

TR-4928: IA responsabile e inferenza riservata - NetApp AI con trasformazione di immagini e dati Protopia
 Suggerisci modifiche
Suggerisci modifiche
Sathish Thyagarajan, Michael Oglesby, NetApp Byung Hoon Ahn, Jennifer Cwagenberg, Protopia
Con l'avvento della cattura e dell'elaborazione delle immagini, le interpretazioni visive sono diventate parte integrante della comunicazione. L'intelligenza artificiale (IA) nell'elaborazione delle immagini digitali offre nuove opportunità di business, ad esempio in campo medico per l'identificazione del cancro e di altre malattie, nell'analisi visiva geospaziale per lo studio dei rischi ambientali, nel riconoscimento di modelli, nell'elaborazione video per la lotta alla criminalità e così via. Tuttavia, questa opportunità comporta anche delle responsabilità straordinarie.
Più decisioni le organizzazioni affidano all'intelligenza artificiale, più accettano rischi legati alla privacy e alla sicurezza dei dati, nonché a questioni legali, etiche e normative. L'intelligenza artificiale responsabile consente una pratica che consente alle aziende e alle organizzazioni governative di creare fiducia e governance, fondamentali per l'intelligenza artificiale su larga scala nelle grandi aziende. Questo documento descrive una soluzione di inferenza AI convalidata da NetApp in tre scenari diversi, utilizzando le tecnologie di gestione dei dati NetApp con il software di offuscamento dei dati Protopia per privatizzare i dati sensibili e ridurre i rischi e le preoccupazioni etiche.
Ogni giorno milioni di immagini vengono generate tramite vari dispositivi digitali, sia da consumatori che da aziende. La conseguente enorme esplosione di dati e di carico di lavoro computazionale spinge le aziende a rivolgersi alle piattaforme di cloud computing per ottenere scalabilità ed efficienza. Nel frattempo, sorgono preoccupazioni relative alla privacy delle informazioni sensibili contenute nei dati delle immagini con il trasferimento su un cloud pubblico. La mancanza di garanzie di sicurezza e privacy diventa il principale ostacolo all'implementazione di sistemi di intelligenza artificiale per l'elaborazione delle immagini.
Inoltre, c'è il "diritto alla cancellazione" dal GDPR, il diritto di un individuo di richiedere a un'organizzazione di cancellare tutti i suoi dati personali. C'è anche il "Legge sulla privacy" , che stabilisce un codice di corrette pratiche informative. Le immagini digitali, come le fotografie, possono costituire dati personali ai sensi del GDPR, che disciplina le modalità di raccolta, elaborazione e cancellazione dei dati. La mancata osservanza di tale norma costituisce una violazione del GDPR, che potrebbe comportare pesanti sanzioni per violazione delle norme, con conseguenti gravi danni per le organizzazioni. I principi di privacy sono tra i pilastri dell'implementazione di un'intelligenza artificiale responsabile che garantisca l'equità nelle previsioni dei modelli di apprendimento automatico (ML) e di apprendimento profondo (DL) e riduca i rischi associati alla violazione della privacy o della conformità normativa.
Questo documento descrive una soluzione di progettazione convalidata in tre diversi scenari con e senza offuscamento delle immagini, rilevanti per preservare la privacy e implementare una soluzione di intelligenza artificiale responsabile:
-
Scenario 1. Inferenza su richiesta all'interno del notebook Jupyter.
-
Scenario 2. Inferenza batch su Kubernetes.
-
Scenario 3. Server di inferenza NVIDIA Triton.
Per questa soluzione utilizziamo il Face Detection Data Set and Benchmark (FDDB), un set di dati di regioni del viso progettato per studiare il problema del rilevamento del viso senza vincoli, combinato con il framework di apprendimento automatico PyTorch per l'implementazione di FaceBox. Questo set di dati contiene le annotazioni per 5171 volti in un set di 2845 immagini di varie risoluzioni. Inoltre, questo rapporto tecnico presenta alcune delle aree di soluzione e dei casi d'uso rilevanti raccolti dai clienti NetApp e dai tecnici sul campo in situazioni in cui questa soluzione è applicabile.
Pubblico di destinazione
Il presente rapporto tecnico è destinato ai seguenti destinatari:
-
Leader aziendali e architetti aziendali che desiderano progettare e implementare un'intelligenza artificiale responsabile e affrontare le problematiche relative alla protezione dei dati e alla privacy relative all'elaborazione delle immagini facciali negli spazi pubblici.
-
Data scientist, data engineer, ricercatori di intelligenza artificiale/apprendimento automatico (ML) e sviluppatori di sistemi di intelligenza artificiale/ML che mirano a proteggere e preservare la privacy.
-
Architetti aziendali che progettano soluzioni di offuscamento dei dati per modelli e applicazioni AI/ML conformi agli standard normativi quali GDPR, CCPA o il Privacy Act del Dipartimento della Difesa (DoD) e delle organizzazioni governative.
-
Data scientist e ingegneri dell'intelligenza artificiale cercano modi efficienti per implementare modelli di deep learning (DL) e di inferenza AI/ML/DL che proteggano le informazioni sensibili.
-
I gestori dei dispositivi edge e gli amministratori dei server edge sono responsabili dell'implementazione e della gestione dei modelli di inferenza edge.
Architettura della soluzione
Questa soluzione è progettata per gestire carichi di lavoro di intelligenza artificiale in tempo reale e in batch su grandi set di dati, sfruttando la potenza di elaborazione delle GPU insieme alle CPU tradizionali. Questa convalida dimostra l'inferenza che preserva la privacy per l'apprendimento automatico e la gestione ottimale dei dati richiesta alle organizzazioni che cercano implementazioni di intelligenza artificiale responsabili. Questa soluzione fornisce un'architettura adatta per una piattaforma Kubernetes a nodo singolo o multiplo per l'edge computing e il cloud computing interconnessi con NetApp ONTAP AI nel core on-premise, NetApp DataOps Toolkit e il software di offuscamento Protopia utilizzando le interfacce Jupyter Lab e CLI. La figura seguente mostra la panoramica dell'architettura logica del data fabric basato su NetApp con DataOps Toolkit e Protopia.
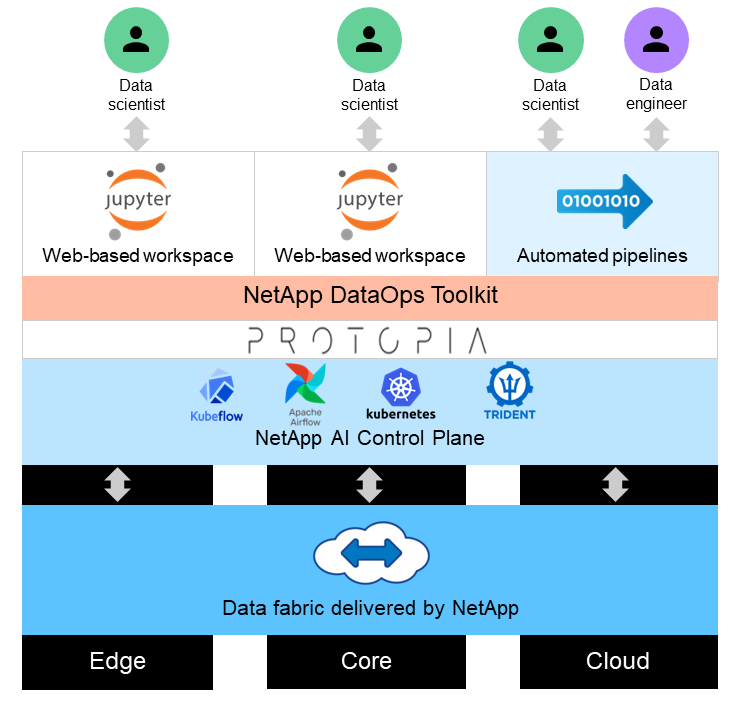
Il software di offuscamento Protopia funziona perfettamente su NetApp DataOps Toolkit e trasforma i dati prima di lasciare il server di archiviazione.