

Data Fabric optimisé par NetApp pour l'architecture Big Data
 Suggérer des modifications
Suggérer des modifications
La structure de données optimisée par NetApp simplifie et intègre la gestion des données dans les environnements cloud et sur site pour accélérer la transformation numérique.
La structure de données optimisée par NetApp fournit des services et des applications de gestion de données cohérents et intégrés (blocs de construction) pour la visibilité et les informations sur les données, l'accès et le contrôle des données, ainsi que la protection et la sécurité des données, comme illustré dans la figure ci-dessous.
Cas d'utilisation client éprouvés de Data Fabric
La structure de données optimisée par NetApp fournit les neuf cas d'utilisation éprouvés suivants aux clients :
-
Accélérer les charges de travail d'analyse
-
Accélérer la transformation DevOps
-
Construire une infrastructure d'hébergement cloud
-
Intégrer les services de données cloud
-
Protéger et sécuriser les données
-
Optimiser les données non structurées
-
Gagnez en efficacité dans votre centre de données
-
Fournir des informations et un contrôle sur les données
-
Simplifier et automatiser
Ce document couvre deux des neuf cas d’utilisation (ainsi que leurs solutions) :
-
Accélérer les charges de travail d'analyse
-
Protéger et sécuriser les données
Accès direct NetApp NFS
NetApp NFS permet aux clients d'exécuter des tâches d'analyse de Big Data sur leurs données NFSv3 ou NFSv4 existantes ou nouvelles sans déplacer ni copier les données. Il empêche les copies multiples de données et élimine le besoin de synchroniser les données avec une source. Par exemple, dans le secteur financier, le déplacement de données d’un endroit à un autre doit répondre à des obligations légales, ce qui n’est pas une tâche facile. Dans ce scénario, l’accès direct NetApp NFS analyse les données financières à partir de leur emplacement d’origine. Un autre avantage clé est que l’utilisation de l’accès direct NetApp NFS simplifie la protection des données Hadoop en utilisant des commandes Hadoop natives et permet des flux de travail de protection des données exploitant le riche portefeuille de gestion des données de NetApp.
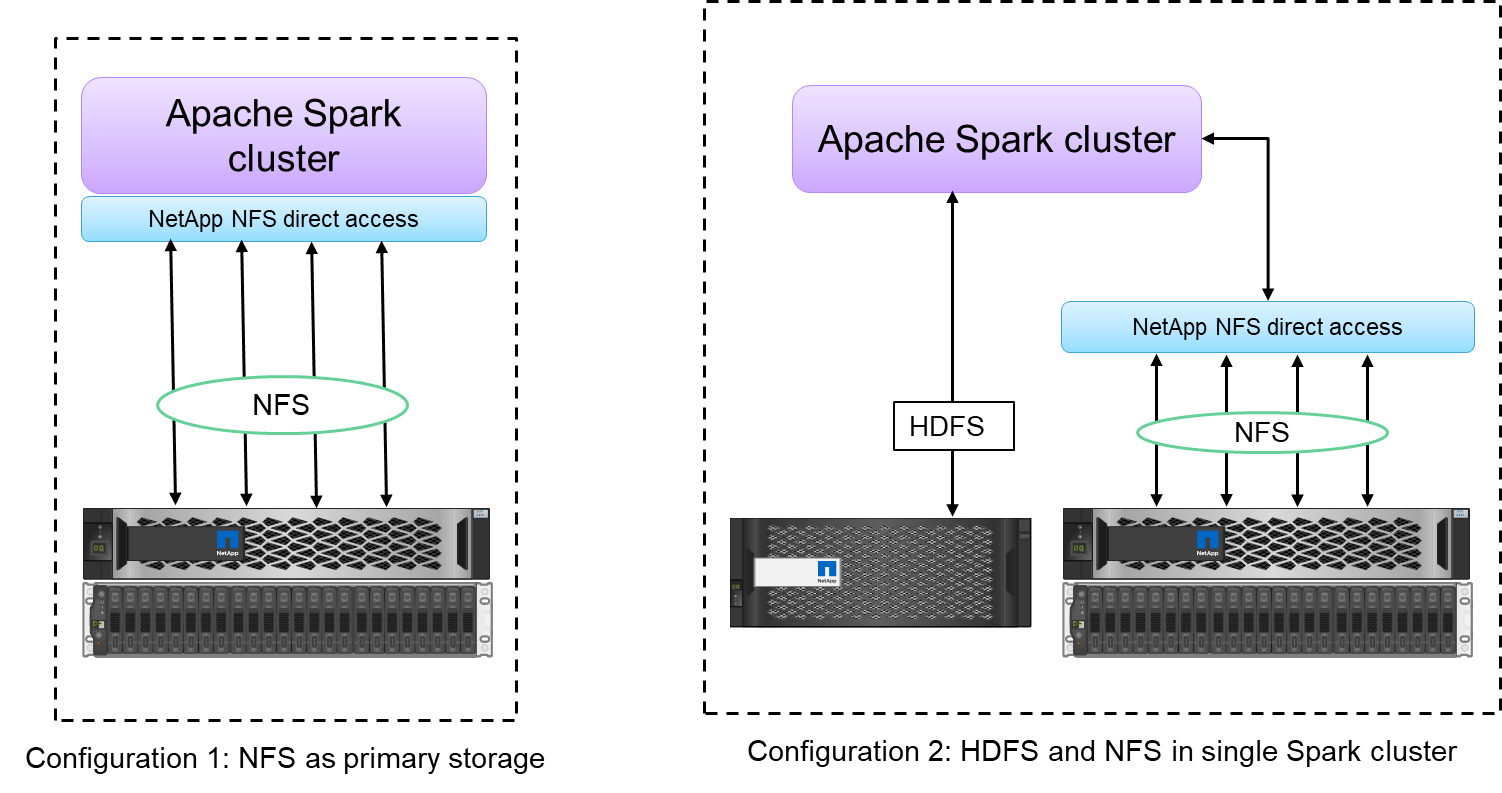
L'accès direct NetApp NFS offre deux types d'options de déploiement pour les clusters Hadoop/Spark :
-
Par défaut, les clusters Hadoop/Spark utilisent Hadoop Distributed File System (HDFS) pour le stockage des données et le système de fichiers par défaut. L'accès direct NetApp NFS peut remplacer le HDFS par défaut par le stockage NFS comme système de fichiers par défaut, permettant des opérations d'analyse directes sur les données NFS.
-
Dans une autre option de déploiement, l'accès direct NetApp NFS prend en charge la configuration de NFS comme stockage supplémentaire avec HDFS dans un seul cluster Hadoop/Spark. Dans ce cas, le client peut partager des données via des exportations NFS et y accéder à partir du même cluster avec les données HDFS.
Les principaux avantages de l’utilisation de l’accès direct NetApp NFS incluent :
-
Analyse les données à partir de leur emplacement actuel, ce qui évite la tâche fastidieuse et coûteuse en performances consistant à déplacer les données d'analyse vers une infrastructure Hadoop telle que HDFS.
-
Réduit le nombre de répliques de trois à une.
-
Permet aux utilisateurs de découpler le calcul et le stockage pour les faire évoluer indépendamment.
-
Fournit une protection des données d'entreprise en exploitant les riches capacités de gestion des données d' ONTAP.
-
Est certifié avec la plateforme de données Hortonworks.
-
Permet des déploiements d’analyse de données hybrides.
-
Réduit le temps de sauvegarde en exploitant la capacité multithread dynamique.
Éléments de base du Big Data
La structure de données optimisée par NetApp intègre des services et des applications de gestion des données (blocs de construction) pour l'accès, le contrôle, la protection et la sécurité des données, comme illustré dans la figure ci-dessous.
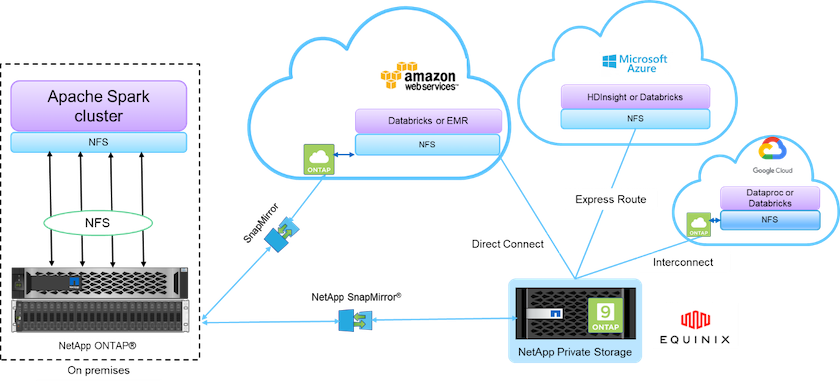
Les éléments constitutifs de la figure ci-dessus comprennent :
-
* Accès direct NetApp NFS.* Fournit aux derniers clusters Hadoop et Spark un accès direct aux volumes NetApp NFS sans exigences de logiciel ou de pilote supplémentaires.
-
* NetApp Cloud Volumes ONTAP et Google Cloud NetApp Volumes.* Stockage connecté défini par logiciel basé sur ONTAP exécuté dans Amazon Web Services (AWS) ou Azure NetApp Files (ANF) dans les services cloud Microsoft Azure.
-
* Technologie NetApp SnapMirror *. Fournit des capacités de protection des données entre les instances locales et ONTAP Cloud ou NPS.
-
Fournisseurs de services cloud. Ces fournisseurs incluent AWS, Microsoft Azure, Google Cloud et IBM Cloud.
-
PaaS. Services d'analyse basés sur le cloud tels qu'Amazon Elastic MapReduce (EMR) et Databricks dans AWS ainsi que Microsoft Azure HDInsight et Azure Databricks.