

MLOps Open Source avec NetApp
 Suggérer des modifications
Suggérer des modifications
Mike Oglesby, NetApp Sufian Ahmad, NetApp Rick Huang, NetApp Mohan Acharya, NetApp
Les entreprises et organisations de toutes tailles et de nombreux secteurs se tournent vers l’intelligence artificielle (IA) pour résoudre des problèmes du monde réel, fournir des produits et services innovants et obtenir un avantage sur un marché de plus en plus concurrentiel. De nombreuses organisations se tournent vers des outils MLOps open source afin de suivre le rythme rapide de l’innovation dans le secteur. Ces outils open source offrent des capacités avancées et des fonctionnalités de pointe, mais ne tiennent souvent pas compte de la disponibilité et de la sécurité des données. Malheureusement, cela signifie que les scientifiques de données hautement qualifiés sont obligés de passer beaucoup de temps à attendre d’avoir accès aux données ou à attendre que des opérations rudimentaires liées aux données soient terminées. En associant des outils MLOps open source populaires à une infrastructure de données intelligente de NetApp, les organisations peuvent accélérer leurs pipelines de données, ce qui, à son tour, accélère leurs initiatives d'IA. Ils peuvent exploiter pleinement leurs données tout en garantissant qu’elles restent protégées et sécurisées. Cette solution démontre l’association des capacités de gestion des données NetApp avec plusieurs outils et frameworks open source populaires afin de relever ces défis.
La liste suivante met en évidence certaines fonctionnalités clés activées par cette solution :
-
Les utilisateurs peuvent rapidement provisionner de nouveaux volumes de données haute capacité et des espaces de travail de développement soutenus par un stockage NetApp hautes performances et évolutif.
-
Les utilisateurs peuvent cloner presque instantanément des volumes de données de grande capacité et des espaces de travail de développement afin de permettre l’expérimentation ou l’itération rapide.
-
Les utilisateurs peuvent enregistrer presque instantanément des instantanés de volumes de données de grande capacité et d'espaces de travail de développement à des fins de sauvegarde et/ou de traçabilité/base de référence.
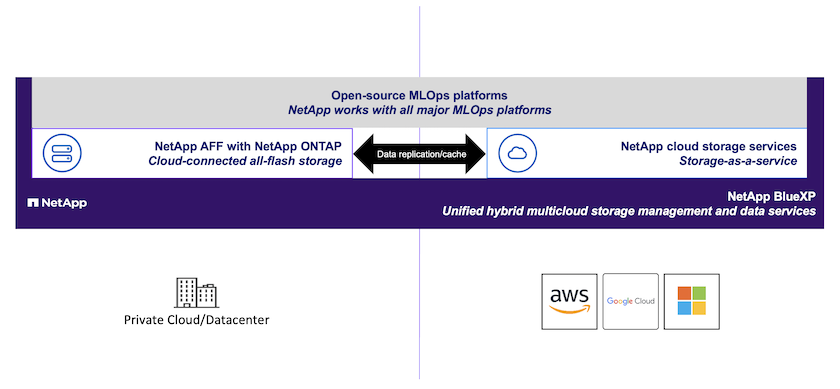
Un flux de travail MLOps typique intègre des espaces de travail de développement, prenant généralement la forme de"Carnets Jupyter" ; suivi des expériences ; pipelines de formation automatisés ; pipelines de données ; et inférence/déploiement. Cette solution met en évidence plusieurs outils et cadres différents qui peuvent être utilisés indépendamment ou conjointement pour traiter les différents aspects du flux de travail. Nous démontrons également l’association des capacités de gestion des données NetApp avec chacun de ces outils. Cette solution vise à offrir des blocs de construction à partir desquels une organisation peut construire un flux de travail MLOps personnalisé et spécifique à ses cas d'utilisation et à ses exigences.
Les outils/frameworks suivants sont couverts dans cette solution :
La liste suivante décrit les modèles courants de déploiement de ces outils indépendamment ou conjointement.
-
Déployer JupyterHub, MLflow et Apache Airflow conjointement - JupyterHub pour"Carnets Jupyter" MLflow pour le suivi des expériences et Apache Airflow pour la formation automatisée et les pipelines de données.
-
Déployer Kubeflow et Apache Airflow conjointement - Kubeflow pour"Carnets Jupyter" , suivi des expériences, pipelines de formation automatisés et inférence ; et Apache Airflow pour les pipelines de données.
-
Déployez Kubeflow en tant que solution de plateforme MLOps tout-en-un pour"Carnets Jupyter" , suivi des expériences, formation automatisée et pipelines de données, et inférence.