

Rendimiento
 Sugerir cambios
Sugerir cambios
NetApp AFX se creó pensando en el rendimiento y la escalabilidad, específicamente orientado a cargas de trabajo que requieren un alto rendimiento de lectura y escritura y pueden ofrecer una escalabilidad simple y lineal.
Rendimiento por nodo
Cada nodo de almacenamiento NetApp AFX proporciona una cantidad específica de rendimiento para lecturas y escrituras. A medida que se añaden nodos al clúster, aumentan linealmente ese rendimiento, como se explica en la sección "Escalado lineal del rendimiento de los nodos" de este documento.
Actualmente, los tipos de nodo son "AFX 1K" y proporcionan un rendimiento para lecturas y escrituras de aproximadamente las cantidades indicadas a continuación. A medida que se disponga de hardware más nuevo para NetApp AFX, estos límites pueden cambiar. NOTA: El rendimiento máximo se alcanzó utilizando varios clientes que leían y escribían varios archivos, como se muestra en la sección "Benchmark results" a continuación.
Estimaciones de rendimiento por nodo
| Tipo de nodo | Rendimiento máximo de lectura | Rendimiento máximo de escritura |
|---|---|---|
AFX 1K |
~35GB/s |
~10GB/s |

|
Para conocer las estimaciones de rendimiento más actualizadas, consulta a tu equipo de ventas de NetApp. |
Rendimiento por estante
Cada estantería contiene módulos de estantería de alto rendimiento con 16 puertos Ethernet de 100 GB que aprovechan la comunicación RoCEv2 para una interacción de almacenamiento de ancho de banda elevado con los nodos de computación del clúster. Al igual que cualquier recurso físico, estas estanterías tienen máximos que se pueden alcanzar, especialmente porque NetApp AFX puede presentar múltiples nodos apuntando al mismo conjunto de discos. La siguiente tabla muestra el rendimiento máximo estimado de lectura y escritura para una sola estantería con unidades TLC y QLC. Para obtener más información sobre las diferencias entre TLC y QLC, consulta "TLC frente a QLC".
Estimaciones de rendimiento por estantería
| Tipo de módulo de estantería | Rendimiento máximo de lectura | Rendimiento máximo de escritura |
|---|---|---|
NSM 140 |
140GB/s (TLC y QLC) |
70GB/s TLC 35GB/s QLC |
|
|
Para conocer las estimaciones de rendimiento más actualizadas, consulta a tu equipo de ventas de NetApp. |
Densidad de rendimiento
La desvinculación de los nodos de almacenamiento de las estanterías en la arquitectura desagregada de ONTAP permite que más nodos dirijan el tráfico a menos estanterías, lo que ayuda a reducir la huella total del centro de datos necesaria para obtener el máximo rendimiento con solo la capacidad que necesitas.
Este concepto de "densidad de rendimiento" permite a los administradores de almacenamiento aprovechar al máximo el hardware que tienen sin tener que sobreaprovisionar nunca su entorno de almacenamiento.
Por ejemplo, en un clúster ONTAP unificado, como cada nodo tiene su propio conjunto de discos, el rendimiento se dirige solo a los discos propiedad del nodo, y como solo un nodo puede acceder a un conjunto de discos, no necesariamente puede saturar los discos disponibles y alcanzar su máximo rendimiento.
ONTAP unificado – cómo se divide el rendimiento
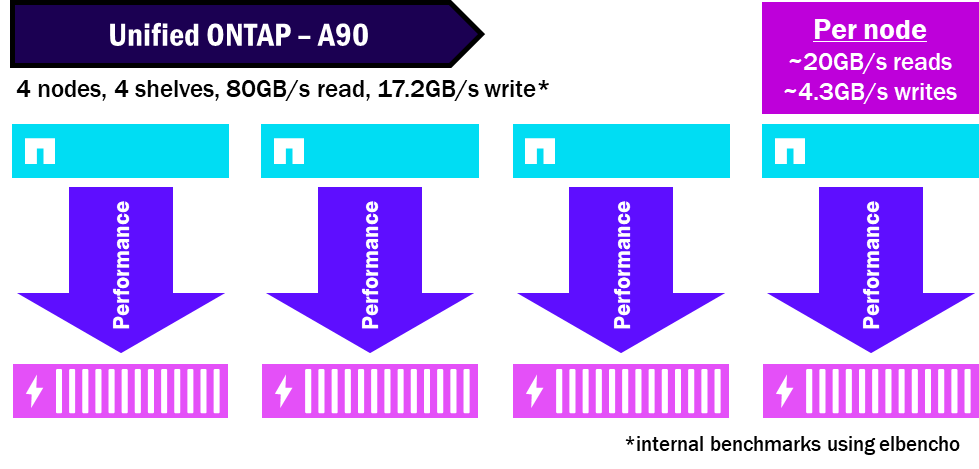
NetApp AFX agrupa todos los discos en una única Zona de Disponibilidad de Almacenamiento, así que todos los nodos pueden aprovechar todos los discos. Y como los discos y los nodos están desacoplados, no necesitarás tantas estanterías para obtener el mismo rendimiento. Esto condensa el rendimiento y maximiza el potencial de rendimiento máximo de la estantería.
NetApp AFX – Densidad de rendimiento
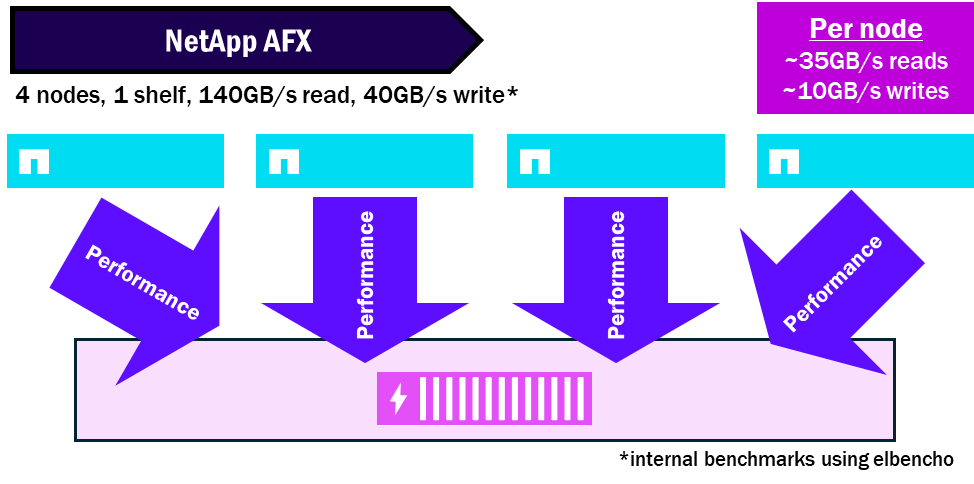
Relación entre nodos y estantes
Los nodos de Unified ONTAP requieren al menos un conjunto de discos por nodo y pueden tener varias estanterías conectadas a un único nodo. Como resultado, puede haber cuellos de botella de rendimiento en el único nodo que puede no ser capaz de saturar sus propios discos.
NetApp AFX presenta todos los estantes de discos a todos los nodos. Cada estante contiene módulos con 16 x 100GB interfaces compatibles con RoCE para aumentar la cantidad total de rendimiento permitido por estante. Por esto, puedes saturar un solo estante con varios nodos que estarán leyendo y escribiendo en el mismo conjunto de discos.
A partir de ONTAP 9.19.1, el ratio de saturación nodo:estantería es de aproximadamente 4:1.
Resultados de las pruebas de rendimiento
La siguiente sección cubre los resultados de las pruebas de rendimiento utilizando un cluster NetApp AFX con los siguientes parámetros de configuración.
-
4 nodos, 4 interfaces de datos
-
2 estantes (unidades de 7,6 TB)
-
ONTAP 9.19.1
-
NFSv4.2 (pNFS, trunking de sesiones)
-
FlexGroup volumen
-
"ElBencho" referencia
-
Escrituras: elbencho --hosts=x.x.x.[y-z] -d -w -b 1M -t 80 --iodepth 1 --direct -s 600g /fio_vol1/
-
Lecturas: elbencho --hosts=x.x.x.[y-z] -r -b 256k -t 80 --lat --iodepth 2 --direct -s 600g --infloop /fio_vol1/
-
4 servidores Cisco C240 M8, tarjetas CX-7 de 2 puertos * 200GbE, 80 hilos
-
Opciones de montaje NFS: rw,vers=4.2,rsize=1048576,wsize=1048576,trunkdiscovery,proto=tcp
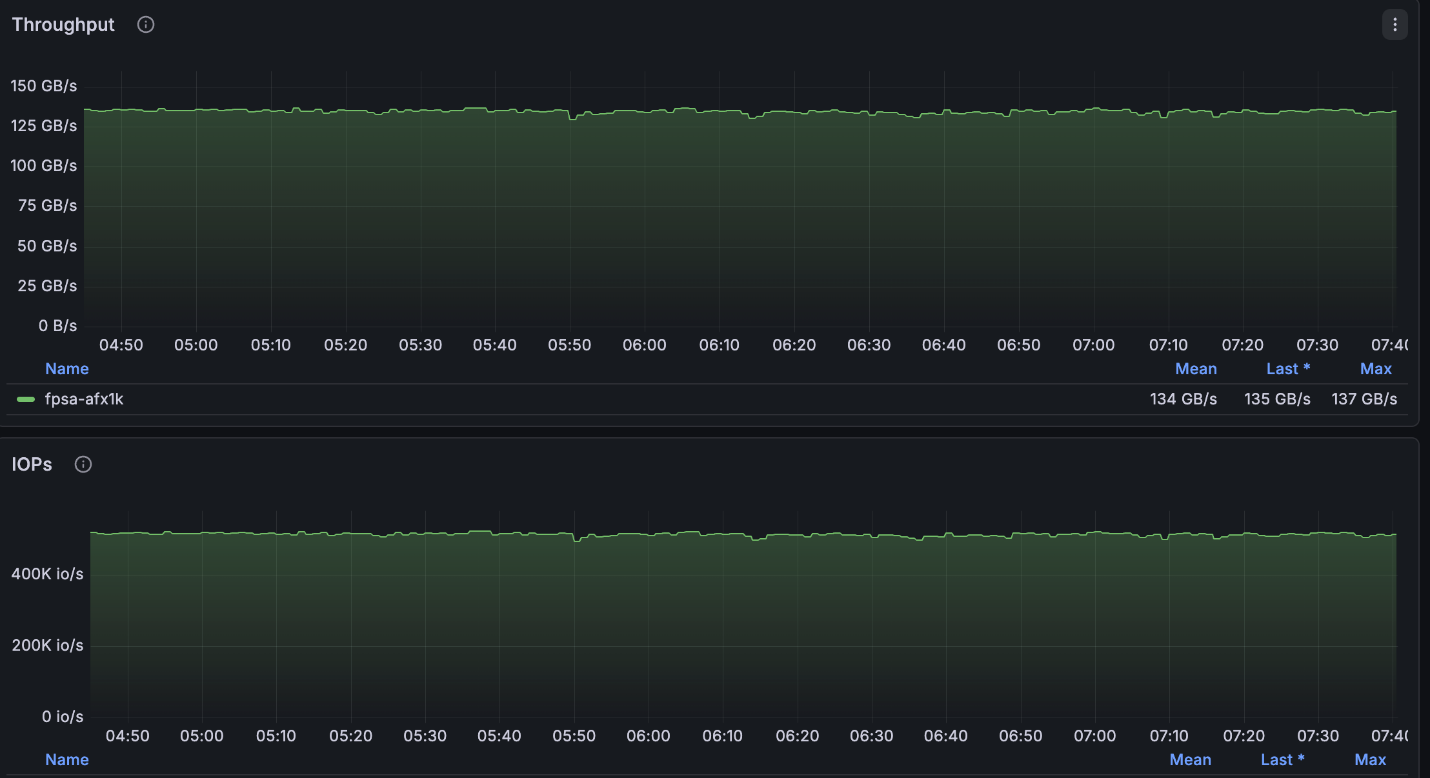
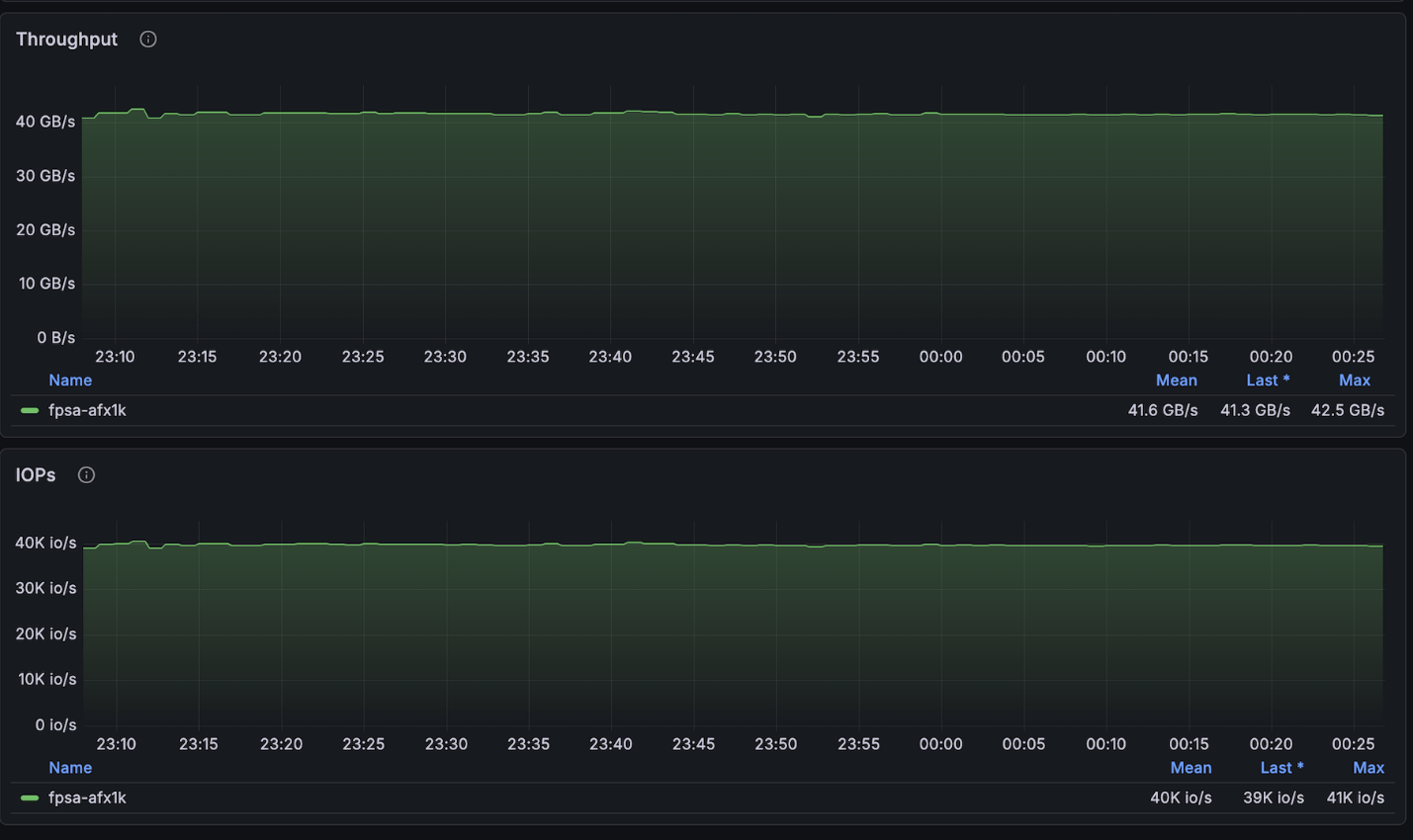
La configuración anterior alcanzó casi el máximo de lecturas disponible para el clúster de 4 nodos (~134GB/s) y se situó justo en el máximo de escrituras permitido por nodo (40GB/s).
NetApp AFX – ElBencho rendimiento de lectura, 4 nodos
NetApp AFX – ElBencho rendimiento de escritura, 4 nodos
Lectura anticipada agresiva
En las cargas de trabajo de streaming multimedia, una película 4K suele dividirse en decenas de miles de archivos, cada uno de los cuales suele tener un tamaño de entre 50 MB y 250 MB. Cada archivo representa un fotograma, y la aplicación lee un fotograma completo en una única solicitud. Para mantener un flujo fluido e ininterrumpido sin búferes visibles, estas lecturas de fotogramas deben completarse sin caídas.
ONTAP proporciona una opción a nivel de volumen (-aggressive-readahead-mode para optimizar estas cargas de trabajo. A partir de ONTAP 9.19.1, se ha introducido un nuevo modo cross_file_sequential_read para readahead agresivo en AFX para acelerar las cargas de trabajo con patrones de E/S predecibles a través de tipos de archivo similares (por ejemplo, renderización multimedia y streaming).
cross_file_sequential_read predice el siguiente archivo que se va a leer basándose en su nombre y comienza la lectura anticipada de esos archivos antes de que el cliente emita la llamada de lectura. La lógica de predicción asume que todos los archivos de un directorio siguen un patrón de nomenclatura con un sufijo numérico monotónicamente creciente (por ejemplo, archivo1, archivo2, archivo3). Todos los archivos del directorio deben seguir este patrón, utilizando numeración decimal o hexadecimal. Los nombres de archivo pueden tener hasta 255 caracteres. La lógica es independiente de la extensión y genera el siguiente conjunto de nombres de archivo en el directorio actual basándose únicamente en el nombre de archivo actual. Si un nombre de archivo generado previamente utilizando numeración base10 no existe en el directorio, los nombres se vuelven a generar utilizando numeración hexadecimal. Si no existe ninguno de los nombres de archivo generados, no se emite ninguna precarga para ese conjunto. La precarga se reanuda cuando se emite la siguiente lectura del cliente.
Con estas opciones activadas, las pruebas de rendimiento de "frametest" pudieron leer 30,000 fotogramas 4K a 30 fotogramas por segundo con 30 clientes (NFSv3 y SMB3) y 34 clientes (NFSv4.1), sin que se perdiera ni un solo fotograma.
Aunque la lectura secuencial de archivos cruzados está diseñada principalmente para cargas de trabajo multimedia, también pueden beneficiarse otras cargas de trabajo de lectura intensiva con patrones de acceso y nombres de archivos predecibles, como el entrenamiento y la inferencia de IA.
Consideraciones y advertencias
-
Caché de búfer compartida: la lectura anticipada agresiva utiliza la misma caché de búfer que otros volúmenes en el nodo. Activarla puede afectar el rendimiento de lectura de otros volúmenes en ese nodo.
-
Rendimiento del almacenamiento subyacente: si los archivos no pueden leerse con la suficiente rapidez (por ejemplo, en sistemas FAS basados en HDD), los datos almacenados en caché pueden desalojarse antes de que se produzca la lectura del cliente, lo que anula las ventajas de la lectura anticipada.
-
Requisitos de patrón de acceso: si el patrón de lectura de la carga de trabajo no es secuencial, o si los archivos de un directorio no se nombran en un orden secuencial creciente, el modo de lectura por adelantado agresivo cross_file_sequential_read no proporcionará beneficios significativos.
Mejoras del rendimiento de NFSv4.x
La versión de NFS 3 ha sido el estándar de oro para las aplicaciones NFS durante décadas, desde 1995, cuando se lanzó oficialmente por primera vez. Su combinación de rendimiento y resiliencia ha hecho que sea difícil considerar un cambio a versiones de NFS más recientes, y con razón.
Sin embargo, NFSv3 no está exento de limitaciones. La falta de estado del protocolo, aunque es genial para el rendimiento y para minimizar las interrupciones en la conmutación por error de almacenamiento, no lo es tanto para la coherencia de los datos y la gestión de bloqueos. Un servidor NFS no realiza un seguimiento real de los estados de bloqueo, así que si ocurre una falla, el servidor NFS puede o no liberar los bloqueos, y el cliente de NFS puede que no sepa si un archivo está bloqueado o no.
Security for NFSv3 is also a bit lacking. The protocol requires multiple open firewall ports to function properly and numeric IDs are sent in plaintext over the wire. Furthermore, NFS does not have robust ACL support, and does not include native file and folder auditing. As a result of these limitations, NFSv4 was created in 2003 via link:https://datatracker.ietf.org/doc/html/rfc3530[RFC-3530^] (obsoleted in 2015 by link:https://datatracker.ietf.org/doc/html/rfc7530[RFC-7530^]). Aunque NFSv4.x existe desde hace más de 20 años, aún no se ha generalizado su adopción por varias razones.
-
Complejidad de la gestión de identidades: muchos entornos no disponen de una infraestructura de servicio de nombres para aprovechar adecuadamente los requisitos de cadena de nombres y de seguridad de Kerberos en NFSv4.x.
-
Necesidad de clientes de NFS más recientes: esta preocupación es menos acuciante en los entornos NFS modernos de hoy en día, ya que cuanto más nos alejamos de la fecha de lanzamiento inicial de NFSv4. Casi todos los sistemas operativos utilizados actualmente incluyen clientes de NFS con compatibilidad total con NFSv4, pero todavía hay sistemas heredados que pueden no tener los paquetes NFSv4.x necesarios. De hecho, algunas aplicaciones todavía requieren el uso de versiones de NFS más antiguas.
-
mentalidad de "si no está roto, no lo arregles": Las empresas de TI son notoriamente conservadoras a la hora de adoptar nuevas tecnologías, incluso las que llevan más de 20 años en el mercado. Y si la versión de NFS actual funciona bien, ¿para qué cambiar?
-
Problemas de rendimiento: El rendimiento de un protocolo con estado como NFSv4.x ha sido inferior al de NFSv3 sin estado durante gran parte de los últimos 20 años. En el pasado, el impacto en el rendimiento a menudo superaba los beneficios de NFSv4.x.
Mejoras de NFSv4.x en ONTAP 9.18.1 mediante AFX
Algunos cambios en la arquitectura de ONTAP han proporcionado un aumento de rendimiento muy necesario para NFS en general y han hecho algunos avances importantes para mejorar el rendimiento de NFSv4.x en general.
A continuación se ofrece un resumen a grandes rasgos de algunos de esos cambios.
Mejora de la lectura secuencial: NFSv4.1 un 30% mejor que NFSv3
ONTAP 9.18.1 introduce soporte para IO multivía con NFSv4.1. En lugar de procesar las lecturas del sistema de archivos WAFL, MPIO desplaza las operaciones de lectura a un dominio de red para que se sirvan de forma segura multivía. Este enfoque reduce los cambios de contexto, proporcionando un mayor paralelismo general en el tráfico de lectura secuencial, además de reducir la sobrecarga de la gestión de búferes al evitar WAFL.
Mejora de la lectura aleatoria para volúmenes FlexGroup: NFSv4.1 dentro del 7% de NFSv3
Los volúmenes FlexGroup son volúmenes que toman muchos volúmenes constituyentes subyacentes y los presentan como un único espacio de nombres unificado. En AFX, los volúmenes FlexGroup tienen activado por defecto el equilibrio de capacidad avanzado, que escribirá archivos de más de 10GB en varios volúmenes constituyentes como archivos multiparte. Debido a la ubicación remota de estas partes de archivos, las lecturas aleatorias tradicionalmente han tenido una desventaja de rendimiento modesta con NFSv4.x (alrededor del 18% menos que NFSv3). ONTAP 9.18.1 introduce soporte para IO en caché para lecturas multiparte con NFSv4.x para ayudar a solucionar esto. NOTA: este cambio no se aplica a los volúmenes FlexVol.
Escrituras secuenciales: +10% de mejora respecto a versiones anteriores
Una mejora de la forma en que replicamos los datos NVLOG utilizados para la funcionalidad de conmutación por error en HA aumentó el rendimiento general de escritura secuencial para los sistemas NetApp AFX.
Operaciones de metadatos: dentro del 15% del rendimiento de NFSv3 para los benchmarks de EDA
NFSv4.1 tradicionalmente serializa todas las operaciones OPEN y CLOSE, con un nodo del clúster que las procesa de una en una antes de que puedan ser enviadas desde la red a WAFL. ONTAP 9.18.1 introduce Concurrent Open Close (COC), que elimina la serialización de la red cambiando cómo se resuelven las condiciones de carrera, lo que elimina los cuellos de botella OPEN/CLOSE vistos en versiones anteriores.
Todos estos cambios, junto con los cambios de arquitectura introducidos en AFX, han permitido mejorar el rendimiento general de NFSv4.1 en ONTAP 9.18.1.
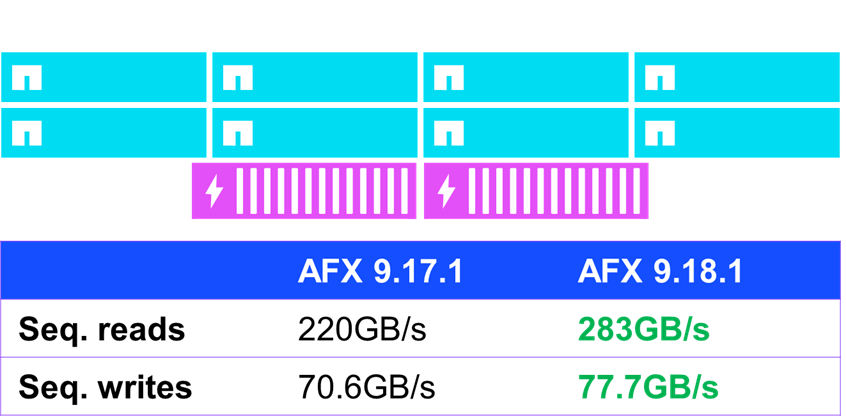
Resultados de IO secuenciales
Una de las áreas en las que se observaron algunas modestas mejoras de rendimiento fue con la IO secuencial (es decir, IO que es predecible y se emite de forma consecutiva). En las pruebas de rendimiento estándar utilizando fio, AFX ejecutando ONTAP 9.18.1 mejoró el rendimiento de lectura secuencial en casi un 30% y el rendimiento de escritura secuencial en un 10%.
NetApp AFX – rendimiento de IO secuencial NFSv4.1 en ONTAP 9.18.1
Resultados de cargas de trabajo con muchos metadatos
Aún más impresionantes son las mejoras en uno de los principales problemas de rendimiento de NFSv4.x: los metadatos. Se trata de IO aleatorias, normalmente del orden de 4K, que se utilizan para gestionar los propietarios y atributos de los archivos, crear y listar archivos, y así sucesivamente. Debido al carácter de estado de NFSv4.x, este tipo de operaciones tienden a costar más en CPU y latencia, lo que a su vez reduce el rendimiento general posible.
Con los cambios introducidos en AFX ONTAP 9.18.1, el rendimiento de NFSv4.x para este tipo de cargas de trabajo ha mejorado sustancialmente y ha cerrado la brecha con el rendimiento de NFSv3 (dentro del 15%).
Nuestros equipos de ingeniería de rendimiento compararon el rendimiento de las imágenes de IA estándar, EDA y los puntos de referencia de creación de software y descubrieron enormes mejoras con respecto a la versión anterior de ONTAP.
NetApp AFX – rendimiento de IO de metadatos NFSv4.1 en ONTAP 9.18.1
