TR-4912 : Recommandations de bonnes pratiques pour le stockage hiérarchisé Confluent Kafka avec NetApp
 Suggérer des modifications
Suggérer des modifications
Karthikeyan Nagalingam, Joseph Kandatilparambil, NetApp Rankesh Kumar, Confluent
Apache Kafka est une plateforme de streaming d'événements distribuée par la communauté, capable de gérer des milliards d'événements par jour. Initialement conçu comme une file d'attente de messagerie, Kafka est basé sur une abstraction d'un journal de validation distribué. Depuis sa création et sa publication en open source par LinkedIn en 2011, Kafka est passé d'une simple file d'attente de messages à une plateforme de streaming d'événements à part entière. Confluent fournit la distribution d'Apache Kafka avec la plateforme Confluent. La plateforme Confluent complète Kafka avec des fonctionnalités communautaires et commerciales supplémentaires conçues pour améliorer l'expérience de streaming des opérateurs et des développeurs en production à grande échelle.
Ce document décrit les meilleures pratiques pour l'utilisation du stockage hiérarchisé Confluent sur une offre de stockage d'objets NetApp en fournissant le contenu suivant :
-
Vérification confluente avec le stockage d'objets NetApp – NetApp StorageGRID
-
Tests de performances de stockage hiérarchisé
-
Lignes directrices sur les meilleures pratiques pour Confluent sur les systèmes de stockage NetApp
Pourquoi choisir le stockage hiérarchisé Confluent ?
Confluent est devenu la plateforme de streaming en temps réel par défaut pour de nombreuses applications, en particulier pour les charges de travail de Big Data, d'analyse et de streaming. Le stockage hiérarchisé permet aux utilisateurs de séparer le calcul du stockage sur la plateforme Confluent. Il rend le stockage des données plus rentable, vous permet de stocker des quantités pratiquement infinies de données et d'augmenter (ou de réduire) les charges de travail à la demande, et facilite les tâches administratives telles que le rééquilibrage des données et des locataires. Les systèmes de stockage compatibles S3 peuvent tirer parti de toutes ces fonctionnalités pour démocratiser les données avec tous les événements en un seul endroit, éliminant ainsi le besoin d'une ingénierie de données complexe. Pour plus d'informations sur les raisons pour lesquelles vous devriez utiliser le stockage hiérarchisé pour Kafka, consultez"cet article de Confluent" .
NetApp instaclustr prend également en charge Kafka avec stockage hiérarchisé à partir de la version 3.8.1. Veuillez consulter plus de détails ici "instaclust utilisant le stockage hiérarchisé de Kafka"
Pourquoi NetApp StorageGRID pour le stockage hiérarchisé ?
StorageGRID est une plate-forme de stockage d'objets leader du secteur de NetApp. StorageGRID est une solution de stockage basée sur des objets définie par logiciel qui prend en charge les API d'objets standard du secteur, notamment l'API Amazon Simple Storage Service (S3). StorageGRID stocke et gère les données non structurées à grande échelle pour fournir un stockage d'objets sécurisé et durable. Le contenu est placé au bon endroit, au bon moment et sur le bon niveau de stockage, optimisant ainsi les flux de travail et réduisant les coûts des médias riches distribués à l'échelle mondiale.
Le principal facteur de différenciation de StorageGRID est son moteur de politique de gestion du cycle de vie des informations (ILM) qui permet une gestion du cycle de vie des données basée sur des politiques. Le moteur de politique peut utiliser les métadonnées pour gérer la manière dont les données sont stockées tout au long de leur durée de vie afin d'optimiser initialement les performances et d'optimiser automatiquement les coûts et la durabilité à mesure que les données vieillissent.
Activation du stockage hiérarchisé Confluent
L’idée de base du stockage hiérarchisé est de séparer les tâches de stockage des données du traitement des données. Grâce à cette séparation, il devient beaucoup plus facile pour le niveau de stockage des données et le niveau de traitement des données de s'adapter indépendamment.
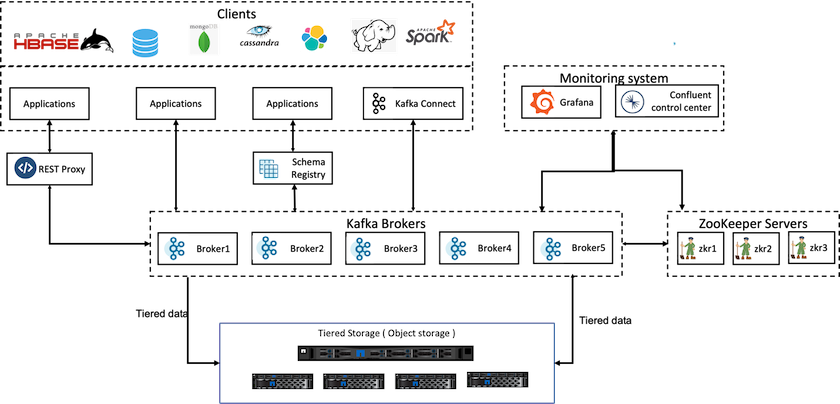
Une solution de stockage à plusieurs niveaux pour Confluent doit tenir compte de deux facteurs. Tout d’abord, il doit contourner ou éviter les propriétés courantes de cohérence et de disponibilité du magasin d’objets, telles que les incohérences dans les opérations LIST et l’indisponibilité occasionnelle des objets. Deuxièmement, il doit gérer correctement l'interaction entre le stockage hiérarchisé et le modèle de réplication et de tolérance aux pannes de Kafka, y compris la possibilité que les leaders zombies continuent à hiérarchiser les plages de décalage. Le stockage d'objets NetApp offre à la fois une disponibilité d'objet cohérente et un modèle HA qui rend le stockage fatigué disponible pour les plages de décalage de niveaux. Le stockage d'objets NetApp offre une disponibilité d'objet cohérente et un modèle HA pour rendre le stockage fatigué disponible pour les plages de décalage de niveaux.
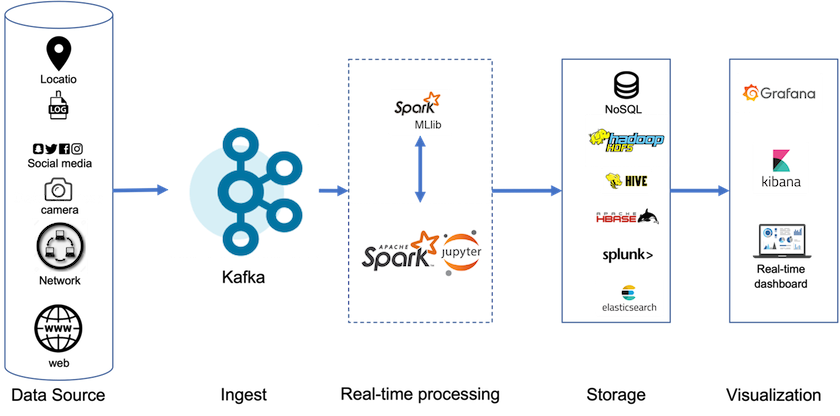
Avec le stockage hiérarchisé, vous pouvez utiliser des plates-formes hautes performances pour les lectures et écritures à faible latence près de la fin de vos données en streaming, et vous pouvez également utiliser des magasins d'objets évolutifs et moins chers comme NetApp StorageGRID pour les lectures historiques à haut débit. Nous avons également une solution technique pour Spark avec le contrôleur de stockage NetApp et les détails sont ici. La figure suivante montre comment Kafka s’intègre dans un pipeline d’analyse en temps réel.
La figure suivante illustre comment NetApp StorageGRID s’intègre en tant que niveau de stockage d’objets de Confluent Kafka.