

FabricPool
 Suggerisci modifiche
Suggerisci modifiche
Panoramica di FabricPool
FabricPool è una soluzione di storage ibrido in ONTAP che utilizza un aggregato all-flash (SSD) come Tier di performance e un archivio di oggetti in un servizio di cloud pubblico come Tier di cloud. Questa configurazione consente lo spostamento dei dati basato su policy, a seconda che i dati siano o meno utilizzati frequentemente. FabricPool è supportato in ONTAP per aggregati AFF e all-SSD su piattaforme FAS. L'elaborazione dei dati viene eseguita a livello di blocco, con blocchi di dati ad accesso frequente nel Tier di performance all-flash contrassegnati come blocchi a caldo e ad accesso non frequente contrassegnati come cold.
L'utilizzo di FabricPool consente di ridurre i costi dello storage senza compromettere performance, efficienza, sicurezza o protezione. FabricPool è trasparente per le applicazioni aziendali e sfrutta l'efficienza del cloud riducendo il TCO dello storage senza dover riprogettare l'infrastruttura applicativa.
FlexPod può trarre vantaggio dalle funzionalità di tiering dello storage di FabricPool per un utilizzo più efficiente dello storage flash ONTAP. Le macchine virtuali inattive (VM), i modelli di macchine virtuali utilizzati di rado e i backup delle macchine virtuali da NetApp SnapCenter per vSphere possono consumare spazio prezioso nel volume del datastore. Lo spostamento dei dati cold nel Tier cloud libera spazio e risorse per applicazioni mission-critical ad alte performance ospitate nell'infrastruttura FlexPod.

|
I protocolli Fibre Channel e iSCSI in genere impiegano più tempo prima di riscontrare un timeout (da 60 a 120 secondi), ma non riprovano a stabilire una connessione nello stesso modo dei protocolli NAS. In caso di timeout di un protocollo SAN, l'applicazione deve essere riavviata. Anche una breve interruzione potrebbe essere disastrosa per le applicazioni di produzione che utilizzano i protocolli SAN perché non esiste alcun modo per garantire la connettività ai cloud pubblici. Per evitare questo problema, NetApp consiglia di utilizzare cloud privati quando si tierano i dati a cui si accede dai protocolli SAN. |
In ONTAP 9.6, FabricPool si integra con tutti i principali provider di cloud pubblico: Alibaba Cloud Object Storage Service, Amazon AWS S3, Google Cloud Storage, IBM Cloud Object Storage e Microsoft Azure Blob Storage. Questo report si concentra sullo storage Amazon AWS S3 come livello di oggetti cloud preferito.
L'aggregato composito
Un'istanza di FabricPool viene creata associando un aggregato flash ONTAP a un archivio di oggetti cloud, ad esempio un bucket AWS S3, per creare un aggregato composito. Quando i volumi vengono creati all'interno dell'aggregato composito, possono sfruttare le funzionalità di tiering di FabricPool. Quando i dati vengono scritti nel volume, ONTAP assegna una temperatura a ciascuno dei blocchi di dati. Quando il blocco viene scritto per la prima volta, viene assegnata una temperatura di caldo. Con il passare del tempo, se i dati non sono accessibili, vengono sottoposti a un processo di raffreddamento fino a quando non viene assegnato uno stato Cold. Questi blocchi di dati ad accesso non frequente vengono quindi suddivisi in tiering dall'aggregato SSD delle performance e nell'archivio di oggetti cloud.
Il periodo di tempo che intercorre tra il momento in cui un blocco viene designato come cold e il momento in cui viene spostato nello storage a oggetti cloud viene modificato dalla policy di tiering del volume in ONTAP. Un'ulteriore granularità si ottiene modificando le impostazioni di ONTAP che controllano il numero di giorni necessari per far sì che un blocco diventi freddo. I candidati per il tiering dei dati sono le snapshot dei volumi tradizionali, i backup di SnapCenter per vSphere VM e altri backup basati su Snapshot di NetApp e tutti i blocchi utilizzati di rado in un datastore vSphere, come i modelli di macchine virtuali e i dati delle macchine virtuali a cui si accede di rado.
Reporting dei dati inattivi
Il reporting dei dati inattivi (IDR) è disponibile in ONTAP per valutare la quantità di dati cold che possono essere suddivisi in più livelli da un aggregato. IDR è attivato per impostazione predefinita in ONTAP 9.6 e utilizza un criterio di raffreddamento predefinito di 31 giorni per determinare quali dati nel volume sono inattivi.
|
|
La quantità di dati cold a più livelli dipende dai criteri di tiering impostati sul volume. Questa quantità può essere diversa dalla quantità di dati cold rilevata da IDR utilizzando il periodo di raffreddamento predefinito di 31 giorni. |
Creazione di oggetti e spostamento dei dati
FabricPool lavora a livello di NetApp WAFL Block, raffreddando i blocchi, concatenandoli in oggetti storage e migrando tali oggetti a un livello cloud. Ogni oggetto FabricPool è di 4 MB ed è composto da 1,024 blocchi da 4 KB. La dimensione dell'oggetto è fissa a 4 MB in base ai consigli sulle performance dei principali cloud provider e non può essere modificata. Se i blocchi cold vengono letti e resi hot, vengono recuperati solo i blocchi richiesti nell'oggetto da 4 MB e spostati di nuovo nel Tier di performance. L'intero oggetto e l'intero file non vengono migrati di nuovo. Vengono migrati solo i blocchi necessari.
|
|
Se ONTAP rileva un'opportunità di readhead sequenziali, richiede i blocchi dal Tier cloud prima di essere letti per migliorare le performance. |
Per impostazione predefinita, i dati vengono spostati nel Tier cloud solo quando l'aggregato delle performance viene utilizzato oltre il 50%. Questa soglia può essere impostata su una percentuale inferiore per consentire lo spostamento di una minore quantità di storage dei dati sul Tier flash delle performance nel cloud. Questo potrebbe essere utile se la strategia di tiering è quella di spostare i dati cold solo quando l'aggregato si avvicina alla capacità.
Se l'utilizzo del Tier di performance è superiore al 70% della capacità, i dati cold vengono letti direttamente dal Tier cloud senza essere riscritti nel Tier di performance. Impedendo il write-back dei dati cold su aggregati fortemente utilizzati, FabricPool preserva l'aggregato per i dati attivi.
Recuperare lo spazio del Tier di performance
Come discusso in precedenza, il caso d'utilizzo principale di FabricPool è quello di facilitare l'utilizzo più efficiente dello storage flash on-premise dalle performance elevate. I dati cold sotto forma di snapshot di volumi e backup di macchine virtuali dell'infrastruttura virtuale FlexPod possono occupare una quantità significativa di costoso storage flash. È possibile liberare lo storage Tier dalle performance preziose implementando una delle due policy di tiering: Snapshot-only o Auto.
Policy di tiering solo Snapshot
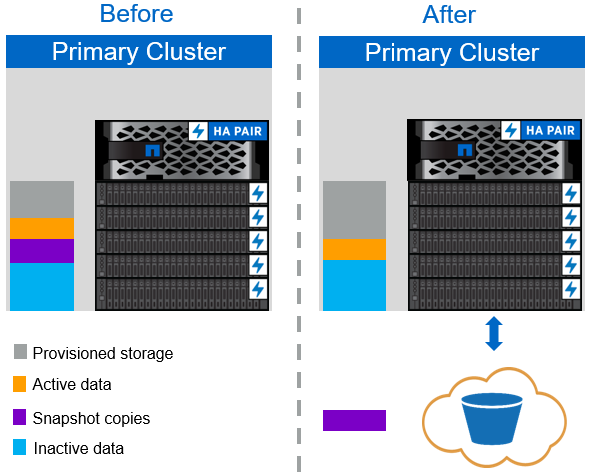
La policy di tiering Snapshot-Only, illustrata nella figura seguente, sposta i dati snapshot dei volumi cold e i backup SnapCenter per vSphere delle macchine virtuali che occupano spazio ma non condividono blocchi con il file system attivo in un archivio di oggetti cloud. La policy di tiering Snapshot-Only sposta i blocchi di dati cold nel Tier cloud. Se è necessario un ripristino, i blocchi freddi nel cloud vengono resi hot e spostati di nuovo sul Tier flash delle performance on-premise.
Policy di tiering automatico
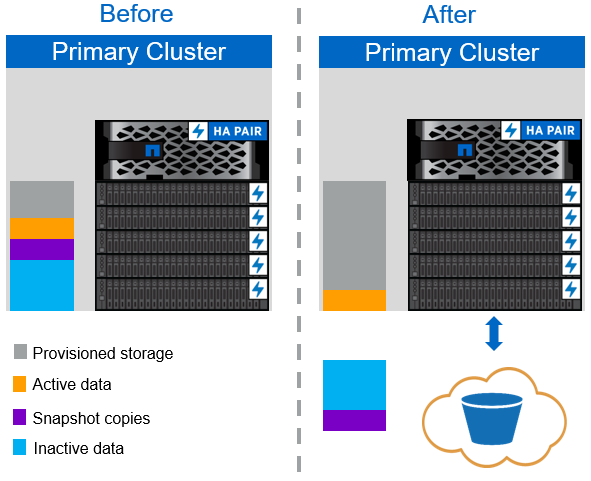
La policy di tiering automatico di FabricPool, illustrata nella figura seguente, non solo sposta i blocchi di dati cold snapshot nel cloud, ma sposta anche i blocchi cold nel file system attivo. Questo può includere modelli di macchine virtuali ed eventuali dati di macchine virtuali inutilizzati nel volume dell'archivio dati. I blocchi a freddo che vengono spostati sono controllati da tiering-minimum-cooling-days impostazione del volume. Se un'applicazione legge casualmente i blocchi freddi nel Tier cloud, questi vengono resi hot e riportati al Tier di performance. Tuttavia, se i blocchi freddi vengono letti da un processo sequenziale come un antivirus scanner, i blocchi rimangono freddi e persistono nell'archivio di oggetti cloud; non vengono spostati di nuovo al livello di performance.
Quando si utilizza la policy di tiering automatico, i blocchi a cui si accede raramente e che vengono resi a caldo vengono ritirati dal Tier cloud alla velocità della connettività cloud. Questo può influire sulle prestazioni delle macchine virtuali se l'applicazione è sensibile alla latenza, che deve essere presa in considerazione prima di utilizzare il criterio di tiering automatico nel datastore. NetApp consiglia di posizionare le LIF Intercluster su porte con una velocità di 10 GbE per ottenere performance adeguate.
|
|
Il profiler dell'archivio di oggetti deve essere utilizzato per verificare la latenza e il throughput nell'archivio di oggetti prima di associarlo a un aggregato FabricPool. |
Policy di tiering
A differenza delle policy Auto e Snapshot-Only, la policy all tiering sposta immediatamente interi volumi di dati nel Tier cloud. Questa policy è più adatta alla protezione dei dati secondari o ai volumi di archiviazione per i quali i dati devono essere conservati per scopi storici o normativi, ma a cui si accede raramente. La policy all non è consigliata per i volumi del datastore VMware perché qualsiasi dato scritto nel datastore viene immediatamente spostato nel Tier cloud. Le successive operazioni di lettura vengono eseguite dal cloud e potrebbero potenzialmente introdurre problemi di performance per le macchine virtuali e le applicazioni che risiedono nel volume del datastore.
Sicurezza
La sicurezza è una preoccupazione centrale per il cloud e per FabricPool. Tutte le funzionalità di sicurezza native di ONTAP sono supportate nel Tier di performance e lo spostamento dei dati è protetto quando vengono trasferiti al Tier cloud. FabricPool utilizza "AES-256-GCM" algoritmo di crittografia sul tier di performance e mantiene la crittografia end-to-end nel tier cloud. I blocchi di dati spostati nell'archivio di oggetti cloud sono protetti con TLS (Transport Layer Security) v1.2 per mantenere la riservatezza e l'integrità dei dati tra i livelli di storage.
|
|
La comunicazione con l'archivio di oggetti cloud tramite una connessione non crittografata è supportata ma non consigliata da NetApp. |
Crittografia dei dati
La crittografia dei dati è fondamentale per la protezione della proprietà intellettuale, delle informazioni commerciali e delle informazioni personali dei clienti. FabricPool supporta completamente la crittografia dei volumi NetApp (NVE) e la crittografia dello storage NetApp (NSE) per mantenere le strategie di protezione dei dati esistenti. Tutti i dati crittografati nel Tier di performance rimangono crittografati quando vengono spostati nel Tier cloud. Le chiavi di crittografia lato client sono di proprietà di ONTAP e le chiavi di crittografia dell'archivio di oggetti lato server sono di proprietà del rispettivo archivio di oggetti cloud. Tutti i dati non crittografati con NVE vengono crittografati con l'algoritmo AES-256-GCM. Non sono supportati altri tipi di crittografia AES-256.
|
|
L'utilizzo di NSE o NVE è opzionale e non è richiesto per l'utilizzo di FabricPool. |