

Stratégie de déploiement et meilleures pratiques pour la synchronisation active ONTAP SnapMirror
 Suggérer des modifications
Suggérer des modifications
Il est important que votre stratégie de protection des données identifie clairement les charges de travail qui doivent être protégées pour la continuité des activités. L’étape la plus critique de votre stratégie de protection des données consiste à clarifier la disposition des données de votre application d’entreprise afin de pouvoir décider comment vous distribuez les volumes et protégez la continuité des activités. Étant donné que le basculement se produit au niveau du groupe de cohérence pour chaque application, assurez-vous d’ajouter les volumes de données nécessaires au groupe de cohérence.
Configuration d'un SVM
Le diagramme représente la configuration recommandée pour les machines virtuelles de stockage (SVM) pour la synchronisation active SnapMirror.
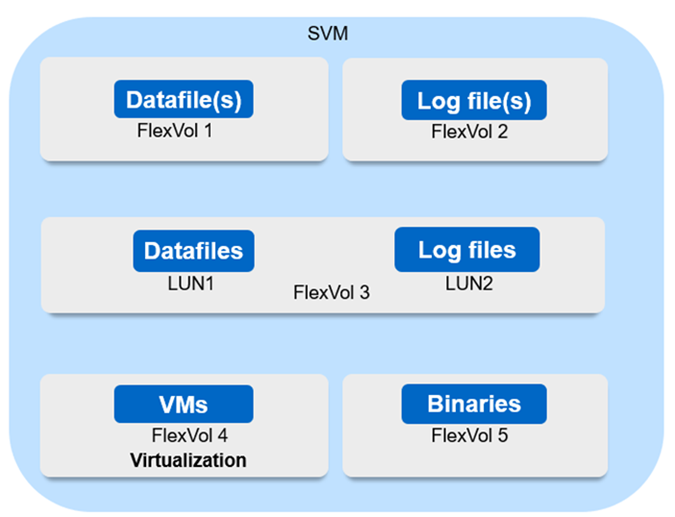
-
Pour les volumes de données :
-
Les charges de travail de lecture aléatoire sont isolées des écritures séquentielles. Par conséquent, selon la taille de la base de données, les données et les fichiers journaux sont généralement placés sur des volumes distincts.
-
Pour les grandes bases de données critiques, le fichier de données unique se trouve sur FlexVol 1 et son fichier journal correspondant sur FlexVol 2.
-
Pour une meilleure consolidation, les bases de données non stratégiques de petite à moyenne taille sont regroupées de manière à ce que tous les fichiers de données se trouvent sur FlexVol 1 et que les fichiers journaux correspondants se trouvent sur FlexVol 2. Cependant, vous perdrez la granularité au niveau de l'application par le biais de ce regroupement.
-
-
Une autre variante est d'avoir tous les fichiers dans le même FlexVol 3, avec les fichiers de données dans LUN2 1 et ses fichiers journaux dans le LUN 2.
-
-
Si votre environnement est virtualisé, toutes les machines virtuelles des diverses applications d'entreprise sont partagées dans un datastore. En général, les VM et les binaires d'application sont répliqués de manière asynchrone à l'aide de SnapMirror.