TR-4920: Data center FlexPod con NetApp SnapMirror Business Continuity e ONTAP 9.10
 Suggerisci modifiche
Suggerisci modifiche
Jyh-ishing Chen, NetApp
Introduzione
Soluzione FlexPod
FlexPod è un'architettura per data center con infrastruttura convergente basata su Best practice che include i seguenti componenti di Cisco e NetApp:
-
Cisco Unified Computing System (Cisco UCS)
-
Famiglie di switch Cisco Nexus e MDS
-
Sistemi NetApp FAS, NetApp AFF e NetApp All SAN Array (ASA)
La figura seguente mostra alcuni dei componenti utilizzati per la creazione di soluzioni FlexPod. Questi componenti sono collegati e configurati in base alle Best practice di Cisco e NetApp per fornire una piattaforma ideale per l'esecuzione sicura di una vasta gamma di workload aziendali.
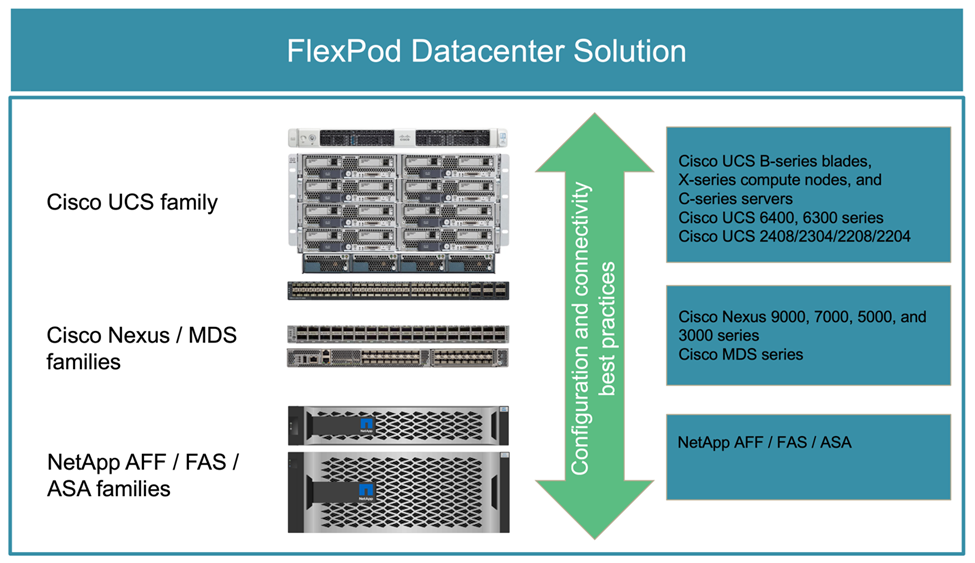
È disponibile un ampio portfolio di Cisco Validated Designs (CVD) e NetApp Verified Architectures (NVA). Questi CVD e NVA coprono tutti i principali carichi di lavoro dei data center e sono il risultato di continue collaborazioni e innovazioni tra NetApp e Cisco sulle soluzioni FlexPod.
Incorporando test e validazioni estesi nel processo di creazione, i CVD e gli NVA di FlexPod offrono progetti di architettura di soluzioni di riferimento e guide di implementazione passo per aiutare partner e clienti a implementare e adottare le soluzioni FlexPod. Utilizzando questi CVD e NVA come guide per la progettazione e l'implementazione, le aziende possono ridurre i rischi, ridurre il downtime della soluzione e aumentare la disponibilità, la scalabilità, la flessibilità e la sicurezza delle soluzioni FlexPod che implementano.
Ciascuna delle famiglie di componenti FlexPod illustrate (Cisco UCS, switch Cisco Nexus/MDS e storage NetApp) offre opzioni di piattaforma e risorse per scalare l'infrastruttura in verticale o in orizzontale, supportando al contempo le funzionalità e le funzionalità richieste dalle Best practice di configurazione e connettività di FlexPod. FlexPod può anche scalare verso l'esterno per ambienti che richiedono implementazioni multiple e coerenti, implementando ulteriori stack FlexPod.
Disaster recovery e business continuity
Le aziende possono adottare diversi metodi per garantire che possano ripristinare rapidamente le applicazioni e i servizi dati in caso di disastri. La disponibilità di un piano di disaster recovery (DR) e business continuity (BC), l'implementazione di una soluzione che soddisfi gli obiettivi di business e l'esecuzione di test regolari degli scenari di disastro consente alle aziende di eseguire il ripristino da un disastro e di continuare i servizi business critici in seguito a una situazione di disastro.
Le aziende potrebbero avere requisiti di DR e BC diversi per diversi tipi di applicazioni e servizi dati. Alcune applicazioni e alcuni dati potrebbero non essere necessari in situazioni di emergenza o di emergenza, mentre altri potrebbero dover essere continuamente disponibili per supportare i requisiti di business.
Per applicazioni mission-critical e servizi dati che potrebbero interrompere il business quando non sono disponibili, è necessaria una valutazione accurata per rispondere a domande come il tipo di manutenzione e scenari di disastro che l'azienda deve prendere in considerazione, la quantità di dati che l'azienda può permettersi di perdere in caso di disastro e la rapidità con cui il ripristino può e deve avvenire.
Per le aziende che si affidano ai servizi dati per la generazione di ricavi, potrebbe essere necessario proteggere i servizi dati da una soluzione in grado di resistere non solo a diversi scenari di guasto singolo punto di errore, ma anche a uno scenario di disastro di interruzione del sito per garantire operazioni di business continue.
Obiettivo del punto di ripristino e obiettivo del tempo di ripristino
L'RPO (Recovery Point Objective) misura la quantità di dati, in termini di tempo, che è possibile permettersi di perdere, o il punto in cui è possibile ripristinare i dati. Con un piano di backup giornaliero, un'azienda potrebbe perdere un giorno di dati perché le modifiche apportate ai dati dall'ultimo backup potrebbero andare perse in caso di disastro. Per i servizi dati business-critical e mission-critical, potrebbe essere necessario un RPO zero e un piano e infrastrutture associati per proteggere i dati senza alcuna perdita di dati.
L'RTO (Recovery Time Objective) misura il tempo che è possibile dedicare a non disporre dei dati o la rapidità con cui i servizi dati devono essere ripristinati. Ad esempio, un'azienda potrebbe disporre di un'implementazione di backup e ripristino che utilizza nastri tradizionali per determinati set di dati a causa delle sue dimensioni. Di conseguenza, il ripristino dei dati dai nastri di backup potrebbe richiedere diverse ore o persino giorni in caso di guasto dell'infrastruttura. Le considerazioni sul tempo devono includere anche il tempo necessario per eseguire il backup dell'infrastruttura oltre al ripristino dei dati. Per i servizi dati mission-critical, potrebbe essere necessario un RTO molto basso e quindi tollerare solo un tempo di failover di secondi o minuti per riportare rapidamente i servizi dati online per la business continuity.
SM-BC
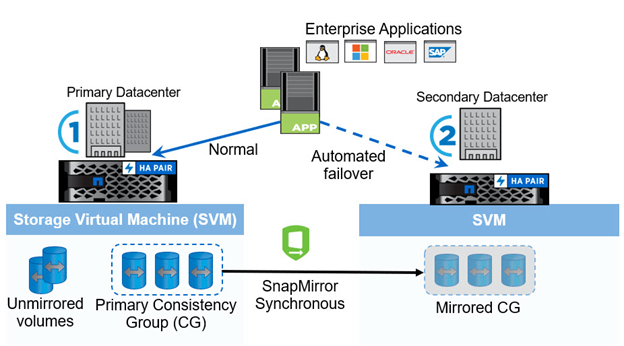
A partire da ONTAP 9.8, è possibile proteggere i carichi di lavoro SAN per il failover trasparente delle applicazioni con NetApp SM-BC. È possibile creare relazioni di gruppo di coerenza tra due cluster AFF o due cluster ASA per la replica dei dati in modo da ottenere un RPO pari a zero e un RTO pari quasi a zero.
La soluzione SM-BC replica i dati utilizzando la tecnologia SnapMirror Synchronous su una rete IP. Offre granularità a livello di applicazione e failover automatico per proteggere i servizi dati business-critical come Microsoft SQL Server, Oracle e così via con LUN SAN basate su protocollo iSCSI o FC. Un mediatore ONTAP implementato in un terzo sito monitora la soluzione SM-BC e consente il failover automatico in caso di disastro del sito.
Un gruppo di coerenza (CG) è un insieme di volumi FlexVol che fornisce una garanzia di coerenza dell'ordine di scrittura per il carico di lavoro dell'applicazione che deve essere protetto per la business continuity. Consente copie Snapshot simultanee coerenti con il crash di un insieme di volumi in un momento specifico. Una relazione SnapMirror, nota anche come relazione CG, viene stabilita tra un CG di origine e un CG di destinazione. Il gruppo di volumi scelto come parte di un CG può essere mappato a un'istanza dell'applicazione, a un gruppo di istanze dell'applicazione o a un'intera soluzione. Inoltre, le relazioni del gruppo di coerenza SM-BC possono essere create o eliminate su richiesta in base ai requisiti e alle modifiche aziendali.
Come illustrato nella figura seguente, i dati del gruppo di coerenza vengono replicati in un secondo cluster ONTAP per il disaster recovery e la business continuity. Le applicazioni sono dotate di connettività ai LUN in entrambi i cluster ONTAP. L'i/o viene normalmente gestito dal cluster primario e riprende automaticamente dal cluster secondario se si verifica un disastro sul primario. Durante la progettazione di una soluzione SM-BC, è necessario osservare i conteggi degli oggetti supportati per le relazioni CG (ad esempio, un massimo di 20 CGS e 200 endpoint) per evitare di superare i limiti supportati.