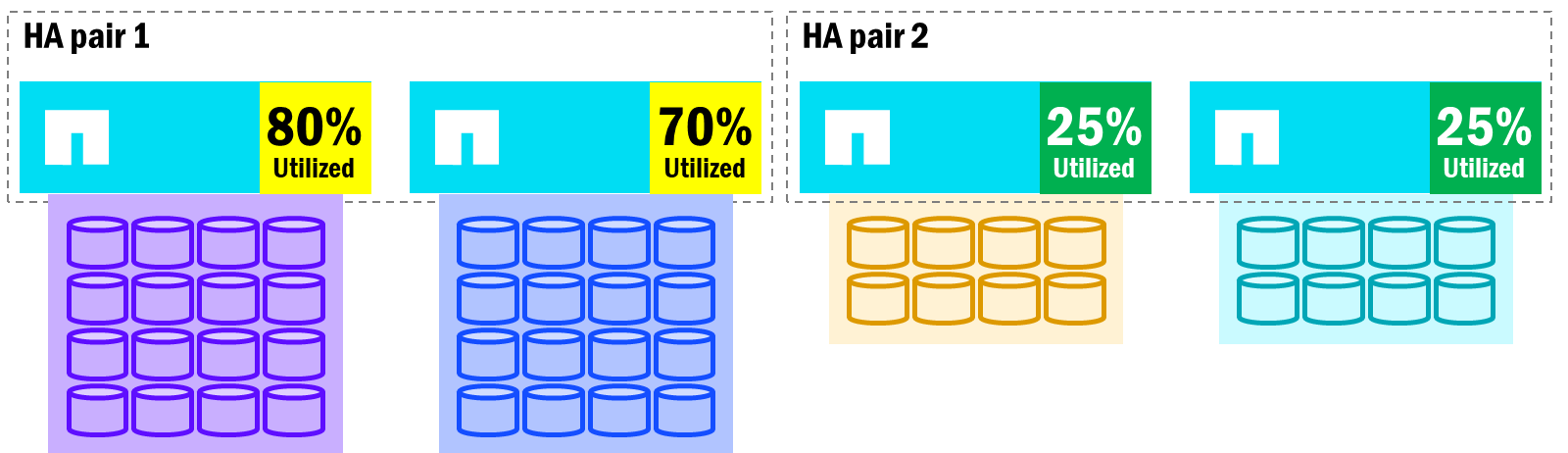
Cuando los nodos de un par de HA se desequilibran con el recuento de volúmenes y la utilización del rendimiento, los fallos de los nodos afectarán el rendimiento general, ya que el nodo superviviente ahora será propietario de todos los volúmenes del nodo que ha fallado. Mientras tanto, otros nodos del clúster pueden tener espacio para asumir trabajo adicional.
ONTAP unificado – Impacto de la conmutación por error en la utilización de nodos
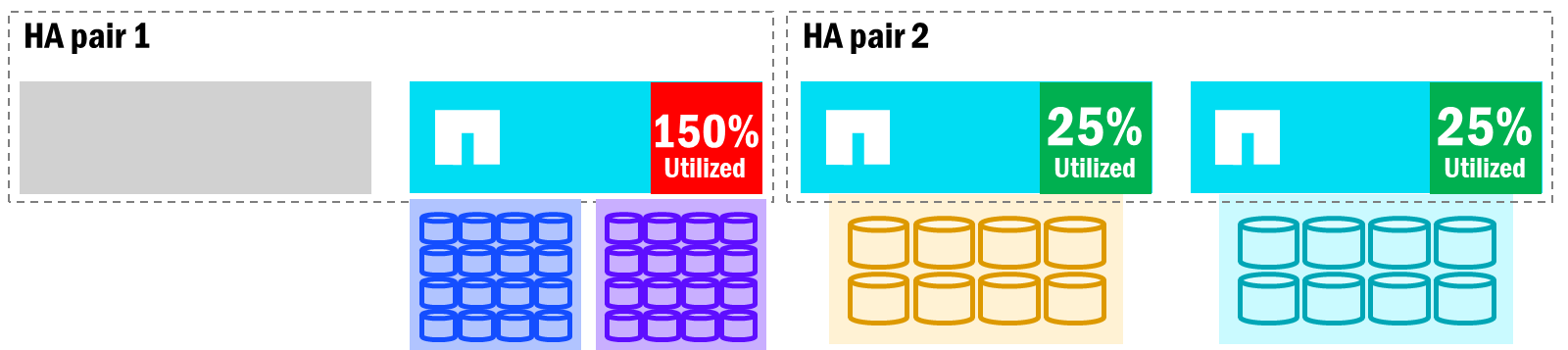
En el caso anterior, cuando un socio de HA tiene que asumir trabajo adicional, puede potencialmente sobrecargarse y afectar al rendimiento de todos los volúmenes en ese nodo. Los movimientos de volumen pueden ayudar a aliviar la situación, pero esos requieren copias entre nodos (lo que requiere espacio libre disponible), y el tiempo que lleva puede exceder el tiempo que tardan los nodos en recuperarse. Además, si reubicas un volumen, no volverá al nodo original. En su lugar, permanecerá en el nodo al que lo moviste.
Con NetApp AFX, las conmutaciones por error de los nodos adoptan algunos comportamientos diferentes.
-
Dado que los nodos no poseen discos y no hay agregados físicos, la conmutación por error de un nodo no requerirá la transferencia de esos recursos. En su lugar, solo se transfieren a otros nodos las interfaces de red y la propiedad de los volúmenes.
-
Los commits de NVRAM siguen produciéndose, pero a través de la red de HA en lugar de una conexión directa.
-
Una vez que los volúmenes realizan la conmutación por error inicial al nodo asociado, AFX redistribuirá los volúmenes entre otros nodos supervivientes del clúster. Esto es posible gracias a los movimientos de volúmenes de copia cero.
-
Cuando se recupere el nodo, los volúmenes volverán al nodo original.
NetApp AFX ya mantiene un equilibrio de rendimiento entre los nodos del clúster para mantener una utilización relativamente uniforme, así que cuando ocurre un failover y se reequilibran los volúmenes, la utilización de los nodos debería ser aproximadamente la misma en todo el clúster.
NetApp AFX - Reequilibrio de volúmenes tras la conmutación por error
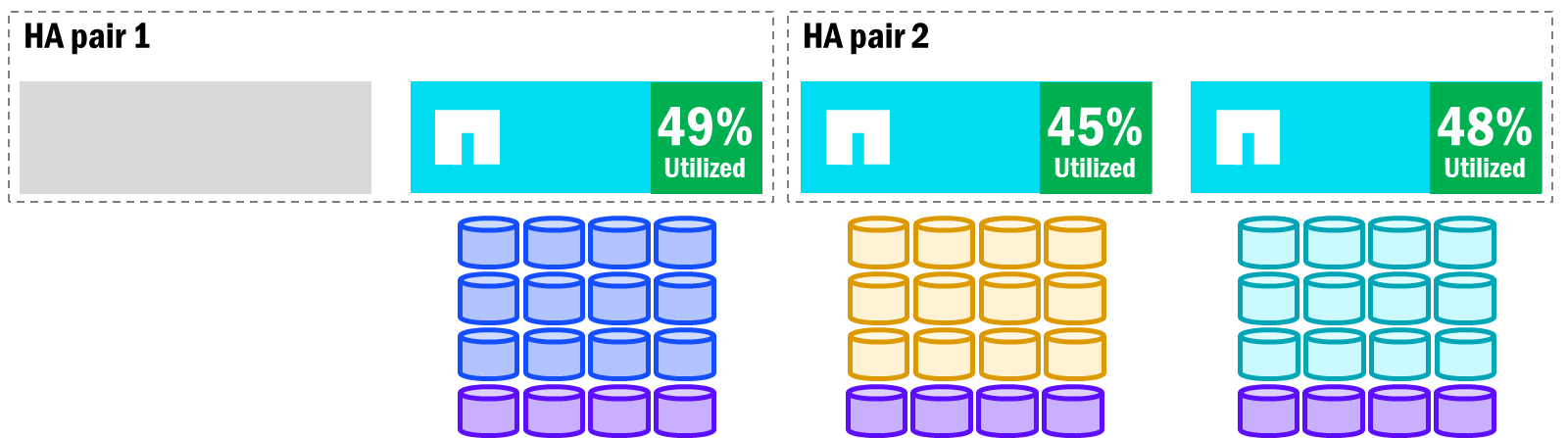
Adiciones y eliminaciones de nodos
Tanto ONTAP unificado como NetApp AFX permiten añadir y eliminar nodos del clúster. Sin embargo, debido a algunas de las diferencias arquitectónicas, el proceso para añadir y eliminar nodos difiere un poco.
Adición/eliminación de nodos en ONTAP unificado
Ya hemos aprendido que ONTAP unificado tiene una propiedad directa de nodo a disco y que todos los nodos deben tener algunos discos y al menos un agregado conectado a ellos. Teniendo esto en cuenta, lo siguiente es válido para adiciones y eliminaciones.
-
Las adiciones de nodos en ONTAP unificado no requieren ningún paso adicional, pero para proporcionar un rendimiento equilibrado en todos los nodos (incluidos los nuevos nodos), sería necesario mover los volúmenes a los nuevos nodos. Esto requiere un análisis previo de los volúmenes existentes y sus cargas de trabajo, decisiones sobre qué volúmenes mover y luego los movimientos de volumen reales, que, de nuevo, requerirían una copia de esos datos a través de la red de clúster backend.
-
Las eliminaciones de nodos en ONTAP unificado requerirían una evacuación manual de los volúmenes existentes en el nodo, lo que significa que tienes que identificar qué nodos pueden alojar qué volúmenes para mantener un rendimiento uniforme, y debes tener suficiente capacidad libre para proporcionar un lugar a donde mover esos volúmenes. Si la capacidad libre es un reto, puede que sea necesario mover volúmenes adicionales para reorganizar un poco las cargas de trabajo en el clúster. Las eliminaciones de nodos también implican eliminaciones de pares de HA, así que el trabajo se duplica. Como los nodos son dueños de los discos, también sería necesaria una reinicialización completa de los discos para esos nodos. Cada una de estas cosas añade tiempo y esfuerzo a lo que debería ser una tarea relativamente sencilla.
Adición/eliminación de nodos en NetApp AFX
También hemos aprendido que NetApp AFX no aprovecha la propiedad estándar de nodo a disco y no utiliza agregados físicos para presentar capacidad al clúster. Por eso, las incorporaciones y eliminaciones de nodos se comportan de manera un poco diferente.
-
Las adiciones de nodos en NetApp AFX no requerirán el mismo análisis previo de volúmenes ni la intervención administrativa para garantizar que cada nodo tenga un equilibrio uniforme de volúmenes. En su lugar, ONTAP equilibra automáticamente los recuentos de volúmenes entre los nodos recién añadidos para mantener perfiles de rendimiento relativamente uniformes. ONTAP moverá automáticamente los volúmenes entre los nodos sin copiar nada, lo que reduce el tiempo, la capacidad y el esfuerzo necesarios para añadir nodos a un clúster.
-
La eliminación de nodos en NetApp AFX tampoco requiere mucha, si es que alguna, intervención manual. Cuando se marca un nodo para eliminación, ONTAP mueve automáticamente los volúmenes entre los nodos (de nuevo, sin copiar) para evacuar los nodos que se eliminan. Y como no hay discos propiedad de los nodos, no es necesario reinicializar los discos después de eliminar nodos. Esto hace que los nodos en AFX sean modulares por naturaleza y fáciles de escalar hacia arriba o hacia abajo.
Movimientos de volumen condicionados por el rendimiento
NetApp La funcionalidad de movimiento de volumen de copia cero de AFX significa que puede reequilibrar volúmenes según sea necesario sin copiar datos, lo que le permite actuar con rapidez y sin necesidad de capacidad adicional. Esto significa que los movimientos de volumen pueden convertirse en una mayor parte del equilibrio de carga automatizado disponible para los clusters ONTAP. Ahora que mover un volumen no cuesta relativamente nada, ONTAP puede aprovechar esta valiosa herramienta para incorporar funciones como el equilibrio de carga de volúmenes condicionado por el rendimiento.
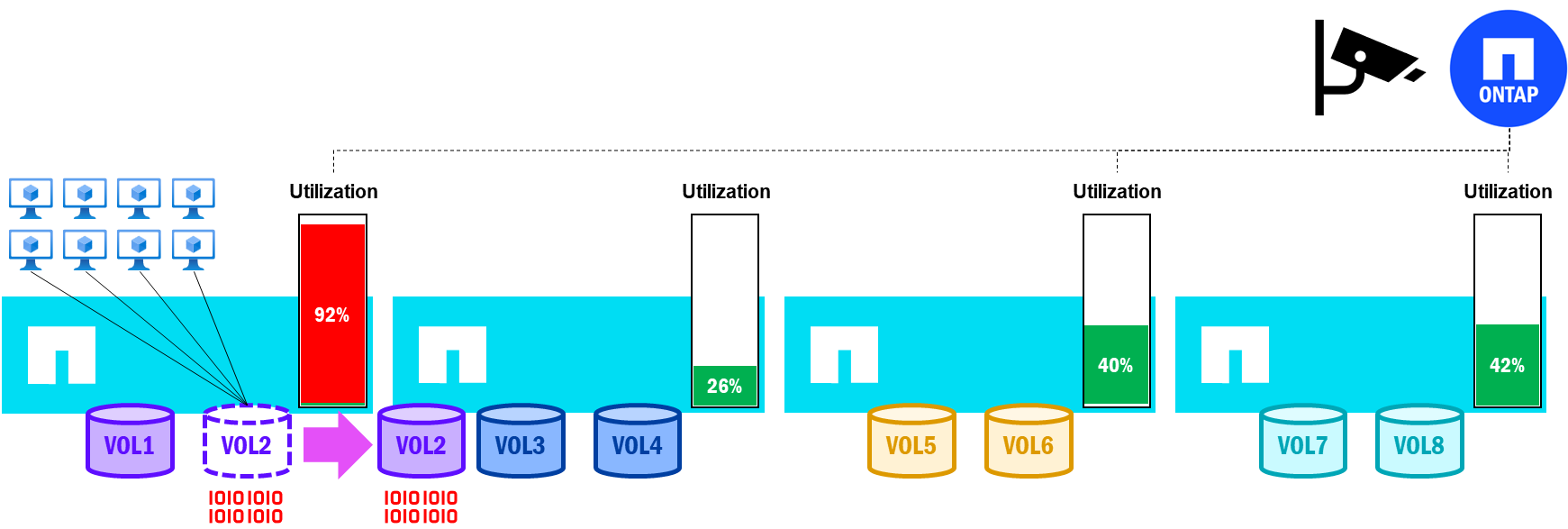
En NetApp AFX con ONTAP 9.18.1 y versiones posteriores, la utilización de nodos, pares de HA y volúmenes se supervisa constantemente, mientras se recopilan y analizan los datos de rendimiento. Si la utilización de un nodo cae fuera de los umbrales definidos, ONTAP seleccionará automáticamente un volumen para moverlo a un nodo menos utilizado en un esfuerzo por mantener un rendimiento equilibrado en todo el clúster.
Movimientos de volumen condicionados por el rendimiento en NetApp AFX – una alta utilización desencadena un movimiento de volumen
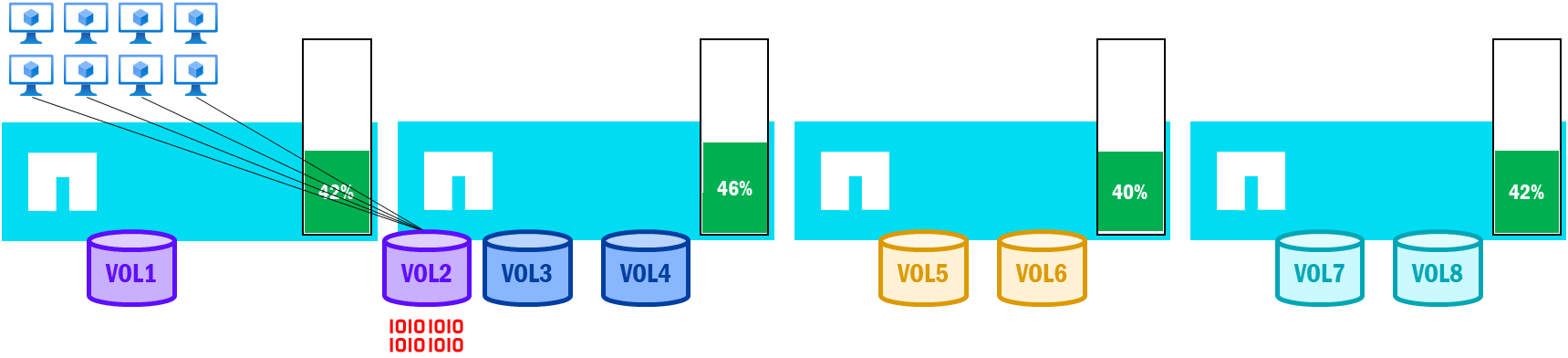
Movimientos de volumen condicionados por el rendimiento en NetApp AFX – Utilización equilibrada de nodos tras el movimiento de volumen
Escala y expansión de clústeres
Los clústeres Unified ONTAP admiten hasta 24 nodos y cada nodo que se añada también debe añadirse con discos (tanto para la funcionalidad del sistema como para los servicios de datos). Se pueden añadir estantes de discos al clúster, pero siempre están conectados a un único par de alta disponibilidad y son propiedad de un solo nodo, incluso si el clúster tiene 24 nodos. Esto significa que se añade capacidad a un clúster incluso cuando solo se necesita rendimiento, y ese aumento de rendimiento queda relegado en su mayor parte a un conjunto específico de discos propiedad de los nuevos nodos. Como resultado, es posible que termines con una capacidad extra que no necesitas necesariamente.
Unified ONTAP – consideraciones de escala añadidas
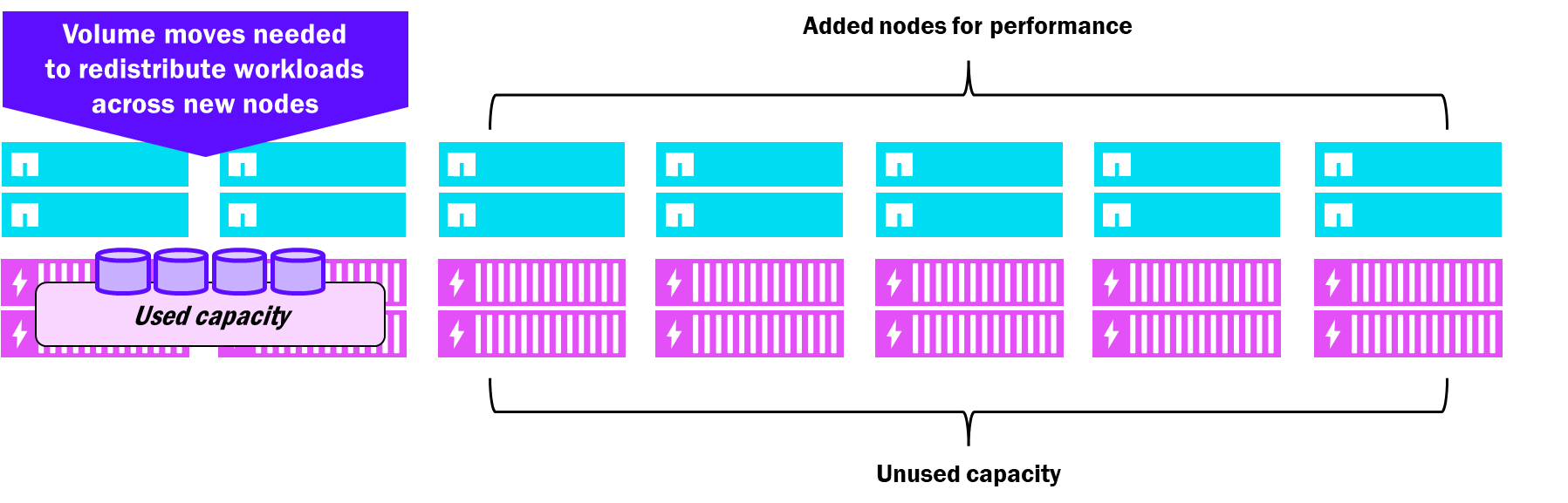
NetApp AFX es compatible con clústeres a mayor escala. A partir de la versión 9.19.1, los clústeres AFX pueden alcanzar los 32 nodos en un único clúster. Y como todos los nodos pueden ver y acceder a todos los discos, todos pueden compartir el rendimiento y la capacidad (hasta 32PB a partir de ONTAP 9.19.1) de esos discos para que nunca haya ningún recurso varado. Los movimientos de volúmenes no requieren copias, por lo que ONTAP es capaz de mover automáticamente los volúmenes a los nodos recién añadidos para garantizar una utilización uniforme de los nodos, mientras que la capacidad se distribuye uniformemente a través de la Storage Availability Zone.
NetApp AFX – consideraciones de escala añadidas

Cambios en el volumen raíz
En NetApp ONTAP, a cada nodo se le asigna un volumen raíz, que se utiliza para archivos y funciones específicos del sistema, como archivos de registro, imágenes de arranque, archivos de núcleo, bases de datos de clúster y más.
En ONTAP unificado, esos volúmenes raíz vivían en agregados raíz físicos. Para reducir la cantidad de capacidad que utilizaban los agregados raíz, se crearon a través de particiones de unidades de datos mediante Advanced Disk Partitioning (ADP).
NetApp AFX elimina los agregados físicos de la ecuación y, como resultado, elimina la necesidad de utilizar agregados raíz y ADP. Los volúmenes raíz siguen siendo un concepto, pero ahora viven en áreas virtualizadas del pool de capacidad y no requieren configuración adicional. Además, la funcionalidad del volumen raíz cambia. Las imágenes de arranque y las bases de datos de clúster replicadas se trasladan de la pila de almacenamiento a un medio de arranque integrado que se encuentra en cada nodo AFX. Ahora, si se pierde el acceso a la pila de almacenamiento, los nodos pueden seguir arrancando y mantener la elegibilidad del clúster, lo que reduce la complejidad de la resolución de problemas.
Medios de arranque a bordo
NetApp Los nodos AFX utilizan un medio de arranque integrado, que es un dispositivo M.2 conectado a NVMe de aproximadamente 3,8 TB. Estos dispositivos de arranque contienen archivos de imagen de arranque y bases de datos replicadas que están separadas de las cabinas de almacenamiento, lo que proporciona redundancia adicional en caso de problemas de acceso al disco. Si el medio de arranque falla, el nodo será asumido por su socio de HA y el medio de arranque puede ser reemplazado. Una vez reemplazado, un administrador de almacenamiento cargará una nueva imagen de ONTAP en el dispositivo y ONTAP reconstruirá automáticamente la base de datos del clúster para restaurar la funcionalidad completa.