

Estrategia de implementación y mejores prácticas para la sincronización activa de ONTAP SnapMirror
 Sugerir cambios
Sugerir cambios
Es importante que su estrategia de protección de datos identifique claramente las cargas de trabajo que necesitan protegerse para la continuidad del negocio. El paso más crítico en su estrategia de protección de datos es tener claridad en el diseño de los datos de sus aplicaciones empresariales para que pueda decidir cómo distribuir los volúmenes y proteger la continuidad del negocio. Dado que la conmutación por error se produce a nivel del grupo de consistencia por aplicación, asegúrese de agregar los volúmenes de datos necesarios al grupo de consistencia.
Configuración de SVM
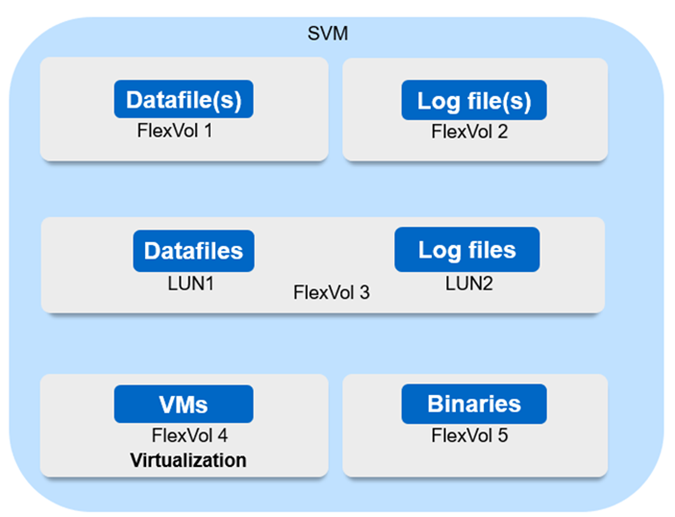
El diagrama captura una configuración de máquina virtual de almacenamiento (SVM) recomendada para la sincronización activa de SnapMirror.
-
Para volúmenes de datos:
-
Las cargas de trabajo de lectura aleatoria están aisladas de escrituras secuenciales; por lo tanto, según el tamaño de la base de datos, los archivos de datos y de registro suelen colocarse en volúmenes independientes.
-
Para las bases de datos críticas de gran tamaño, el archivo de datos único se encuentra en FlexVol 1 y el archivo de registro correspondiente se encuentra en FlexVol 2.
-
Para una mejor consolidación, las bases de datos no críticas de tamaño pequeño a mediano se agrupan de modo que todos los archivos de datos se encuentran en FlexVol 1 y los archivos de registro correspondientes se encuentran en FlexVol 2. Sin embargo, perderá la granularidad a nivel de aplicación a través de esta agrupación.
-
-
Otra variante es tener todos los archivos dentro del mismo FlexVol 3, con archivos de datos en LUN1 y sus archivos de registro en LUN 2.
-
-
Si su entorno está virtualizado, tendría todas las máquinas virtuales de varias aplicaciones empresariales compartidas en un almacén de datos. Normalmente, los equipos virtuales y los binarios de aplicaciones se replican de forma asíncrona mediante SnapMirror.