

Aperçu de la technologie
 Suggérer des modifications
Suggérer des modifications
Cette section décrit la technologie utilisée dans cette solution.
Contrôleur de stockage NetApp ONTAP
NetApp ONTAP est un système d’exploitation de stockage hautes performances de niveau entreprise.
NetApp ONTAP 9.8 introduit la prise en charge des API Amazon Simple Storage Service (S3). ONTAP prend en charge un sous-ensemble d'actions d'API S3 d'Amazon Web Services (AWS) et permet aux données d'être représentées sous forme d'objets dans les systèmes basés sur ONTAP sur les fournisseurs de cloud (AWS, Azure et GCP) et sur site.
Le logiciel NetApp StorageGRID est la solution phare de NetApp pour le stockage d'objets. ONTAP complète StorageGRID en fournissant un point d'ingestion et de prétraitement en périphérie, en étendant la structure de données optimisée par NetApp pour les données d'objets et en augmentant la valeur du portefeuille de produits NetApp .
L'accès à un compartiment S3 est fourni via des applications utilisateur et client autorisées. Le diagramme suivant montre l’application accédant à un bucket S3.
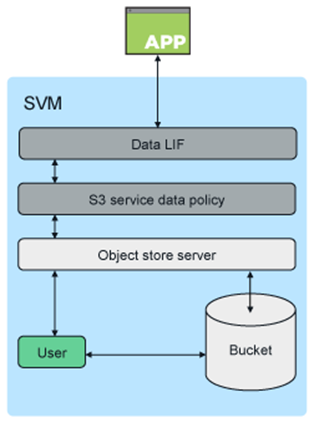
Principaux cas d'utilisation
L’objectif principal de la prise en charge des API S3 est de fournir un accès aux objets sur ONTAP. L'architecture de stockage unifiée ONTAP prend désormais en charge les fichiers (NFS et SMB), les blocs (FC et iSCSI) et les objets (S3).
Applications S3 natives
Un nombre croissant d’applications sont capables d’exploiter la prise en charge ONTAP pour l’accès aux objets à l’aide de S3. Bien que bien adapté aux charges de travail d'archivage à haute capacité, le besoin de hautes performances dans les applications S3 natives augmente rapidement et comprend :
-
Analytique
-
Intelligence artificielle
-
Ingestion de la périphérie au cœur
-
Apprentissage automatique
Les clients peuvent désormais utiliser des outils de gestion familiers tels ONTAP System Manager pour provisionner rapidement un stockage d'objets hautes performances pour le développement et les opérations dans ONTAP, en profitant de l'efficacité et de la sécurité du stockage ONTAP .
Points de terminaison FabricPool
À partir d' ONTAP 9.8, FabricPool prend en charge la hiérarchisation des buckets dans ONTAP, permettant ainsi la hiérarchisation ONTAP vers ONTAP . Il s’agit d’une excellente option pour les clients qui souhaitent réutiliser l’infrastructure FAS existante comme point de terminaison de magasin d’objets.
FabricPool prend en charge la hiérarchisation vers ONTAP de deux manières :
-
Hiérarchisation des clusters locaux. Les données inactives sont hiérarchisées vers un compartiment situé sur le cluster local à l'aide de LIF de cluster.
-
Hiérarchisation de clusters distants. Les données inactives sont hiérarchisées vers un compartiment situé sur un cluster distant d'une manière similaire à un niveau cloud FabricPool traditionnel à l'aide de LIF IC sur le client FabricPool et de LIF de données sur le magasin d'objets ONTAP .
ONTAP S3 est approprié si vous souhaitez des fonctionnalités S3 sur des clusters existants sans matériel ni gestion supplémentaires. Pour les déploiements supérieurs à 300 To, le logiciel NetApp StorageGRID reste la solution phare de NetApp pour le stockage d'objets. Une licence FabricPool n’est pas requise lors de l’utilisation ONTAP ou de StorageGRID comme niveau cloud.
NetApp ONTAP pour le stockage hiérarchisé Confluent
Chaque centre de données doit garantir le fonctionnement des applications critiques pour l’entreprise et la disponibilité et la sécurité des données importantes. Le nouveau système NetApp AFF A900 est alimenté par le logiciel ONTAP Enterprise Edition et une conception haute résilience. Notre nouveau système de stockage NVMe ultra-rapide élimine les perturbations des opérations critiques, minimise le réglage des performances et protège vos données contre les attaques de ransomware.
Du déploiement initial à la mise à l'échelle de votre cluster Confluent, votre environnement exige une adaptation rapide aux changements qui ne perturbent pas vos applications critiques. La gestion des données d'entreprise, la qualité de service (QoS) et les performances ONTAP vous permettent de planifier et de vous adapter à votre environnement.
L'utilisation conjointe de NetApp ONTAP et de Confluent Tiered Storage simplifie la gestion des clusters Apache Kafka en exploitant ONTAP comme cible de stockage évolutive et permet une mise à l'échelle indépendante des ressources de calcul et de stockage pour Confluent.
Un serveur ONTAP S3 est construit sur les capacités de stockage évolutives matures d' ONTAP. La mise à l’échelle de votre cluster ONTAP peut être effectuée de manière transparente en étendant vos buckets S3 pour utiliser les nœuds nouvellement ajoutés au cluster ONTAP .
Gestion simple avec ONTAP System Manager
ONTAP System Manager est une interface graphique basée sur un navigateur qui vous permet de configurer, de gérer et de surveiller votre contrôleur de stockage ONTAP sur des emplacements répartis dans le monde entier dans une seule fenêtre.
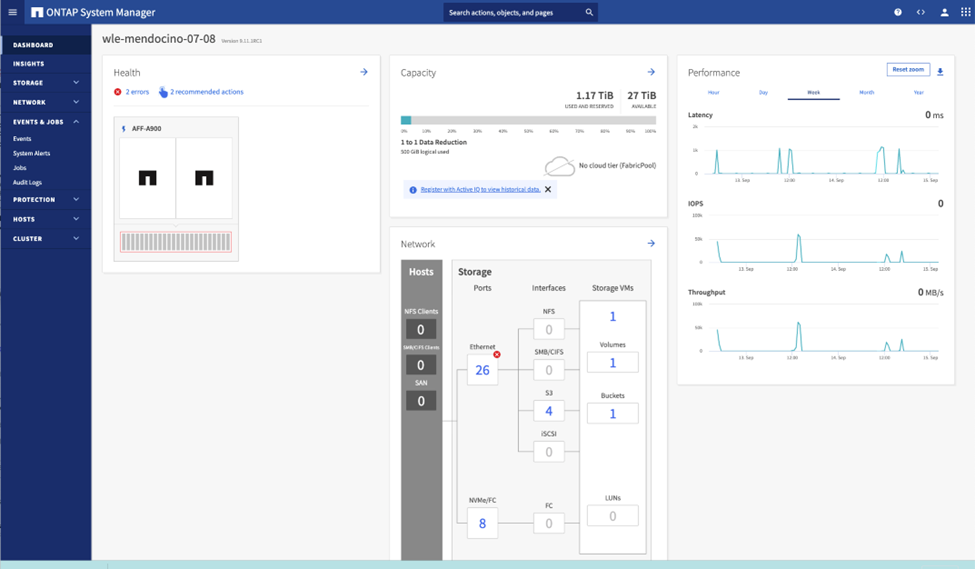
Vous pouvez configurer et gérer ONTAP S3 avec System Manager et l'interface de ligne de commande ONTAP . Lorsque vous activez S3 et créez des buckets à l’aide de System Manager, ONTAP fournit des valeurs par défaut de bonnes pratiques pour une configuration simplifiée. Si vous configurez le serveur S3 et les buckets à partir de l'interface de ligne de commande, vous pouvez toujours les gérer avec System Manager si vous le souhaitez ou vice-versa.
Lorsque vous créez un compartiment S3 à l'aide de System Manager, ONTAP configure un niveau de service de performances par défaut qui est le plus élevé disponible sur votre système. Par exemple, sur un système AFF , le paramètre par défaut serait Extrême. Les niveaux de service de performance sont des groupes de politiques QoS adaptatifs prédéfinis. Au lieu de l’un des niveaux de service par défaut, vous pouvez spécifier un groupe de politiques QoS personnalisé ou aucun groupe de politiques.
Les groupes de politiques QoS adaptatives prédéfinis incluent les éléments suivants :
-
Extrême. Utilisé pour les applications qui nécessitent la latence la plus faible et les performances les plus élevées.
-
Performance. Utilisé pour les applications avec des besoins de performances et de latence modestes.
-
Valeur. Utilisé pour les applications pour lesquelles le débit et la capacité sont plus importants que la latence.
-
Coutume. Spécifiez une politique QoS personnalisée ou aucune politique QoS.
Si vous sélectionnez Utiliser pour la hiérarchisation, aucun niveau de service de performances n'est sélectionné et le système tente de sélectionner des supports à faible coût avec des performances optimales pour les données hiérarchisées.
ONTAP essaie de provisionner ce bucket sur les niveaux locaux qui disposent des disques les plus appropriés, satisfaisant le niveau de service choisi. Toutefois, si vous devez spécifier les disques à inclure dans le bucket, envisagez de configurer le stockage d'objets S3 à partir de l'interface de ligne de commande en spécifiant les niveaux locaux (agrégat). Si vous configurez le serveur S3 à partir de l'interface de ligne de commande, vous pouvez toujours le gérer avec le Gestionnaire système si vous le souhaitez.
Si vous souhaitez pouvoir spécifier quels agrégats sont utilisés pour les buckets, vous ne pouvez le faire qu'à l'aide de l'interface de ligne de commande.
Confluent
Confluent Platform est une plateforme de streaming de données à grande échelle qui vous permet d'accéder, de stocker et de gérer facilement les données sous forme de flux continus en temps réel. Conçu par les créateurs originaux d'Apache Kafka, Confluent étend les avantages de Kafka avec des fonctionnalités de niveau entreprise tout en supprimant le fardeau de la gestion ou de la surveillance de Kafka. Aujourd’hui, plus de 80 % des entreprises du Fortune 100 utilisent la technologie de streaming de données, et la plupart utilisent Confluent.
Pourquoi Confluent ?
En intégrant des données historiques et en temps réel dans une source unique et centrale de vérité, Confluent facilite la création d'une toute nouvelle catégorie d'applications modernes axées sur les événements, l'obtention d'un pipeline de données universel et le déblocage de nouveaux cas d'utilisation puissants avec une évolutivité, des performances et une fiabilité complètes.
À quoi sert Confluent ?
Confluent Platform vous permet de vous concentrer sur la manière de tirer profit de vos données plutôt que de vous soucier des mécanismes sous-jacents, tels que la manière dont les données sont transportées ou intégrées entre des systèmes disparates. Plus précisément, Confluent Platform simplifie la connexion des sources de données à Kafka, la création d'applications de streaming, ainsi que la sécurisation, la surveillance et la gestion de votre infrastructure Kafka. Aujourd'hui, Confluent Platform est utilisé pour un large éventail de cas d'utilisation dans de nombreux secteurs, des services financiers, de la vente au détail omnicanal et des voitures autonomes à la détection de fraude, aux microservices et à l'IoT.
La figure suivante montre les composants de Confluent Platform.
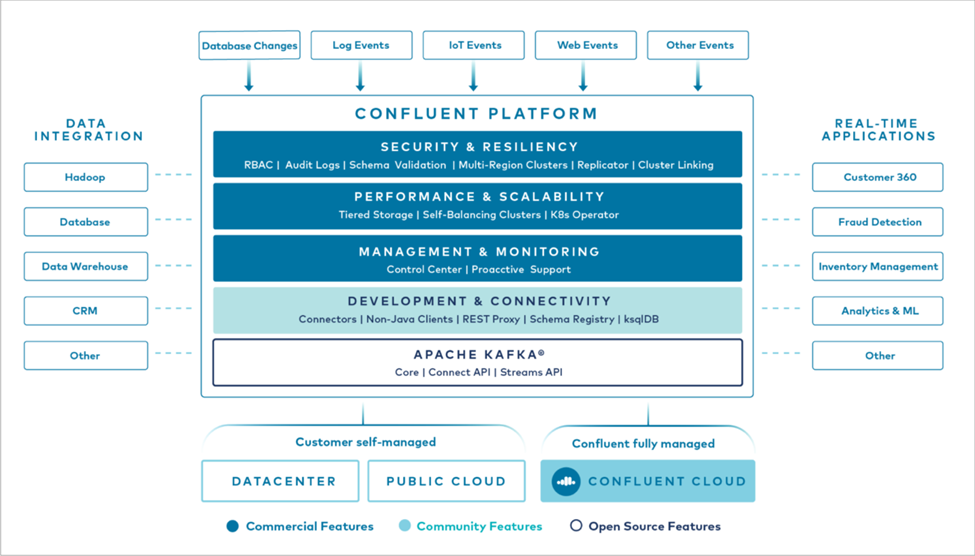
Présentation de la technologie de diffusion d'événements Confluent
Au cœur de la plateforme Confluent se trouve "Kafka" , la plateforme de streaming distribuée open source la plus populaire. Les principales fonctionnalités de Kafka sont les suivantes :
-
Publiez et abonnez-vous à des flux d'enregistrements.
-
Stockez des flux d’enregistrements de manière tolérante aux pannes.
-
Traiter les flux d'enregistrements.
Prêt à l'emploi, Confluent Platform inclut également Schema Registry, REST Proxy, un total de plus de 100 connecteurs Kafka prédéfinis et ksqlDB.
Présentation des fonctionnalités d'entreprise de la plateforme Confluent
-
Centre de contrôle Confluent. Un système basé sur l'interface utilisateur pour la gestion et la surveillance de Kafka. Il vous permet de gérer facilement Kafka Connect et de créer, modifier et gérer des connexions à d'autres systèmes.
-
Confluent pour Kubernetes. Confluent pour Kubernetes est un opérateur Kubernetes. Les opérateurs Kubernetes étendent les capacités d’orchestration de Kubernetes en fournissant les fonctionnalités et les exigences uniques pour une application de plate-forme spécifique. Pour Confluent Platform, cela inclut la simplification considérable du processus de déploiement de Kafka sur Kubernetes et l'automatisation des tâches typiques du cycle de vie de l'infrastructure.
-
Connecteurs Kafka Connect. Les connecteurs utilisent l'API Kafka Connect pour connecter Kafka à d'autres systèmes tels que des bases de données, des magasins de clés-valeurs, des index de recherche et des systèmes de fichiers. Confluent Hub propose des connecteurs téléchargeables pour les sources et récepteurs de données les plus populaires, y compris des versions entièrement testées et prises en charge de ces connecteurs avec Confluent Platform. Plus de détails peuvent être trouvés "ici" .
-
Clusters auto-équilibrés. Fournit un équilibrage de charge automatisé, une détection des pannes et une auto-réparation. Il fournit également un support pour l'ajout ou la désactivation de courtiers selon les besoins, sans réglage manuel.
-
Liaison de cluster confluent. Connecte directement les clusters entre eux et reflète les sujets d'un cluster à un autre via un pont de liaison. La liaison de cluster simplifie la configuration des déploiements multi-centres de données, multi-clusters et cloud hybride.
-
Équilibreur de données automatique Confluent. Surveille votre cluster pour le nombre de courtiers, la taille des partitions, le nombre de partitions et le nombre de leaders au sein du cluster. Il vous permet de déplacer les données pour créer une charge de travail uniforme sur votre cluster, tout en limitant le trafic de rééquilibrage pour minimiser l'effet sur les charges de travail de production lors du rééquilibrage.
-
Réplicateur confluent. Il est plus facile que jamais de maintenir plusieurs clusters Kafka dans plusieurs centres de données.
-
Stockage à plusieurs niveaux. Fournit des options pour stocker de grands volumes de données Kafka à l'aide de votre fournisseur de cloud préféré, réduisant ainsi la charge et les coûts opérationnels. Avec le stockage hiérarchisé, vous pouvez conserver les données sur un stockage d'objets rentable et faire évoluer les courtiers uniquement lorsque vous avez besoin de davantage de ressources de calcul.
-
Client JMS confluent. Confluent Platform inclut un client compatible JMS pour Kafka. Ce client Kafka implémente l'API standard JMS 1.1, en utilisant les courtiers Kafka comme backend. Ceci est utile si vous avez des applications héritées utilisant JMS et que vous souhaitez remplacer le courtier de messages JMS existant par Kafka.
-
Proxy MQTT confluent. Fournit un moyen de publier des données directement sur Kafka à partir d'appareils et de passerelles MQTT sans avoir besoin d'un courtier MQTT au milieu.
-
Plugins de sécurité Confluent. Les plugins de sécurité Confluent sont utilisés pour ajouter des fonctionnalités de sécurité à divers outils et produits de la plateforme Confluent. Actuellement, il existe un plugin disponible pour le proxy REST Confluent qui permet d'authentifier les requêtes entrantes et de propager le principal authentifié aux requêtes vers Kafka. Cela permet aux clients proxy Confluent REST d'utiliser les fonctionnalités de sécurité multilocataire du courtier Kafka.