

Performances
 Suggérer des modifications
Suggérer des modifications
NetApp AFX a été conçu en privilégiant la performance et l'évolutivité – spécifiquement adapté aux charges de travail nécessitant un débit de lecture et d'écriture élevé et capable de fournir une mise à l'échelle simple et linéaire.
Performances par nœud
Chaque nœud de stockage NetApp AFX offre un débit spécifique en lecture et en écriture. L'ajout de nœuds au cluster augmente linéairement ces performances, comme expliqué dans la section « Évolution linéaire des performances des nœuds » de ce document.
Actuellement, les types de nœuds sont "AFX 1K" et offrent un débit de lecture et d'écriture approximativement conforme aux valeurs ci-dessous. À mesure que de nouveaux matériels sont disponibles pour NetApp AFX, ces limites peuvent changer. REMARQUE : Les performances maximales ont été atteintes en utilisant plusieurs clients lisant et écrivant plusieurs fichiers, comme indiqué dans la section « Benchmark results » ci-dessous.
Estimations des performances par nœud
| Type de nœud | Performances de lecture maximales | Performances d'écriture maximales |
|---|---|---|
AFX 1K |
~35 Go/s |
~10 Go/s |

|
Pour obtenir les estimations de performance les plus récentes, veuillez contacter votre équipe commerciale NetApp. |
Performance par étagère
Chaque baie contient des modules hautes performances dotés de 16 ports Ethernet 100 Gb qui utilisent la communication RoCEv2 pour une interaction de stockage à large bande passante avec les nœuds de calcul du cluster. Comme toute ressource physique, ces baies ont des maximums qui peuvent être atteints – en particulier puisque NetApp AFX peut présenter plusieurs nœuds pointant vers le même ensemble de disques. Le tableau suivant présente les performances maximales estimées en lecture et en écriture pour une seule baie, pour les disques TLC et QLC. Pour plus d'informations sur les différences entre TLC et QLC, voir "TLC vs QLC".
Estimations de performance par étagère
| Type de module d'étagère | Performances de lecture maximales | Performances d'écriture maximales |
|---|---|---|
NSM 140 |
140 Go/s (TLC et QLC) |
70 Go/s TLC 35 Go/s QLC |
|
|
Pour obtenir les estimations de performance les plus récentes, veuillez contacter votre équipe commerciale NetApp. |
densité de performance
Le découplage des nœuds de stockage des étagères dans l'architecture ONTAP désagrégée permet à un plus grand nombre de nœuds de diriger le trafic vers un nombre réduit d'étagères, ce qui contribue à réduire l'encombrement du centre de données nécessaire pour obtenir des performances maximales avec uniquement la capacité requise.
Ce concept de « densité de performance » permet aux administrateurs de stockage de tirer le meilleur parti du matériel dont ils disposent sans jamais avoir à surdimensionner leur environnement de stockage.
Par exemple, dans un cluster ONTAP unifié, étant donné que chaque nœud possède son propre ensemble de disques, les performances sont uniquement dirigées vers les disques appartenant au nœud, et comme un seul nœud peut accéder à un ensemble de disques, il ne peut pas nécessairement saturer les disques disponibles et atteindre ses performances maximales.
Unified ONTAP – Répartition des performances
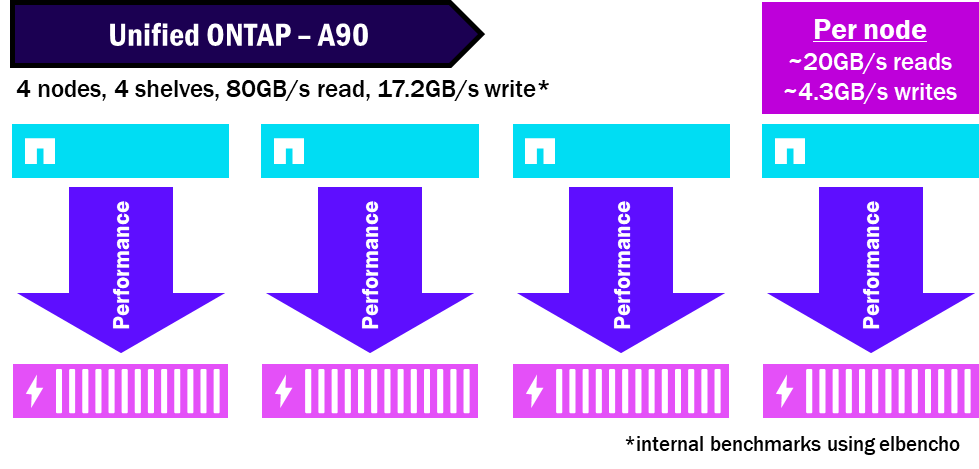
NetApp AFX regroupe tous les disques dans une seule Storage Availability Zone, permettant ainsi à tous les nœuds d'exploiter l'ensemble des disques. Et parce que les disques et les nœuds sont découplés, vous n'aurez pas besoin d'autant de baies pour obtenir les mêmes performances. Cela condense les performances et maximise le potentiel de performance maximal de la baie.
NetApp AFX – Densité de performance
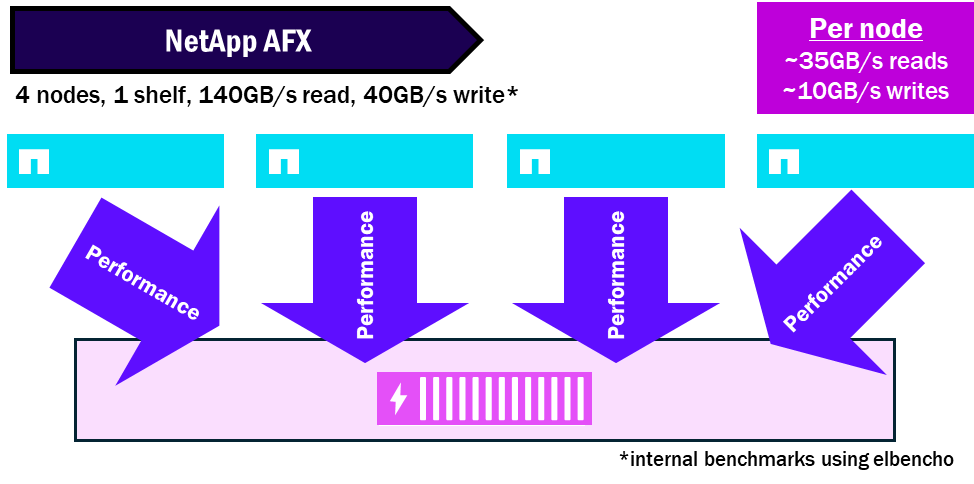
Ratios nœud/étagère
Les nœuds Unified ONTAP nécessitent au moins un ensemble de disques par nœud et peuvent avoir plusieurs baies connectées à un seul nœud. Par conséquent, il peut y avoir des goulots d'étranglement au niveau du nœud unique qui peut ne pas être capable de saturer ses propres disques.
NetApp AFX met à disposition toutes les baies de disques pour tous les nœuds. Chaque baie contient des modules dotés de 16 interfaces RoCE de 100 Go afin d’augmenter la quantité totale de performances autorisée par baie. De ce fait, il est possible de saturer une seule baie avec plusieurs nœuds qui liront et écriront sur le même ensemble de disques.
À partir de ONTAP 9.19.1, le rapport de saturation nœud:étagère est d'environ 4:1.
Résultats de référence
La section suivante présente les résultats de tests de performance obtenus avec un cluster NetApp AFX doté des paramètres de configuration suivants.
-
4 nœuds, 4 interfaces de données
-
2 étagères (disques durs de 7,6 To)
-
ONTAP 9.19.1
-
NFSv4.2 (pNFS, agrégation de sessions)
-
Volume FlexGroup
-
"ElBencho"point de référence
-
Écritures : elbencho --hosts=x.x.x.[y-z] -d -w -b 1M -t 80 --iodepth 1 --direct -s 600g /fio_vol1/
-
Lectures : elbencho --hosts=x.x.x.[y-z] -r -b 256k -t 80 --lat --iodepth 2 --direct -s 600g --infloop /fio_vol1/
-
4 serveurs Cisco C240 M8, 2 cartes 2 ports * 200GbE CX-7, 80 threads
-
Options de montage NFS : rw,vers=4.2,rsize=1048576,wsize=1048576,trunkdiscovery,proto=tcp
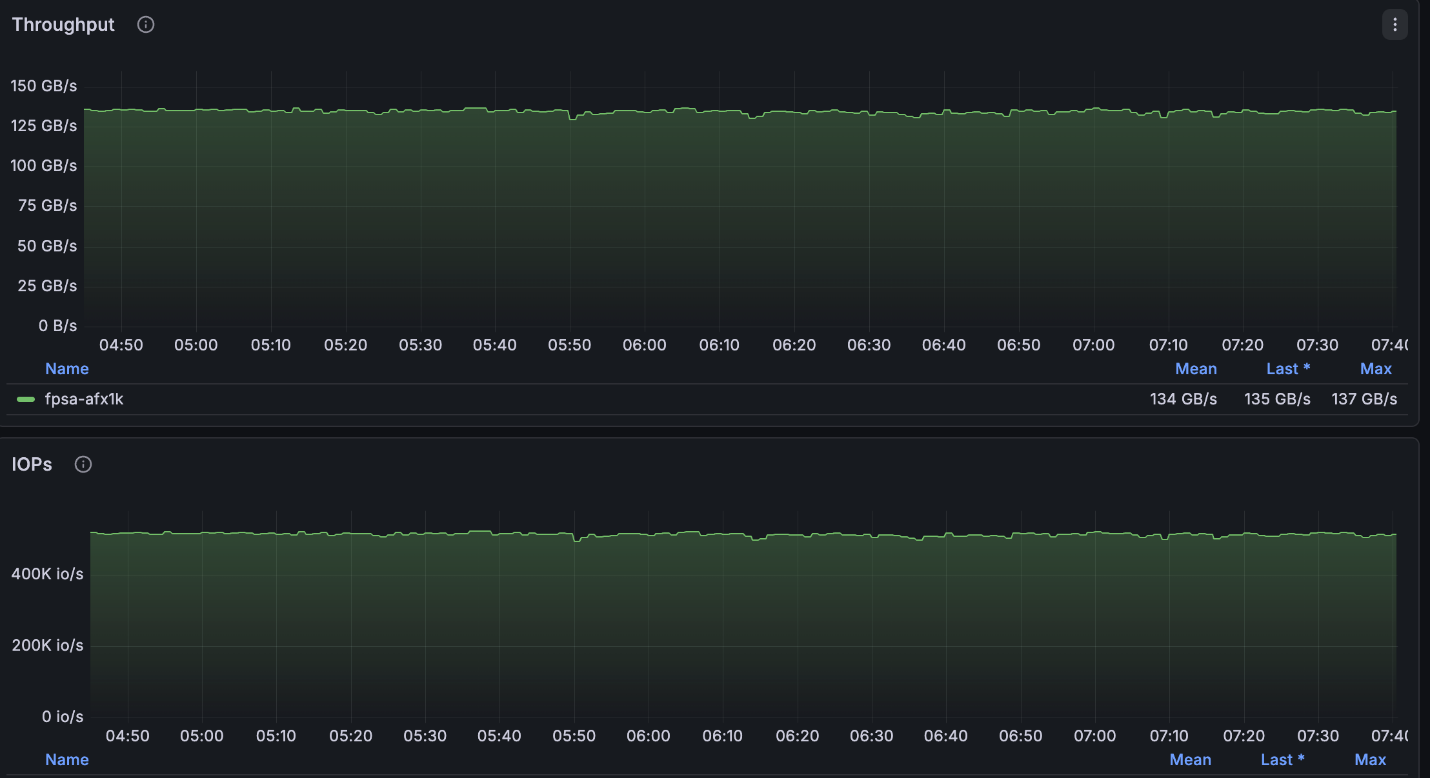
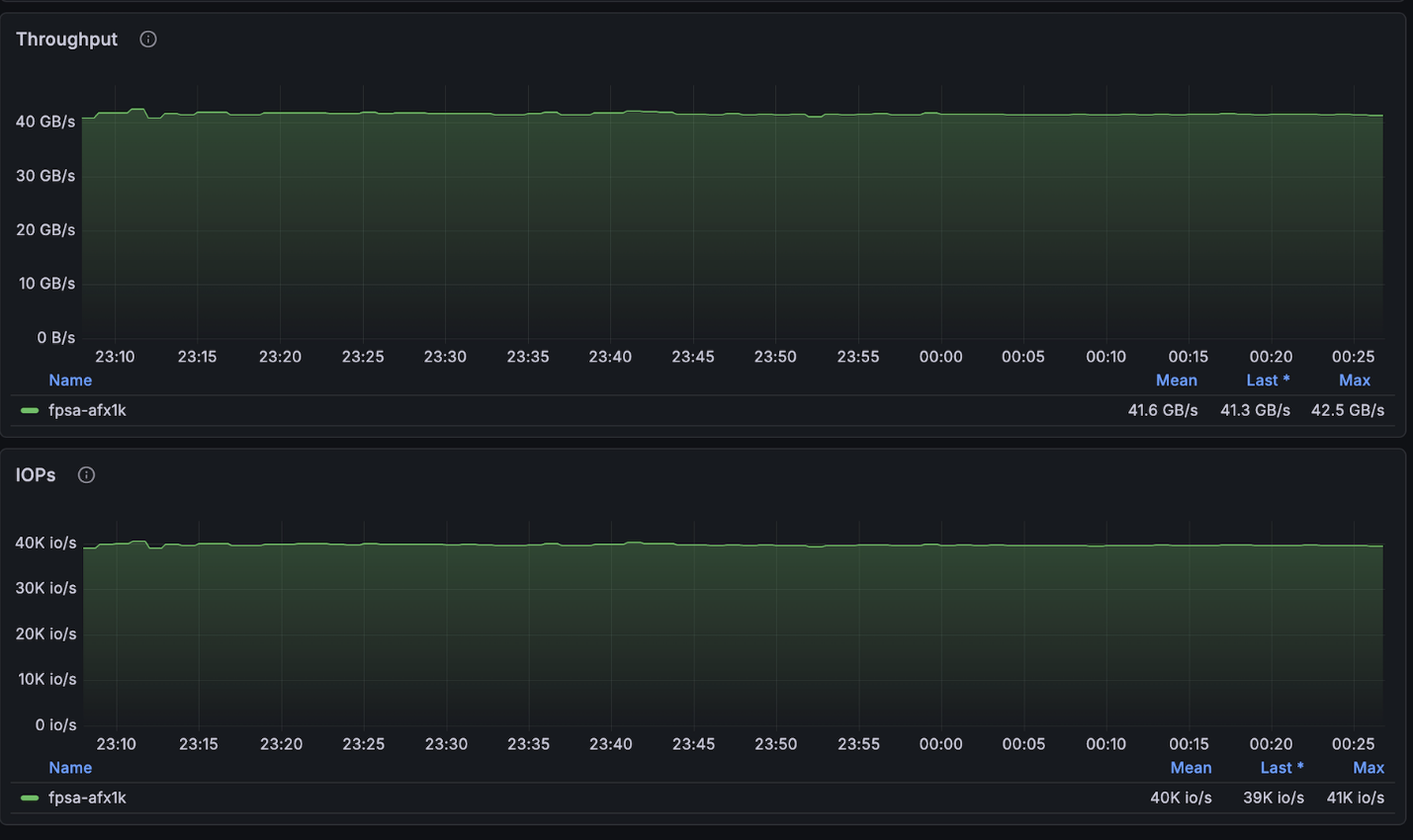
La configuration ci-dessus a atteint très près du nombre maximal de lectures disponibles pour le cluster à 4 nœuds (~134 Go/s) et était exactement au nombre maximal d'écritures autorisées par nœud (40 Go/s).
NetApp AFX – ElBencho performances de lecture, 4 nœuds
NetApp AFX – ElBencho performances d'écriture, 4 nœuds
Lecture anticipée agressive
Dans le traitement des flux multimédias, un film 4K est souvent divisé en des dizaines de milliers de fichiers, d'une taille typique de 50 à 250 Mo. Chaque fichier représente une image, et l'application lit une image entière en une seule requête. Pour garantir un flux fluide et continu, sans mise en mémoire tampon visible, la lecture de ces images doit s'effectuer sans perte.
ONTAP propose une option au niveau du volume (-aggressive-readahead-mode pour optimiser ces charges de travail. À partir d'ONTAP 9.19.1, un nouveau cross_file_sequential_read mode de lecture anticipée agressive a été introduit sur AFX afin d'accélérer les charges de travail présentant des modèles d'E/S prévisibles sur des types de fichiers similaires (par exemple, le rendu et la diffusion multimédia).
La fonction cross_file_sequential_read prédit le prochain fichier à lire en fonction de son nom et lance une prélecture sur ces fichiers avant que le client n'émette l'appel de lecture. La logique de prédiction suppose que tous les fichiers d'un répertoire suivent un schéma de nommage avec un suffixe numérique croissant de façon monotone (par exemple, file1, file2, file3). Tous les fichiers du répertoire doivent suivre ce schéma, en utilisant soit une numérotation décimale, soit hexadécimale. Les noms de fichiers peuvent comporter jusqu'à 255 caractères. La logique est indépendante de l'extension et génère le prochain ensemble de noms de fichiers dans le répertoire actuel uniquement à partir du nom de fichier actuel. Si un nom de fichier précédemment généré en base 10 n'existe pas dans le répertoire, les noms sont régénérés en utilisant une numérotation hexadécimale. Si aucun des noms de fichiers générés n'existe, aucune prélecture n'est effectuée pour cet ensemble. La prélecture reprend lorsque la prochaine lecture client est émise.
Avec ces options activées, "test de trame" les tests de performance ont permis de lire 30 000 images 4K à 30 images par seconde avec 30 clients (NFSv3 et SMB3) et 34 clients (NFSv4.1), sans une seule image perdue.
Bien que la lecture séquentielle inter-fichiers soit principalement conçue pour les charges de travail multimédias, d'autres charges de travail à forte intensité de lecture avec des modèles d'accès et des noms de fichiers prévisibles, telles que l'entraînement et l'inférence de l'IA, peuvent également en bénéficier.
Considérations et mises en garde
-
Cache de mémoire tampon partagé – La lecture anticipée agressive utilise le même cache de mémoire tampon que les autres volumes sur le nœud. Son activation peut affecter les performances de lecture des autres volumes sur ce nœud.
-
Performances de stockage sous-jacentes – Si les fichiers ne peuvent pas être lus assez rapidement (par exemple, sur les systèmes FAS basés sur des disques durs), les données mises en cache peuvent être supprimées avant que la lecture du client n’ait lieu, annulant ainsi les avantages de la lecture anticipée.
-
Exigences relatives au modèle d'accès – Si le modèle de lecture de la charge de travail n'est pas séquentiel, ou si les fichiers d'un répertoire ne sont pas nommés dans un ordre séquentiel croissant, le mode de lecture anticipée agressif cross_file_sequential_read n'apportera pas d'avantages significatifs.
Améliorations des performances de NFSv4.x
La version 3 de NFS fait figure de référence pour les applications NFS depuis des décennies, dès sa sortie officielle en 1995. Son excellent rapport performance/résilience explique pourquoi il est difficile d’envisager une migration vers des versions NFS plus récentes.
Cependant, NFSv3 présente certaines limitations. L'absence d'état du protocole, bien qu'avantageuse pour les performances et la minimisation des interruptions lors d'un basculement de stockage, est moins favorable à la cohérence des données et à la gestion des verrous. Un serveur NFS ne conserve pas réellement l'historique des états de verrouillage, donc en cas de panne, il se peut que le serveur NFS libère ou non les verrous, et le client NFS peut ne pas savoir si un fichier est verrouillé ou non.
Security for NFSv3 is also a bit lacking. The protocol requires multiple open firewall ports to function properly and numeric IDs are sent in plaintext over the wire. Furthermore, NFS does not have robust ACL support, and does not include native file and folder auditing. As a result of these limitations, NFSv4 was created in 2003 via link:https://datatracker.ietf.org/doc/html/rfc3530[RFC-3530^] (obsoleted in 2015 by link:https://datatracker.ietf.org/doc/html/rfc7530[RFC-7530^]). Bien que NFSv4.x existe depuis plus de 20 ans, son adoption reste limitée pour plusieurs raisons.
-
Complexité de la gestion des identités : de nombreux environnements ne disposent pas d’une infrastructure de service de noms en place pour tirer pleinement parti des exigences de sécurité des chaînes de noms et de Kerberos dans NFSv4.x.
-
Nécessité de clients NFS plus récents : cette problématique est moins pressante dans les environnements NFS modernes, à mesure que l’on s’éloigne de la date de sortie initiale de NFSv4. Presque tous les systèmes d’exploitation actuels intègrent des clients NFS compatibles avec NFSv4, mais certains systèmes plus anciens peuvent ne pas disposer des paquets NFSv4.x nécessaires. De fait, certaines applications requièrent encore l’utilisation d’anciennes versions de NFS.
-
L'adage « On ne change pas une équipe qui gagne » : les services informatiques des grandes entreprises sont réputés pour leur réticence à adopter les nouvelles technologies, même celles qui existent depuis plus de 20 ans. Et si la version actuelle de NFS fonctionne correctement, pourquoi changer ?
-
Problèmes de performance : les performances d’un protocole avec état comme NFSv4.x ont été inférieures à celles du protocole sans état NFSv3 pendant la majeure partie des 20 dernières années. Par le passé, l’impact sur les performances était souvent supérieur aux avantages de NFSv4.x.
Améliorations de NFSv4.x dans ONTAP 9.18.1 utilisant AFX
Certaines modifications architecturales apportées à ONTAP ont permis d'améliorer considérablement les performances de NFS en général et ont contribué de manière significative à l'amélioration des performances de NFSv4.x en général.
Vous trouverez ci-dessous un résumé général de certains de ces changements.
Amélioration de la lecture séquentielle : NFSv4.1 30 % plus performant que NFSv3
ONTAP 9.18.1 introduit la prise en charge des E/S multipath avec NFSv4.1. Au lieu de traiter les lectures depuis le système de fichiers WAFL, MPIO déplace les opérations de lecture vers un domaine réseau afin de garantir la compatibilité multipath. Cette approche réduit les changements de contexte, offrant un parallélisme global supérieur dans le trafic de lecture séquentiel, tout en diminuant la surcharge liée à la gestion des tampons en contournant WAFL.
Amélioration de la lecture aléatoire pour les volumes FlexGroup : NFSv4.1 à moins de 7 % de NFSv3
FlexGroup volumes sont des volumes qui regroupent plusieurs volumes sous-jacents et les présentent comme un espace de noms unifié. Dans AFX, les volumes FlexGroup ont l’équilibrage de capacité avancé activé par défaut, ce qui permet d’écrire les fichiers de plus de 10 Go sur plusieurs volumes sous forme de fichiers multiparties. En raison de l’emplacement distant de ces parties de fichier, les lectures aléatoires présentaient traditionnellement un léger désavantage en termes de performances avec NFSv4.x (environ 18 % de moins qu’avec NFSv3). ONTAP 9.18.1 introduit la prise en charge des E/S mises en cache pour les lectures multiparties avec NFSv4.x afin de pallier ce problème. REMARQUE : Cette modification ne s’applique pas aux volumes FlexVol.
Écritures séquentielles : amélioration de 10 % par rapport aux versions précédentes
L'amélioration de la façon dont nous répliquons les données NVLOG utilisées pour la fonctionnalité de basculement HA a augmenté les performances d'écriture séquentielle globales pour les systèmes NetApp AFX.
Opérations sur les métadonnées : Performances à moins de 15 % de celles de NFSv3 pour les benchmarks EDA
Traditionnellement, NFSv4.1 sérialise toutes les opérations d'OPEN et de CLOSE, un nœud de cluster les traitant une à une avant qu'elles puissent être envoyées du réseau à WAFL. ONTAP 9.18.1 introduit Concurrent Open Close (COC), qui élimine la sérialisation réseau en modifiant la façon dont les conditions de concurrence sont résolues, supprimant ainsi les goulots d'étranglement OPEN/CLOSE observés dans les versions précédentes.
Tous ces changements – ainsi que les modifications d'architecture apportées dans AFX – ont permis d'améliorer les performances globales de NFSv4.1 dans ONTAP 9.18.1.
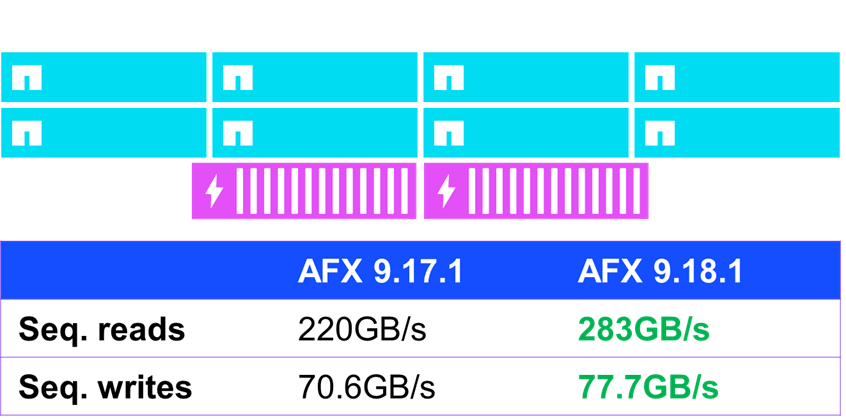
Résultats d'E/S séquentiels
L'un des domaines où de modestes améliorations de performances ont été observées concerne les E/S séquentielles (c'est-à-dire les E/S prévisibles et émises consécutivement). Lors de tests de performances standard utilisant fio, AFX exécutant ONTAP 9.18.1 a amélioré les performances de lecture séquentielle de près de 30 % et les performances d'écriture séquentielle de 10 %.
NetApp AFX – performances d'E/S séquentielles NFSv4.1 dans ONTAP 9.18.1
Résultats de charge de travail nécessitant de nombreuses métadonnées
Plus impressionnantes encore sont les améliorations apportées à l'un des principaux points faibles de NFSv4.x en termes de performances : les métadonnées. Il s'agit d'E/S aléatoires, généralement de l'ordre de 4 Ko, utilisées pour gérer les propriétaires et les attributs des fichiers, créer et lister les fichiers, etc. En raison de la gestion des états inhérente à NFSv4.x, ces opérations ont tendance à être plus gourmandes en ressources CPU et à engendrer une latence plus élevée, ce qui réduit les performances globales potentielles.
Avec les modifications apportées à AFX ONTAP 9.18.1, les performances NFSv4.x pour ces types de charges de travail se sont considérablement améliorées et ont comblé l'écart avec les performances NFSv3 (à moins de 15%).
Nos équipes d'ingénierie de la performance ont comparé les performances des benchmarks standard d'imagerie IA, d'EDA et de compilation logicielle et ont constaté des gains considérables par rapport à la version précédente d'ONTAP.
NetApp AFX – Performances d'E/S des métadonnées NFSv4.1 dans ONTAP 9.18.1
