

DR tramite BlueXP DRaaS per datastore VMFS
 Suggerisci modifiche
Suggerisci modifiche
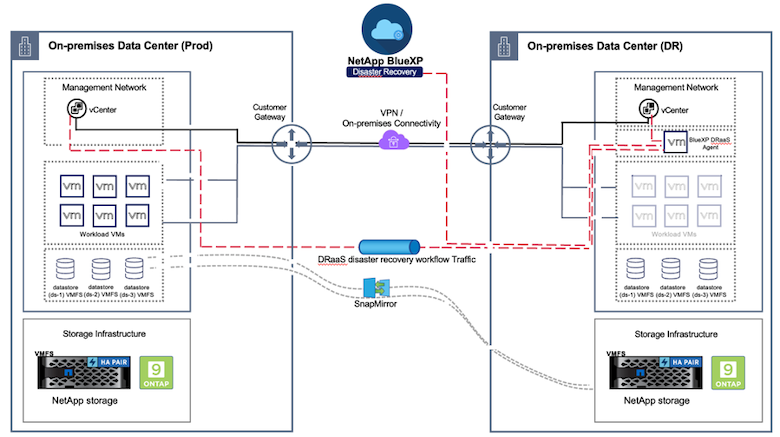
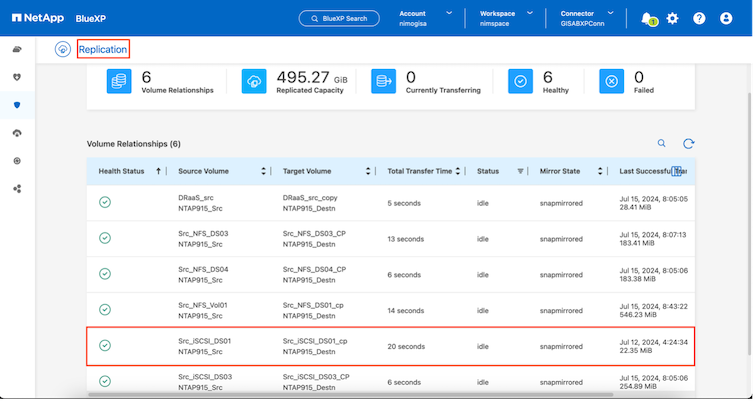
Il disaster recovery mediante replica a livello di blocco dal sito di produzione al sito di disaster recovery è un modo resiliente ed economico per proteggere i carichi di lavoro da interruzioni del sito ed eventi di danneggiamento dei dati, come gli attacchi ransomware. Con la replica NetApp SnapMirror , i carichi di lavoro VMware in esecuzione su sistemi ONTAP locali che utilizzano datastore VMFS possono essere replicati su un altro sistema di storage ONTAP in un data center di ripristino designato in cui risiede VMware
Questa sezione del documento descrive la configurazione di BlueXP DRaaS per impostare il disaster recovery per le VM VMware on-premise su un altro sito designato. Come parte di questa configurazione, l'account BlueXP , il connettore BlueXP e gli array ONTAP sono stati aggiunti all'interno dell'area di lavoro BlueXP , necessari per abilitare la comunicazione da VMware vCenter allo storage ONTAP . Inoltre, questo documento spiega nel dettaglio come configurare la replica tra siti e come impostare e testare un piano di ripristino. L'ultima sezione contiene istruzioni su come eseguire un failover completo del sito e su come effettuare il failback quando il sito primario viene ripristinato e acquistato online.
Utilizzando il servizio BlueXP disaster recovery , integrato nella console NetApp BlueXP , i clienti possono scoprire i propri VMware vCenter on-premise insieme allo storage ONTAP , creare raggruppamenti di risorse, creare un piano di disaster recovery, associarlo a gruppi di risorse e testare o eseguire failover e failback. SnapMirror fornisce la replicazione a blocchi a livello di storage per mantenere i due siti aggiornati con modifiche incrementali, con un RPO fino a 5 minuti. È anche possibile simulare le procedure DR come un'esercitazione regolare senza influire sulla produzione e sui datastore replicati o incorrere in costi di archiviazione aggiuntivi. Il BlueXP disaster recovery sfrutta la tecnologia FlexClone di ONTAP per creare una copia efficiente in termini di spazio del datastore VMFS dall'ultimo snapshot replicato sul sito DR. Una volta completato il test DR, i clienti possono semplicemente eliminare l'ambiente di test, sempre senza alcun impatto sulle risorse di produzione effettivamente replicate. Quando si verifica la necessità (pianificata o meno) di un failover effettivo, con pochi clic il servizio BlueXP disaster recovery organizzerà tutti i passaggi necessari per ripristinare automaticamente le macchine virtuali protette sul sito di disaster recovery designato. Il servizio invertirà anche la relazione SnapMirror con il sito primario e replicherà eventuali modifiche dal secondario al primario per un'operazione di failback, quando necessario. Tutto ciò può essere ottenuto con una frazione del costo rispetto ad altre alternative note.
Iniziare
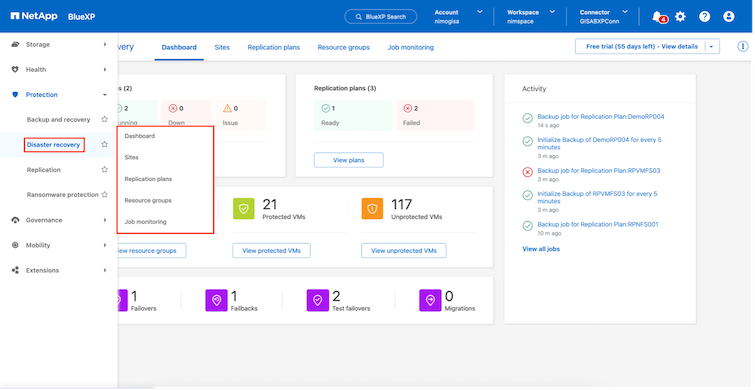
Per iniziare a utilizzare il BlueXP disaster recovery, utilizzare la console BlueXP e quindi accedere al servizio.
-
Accedi a BlueXP.
-
Dal menu di navigazione a sinistra BlueXP , seleziona Protezione > Ripristino di emergenza.
-
Viene visualizzata la Dashboard BlueXP disaster recovery .
Prima di configurare il piano di disaster recovery, assicurarsi che siano soddisfatti i seguenti prerequisiti:
-
BlueXP Connector è configurato in NetApp BlueXP. Il connettore deve essere distribuito in AWS VPC.
-
Le istanze del connettore BlueXP dispongono di connettività con i sistemi di archiviazione e vCenter di origine e di destinazione.
-
In BlueXP sono stati aggiunti sistemi di storage NetApp on-premise che ospitano datastore VMFS per VMware.
-
Quando si utilizzano nomi DNS, è necessario che sia attiva la risoluzione DNS. In caso contrario, utilizzare gli indirizzi IP per vCenter.
-
La replica SnapMirror è configurata per i volumi di datastore basati su VMFS designati.
Una volta stabilita la connettività tra il sito di origine e quello di destinazione, procedere con la configurazione, che dovrebbe richiedere dai 3 ai 5 minuti.

|
NetApp consiglia di distribuire il connettore BlueXP nel sito di disaster recovery o in un terzo sito, in modo che il connettore BlueXP possa comunicare tramite la rete con le risorse di origine e di destinazione durante interruzioni reali o calamità naturali. |
|
|
Al momento della stesura di questo documento, il supporto per i datastore VMFS da locale a locale è in fase di anteprima tecnologica. Questa funzionalità è supportata sia con i datastore VMFS basati sul protocollo FC che ISCSI. |
Configurazione BlueXP disaster recovery
Il primo passo per prepararsi al disaster recovery è individuare e aggiungere le risorse di archiviazione e vCenter locali al BlueXP disaster recovery.
|
|
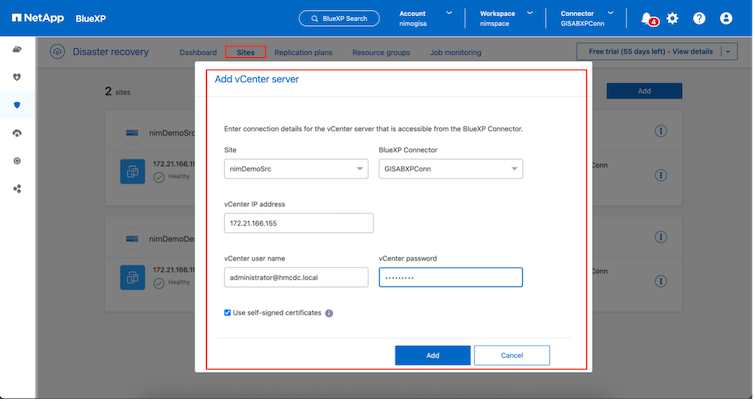
Assicurarsi che i sistemi di archiviazione ONTAP siano aggiunti all'ambiente di lavoro all'interno della tela. Aprire la console BlueXP e selezionare Protezione > Ripristino di emergenza dal menu di navigazione a sinistra. Selezionare Scopri server vCenter oppure utilizzare il menu in alto, selezionare Siti > Aggiungi > Aggiungi vCenter. |
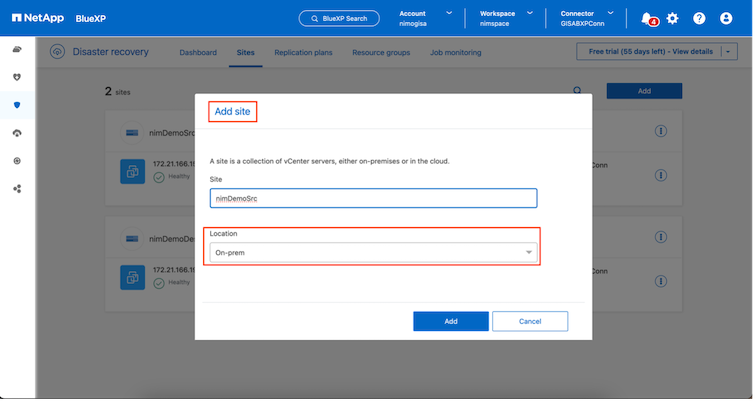
Aggiungere le seguenti piattaforme:
-
Fonte. vCenter locale.
-
Destinazione. VMC SDDC vCenter.
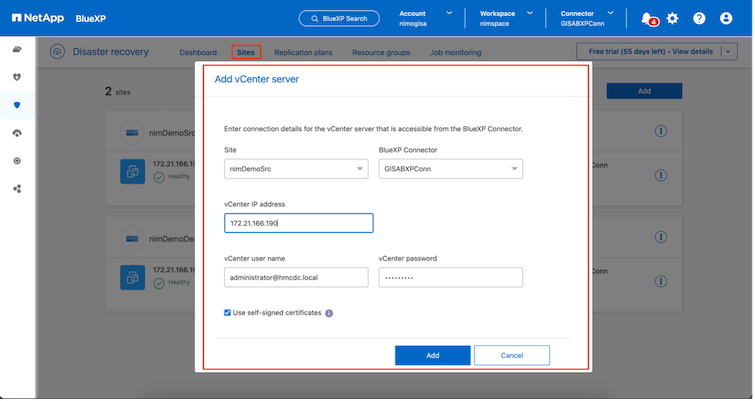
Una volta aggiunti i vCenter, viene attivata la rilevazione automatica.
Configurazione della replica di archiviazione tra il sito di origine e quello di destinazione
SnapMirror utilizza gli snapshot ONTAP per gestire il trasferimento dei dati da una posizione all'altra. Inizialmente, una copia completa basata su uno snapshot del volume di origine viene copiata sulla destinazione per eseguire una sincronizzazione di base. Quando si verificano modifiche ai dati all'origine, viene creato un nuovo snapshot e confrontato con lo snapshot di base. I blocchi che risultano modificati vengono quindi replicati nella destinazione, con lo snapshot più recente che diventa la baseline corrente o lo snapshot comune più recente. Ciò consente di ripetere il processo e di inviare aggiornamenti incrementali alla destinazione.
Una volta stabilita una relazione SnapMirror , il volume di destinazione è in uno stato di sola lettura online e quindi è ancora accessibile. SnapMirror funziona con blocchi fisici di archiviazione, anziché a livello di file o altro livello logico. Ciò significa che il volume di destinazione è una replica identica del volume di origine, inclusi snapshot, impostazioni del volume, ecc. Se il volume di origine utilizza funzionalità di efficienza dello spazio ONTAP , come la compressione dei dati e la deduplicazione dei dati, il volume replicato manterrà queste ottimizzazioni.
L'interruzione della relazione SnapMirror rende il volume di destinazione scrivibile e in genere viene utilizzato per eseguire un failover quando SnapMirror viene utilizzato per sincronizzare i dati in un ambiente DR. SnapMirror è sufficientemente sofisticato da consentire la risincronizzazione efficiente dei dati modificati nel sito di failover con il sistema primario, qualora questo dovesse tornare online in seguito, e quindi consentire il ripristino della relazione SnapMirror originale.
Come configurarlo per VMware Disaster Recovery
Il processo per creare una replica SnapMirror rimane lo stesso per qualsiasi applicazione. Il processo può essere manuale o automatizzato. Il modo più semplice è sfruttare BlueXP per configurare la replica SnapMirror , utilizzando un semplice trascinamento del sistema ONTAP di origine nell'ambiente sulla destinazione per avviare la procedura guidata che guida attraverso il resto del processo.
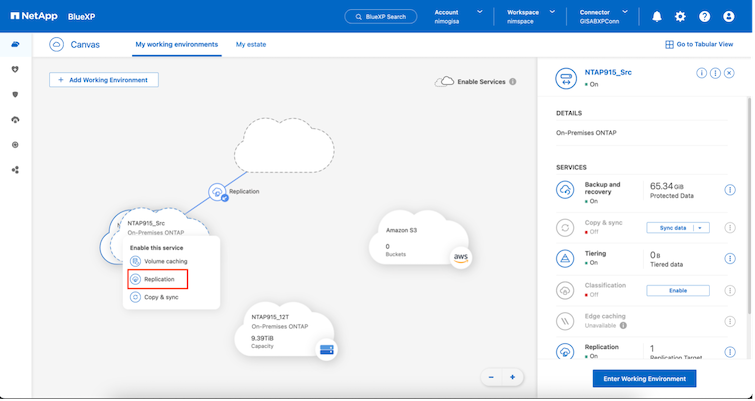
BlueXP DRaaS può anche automatizzare la stessa operazione, a condizione che siano soddisfatti i due criteri seguenti:
-
I cluster di origine e di destinazione hanno una relazione peer.
-
L'SVM di origine e l'SVM di destinazione hanno una relazione peer.
|
|
Se la relazione SnapMirror è già configurata per il volume tramite CLI, BlueXP DRaaS rileva la relazione e continua con il resto delle operazioni del flusso di lavoro. |
|
|
Oltre agli approcci sopra descritti, la replica SnapMirror può essere creata anche tramite ONTAP CLI o System Manager. Indipendentemente dall'approccio utilizzato per sincronizzare i dati tramite SnapMirror, BlueXP DRaaS orchestra il flusso di lavoro per operazioni di disaster recovery efficienti e senza interruzioni. |
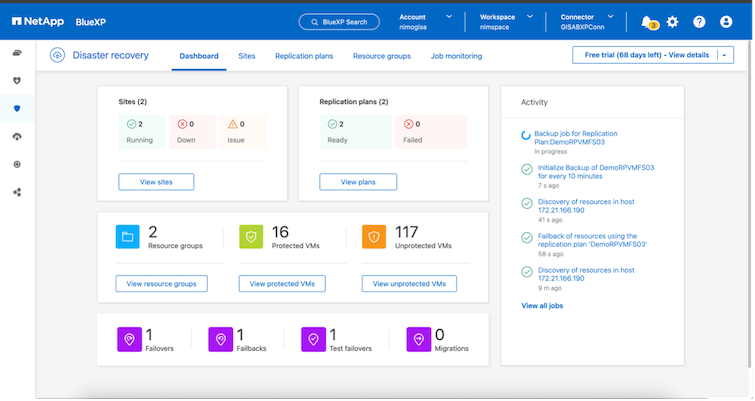
Cosa può fare per te il BlueXP disaster recovery ?
Dopo aver aggiunto i siti di origine e di destinazione, il BlueXP disaster recovery esegue automaticamente un'analisi approfondita e visualizza le VM insieme ai metadati associati. Il BlueXP disaster recovery rileva automaticamente anche le reti e i gruppi di porte utilizzati dalle VM e li popola.
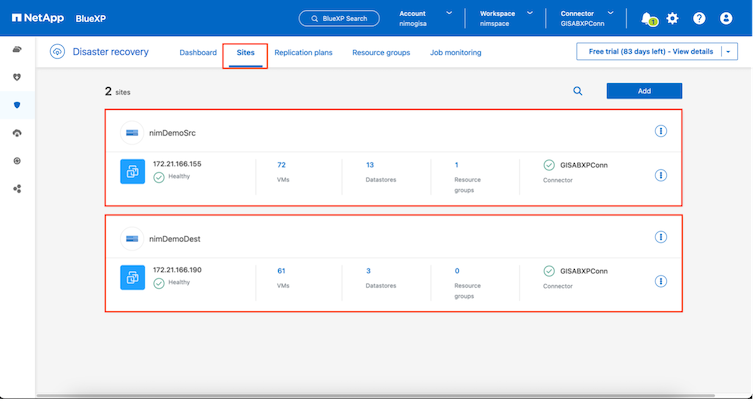
Dopo aver aggiunto i siti, le VM possono essere raggruppate in gruppi di risorse. I gruppi di risorse BlueXP disaster recovery consentono di raggruppare un set di VM dipendenti in gruppi logici che contengono i relativi ordini di avvio e ritardi di avvio che possono essere eseguiti al momento del ripristino. Per iniziare a creare gruppi di risorse, vai su Gruppi di risorse e fai clic su Crea nuovo gruppo di risorse.
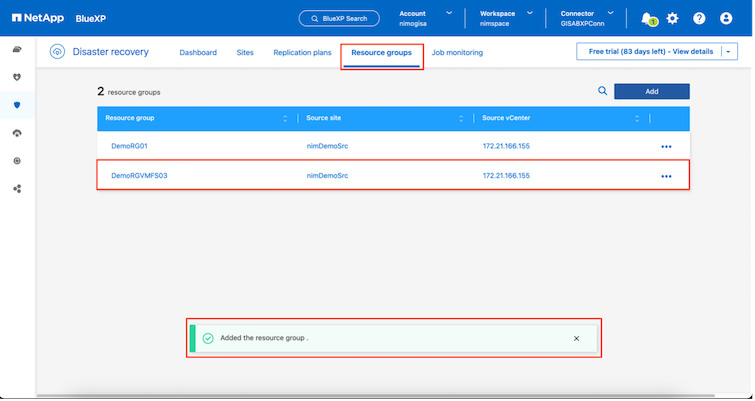
|
|
Il gruppo di risorse può essere creato anche durante la creazione di un piano di replica. |
L'ordine di avvio delle VM può essere definito o modificato durante la creazione dei gruppi di risorse utilizzando un semplice meccanismo di trascinamento della selezione.
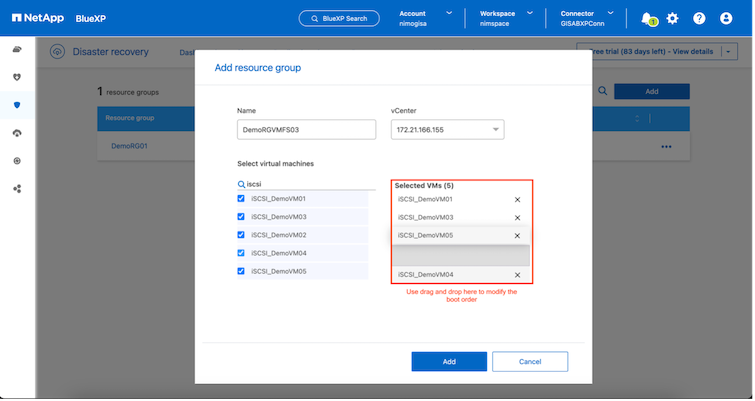
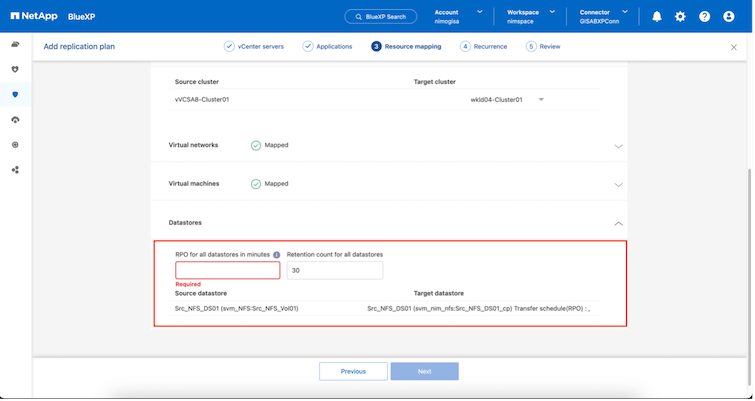
Una volta creati i gruppi di risorse, il passaggio successivo consiste nel creare il progetto di esecuzione o un piano per ripristinare macchine virtuali e applicazioni in caso di disastro. Come indicato nei prerequisiti, la replica SnapMirror può essere configurata in anticipo oppure DRaaS può configurarla utilizzando l'RPO e il conteggio di conservazione specificati durante la creazione del piano di replica.
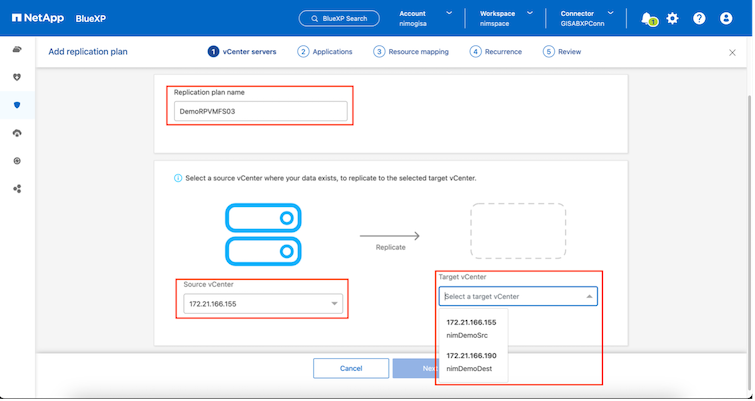
Configurare il piano di replica selezionando le piattaforme vCenter di origine e di destinazione dal menu a discesa e scegliere i gruppi di risorse da includere nel piano, insieme al raggruppamento delle modalità di ripristino e accensione delle applicazioni e alla mappatura di cluster e reti. Per definire il piano di ripristino, accedere alla scheda Piano di replica e fare clic su Aggiungi piano.
Per prima cosa, seleziona il vCenter di origine e poi quello di destinazione.
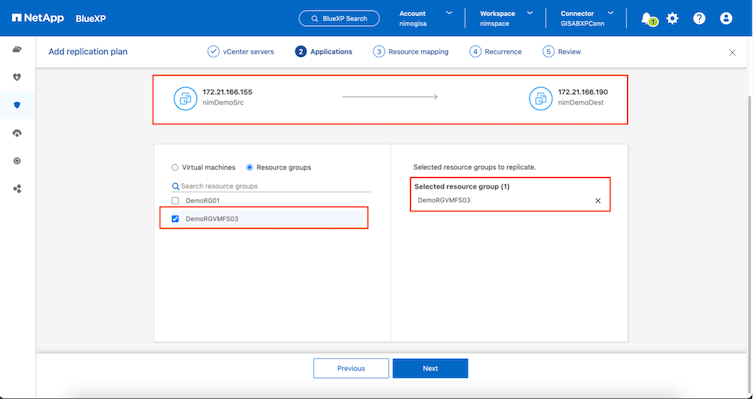
Il passo successivo è selezionare i gruppi di risorse esistenti. Se non è stato creato alcun gruppo di risorse, la procedura guidata aiuta a raggruppare le macchine virtuali richieste (in pratica a creare gruppi di risorse funzionali) in base agli obiettivi di ripristino. Ciò aiuta anche a definire la sequenza operativa di come devono essere ripristinate le macchine virtuali delle applicazioni.
|
|
Il gruppo di risorse consente di impostare l'ordine di avvio utilizzando la funzionalità di trascinamento della selezione. Può essere utilizzato per modificare facilmente l'ordine in cui le VM verranno accese durante il processo di ripristino. |
|
|
Ogni macchina virtuale all'interno di un gruppo di risorse viene avviata in sequenza in base all'ordine. Vengono avviati in parallelo due gruppi di risorse. |
La schermata seguente mostra l'opzione per filtrare macchine virtuali o datastore specifici in base ai requisiti organizzativi se i gruppi di risorse non sono stati creati in precedenza.
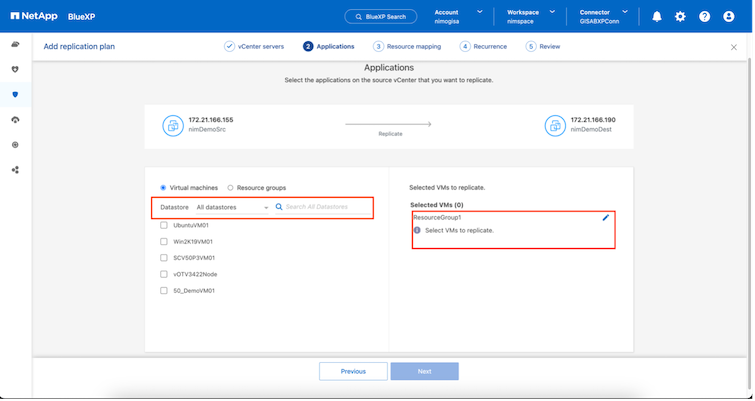
Una volta selezionati i gruppi di risorse, creare i mapping di failover. In questo passaggio, specificare come le risorse dall'ambiente di origine vengono mappate alla destinazione. Ciò include risorse di elaborazione e reti virtuali. Personalizzazione IP, pre- e post-script, ritardi di avvio, coerenza delle applicazioni e così via. Per informazioni dettagliate, fare riferimento a"Creare un piano di replicazione" .
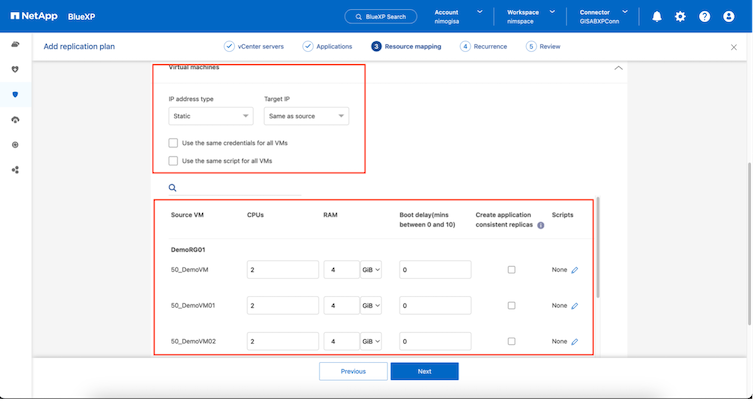
|
|
Per impostazione predefinita, vengono utilizzati gli stessi parametri di mappatura sia per le operazioni di test che per quelle di failover. Per applicare mappature diverse per l'ambiente di test, selezionare l'opzione Mappatura test dopo aver deselezionato la casella di controllo come mostrato di seguito: |
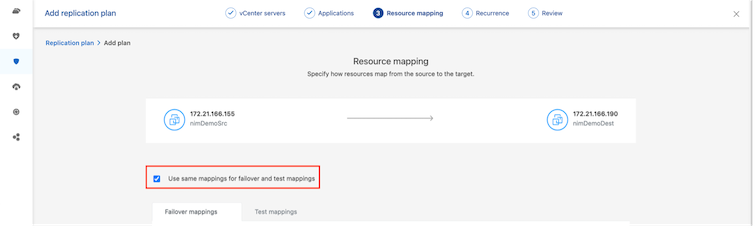
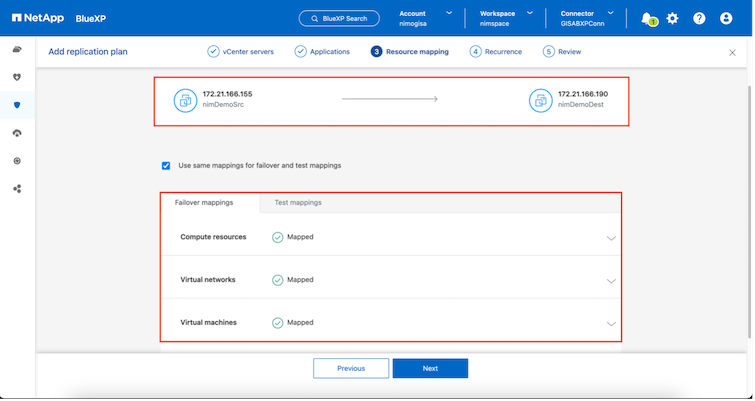
Una volta completata la mappatura delle risorse, fare clic su Avanti.
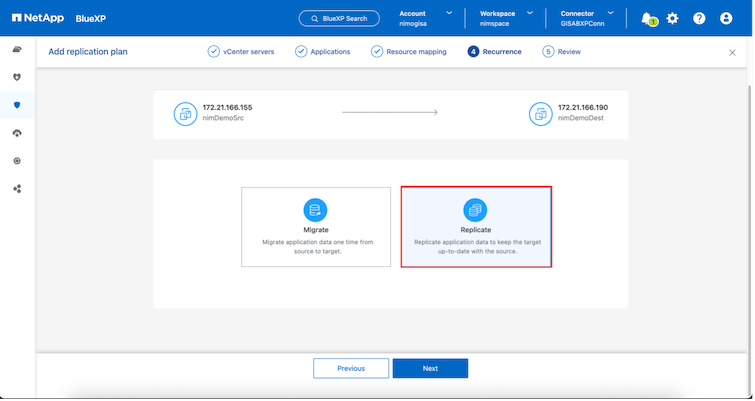
Selezionare il tipo di ricorrenza. In parole semplici, seleziona l'opzione Migra (migrazione una tantum tramite failover) o replica continua ricorrente. In questa procedura dettagliata è selezionata l'opzione Replica.
Una volta fatto, rivedi le mappature create e poi fai clic su Aggiungi piano.
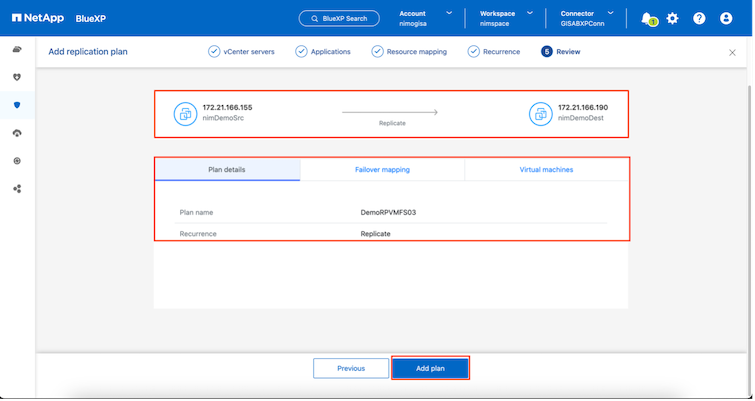
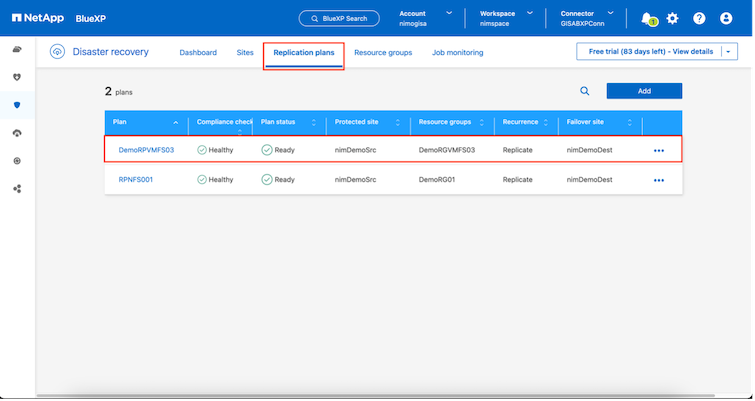
Una volta creato il piano di replicazione, è possibile eseguire il failover a seconda dei requisiti selezionando l'opzione failover, l'opzione test-failover o l'opzione migrate. Il BlueXP disaster recovery garantisce che il processo di replicazione venga eseguito secondo il piano ogni 30 minuti. Durante le opzioni di failover e test-failover, è possibile utilizzare la copia Snapshot SnapMirror più recente oppure selezionare una copia Snapshot specifica da una copia Snapshot di un determinato momento (in base ai criteri di conservazione di SnapMirror). L'opzione point-in-time può essere molto utile in caso di un evento di corruzione come un ransomware, in cui le repliche più recenti sono già compromesse o crittografate. Il BlueXP disaster recovery mostra tutti i punti di ripristino disponibili.
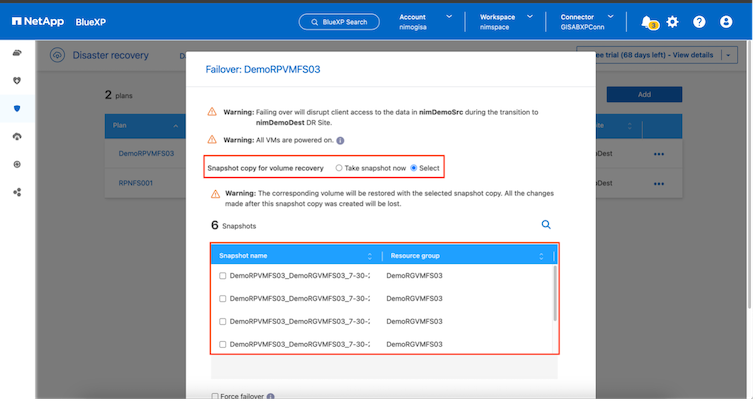
Per attivare il failover o il failover di prova con la configurazione specificata nel piano di replica, fare clic su Failover o Failover di prova.
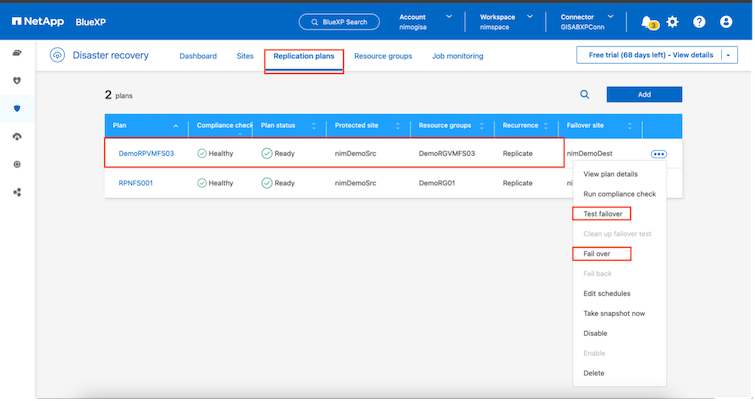
Cosa succede durante un'operazione di failover o di test failover?
Durante un'operazione di failover di prova, il BlueXP disaster recovery crea un volume FlexClone sul sistema di archiviazione ONTAP di destinazione utilizzando la copia Snapshot più recente o uno snapshot selezionato del volume di destinazione.
|
|
Un'operazione di failover di prova crea un volume clonato sul sistema di archiviazione ONTAP di destinazione. |
|
|
L'esecuzione di un'operazione di ripristino di prova non influisce sulla replica SnapMirror . |
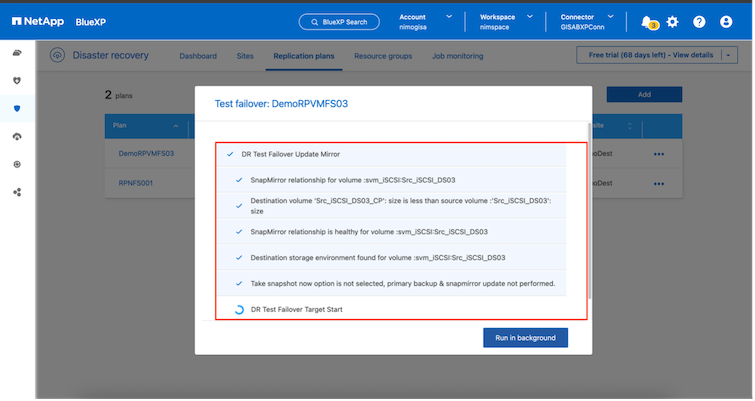
Durante il processo, il BlueXP disaster recovery non mappa il volume di destinazione originale. Al contrario, crea un nuovo volume FlexClone dallo Snapshot selezionato e un datastore temporaneo che supporta il volume FlexClone viene mappato sugli host ESXi.
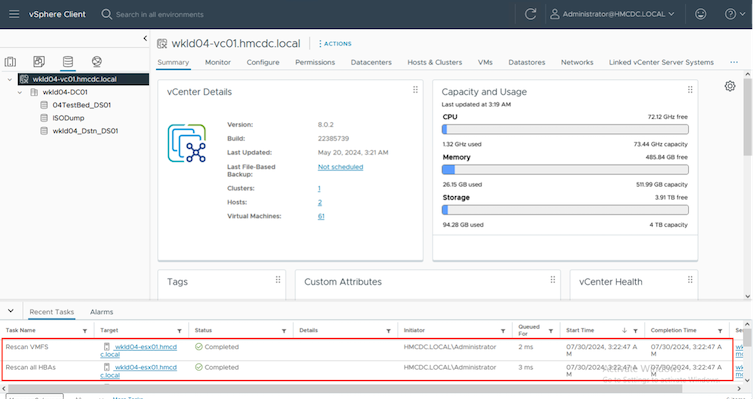
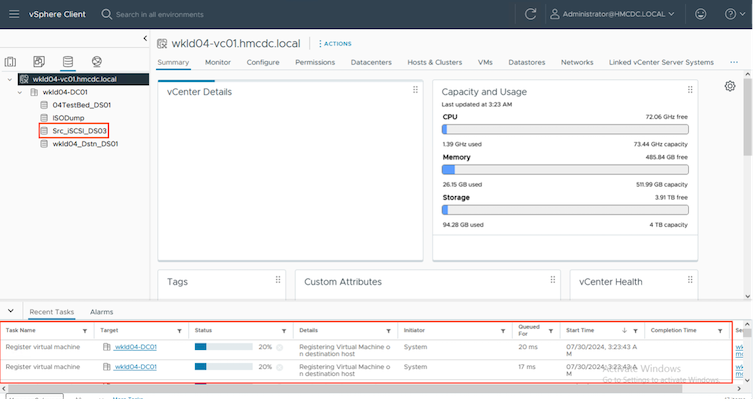
Una volta completata l'operazione di failover di prova, è possibile avviare l'operazione di pulizia utilizzando "Clean Up failover test". Durante questa operazione, il BlueXP disaster recovery distrugge il volume FlexClone utilizzato nell'operazione.
In caso di un vero disastro, il BlueXP disaster recovery esegue i seguenti passaggi:
-
Interrompe la relazione SnapMirror tra i siti.
-
Monta il volume del datastore VMFS dopo la nuova firma per un utilizzo immediato.
-
Registrare le VM
-
Accendere le VM
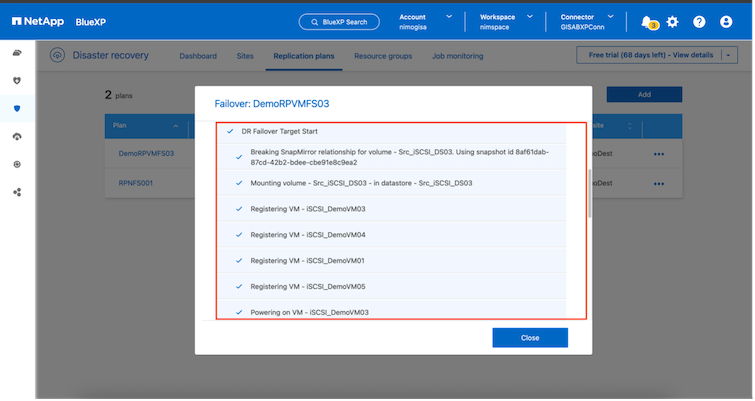
Una volta che il sito primario è attivo e funzionante, il BlueXP disaster recovery consente la risincronizzazione inversa per SnapMirror e abilita il failback, che può essere eseguito con un semplice clic.
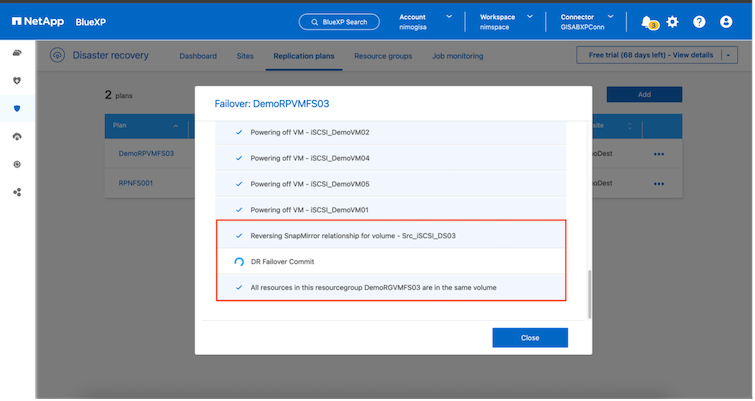
Se si sceglie l'opzione di migrazione, questa viene considerata un evento di failover pianificato. In questo caso, viene attivato un ulteriore passaggio che consiste nello spegnimento delle macchine virtuali nel sito di origine. Il resto dei passaggi rimane lo stesso dell'evento di failover.
Da BlueXP o dalla CLI ONTAP è possibile monitorare lo stato di integrità della replica per i volumi del datastore appropriati, mentre lo stato di un failover o di un failover di prova può essere monitorato tramite Job Monitoring.
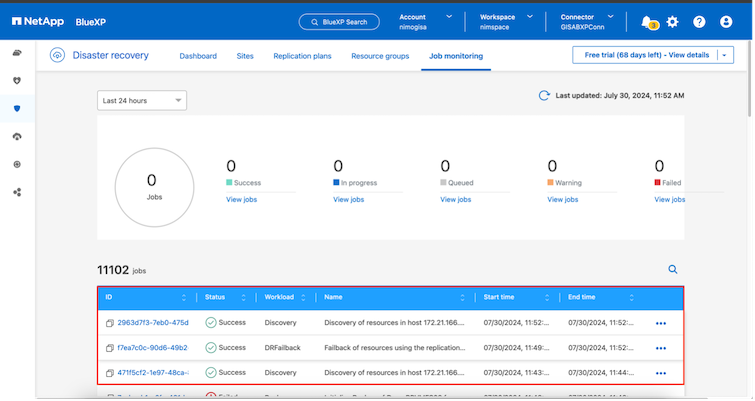
Si tratta di una soluzione potente per gestire un piano di disaster recovery personalizzato e su misura. Il failover può essere eseguito come failover pianificato oppure con un clic su un pulsante quando si verifica un disastro e si decide di attivare il sito DR.
Per saperne di più su questo processo, sentiti libero di seguire il video dettagliato o di utilizzare il"simulatore di soluzioni" .