Tr-4920 : continuité de l'activité pour FlexPod Datacenter avec NetApp SnapMirror et ONTAP 9.10
 Suggérer des modifications
Suggérer des modifications
Jyh-shing Chen, NetApp
Introduction
Solution FlexPod
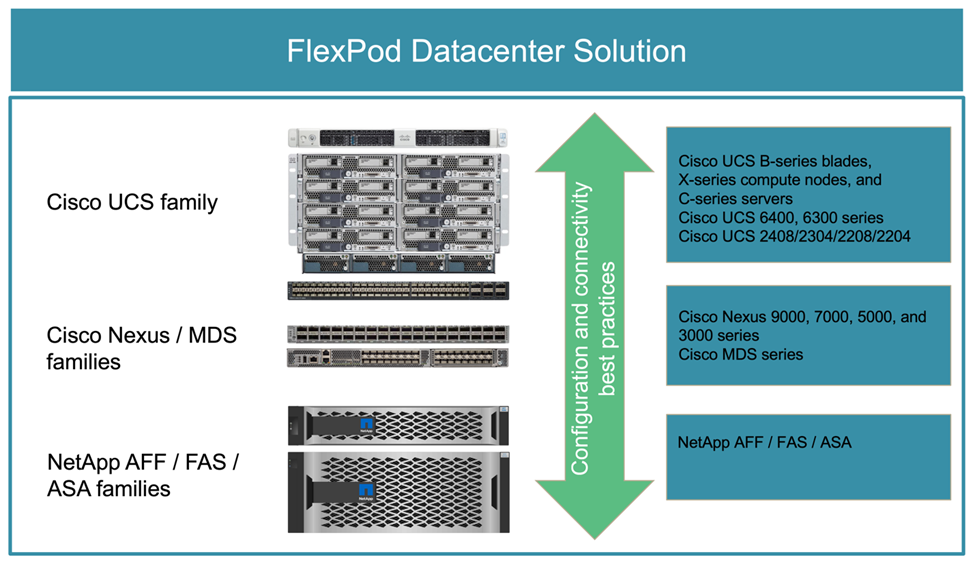
FlexPod est une architecture de data Center basée sur les bonnes pratiques. Elle inclut les composants suivants de Cisco et NetApp :
-
Serveurs Cisco Unified Computing System (Cisco UCS)
-
Gammes de commutateurs Cisco Nexus et MDS
-
Systèmes NetApp FAS, NetApp AFF et ASA
La figure suivante décrit certains des composants utilisés pour créer des solutions FlexPod. Ces composants sont connectés et configurés conformément aux meilleures pratiques recommandées par Cisco et NetApp pour fournir une plateforme idéale pour exécuter en toute confiance une variété de charges de travail d'entreprise.
Un large portefeuille de conceptions validées Cisco (CVD) et d'architectures vérifiées NetApp (NVA) est disponible. Ces CVD et NVA couvrent l'ensemble des charges de travail majeures des data centers et résultent d'une collaboration et d'innovations continues entre NetApp et Cisco sur les solutions FlexPod.
En intégrant des tests et des validations déjà exhaustifs dans le processus de création, les conformément aux CVD et aux NVA de FlexPod fournissent des conceptions d'architecture de solutions de référence et des guides de déploiement détaillés pour aider les partenaires et les clients à déployer et à adopter les solutions FlexPod. En utilisant ces CVD et les NVA comme guides de conception et d'implémentation, les entreprises peuvent réduire les risques, réduire les temps d'indisponibilité de la solution et augmenter la disponibilité, l'évolutivité, la flexibilité et la sécurité des solutions FlexPod qu'elles déploient.
Chacune des familles de composants FlexPod présentées (Cisco UCS, commutateurs Cisco Nexus/MDS et stockage NetApp) offre des options de plateforme et de ressources pour faire évoluer l'infrastructure de manière verticale ou horizontale, tout en prenant en charge les fonctionnalités requises selon les meilleures pratiques de configuration et de connectivité de FlexPod. FlexPod peut également évoluer horizontalement pour les environnements nécessitant plusieurs déploiements cohérents en déployant des piles FlexPod supplémentaires.
Assurer une reprise après incident rapide et la continuité de l'activité
Plusieurs méthodes permettent aux entreprises de récupérer rapidement leurs applications et services de données en cas d'incident. La mise en place d'un plan de reprise après incident et de continuité de l'activité, l'implémentation d'une solution qui répond aux objectifs métier et l'exécution de tests réguliers des scénarios d'incident permettent aux entreprises de bénéficier d'une reprise après incident et de continuer les services stratégiques après une situation d'incident.
Les exigences en matière de reprise après incident et de continuité de l'activité peuvent être différentes pour les types de services d'applications et de données. Certaines applications et données ne sont pas nécessaires en cas d'urgence ou d'incident, alors que d'autres doivent être disponibles en continu pour répondre aux exigences de l'entreprise.
Pour les applications stratégiques et les services de données qui risquent de perturber votre activité alors qu'ils ne sont pas disponibles, une évaluation minutieuse est nécessaire pour répondre à des questions telles que le type de maintenance et les scénarios d'incident auxquels l'entreprise doit tenir compte, quelle quantité de données l'entreprise peut se permettre de perdre en cas d'incident, et la rapidité à laquelle la reprise peut et doit avoir lieu.
Pour les entreprises qui ont recours à des services de données pour générer du chiffre d'affaires, les services de données doivent être protégés par une solution capable de résister à plusieurs scénarios de défaillance unique, mais aussi à un scénario de panne sur site dans le but d'assurer la continuité de l'activité.
Objectifs de point de restauration et de délai de restauration
L'objectif de point de restauration (RPO) mesure la quantité de données générée, en termes de temps, vous pouvez vous permettre de perdre ou bien le point auquel vous pouvez récupérer vos données. Avec un plan de sauvegarde quotidien, une entreprise risque de perdre une journée de données, car les modifications apportées aux données depuis la dernière sauvegarde pourraient être perdues en cas d'incident. Pour les services de données stratégiques et stratégiques, vous avez besoin d'un RPO nul et d'un plan et d'infrastructures associés pour protéger vos données sans aucune perte.
L'objectif de délai de restauration (RTO) mesure le temps que vous pouvez vous permettre d'éviter que les données ne soient disponibles ou la rapidité à laquelle les services de données doivent être mis en service. Par exemple, une entreprise peut disposer d'une implémentation de la sauvegarde et de la restauration qui utilise des bandes traditionnelles pour certains jeux de données en raison de sa taille. Par conséquent, la restauration des données à partir des bandes de sauvegarde peut prendre plusieurs heures, voire des jours, en cas de défaillance de l'infrastructure. Il faut également comprendre le temps nécessaire pour sauvegarder l'infrastructure et restaurer les données. Pour les services de données stratégiques, vous pourriez avoir besoin d'un RTO très faible et vous ne pouvez tolérer qu'un temps de basculement de quelques secondes ou minutes pour remettre en ligne les services de données pour assurer la continuité de l'activité.
SM-BC
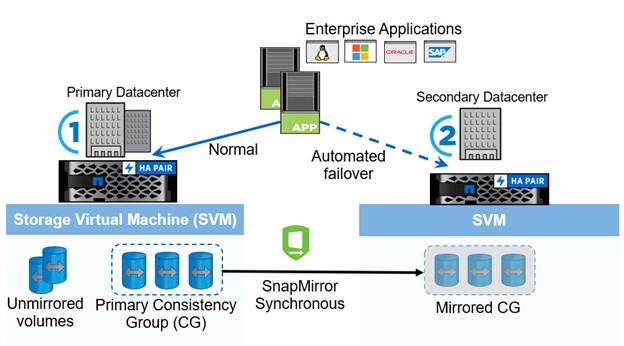
Depuis ONTAP 9.8, vous pouvez protéger les charges de travail SAN pour un basculement transparent des applications avec NetApp SM-BC. Vous pouvez créer des relations de groupes de cohérence entre deux clusters AFF ou deux clusters ASA pour la réplication des données afin d'atteindre un RPO nul et un RTO proche de zéro.
La solution SM-BC réplique les données à l'aide de la technologie SnapMirror synchrone sur un réseau IP. Elle offre une granularité au niveau des applications et un basculement automatique pour protéger vos services de données stratégiques, tels que Microsoft SQL Server, Oracle, etc. Avec des LUN SAN basées sur des protocoles iSCSI ou FC. Un médiateur ONTAP déployé sur un troisième site surveille la solution SM-BC et active le basculement automatique en cas d'incident sur site.
Un groupe de cohérence est une collection de volumes FlexVol qui offre une garantie de cohérence de l'ordre d'écriture pour la charge de travail applicative qui doit être protégée pour la continuité de l'activité. Elle permet d'effectuer simultanément des copies Snapshot cohérentes après panne d'un ensemble de volumes à un point dans le temps. Une relation SnapMirror, également appelée relation de groupe de cohérence, est établie entre un groupe de cohérence source et un groupe de cohérence de destination. Le groupe de volumes sélectionnés pour faire partie d'un groupe de cohérence peut être mappé à une instance d'application, à un groupe d'instances d'applications ou à une solution complète. En outre, les relations de groupe de cohérence SM-BC peuvent être créées ou supprimées à la demande en fonction des exigences et des changements de l'entreprise.
Comme illustré dans la figure suivante, les données du groupe de cohérence sont répliquées sur un second cluster ONTAP pour la reprise sur incident et la continuité de l'activité. Les applications disposent d'une connectivité aux LUN des deux clusters ONTAP. Les E/S sont généralement servies par le cluster primaire et reprises automatiquement à partir du cluster secondaire si un incident se produit sur le cluster primaire. Lors de la conception d'une solution SM-BC, les nombres d'objets pris en charge pour les relations CG (par exemple, un maximum de 20 CGS et un maximum de 200 noeuds finaux) doivent être observés pour éviter de dépasser les limites prises en charge.