

Esempio di flusso di lavoro: addestrare un modello di riconoscimento delle immagini utilizzando Kubeflow e NetApp DataOps Toolkit
 Suggerisci modifiche
Suggerisci modifiche
Questa sezione descrive i passaggi necessari per addestrare e distribuire una rete neurale per il riconoscimento delle immagini utilizzando Kubeflow e NetApp DataOps Toolkit. Questo esempio vuole mostrare un lavoro di formazione che incorpora l'archiviazione NetApp .
Prerequisiti
Creare un Dockerfile con le configurazioni richieste da utilizzare per i passaggi di training e test all'interno della pipeline Kubeflow. Ecco un esempio di Dockerfile:
FROM pytorch/pytorch:latest
RUN pip install torchvision numpy scikit-learn matplotlib tensorboard
WORKDIR /app
COPY . /app
COPY train_mnist.py /app/train_mnist.py
CMD ["python", "train_mnist.py"]A seconda delle tue esigenze, installa tutte le librerie e i pacchetti necessari per eseguire il programma. Prima di addestrare il modello di Machine Learning, si presuppone che si disponga già di una distribuzione Kubeflow funzionante.
Addestrare una piccola rete neurale su dati MNIST utilizzando pipeline PyTorch e Kubeflow
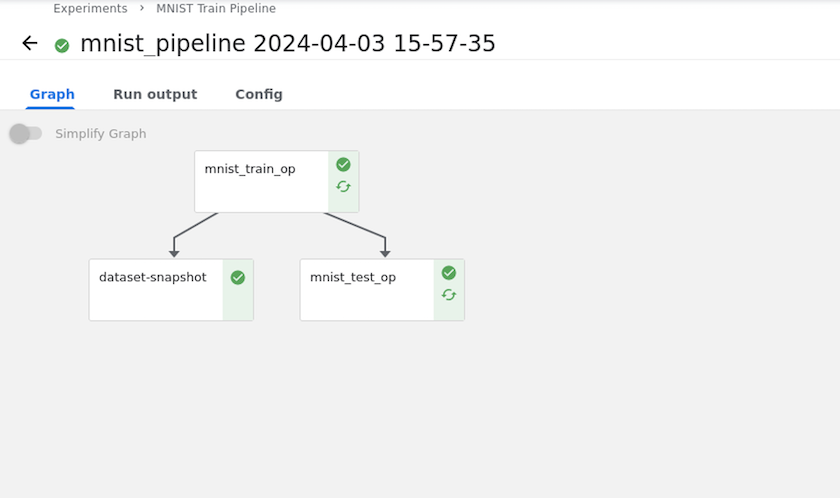
Utilizziamo l'esempio di una piccola rete neurale addestrata sui dati MNIST. Il set di dati MNIST è costituito da immagini manoscritte di cifre da 0 a 9. Le immagini hanno una dimensione di 28x28 pixel. Il set di dati è suddiviso in 60.000 immagini di treno e 10.000 immagini di convalida. La rete neurale utilizzata per questo esperimento è una rete feedforward a 2 strati. La formazione viene eseguita utilizzando Kubeflow Pipelines. Fare riferimento alla documentazione "Qui" per maggiori informazioni. La nostra pipeline Kubeflow incorpora l'immagine Docker dalla sezione Prerequisiti.
Visualizza i risultati utilizzando Tensorboard
Una volta addestrato il modello, possiamo visualizzare i risultati utilizzando Tensorboard. "Tensorboard" è disponibile come funzionalità nella dashboard di Kubeflow. Puoi creare un tensorboard personalizzato per il tuo lavoro. Di seguito è riportato un esempio che mostra il grafico dell'accuratezza dell'addestramento rispetto al numero di epoche e della perdita dell'addestramento rispetto al numero di epoche.

Sperimentare con gli iperparametri utilizzando Katib
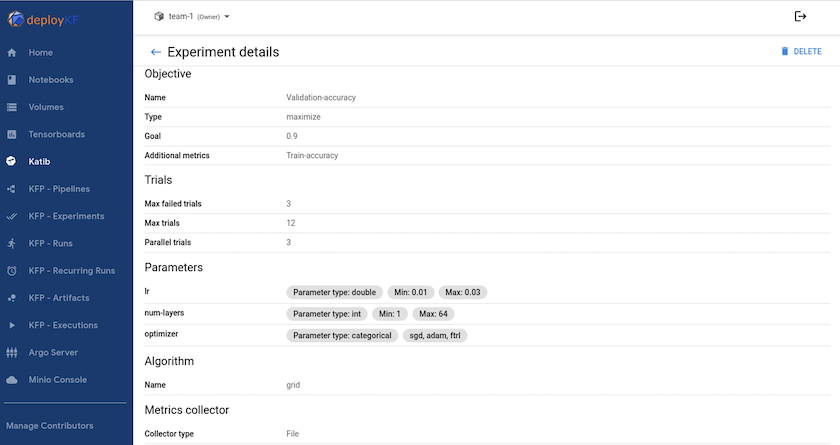
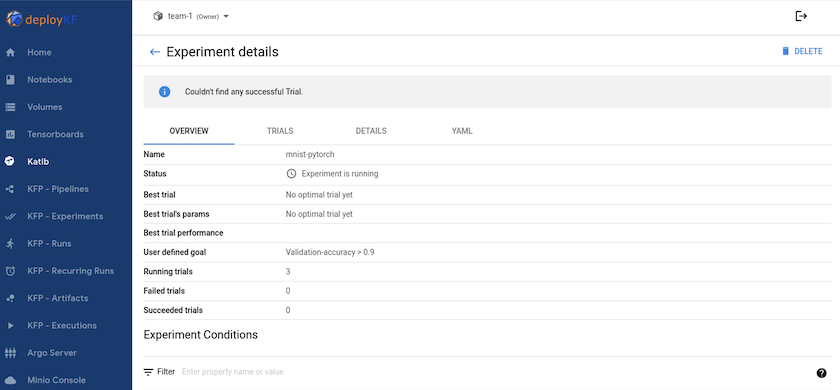
"Katib"è uno strumento all'interno di Kubeflow che può essere utilizzato per sperimentare con gli iperparametri del modello. Per creare un esperimento, definisci prima una metrica/un obiettivo desiderato. Di solito questa è la precisione del test. Una volta definita la metrica, scegli gli iperparametri con cui vuoi sperimentare (ottimizzatore/tasso di apprendimento/numero di livelli). Katib esegue una scansione degli iperparametri con i valori definiti dall'utente per trovare la migliore combinazione di parametri che soddisfi la metrica desiderata. È possibile definire questi parametri in ogni sezione dell'interfaccia utente. In alternativa, è possibile definire un file YAML con le specifiche necessarie. Di seguito è riportata un'illustrazione di un esperimento di Katib:
Utilizzare gli snapshot NetApp per salvare i dati per la tracciabilità
Durante l'addestramento del modello, potremmo voler salvare un'istantanea del set di dati di addestramento per la tracciabilità. Per fare ciò, possiamo aggiungere un passaggio di snapshot alla pipeline come mostrato di seguito. Per creare lo snapshot, possiamo usare il "Kit degli strumenti NetApp DataOps per Kubernetes" .

Fare riferimento al "Esempio di NetApp DataOps Toolkit per Kubeflow" per maggiori informazioni.