

Mise à niveau manuelle sans interruption d'une configuration MetroCluster à quatre ou huit nœuds via l'interface de ligne de commande ONTAP
 Suggérer des modifications
Suggérer des modifications
La mise à niveau manuelle d'une configuration MetroCluster à quatre ou huit nœuds implique de préparer la mise à jour, de mettre à jour les paires DR dans chacun des deux groupes DR simultanément et d'effectuer des tâches post-mise à niveau.
-
Cette tâche s'applique aux configurations suivantes :
-
Configurations FC ou IP MetroCluster à quatre nœuds exécutant ONTAP 9.2 ou une version antérieure
-
Configurations FC à 8 nœuds MetroCluster, quelle que soit la version d'ONTAP utilisée
-
-
Si vous disposez d'une configuration MetroCluster à deux nœuds, n'utilisez pas cette procédure.
-
Les tâches suivantes font référence à l'ancienne et à la nouvelle version de ONTAP.
-
Lors de la mise à niveau, l'ancienne version est une version précédente de ONTAP, avec un numéro de version inférieur à celui de la nouvelle version de ONTAP.
-
Lors de la restauration, l'ancienne version est une version plus récente de ONTAP, avec un numéro de version plus élevé que la nouvelle version de ONTAP.
-
-
Cette tâche utilise le flux de travail de haut niveau suivant :
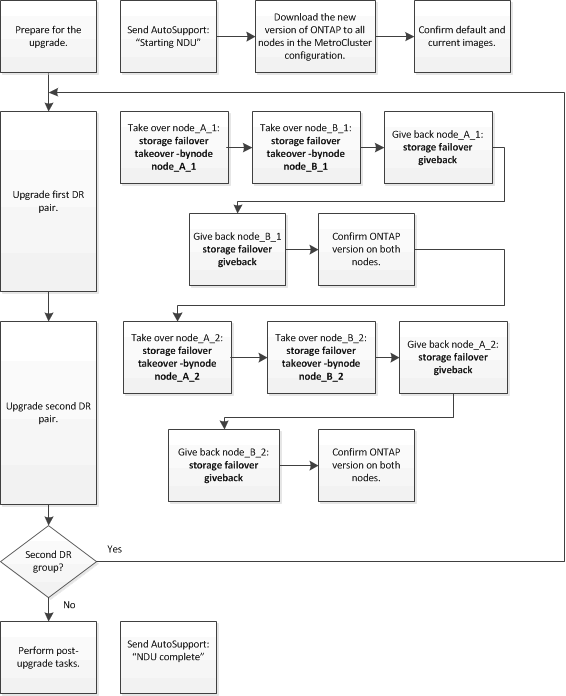
Différences lors de la mise à jour du logiciel ONTAP sur une configuration MetroCluster à huit ou quatre nœuds
La procédure de mise à niveau du logiciel MetroCluster diffère selon qu'il y a huit ou quatre nœuds dans la configuration MetroCluster.
Une configuration MetroCluster se compose d'un ou deux groupes de reprise sur incident. Chaque groupe de reprise après incident est constitué de deux paires haute disponibilité, une paire haute disponibilité sur chaque cluster MetroCluster. Un MetroCluster à 8 nœuds inclut deux groupes de reprise après incident :
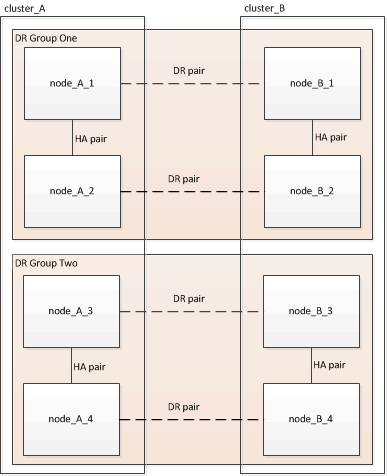
Vous mettez à niveau un groupe de reprise après incident à la fois.
-
Mettre à niveau le groupe de reprise sur incident un :
-
Mettre à niveau les nœuds_A_1 et node_B_1.
-
Mettre à niveau node_A_2 et node_B_2.
-
-
Mettre à niveau le groupe de reprise sur incident un :
-
Mettre à niveau les nœuds_A_1 et node_B_1.
-
Mettre à niveau node_A_2 et node_B_2.
-
-
Mettre à niveau le DR Groupe deux :
-
Mettre à niveau les nœuds_A_3 et node_B_3.
-
Mettre à niveau les nœuds_A_4 et node_B_4.
-
Préparation de la mise à niveau d'un groupe DR MetroCluster
Avant de mettre à niveau le logiciel ONTAP sur les nœuds, vous devez identifier les relations de DR entre les nœuds, envoyer un message AutoSupport indiquant que vous initiez une mise à niveau et confirmer la version de ONTAP exécutée sur chaque nœud.
Vous devez avoir "téléchargé" et "installé" les images du logiciel.
Cette tâche doit être répétée sur chaque groupe de reprise sur incident. Si la configuration MetroCluster comprend huit nœuds, il y a deux groupes de reprise sur incident. Cette tâche doit donc être répétée sur chaque groupe de reprise sur incident.
Les exemples fournis dans cette tâche utilisent les noms illustrés dans l'illustration suivante pour identifier les clusters et les nœuds :
-
Identifier les paires de reprise sur incident dans la configuration :
metrocluster node show -fields dr-partnercluster_A::> metrocluster node show -fields dr-partner (metrocluster node show) dr-group-id cluster node dr-partner ----------- ------- -------- ---------- 1 cluster_A node_A_1 node_B_1 1 cluster_A node_A_2 node_B_2 1 cluster_B node_B_1 node_A_1 1 cluster_B node_B_2 node_A_2 4 entries were displayed. cluster_A::>
-
Définissez le niveau de privilège de admin sur avancé, en entrant y lorsque vous êtes invité à continuer :
set -privilege advancedL'invite avancée (
*>) s'affiche. -
Confirmer la version de ONTAP sur cluster_A :
system image showcluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
Vérifier la version du cluster_B :
system image showcluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_B_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::> -
Déclencher une notification AutoSupport :
autosupport invoke -node * -type all -message "Starting_NDU"Cette notification AutoSupport inclut un enregistrement de l'état du système avant la mise à niveau. Il enregistre des informations de dépannage utiles en cas de problème avec le processus de mise à niveau.
Si votre cluster n'est pas configuré pour envoyer des messages AutoSupport, une copie de la notification est enregistrée localement.
-
Pour chaque nœud du premier jeu, définissez l'image logicielle ONTAP cible sur l'image par défaut :
system image modify {-node nodename -iscurrent false} -isdefault trueCette commande utilise une requête étendue pour modifier l'image du logiciel cible, qui est installée comme image secondaire, comme image par défaut pour le nœud.
-
Vérifiez que l'image du logiciel ONTAP cible est définie comme image par défaut sur cluster_A :
system image showDans l'exemple suivant, image2 est la nouvelle version de ONTAP et est définie en tant qu'image par défaut sur chacun des nœuds du premier ensemble :
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed.-
Vérifiez que l'image du logiciel ONTAP cible est définie comme image par défaut sur cluster_B :
system image showL'exemple suivant montre que la version cible est définie en tant qu'image par défaut sur chacun des nœuds du premier jeu :
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/YY/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed. -
-
Déterminer si les nœuds à mettre à niveau servent actuellement des clients deux fois pour chaque nœud :
system node run -node target-node -command uptimeLa commande UpTime affiche le nombre total d'opérations que le nœud a effectuées pour les clients NFS, CIFS, FC et iSCSI depuis le dernier démarrage du nœud. Pour chaque protocole, vous devez exécuter la commande deux fois afin de déterminer si le nombre d'opérations augmente. S'ils augmentent, le nœud diffuse actuellement des clients pour ce protocole. Si ce n'est pas le cas, le nœud ne diffuse actuellement pas les clients pour ce protocole.

Vous devez noter chaque protocole dont les opérations client augmentent, de sorte qu'après la mise à niveau du nœud, vous pouvez vérifier que le trafic client a repris. Cet exemple montre un nœud avec des opérations NFS, CIFS, FC et iSCSI. Toutefois, le nœud dessert actuellement uniquement les clients NFS et iSCSI.
cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:16 800000260 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32810 iSCSI ops cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:17 800001573 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32815 iSCSI ops
Mise à jour de la première paire DR dans un groupe MetroCluster DR
Vous devez effectuer un basculement et un retour des nœuds afin de faire de la nouvelle version d'ONTAP la version actuelle du nœud.
Tous les nœuds doivent exécuter l'ancienne version de ONTAP.
Dans cette tâche, les nœuds_A_1 et node_B_1 sont mis à niveau.
Si vous avez mis à niveau le logiciel ONTAP sur le premier groupe DR et que vous mettez à niveau le deuxième groupe DR dans une configuration MetroCluster à huit nœuds, dans cette tâche, vous mettiez à jour node_A_3 et node_B_3.
-
Migrer tous les LIFs de données loin du nœud :
network interface migrate-all -node node_A_1network interface migrate-all -node node_B_1 -
Si le logiciel MetroCluster Tiebreaker est activé, désactivez-le.
-
Pour chaque nœud de la paire HA, désactiver le rétablissement automatique :
storage failover modify -node target-node -auto-giveback falseCette commande doit être répétée pour chaque nœud de la paire HA.
-
Vérifier que le retour automatique est désactivé :
storage failover show -fields auto-givebackCet exemple montre que le rétablissement automatique a été désactivé sur les deux nœuds :
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 false node_x_2 false 2 entries were displayed.
-
Assurez-vous que les E/S ne dépassent pas ~50 % pour chaque contrôleur et que l'utilisation du CPU ne dépasse pas ~50 % par contrôleur.
-
Initier un basculement du nœud cible sur cluster_A :
Ne spécifiez pas le paramètre -option immédiate, car un basculement normal est nécessaire pour les nœuds pris en charge afin de démarrer sur la nouvelle image logicielle.
-
Reprendre le partenaire de reprise après incident sur cluster_A (node_A_1) :
storage failover takeover -ofnode node_A_1Le nœud démarre à l'état « waiting for giveback ».
Si AutoSupport est activé, un message AutoSupport est envoyé pour indiquer que les nœuds sont hors du quorum du cluster. Vous pouvez ignorer cette notification et poursuivre la mise à niveau. -
Vérifiez que le basculement est réussi :
storage failover showL'exemple suivant montre que le basculement a réussi. L'état « waiting for giveback » est défini sur node_A_1 et node_A_2 est à l'état « In Takeover ».
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 - Waiting for giveback (HA mailboxes) node_A_2 node_A_1 false In takeover 2 entries were displayed. -
-
Reprendre le partenaire de reprise après incident sur le cluster_B (node_B_1) :
Ne spécifiez pas le paramètre -option immédiate, car un basculement normal est nécessaire pour les nœuds pris en charge afin de démarrer sur la nouvelle image logicielle.
-
Reprendre le noeud_B_1 :
storage failover takeover -ofnode node_B_1Le nœud démarre à l'état « waiting for giveback ».
Si AutoSupport est activé, un message AutoSupport est envoyé pour indiquer que les nœuds sont hors du quorum du cluster. Vous pouvez ignorer cette notification et poursuivre la mise à niveau. -
Vérifiez que le basculement est réussi :
storage failover showL'exemple suivant montre que le basculement a réussi. Le nœud_B_1 est dans l'état « waiting for giveback » et le nœud_B_2 est à l'état « In Takeover ».
cluster_B::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 - Waiting for giveback (HA mailboxes) node_B_2 node_B_1 false In takeover 2 entries were displayed. -
-
Attendez au moins huit minutes pour vérifier les conditions suivantes :
-
Les chemins d'accès multiples du client (si déployés) sont stabilisés.
-
Les clients sont récupérés à partir de la pause des E/S qui a lieu lors du basculement.
Le temps de restauration est spécifique au client et peut prendre plus de huit minutes selon les caractéristiques des applications client.
-
-
Renvoyez les agrégats aux nœuds cibles :
Après la mise à niveau des configurations IP de MetroCluster vers ONTAP 9.5 ou une version ultérieure, les agrégats sont dégradés pendant une courte période avant de resynchroniser et de revenir à un état miroir.
-
Renvoyer les agrégats au partenaire de reprise après incident sur cluster_A :
storage failover giveback -ofnode node_A_1 -
Renvoyer les agrégats au partenaire de reprise après incident sur cluster_B :
storage failover giveback -ofnode node_B_1L'opération de rétablissement renvoie tout d'abord l'agrégat racine sur le nœud, puis, une fois le démarrage du nœud terminé, renvoie les agrégats non-racine.
-
-
Vérifiez que tous les agrégats ont été renvoyés en exécutant la commande suivante sur les deux clusters :
storage failover show-givebackSi le champ État de rétablissement indique qu'il n'y a pas d'agrégats à renvoyer, tous les agrégats ont été renvoyés. Si le retour est vetoté, la commande affiche la progression du rétablissement et le sous-système qui a mis son veto au rétablissement.
-
Si un agrégat n'a pas été renvoyé, procédez comme suit :
-
Examinez la solution de contournement du veto pour déterminer si vous voulez répondre à la condition "verto" ou remplacer le veto.
-
Si nécessaire, répondez à la condition "verto" décrite dans le message d'erreur, en veillant à ce que toutes les opérations identifiées soient arrêtées de manière normale.
-
Saisissez de nouveau la commande Storage failover giveback.
Si vous décidez de remplacer la condition "verto", définissez le paramètre -override-vetos sur true.
-
-
Attendez au moins huit minutes pour vérifier les conditions suivantes :
-
Les chemins d'accès multiples du client (si déployés) sont stabilisés.
-
Les clients sont récupérés à partir de la pause des E/S qui a lieu au cours du rétablissement
Le temps de restauration est spécifique au client et peut prendre plus de huit minutes selon les caractéristiques des applications client.
-
-
Définissez le niveau de privilège de admin sur avancé, en entrant y lorsque vous êtes invité à continuer :
set -privilege advancedL'invite avancée (
*>) s'affiche. -
Vérifier la version du cluster_A :
system image showL'exemple suivant montre que l'image système2 (image ONTAP cible) est la version par défaut et actuelle sur le nœud_A_1 :
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
Vérifier la version du cluster_B :
system image showL'exemple suivant montre que l'image système2 (image ONTAP cible) est la version par défaut et actuelle sur le nœud_B_1 :
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::>
Mise à jour de la seconde paire DR dans un groupe MetroCluster DR
Vous devez effectuer un basculement et un retour du nœud afin de faire de la nouvelle version d'ONTAP la version actuelle du nœud.
Vous devez avoir mis à niveau la première paire DR (node_A_1 et node_B_1).
Dans cette tâche, les nœuds_A_2 et node_B_2 sont mis à niveau.
Si vous avez mis à niveau le logiciel ONTAP sur le premier groupe DR et que vous mettez à jour le deuxième groupe DR dans une configuration MetroCluster à huit nœuds, dans cette tâche, vous mettez à jour node_A_4 et node_B_4.
-
Migrer tous les LIFs de données loin du nœud :
network interface migrate-all -node node_A_2network interface migrate-all -node node_B_2 -
Initier un basculement du nœud cible sur cluster_A :
Ne spécifiez pas le paramètre -option immédiate, car un basculement normal est nécessaire pour les nœuds pris en charge afin de démarrer sur la nouvelle image logicielle.
-
Reprendre le partenaire de reprise après incident sur cluster_A :
storage failover takeover -ofnode node_A_2 -option allow-version-mismatch
Le allow-version-mismatchAucune option n'est requise pour les mises à niveau de ONTAP 9.0 vers ONTAP 9.1 ou pour les mises à niveau de correctifs.Le nœud démarre à l'état « waiting for giveback ».
Si AutoSupport est activé, un message AutoSupport est envoyé pour indiquer que les nœuds sont hors du quorum du cluster. Vous pouvez ignorer cette notification et poursuivre la mise à niveau.
-
Vérifiez que le basculement est réussi :
storage failover showL'exemple suivant montre que le basculement a réussi. L'état « waiting for giveback » est défini sur node_A_2 et node_A_1 est à l'état « In Takeover ».
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 false In takeover node_A_2 node_A_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed. -
-
Initier un basculement du nœud cible sur cluster_B :
Ne spécifiez pas le paramètre -option immédiate, car un basculement normal est nécessaire pour les nœuds pris en charge afin de démarrer sur la nouvelle image logicielle.
-
Reprendre le partenaire de reprise sur incident sur cluster_B (node_B_2) :
Si vous effectuez une mise à niveau depuis… Entrez cette commande… ONTAP 9.2 ou ONTAP 9.1
storage failover takeover -ofnode node_B_2ONTAP 9.0 ou Data ONTAP 8.3.x
storage failover takeover -ofnode node_B_2 -option allow-version-mismatch
Le allow-version-mismatchAucune option n'est requise pour les mises à niveau de ONTAP 9.0 vers ONTAP 9.1 ou pour les mises à niveau de correctifs.Le nœud démarre à l'état « waiting for giveback ».
Si AutoSupport est activé, un message AutoSupport est envoyé, indiquant que les nœuds ne disposent pas du quorum du cluster. Vous pouvez ignorer cette notification en toute sécurité et poursuivre la mise à niveau. -
Vérifiez que le basculement est réussi :
storage failover showL'exemple suivant montre que le basculement a réussi. L'état « waiting for giveback » est défini sur node_B_2 et le nœud_B_1 est à l'état « In Takeover ».
cluster_B::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 false In takeover node_B_2 node_B_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed. -
-
Attendez au moins huit minutes pour vérifier les conditions suivantes :
-
Les chemins d'accès multiples du client (si déployés) sont stabilisés.
-
Les clients sont récupérés à partir de la pause des E/S qui a lieu lors du basculement.
Le temps de restauration est spécifique au client et peut prendre plus de huit minutes selon les caractéristiques des applications client.
-
-
Renvoyez les agrégats aux nœuds cibles :
Après la mise à niveau des configurations IP de MetroCluster vers ONTAP 9.5, les agrégats seront sur une courte période avant de resynchroniser et de rétablir l'état miroir.
-
Renvoyer les agrégats au partenaire de reprise après incident sur cluster_A :
storage failover giveback -ofnode node_A_2 -
Renvoyer les agrégats au partenaire de reprise après incident sur cluster_B :
storage failover giveback -ofnode node_B_2L'opération de rétablissement renvoie tout d'abord l'agrégat racine sur le nœud, puis, une fois le démarrage du nœud terminé, renvoie les agrégats non-racine.
-
-
Vérifiez que tous les agrégats ont été renvoyés en exécutant la commande suivante sur les deux clusters :
storage failover show-givebackSi le champ État de rétablissement indique qu'il n'y a pas d'agrégats à renvoyer, tous les agrégats ont été renvoyés. Si le retour est vetoté, la commande affiche la progression du rétablissement et le sous-système qui a mis son veto au rétablissement.
-
Si un agrégat n'a pas été renvoyé, procédez comme suit :
-
Examinez la solution de contournement du veto pour déterminer si vous voulez répondre à la condition "verto" ou remplacer le veto.
-
Si nécessaire, répondez à la condition "verto" décrite dans le message d'erreur, en veillant à ce que toutes les opérations identifiées soient arrêtées de manière normale.
-
Saisissez de nouveau la commande Storage failover giveback.
Si vous décidez de remplacer la condition "verto", définissez le paramètre -override-vetos sur true.
-
-
Attendez au moins huit minutes pour vérifier les conditions suivantes :
-
Les chemins d'accès multiples du client (si déployés) sont stabilisés.
-
Les clients sont récupérés à partir de la pause des E/S qui a lieu au cours du rétablissement
Le temps de restauration est spécifique au client et peut prendre plus de huit minutes selon les caractéristiques des applications client.
-
-
Définissez le niveau de privilège de admin sur avancé, en entrant y lorsque vous êtes invité à continuer :
set -privilege advancedL'invite avancée (
*>) s'affiche. -
Vérifier la version du cluster_A :
system image showL'exemple suivant montre que l'image système2 (image ONTAP cible) est la version par défaut et actuelle sur le nœud_A_2 :
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
Vérifier la version du cluster_B :
system image showL'exemple suivant montre que l'image système2 (image ONTAP cible) est la version par défaut et actuelle sur le nœud_B_2 :
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::> -
Pour chaque nœud de la paire HA, activez le rétablissement automatique :
storage failover modify -node target-node -auto-giveback trueCette commande doit être répétée pour chaque nœud de la paire HA.
-
Vérifier que le rétablissement automatique est activé :
storage failover show -fields auto-givebackCet exemple montre que le rétablissement automatique a été activé sur les deux nœuds :
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 true node_x_2 true 2 entries were displayed.