

Flux de travail pour le bursting développement/test vers le cloud
 Suggérer des modifications
Suggérer des modifications
L'agilité du cloud public, le délai de rentabilisation et les économies de coûts sont autant de propositions de valeur significatives pour les entreprises qui adoptent le cloud public pour le développement et les tests d'applications de base de données. Il n’existe pas de meilleur outil que SnapCenter pour faire de cela une réalité. SnapCenter peut non seulement protéger votre base de données de production sur site, mais peut également cloner rapidement une copie pour le développement d'applications ou les tests de code dans le cloud public tout en consommant très peu de stockage supplémentaire. Vous trouverez ci-dessous des détails sur les processus étape par étape pour utiliser cet outil.
Cloner une base de données Oracle pour le développement/test à partir d'une sauvegarde instantanée répliquée
-
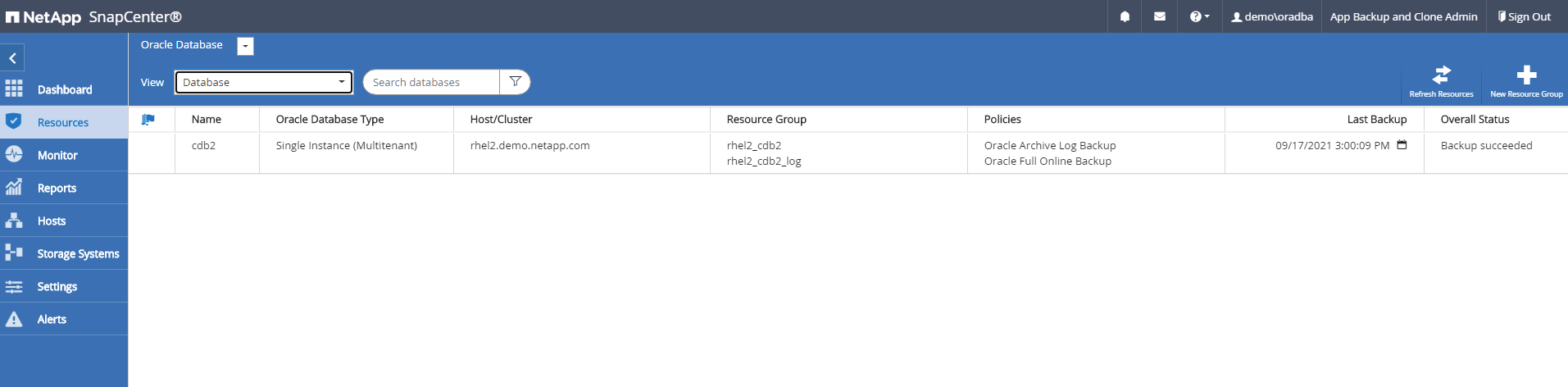
Connectez-vous à SnapCenter avec un ID utilisateur de gestion de base de données pour Oracle. Accédez à l’onglet Ressources, qui affiche les bases de données Oracle protégées par SnapCenter.
-
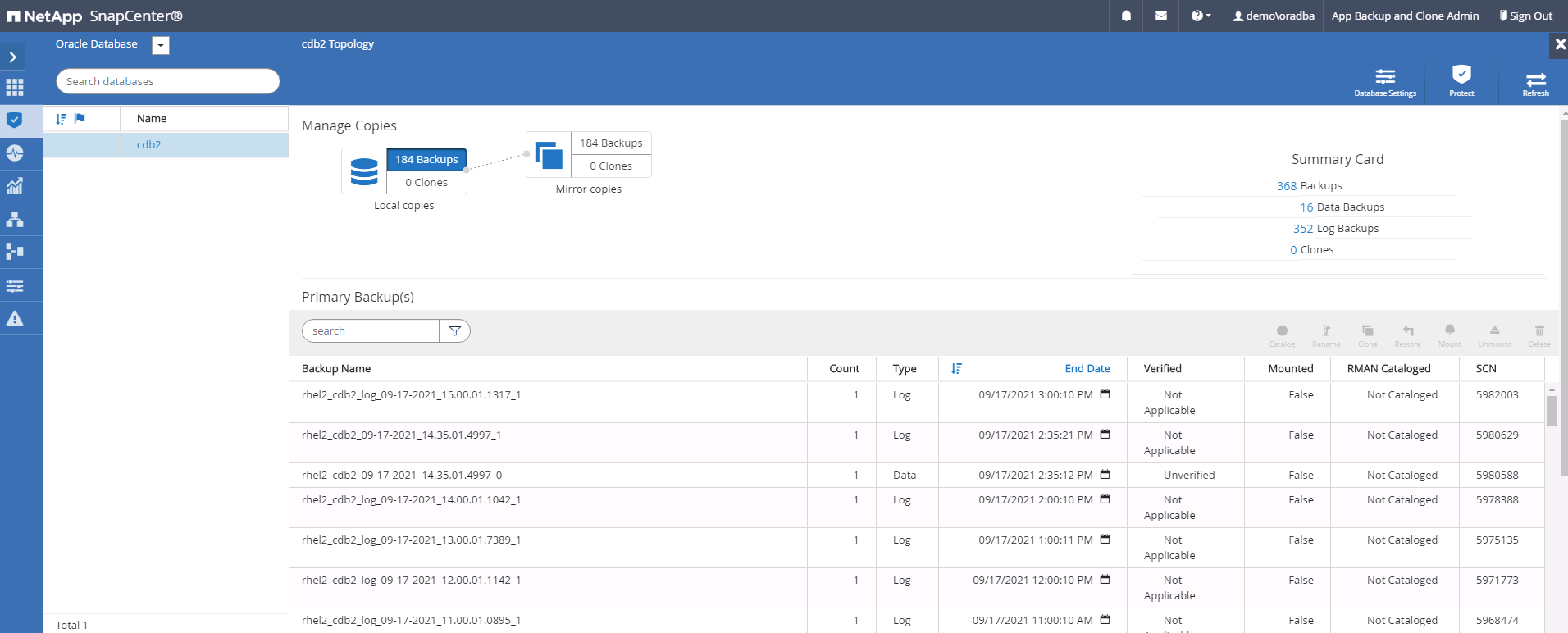
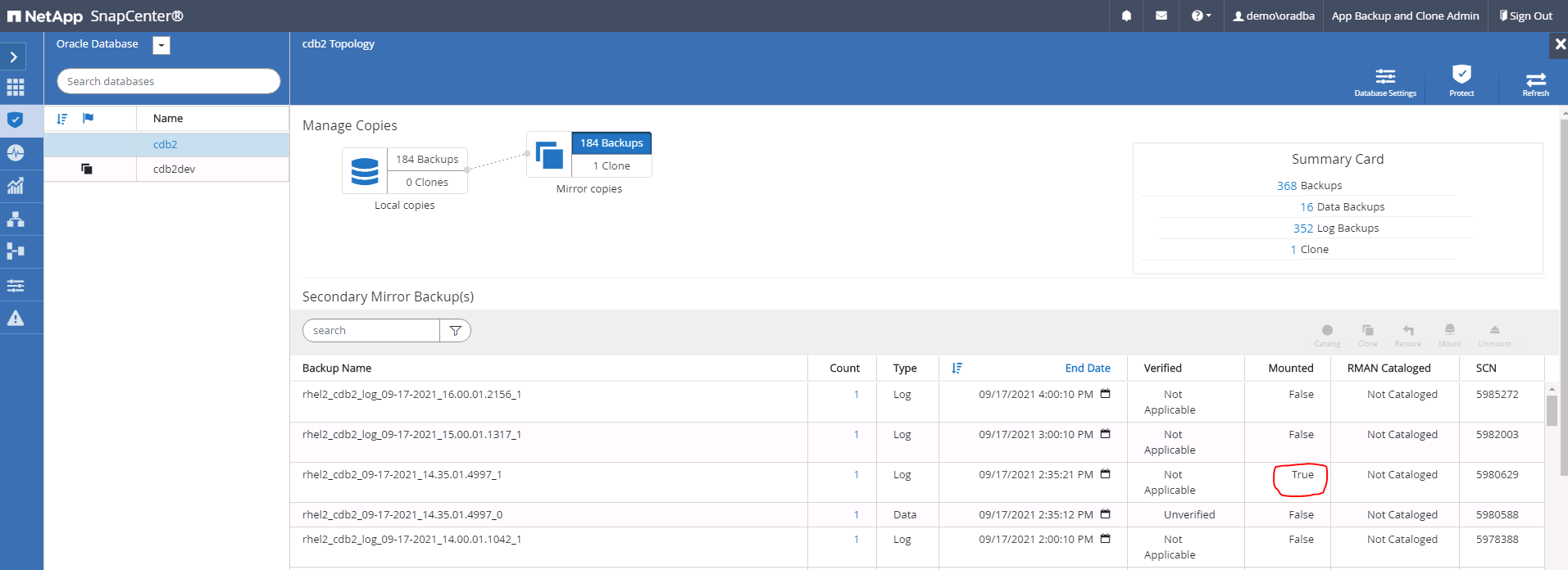
Cliquez sur le nom de la base de données locale prévue pour la topologie de sauvegarde et la vue détaillée. Si un emplacement répliqué secondaire est activé, il affiche les sauvegardes miroir liées.
-
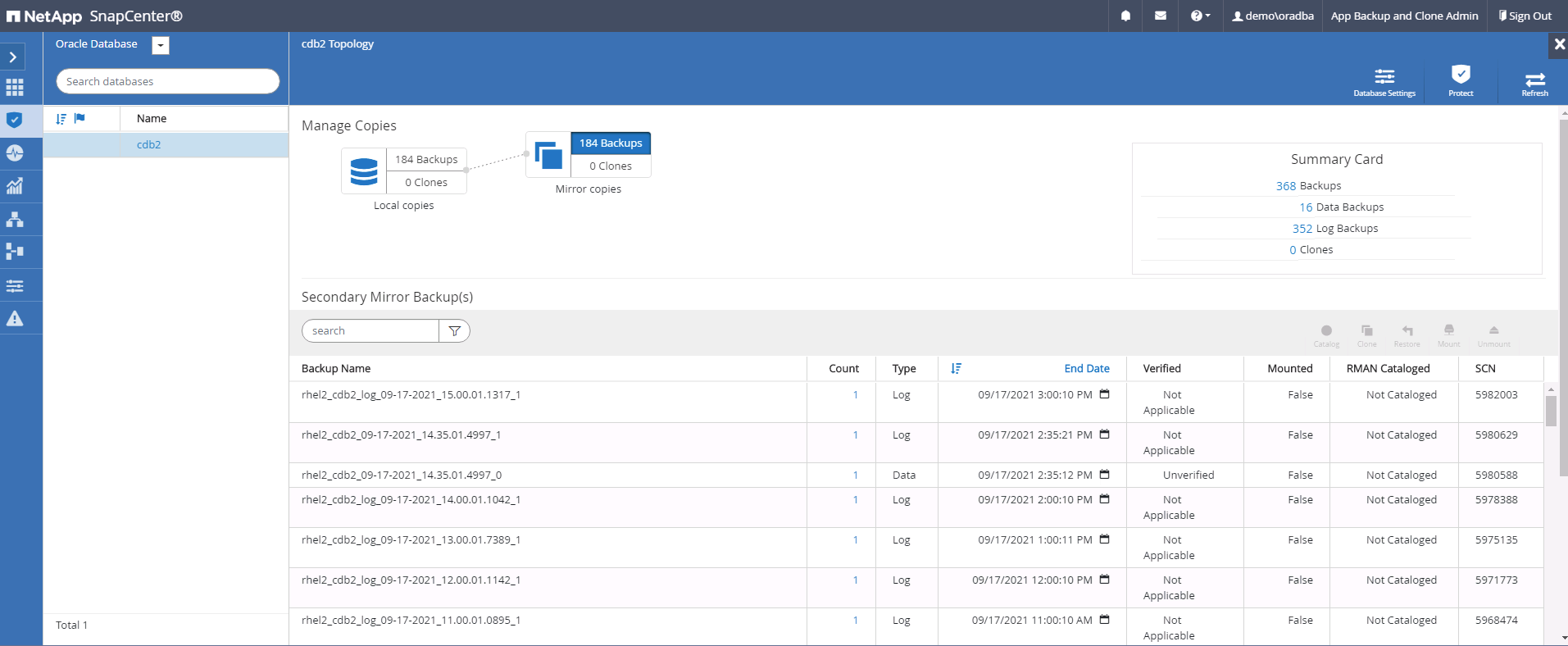
Basculez vers la vue des sauvegardes en miroir en cliquant sur les sauvegardes en miroir. La ou les sauvegardes miroir secondaires sont alors affichées.
-
Choisissez une copie de sauvegarde de base de données secondaire en miroir à cloner et déterminez un point de récupération soit par heure et numéro de modification du système, soit par SCN. En règle générale, le point de récupération doit suivre le temps de sauvegarde complet de la base de données ou le SCN à cloner. Une fois le point de récupération déterminé, la sauvegarde du fichier journal requise doit être montée pour la récupération. La sauvegarde du fichier journal doit être montée sur le serveur de base de données cible sur lequel la base de données clonée doit être hébergée.
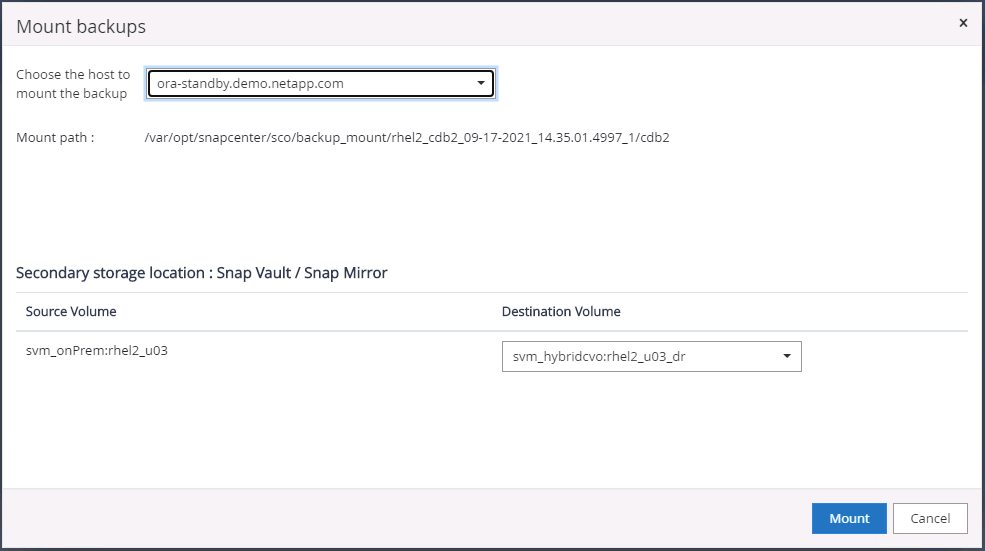

Si l'élagage des journaux est activé et que le point de récupération est étendu au-delà du dernier élagage des journaux, plusieurs sauvegardes de journaux d'archive peuvent devoir être montées. -
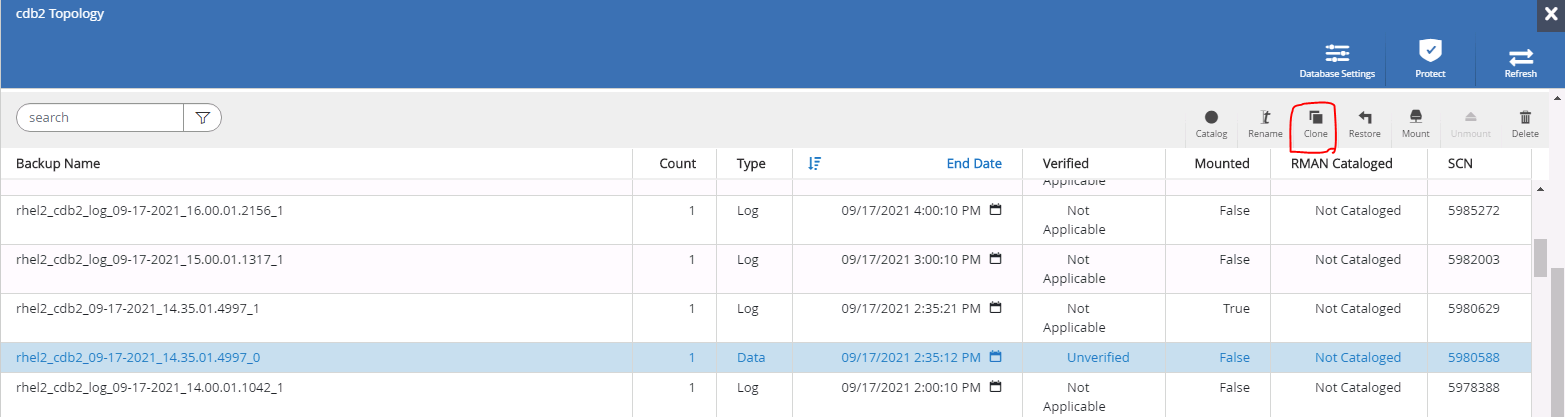
Mettez en surbrillance la copie de sauvegarde complète de la base de données à cloner, puis cliquez sur le bouton Cloner pour démarrer le flux de travail de clonage de la base de données.
-
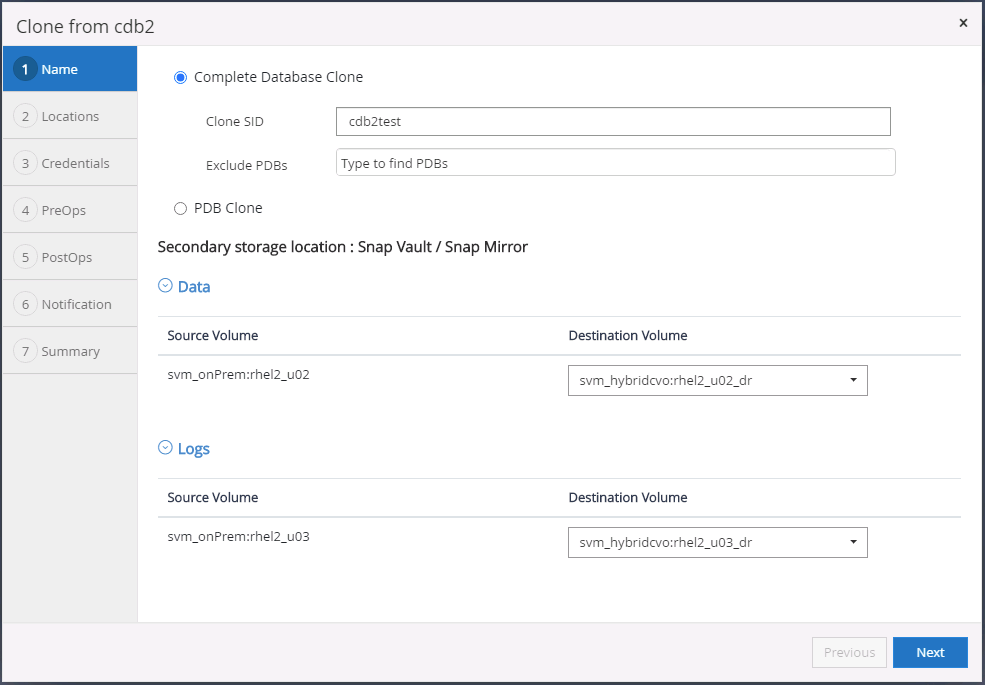
Choisissez un SID de base de données clone approprié pour une base de données de conteneur complète ou un clone CDB.
-
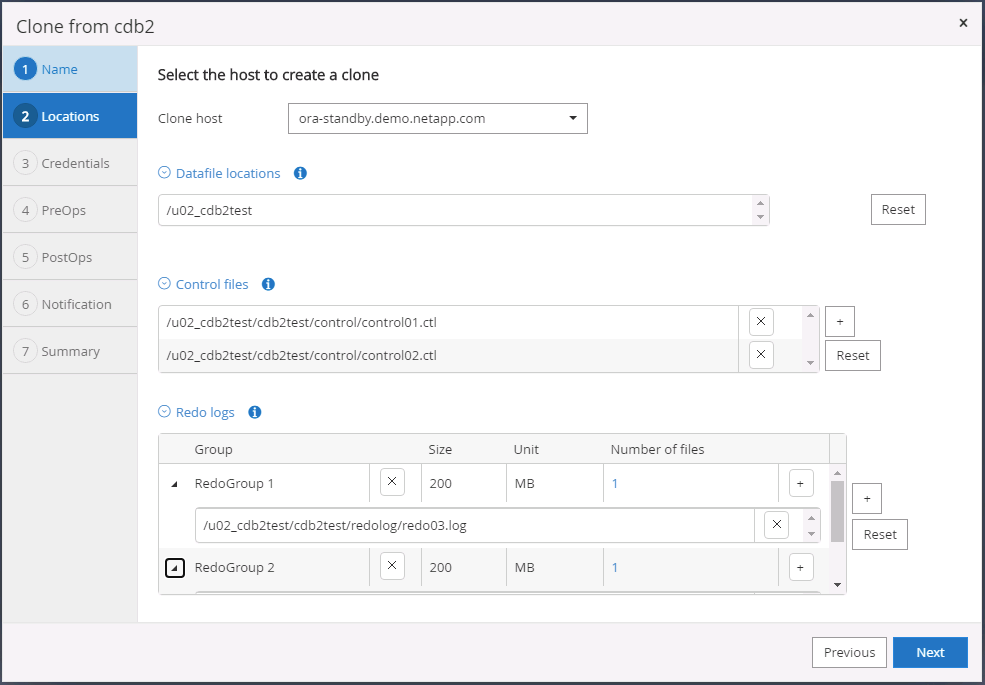
Sélectionnez l'hôte de clonage cible dans le cloud, et les répertoires de fichiers de données, de fichiers de contrôle et de journaux de rétablissement sont créés par le flux de travail de clonage.
-
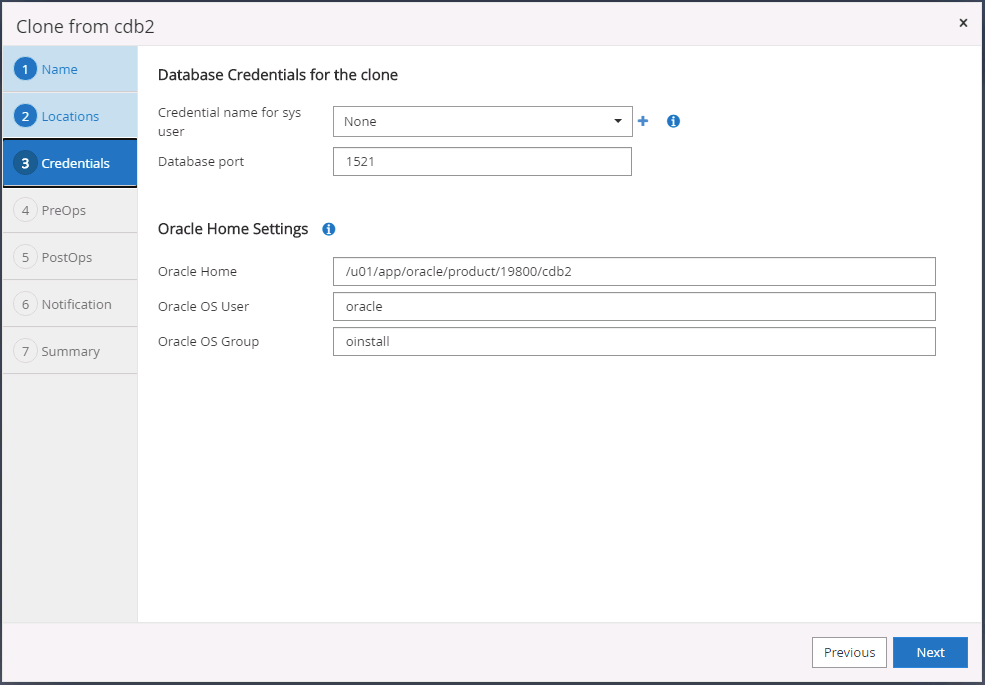
Le nom d'identification None est utilisé pour l'authentification basée sur le système d'exploitation, ce qui rend le port de base de données non pertinent. Renseignez les champs Oracle Home, Oracle OS User et Oracle OS Group appropriés tels que configurés dans le serveur de base de données clone cible.
-
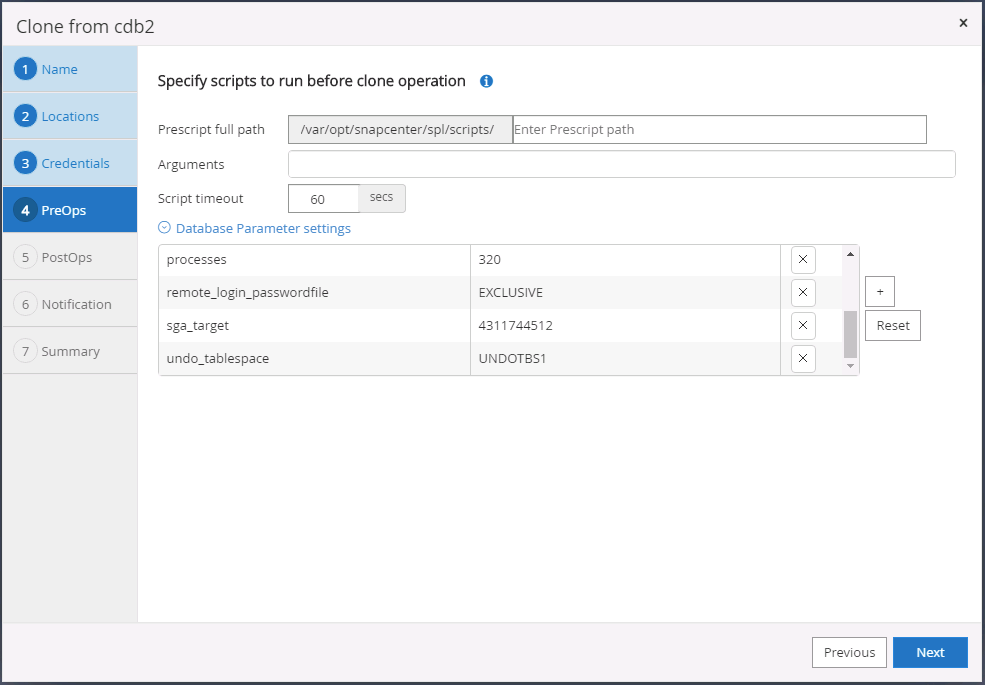
Spécifiez les scripts à exécuter avant l'opération de clonage. Plus important encore, le paramètre d’instance de base de données peut être ajusté ou défini ici.
-
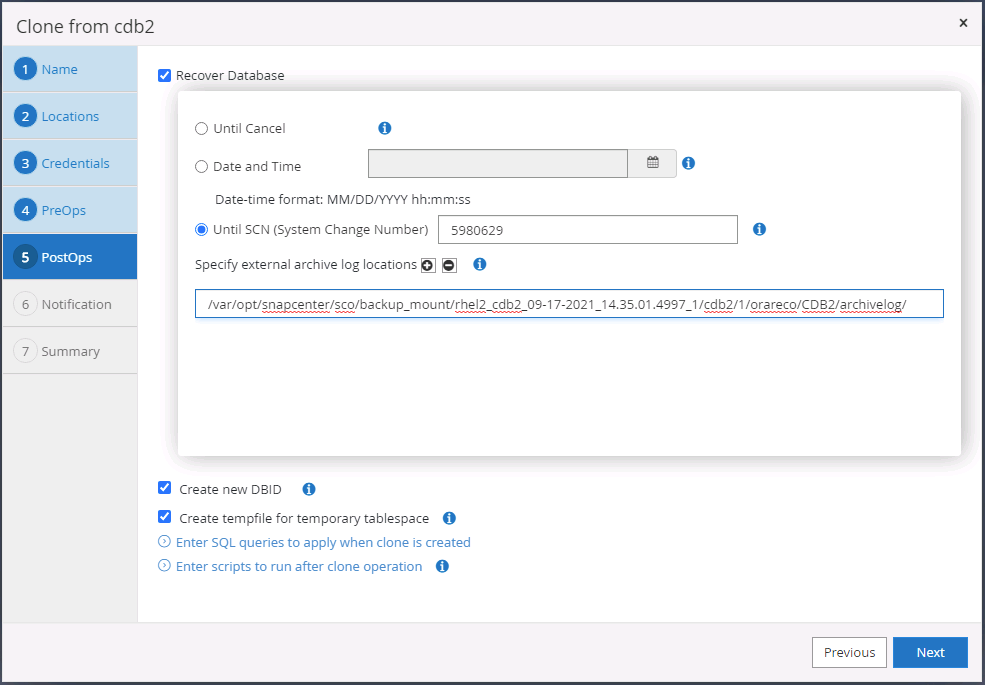
Spécifiez le point de récupération soit par la date et l'heure, soit par le SCN. Jusqu'à ce que Cancel récupère la base de données jusqu'aux journaux d'archives disponibles. Spécifiez l’emplacement du journal d’archive externe à partir de l’hôte cible sur lequel le volume du journal d’archive est monté. Si le propriétaire Oracle du serveur cible est différent du serveur de production local, vérifiez que le répertoire du journal d'archive est lisible par le propriétaire Oracle du serveur cible.

-
Configurez le serveur SMTP pour la notification par e-mail si vous le souhaitez.
-
Résumé du clone.
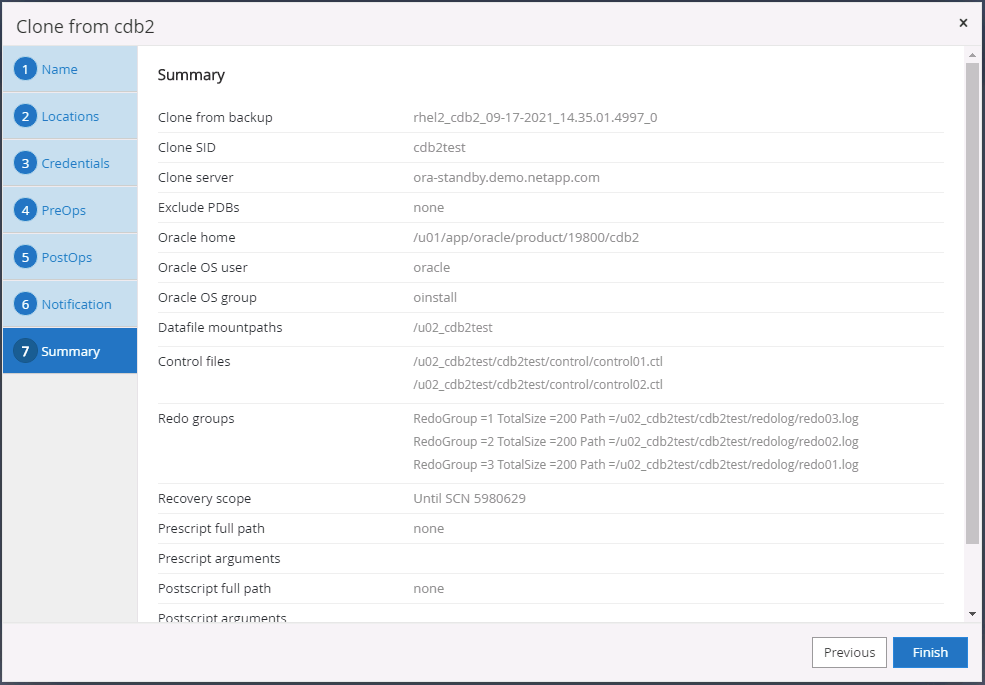
-
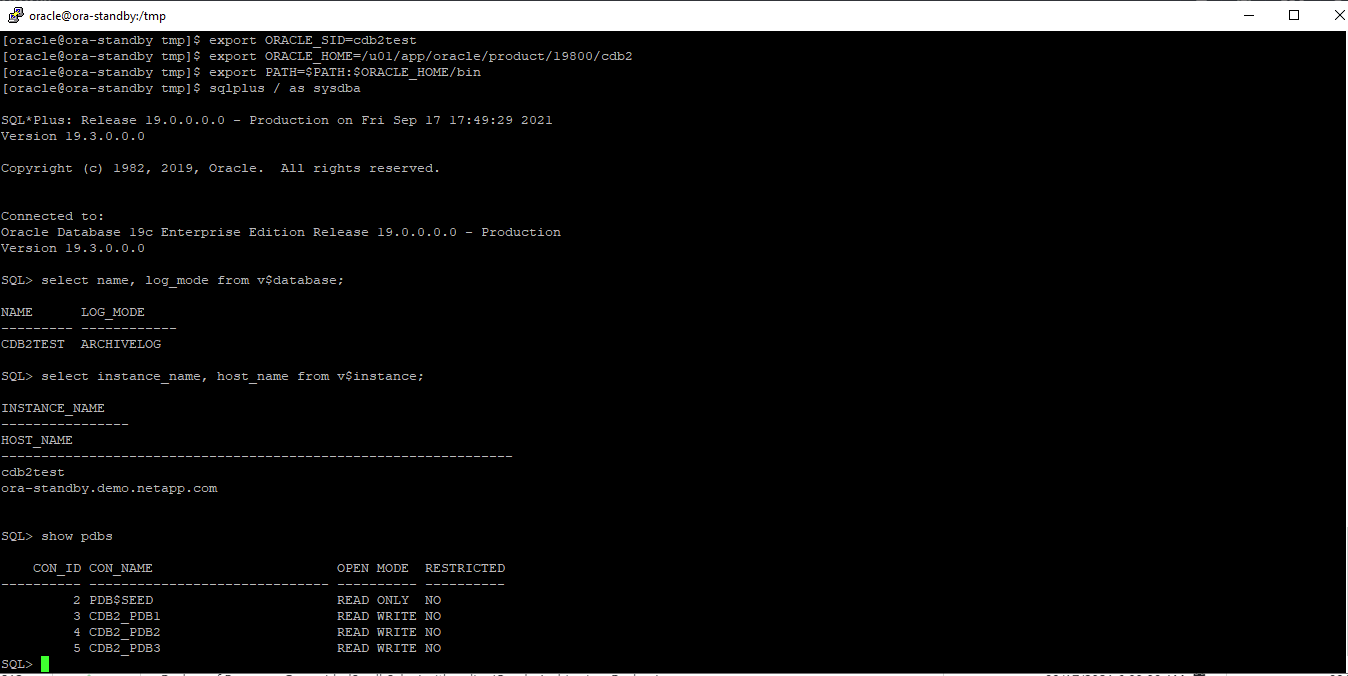
Vous devez valider après le clonage pour vous assurer que la base de données clonée est opérationnelle. Certaines tâches supplémentaires, telles que le démarrage de l'écouteur ou la désactivation du mode d'archivage du journal de la base de données, peuvent être effectuées sur la base de données dev/test.
Cloner une base de données SQL pour le développement/test à partir d'une sauvegarde Snapshot répliquée
-
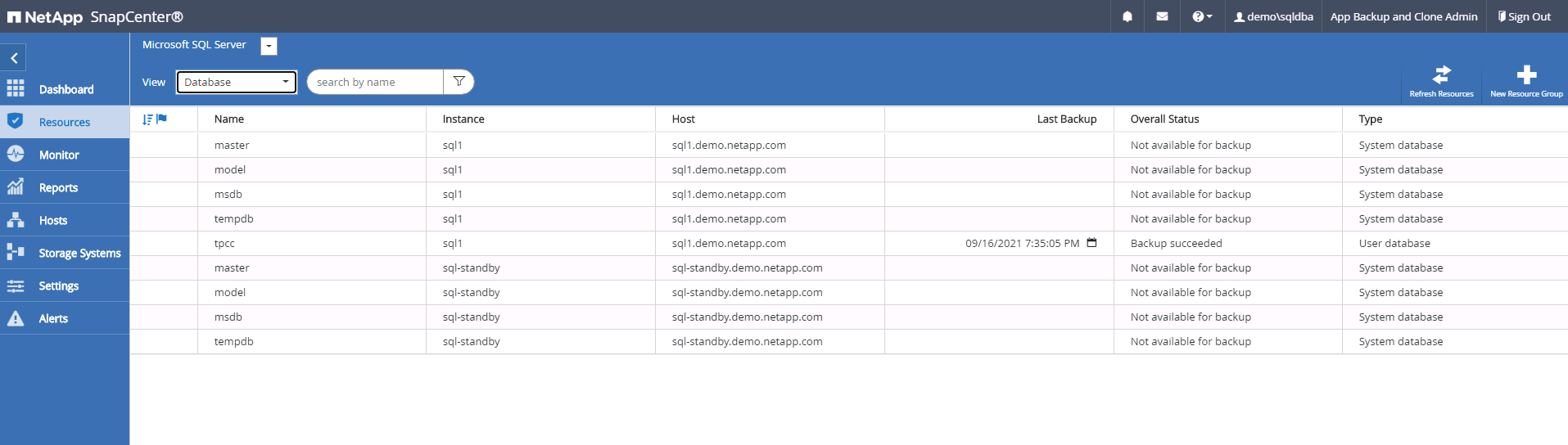
Connectez-vous à SnapCenter avec un ID utilisateur de gestion de base de données pour SQL Server. Accédez à l’onglet Ressources, qui affiche les bases de données utilisateur SQL Server protégées par SnapCenter et une instance SQL de secours cible dans le cloud public.
-
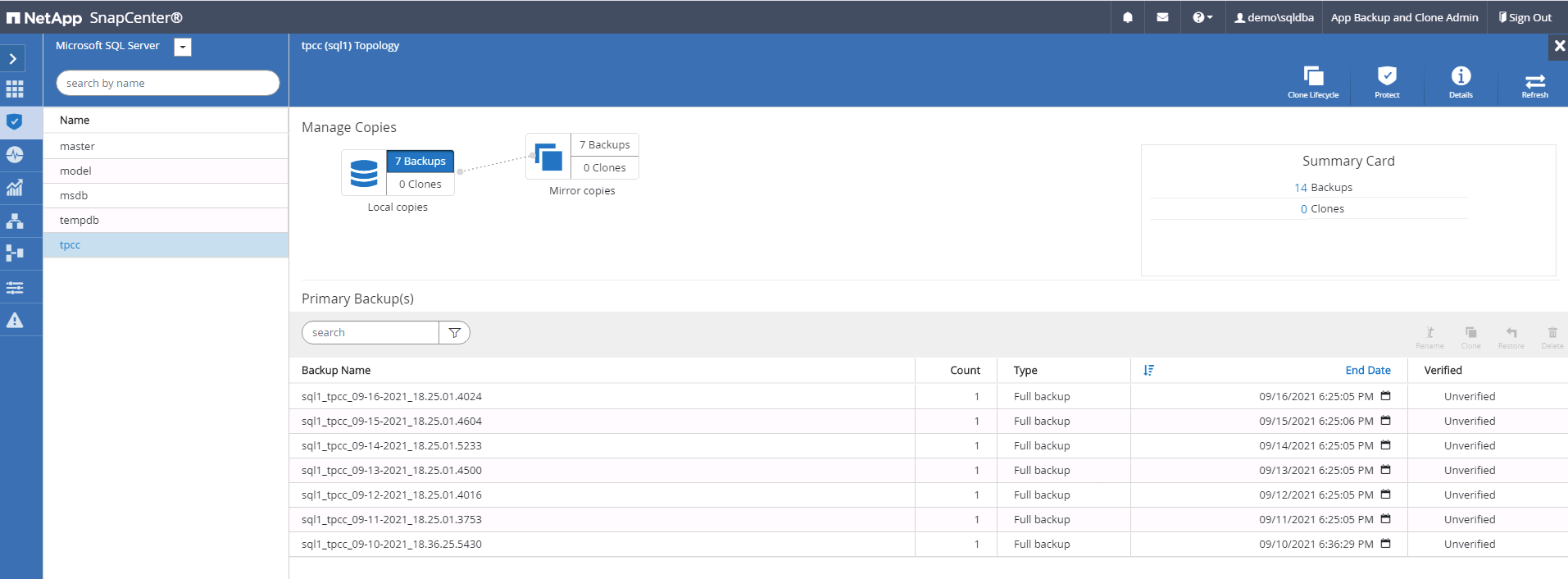
Cliquez sur le nom de la base de données utilisateur SQL Server sur site prévue pour la topologie des sauvegardes et la vue détaillée. Si un emplacement répliqué secondaire est activé, il affiche les sauvegardes miroir liées.
-
Basculez vers la vue Sauvegardes en miroir en cliquant sur Sauvegardes en miroir. Les sauvegardes miroir secondaires sont alors affichées. Étant donné que SnapCenter sauvegarde le journal des transactions SQL Server sur un lecteur dédié pour la récupération, seules les sauvegardes complètes de la base de données sont affichées ici.
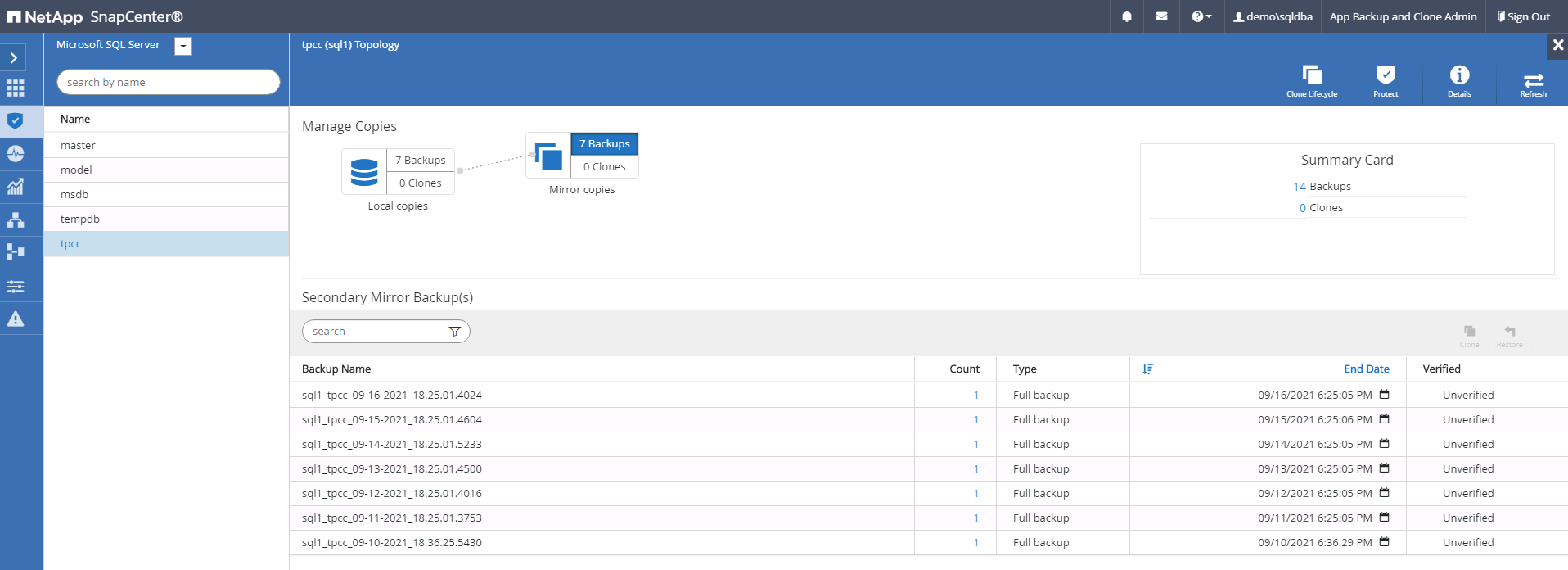
-
Choisissez une copie de sauvegarde, puis cliquez sur le bouton Cloner pour lancer le flux de travail Cloner à partir de la sauvegarde.
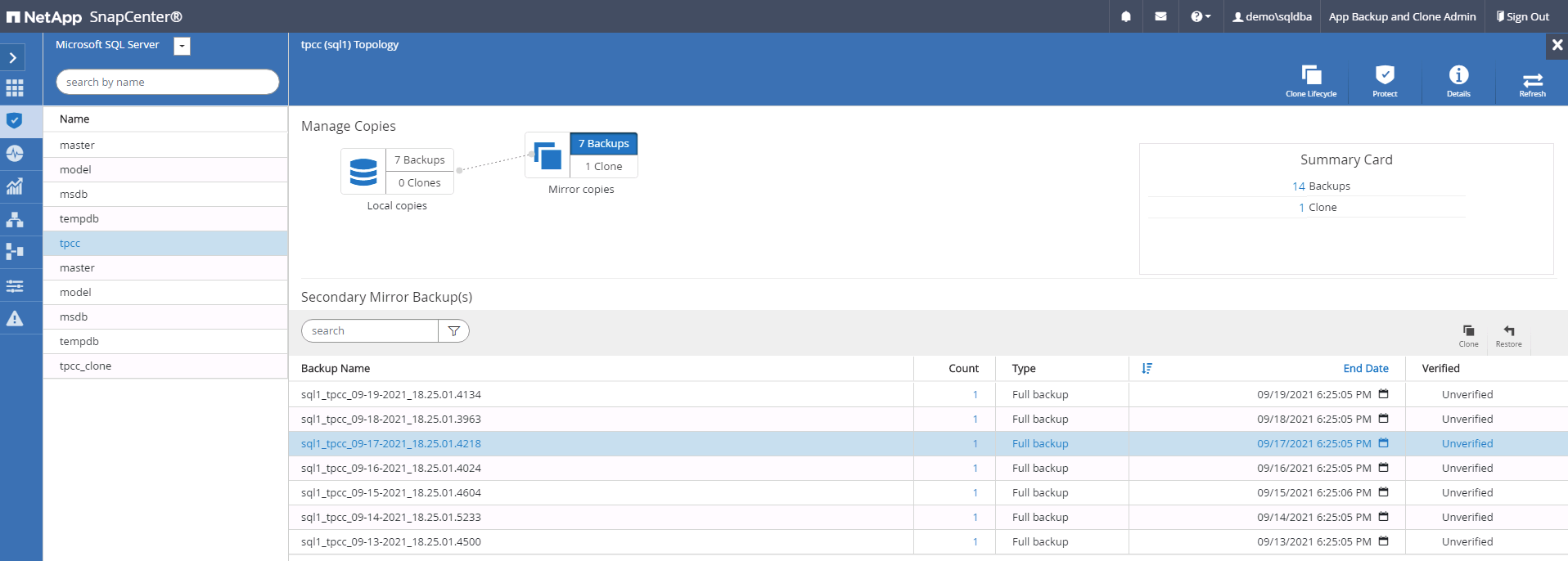
-
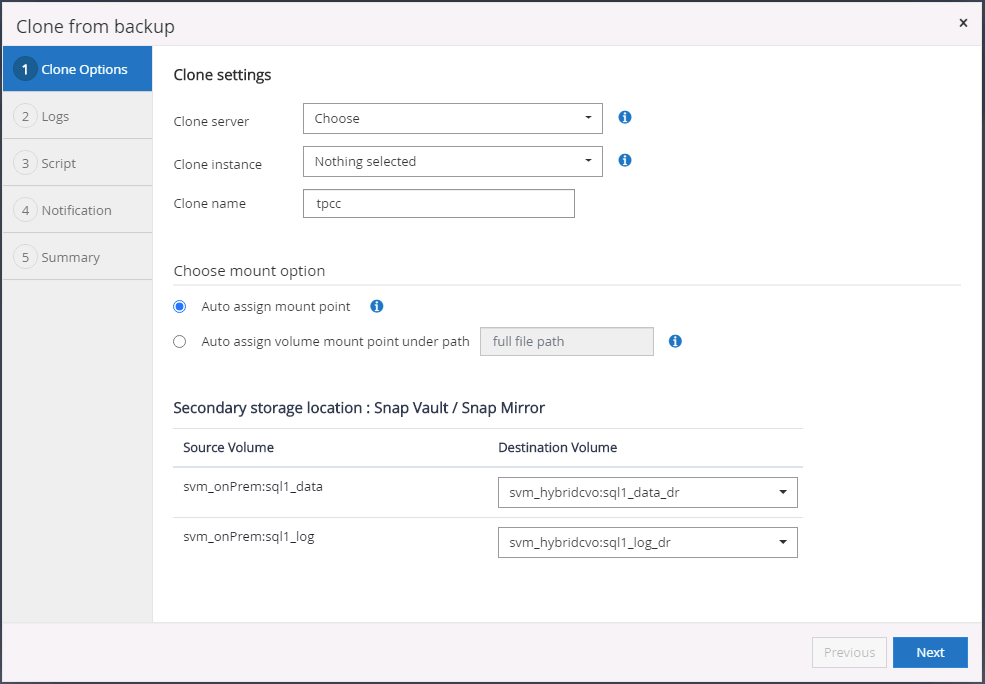
Sélectionnez un serveur cloud comme serveur clone cible, le nom de l'instance de clonage et le nom de la base de données de clonage. Choisissez soit un point de montage à attribution automatique, soit un chemin de point de montage défini par l'utilisateur.
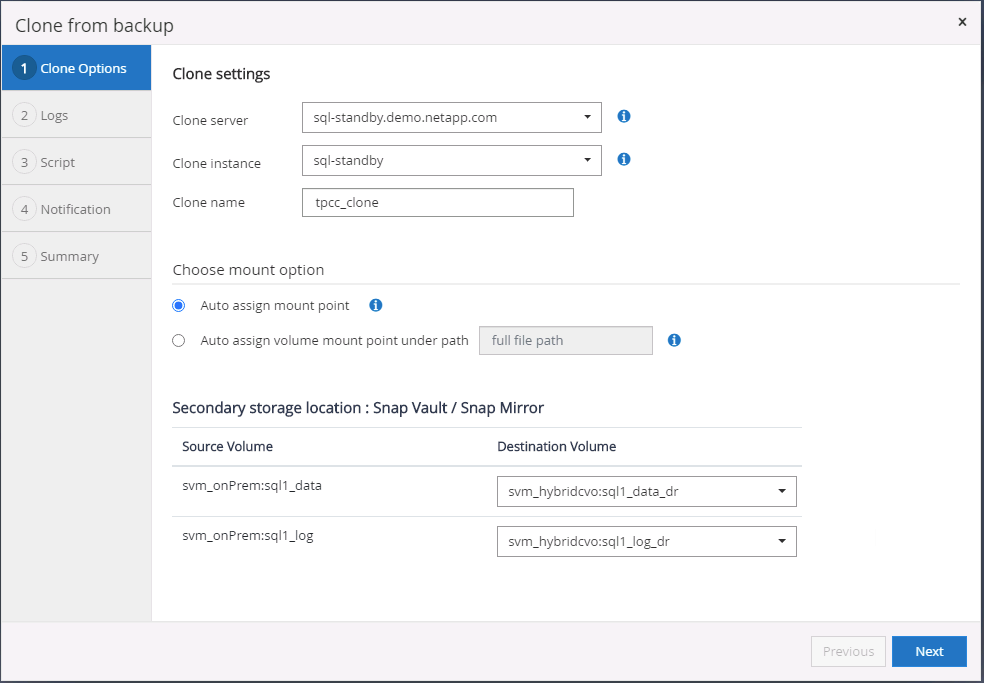
-
Déterminez un point de récupération soit par une heure de sauvegarde du journal, soit par une date et une heure spécifiques.
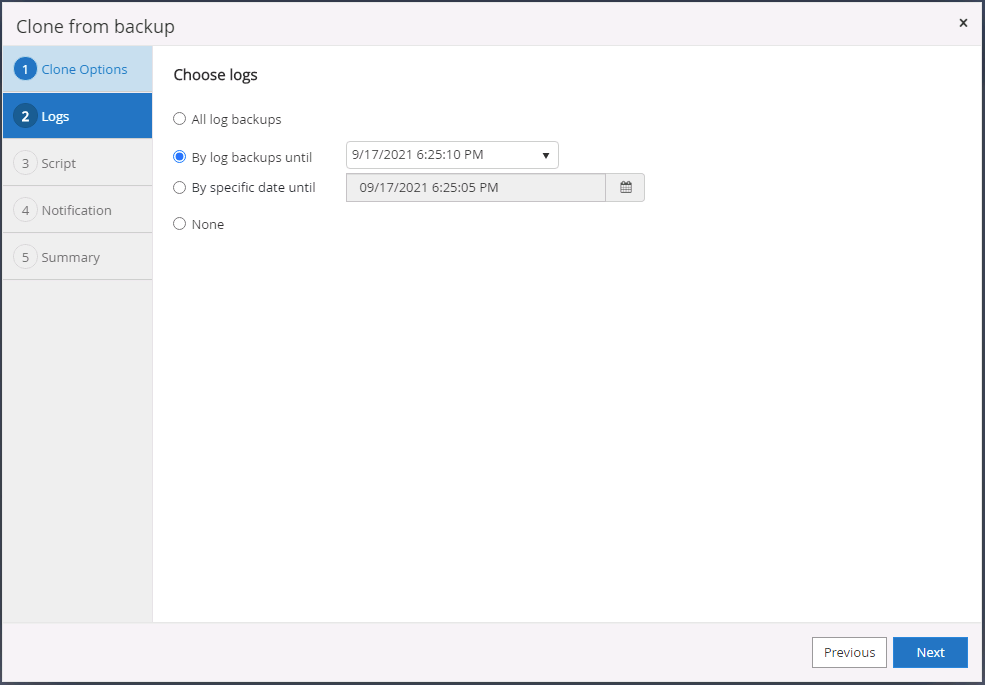
-
Spécifiez les scripts facultatifs à exécuter avant et après l’opération de clonage.
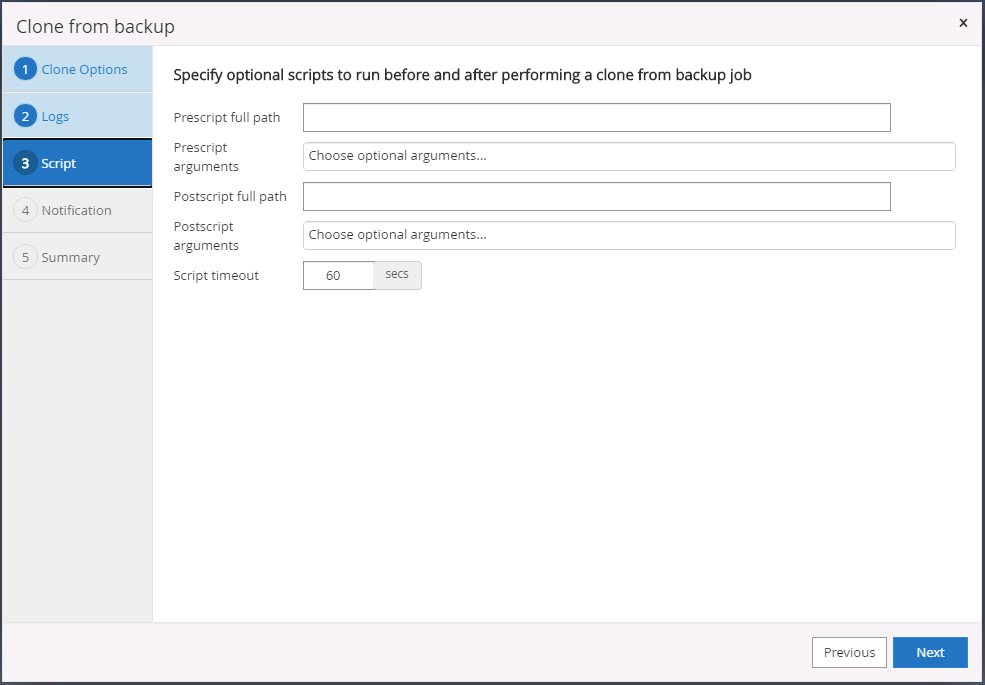
-
Configurez un serveur SMTP si une notification par e-mail est souhaitée.
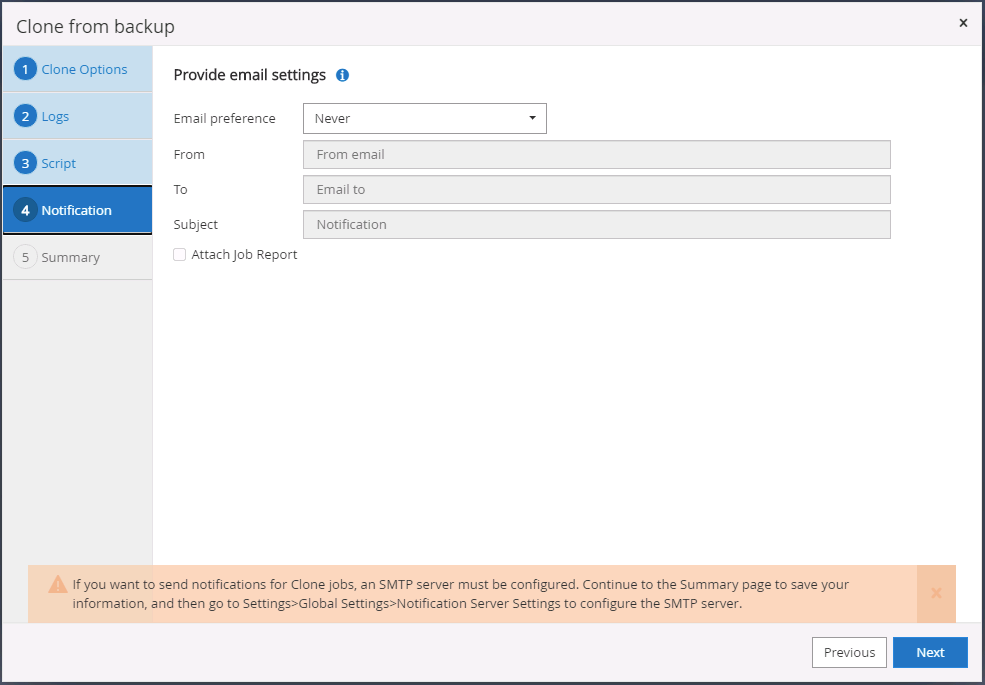
-
Résumé du clone.
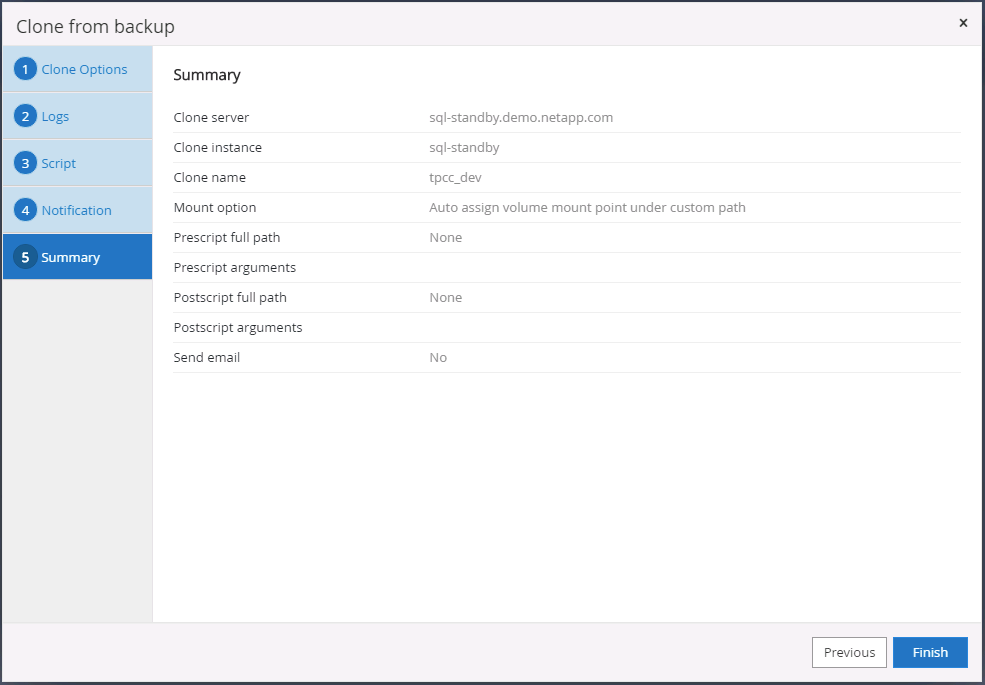
-
Surveillez l’état du travail et validez que la base de données utilisateur prévue a été attachée à une instance SQL cible dans le serveur de clonage cloud.
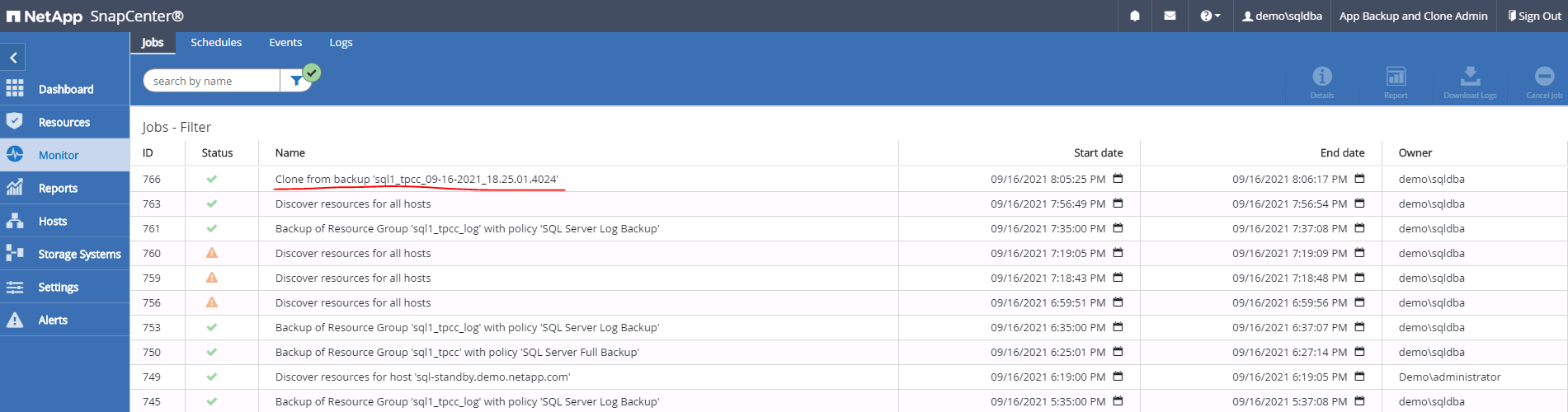
Configuration post-clonage
-
Une base de données de production Oracle sur site s'exécute généralement en mode d'archivage des journaux. Ce mode n'est pas nécessaire pour une base de données de développement ou de test. Pour désactiver le mode d'archivage du journal, connectez-vous à la base de données Oracle en tant que sysdba, exécutez une commande de changement de mode de journal et démarrez la base de données pour y accéder.
-
Configurez un écouteur Oracle ou enregistrez la base de données nouvellement clonée avec un écouteur existant pour l'accès utilisateur.
-
Pour SQL Server, modifiez le mode de journalisation de Complet à Facile afin que le fichier journal de développement/test SQL Server puisse être facilement réduit lorsqu'il remplit le volume du journal.
Actualiser la base de données clonée
-
Supprimez les bases de données clonées et nettoyez l’environnement du serveur de base de données cloud. Suivez ensuite les procédures précédentes pour cloner une nouvelle base de données avec de nouvelles données. Il ne faut que quelques minutes pour cloner une nouvelle base de données.
-
Arrêtez la base de données clonée, exécutez une commande d'actualisation de clone à l'aide de la CLI. Consultez la documentation SnapCenter suivante pour plus de détails :"Rafraîchir un clone" .
Où aller chercher de l’aide ?
Si vous avez besoin d'aide avec cette solution et ces cas d'utilisation, rejoignez le"Canal Slack d'assistance de la communauté NetApp Solution Automation" et recherchez le canal solution-automatisation pour poster vos questions ou demandes de renseignements.