

Configurer les groupes de disponibilité Always On de SQL Server avec Google Cloud NetApp Volumes
 Suggérer des modifications
Suggérer des modifications
Configurez des groupes de disponibilité Always On pour SQL Server sur des instances Google Compute Engine au sein d'un même sous-réseau à l'aide des volumes Google Cloud NetApp Volumes iSCSI stockage bloc. Découvrez comment configurer des instances de calcul, configurer des volumes NetApp, établir un cluster de basculement et déployer des groupes de disponibilité pour une haute disponibilité et une reprise après sinistre.
Prérequis
Avant de poursuivre, complétez les étapes préalables de configuration dans la documentation Google Cloud :
Avant de commencer
Assurez-vous d'avoir rempli les exigences suivantes :
-
Projet Google Cloud avec autorisations d'administrateur pour le calcul, le réseau, IAM et le stockage
-
Réseau VPC avec sous-réseau pour une configuration de région
-
Configuration d'Active Directory et DNS disponible dans une région
-
Règles de pare-feu configurées pour autoriser les ports requis
-
Familiarité avec les groupes de disponibilité Always On de SQL Server et le clustering de basculement

|
Les nouveaux utilisateurs de Google Cloud pourraient être éligibles à "crédits d'essai gratuits". |
Objectifs
La configuration du groupe de disponibilité SQL Server Always On comprend les tâches de haut niveau suivantes :
-
Configurer les instances Compute Engine et les volumes de stockage NetApp
-
Configurer SQL Server sur les deux nœuds
-
Configurer un cluster de basculement Windows Server
-
Configurer le quorum du cluster avec un témoin de partage de fichiers
-
Configurer les groupes de disponibilité SQL Server
-
Configurer le Distributed Network Name (DNN) pour l'accès au listener
Considérations relatives aux coûts
Ce tutoriel utilise des composants payants de Google Cloud, notamment "instances de Compute Engine" et "Google Cloud NetApp Volumes" stockage.
Utilisez "Calculateur de prix" pour générer une estimation des coûts en fonction de vos besoins en calcul et en stockage. La configuration d'exemple utilise des instances de calcul N4-SKU et un stockage de niveau de service Flex NetApp pour la configuration du groupe de disponibilité Always On de SQL Server.
Configurer les comptes de domaine
Configurez deux comptes dans Active Directory : un compte d’installation (votre compte admin) et un compte de service pour les deux SQL Server VMs.
Par exemple, utilisez les valeurs du tableau suivant pour les comptes :
|
|
Cet exemple utilise cvsdemo comme nom de domaine. Remplacez cvsdemo par votre nom de domaine tout au long de cette procédure.
|
| Compte | VM | Nom de domaine complet | Description |
|---|---|---|---|
<your account> |
Les deux (sqlnode1 et sqlnode2) |
cvsdemo\DomainAdmin |
Compte administrateur pour se connecter à l'une ou l'autre des machines virtuelles et configurer le cluster et le groupe de disponibilité |
sqlsvc |
Les deux (sqlnode1 et sqlnode2) |
cvsdemo\sqlsvc |
Compte de service pour SQL Server et SQL Server Agent sur les deux SQL Server VM |
Créer des machines virtuelles Compute Engine pour SQL Server
Créez deux instances de machine virtuelle Google Compute Engine avec SQL Server 2022 Enterprise préinstallé sur Windows Server 2025 pour héberger les réplicas du groupe de disponibilité.
-
Dans la console Google Cloud, accédez à la "Créer une instance" page.
Veuillez vous référer au "Documentation Google Cloud" pour plus d'informations.
-
Pour Nom, saisissez
sqlnode1. -
Dans la section Configuration de la machine :
-
Sélectionnez General Purpose
-
Dans la liste Series, sélectionnez N4
-
Dans la liste Type de machine, sélectionnez n4-highmem-8 (8 vCPU, 64 GB memory)
-
-
Sélectionnez la région où vous avez créé votre VPC (par exemple, region=us-west1, zone=us-west1-a).
-
Dans la section Disque de démarrage, cliquez sur Modifier:
-
Dans l'onglet Images publiques, dans la liste Système d'exploitation, sélectionnez SQL Server on Windows Server.
-
Dans la liste Version, sélectionnez SQL Server 2022 Enterprise on Windows Server 2025 Datacenter.
-
Dans la liste Type de disque de démarrage, sélectionnez Hyperdisk Balanced.
-
Dans le champ Taille (Go), saisissez 50 Go.
-
Cliquez sur Select pour enregistrer la configuration du disque de démarrage.
-
-
Dans la section Réseau, modifiez l'interface réseau pour sélectionner le VPC et le sous-réseau appropriés. Si vous n'avez qu'un seul réseau VPC, il sera sélectionné par défaut.
-
Sur la carte d'interface réseau, sélectionnez gVNIC.
-
Pour "Niveau de service réseau", sélectionnez Premium pour les charges de travail critiques ou Standard pour optimiser les coûts.
-
-
Cliquez sur Créer pour créer la VM.
-
Répétez ces étapes pour créer
sqlnode2.
Joindre les serveurs au domaine
Après avoir créé les machines virtuelles, joignez-les au domaine Active Directory et installez les fonctionnalités Windows requises pour le clustering de basculement et la connectivité iSCSI.
-
Connectez-vous à distance à la machine virtuelle avec le compte administrateur local.
-
Dans le Gestionnaire de serveur, sélectionnez Local Server.
-
Sélectionnez le lien WORKGROUP.
-
Dans la section Nom de l'ordinateur, sélectionnez Modifier.
-
Sélectionnez la case à cocher Domaine et saisissez votre domaine (par exemple,
cvsdemo.internal) dans la zone de texte. -
Cliquez sur OK.
-
Dans la boîte de dialogue Sécurité Windows, spécifiez les informations d'identification du compte d'administrateur de domaine par défaut (par exemple,
cvsdemo\DomainAdmin). -
Lorsque vous voyez le message « Welcome to the cvsdemo.internal domain », cliquez sur OK.
-
Cliquez sur Fermer, puis sélectionnez Redémarrer maintenant dans la boîte de dialogue.
-
Après le redémarrage du serveur, ajoutez le
sqlsvccompte au groupe Administrateurs.
|
|
Votre instance SQL s'exécutera en utilisant le compte sqlsvc, qui est requis pour la configuration du clustering et du basculement. |
Installer les fonctionnalités Windows requises
Installez le clustering de basculement et MPIO sur les deux machines virtuelles SQL Server à l'aide du Gestionnaire de serveur ou de PowerShell.
-
Dans le Gestionnaire de serveur, sélectionnez Gérer > Ajouter des rôles et des fonctionnalités.
-
Sélectionnez Role-based or feature-based installation et cliquez sur Suivant.
-
Sélectionnez votre serveur et cliquez sur Next.
-
Sur la page Fonctionnalités, sélectionnez Cluster de basculement et Multipath I/O.
-
Cliquez sur Ajouter des fonctionnalités lorsque vous êtes invité à inclure des outils de gestion.
-
Terminez l'assistant et redémarrez si vous y êtes invité.
Exécutez PowerShell en tant qu'administrateur et exécutez les commandes suivantes :
# Install Failover Clustering and tools
Install-WindowsFeature Failover-Clustering, RSAT-Clustering-PowerShell, RSAT-Clustering-CmdInterface -IncludeAllSubFeature -IncludeManagementTools
# Install/enable MPIO
Install-WindowsFeature -Name Multipath-IO
Enable-MSDSMAutomaticClaim -BusType "iSCSI"
# Install .NET and other SQL prerequisites (if not already installed)
Install-WindowsFeature NET-Framework-45-Core, NET-Framework-45-Features
Install-WindowsFeature RSAT-AD-PowerShellObtenir les noms des initiateurs iSCSI
Obtenez le nom qualifié iSCSI (IQN) pour chaque machine virtuelle SQL Server à inclure dans le groupe d'hôtes en utilisant soit l'interface graphique de l'initiateur iSCSI, soit PowerShell.
-
Appuyez sur Win+R ou utilisez la barre de recherche Windows pour ouvrir
iscsicpl. -
Dans la boîte de dialogue Propriétés de l’initiateur iSCSI, allez à l’onglet Configuration.
-
Copiez la valeur Initiator Name et incluez-la dans le groupe hôte.
Exemple:
iqn.1991-05.com.microsoft:sqlnode1.cvsdemo.internal
Exécutez la commande suivante dans PowerShell :
Get-InitiatorPort | Select-Object NodeAddressCréer des volumes de stockage bloc NetApp
Créez des volumes de stockage bloc iSCSI à l'aide de Google Cloud NetApp Volumes pour fournir un stockage partagé haute performance aux bases de données SQL Server. Ce processus comprend la création d'un groupe d'hôtes, d'un pool de stockage et de volumes individuels pour les données, les journaux, les volumes temporaires et les sauvegardes.
Créer le groupe hôte
-
Créez un groupe d'hôtes contenant les initiateurs iSCSI des deux nœuds SQL.
gcloud beta netapp host-groups create HOST_GROUP_NAME \ --location=LOCATION \ --type=ISCSI_INITIATOR \ --hosts=HOSTS \ --os-type=OS_TYPE \ --description=DESCRIPTIONPour plus de détails, consultez la documentation "Créer un groupe hôte".
-
Remplacez les valeurs suivantes :
-
HOST_GROUP_NAME: Nom du groupe hôte (par exemple,demosql) -
LOCATION: Région (par exemple,us-west1) -
HOSTS: Liste des IQN séparés par des virgules provenant de sqlnode1 et sqlnode2Exemple :
iqn.1991-05.com.microsoft:sqlnode1.cvsdemo.internal,iqn.1991-05.com.microsoft:sqlnode2.cvsdemo.internal -
OS_TYPE: Type de système d'exploitation (par exemple,WINDOWS) -
DESCRIPTION: Description facultative du groupe hôte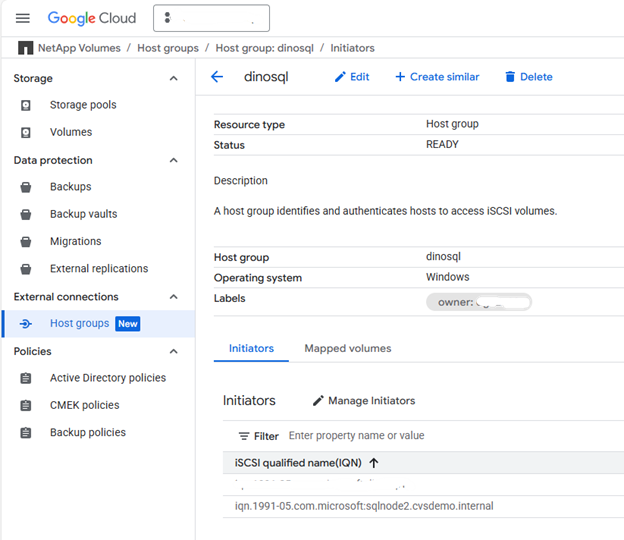
-
Créer un pool de stockage
-
Créez un pool de stockage avec une capacité et des performances appropriées.
gcloud netapp storage-pools create POOL_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --service-level=Flex \ --type=Unified \ --capacity=1024 \ --total-throughput=64 \ --total-iops=1024 \ --network=name=VPC_NAME,psa-range=PSA_RANGEPour plus de détails, consultez la documentation "Créer un pool de stockage".
-
Remplacez les valeurs suivantes :
-
POOL_NAME: Nom du pool (par exemple,sqltest) -
PROJECT_ID: Nom de votre projet Google Cloud -
LOCATION: Même emplacement que vos instances de calcul (par exemple,us-west1-b) -
CAPACITY: Capacité du pool en Gio (par exemple,1024) -
SERVICE_LEVEL: Niveau de service (par exemple,Flex) -
VPC_NAME: Nom de votre réseau VPC -
PSA_RANGE: Plage d'accès aux services privés (par exemple,xx.xxx.xxx.0/20) -
THROUGHPUT: Débit optionnel en MiBps (par exemple,64) -
IOPS: IOPS optionnelles (par exemple,1024)
-
Créer des volumes
-
Créez des volumes pour les données, les journaux, les fichiers temporaires et les sauvegardes. Exécutez la commande suivante pour chaque type de volume :
gcloud beta netapp volumes create VOLUME_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --storage-pool=POOL_NAME \ --capacity=CAPACITY \ --protocols=ISCSI \ --block-devices="name=VOLUME_NAME,host-groups=HOST_GROUP_PATH,os-type=WINDOWS" \ --snapshot-directory=falsePour plus de détails, consultez la "Créer un volume" documentation.
-
Remplacez les valeurs suivantes :
-
VOLUME_NAME: Nom unique pour chaque volume (par exemple,node1data,node1log,node1temp,node1backup) -
PROJECT_ID: Nom de votre projet Google Cloud -
LOCATION: Même emplacement que le pool de stockage (par exemple,us-west1-b) -
POOL_NAME: Nom du pool de stockage (par exemple,sqltest) -
CAPACITY: Capacité de volume en GiB (par exemple,200) -
HOST_GROUP_PATH: Chemin d'accès complet à la ressource du groupe hôte (par exemple,projects/PROJECT_ID/locations/us-west1/hostGroups/demosql)
-

|
Plusieurs groupes d'hôtes peuvent être spécifiés avec un signe # séparant chaque groupe d'hôtes. |
|
|
Répétez cette étape pour chaque type de volume : data, log, temp et backup. |
Monter les volumes iSCSI
Montez les volumes iSCSI non partagés sur chaque instance SQL :
-
Dans la console Google Cloud, accédez à NetApp volumes > Volumes.
-
Sélectionnez le volume créé pour l'instance SQL (par exemple,
node1data). -
Copiez les deux adresses IP de la cible iSCSI (par exemple,
10.165.128.216et10.165.128.217). -
Sur sqlnode1, exécutez
iscsicplou utilisez PowerShell : -
Cliquez sur l'onglet Discover, puis sur Discover Portal.
-
Ajoutez chaque adresse IP obtenue ; laissez le port par défaut 3260.
"10.165.128.216","10.165.128.217" | % { New-IscsiTargetPortal -TargetPortalAddress $_ }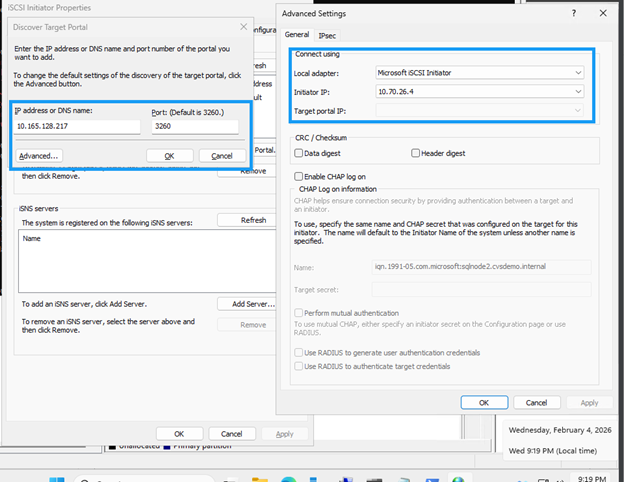
-
Dans la boîte de dialogue Se connecter à la cible, cochez Activer le multi-path si vous utilisez le multipathing.
-
Cliquez sur Advanced et sélectionnez l’adresse IP du portail cible dans la liste déroulante.
-
Cliquez sur OK pour vous connecter.
-
Configurer MPIO pour les périphériques iSCSI
-
Ouvrez MPIO depuis le Panneau de configuration ou Server Manager.
-
Cliquez sur l'onglet Discover Multi-Paths.
-
Cochez Ajouter la prise en charge des périphériques iSCSI et cliquez sur Ajouter.
-
Redémarrez si vous y êtes invité.
-
Vérifiez la configuration multipath dans le Gestionnaire de périphériques sous Lecteurs de disque.
-
-
Initialiser et formater les volumes
-
Lancez Gestion de l'ordinateur (
compmgmt.mscet sélectionnez Gestion des disques. -
Initialisez, partitionnez et formatez chaque disque avec une unité d'allocation de 64K :
Format-Volume -DriveLetter <DriveLetter> -FileSystem NTFS -NewFileSystemLabel <Label> -AllocationUnitSize 65536 -Confirm:$false -
Attribuez des lettres de lecteur (par exemple, D: pour Data, E: pour Log, F: pour Backup, G: pour Temp).
-
Créez la structure de répertoires pour SQL Server :
$paths = "D:\MSSQL\DATA","E:\MSSQL\Log","F:\MSSQL\Backup","G:\MSSQL\Temp" $paths | % { New-Item -ItemType Directory -Path $_ -Force }
-
Configurer SQL Server
Configurez SQL Server sur les deux nœuds pour utiliser le compte de service de domaine, mettez à jour les chemins d'accès par défaut pour utiliser les volumes NetApp, et déplacez les bases de données système vers les nouveaux emplacements de stockage.
-
Mettez à jour les services SQL Server et SQL Server Agent pour qu'ils s'exécutent sous le compte de service de domaine pour l'authentification du cluster et la prise en charge du basculement.
-
Sur chaque instance SQL, ouvrez
services.msc. -
Mettez à jour Se connecter en tant que
domain\sqlsvcpour les services SQL Server et SQL Server Agent. -
Ouvrez SQL Server Management Studio (SSMS) et connectez-vous avec votre compte de domaine.
En cas d'échec de la connexion, lancez SSMS en tant que
<local computer>\Administrator. Assurez-vous que le compte Administrateur est activé dans Utilisateurs & groupes avec un mot de passe approprié.
-
-
Créez les identifiants de connexion du compte de domaine avec les autorisations requises.
Remplacez CVSDEMOpar votre nom de domaine dans les commandes SQL suivantes.USE [master] GO -- Create login for SQL service account CREATE LOGIN [CVSDEMO\sqlsvc] FROM WINDOWS WITH DEFAULT_DATABASE=[master], DEFAULT_LANGUAGE=[us_english] GO -- Add to sysadmin role ALTER SERVER ROLE [sysadmin] ADD MEMBER [CVSDEMO\sqlsvc] GO -- Create user in master and assign role USE [master] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO -- Repeat for model, msdb, and tempdb databases USE [model] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO USE [msdb] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO USE [tempdb] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO -
Mettez à jour les chemins d'accès par défaut pour utiliser les volumes NetApp au lieu du lecteur système :
USE [master] GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'BackupDirectory', REG_SZ, N'F:\MSSQL\Backup' GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'DefaultData', REG_SZ, N'D:\MSSQL\DATA' GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'DefaultLog', REG_SZ, N'E:\MSSQL\Log' GO -
Déplacez les bases de données système (model, msdb, tempdb et master) du disque du système d'exploitation vers les volumes NetApp pour de meilleures performances et une meilleure gestion.
-
Vérifiez les chemins actuels :
-- Check current paths SELECT name, physical_name FROM sys.master_files WHERE database_id IN (DB_ID('model'), DB_ID('msdb')); -
Mise à jour vers de nouveaux emplacements :
-- Move model database ALTER DATABASE model MODIFY FILE (NAME = modeldev, FILENAME = 'D:\MSSQL\Data\model.mdf'); ALTER DATABASE model MODIFY FILE (NAME = modellog, FILENAME = 'E:\MSSQL\Log\modellog.ldf'); -- Move msdb database ALTER DATABASE msdb MODIFY FILE (NAME = MSDBData, FILENAME = 'D:\MSSQL\Data\MSDBData.mdf'); ALTER DATABASE msdb MODIFY FILE (NAME = MSDBLog, FILENAME = 'E:\MSSQL\Log\MSDBLog.ldf'); GO -
Arrêtez SQL Server, déplacez manuellement les fichiers de l'ancien emplacement vers les nouveaux chemins, puis redémarrez SQL Server.
-
Déplacer la base de données tempdb
USE master; GO -- Check current tempdb files SELECT name, physical_name FROM sys.master_files WHERE database_id = DB_ID('tempdb'); -- Change paths for tempdb ALTER DATABASE tempdb MODIFY FILE (NAME = tempdev, FILENAME = 'G:\MSSQL\Temp\tempdb.mdf'); ALTER DATABASE tempdb MODIFY FILE (NAME = templog, FILENAME = 'G:\MSSQL\Temp\templog.ldf'); GO -
Redémarrez SQL Server pour que les modifications prennent effet :
Restart-Service -Name "MSSQLSERVER" -Force
-
-
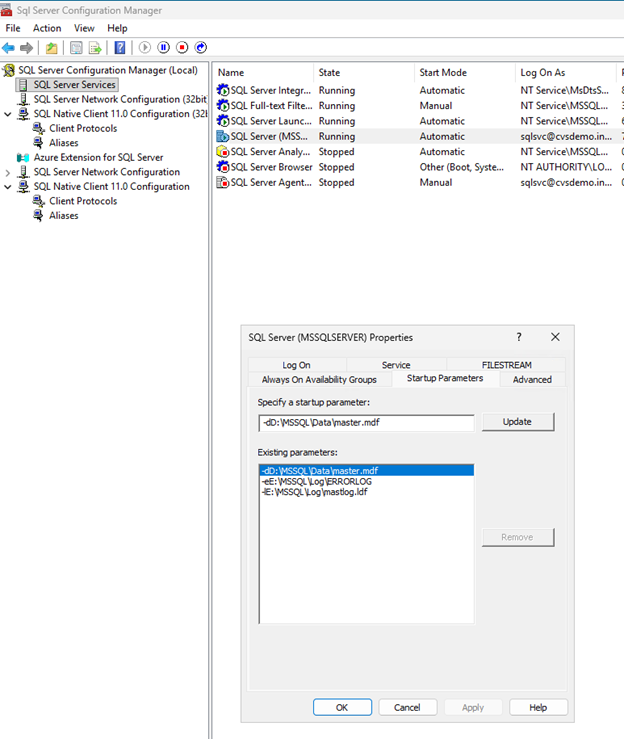
Déplacer la base de données principale
-
Ouvrez le SQL Server Configuration Manager.
-
Accédez à SQL Server Services, cliquez avec le bouton droit sur SQL Server (MSSQLSERVER), puis sélectionnez Propriétés.
-
Cliquez sur l'onglet Startup Parameters.
-
Dans Paramètres existants, repérez les paramètres commençant par
-d,-eet-l. -
Supprimez les anciens paramètres et ajoutez-en de nouveaux :
-dD:\MSSQL\Data\master.mdf -lE:\MSSQL\Log\mastlog.ldf -eE:\MSSQL\Log\ERRORLOG
-
Cliquez sur OK.
-
-
Arrêtez le service SQL Server.
-
Déplacez manuellement
master.mdfetmastlog.ldfde l'ancien emplacement vers les nouveaux chemins. -
Si vous avez modifié le chemin d'accès au journal des erreurs, déplacez le
ERRORLOGfichier également. -
Démarrez le service SQL Server.
Configurer un cluster de basculement
Configurez le clustering de basculement Windows Server pour assurer une haute disponibilité pour SQL Server. Pour plus d'informations, consultez "Documentation sur le clustering de basculement Windows Server".
Configurer les règles du pare-feu
Ouvrez les ports réseau requis sur les deux nœuds SQL pour activer la communication du cluster, la connectivité SQL Server et la réplication du groupe de disponibilité.
-
Ouvrez les ports requis sur les deux nœuds SQL pour la communication du cluster.
Les ports requis incluent : UDP 3343, TCP 3343, TCP 1433, TCP 5022, TCP 135, TCP 445, TCP 49152-65535 (RPC dynamique).
-
Exécutez le point de contrôle suivant sur les deux serveurs pour autoriser SQL Server et la communication du cluster à travers le pare-feu.
Ajustez les numéros de port si vous avez des configurations personnalisées.
# Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022Pour connaître les exigences détaillées en matière de pare-feu, veuillez vous référer à "Exigences relatives aux services et aux ports réseau de Windows Server".
-
Effectuez des contrôles de validation sur les deux nœuds avant de créer le cluster :
Test-Connection servername Resolve-DnsName servername Get-NetAdapterBinding -ComponentID ms_tcpip6
Créer le cluster de basculement
Créez un cluster de basculement Windows Server avec les deux nœuds SQL Server pour activer la haute disponibilité et le basculement automatique.
-
Exécutez
cluadmin.mscou ouvrez Failover Cluster Manager à partir du Server Manager.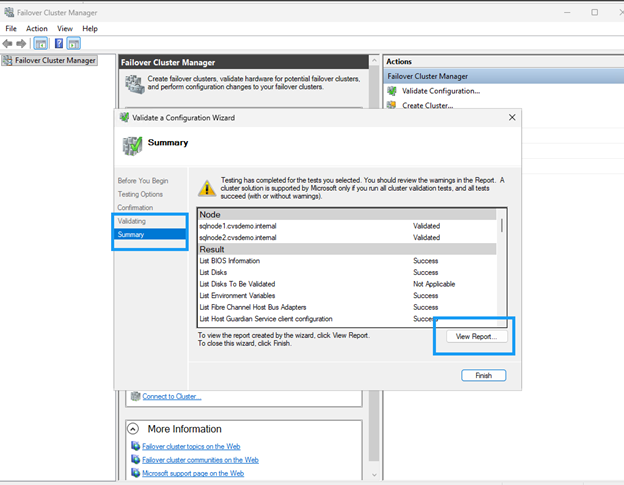
-
Sélectionnez Create Cluster.
-
Ajoutez les deux nœuds SQL (sqlnode1, sqlnode2).
-
Effectuez des tests de validation et assurez-vous que tous les contrôles sont réussis. Examinez et corrigez les avertissements avant de poursuivre.
-
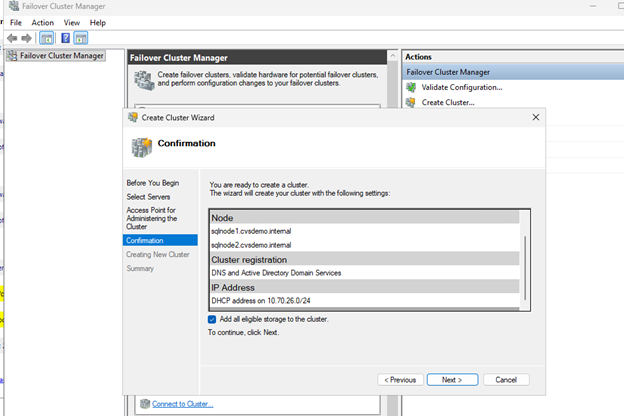
Indiquez un nom de cluster (par exemple,
sqlcluwest1). -
Finalisez la création du cluster.
Configurer le quorum du cluster avec file share witness
Configurez un témoin de partage de fichiers pour maintenir le quorum dans une configuration de cluster à deux nœuds. Le témoin fournit un vote supplémentaire pour éviter les situations de split-brain et garantir la disponibilité du cluster.
Créer un partage de fichiers
Créez un partage de fichiers sur une machine virtuelle dans une zone ou une région différente qui dispose d'une connectivité réseau et se trouve dans le même domaine Active Directory.
-
Connectez-vous à la machine virtuelle du serveur témoin de partage de fichiers.
-
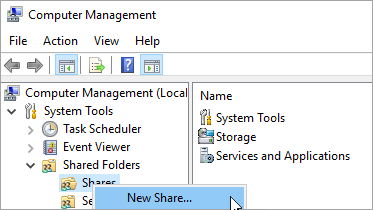
Dans le Gestionnaire de serveur, sélectionnez Outils > Gestion de l’ordinateur.
-
Sélectionnez Dossiers partagés, cliquez avec le bouton droit sur Shares, puis sélectionnez New Share.
-
Utilisez l’Assistant de création de dossier partagé pour créer un partage
\\servername\share. -
Sur la page Chemin du dossier, sélectionnez Parcourir.
-
Localisez ou créez un chemin pour le dossier partagé, puis sélectionnez Suivant.
-
Sur la page Nom, description et paramètres, vérifiez le nom et le chemin du partage, puis sélectionnez Suivant.
-
Sur la page Autorisations des dossiers partagés, sélectionnez Personnaliser les autorisations et cliquez sur Personnalisé
-
Dans la boîte de dialogue Customize Permissions, sélectionnez Add pour ajouter le compte du cluster.
Assurez-vous que le compte utilisé pour créer le cluster (sqlcluwest1$) dispose d'un contrôle total.
-
Cliquez sur OK pour enregistrer les autorisations.
-
Sur la page Autorisations du dossier partagé, sélectionnez Terminer et puis sélectionnez à nouveau Terminer.
Configurer les paramètres de quorum
Configurez le cluster pour utiliser le file share witness pour le vote par quorum.
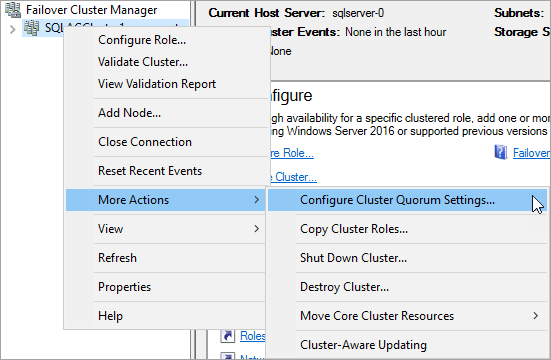
-
Dans le Gestionnaire de cluster de basculement, cliquez avec le bouton droit sur le cluster et sélectionnez Plus d’actions > Configurer les paramètres de quorum du cluster.
-
Dans l’assistant Configure Cluster Quorum, cliquez sur Next.
-
Sur la page Select Quorum Configuration, choisissez Select the quorum witness et cliquez sur Next.
-
Sur la page Select Quorum Witness, sélectionnez Configure a file share witness.
-
Sur la page Configurer le témoin de partage de fichiers, sélectionnez Configurer un file share witness.
-
Saisissez le chemin d'accès au partage que vous avez créé (par exemple,
\\servername\share) et cliquez sur Suivant. -
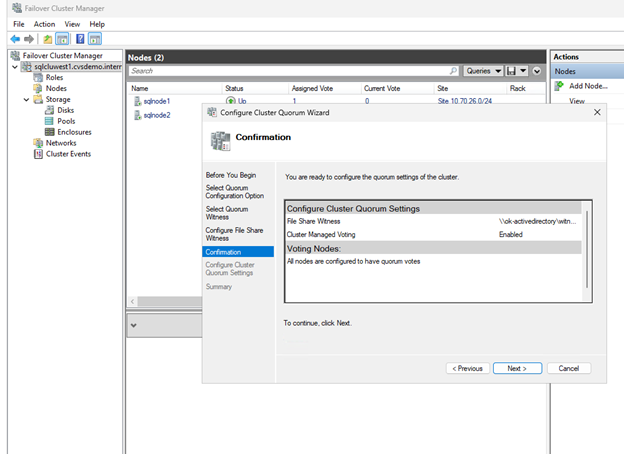
Vérifiez les paramètres sur la page Confirmation et cliquez sur Next.
-
Cliquez sur Terminer.
Les ressources principales du cluster sont désormais configurées avec un file share witness.
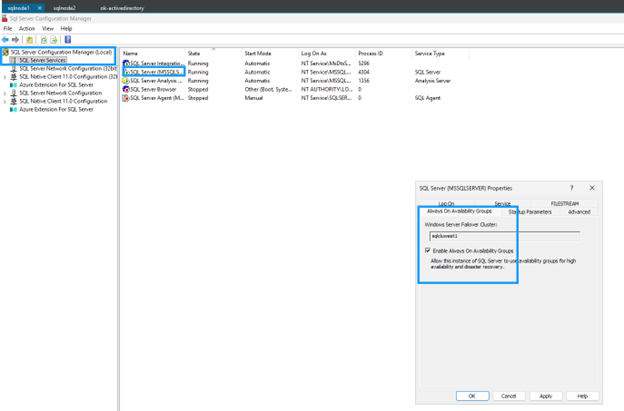
Activer les groupes de disponibilité Always On
Activez Always On availability groups sur les deux machines virtuelles SQL Server :
-
Dans le menu Démarrer, ouvrez SQL Server Configuration Manager.
-
Dans l'arborescence du navigateur, sélectionnez SQL Server Services.
-
Cliquez avec le bouton droit sur SQL Server (MSSQLSERVER) et sélectionnez Properties.
-
Sélectionnez l’onglet Always On High Availability.
-
Cochez Activer les groupes de disponibilité Always On.
-
Cliquez sur Appliquer, puis redémarrez le service SQL Server lorsque vous y êtes invité.
-
Répétez pour la deuxième instance de SQL Server.
Créez une base de données sur la première instance SQL Server
Créez une base de données sur la première instance SQL Server.
-
Connectez-vous à la première machine virtuelle SQL Server avec un compte de domaine qui est membre du rôle serveur fixe sysadmin.
-
Ouvrez SQL Server Management Studio et connectez-vous à la première instance SQL Server.
-
Dans Object Explorer, cliquez avec le bouton droit sur Databases et sélectionnez New Database.
-
Saisissez un nom de base de données (par exemple,
MyDB1) et cliquez sur OK. -
Définissez le mode de restauration de la base de données sur Complet :
ALTER DATABASE MyDB1 SET RECOVERY FULL; GO
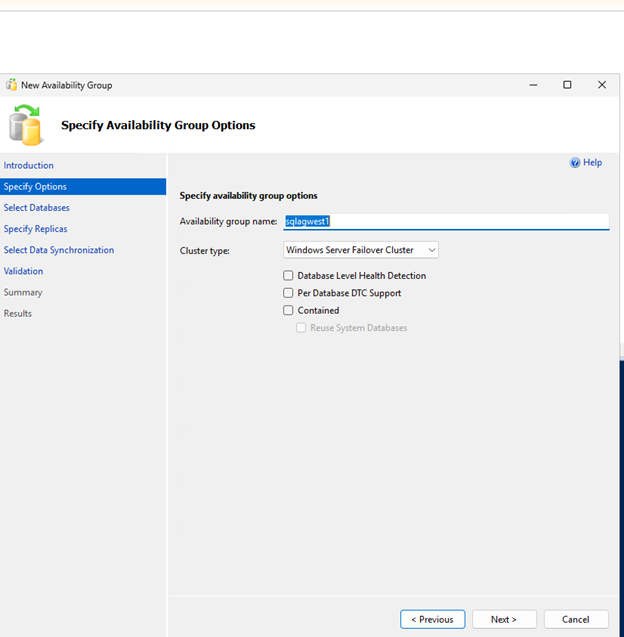
Créer et configurer un groupe de disponibilité
Créez un groupe de disponibilité Always On avec validation synchrone et basculement automatique pour assurer une haute disponibilité pour vos bases de données SQL Server.
-
Effectuez une sauvegarde complète et une sauvegarde du journal des transactions de la base de données.
-- Full backup BACKUP DATABASE MyDB1 TO DISK = 'F:\MSSQL\Backup\MyDB1_Full.bak' WITH INIT, COMPRESSION; -- Transaction log backup BACKUP LOG MyDB1 TO DISK = 'F:\MSSQL\Backup\MyDB1_Log.trn' WITH INIT, COMPRESSION; -
Copiez les fichiers de sauvegarde sur la deuxième instance SQL Server et restaurez-les avec NORECOVERY.
-- Restore full backup RESTORE DATABASE MyDB1 FROM DISK = 'F:\MSSQL\Backup\MyDB1_Full.bak' WITH NORECOVERY; -- Restore log backup RESTORE LOG MyDB1 FROM DISK = 'F:\MSSQL\Backup\MyDB1_Log.trn' WITH NORECOVERY; -
Créez le groupe de disponibilité avec validation synchrone, mode de basculement automatique et réplicas secondaires lisibles :
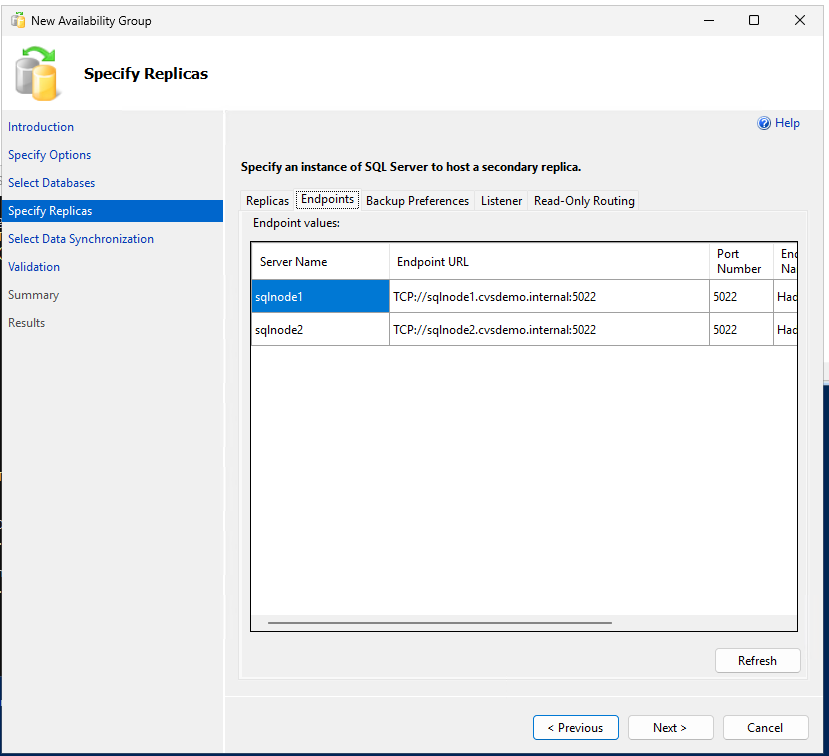
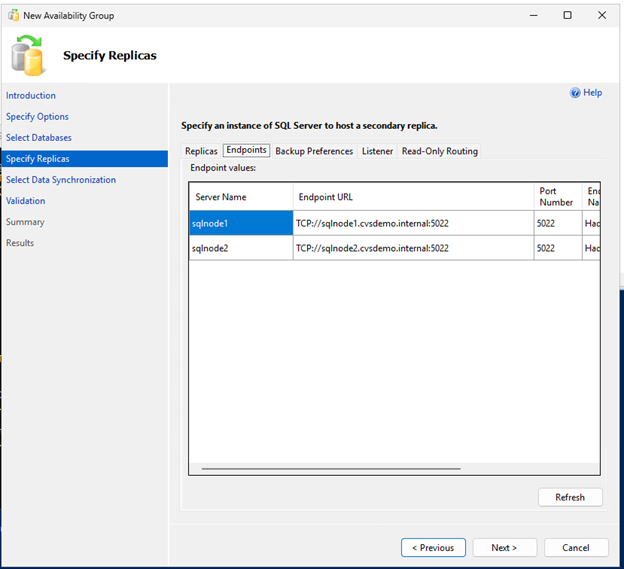
-- Run on primary replica CREATE AVAILABILITY GROUP sqlagwest1 WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY) FOR DATABASE MyDB1 REPLICA ON N'SQLNODE1' WITH ( ENDPOINT_URL = N'TCP://sqlnode1.cvsdemo.internal:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = YES) ), N'SQLNODE2' WITH ( ENDPOINT_URL = N'TCP://sqlnode2.cvsdemo.internal:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = YES) ); GO -
Créez le groupe de disponibilité à l'aide de l'Assistant Groupe de disponibilité.
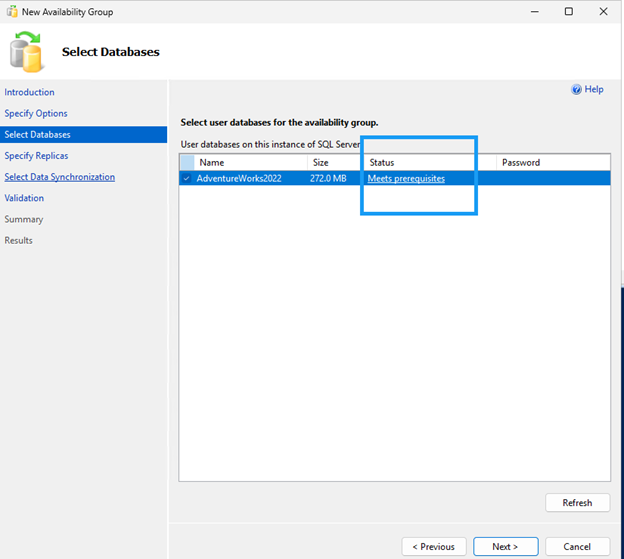

Assurez-vous que le port 5022 du pare-feu est autorisé sur les deux nœuds SQL. 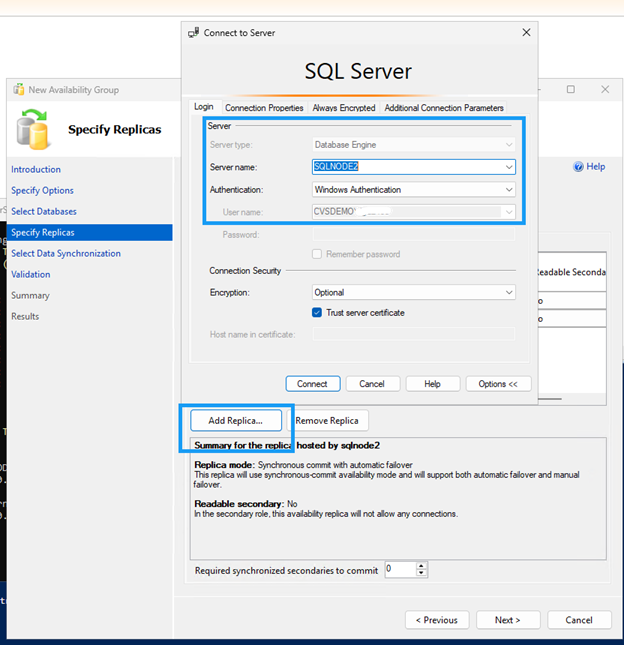
Créer une ressource d'écoute DNN
Créez un écouteur de Distributed Network Name (DNN) pour acheminer le trafic vers la ressource clusterisée appropriée sans nécessiter de load balancer.
Utilisez PowerShell pour créer la ressource DNN :
$Ag = "sqlagwest1"
$Dns = "AOAGDNN"
$Port = "1433"
# Add DNN resource
Add-ClusterResource -Name $Dns -ResourceType "Distributed Network Name" -Group $Ag
# Set DNN properties
Get-ClusterResource -Name $Dns | Set-ClusterParameter -Name DnsName -Value $Dns
Get-ClusterResource -Name $Dns | Set-ClusterParameter -Name Port -Value $Port
# Start DNN resource
Start-ClusterResource -Name $Dns
# Add dependency
$AagResource = Get-ClusterResource | Where-Object {$_.ResourceType -eq "SQL Server Availability Group" -and $_.OwnerGroup -eq $Ag}
Set-ClusterResourceDependency -Resource $AagResource -Dependency "[$Dns]"Configurer les propriétaires possibles
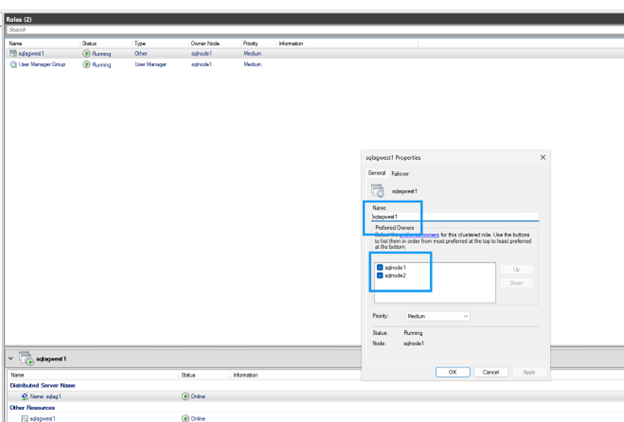
Par défaut, le cluster associe le nom DNS DNN à tous les nœuds. Exclure les nœuds ne participant pas au groupe de disponibilité :
-
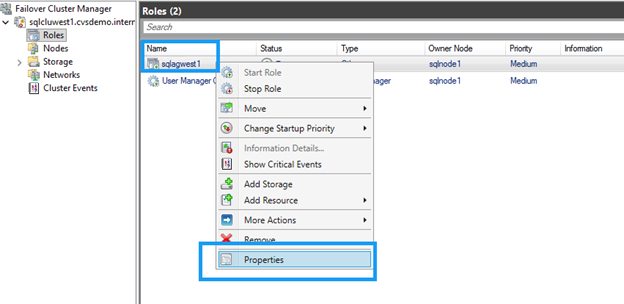
Dans le Gestionnaire de cluster de basculement, localisez la ressource DNN.
-
Cliquez avec le bouton droit sur la ressource DNN et sélectionnez Properties.
-
Décochez la case correspondant aux nœuds qui ne participent pas au groupe de disponibilité.
-
Cliquez sur OK pour enregistrer les paramètres.
Mettre à jour les chaînes de connexion de l'application
Mettez à jour les chaînes de connexion pour utiliser le nom de l'écouteur DNN et inclure le MultiSubnetFailover=True paramètre :
Server=AOAGDNN,1433;Database=MyDB1;MultiSubnetFailover=True;
|
|
Si votre client ne prend pas en charge le paramètre MultiSubnetFailover, il n'est pas compatible avec DNN. |
Tester le basculement
Vérifiez la configuration du groupe de disponibilité et testez le mode de basculement pour vous assurer que le basculement automatique fonctionne correctement entre les nœuds.
-
Exécutez la commande suivante sur n'importe quelle réplique pour vérifier la configuration du groupe de disponibilité.
Les deux répliques doivent afficher
SYNCHRONOUS_COMMITpour le mode de disponibilité etAUTOMATICpour le mode de basculement, ce qui garantit zéro perte de données lors d'un basculement automatique.SELECT ag.name AS AG_Name, ars.primary_replica FROM sys.dm_hadr_availability_group_states AS ars JOIN sys.availability_groups AS ag ON ag.group_id = ars.group_id; -- Check replica configuration SELECT replica_server_name, availability_mode_desc, failover_mode_desc FROM sys.availability_replicas WHERE group_id = (SELECT group_id FROM sys.availability_groups WHERE name = N'sqlagwest1');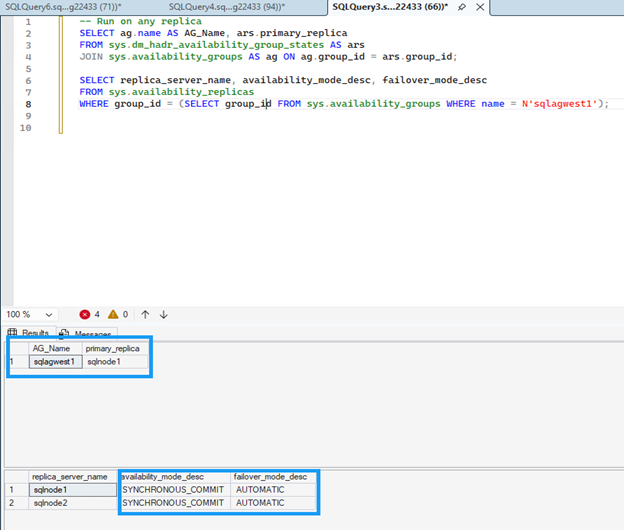
-
Exécutez la commande suivante sur le nœud secondaire pour initier le mode de basculement :
ALTER AVAILABILITY GROUP sqlagwest1 FAILOVER; GO -
Vérifiez que la cible de connectivité a basculé vers le nouveau primary :
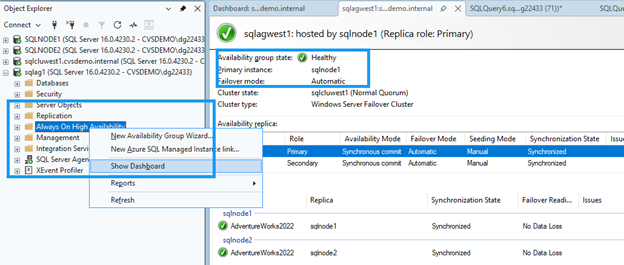
-- SELECT @@SERVERNAME AS NowPrimary;Dans SSMS, développez le nœud du groupe de disponibilité, cliquez avec le bouton droit sur Always On High Availability et sélectionnez Afficher le tableau de bord.
Le tableau de bord doit afficher les deux nœuds avec un statut sain et confirmer le basculement.
Nettoyer les ressources
Après avoir terminé le tutoriel, supprimez les ressources que vous avez créées pour éviter des frais supplémentaires :
-
Supprimer les instances Compute Engine (sqlnode1, sqlnode2)
-
Supprimer Google Cloud NetApp Volumes (volumes, pools de stockage, groupes d'hôtes)
-
Supprimez les ressources VPC et réseau si elles ont été créées spécifiquement pour ce tutoriel
-
Supprimer le serveur témoin de partage de fichiers si applicable
Reportez-vous à "Documentation Google Cloud NetApp Volumes" et "Documentation Google Compute Engine" pour obtenir les étapes détaillées de suppression des ressources.
Où trouver des informations supplémentaires
Pour plus d'informations sur SQL Server sur Google Cloud avec le stockage NetApp, consultez la documentation suivante :