

Validation des solutions : scénarios validés
 Suggérer des modifications
Suggérer des modifications
La solution FlexPod Datacenter SM-BC protège les services de données dans de nombreux scénarios de point de défaillance unique et en cas d'incident sur site. La conception redondante implémentée sur chaque site assure une haute disponibilité et l'implémentation de SM-BC avec réplication synchrone des données sur plusieurs sites protège les services de données d'un incident sur l'ensemble d'un site. La solution déployée est validée pour les fonctions de la solution ainsi que pour les différents scénarios de défaillance pour lesquels la solution est conçue pour la protection.
Validation des fonctions de la solution
Différents cas de test sont utilisés pour vérifier le fonctionnement de la solution et simuler des scénarios de défaillance partielle et complète du site. Pour réduire au minimum la duplication avec les tests déjà effectués dans les solutions de data Center FlexPod existantes dans le cadre du programme de conception validée par Cisco, ce rapport se concentre sur les aspects liés à SM-BC de la solution. Certaines validations FlexPod générales sont incluses pour que les praticiens puissent passer en revue leurs validations de mise en œuvre.
Pour la validation de la solution, une machine virtuelle Windows 10 par hôte ESXi a été créée sur tous les hôtes ESXi des deux sites. L'outil IOMeter a été installé et utilisé pour générer des E/S sur deux disques de données virtuels mappés à partir des datastores iSCSI locaux partagés. Les paramètres de la charge de travail IOMeter configurés étaient à 8 Ko d'E/S, à 75 % de lecture et à 50 % aléatoires, et 8 commandes d'E/S en attente pour chaque disque de données. Dans la plupart des scénarios de test réalisés, la suite des E/S IOMeter montre que le scénario n'a pas provoqué de panne du service de données.
Étant donné que SM-BC est critique pour les applications métier telles que les serveurs de base de données, L'instance Microsoft SQL Server 2019 d'une machine virtuelle Windows Server 2022 a également été incluse dans le cadre des tests pour confirmer que l'application continue à s'exécuter lorsque le stockage sur son site local n'est pas disponible et que le service de données est repris sur le système de stockage du site distant sans application perturbation.
Test de démarrage SAN iSCSI de l'hôte ESXi
Les hôtes ESXi de la solution sont configurés pour démarrer à partir du SAN iSCSI. L'utilisation du démarrage SAN simplifie la gestion du serveur lors du remplacement d'un serveur car le profil de service du serveur peut être associé à un nouveau serveur pour qu'il démarre sans apporter de modifications de configuration supplémentaires.
En plus de démarrer un hôte ESXi situé sur un site à partir de sa LUN de démarrage iSCSI locale, un test a également été effectué pour démarrer l'hôte ESXi lorsque son contrôleur de stockage local est en état de basculement ou lorsque son cluster de stockage local est totalement indisponible. Ces scénarios de validation garantissent la configuration correcte des hôtes ESXi par conception et peuvent démarrer lors d'une maintenance du stockage ou d'un scénario de reprise après incident afin d'assurer la continuité de l'activité.
Avant de configurer la relation de groupe de cohérence SM-BC, une LUN iSCSI hébergée par une paire haute disponibilité de contrôleur de stockage dispose de quatre chemins, deux par le biais de chaque structure iSCSI, selon l'implémentation des meilleures pratiques. Un hôte peut passer au LUN via les deux VLAN/fabrics iSCSI vers le contrôleur hôte LUN, ainsi via le partenaire haute disponibilité du contrôleur.
Une fois la relation de groupe de cohérence SM-BC configurée et les LUN en miroir correctement mappées sur les initiateurs, le nombre de chemins d'accès de la LUN double. Pour cette implémentation, il s'agit de disposer de deux chemins actifs/optimisés et de deux chemins actifs/non optimisés, d'avoir deux chemins actifs/optimisés et six chemins actifs/non optimisés.
La figure suivante illustre les chemins qu'un hôte ESXi peut prendre pour accéder à une LUN, par exemple LUN 0. Comme la LUN est connectée au site A contrôleur 01, seuls les deux chemins qui accèdent directement à la LUN via ce contrôleur sont actifs/optimisés et les six chemins restants sont actifs/non optimisés.
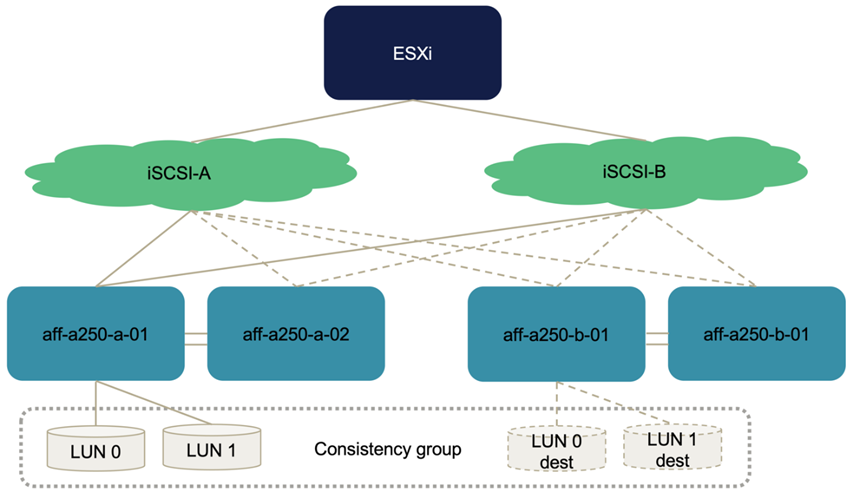
La capture d'écran suivante des informations sur le chemin du périphérique de stockage montre comment l'hôte ESXi voit les deux types de chemins de périphérique. Les deux chemins actifs/optimisés sont indiqués comme ayant active (I/O) l'état du chemin, alors que les six chemins actifs/non optimisés sont affichés uniquement comme active. Notez également que la colonne cible affiche les deux cibles iSCSI et les adresses IP LIF iSCSI respectives pour obtenir les cibles.
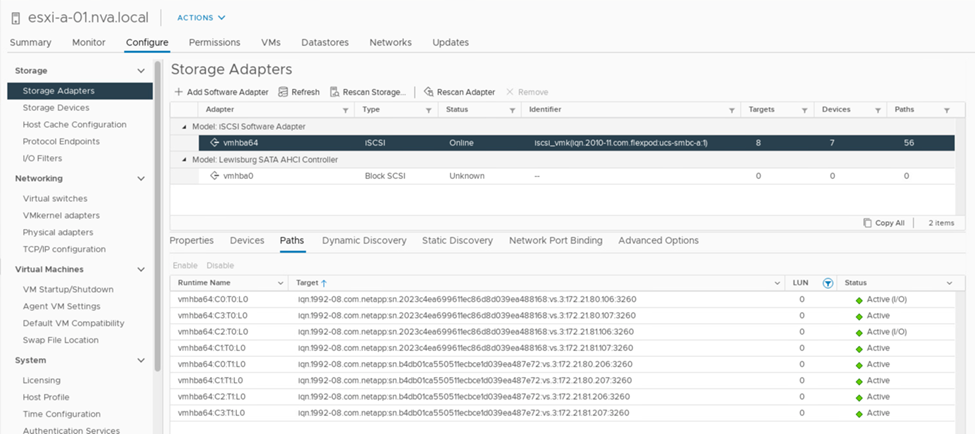
Lorsqu'un des contrôleurs de stockage est en panne pour cause de maintenance ou de mise à niveau, les deux chemins qui atteignent le contrôleur de panne ne sont plus disponibles et affichent le chemin d'accès à dead à la place.
Si un basculement de groupe de cohérence se produit sur le cluster de stockage principal, soit en raison de tests de basculement manuels, soit d'un basculement automatique en cas d'incident, le cluster de stockage secondaire continue à fournir les services de données pour les LUN du groupe de cohérence SM-BC. Comme les identités de LUN sont préservées et que les données ont été répliquées de manière synchrone, toutes les LUN de démarrage de l'hôte ESXi protégées par les groupes de cohérence SM-BC restent disponibles depuis le cluster de stockage distant.
Test d'affinité avec les VM/hôtes VMware vMotion
Bien qu'une solution générique FlexPod VMware Datacenter prenne en charge plusieurs protocoles, tels que FC, iSCSI, NVMe et NFS, la fonctionnalité de la solution FlexPod SM-BC prend en charge les protocoles SAN FC et iSCSI généralement utilisés pour les solutions stratégiques. Cette validation utilise uniquement les datastores basés sur protocole iSCSI et le démarrage SAN iSCSI.
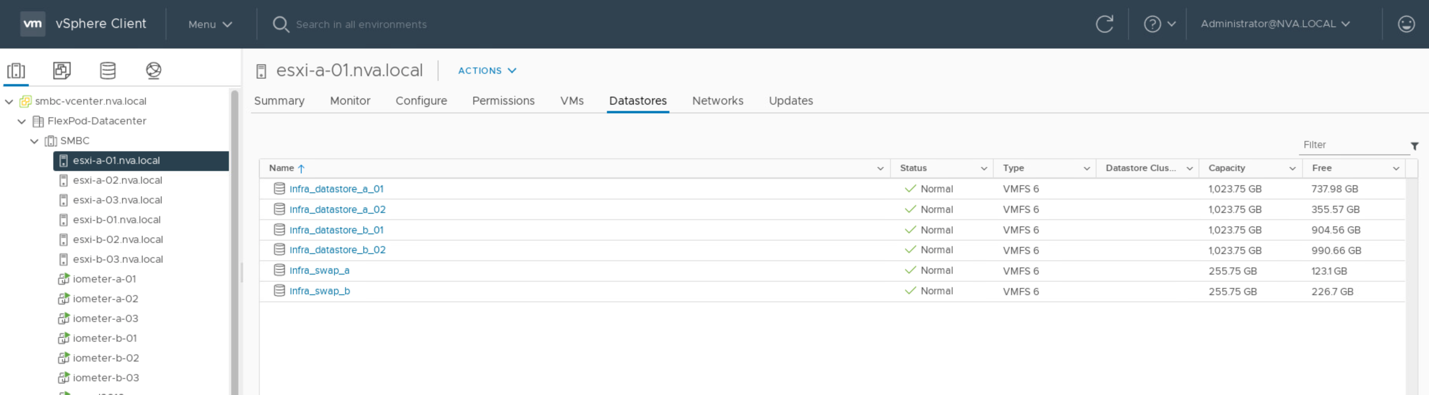
Pour permettre aux machines virtuelles d'utiliser les services de stockage depuis l'un des sites SM-BC, les datastores iSCSI des deux sites doivent être montés par tous les hôtes du cluster afin de permettre la migration des machines virtuelles entre les deux sites et dans le cadre de scénarios de basculement en cas d'incident.
Il est également possible d'utiliser le protocole NFS et les datastores NFS pour les applications exécutées sur l'infrastructure virtuelle qui ne nécessitent pas la protection des groupes de cohérence SM-BC entre les sites. Dans ce cas, il convient d'observer une attention particulière lors de l'allocation du stockage pour les VM afin que les applications stratégiques utilisent correctement les datastores SAN protégés par le groupe de cohérence SM-BC pour assurer la continuité de l'activité.
La capture d'écran suivante montre que les hôtes sont configurés pour monter des datastores iSCSI à partir des deux sites.
Vous pouvez migrer des disques de machines virtuelles entre des datastores iSCSI disponibles depuis les deux sites, comme le montre la figure suivante. Pour considérations de performances, il est optimal de disposer de serveurs virtuels qui utilisent le stockage de leur cluster de stockage local afin de réduire les latences d'E/S des disques. Ceci est particulièrement vrai lorsque les deux sites sont situés à certaines distances, en raison de la latence de distance de aller-retour physique d'environ 1 ms par 100 km de distance.
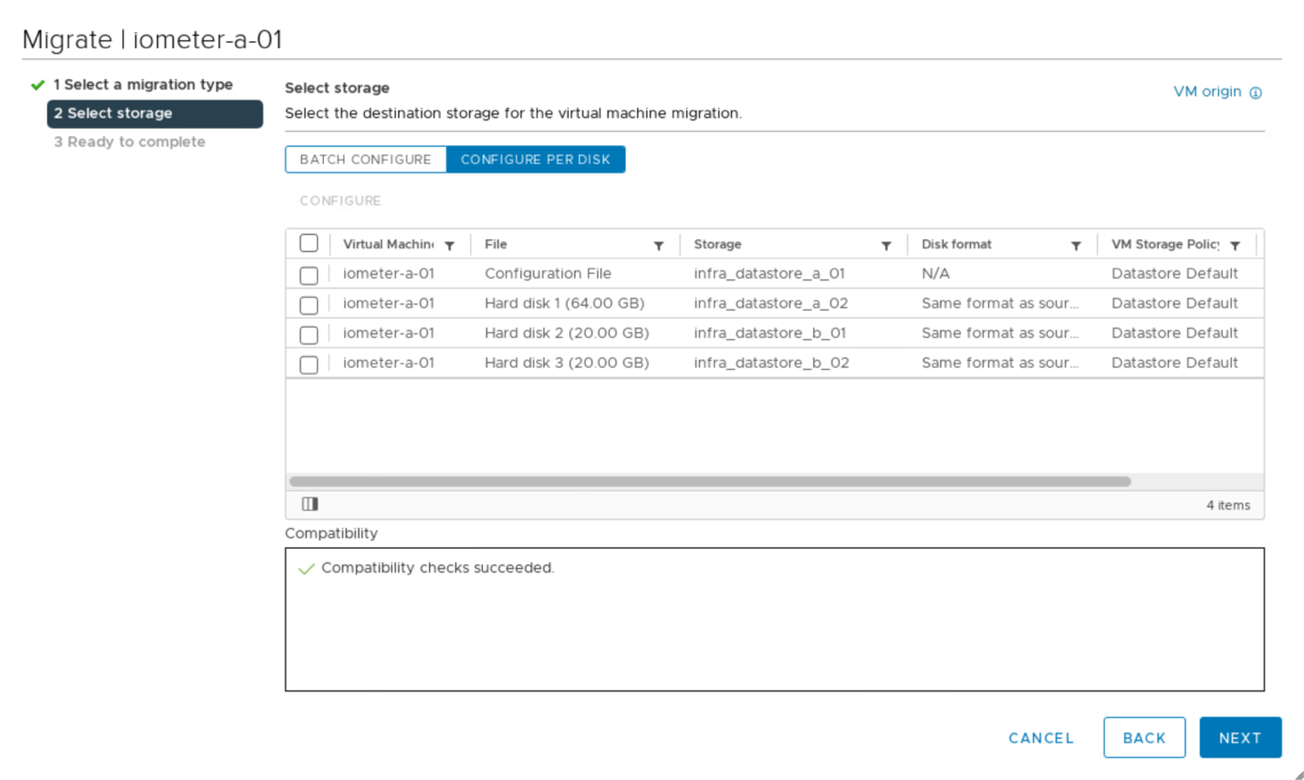
Des tests de vMotion d'machines virtuelles sur un hôte différent au niveau du même site, ainsi que sur plusieurs sites ont été réalisés et ont abouti. Après avoir migré manuellement une machine virtuelle sur plusieurs sites, la règle d'affinité VM/hôte s'active et retransfère la machine virtuelle au groupe où elle appartient dans la condition normale.
Basculement planifié du stockage
Les opérations planifiées de basculement du stockage doivent être réalisées sur la solution après la configuration initiale afin de déterminer si la solution fonctionne correctement après le basculement du stockage. Ce test peut aider à identifier tout problème de connectivité ou de configuration susceptible d'entraîner des interruptions d'E/S. Les tests et la résolution réguliers de tout problème de connectivité ou de configuration permettent de fournir des services de données sans interruption en cas d'incident sur site réel. Le basculement planifié du stockage peut également être utilisé avant une maintenance planifiée du stockage afin que les services de données puissent être assurés depuis le site non affecté.
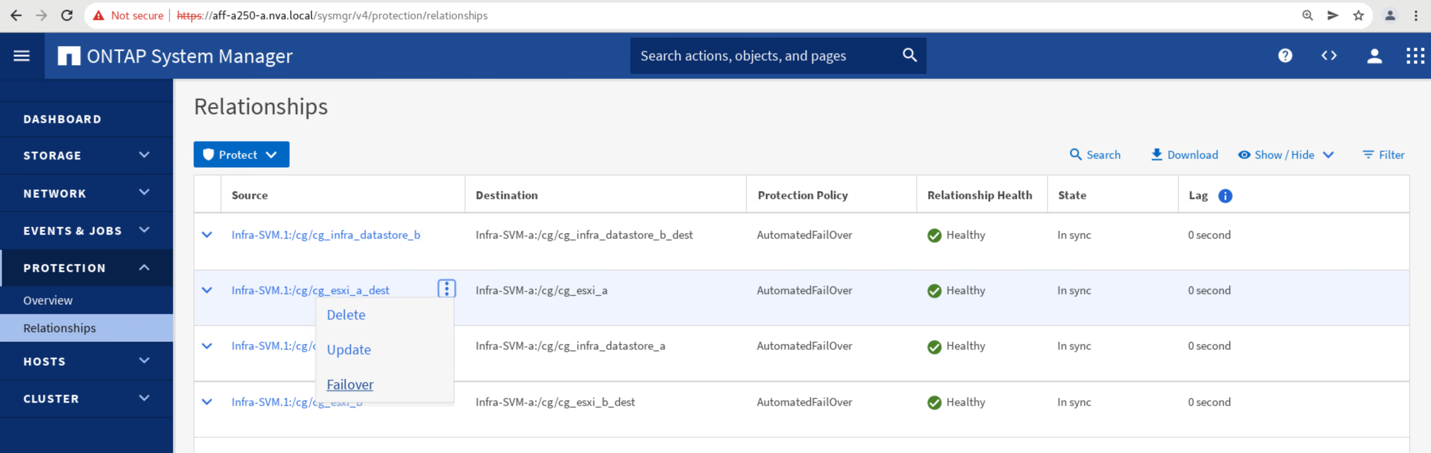
Pour lancer un basculement manuel des services de données de stockage du site A vers le site B, vous pouvez utiliser le site B ONTAP System Manager pour effectuer l'action.
-
Accédez à l'écran protection > relations pour confirmer que l'état de la relation de groupe de cohérence est
In Sync. S'il se trouve toujours dans leSynchronizingattendez que l'état devienneIn Syncavant d'effectuer un basculement. -
Développez les points en regard du nom de la source et cliquez sur basculement.
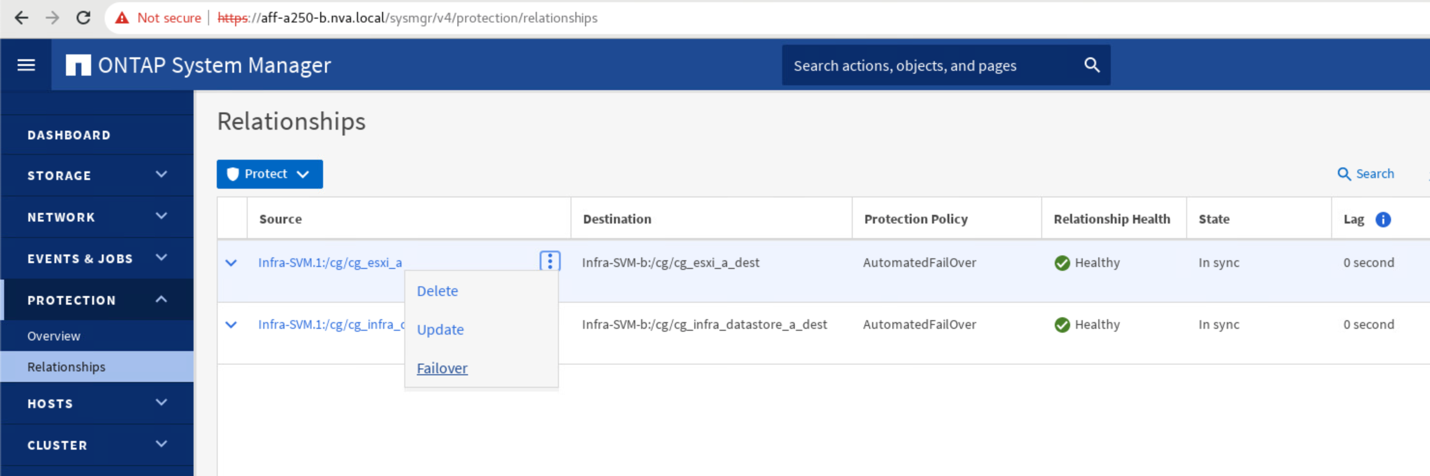
-
Confirmer le basculement pour que l'action démarre.
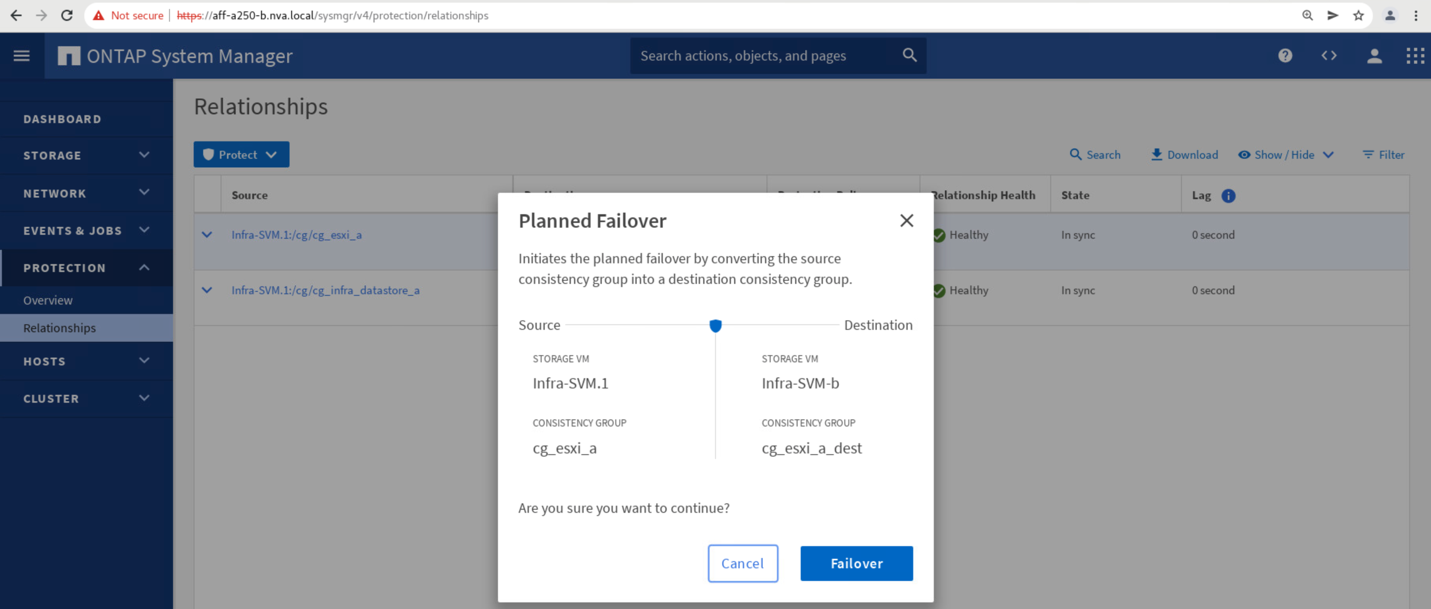
Peu de temps après le lancement du basculement des deux groupes de cohérence, cg_esxi_a et cg_infra_datastore_a, Sur l'interface graphique System Manager du site B, les E/S du site A servant à traiter les deux groupes de cohérence déplacés vers le site B. Ainsi, les E/S sur le site A sont considérablement réduites comme indiqué sur le site A volet performances de System Manager.
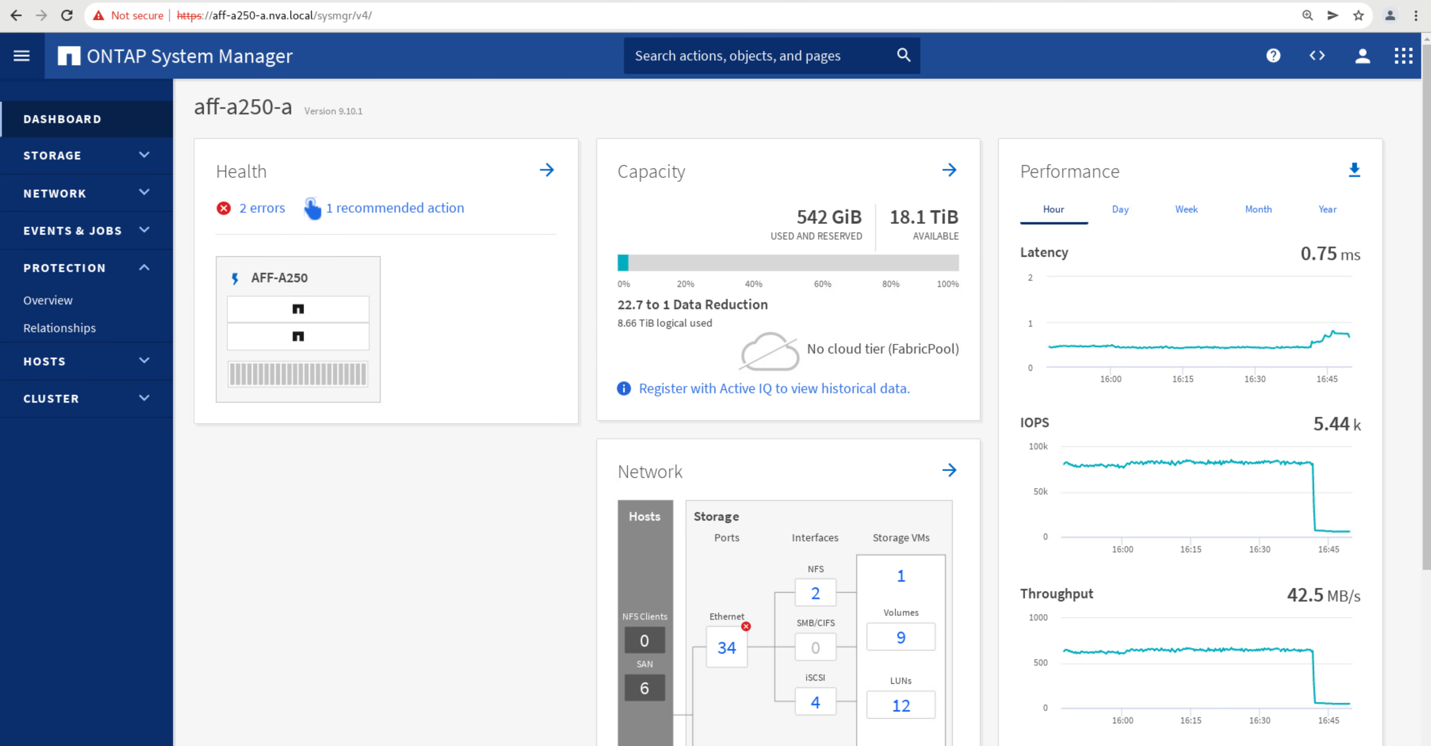
Par contre, le volet performances du tableau de bord du site B System Manager affiche une augmentation significative des IOPS, en raison de la transmission des E/S supplémentaires transférées du site A à environ 130 000 IOPS, De plus, nous avons atteint un débit d'environ 1 Gbit/s, tout en maintenant une latence d'E/S inférieure à la milliseconde.
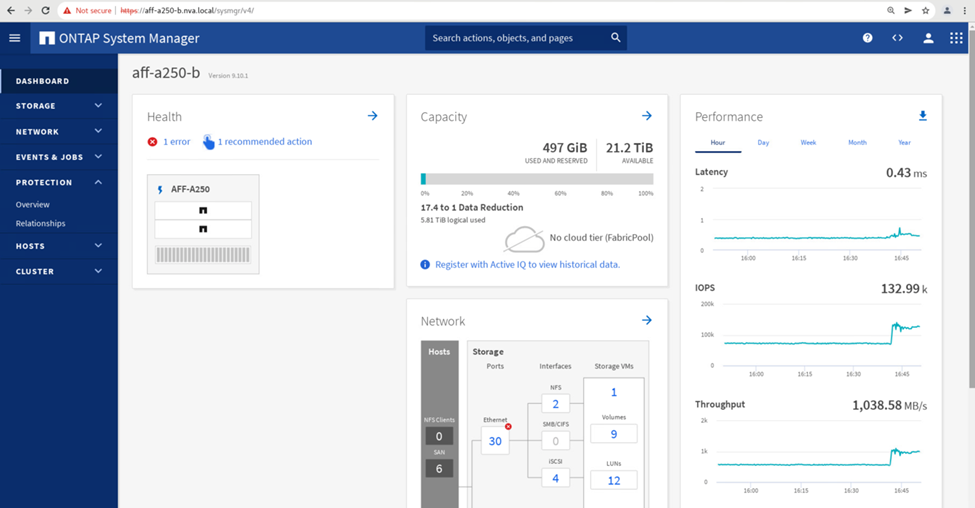
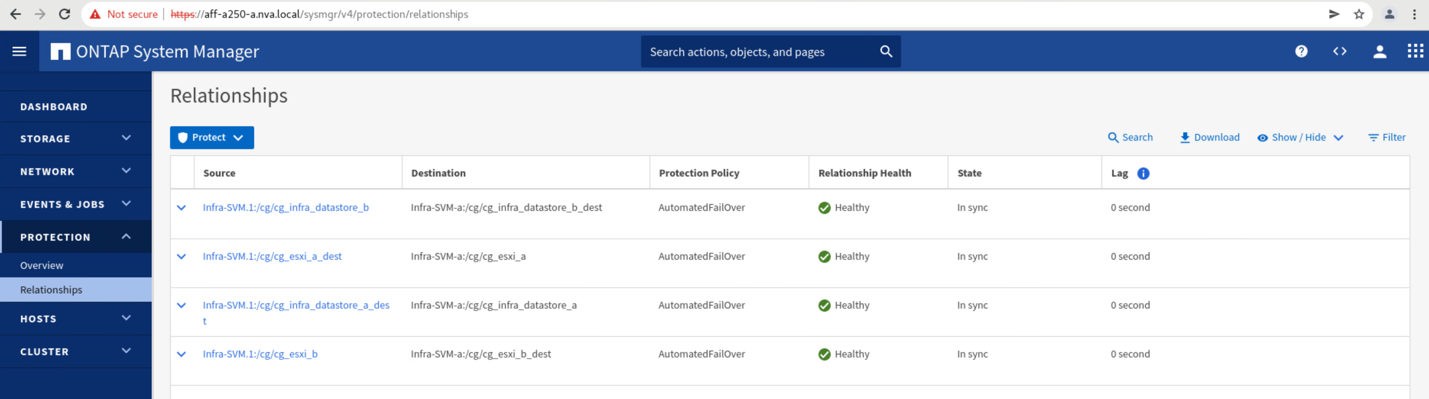
Grâce à la migration transparente des E/S du site A vers le site B, les contrôleurs de stockage du site A peuvent désormais être mis en service afin de planifier la maintenance. Une fois le travail de maintenance ou le test terminé et que le cluster de stockage d'un site est réexécuté et opérationnel, vérifiez et attendez que l'état de protection du groupe de cohérence soit revenir à In sync Avant d'effectuer un basculement pour renvoyer les E/S de basculement du site B vers le site A. Notez que plus un site est arrêté pour les opérations de maintenance ou de test, plus il faut de temps pour synchroniser les données et que le groupe de cohérence est renvoyé au In sync état.
Basculement de stockage non planifié
Un basculement de stockage non planifié peut se produire en cas d'incident réel ou lors d'une simulation d'incident. Par exemple, consultez la figure suivante dans laquelle le système de stockage sur le site A subit une panne de courant, un basculement de stockage non planifié est déclenché et les services de données pour les LUN du site A, protégés par les relations SM-BC, continuent à partir du site B.
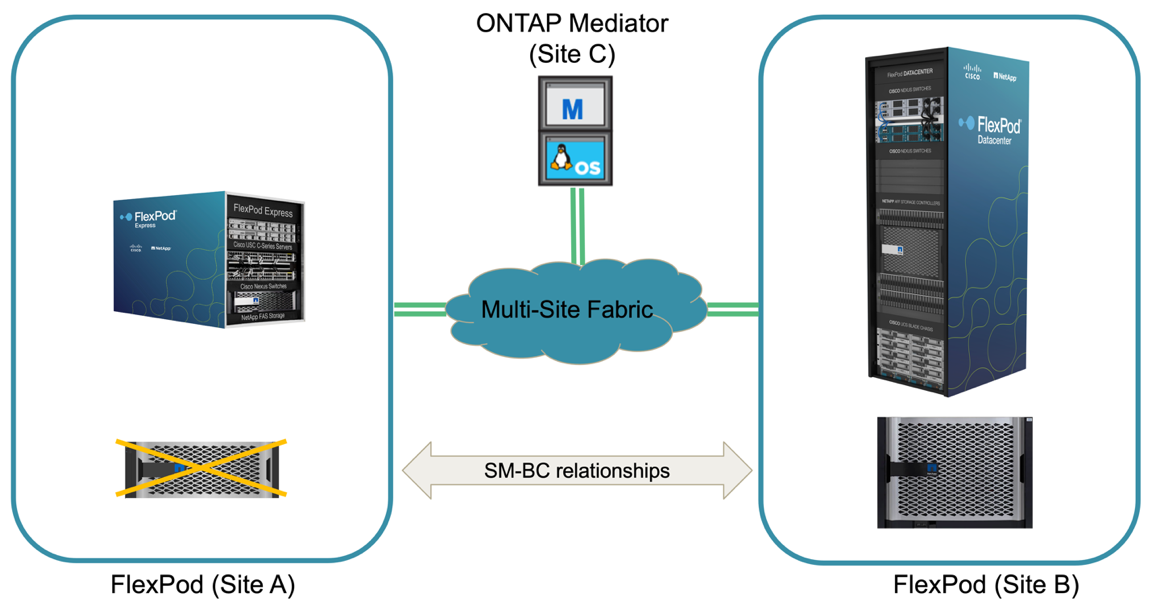
Pour simuler un incident de stockage au niveau du site A, les deux contrôleurs de stockage du site A peuvent être mis hors tension en mettant physiquement l'interrupteur afin de mettre fin à l'alimentation des contrôleurs, ou en utilisant la commande de gestion de l'alimentation système des processeurs de service du contrôleur de stockage pour mettre les contrôleurs hors tension.
Lorsque le cluster de stockage du site a une perte de puissance, les services de données fournis par le site A du cluster de stockage sont stoppés soudainement. Ensuite, le médiateur ONTAP, qui surveille la solution SM-BC à partir d'un troisième site, détecte une condition de défaillance de stockage du site et permet à la solution SM-BC d'effectuer un basculement non planifié automatisé. Cela permet aux contrôleurs de stockage du site B de continuer les services de données pour les LUN configurés dans les relations du groupe de cohérence SM-BC avec le site A.
Du point de vue des applications, les services de données font une pause brève fois que le système d'exploitation vérifie l'état du chemin des LUN, puis reprend les E/S sur les chemins disponibles vers les contrôleurs de stockage du site B survivants.
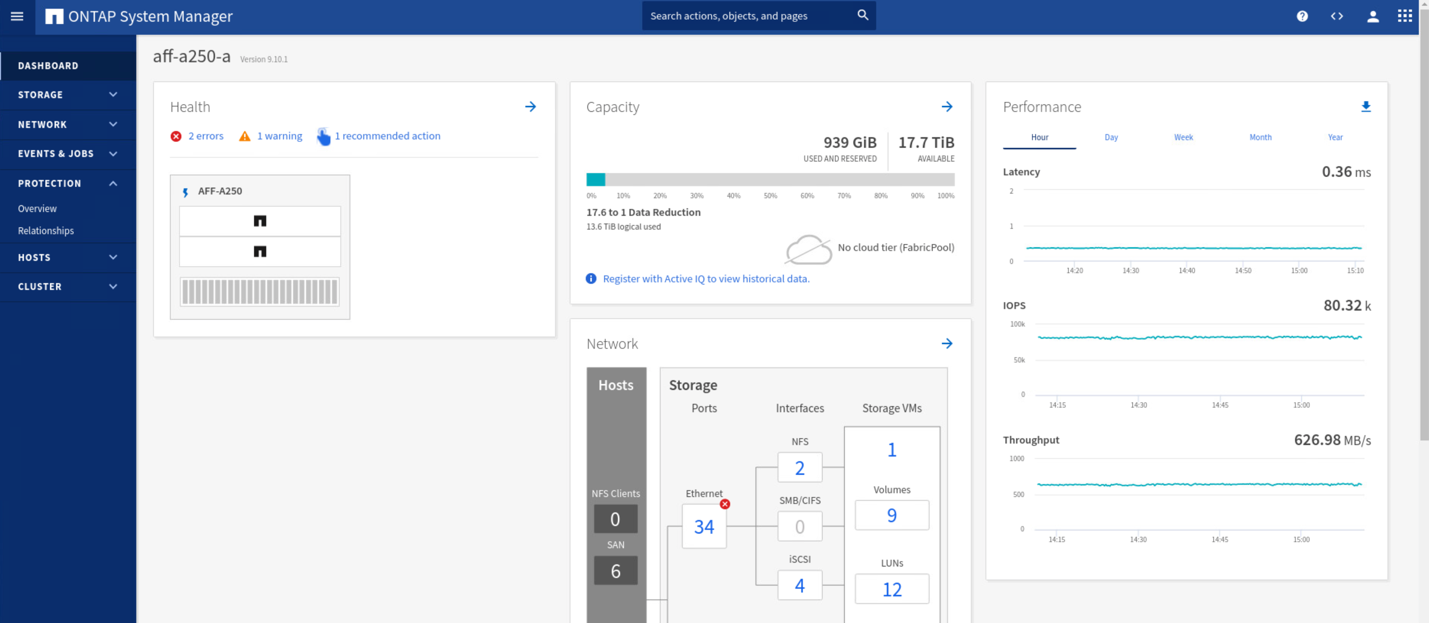
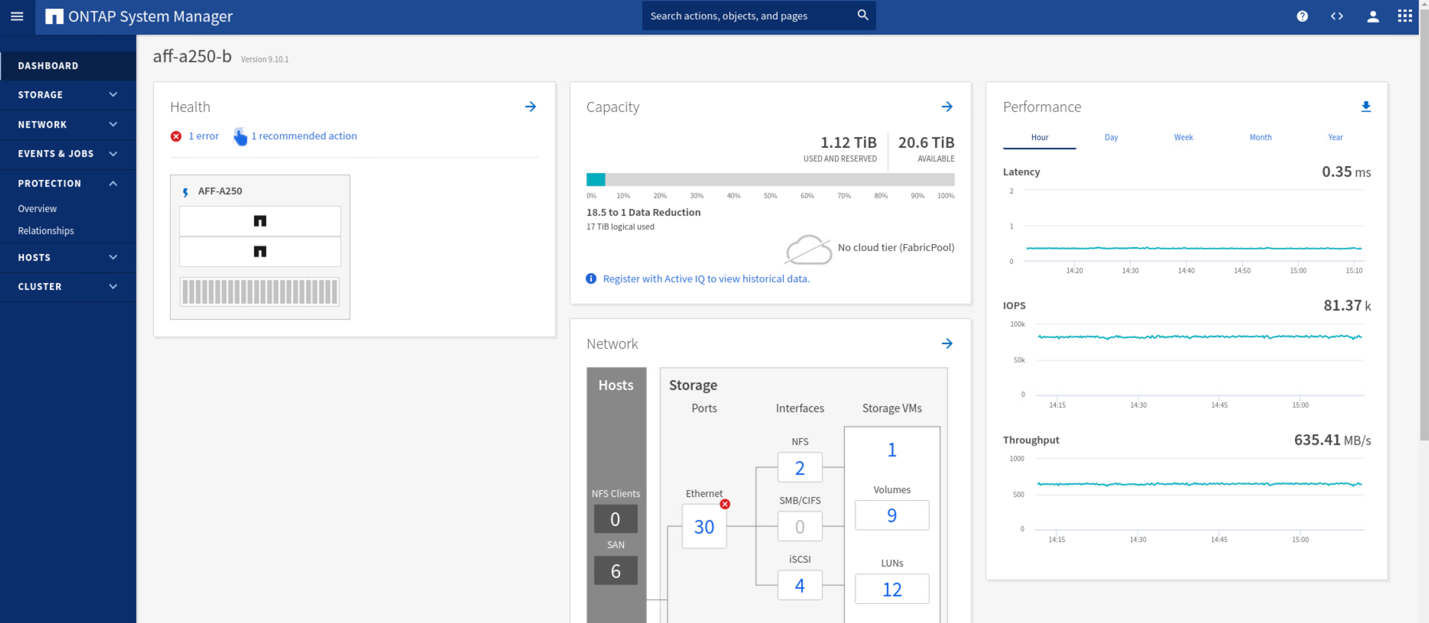
Lors des tests de validation, l'outil IOMeter installé sur les machines virtuelles des deux sites génère des E/S dans leurs datastores locaux. Après la mise hors tension du site D'Un cluster, les E/S sont suspendues brièvement et ont repris ensuite. Reportez-vous aux deux figures suivantes pour les tableaux de bord du cluster de stockage sur le site A et le site B, respectivement avant le sinistre qui montrent environ 80 000 IOPS et un débit de 600 Mo/s sur chaque site.
Après la mise hors tension des contrôleurs de stockage sur le site A, nous pouvons vérifier que les E/S du contrôleur de stockage du site B ont nettement augmenté pour fournir des services de données supplémentaires pour le compte du site A (voir la figure suivante). En outre, l'interface graphique des machines virtuelles IOMeter a également démontré la continuité des E/S malgré la panne du cluster de stockage sur le site. Notez que si d'autres datastores sont sauvegardés par des LUN non protégées par des relations SM-BC, ces datastores ne seront plus accessibles en cas d'incident de stockage. Par conséquent, il est important d'évaluer les besoins métier des diverses données d'application et de les placer correctement dans des datastores protégés par des relations SM-BC pour assurer la continuité de l'activité.
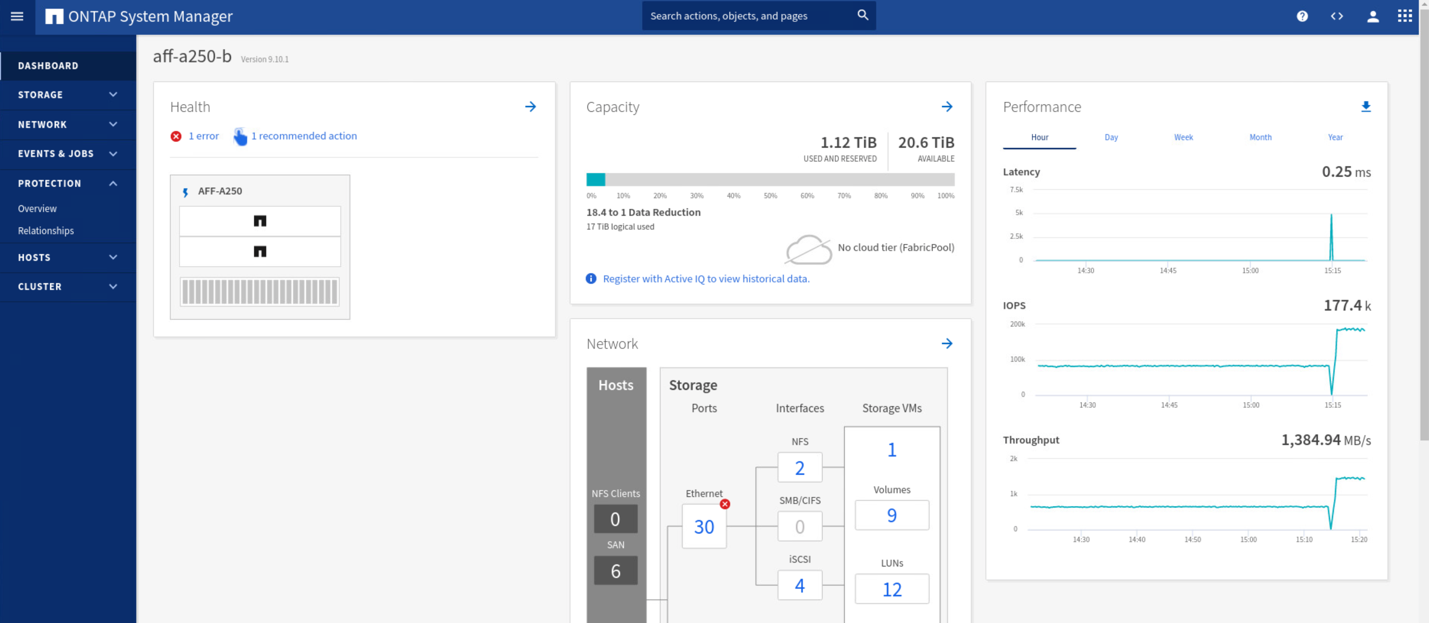
Le site D'Un cluster ne fonctionne pas, mais les relations des groupes cohérents s'affichent Out of sync état comme indiqué dans la figure suivante. Une fois que le système est de nouveau sous tension pour les contrôleurs de stockage du site A, le cluster de stockage démarre et la synchronisation des données entre le site A et le site B se produit automatiquement.
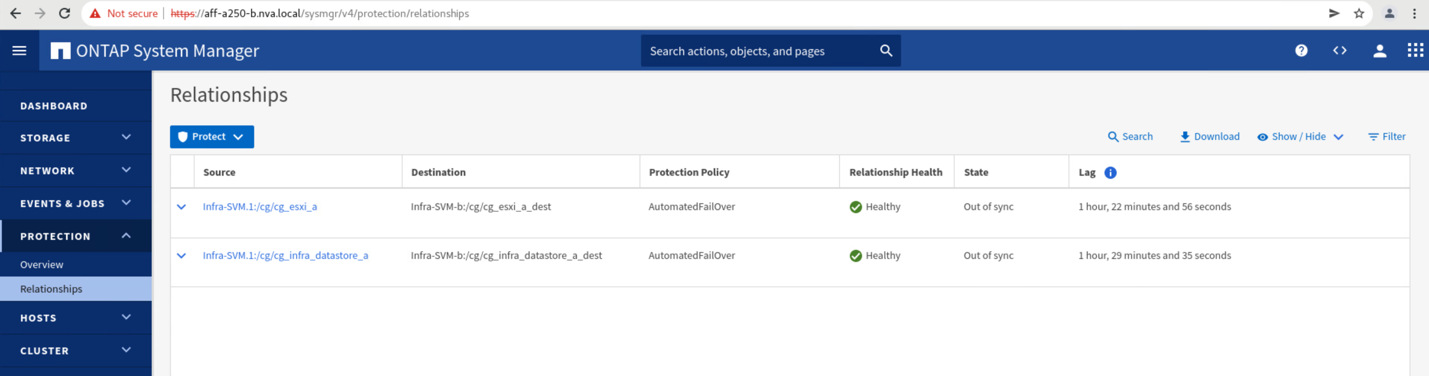
Avant de renvoyer les services de données du site B vers le site A, vous devez consulter le site A System Manager et vérifier que les relations SM-BC sont bien établies et que leur état est de nouveau synchronisé. Après avoir confirmé que les groupes de cohérence sont en cours de synchronisation, une opération de basculement manuel peut être lancée pour renvoyer les services de données dans les relations de groupe de cohérence vers le site A.
Effectuez les opérations de maintenance du site ou les pannes du site
Un site peut avoir besoin d'une maintenance de site, subir des pannes d'électricité ou être touché par une catastrophe naturelle comme un ouragan ou un tremblement de terre. Par conséquent, il est essentiel que vous pratiiez des scénarios d'échec de site planifiés et non planifiés pour vous assurer que votre solution FlexPod SM-BC est correctement configurée pour résister à de telles défaillances pour l'ensemble de vos applications et services de données stratégiques. Les scénarios suivants relatifs au site ont été validés.
-
Scénario de maintenance de site planifié par la migration des machines virtuelles et des services de données critiques vers l'autre site
-
Scénario de panne imprévue à l'échelle du site en mettant hors tension les serveurs et les contrôleurs de stockage à des fins de simulation d'incident
Pour préparer un site pour la maintenance planifiée des sites, une combinaison de migration des machines virtuelles concernées hors du site avec vMotion et d'un basculement manuel des relations de groupes de cohérence SM-BC est nécessaire pour migrer les machines virtuelles et les services de données critiques vers l'autre site. Les tests ont été réalisés en deux commandes différentes : VMotion a d'abord été suivi par les basculements SM-BC et SM-BC, puis vMotion, afin de confirmer que les machines virtuelles continuent à fonctionner et que les services de données ne sont pas interrompus.
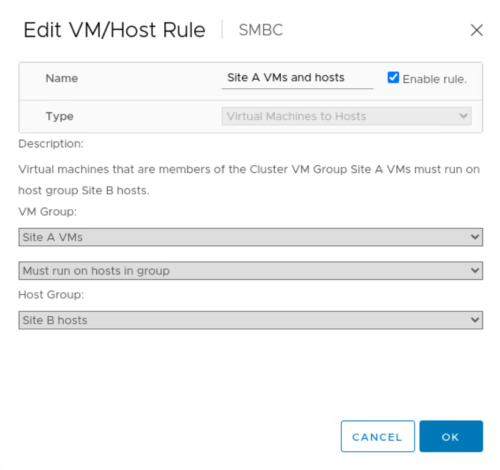
Avant d'effectuer la migration planifiée, mettez à jour la règle d'affinité VM/hôte afin que les machines virtuelles actuellement exécutées sur le site soient automatiquement migrées hors du site en cours de maintenance. La capture d'écran suivante montre un exemple de modification de la règle d'affinité VM/hôte du site A pour que les machines virtuelles migrent automatiquement du site A vers le site B. Au lieu de spécifier que les VM doivent maintenant s'exécuter sur le site B, il est également possible de désactiver temporairement la règle d'affinité pour que les VM puissent être migrées manuellement.
Une fois les ordinateurs virtuels et les services de stockage migrés, vous pouvez mettre hors tension les serveurs, les contrôleurs de stockage, les tiroirs disques et les commutateurs, et réaliser les activités de maintenance du site nécessaires. Une fois la maintenance du site terminée et l'instance FlexPod renvoyée, vous pouvez modifier l'affinité des groupes d'hôtes pour que les VM reprennent leur site d'origine. Ensuite, vous devez modifier la règle d'affinité VM/site hôte "doit être exécuté sur des hôtes dans un groupe" en "devrait s'exécuter sur des hôtes dans un groupe" afin que les machines virtuelles soient autorisées à fonctionner sur des hôtes de l'autre site en cas d'incident. Pour les tests de validation, toutes les machines virtuelles ont été migrées avec succès vers l'autre site et les services de données se sont poursuivis sans problèmes après avoir effectué un basculement pour les relations SM-BC.
Pour la simulation d'incident imprévue à l'échelle du site, les serveurs et les contrôleurs de stockage ont été mis hors tension afin de simuler un incident de site. La fonction VMware HA détecte les machines virtuelles qui sont arrêté et redémarre ces machines virtuelles sur le site survivant. En outre, le médiateur ONTAP fonctionnant sur un troisième site détecte la panne du site et le site survivant lance un basculement et commence à fournir des services de données pour le site en panne comme prévu.
La capture d'écran suivante montre que l'interface de ligne de commande du processeur de service des contrôleurs de stockage a été utilisée pour mettre hors tension le site D'Un cluster brusquement afin de simuler un incident de stockage sur le site.
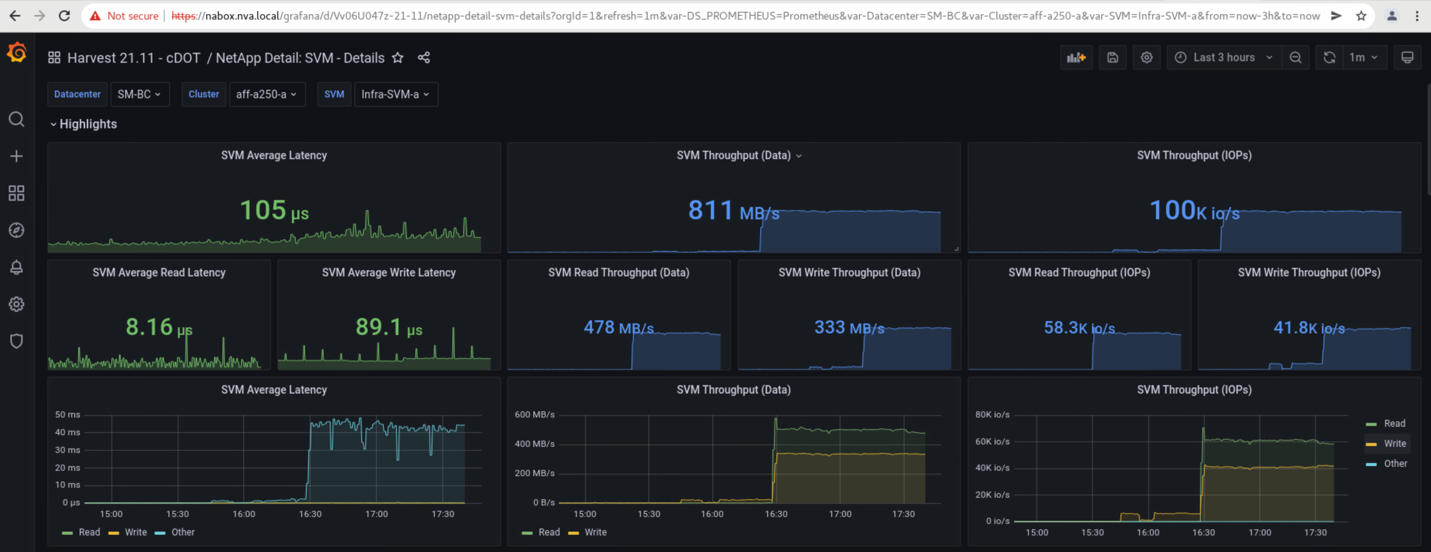
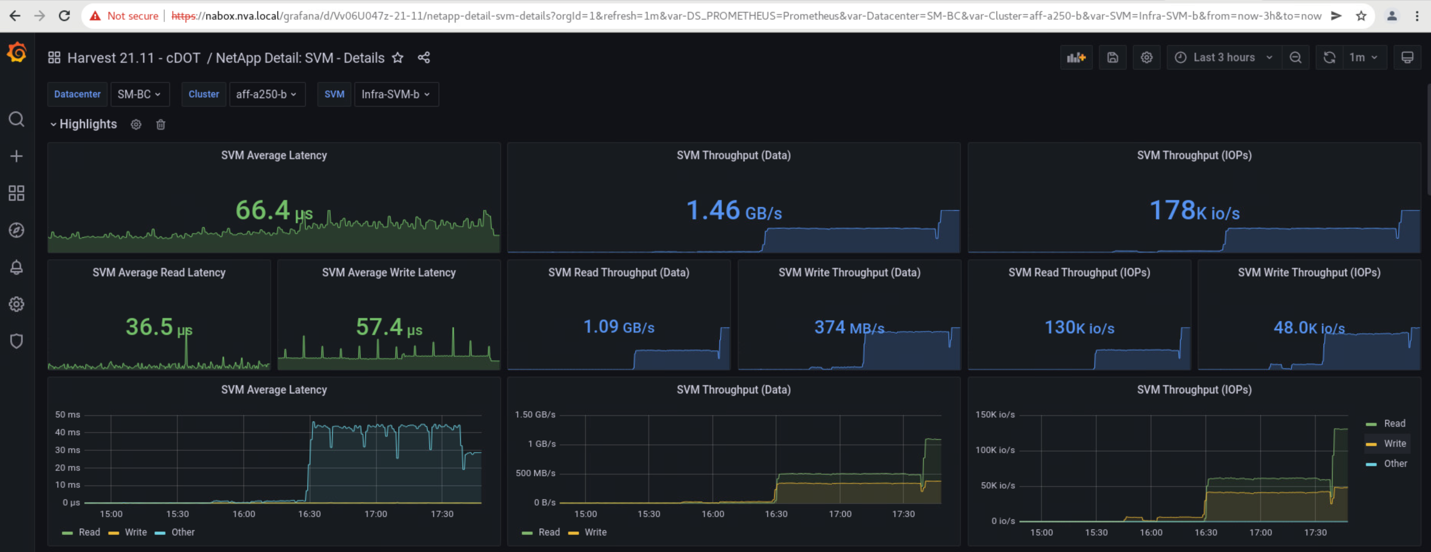
Les tableaux de bord des machines virtuelles de stockage des clusters, tels que capturés par l'outil NetApp Harvest Data et affichés dans le tableau de bord Grafana dans l'outil de surveillance NAbox, sont présentés dans les deux captures d'écran suivantes. Comme l'indique les graphiques à droite des IOPS et des débits, le cluster du site B récupère les charges de travail de stockage du cluster immédiatement après la panne du site A.
Microsoft SQL Server
Microsoft SQL Server est une plateforme de base de données adoptée et déployée pour LE DÉPARTEMENT INFORMATIQUE de l'entreprise. La version Microsoft SQL Server 2019 apporte beaucoup de nouvelles fonctionnalités et améliorations à ses moteurs relationnels et analytiques. Ce logiciel prend en charge les workloads avec des applications exécutées sur site, dans le cloud et dans un environnement hybride. En outre, il peut être déployé sur plusieurs plateformes, notamment Windows, Linux et les conteneurs.
Dans le cadre de la validation des charges de travail stratégiques pour la solution FlexPod SM-BC, Microsoft SQL Server 2019 installé sur une machine virtuelle Windows Server 2022 est inclus avec les machines virtuelles IOMeter pour les tests de basculement du stockage planifiés et non planifiés de SM-BC. Sur la machine virtuelle Windows Server 2022, SQL Server Management Studio est installé pour gérer le serveur SQL. Pour les tests, l'outil base de données HammerDB est utilisé pour générer des transactions de base de données.
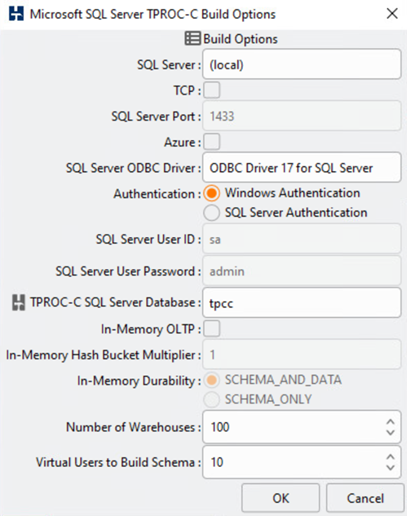
L'outil de test de la base de données HammerDB a été configuré pour les tests avec la charge de travail TPROC-C de Microsoft SQL Server. Pour les configurations de construction de schéma, les options ont été mises à jour pour utiliser 100 entrepôts avec 10 utilisateurs virtuels comme indiqué dans la capture d'écran suivante.
Une fois les options de création de schéma mises à jour, le processus de création de schéma a démarré. Quelques minutes plus tard, une erreur simulée de cluster de stockage du site B a été introduite en mettant hors tension les deux nœuds du cluster de stockage AFF A250 à environ la même heure à l'aide des commandes CLI du processeur système.
Après une courte pause des transactions de base de données, le basculement automatique pour la correction des sinistres a débuté et les transactions ont repris. La capture d'écran ci-dessous montre la capture d'écran du compteur de transactions HammerDB. Étant donné que la base de données de Microsoft SQL Server réside généralement dans le cluster de stockage du site B, la transaction a été interrompue brièvement lorsque le stockage sur le site B s'est arrêté, puis reprise après le basculement automatisé.
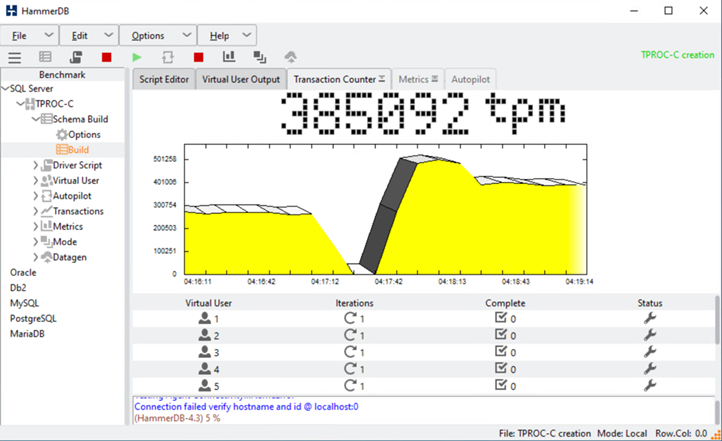
Les metrics du cluster de stockage ont été capturées à l'aide de l'outil NAbox et de l'outil de surveillance de récolte NetApp installé. Les résultats sont affichés dans les tableaux de bord prédéfinis de Grafana pour la machine virtuelle de stockage et autres objets de stockage. Le tableau de bord fournit des schémas de latence, de débit et d'IOPS, ainsi que des détails supplémentaires avec des statistiques de lecture et d'écriture séparées pour le site B et le site A.
Cette capture d'écran présente le tableau de bord des performances NAbox Grafana pour cluster de stockage site B.
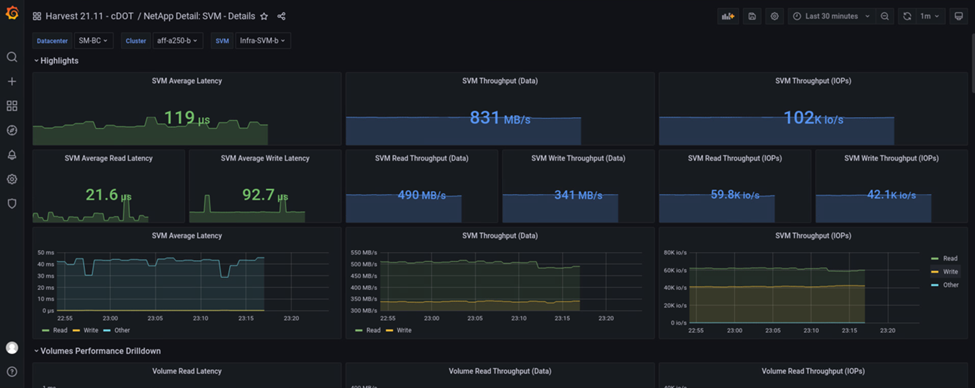
Le cluster de stockage du site B était d'environ 100 000 IOPS avant l'introduction de l'incident. Ensuite, les mesures de performances ont montré une baisse nette de zéro à droite des graphiques dus à l'incident. Comme le cluster de stockage du site B était en panne, aucun élément ne pouvait être collecté à partir du cluster du site B après l'introduction du sinistre.
À l'inverse, les IOPS du cluster de stockage du site A ont récupéré les charges de travail supplémentaires depuis le site B après le basculement automatisé. La charge de travail supplémentaire est facilement affichée à droite des graphiques IOPS et débit dans la capture d'écran suivante, qui montre le tableau de bord des performances de NAbox Grafana pour site De cluster de stockage.
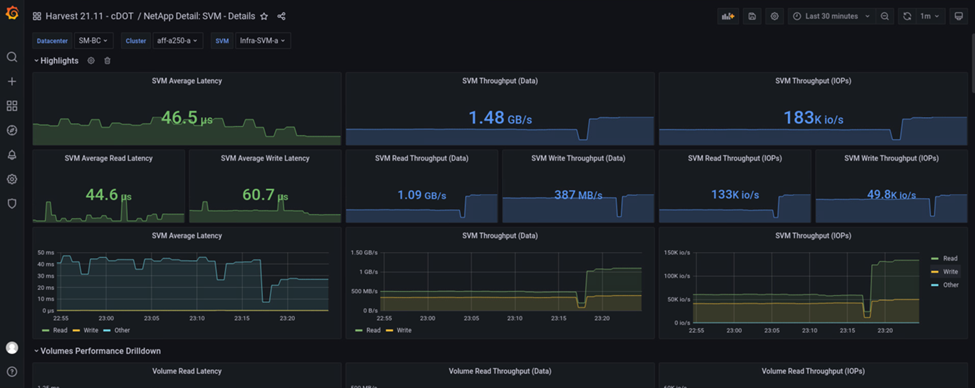
Le scénario de test d'incident de stockage ci-dessus a confirmé que la charge de travail de Microsoft SQL Server peut survivre à une panne complète du cluster de stockage sur le site B où réside la base de données. Une fois l'incident détecté et le basculement effectué, l'application a utilisé de manière transparente les services de données du site De cluster De stockage.
Au niveau de la couche de calcul, lorsque les machines virtuelles qui s'exécutent sur un site particulier souffrent d'une défaillance d'hôte, les machines virtuelles sont conçues pour être redémarrée automatiquement par la fonctionnalité de haute disponibilité VMware. En cas de panne de calcul de l'ensemble du site, les règles d'affinité VM/hôte permettent de redémarrer les machines virtuelles sur le site survivant. Cependant, pour qu'une application stratégique puisse fournir des services sans interruption, une solution de mise en cluster basée sur des applications telles que Microsoft Failover Cluster ou l'architecture applicative basée sur des conteneurs Kubernetes doit éviter les temps d'indisponibilité des applications. Veuillez vous reporter au document relatif à l'implémentation de la mise en cluster basée sur l'application, qui va au-delà du périmètre de ce rapport technique.