

Procedura di prova e risultati dettagliati
 Suggerisci modifiche
Suggerisci modifiche
In questa sezione vengono descritti i risultati dettagliati della procedura di test.
Addestramento al riconoscimento delle immagini tramite ResNet in ONTAP
Abbiamo eseguito il benchmark ResNet50 con uno e due server SR670 V2. Questo test ha utilizzato il contenitore NGC MXNet 22.04-py3 per eseguire l'addestramento.
Per questa convalida abbiamo utilizzato la seguente procedura di test:
-
Abbiamo cancellato la cache dell'host prima di eseguire lo script per assicurarci che i dati non fossero già memorizzati nella cache:
sync ; sudo /sbin/sysctl vm.drop_caches=3
-
Abbiamo eseguito lo script di benchmark con il set di dati ImageNet nell'archiviazione del server (archiviazione SSD locale) e sul sistema di archiviazione NetApp AFF .
-
Abbiamo convalidato le prestazioni di rete e di archiviazione locale utilizzando
ddcomando. -
Per l'esecuzione su un singolo nodo, abbiamo utilizzato il seguente comando:
python train_imagenet.py --gpus 0,1,2,3,4,5,6,7 --batch-size 408 --kv-store horovod --lr 10.5 --mom 0.9 --lr-step-epochs pow2 --lars-eta 0.001 --label-smoothing 0.1 --wd 5.0e-05 --warmup-epochs 2 --eval-period 4 --eval-offset 2 --optimizer sgdwfastlars --network resnet-v1b-stats-fl --num-layers 50 --num-epochs 37 --accuracy-threshold 0.759 --seed 27081 --dtype float16 --disp-batches 20 --image-shape 4,224,224 --fuse-bn-relu 1 --fuse-bn-add-relu 1 --bn-group 1 --min-random-area 0.05 --max-random-area 1.0 --conv-algo 1 --force-tensor-core 1 --input-layout NHWC --conv-layout NHWC --batchnorm-layout NHWC --pooling-layout NHWC --batchnorm-mom 0.9 --batchnorm-eps 1e-5 --data-train /data/train.rec --data-train-idx /data/train.idx --data-val /data/val.rec --data-val-idx /data/val.idx --dali-dont-use-mmap 0 --dali-hw-decoder-load 0 --dali-prefetch-queue 5 --dali-nvjpeg-memory-padding 256 --input-batch-multiplier 1 --dali- threads 6 --dali-cache-size 0 --dali-roi-decode 1 --dali-preallocate-width 5980 --dali-preallocate-height 6430 --dali-tmp-buffer-hint 355568328 --dali-decoder-buffer-hint 1315942 --dali-crop-buffer-hint 165581 --dali-normalize-buffer-hint 441549 --profile 0 --e2e-cuda-graphs 0 --use-dali
-
Per le esecuzioni distribuite, abbiamo utilizzato il modello di parallelizzazione del server dei parametri. Abbiamo utilizzato due server di parametri per nodo e abbiamo impostato il numero di epoche in modo che fosse lo stesso dell'esecuzione a nodo singolo. Lo abbiamo fatto perché la formazione distribuita spesso richiede più epoche a causa della sincronizzazione imperfetta tra i processi. Il diverso numero di epoche può alterare i confronti tra casi a nodo singolo e casi distribuiti.
Velocità di lettura dei dati: archiviazione locale rispetto a quella di rete
La velocità di lettura è stata testata utilizzando il dd comando su uno dei file per il set di dati ImageNet. Nello specifico, abbiamo eseguito i seguenti comandi sia per i dati locali che per quelli di rete:
sync ; sudo /sbin/sysctl vm.drop_caches=3dd if=/a400-100g/netapp-ra/resnet/data/preprocessed_data/train.rec of=/dev/null bs=512k count=2048Results (average of 5 runs): Local storage: 1.7 GB/s Network storage: 1.5 GB/s.
Entrambi i valori sono simili, il che dimostra che l'archiviazione di rete può fornire dati a una velocità simile a quella dell'archiviazione locale.
Caso d'uso condiviso: lavori multipli, indipendenti e simultanei
Questo test ha simulato il caso d'uso previsto per questa soluzione: formazione AI multi-lavoro e multi-utente. Ogni nodo ha eseguito il proprio addestramento utilizzando l'archiviazione di rete condivisa. I risultati sono visualizzati nella figura seguente, che mostra come il caso di soluzione abbia fornito prestazioni eccellenti, con tutti i processi eseguiti sostanzialmente alla stessa velocità dei singoli processi. La produttività totale è proporzionale al numero di nodi.
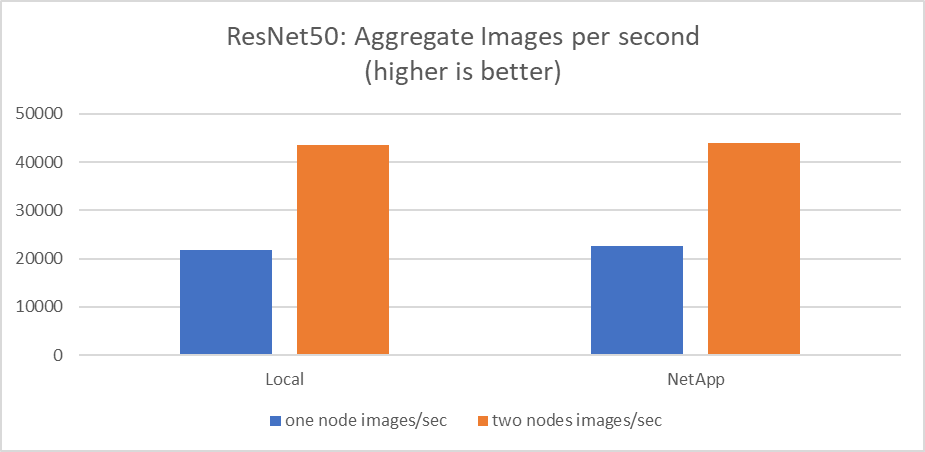
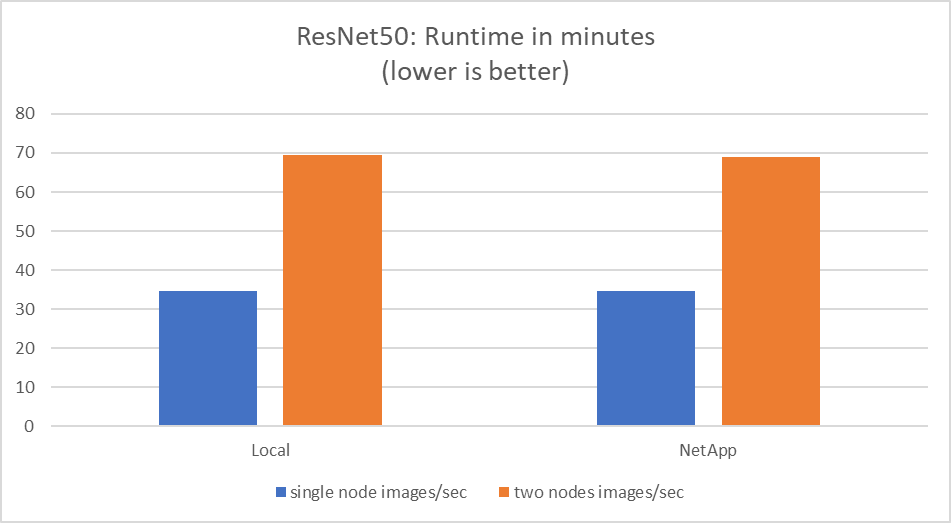
Questi grafici presentano il tempo di esecuzione in minuti e le immagini aggregate al secondo per i nodi di elaborazione che hanno utilizzato otto GPU da ciascun server su una rete client da 100 GbE, combinando sia il modello di addestramento simultaneo che il modello di addestramento singolo. Il tempo di esecuzione medio del modello di addestramento è stato di 35 minuti e 9 secondi. La durata individuale è stata di 34 minuti e 32 secondi, 36 minuti e 21 secondi, 34 minuti e 37 secondi, 35 minuti e 25 secondi e 34 minuti e 31 secondi. Le immagini medie al secondo per il modello di addestramento erano 22.573, mentre le singole immagini al secondo erano 21.764; 23.438; 22.556; 22.564; e 22.547.
In base alla nostra convalida, un modello di addestramento indipendente con un runtime dati NetApp è durato 34 minuti e 54 secondi con 22.231 immagini/sec. Un modello di addestramento indipendente con un runtime di dati locali (DAS) è stato di 34 minuti e 21 secondi con 22.102 immagini/sec. Durante queste esecuzioni, l'utilizzo medio della GPU è stato del 96%, come osservato su nvidia-smi. Si noti che questa media include la fase di test, durante la quale non sono state utilizzate GPU, mentre l'utilizzo della CPU è stato del 40%, come misurato da mpstat. Ciò dimostra che la velocità di trasmissione dei dati è sufficiente in ogni caso.