

Panoramica della verifica della soluzione
 Suggerisci modifiche
Suggerisci modifiche
In questa sezione abbiamo eseguito query di test SQL da più fonti per verificare la funzionalità, testare e verificare lo spillover sullo storage NetApp .
Query SQL su Object Storage
-
Imposta la memoria a 250 GB per server in dremio.env
root@hadoopmaster:~# for i in hadoopmaster hadoopnode1 hadoopnode2 hadoopnode3 hadoopnode4; do ssh $i "hostname; grep -i DREMIO_MAX_MEMORY_SIZE_MB /opt/dremio/conf/dremio-env; cat /proc/meminfo | grep -i memtotal"; done hadoopmaster #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515760 kB hadoopnode1 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515860 kB hadoopnode2 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515864 kB hadoopnode3 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 264004556 kB node4 #DREMIO_MAX_MEMORY_SIZE_MB=120000 DREMIO_MAX_MEMORY_SIZE_MB=250000 MemTotal: 263515484 kB root@hadoopmaster:~#
-
Controllare la posizione di spillover (${DREMIO_HOME}"/dremiocache) nel file dremio.conf e i dettagli di archiviazione.
paths: { # the local path for dremio to store data. local: ${DREMIO_HOME}"/dremiocache" # the distributed path Dremio data including job results, downloads, uploads, etc #dist: "hdfs://hadoopmaster:9000/dremiocache" dist: "dremioS3:///dremioconf" } services: { coordinator.enabled: true, coordinator.master.enabled: true, executor.enabled: false, flight.use_session_service: false } zookeeper: "10.63.150.130:2181,10.63.150.153:2181,10.63.150.151:2181" services.coordinator.master.embedded-zookeeper.enabled: false -
Indicare la posizione di spillover di Dremio allo storage NFS NetApp
root@hadoopnode1:~# ls -ltrh /dremiocache total 4.0K drwx------ 3 nobody nogroup 4.0K Sep 13 16:00 spilling_stlrx2540m4-12-10g_45678 root@hadoopnode1:~# ls -ltrh /opt/dremio/dremiocache/ total 8.0K drwxr-xr-x 3 dremio dremio 4.0K Aug 22 18:19 spill_old drwxr-xr-x 4 dremio dremio 4.0K Aug 22 18:19 cm lrwxrwxrwx 1 root root 12 Aug 22 19:03 spill -> /dremiocache root@hadoopnode1:~# ls -ltrh /dremiocache total 4.0K drwx------ 3 nobody nogroup 4.0K Sep 13 16:00 spilling_stlrx2540m4-12-10g_45678 root@hadoopnode1:~# df -h /dremiocache Filesystem Size Used Avail Use% Mounted on 10.63.150.159:/dremiocache_hadoopnode1 2.1T 209M 2.0T 1% /dremiocache root@hadoopnode1:~#
-
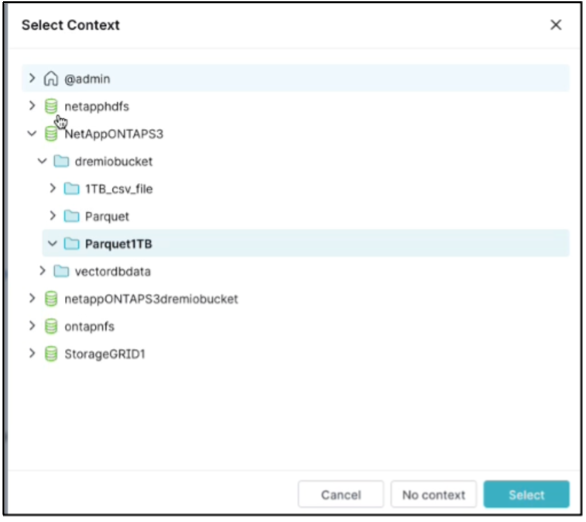
Seleziona il contesto. Nel nostro test, abbiamo eseguito il test sui file parquet generati da TPCDS residenti in ONTAP S3. Dashboard Dremio → SQL runner → contesto → NetAppONTAPS3→Parquet1TB
-
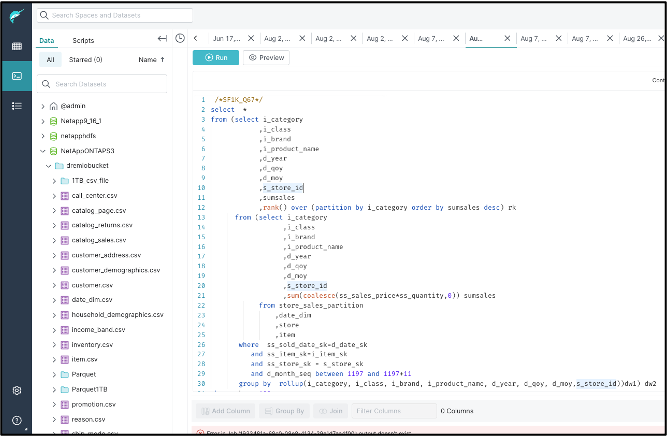
Eseguire la query TPC-DS67 dalla dashboard di Dremio
-
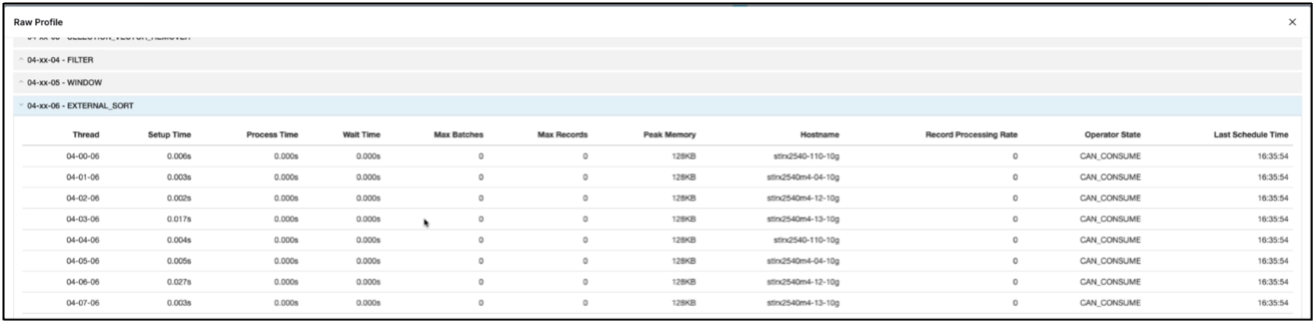
Verificare che il lavoro sia in esecuzione su tutti gli esecutori. Dashboard di Dremio → lavori → <jobid> → profilo raw → seleziona EXTERNAL_SORT → Nome host
-
Quando si esegue la query SQL, è possibile controllare la cartella divisa per la memorizzazione dei dati nella cache nel controller di archiviazione NetApp .
root@hadoopnode1:~# ls -ltrh /dremiocache total 4.0K drwx------ 3 nobody nogroup 4.0K Sep 13 16:00 spilling_stlrx2540m4-12-10g_45678 root@hadoopnode1:~# ls -ltrh /dremiocache/spilling_stlrx2540m4-12-10g_45678/ total 4.0K drwxr-xr-x 2 root daemon 4.0K Sep 13 16:23 1726243167416
-
La query SQL è stata completata con spill over

-
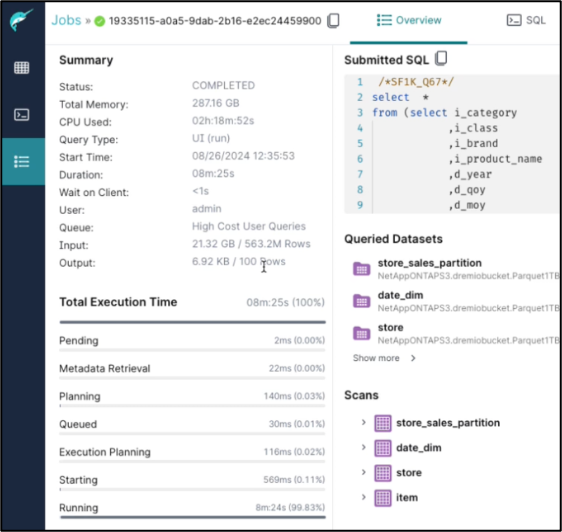
Riepilogo del completamento del lavoro.
-
Controllare la dimensione dei dati fuoriusciti
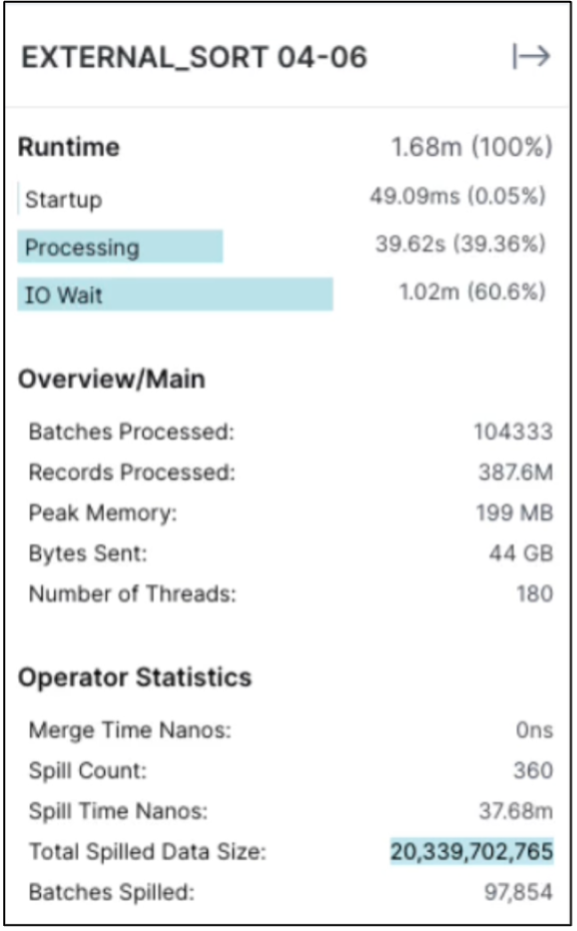
La stessa procedura è applicabile per l'archiviazione di oggetti NAS e StorageGRID .