Caso d'uso 2: Backup e disaster recovery dal cloud all'ambiente locale
 Suggerisci modifiche
Suggerisci modifiche
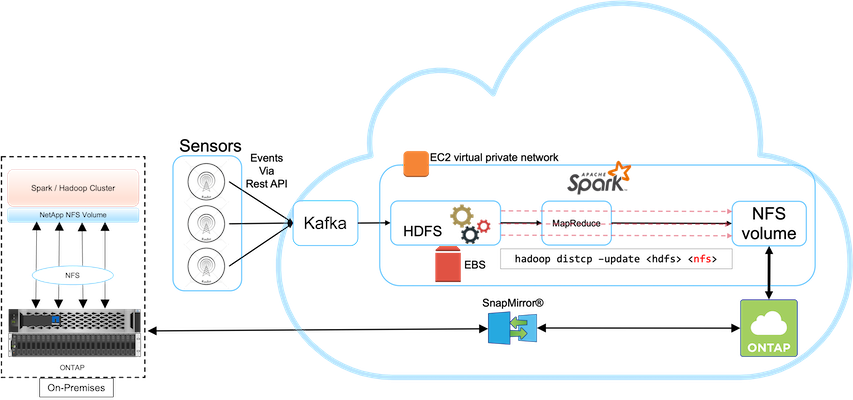
Questo caso d'uso si basa su un cliente di trasmissione che ha bisogno di eseguire il backup dei dati di analisi basati su cloud nel proprio data center locale, come illustrato nella figura seguente.
Scenario
In questo scenario, i dati dei sensori IoT vengono acquisiti nel cloud e analizzati utilizzando un cluster Apache Spark open source all'interno di AWS. Il requisito è quello di eseguire il backup dei dati elaborati dal cloud in locale.
Requisiti e sfide
I principali requisiti e sfide per questo caso d'uso includono:
-
L'abilitazione della protezione dei dati non dovrebbe avere alcun effetto sulle prestazioni del cluster Spark/Hadoop di produzione nel cloud.
-
I dati dei sensori cloud devono essere trasferiti e protetti in locale in modo efficiente e sicuro.
-
Flessibilità nel trasferire dati dal cloud all'ambiente locale in diverse condizioni, ad esempio su richiesta, istantaneamente e durante periodi di basso carico del cluster.
Soluzione
Il cliente utilizza AWS Elastic Block Store (EBS) per l'archiviazione HDFS del cluster Spark per ricevere e acquisire dati da sensori remoti tramite Kafka. Di conseguenza, l'archiviazione HDFS funge da origine per i dati di backup.
Per soddisfare questi requisiti, NetApp ONTAP Cloud viene distribuito in AWS e viene creata una condivisione NFS che funge da destinazione di backup per il cluster Spark/Hadoop.
Dopo aver creato la condivisione NFS, copiare i dati dall'archiviazione EBS HDFS nella condivisione NFS ONTAP . Dopo che i dati risiedono in NFS in ONTAP Cloud, la tecnologia SnapMirror può essere utilizzata per eseguire il mirroring dei dati dal cloud all'archiviazione locale, secondo necessità, in modo sicuro ed efficiente.
Questa immagine mostra la soluzione di backup e disaster recovery dal cloud a quella on-premise.