

Fonctionnement de la sélection des ressources
 Suggérer des modifications
Suggérer des modifications
OnCommand Workflow Automation (WFA) utilise des algorithmes de recherche pour sélectionner des ressources de stockage pour l'exécution du workflow. Vous devez comprendre le fonctionnement de la sélection des ressources pour concevoir des flux de travail efficacement.
WFA sélectionne les ressources d'entrée du dictionnaire, telles que les unités vFiler, les agrégats et les machines virtuelles, à l'aide d'algorithmes de recherche. Les ressources sélectionnées sont ensuite utilisées pour exécuter le flux de travail. Les algorithmes de recherche WFA font partie des éléments de base WFA et incluent des finders et des filtres. Pour localiser et sélectionner les ressources requises, les algorithmes de recherche font appel aux données mises en cache à partir de différents référentiels, tels que Active IQ Unified Manager, VMware vCenter Server et une base de données. Par défaut, un filtre est disponible pour chaque entrée de dictionnaire pour la recherche d'une ressource en fonction de ses clés naturelles.
Vous devez définir les critères de sélection des ressources pour chaque commande de votre flux de travail. De plus, vous pouvez utiliser un viseur pour définir les critères de sélection de ressources dans chaque ligne de votre flux de travail. Par exemple, lorsque vous créez un volume qui nécessite une quantité spécifique d'espace de stockage, vous pouvez utiliser le détecteur « Find Aggregate by Available Capacity » (Rechercher un agrégat par capacité disponible) de la commande « Create Volume » (Créer un volume), qui sélectionne un agrégat disposant d'une quantité spécifique d'espace disponible et en crée le volume.
Vous pouvez définir un ensemble de règles de filtrage pour les ressources d'entrée du dictionnaire, telles que les unités vFiler, les agrégats et les machines virtuelles. Les règles de filtre peuvent contenir un ou plusieurs groupes de règles. Une règle se compose d'un attribut d'entrée de dictionnaire, d'un opérateur et d'une valeur. L'attribut peut également inclure des attributs de ses références. Vous pouvez par exemple spécifier une règle pour les agrégats comme suit : répertoriez tous les agrégats dont le nom commence par la chaîne « aggr » et disposent de plus de 5 Go d'espace disponible. La première règle du groupe est l'attribut « nom », l'opérateur « définir avec » et la valeur « aggr ». La deuxième règle du même groupe est l'attribut « Available_size_mb », avec l'opérateur « »> » et la valeur « 5000 ». Vous pouvez définir un ensemble de règles de filtre avec des filtres publics. L'option définir des règles de filtre est désactivée si vous avez sélectionné un Finder. L'option Enregistrer comme Finder est désactivée si vous avez coché la case définir des règles de filtre.
En plus des filtres et des finders, vous pouvez utiliser une commande de recherche ou de définition pour rechercher les ressources disponibles. La commande Rechercher ou définir est l'option préférée par rapport aux commandes No-op. La commande Rechercher et définir permet de définir les ressources du type d'entrée du dictionnaire certifié et du type d'entrée du dictionnaire personnalisé. La commande Rechercher ou définir recherche les ressources mais n'effectue aucune action sur la ressource. Toutefois, lorsqu'un Finder est utilisé pour rechercher des ressources, il est utilisé dans le contexte d'une commande et les actions définies par la commande sont exécutées sur les ressources. Les ressources renvoyées par une commande de recherche ou de définition sont utilisées comme variables pour les autres commandes du flux de travail.
L'illustration suivante montre qu'un filtre est utilisé pour la sélection de ressources :
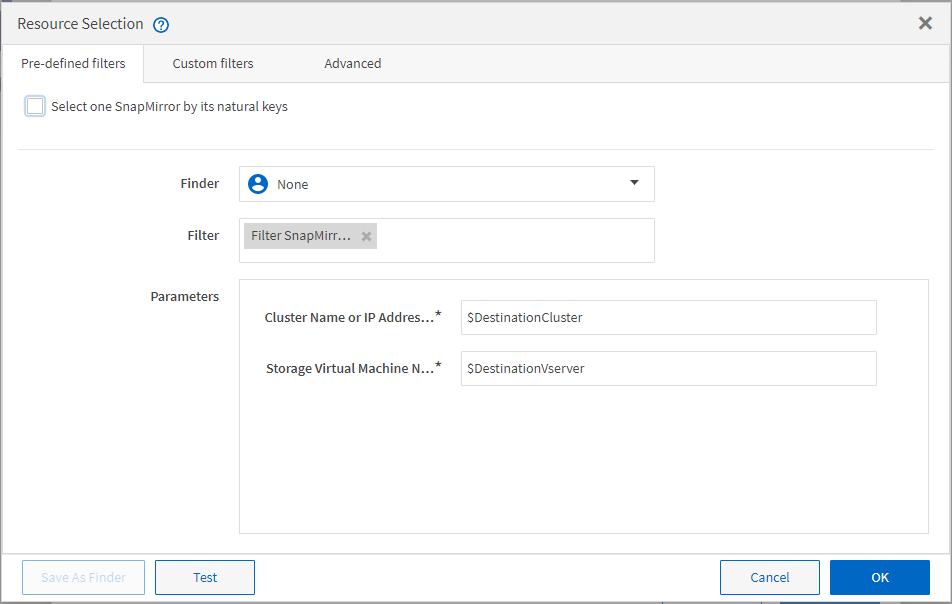
Exemples de sélection de ressources dans des flux de travail prédéfinis
Vous pouvez ouvrir les détails de la commande des flux de travail prédéfinis suivants dans le concepteur pour comprendre comment les options de sélection des ressources sont utilisées :
-
Créez un volume NFS Data ONTAP en cluster
-
Mettre en place le peering de cluster
-
Supprimer un volume clustered Data ONTAP