

Procédure de test et résultats détaillés
 Suggérer des modifications
Suggérer des modifications
Cette section décrit les résultats détaillés de la procédure de test.
Formation à la reconnaissance d'images avec ResNet dans ONTAP
Nous avons exécuté le benchmark ResNet50 avec un et deux serveurs SR670 V2. Ce test a utilisé le conteneur MXNet 22.04-py3 NGC pour exécuter la formation.
Nous avons utilisé la procédure de test suivante dans cette validation :
-
Nous avons vidé le cache de l'hôte avant d'exécuter le script pour nous assurer que les données n'étaient pas déjà mises en cache :
sync ; sudo /sbin/sysctl vm.drop_caches=3
-
Nous avons exécuté le script de référence avec l’ensemble de données ImageNet dans le stockage du serveur (stockage SSD local) ainsi que sur le système de stockage NetApp AFF .
-
Nous avons validé les performances du réseau et du stockage local à l'aide de
ddcommande. -
Pour l'exécution sur un seul nœud, nous avons utilisé la commande suivante :
python train_imagenet.py --gpus 0,1,2,3,4,5,6,7 --batch-size 408 --kv-store horovod --lr 10.5 --mom 0.9 --lr-step-epochs pow2 --lars-eta 0.001 --label-smoothing 0.1 --wd 5.0e-05 --warmup-epochs 2 --eval-period 4 --eval-offset 2 --optimizer sgdwfastlars --network resnet-v1b-stats-fl --num-layers 50 --num-epochs 37 --accuracy-threshold 0.759 --seed 27081 --dtype float16 --disp-batches 20 --image-shape 4,224,224 --fuse-bn-relu 1 --fuse-bn-add-relu 1 --bn-group 1 --min-random-area 0.05 --max-random-area 1.0 --conv-algo 1 --force-tensor-core 1 --input-layout NHWC --conv-layout NHWC --batchnorm-layout NHWC --pooling-layout NHWC --batchnorm-mom 0.9 --batchnorm-eps 1e-5 --data-train /data/train.rec --data-train-idx /data/train.idx --data-val /data/val.rec --data-val-idx /data/val.idx --dali-dont-use-mmap 0 --dali-hw-decoder-load 0 --dali-prefetch-queue 5 --dali-nvjpeg-memory-padding 256 --input-batch-multiplier 1 --dali- threads 6 --dali-cache-size 0 --dali-roi-decode 1 --dali-preallocate-width 5980 --dali-preallocate-height 6430 --dali-tmp-buffer-hint 355568328 --dali-decoder-buffer-hint 1315942 --dali-crop-buffer-hint 165581 --dali-normalize-buffer-hint 441549 --profile 0 --e2e-cuda-graphs 0 --use-dali
-
Pour les exécutions distribuées, nous avons utilisé le modèle de parallélisation du serveur de paramètres. Nous avons utilisé deux serveurs de paramètres par nœud et nous avons défini le nombre d'époques pour qu'il soit le même que pour l'exécution à nœud unique. Nous avons fait cela parce que la formation distribuée prend souvent plus d’époques en raison d’une synchronisation imparfaite entre les processus. Le nombre différent d’époques peut fausser les comparaisons entre les cas à nœud unique et les cas distribués.
Vitesse de lecture des données : stockage local ou réseau
La vitesse de lecture a été testée en utilisant le dd commande sur l'un des fichiers de l'ensemble de données ImageNet. Plus précisément, nous avons exécuté les commandes suivantes pour les données locales et réseau :
sync ; sudo /sbin/sysctl vm.drop_caches=3dd if=/a400-100g/netapp-ra/resnet/data/preprocessed_data/train.rec of=/dev/null bs=512k count=2048Results (average of 5 runs): Local storage: 1.7 GB/s Network storage: 1.5 GB/s.
Les deux valeurs sont similaires, ce qui démontre que le stockage réseau peut fournir des données à un débit similaire au stockage local.
Cas d'utilisation partagé : tâches multiples, indépendantes et simultanées
Ce test a simulé le cas d’utilisation attendu pour cette solution : formation d’IA multi-tâches et multi-utilisateurs. Chaque nœud a exécuté sa propre formation tout en utilisant le stockage réseau partagé. Les résultats sont affichés dans la figure suivante, qui montre que le cas de solution a fourni d’excellentes performances avec tous les travaux exécutés essentiellement à la même vitesse que les travaux individuels. Le débit total évolue linéairement avec le nombre de nœuds.
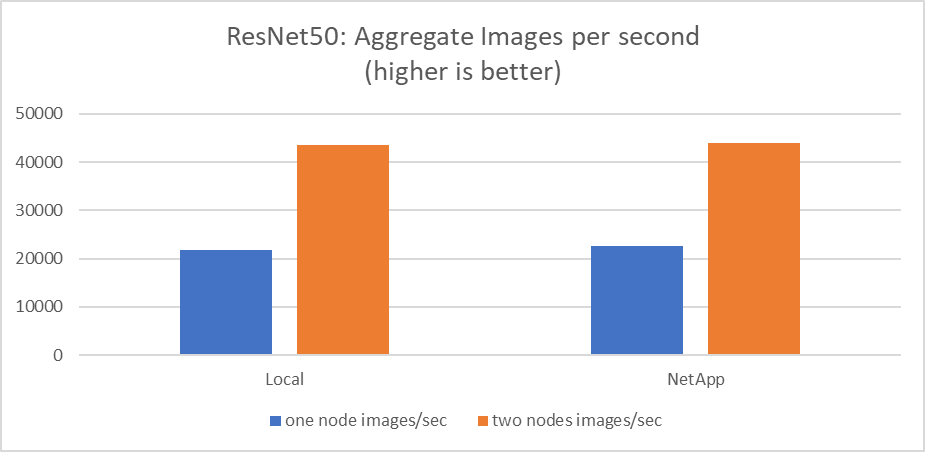
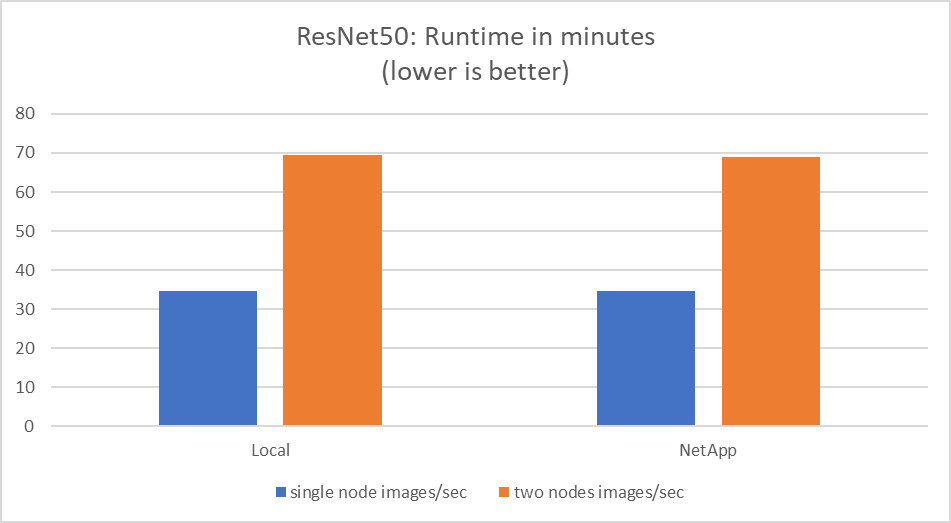
Ces graphiques présentent le temps d'exécution en minutes et les images agrégées par seconde pour les nœuds de calcul qui ont utilisé huit GPU de chaque serveur sur un réseau client 100 GbE, combinant à la fois le modèle de formation simultanée et le modèle de formation unique. La durée moyenne d’exécution du modèle de formation était de 35 minutes et 9 secondes. Les durées individuelles étaient de 34 minutes et 32 secondes, 36 minutes et 21 secondes, 34 minutes et 37 secondes, 35 minutes et 25 secondes et 34 minutes et 31 secondes. Le nombre moyen d'images par seconde pour le modèle d'entraînement était de 22 573, et le nombre d'images individuelles par seconde était de 21 764 ; 23 438 ; 22 556 ; 22 564 ; et 22 547.
Sur la base de notre validation, un modèle de formation indépendant avec un temps d'exécution de données NetApp était de 34 minutes et 54 secondes avec 22 231 images/s. Un modèle de formation indépendant avec une durée d'exécution de données locales (DAS) était de 34 minutes et 21 secondes avec 22 102 images/sec. Au cours de ces exécutions, l'utilisation moyenne du GPU était de 96 %, comme observé sur nvidia-smi. Notez que cette moyenne inclut la phase de test, pendant laquelle les GPU n'ont pas été utilisés, tandis que l'utilisation du CPU était de 40 % telle que mesurée par mpstat. Cela démontre que le débit de livraison des données est suffisant dans chaque cas.