Procédures de déploiement Oracle étape par étape sur AWS EC2 et FSx
 Suggérer des modifications
Suggérer des modifications
Cette section décrit les procédures de déploiement de la base de données personnalisée Oracle RDS avec le stockage FSx.
Déployer une instance EC2 Linux pour Oracle via la console EC2
Si vous êtes nouveau sur AWS, vous devez d’abord configurer un environnement AWS. L'onglet de documentation sur la page de destination du site Web AWS fournit des liens d'instructions EC2 sur la façon de déployer une instance Linux EC2 qui peut être utilisée pour héberger votre base de données Oracle via la console AWS EC2. La section suivante est un résumé de ces étapes. Pour plus de détails, consultez la documentation spécifique à AWS EC2.
Configuration de votre environnement AWS EC2
Vous devez créer un compte AWS pour provisionner les ressources nécessaires à l'exécution de votre environnement Oracle sur le service EC2 et FSx. La documentation AWS suivante fournit les détails nécessaires :
Thèmes clés :
-
Inscrivez-vous à AWS.
-
Créer une paire de clés.
-
Créer un groupe de sécurité.
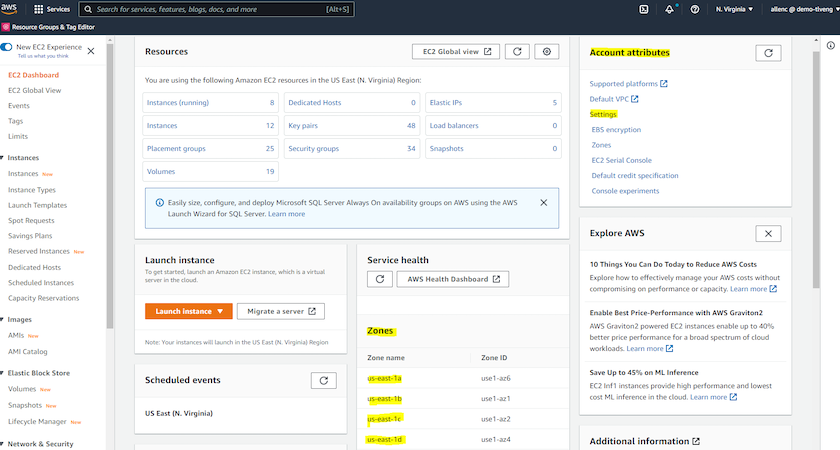
Activation de plusieurs zones de disponibilité dans les attributs de compte AWS
Pour une configuration de haute disponibilité Oracle telle que démontrée dans le diagramme d'architecture, vous devez activer au moins quatre zones de disponibilité dans une région. Les zones de disponibilité multiples peuvent également être situées dans différentes régions pour répondre aux distances requises pour la reprise après sinistre.
Création et connexion à une instance EC2 pour l'hébergement d'une base de données Oracle
Voir le tutoriel"Démarrer avec les instances Linux Amazon EC2" pour les procédures de déploiement étape par étape et les meilleures pratiques.
Thèmes clés :
-
Aperçu.
-
Prérequis.
-
Étape 1 : Lancer une instance.
-
Étape 2 : connectez-vous à votre instance.
-
Étape 3 : Nettoyez votre instance.
Les captures d’écran suivantes illustrent le déploiement d’une instance Linux de type m5 avec la console EC2 pour exécuter Oracle.
-
Depuis le tableau de bord EC2, cliquez sur le bouton jaune Lancer l’instance pour démarrer le workflow de déploiement de l’instance EC2.
-
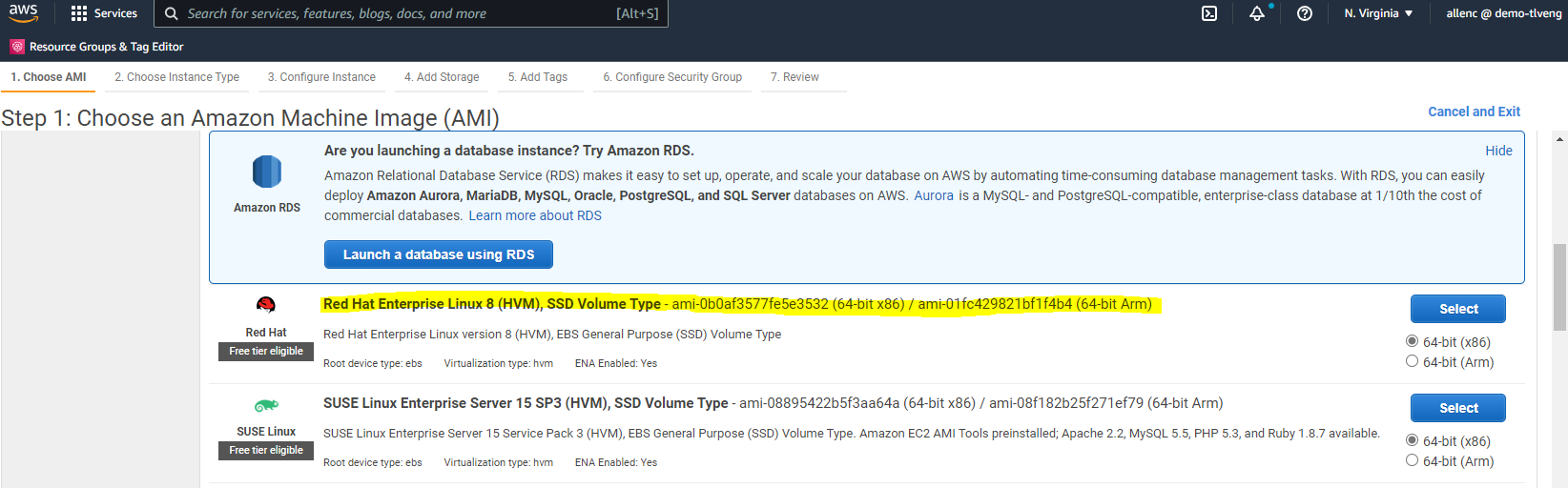
À l'étape 1, sélectionnez « Red Hat Enterprise Linux 8 (HVM), type de volume SSD - ami-0b0af3577fe5e3532 (64 bits x86) / ami-01fc429821bf1f4b4 (64 bits Arm) ».
-
À l’étape 2, sélectionnez un type d’instance m5 avec l’allocation de CPU et de mémoire appropriée en fonction de la charge de travail de votre base de données Oracle. Cliquez sur « Suivant : Configurer les détails de l’instance ».
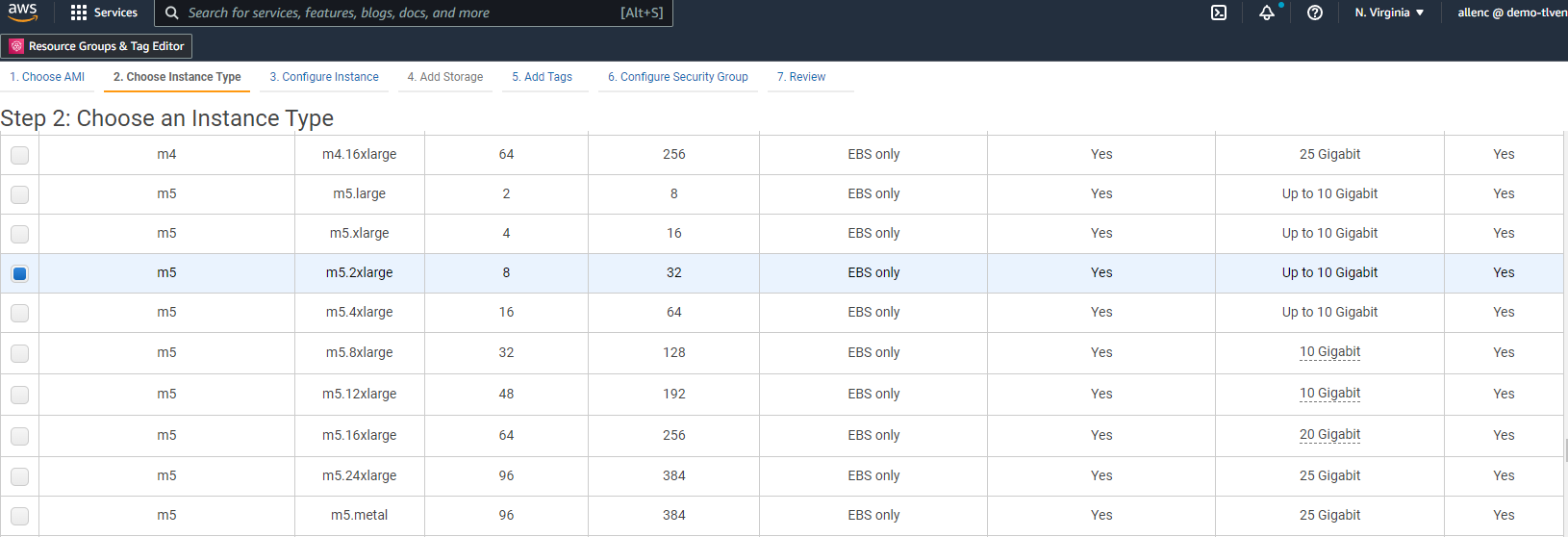
-
À l’étape 3, choisissez le VPC et le sous-réseau où l’instance doit être placée et activez l’attribution d’adresse IP publique. Cliquez sur « Suivant : Ajouter du stockage ».
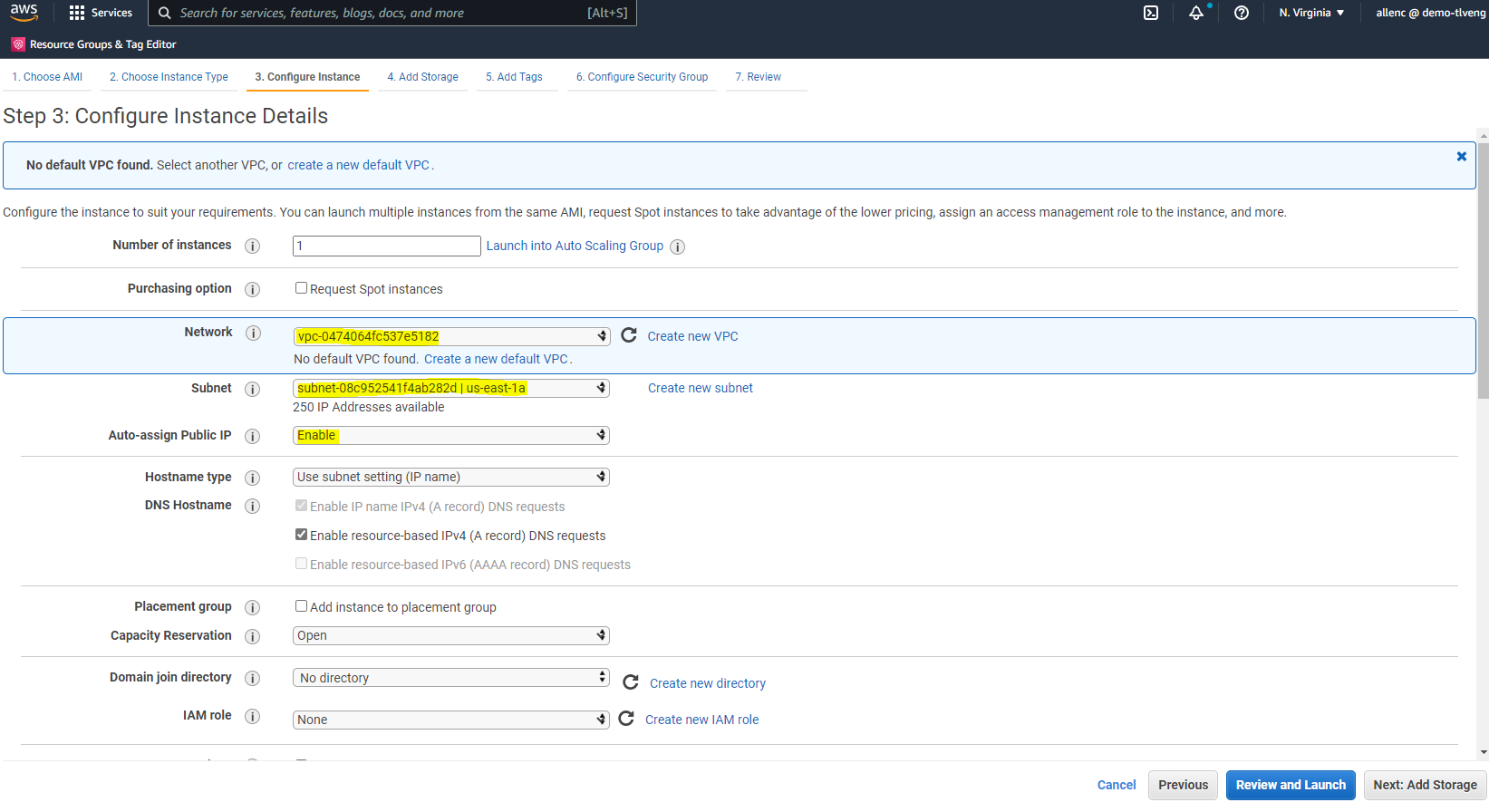
-
À l’étape 4, allouez suffisamment d’espace pour le disque racine. Vous aurez peut-être besoin d’espace pour ajouter un échange. Par défaut, l'instance EC2 attribue un espace de swap nul, ce qui n'est pas optimal pour l'exécution d'Oracle.
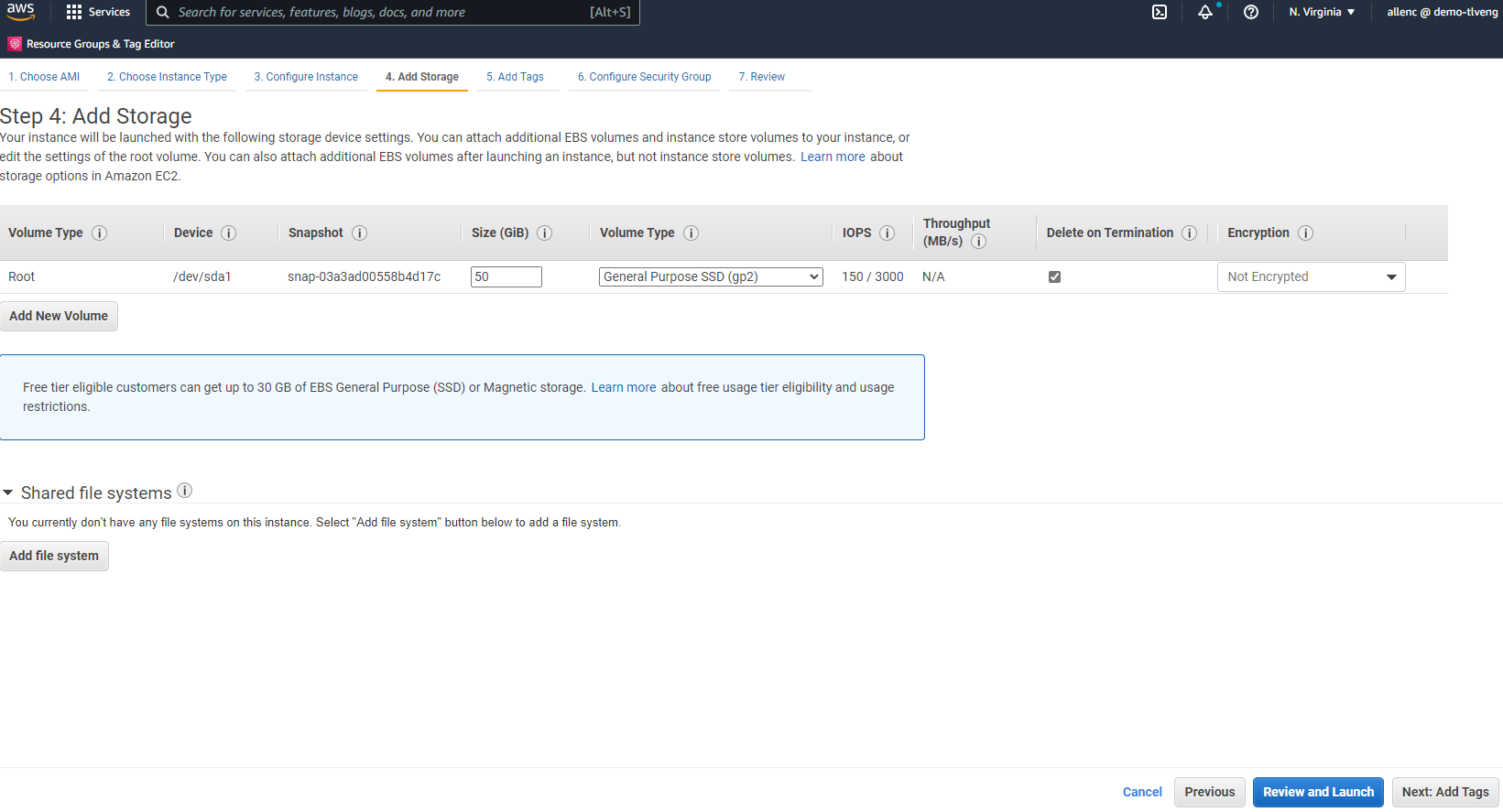
-
À l’étape 5, ajoutez une balise pour l’identification de l’instance si nécessaire.
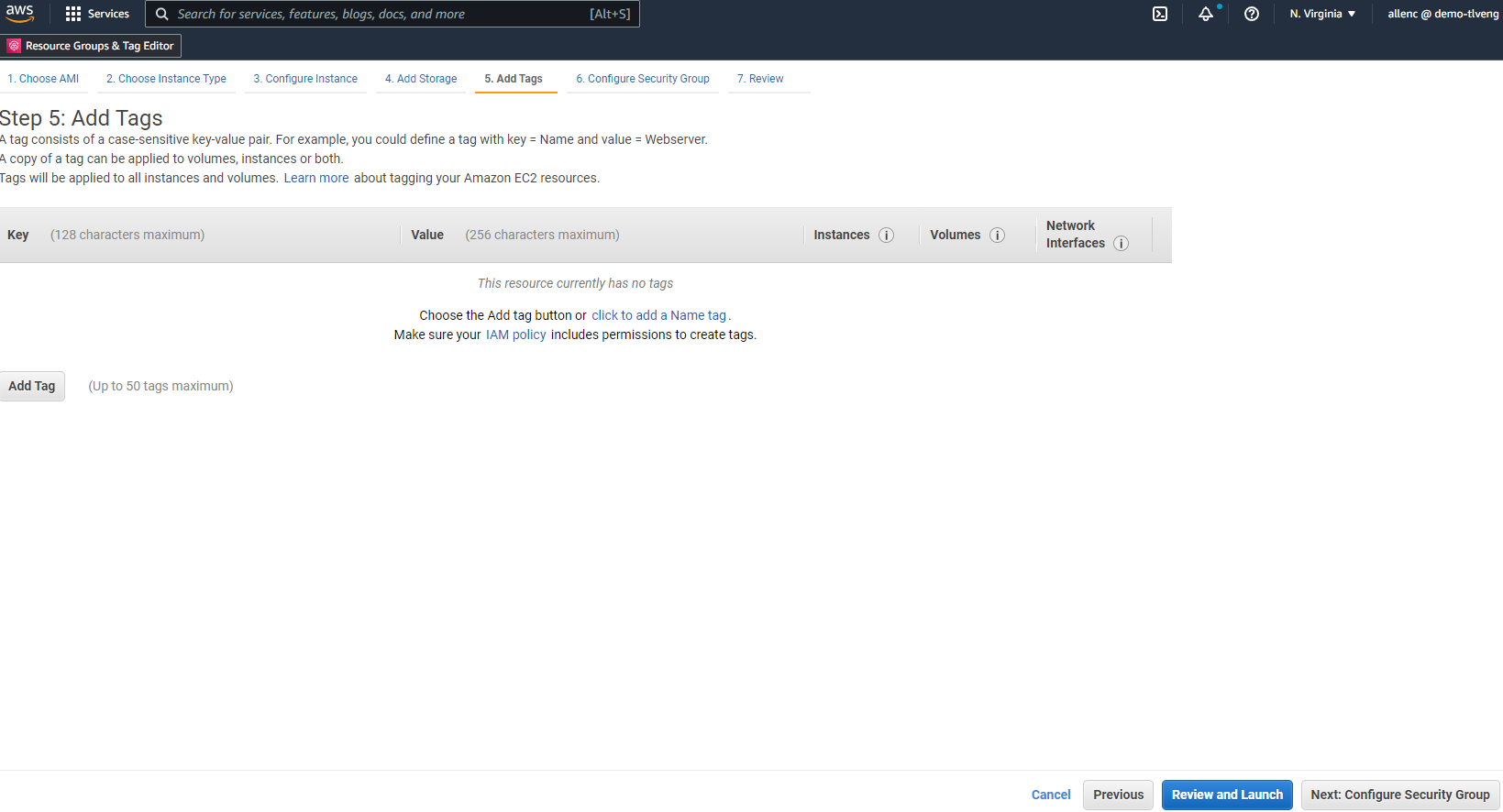
-
À l’étape 6, sélectionnez un groupe de sécurité existant ou créez-en un nouveau avec la politique entrante et sortante souhaitée pour l’instance.
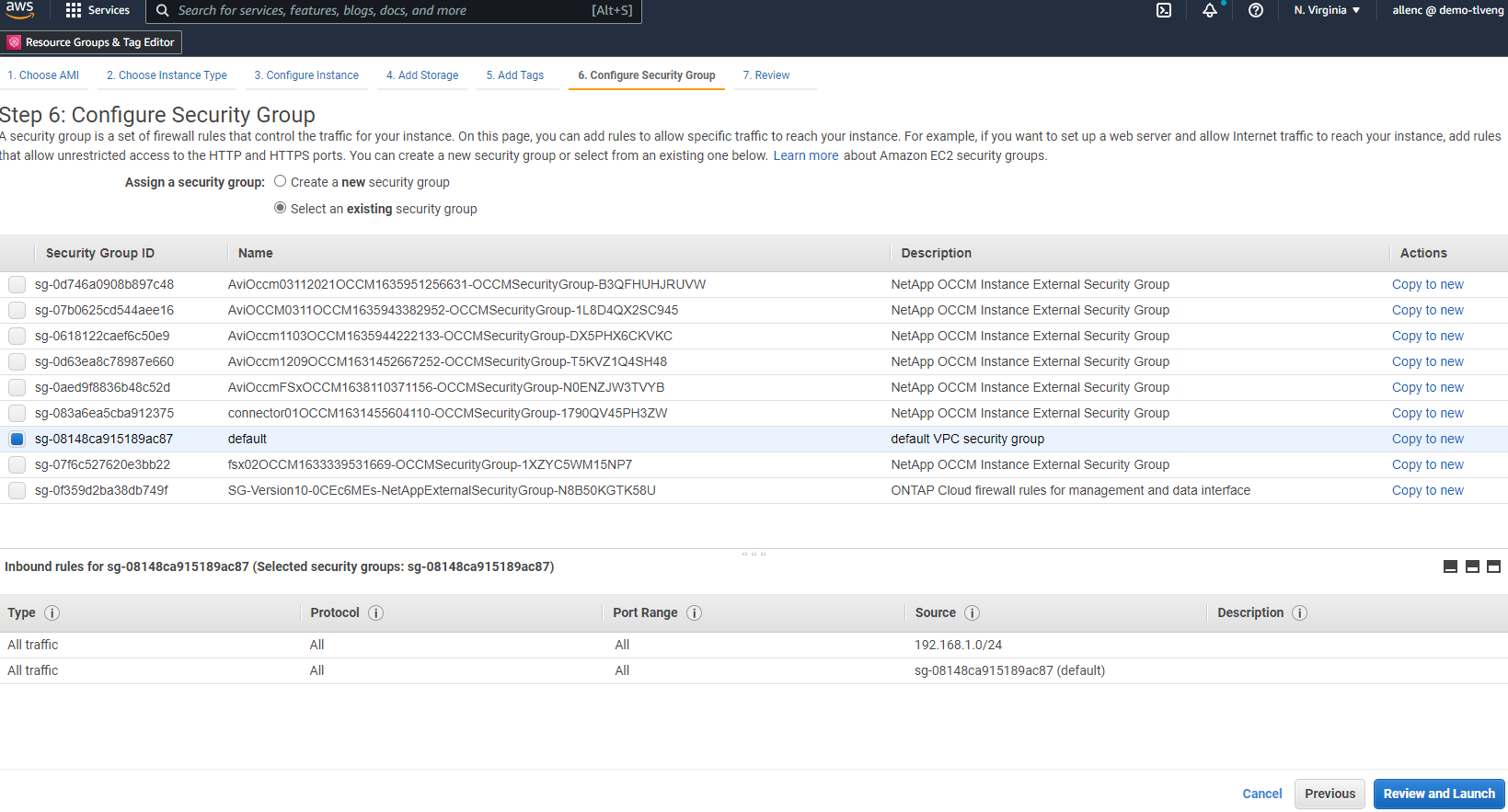
-
À l’étape 7, examinez le résumé de la configuration de l’instance et cliquez sur Lancer pour démarrer le déploiement de l’instance. Vous êtes invité à créer une paire de clés ou à sélectionner une paire de clés pour accéder à l'instance.
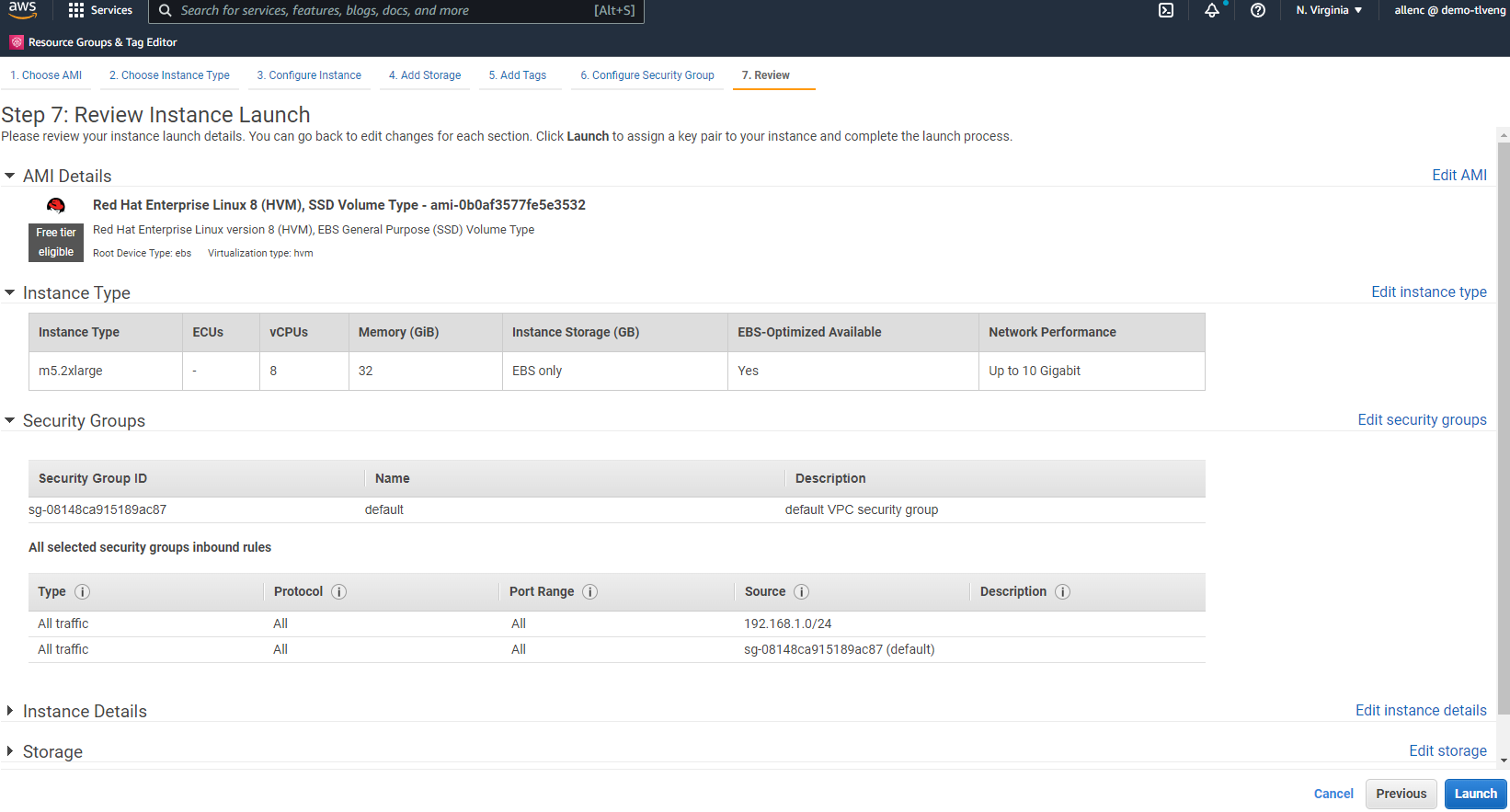
-
Connectez-vous à l’instance EC2 à l’aide d’une paire de clés SSH. Apportez les modifications appropriées au nom de votre clé et à l’adresse IP de votre instance.
ssh -i ora-db1v2.pem ec2-user@54.80.114.77
Vous devez créer deux instances EC2 en tant que serveurs Oracle principal et de secours dans leur zone de disponibilité désignée, comme illustré dans le diagramme d'architecture.
Provisionner les systèmes de fichiers FSx ONTAP pour le stockage de bases de données Oracle
Le déploiement d’instance EC2 alloue un volume racine EBS pour le système d’exploitation. Les systèmes de fichiers FSx ONTAP fournissent des volumes de stockage de base de données Oracle, y compris les volumes binaires, de données et de journaux Oracle. Les volumes NFS de stockage FSx peuvent être provisionnés à partir de la console AWS FSx ou à partir de l'installation Oracle et de l'automatisation de la configuration qui alloue les volumes selon la configuration de l'utilisateur dans un fichier de paramètres d'automatisation.
Création de systèmes de fichiers FSx ONTAP
Référé à cette documentation "Gestion des systèmes de fichiers FSx ONTAP" pour créer des systèmes de fichiers FSx ONTAP .
Considérations clés :
-
Capacité de stockage SSD. Minimum 1 024 Gio, maximum 192 Tio.
-
IOPS SSD provisionnés. En fonction des exigences de charge de travail, un maximum de 80 000 IOPS SSD par système de fichiers.
-
Capacité de débit.
-
Définir le mot de passe administrateur fsxadmin/vsadmin. Requis pour l'automatisation de la configuration FSx.
-
Sauvegarde et maintenance. Désactivez les sauvegardes quotidiennes automatiques ; la sauvegarde du stockage de la base de données est exécutée via la planification SnapCenter .
-
Récupérez l'adresse IP de gestion SVM ainsi que les adresses d'accès spécifiques au protocole à partir de la page des détails SVM. Requis pour l'automatisation de la configuration FSx.
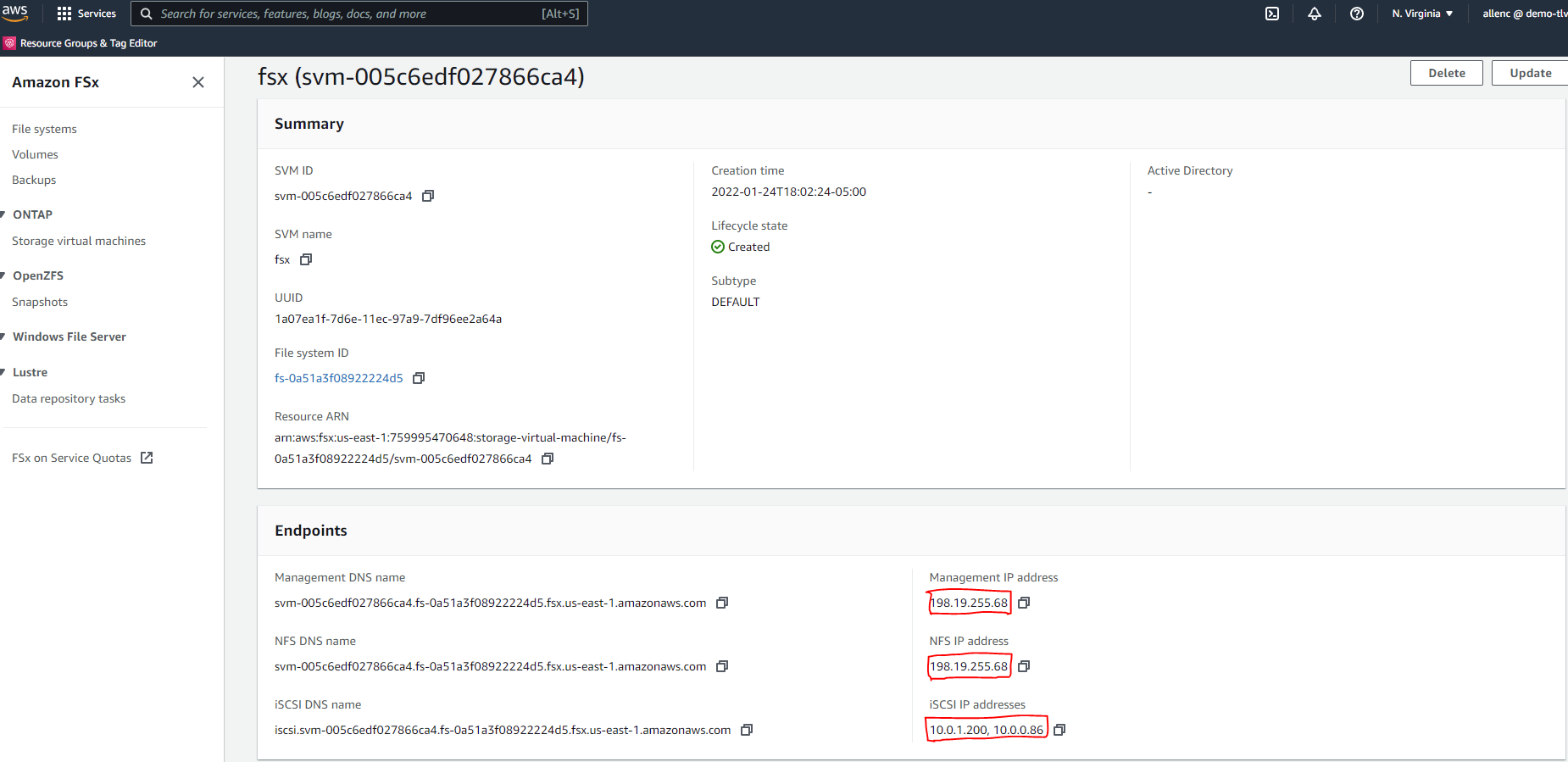
Consultez les procédures étape par étape suivantes pour configurer un cluster HA FSx principal ou de secours.
-
Depuis la console FSx, cliquez sur Créer un système de fichiers pour démarrer le flux de travail de provisionnement FSx.
-
Sélectionnez Amazon FSx ONTAP. Cliquez ensuite sur Suivant.
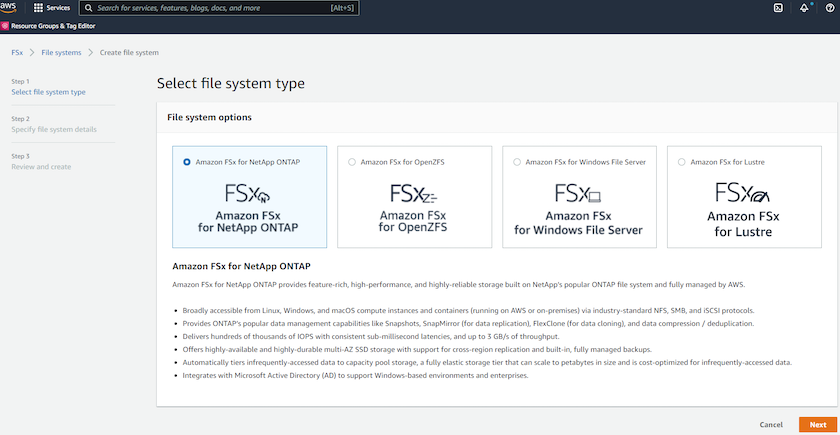
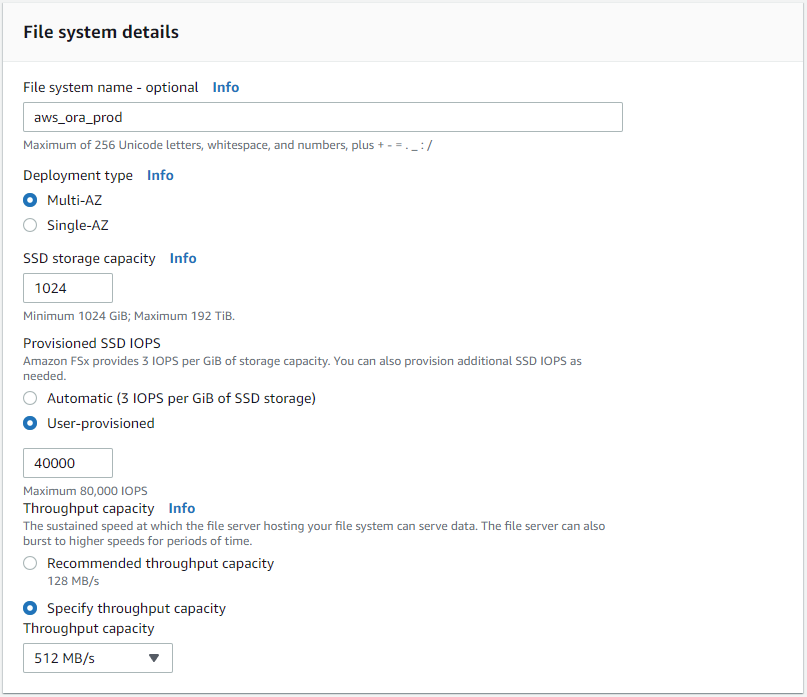
-
Sélectionnez Création standard et, dans Détails du système de fichiers, nommez votre système de fichiers, Multi-AZ HA. En fonction de la charge de travail de votre base de données, choisissez des IOPS automatiques ou provisionnées par l'utilisateur jusqu'à 80 000 IOPS SSD. Le stockage FSx est livré avec jusqu'à 2 TiB de mise en cache NVMe au niveau du backend, ce qui peut fournir des IOPS mesurées encore plus élevées.
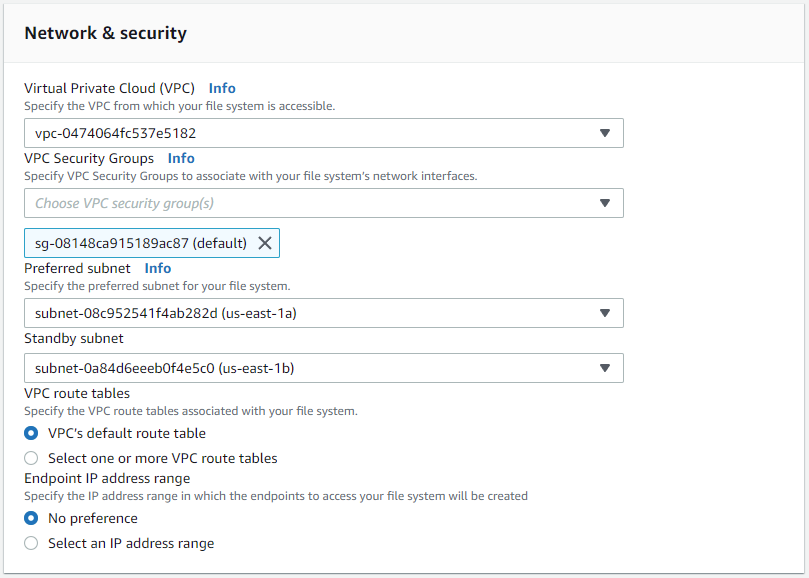
-
Dans la section Réseau et sécurité, sélectionnez le VPC, le groupe de sécurité et les sous-réseaux. Ceux-ci doivent être créés avant le déploiement de FSx. En fonction du rôle du cluster FSx (principal ou de secours), placez les nœuds de stockage FSx dans les zones appropriées.
-
Dans la section Sécurité et chiffrement, acceptez la valeur par défaut et entrez le mot de passe fsxadmin.
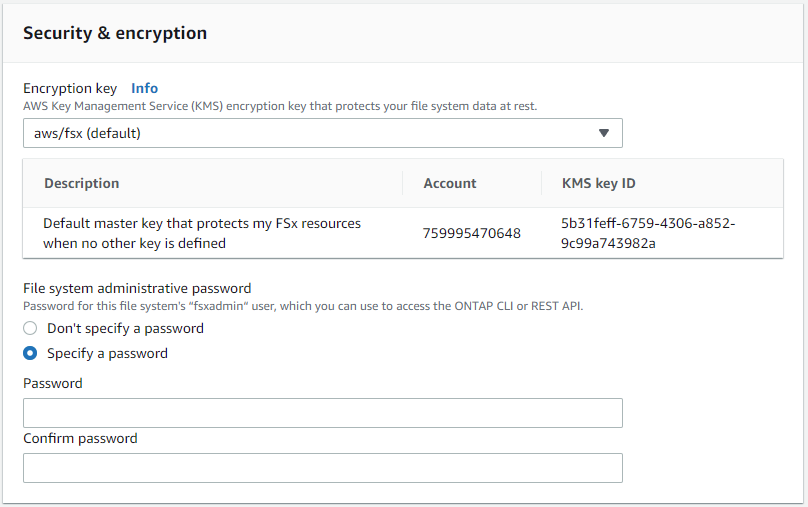
-
Entrez le nom SVM et le mot de passe vsadmin.
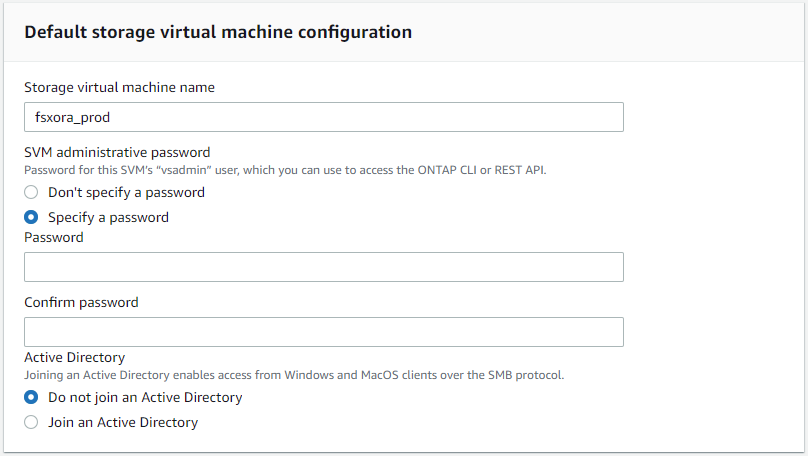
-
Laissez la configuration du volume vide ; vous n’avez pas besoin de créer de volume à ce stade.
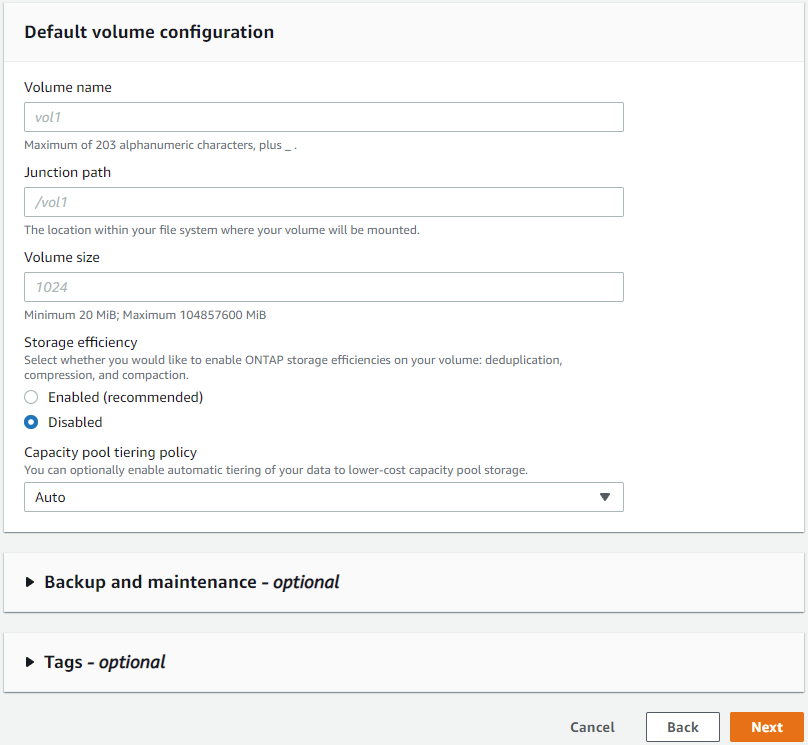
-
Consultez la page Résumé et cliquez sur Créer un système de fichiers pour terminer la mise à disposition du système de fichiers FSx.
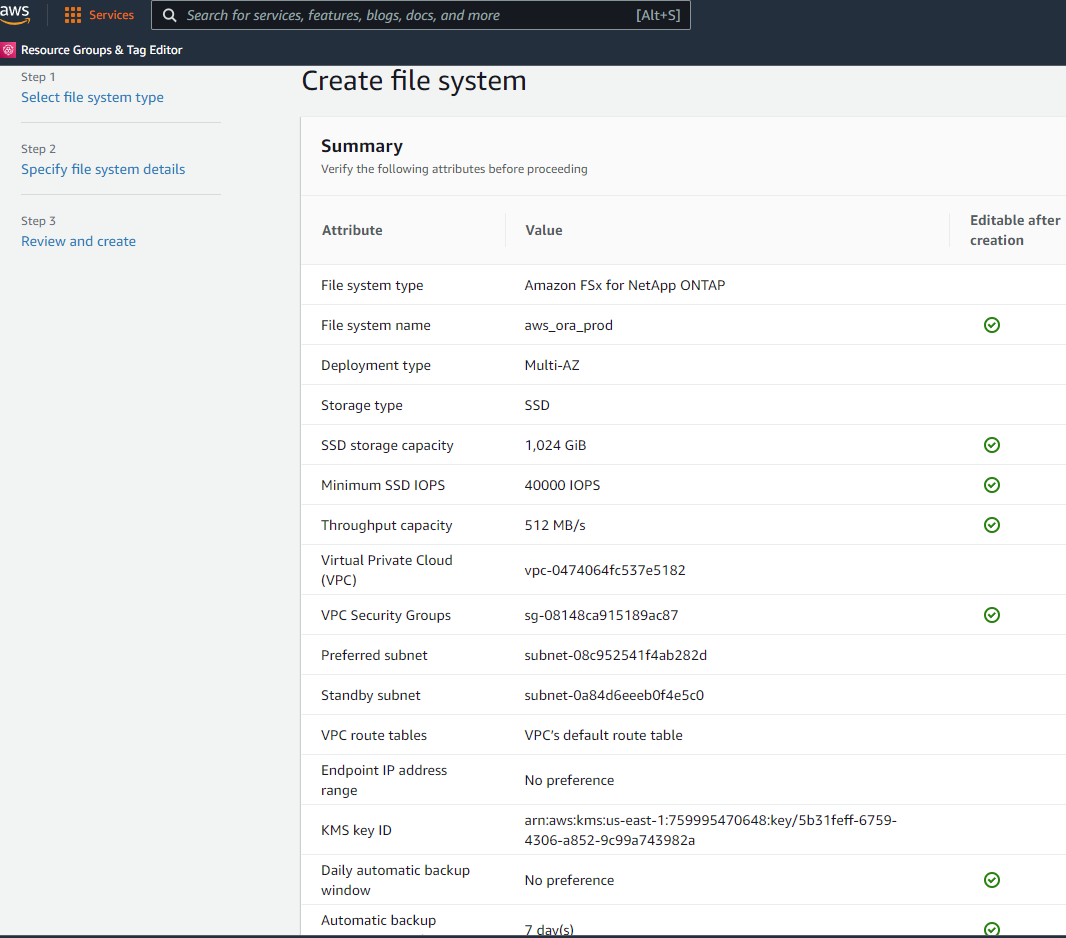
Provisionnement de volumes de base de données pour la base de données Oracle
Voir"Gestion des volumes FSx ONTAP – création d'un volume" pour plus de détails.
Considérations clés :
-
Dimensionner les volumes de base de données de manière appropriée.
-
Désactivation de la stratégie de hiérarchisation du pool de capacité pour la configuration des performances.
-
Activation d'Oracle dNFS pour les volumes de stockage NFS.
-
Configuration de multipath pour les volumes de stockage iSCSI.
Créer un volume de base de données à partir de la console FSx
À partir de la console AWS FSx, vous pouvez créer trois volumes pour le stockage des fichiers de base de données Oracle : un pour le binaire Oracle, un pour les données Oracle et un pour le journal Oracle. Assurez-vous que le nom du volume correspond au nom d'hôte Oracle (défini dans le fichier hosts de la boîte à outils d'automatisation) pour une identification correcte. Dans cet exemple, nous utilisons db1 comme nom d'hôte Oracle EC2 au lieu d'un nom d'hôte basé sur une adresse IP classique pour une instance EC2.
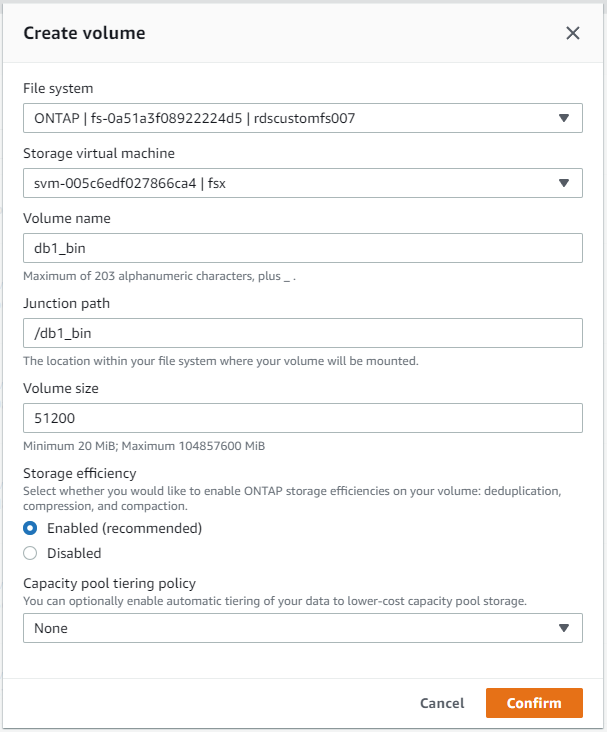
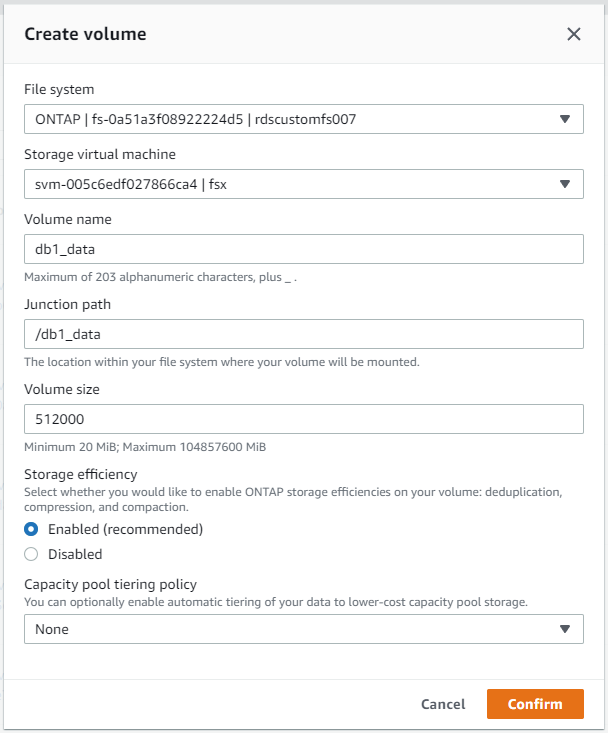
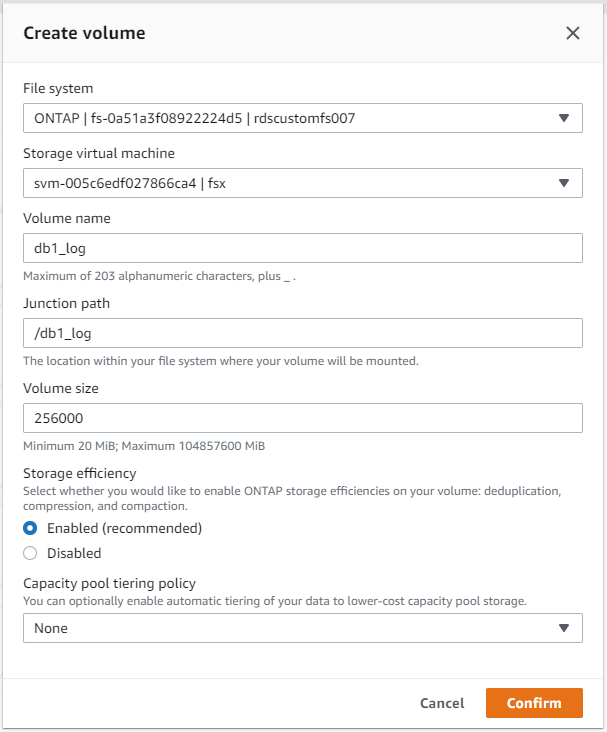

|
La création de LUN iSCSI n'est actuellement pas prise en charge par la console FSx. Pour le déploiement des LUN iSCSI pour Oracle, les volumes et les LUN peuvent être créés à l'aide de l'automatisation pour ONTAP avec NetApp Automation Toolkit. |
Installer et configurer Oracle sur une instance EC2 avec des volumes de base de données FSx
L'équipe d'automatisation NetApp fournit un kit d'automatisation pour exécuter l'installation et la configuration d'Oracle sur les instances EC2 conformément aux meilleures pratiques. La version actuelle du kit d'automatisation prend en charge Oracle 19c sur NFS avec le patch RU par défaut 19.8. Le kit d'automatisation peut être facilement adapté à d'autres patchs RU si nécessaire.
Préparer un contrôleur Ansible pour exécuter l'automatisation
Suivez les instructions dans la section «Création et connexion à une instance EC2 pour l'hébergement d'une base de données Oracle " pour provisionner une petite instance Linux EC2 pour exécuter le contrôleur Ansible. Plutôt que d'utiliser RedHat, Amazon Linux t2.large avec 2vCPU et 8G RAM devrait être suffisant.
Récupérer la boîte à outils d'automatisation du déploiement NetApp Oracle
Connectez-vous à l'instance du contrôleur EC2 Ansible provisionnée à l'étape 1 en tant qu'utilisateur ec2 et à partir du répertoire personnel ec2-user, exécutez la commande git clone commande pour cloner une copie du code d'automatisation.
git clone https://github.com/NetApp-Automation/na_oracle19c_deploy.gitgit clone https://github.com/NetApp-Automation/na_rds_fsx_oranfs_config.gitExécuter un déploiement automatisé d'Oracle 19c à l'aide de la boîte à outils d'automatisation
Voir ces instructions détaillées"Déploiement CLI de la base de données Oracle 19c" pour déployer Oracle 19c avec l'automatisation CLI. Il y a un petit changement dans la syntaxe de commande pour l'exécution du playbook car vous utilisez une paire de clés SSH au lieu d'un mot de passe pour l'authentification de l'accès à l'hôte. La liste suivante est un résumé de haut niveau :
-
Par défaut, une instance EC2 utilise une paire de clés SSH pour l’authentification d’accès. À partir des répertoires racines d'automatisation du contrôleur Ansible
/home/ec2-user/na_oracle19c_deploy, et/home/ec2-user/na_rds_fsx_oranfs_config, faire une copie de la clé SSHaccesststkey.pempour l'hôte Oracle déployé à l'étape «Création et connexion à une instance EC2 pour l'hébergement d'une base de données Oracle ." -
Connectez-vous à l'hôte de la base de données de l'instance EC2 en tant qu'utilisateur ec2 et installez la bibliothèque python3.
sudo yum install python3 -
Créez un espace d’échange de 16 Go à partir du lecteur de disque racine. Par défaut, une instance EC2 crée un espace de swap nul. Suivez cette documentation AWS :"Comment allouer de la mémoire pour fonctionner comme espace d'échange dans une instance Amazon EC2 à l'aide d'un fichier d'échange ?" .
-
Retour au contrôleur Ansible(
cd /home/ec2-user/na_rds_fsx_oranfs_config), et exécutez le playbook de préclonage avec les exigences appropriées etlinux_configbalises.ansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t requirements_configansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t linux_config -
Passer au
/home/ec2-user/na_oracle19c_deploy-masterrépertoire, lisez le fichier README et remplissez le fichier globalvars.ymlfichier avec les paramètres globaux pertinents. -
Remplir le
host_name.ymlfichier avec les paramètres pertinents dans lehost_varsannuaire. -
Exécutez le playbook pour Linux et appuyez sur Entrée lorsque vous êtes invité à saisir le mot de passe vsadmin.
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t linux_config -e @vars/vars.yml -
Exécutez le playbook pour Oracle et appuyez sur Entrée lorsque vous êtes invité à saisir le mot de passe vsadmin.
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t oracle_config -e @vars/vars.yml
Modifiez le bit d'autorisation sur le fichier de clé SSH à 400 si nécessaire. Changer l'hôte Oracle(ansible_host dans le host_vars fichier) Adresse IP vers l'adresse publique de votre instance EC2.
Configuration de SnapMirror entre le cluster FSx HA principal et le cluster FSx HA de secours
Pour une haute disponibilité et une reprise après sinistre, vous pouvez configurer la réplication SnapMirror entre le cluster de stockage FSx principal et de secours. Contrairement à d’autres services de stockage cloud, FSx permet à un utilisateur de contrôler et de gérer la réplication du stockage à la fréquence et au débit de réplication souhaités. Il permet également aux utilisateurs de tester HA/DR sans aucun effet sur la disponibilité.
Les étapes suivantes montrent comment configurer la réplication entre un cluster de stockage FSx principal et de secours.
-
Configurer l'appairage des clusters principaux et de secours. Connectez-vous au cluster principal en tant qu’utilisateur fsxadmin et exécutez la commande suivante. Ce processus de création réciproque exécute la commande de création sur le cluster principal et le cluster de secours. Remplacer
standby_cluster_nameavec le nom approprié à votre environnement.cluster peer create -peer-addrs standby_cluster_name,inter_cluster_ip_address -username fsxadmin -initial-allowed-vserver-peers * -
Configurez le peering vServer entre le cluster principal et le cluster de secours. Connectez-vous au cluster principal en tant qu’utilisateur vsadmin et exécutez la commande suivante. Remplacer
primary_vserver_name,standby_vserver_name,standby_cluster_nameavec les noms appropriés à votre environnement.vserver peer create -vserver primary_vserver_name -peer-vserver standby_vserver_name -peer-cluster standby_cluster_name -applications snapmirror -
Vérifiez que les peerings du cluster et du serveur virtuel sont correctement configurés.
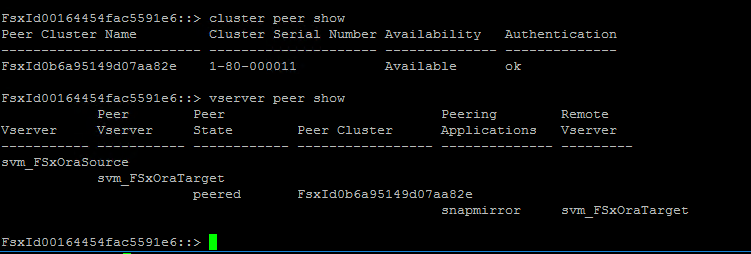
-
Créez des volumes NFS cibles sur le cluster FSx de secours pour chaque volume source sur le cluster FSx principal. Remplacez le nom du volume en fonction de votre environnement.
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -type DPvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -type DPvol create -volume dr_db1_log -aggregate aggr1 -size 250G -state online -policy default -type DP -
Vous pouvez également créer des volumes iSCSI et des LUN pour le binaire Oracle, les données Oracle et le journal Oracle si le protocole iSCSI est utilisé pour l'accès aux données. Laissez environ 10 % d’espace libre dans les volumes pour les instantanés.
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_bin/dr_db1_bin_01 -size 45G -ostype linuxvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_data/dr_db1_data_01 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_02 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_03 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_04 -size 100G -ostype linuxvol create -volume dr_db1_log -aggregate aggr1 -size 250G -state online -policy default -unix-permissions ---rwxr-xr-x -type RW
lun create -path /vol/dr_db1_log/dr_db1_log_01 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_02 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_03 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_04 -size 45G -ostype linux -
Pour les LUN iSCSI, créez un mappage pour l'initiateur d'hôte Oracle pour chaque LUN, en utilisant le LUN binaire comme exemple. Remplacez le groupe igroup par un nom approprié pour votre environnement et incrémentez le lun-id pour chaque LUN supplémentaire.
lun mapping create -path /vol/dr_db1_bin/dr_db1_bin_01 -igroup ip-10-0-1-136 -lun-id 0lun mapping create -path /vol/dr_db1_data/dr_db1_data_01 -igroup ip-10-0-1-136 -lun-id 1 -
Créez une relation SnapMirror entre les volumes de base de données principal et de secours. Remplacez le nom SVM approprié pour votre environnement.
snapmirror create -source-path svm_FSxOraSource:db1_bin -destination-path svm_FSxOraTarget:dr_db1_bin -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_data -destination-path svm_FSxOraTarget:dr_db1_data -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_log -destination-path svm_FSxOraTarget:dr_db1_log -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DP
Cette configuration SnapMirror peut être automatisée avec un kit d’outils d’automatisation NetApp pour les volumes de base de données NFS. La boîte à outils est disponible en téléchargement sur le site GitHub public de NetApp .
git clone https://github.com/NetApp-Automation/na_ora_hadr_failover_resync.gitLisez attentivement les instructions README avant de tenter la configuration et le test de basculement.
|
|
La réplication du binaire Oracle du cluster principal vers un cluster de secours peut avoir des implications sur la licence Oracle. Contactez votre représentant de licence Oracle pour obtenir des éclaircissements. L’alternative consiste à installer et configurer Oracle au moment de la récupération et du basculement. |
Déploiement de SnapCenter
Installation de SnapCenter
Suivre"Installation du serveur SnapCenter" pour installer le serveur SnapCenter . Cette documentation explique comment installer un serveur SnapCenter autonome. Une version SaaS de SnapCenter est en phase de test bêta et pourrait être disponible prochainement. Vérifiez la disponibilité auprès de votre représentant NetApp si nécessaire.
Configurer le plugin SnapCenter pour l'hôte Oracle EC2
-
Après l’installation automatisée de SnapCenter , connectez-vous à SnapCenter en tant qu’utilisateur administrateur pour l’hôte Windows sur lequel le serveur SnapCenter est installé.

-
Dans le menu de gauche, cliquez sur Paramètres, puis sur Informations d’identification et Nouveau pour ajouter les informations d’identification ec2-user pour l’installation du plug-in SnapCenter .
-
Réinitialisez le mot de passe ec2-user et activez l'authentification SSH par mot de passe en modifiant le
/etc/ssh/sshd_configfichier sur l'hôte de l'instance EC2. -
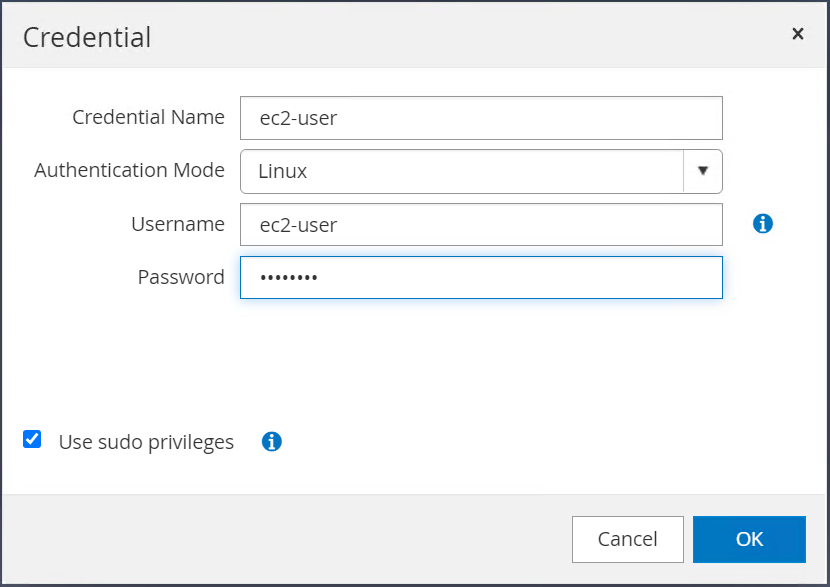
Vérifiez que la case à cocher « Utiliser les privilèges sudo » est sélectionnée. Vous venez de réinitialiser le mot de passe ec2-user à l'étape précédente.
-
Ajoutez le nom du serveur SnapCenter et l’adresse IP au fichier hôte de l’instance EC2 pour la résolution de nom.
[ec2-user@ip-10-0-0-151 ~]$ sudo vi /etc/hosts [ec2-user@ip-10-0-0-151 ~]$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.0.1.233 rdscustomvalsc.rdscustomval.com rdscustomvalsc
-
Sur l'hôte Windows du serveur SnapCenter , ajoutez l'adresse IP de l'hôte de l'instance EC2 au fichier hôte Windows
C:\Windows\System32\drivers\etc\hosts.10.0.0.151 ip-10-0-0-151.ec2.internal
-
Dans le menu de gauche, sélectionnez Hôtes > Hôtes gérés, puis cliquez sur Ajouter pour ajouter l'hôte d'instance EC2 à SnapCenter.
Vérifiez la base de données Oracle et, avant de soumettre, cliquez sur Plus d'options.
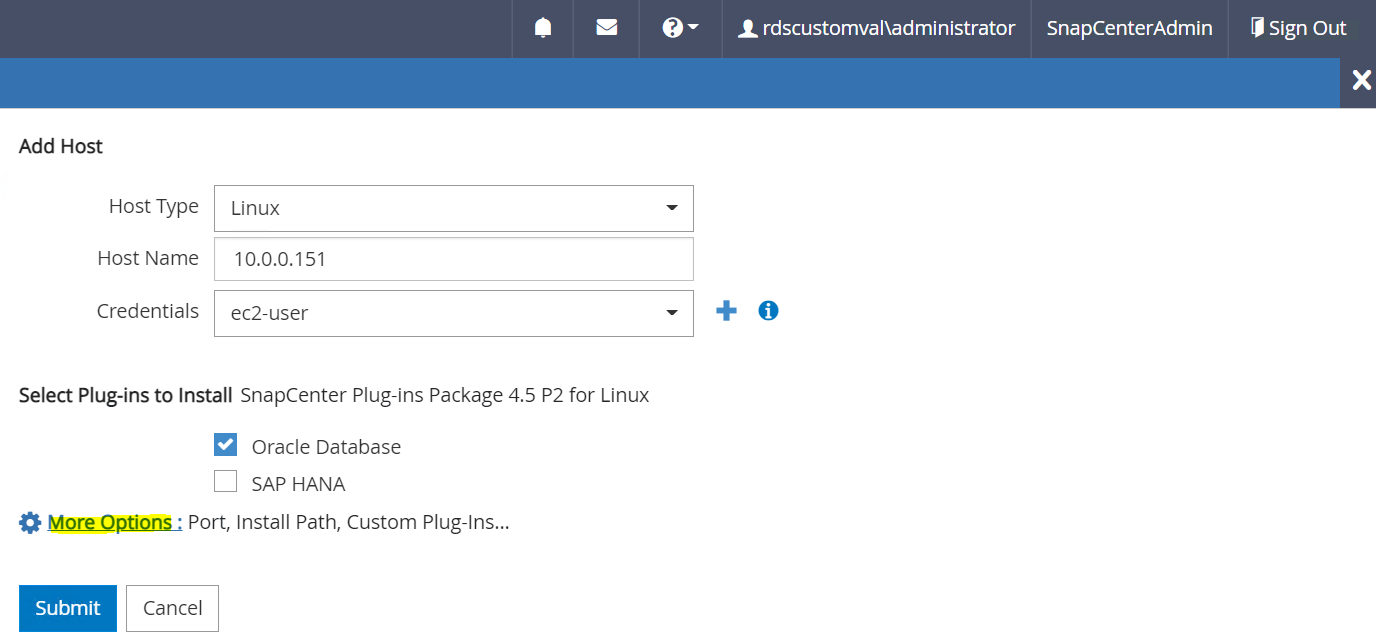
Cochez la case Ignorer les vérifications de préinstallation. Confirmez l’ignorance des vérifications de préinstallation, puis cliquez sur Soumettre après l’enregistrement.
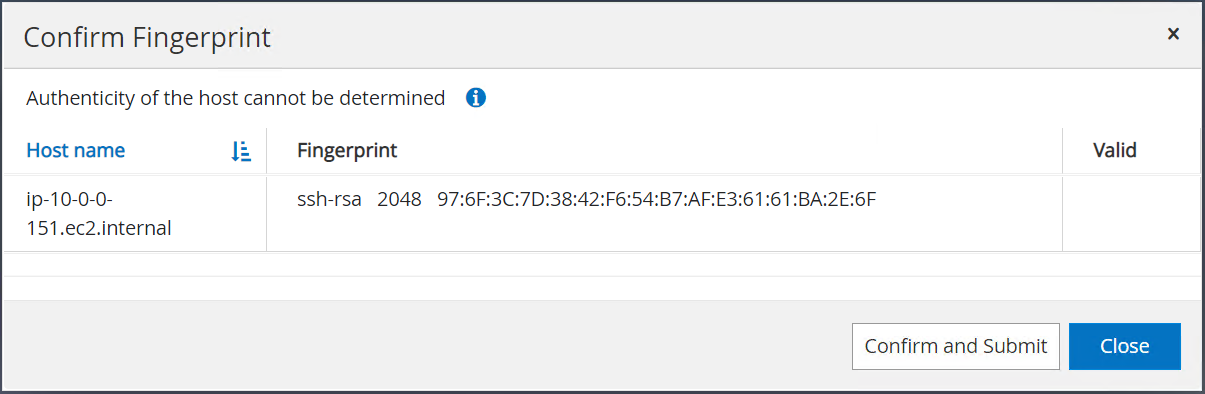
Vous êtes invité à confirmer l'empreinte digitale, puis à cliquer sur Confirmer et soumettre.
Après une configuration réussie du plug-in, l'état général de l'hôte géré s'affiche comme étant en cours d'exécution.

Configurer la politique de sauvegarde pour la base de données Oracle
Consultez cette section"Configurer la politique de sauvegarde de la base de données dans SnapCenter" pour plus de détails sur la configuration de la politique de sauvegarde de la base de données Oracle.
En règle générale, vous devez créer une politique pour la sauvegarde instantanée complète de la base de données Oracle et une politique pour la sauvegarde instantanée du journal d'archive Oracle uniquement.
|
|
Vous pouvez activer l'élagage du journal d'archive Oracle dans la politique de sauvegarde pour contrôler l'espace d'archivage du journal. Cochez « Mettre à jour SnapMirror après avoir créé une copie Snapshot locale » dans « Sélectionner l'option de réplication secondaire » car vous devez répliquer vers un emplacement de secours pour HA ou DR. |
Configurer la sauvegarde et la planification de la base de données Oracle
La sauvegarde de la base de données dans SnapCenter est configurable par l'utilisateur et peut être configurée individuellement ou en tant que groupe dans un groupe de ressources. L'intervalle de sauvegarde dépend des objectifs RTO et RPO. NetApp vous recommande d'exécuter une sauvegarde complète de la base de données toutes les quelques heures et d'archiver la sauvegarde du journal à une fréquence plus élevée, par exemple 10 à 15 minutes, pour une récupération rapide.
Reportez-vous à la section Oracle de"Mettre en œuvre une politique de sauvegarde pour protéger la base de données" pour un processus détaillé étape par étape pour la mise en œuvre de la politique de sauvegarde créée dans la sectionConfigurer la politique de sauvegarde pour la base de données Oracle et pour la planification des tâches de sauvegarde.
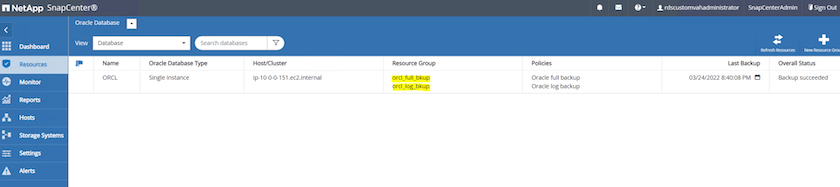
L'image suivante fournit un exemple des groupes de ressources configurés pour sauvegarder une base de données Oracle.