

Gestion de bases de données Oracle EC2 et FSx
 Suggérer des modifications
Suggérer des modifications
Outre la console de gestion AWS EC2 et FSx, le nœud de contrôle Ansible et l'outil d'interface utilisateur SnapCenter sont déployés pour la gestion de la base de données dans cet environnement Oracle.
Un nœud de contrôle Ansible peut être utilisé pour gérer la configuration de l'environnement Oracle, avec des mises à jour parallèles qui maintiennent les instances principales et de secours synchronisées pour les mises à jour du noyau ou des correctifs. Le basculement, la resynchronisation et la restauration peuvent être automatisés avec NetApp Automation Toolkit pour archiver la récupération et la disponibilité rapides des applications avec Ansible. Certaines tâches de gestion de base de données répétables peuvent être exécutées à l’aide d’un playbook pour réduire les erreurs humaines.
L'outil d'interface utilisateur SnapCenter peut effectuer une sauvegarde instantanée de base de données, une récupération à un instant T, un clonage de base de données, etc. avec le plug-in SnapCenter pour les bases de données Oracle. Pour plus d'informations sur les fonctionnalités du plugin Oracle, consultez le"Présentation du plug-in SnapCenter pour la base de données Oracle" .
Les sections suivantes fournissent des détails sur la manière dont les fonctions clés de la gestion de base de données Oracle sont remplies avec l'interface utilisateur SnapCenter :
-
Sauvegardes instantanées de bases de données
-
Restauration ponctuelle de la base de données
-
Création de clone de base de données
Le clonage de base de données crée une réplique d'une base de données principale sur un hôte EC2 distinct pour la récupération des données en cas d'erreur ou de corruption de données logiques, et les clones peuvent également être utilisés pour les tests d'application, le débogage, la validation des correctifs, etc.
Prendre un instantané
Une base de données Oracle EC2/FSx est régulièrement sauvegardée à des intervalles configurés par l'utilisateur. Un utilisateur peut également effectuer une sauvegarde instantanée ponctuelle à tout moment. Cela s'applique aussi bien aux sauvegardes de snapshots de bases de données complètes qu'aux sauvegardes de snapshots de journaux d'archives uniquement.
Prendre un instantané complet de la base de données
Un instantané complet de la base de données inclut tous les fichiers Oracle, y compris les fichiers de données, les fichiers de contrôle et les fichiers journaux d'archive.
-
Connectez-vous à l’interface utilisateur SnapCenter et cliquez sur Ressources dans le menu de gauche. Dans la liste déroulante Affichage, passez à la vue Groupe de ressources.
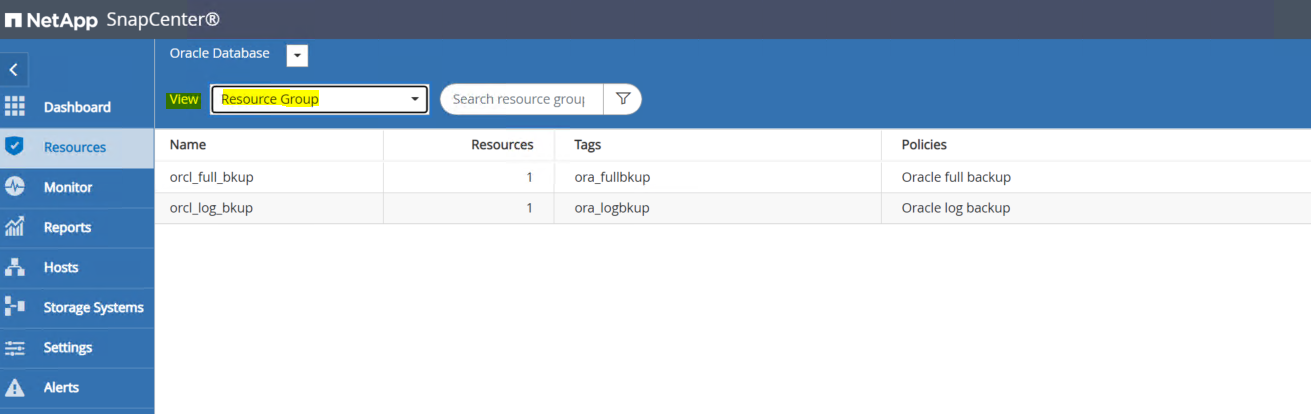
-
Cliquez sur le nom de la ressource de sauvegarde complète, puis cliquez sur l’icône Sauvegarder maintenant pour lancer une sauvegarde supplémentaire.
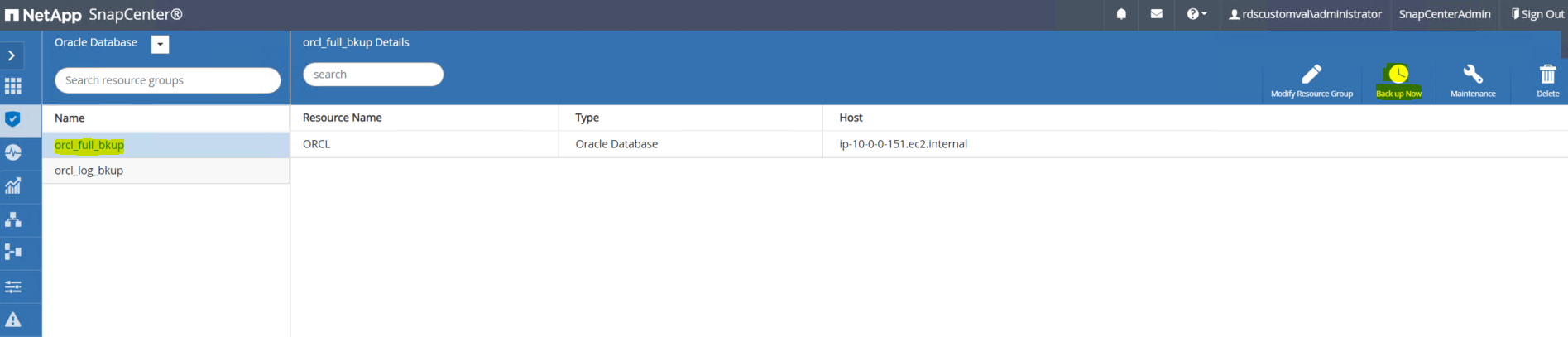
-
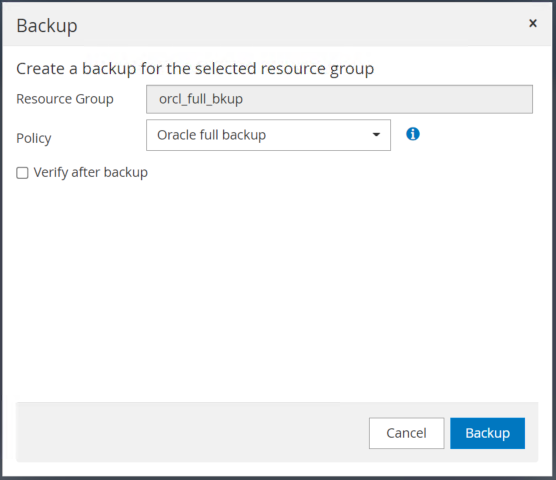
Cliquez sur Sauvegarder, puis confirmez la sauvegarde pour démarrer une sauvegarde complète de la base de données.
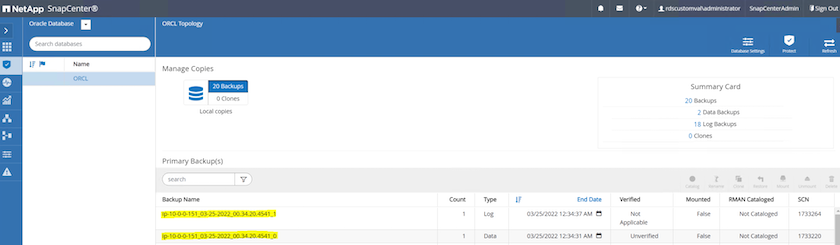
À partir de la vue Ressources de la base de données, ouvrez la page Copies de sauvegarde gérées de la base de données pour vérifier que la sauvegarde ponctuelle s'est terminée avec succès. Une sauvegarde complète de la base de données crée deux instantanés : un pour le volume de données et un pour le volume du journal.
Prendre un instantané du journal d'archive
Un instantané du journal d'archive est uniquement pris pour le volume du journal d'archive Oracle.
-
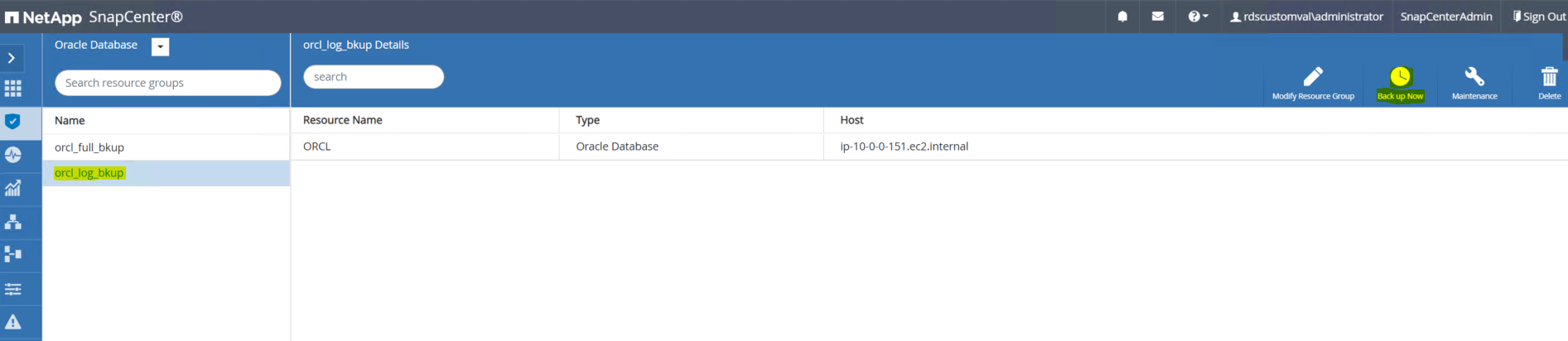
Connectez-vous à l’interface utilisateur SnapCenter et cliquez sur l’onglet Ressources dans la barre de menu de gauche. Dans la liste déroulante Affichage, passez à la vue Groupe de ressources.
-
Cliquez sur le nom de la ressource de sauvegarde du journal, puis cliquez sur l’icône Sauvegarder maintenant pour lancer une sauvegarde complémentaire pour les journaux d’archive.
-
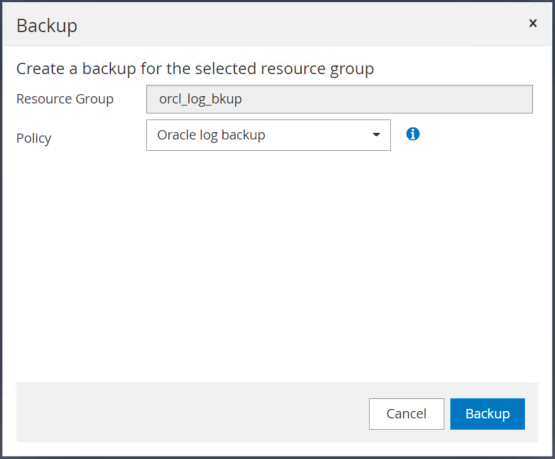
Cliquez sur Sauvegarder, puis confirmez la sauvegarde pour démarrer une sauvegarde du journal d’archive.
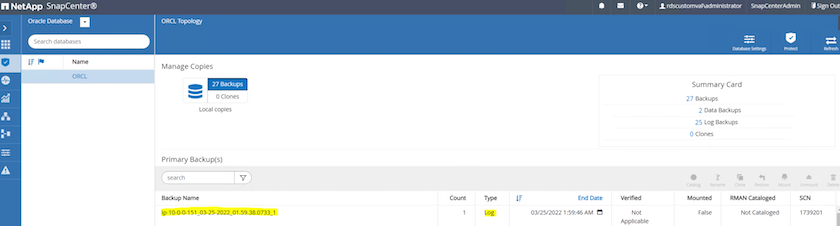
À partir de la vue Ressources de la base de données, ouvrez la page Copies de sauvegarde gérées de la base de données pour vérifier que la sauvegarde ponctuelle du journal d'archive s'est terminée avec succès. Une sauvegarde du journal d’archive crée un instantané pour le volume du journal.
Restauration à un moment précis
La restauration basée sur SnapCenter à un moment donné est exécutée sur le même hôte d’instance EC2. Suivez les étapes suivantes pour effectuer la restauration :
-
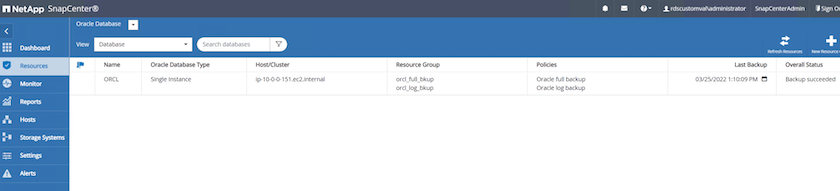
Dans l’onglet Ressources SnapCenter > Vue Base de données, cliquez sur le nom de la base de données pour ouvrir la sauvegarde de la base de données.
-
Sélectionnez la copie de sauvegarde de la base de données et le moment souhaité à restaurer. Notez également le numéro SCN correspondant à ce moment précis. La restauration ponctuelle peut être effectuée à l'aide de l'heure ou du SCN.
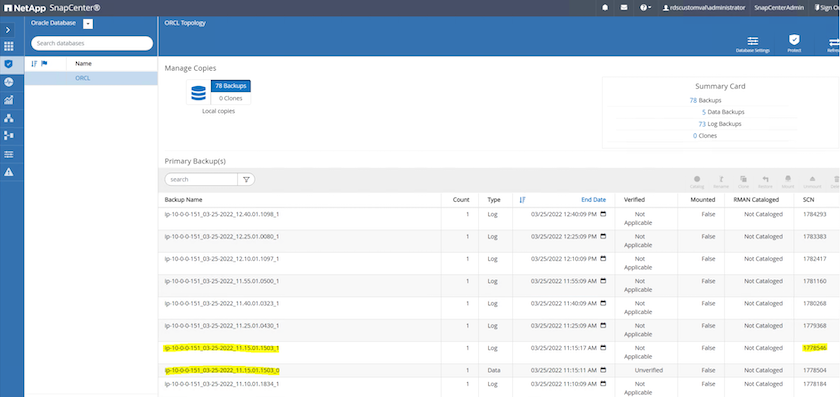
-
Mettez en surbrillance l’instantané du volume du journal et cliquez sur le bouton Monter pour monter le volume.
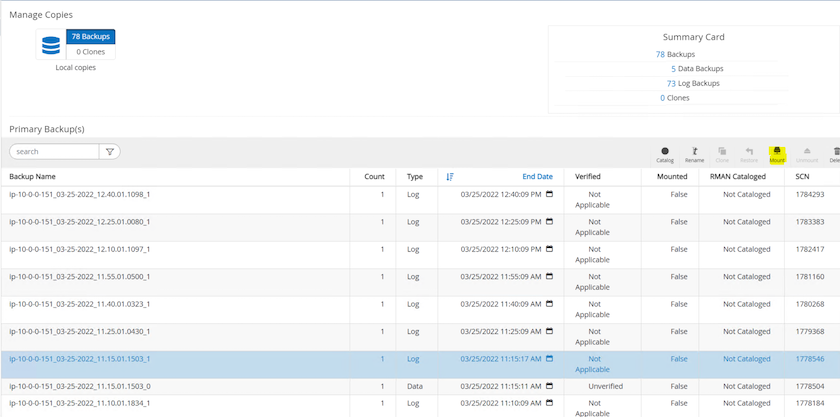
-
Choisissez l’instance EC2 principale pour monter le volume de journal.
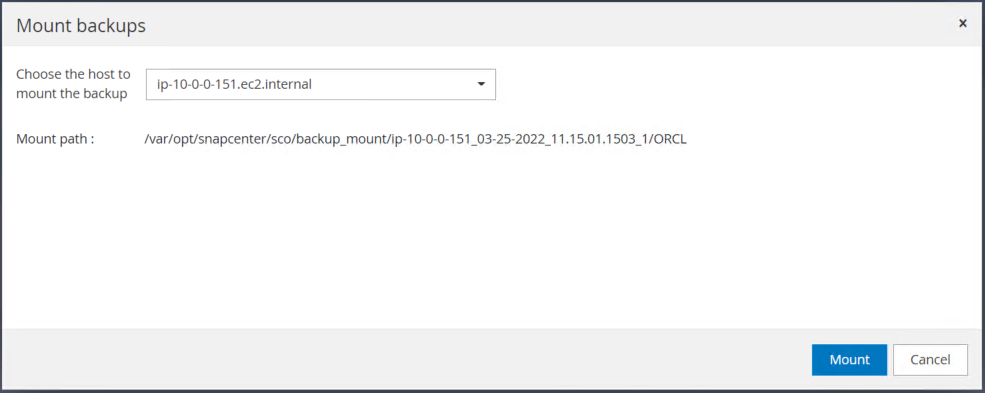
-
Vérifiez que le travail de montage se termine avec succès. Vérifiez également l'hôte de l'instance EC2 pour voir le volume de journal monté ainsi que le chemin du point de montage.


-
Copiez les journaux d’archive du volume de journal monté vers le répertoire de journal d’archive actuel.
[ec2-user@ip-10-0-0-151 ~]$ cp /var/opt/snapcenter/sco/backup_mount/ip-10-0-0-151_03-25-2022_11.15.01.1503_1/ORCL/1/db/ORCL_A/arch/*.arc /ora_nfs_log/db/ORCL_A/arch/
-
Revenez à l’onglet Ressource SnapCenter > page de sauvegarde de la base de données, mettez en surbrillance la copie instantanée des données et cliquez sur le bouton Restaurer pour démarrer le flux de travail de restauration de la base de données.
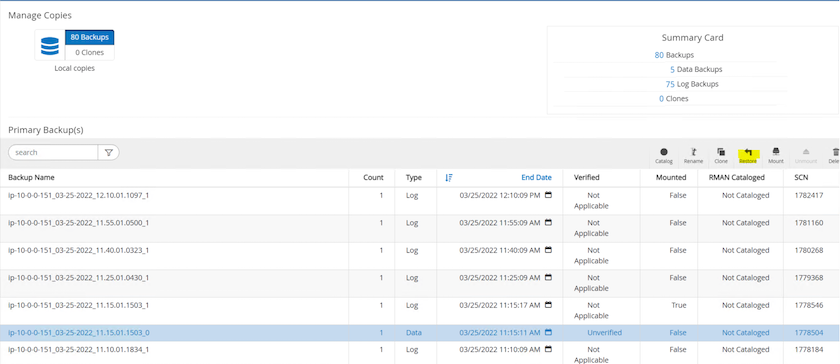
-
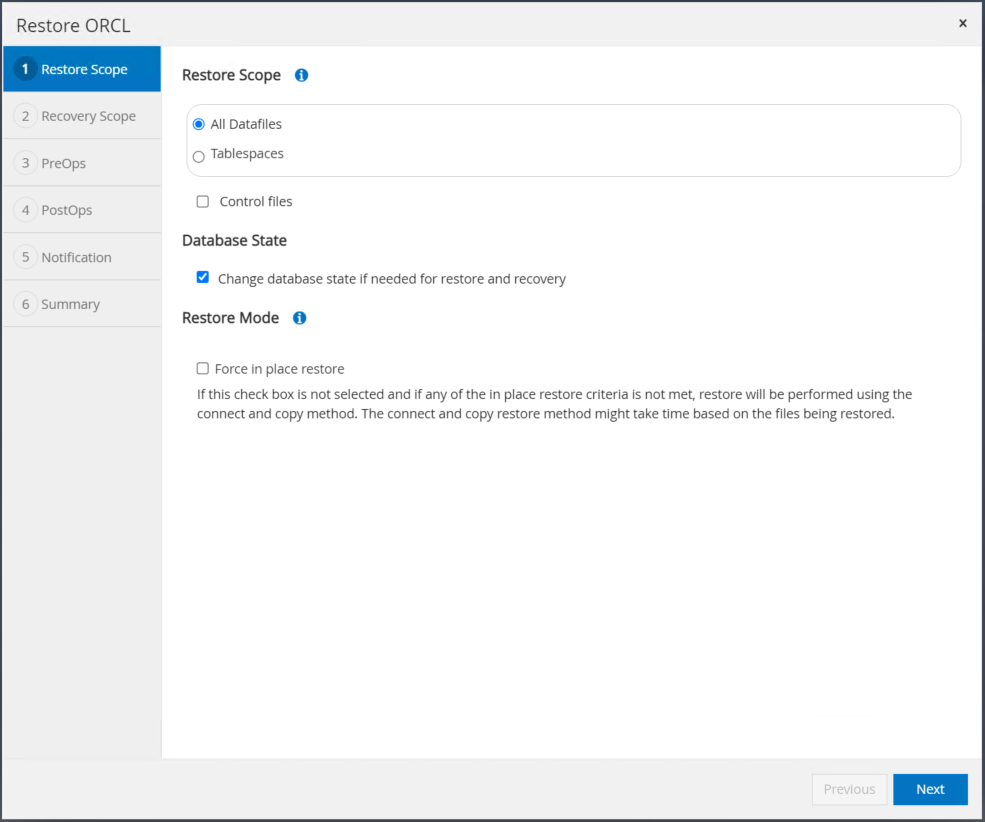
Cochez « Tous les fichiers de données » et « Modifier l’état de la base de données si nécessaire pour la restauration et la récupération », puis cliquez sur Suivant.
-
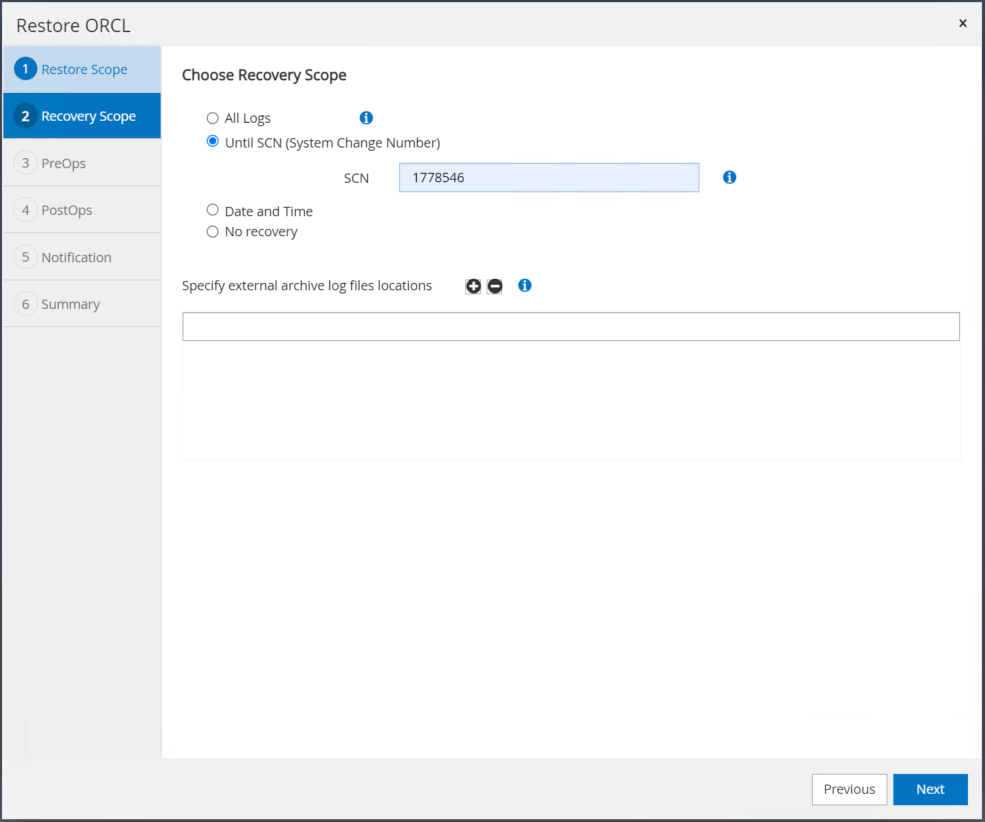
Choisissez une étendue de récupération souhaitée à l'aide de SCN ou de l'heure. Plutôt que de copier les journaux d'archive montés dans le répertoire de journaux actuel comme démontré à l'étape 6, le chemin d'accès au journal d'archive monté peut être répertorié dans « Spécifier les emplacements des fichiers journaux d'archive externes » pour la récupération.
-
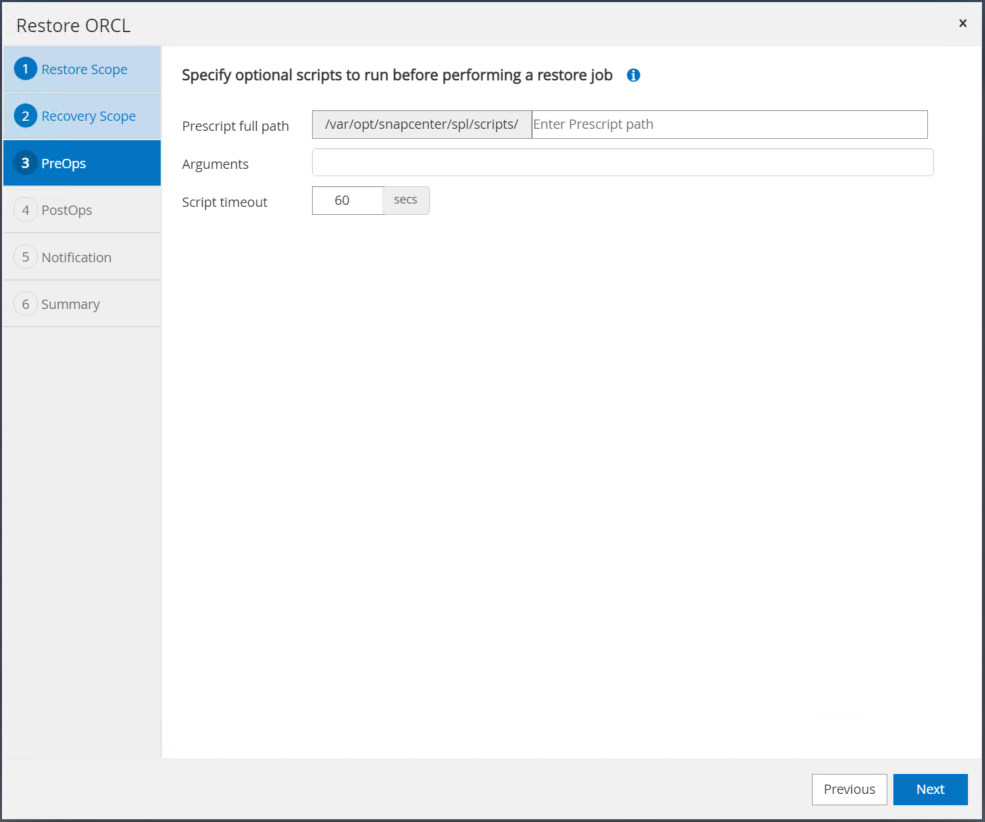
Spécifiez un prescript facultatif à exécuter si nécessaire.
-
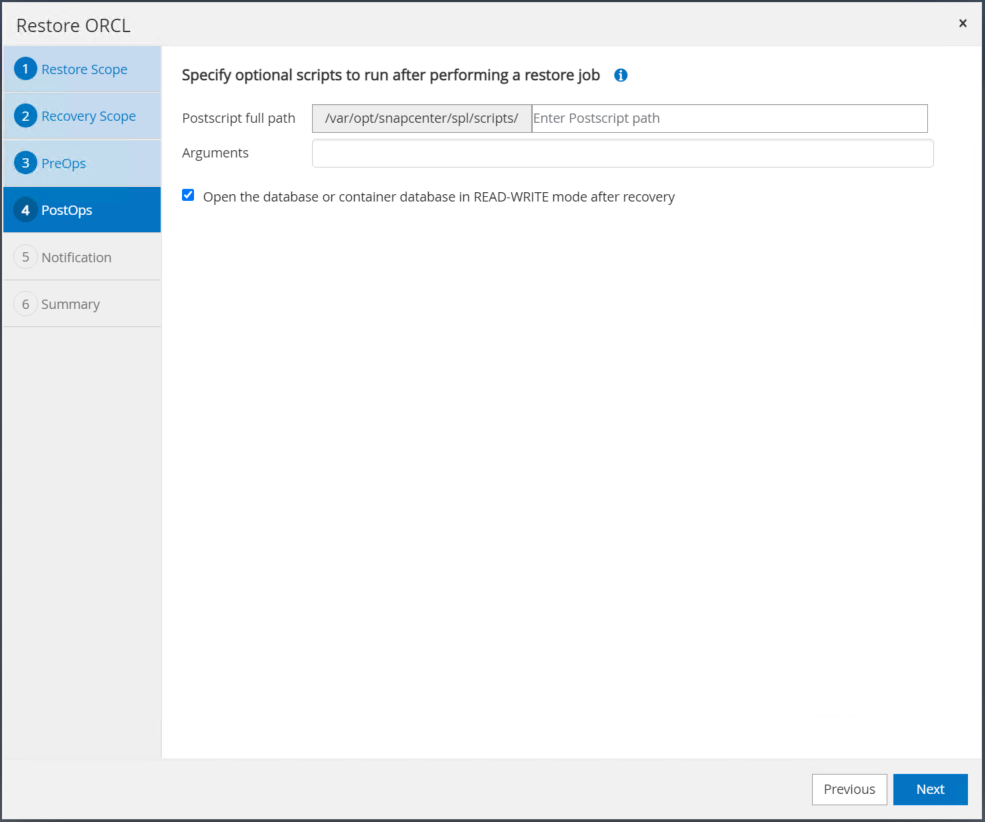
Spécifiez un script ultérieur facultatif à exécuter si nécessaire. Vérifiez la base de données ouverte après la récupération.
-
Fournissez un serveur SMTP et une adresse e-mail si une notification de travail est nécessaire.
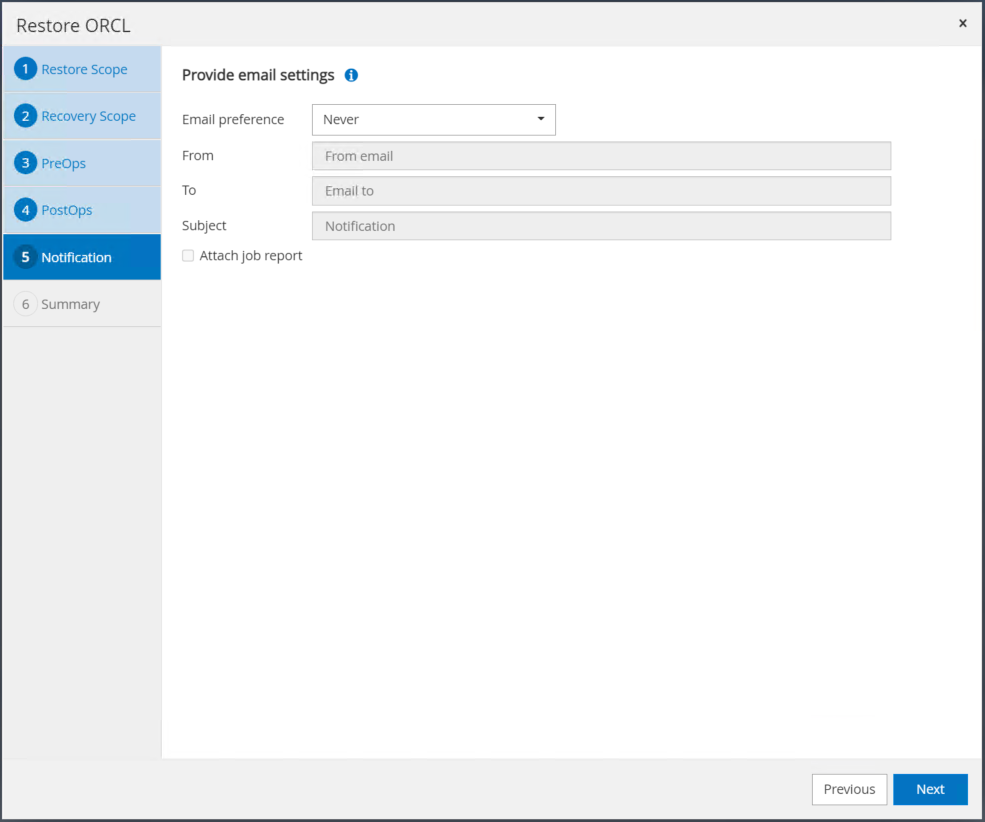
-
Restaurer le résumé du travail. Cliquez sur Terminer pour lancer la tâche de restauration.
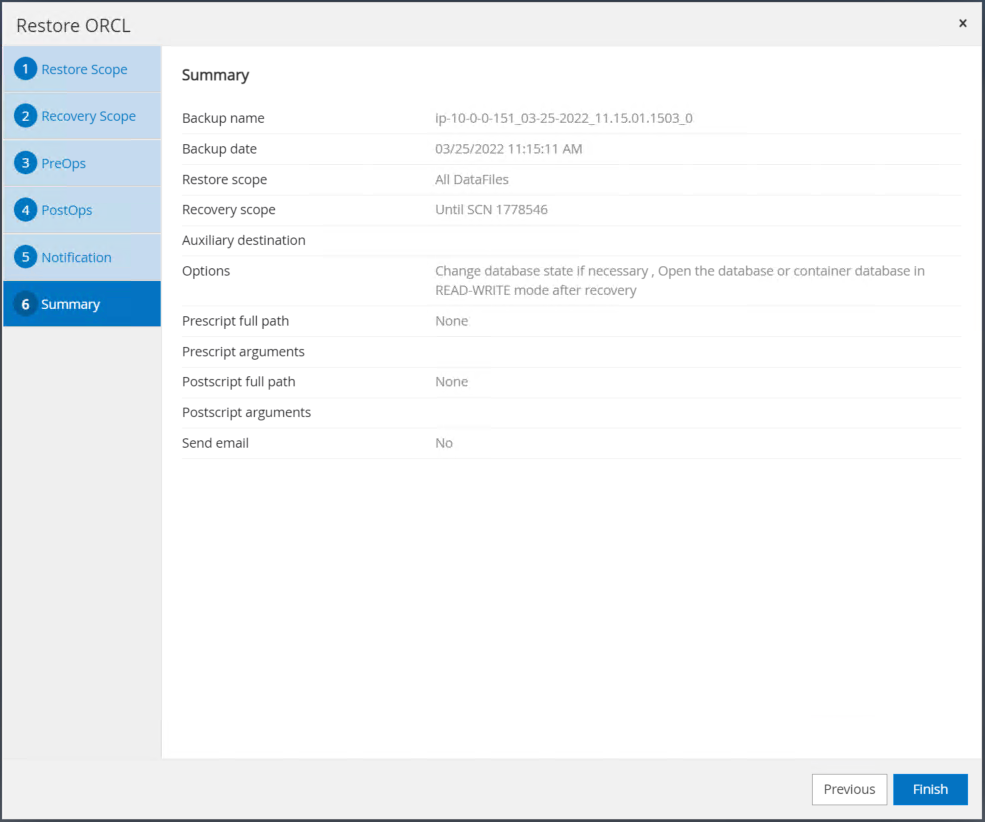
-
Validez la restauration depuis SnapCenter.
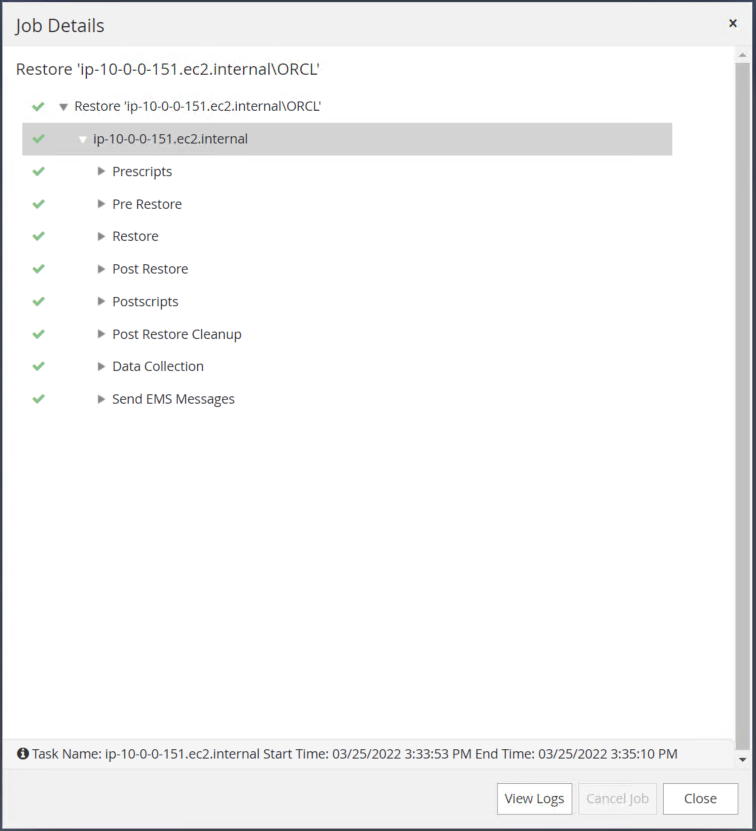
-
Validez la restauration à partir de l’hôte d’instance EC2.
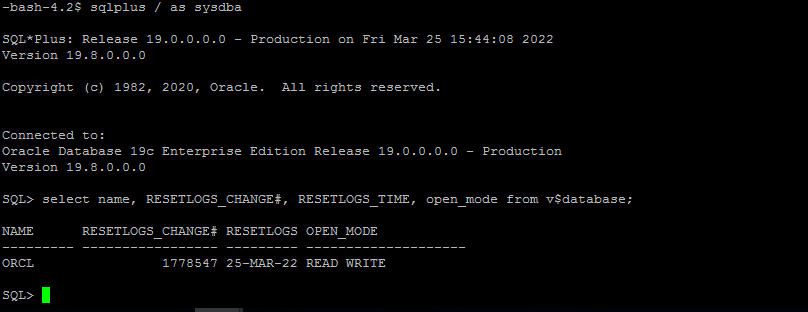
-
Pour démonter le volume du journal de restauration, inversez les étapes de l’étape 4.
Création d'un clone de base de données
La section suivante montre comment utiliser le flux de travail de clonage SnapCenter pour créer un clone de base de données à partir d'une base de données principale vers une instance EC2 de secours.
-
Effectuez une sauvegarde instantanée complète de la base de données principale à partir de SnapCenter à l'aide du groupe de ressources de sauvegarde complète.
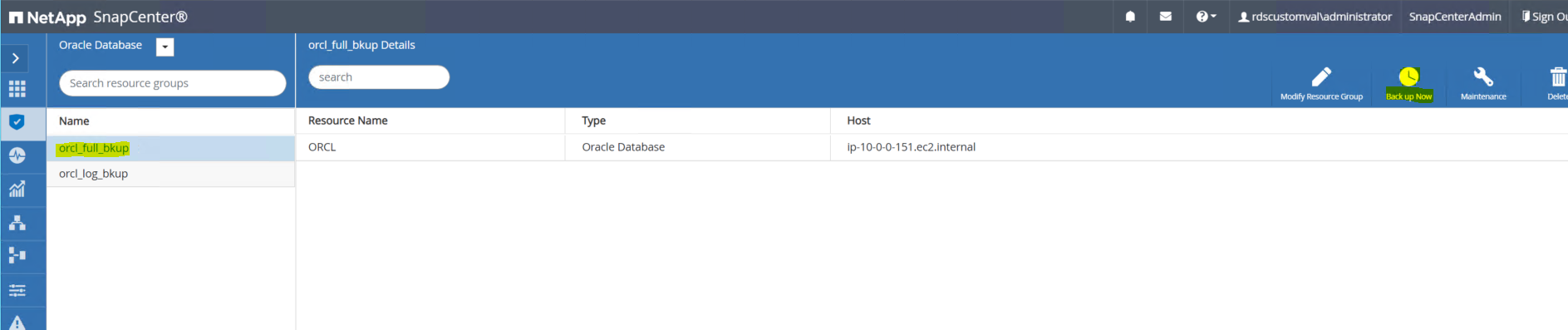
-
Dans l'onglet Ressource SnapCenter > Vue Base de données, ouvrez la page Gestion de sauvegarde de base de données pour la base de données principale à partir de laquelle la réplique doit être créée.
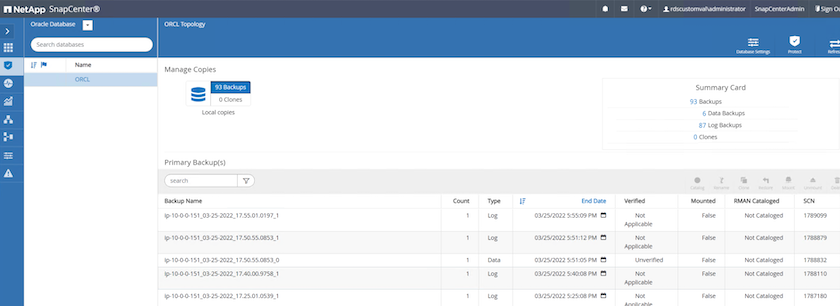
-
Montez l’instantané du volume de journal pris à l’étape 4 sur l’hôte d’instance EC2 de secours.
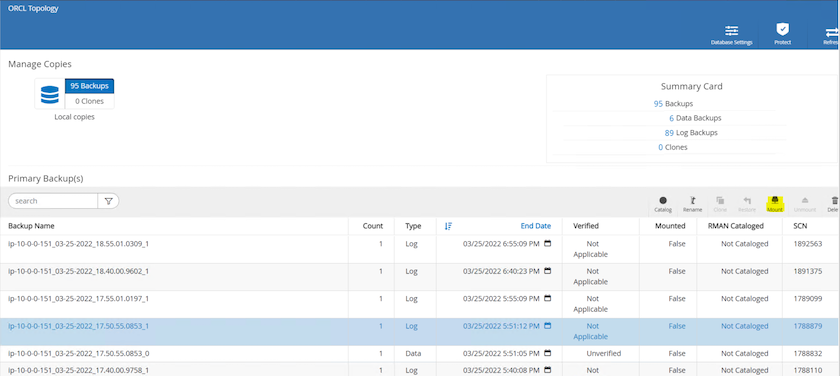
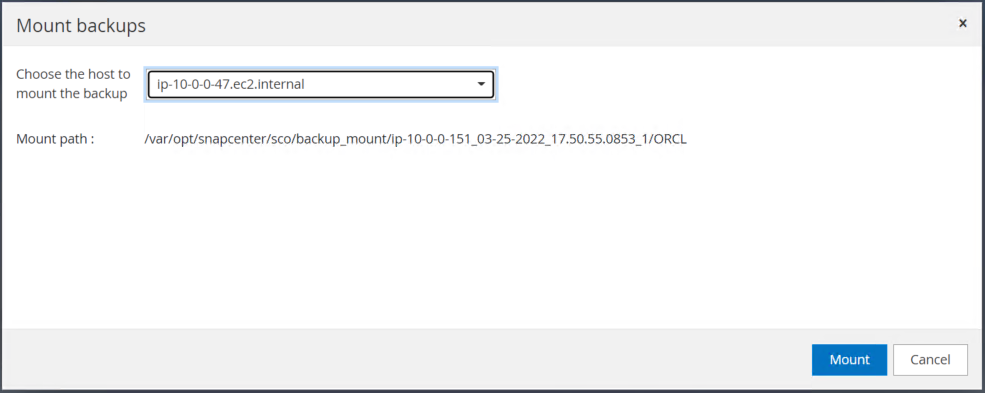
-
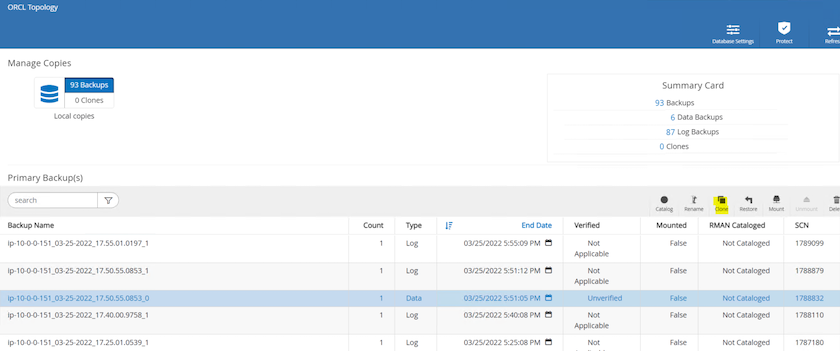
Mettez en surbrillance la copie instantanée à cloner pour la réplique et cliquez sur le bouton Cloner pour démarrer la procédure de clonage.
-
Modifiez le nom de la copie de réplication afin qu'il soit différent du nom de la base de données principale. Cliquez sur Suivant.

-
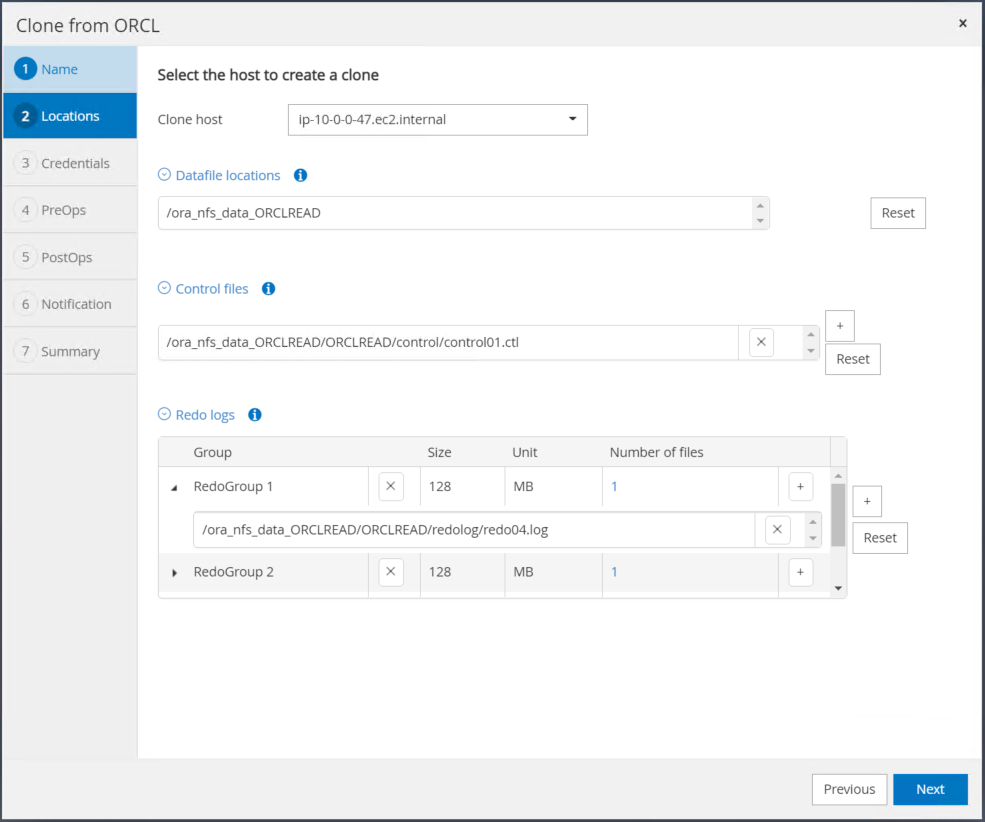
Remplacez l’hôte clone par l’hôte EC2 de secours, acceptez le nom par défaut et cliquez sur Suivant.
-
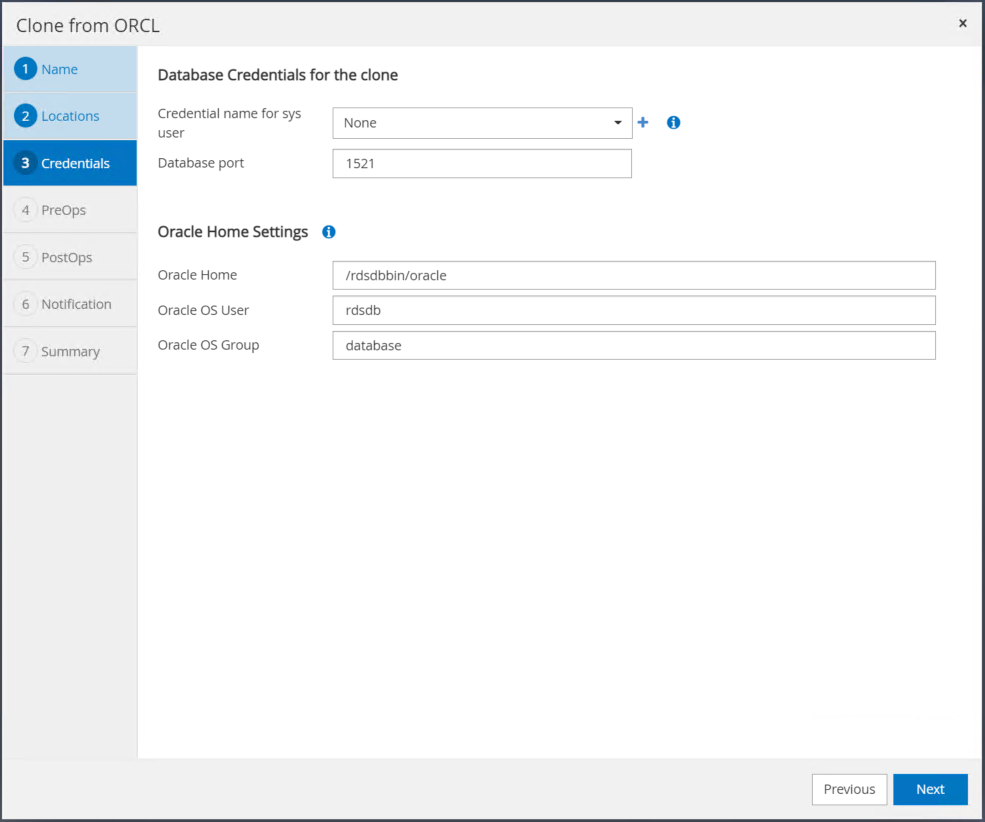
Modifiez vos paramètres d'accueil Oracle pour qu'ils correspondent à ceux configurés pour l'hôte du serveur Oracle cible, puis cliquez sur Suivant.
-
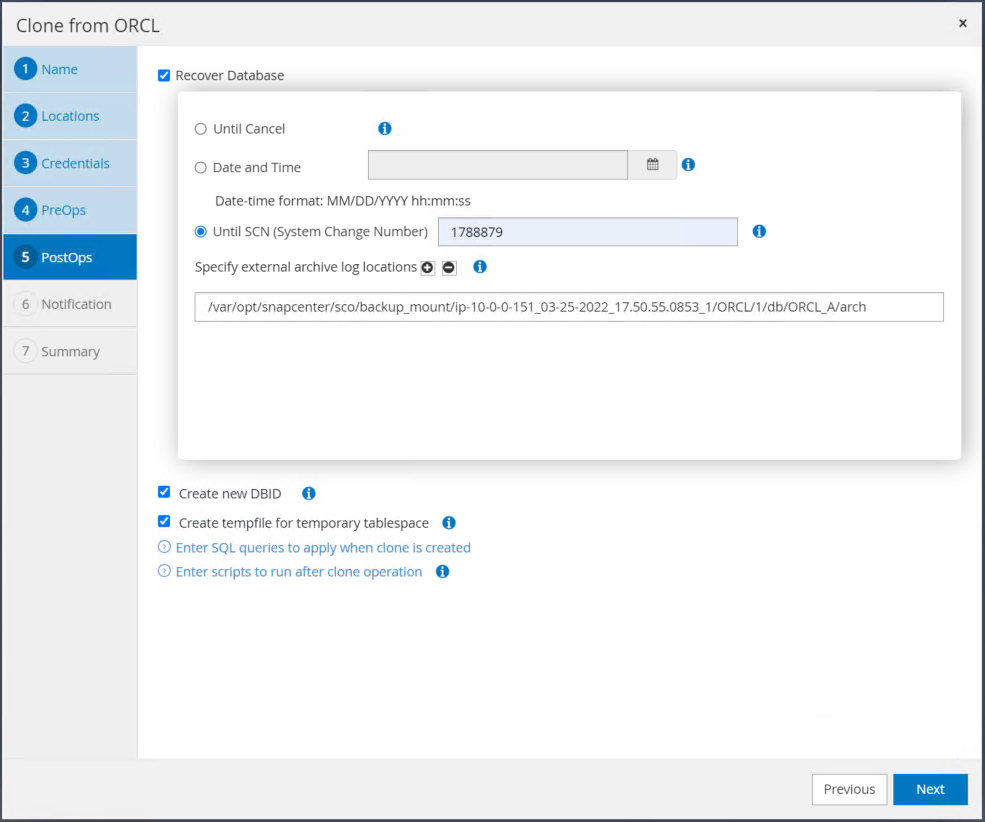
Spécifiez un point de récupération en utilisant l'heure ou le SCN et le chemin du journal d'archive monté.
-
Envoyez les paramètres de messagerie SMTP si nécessaire.
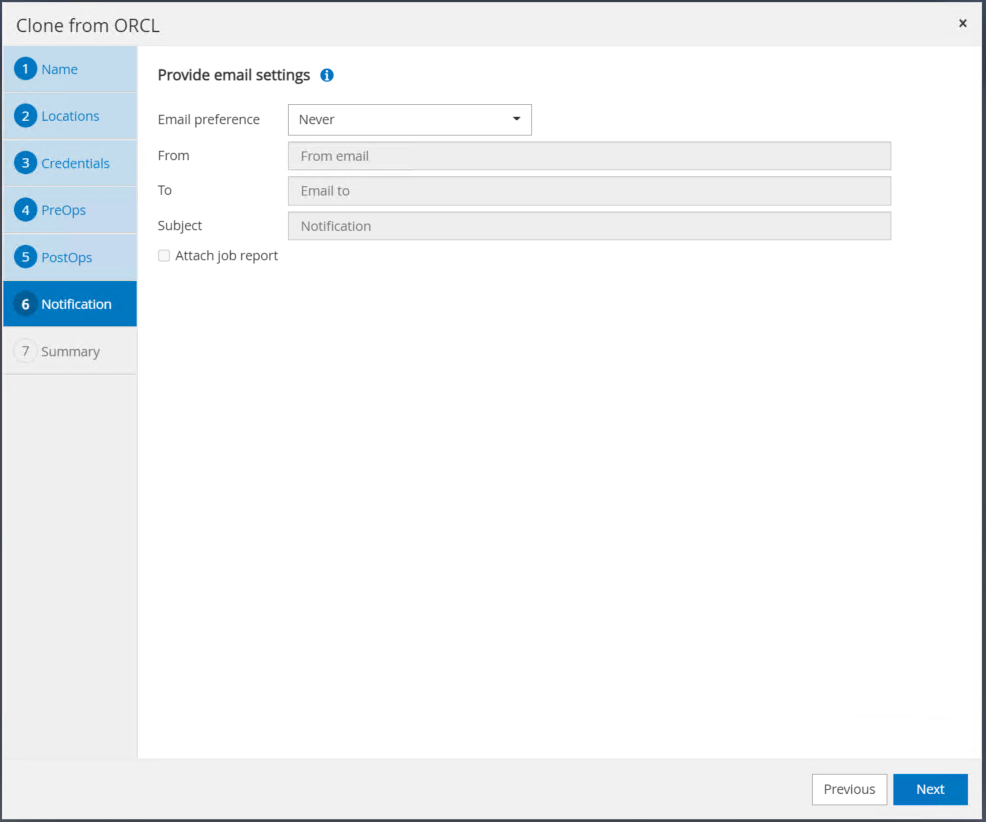
-
Clonez le résumé du travail et cliquez sur Terminer pour lancer le travail de clonage.
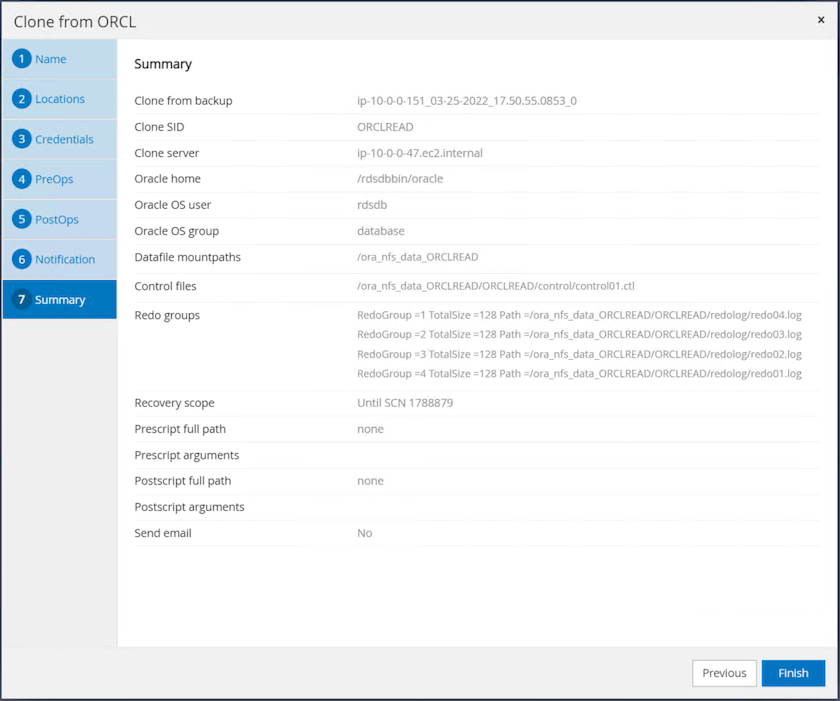
-
Validez le clone de réplique en examinant le journal des tâches de clonage.
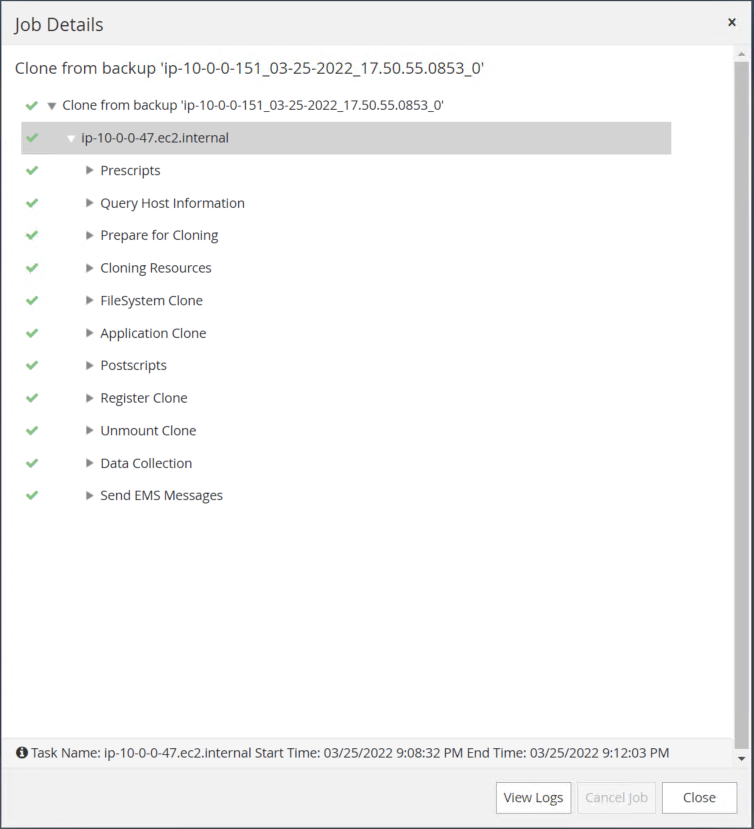
La base de données clonée est immédiatement enregistrée dans SnapCenter .
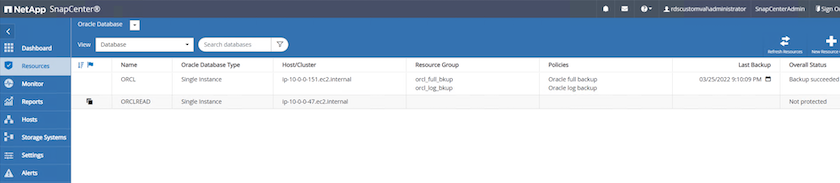
-
Désactivez le mode journal d'archivage Oracle. Connectez-vous à l'instance EC2 en tant qu'utilisateur Oracle et exécutez la commande suivante :
sqlplus / as sysdbashutdown immediate;startup mount;alter database noarchivelog;alter database open;

|
Au lieu de copies de sauvegarde Oracle principales, un clone peut également être créé à partir de copies de sauvegarde secondaires répliquées sur le cluster FSx cible avec les mêmes procédures. |
Basculement HA vers le mode veille et resynchronisation
Le cluster Oracle HA de secours offre une haute disponibilité en cas de panne du site principal, soit au niveau de la couche de calcul, soit au niveau de la couche de stockage. L’un des avantages majeurs de la solution est qu’un utilisateur peut tester et valider l’infrastructure à tout moment ou à n’importe quelle fréquence. Le basculement peut être simulé par l'utilisateur ou déclenché par une panne réelle. Les processus de basculement sont identiques et peuvent être automatisés pour une récupération rapide des applications.
Consultez la liste suivante des procédures de basculement :
-
Pour un basculement simulé, exécutez une sauvegarde instantanée du journal pour vider les dernières transactions sur le site de secours, comme illustré dans la sectionPrendre un instantané du journal d'archive . Pour un basculement déclenché par une panne réelle, les dernières données récupérables sont répliquées sur le site de secours avec la dernière sauvegarde planifiée réussie du volume de journal.
-
Rompre le SnapMirror entre le cluster FSx principal et de secours.
-
Montez les volumes de base de données de secours répliqués sur l’hôte d’instance EC2 de secours.
-
Reliez le binaire Oracle si le binaire Oracle répliqué est utilisé pour la récupération Oracle.
-
Récupérez la base de données Oracle de secours vers le dernier journal d'archive disponible.
-
Ouvrez la base de données Oracle de secours pour l'accès des applications et des utilisateurs.
-
En cas de panne réelle du site principal, la base de données Oracle de secours prend désormais le rôle du nouveau site principal et les volumes de base de données peuvent être utilisés pour reconstruire le site principal défaillant en tant que nouveau site de secours avec la méthode SnapMirror inversée.
-
Pour une défaillance simulée du site principal à des fins de test ou de validation, arrêtez la base de données Oracle de secours une fois les exercices de test terminés. Démontez ensuite les volumes de base de données de secours de l'hôte d'instance EC2 de secours et resynchronisez la réplication du site principal vers le site de secours.
Ces procédures peuvent être effectuées avec le NetApp Automation Toolkit disponible en téléchargement sur le site public NetApp GitHub.
git clone https://github.com/NetApp-Automation/na_ora_hadr_failover_resync.gitLisez attentivement les instructions README avant de tenter la configuration et le test de basculement.