

Gestione del database Oracle EC2 e FSx
 Suggerisci modifiche
Suggerisci modifiche
Oltre alla console di gestione AWS EC2 e FSx, in questo ambiente Oracle vengono implementati il nodo di controllo Ansible e lo strumento SnapCenter UI per la gestione del database.
Un nodo di controllo Ansible può essere utilizzato per gestire la configurazione dell'ambiente Oracle, con aggiornamenti paralleli che mantengono sincronizzate le istanze primarie e di standby per gli aggiornamenti del kernel o delle patch. Il failover, la risincronizzazione e il failback possono essere automatizzati con NetApp Automation Toolkit per archiviare rapidamente il ripristino e la disponibilità delle applicazioni con Ansible. Alcune attività ripetibili di gestione del database possono essere eseguite utilizzando un playbook per ridurre gli errori umani.
Lo strumento SnapCenter UI può eseguire il backup degli snapshot del database, il ripristino point-in-time, la clonazione del database e così via con il plug-in SnapCenter per i database Oracle. Per ulteriori informazioni sulle funzionalità del plugin Oracle, vedere"Panoramica del plug-in SnapCenter per Oracle Database" .
Le sezioni seguenti forniscono dettagli su come le funzioni chiave della gestione del database Oracle vengono eseguite con l'interfaccia utente SnapCenter :
-
Backup degli snapshot del database
-
Ripristino del database in un punto temporale specifico
-
Creazione di cloni di database
La clonazione del database crea una replica di un database primario su un host EC2 separato per il ripristino dei dati in caso di errore logico o danneggiamento dei dati; i cloni possono essere utilizzati anche per il test delle applicazioni, il debug, la convalida delle patch e così via.
Scattare un'istantanea
Un database Oracle EC2/FSx viene sottoposto a backup periodico a intervalli configurati dall'utente. Un utente può anche effettuare un backup snapshot una tantum in qualsiasi momento. Ciò si applica sia ai backup di snapshot completi del database sia ai backup di snapshot solo del registro di archivio.
Esecuzione di uno snapshot completo del database
Uno snapshot completo del database include tutti i file Oracle, inclusi i file di dati, i file di controllo e i file di registro di archivio.
-
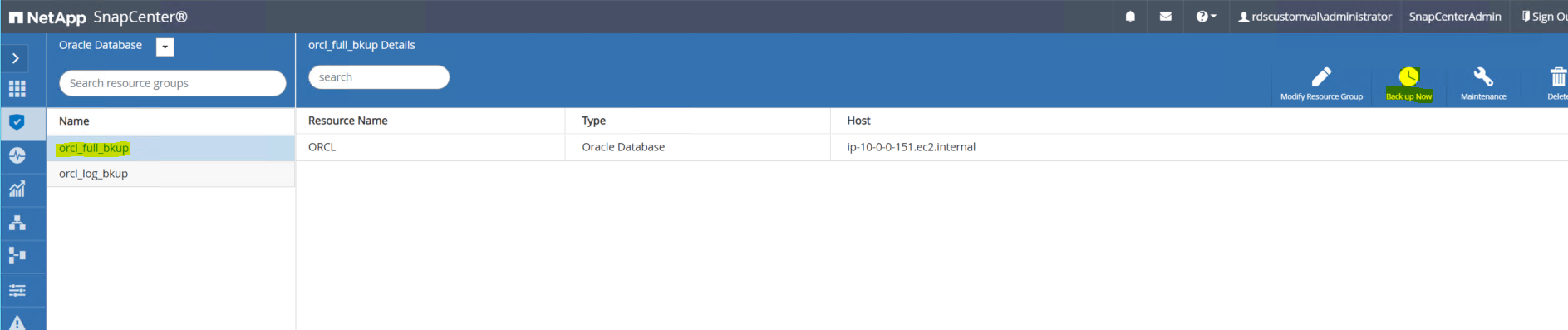
Accedi all'interfaccia utente SnapCenter e fai clic su Risorse nel menu a sinistra. Dal menu a discesa Visualizza, passare alla visualizzazione Gruppo di risorse.
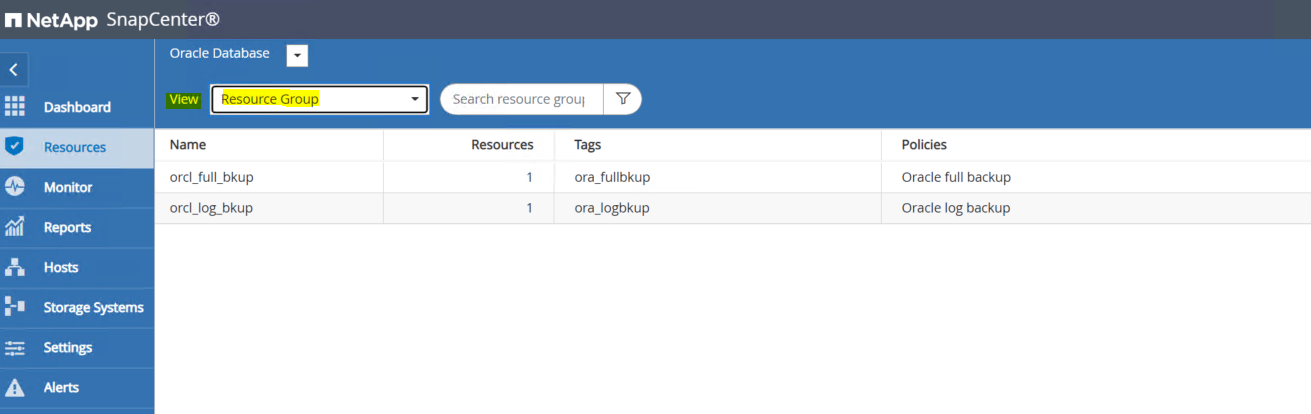
-
Fare clic sul nome completo della risorsa di backup, quindi fare clic sull'icona Esegui backup ora per avviare un backup aggiuntivo.
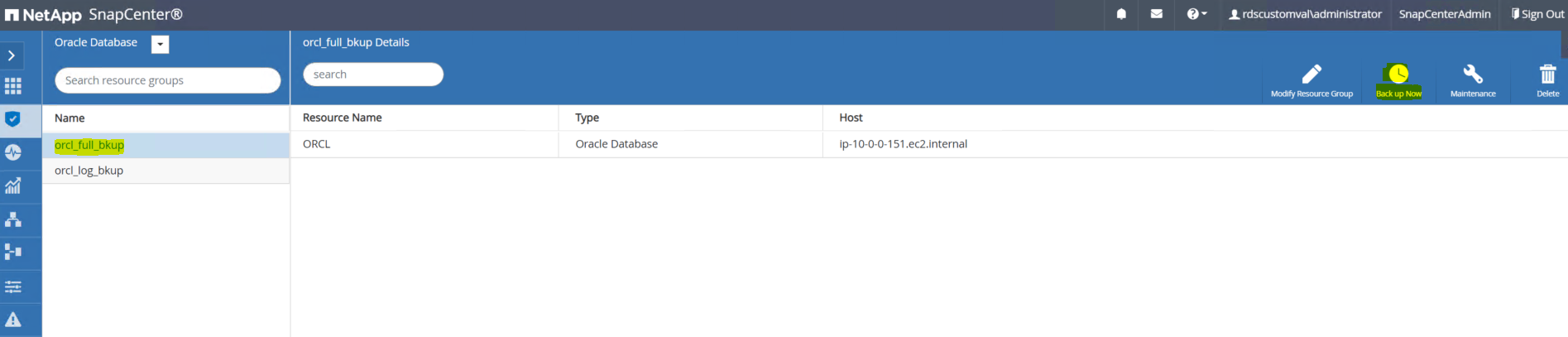
-
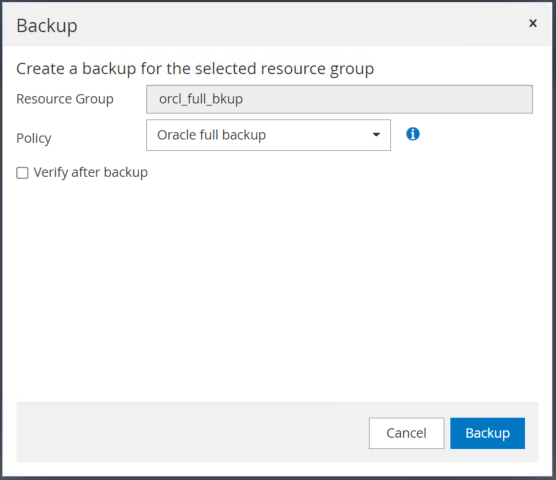
Fare clic su Backup e quindi confermare il backup per avviare un backup completo del database.
Dalla vista Risorse del database, aprire la pagina Copie di backup gestite del database per verificare che il backup una tantum sia stato completato correttamente. Un backup completo del database crea due snapshot: uno per il volume dati e uno per il volume log.
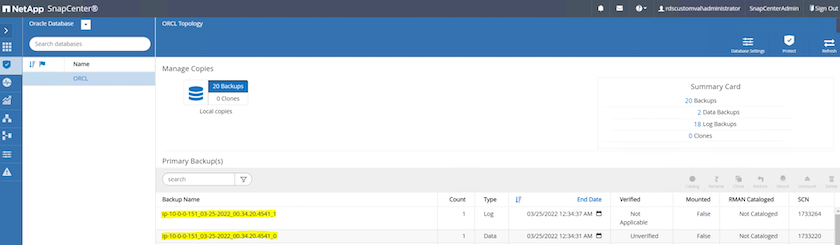
Acquisizione di uno snapshot del registro di archivio
Uno snapshot del log di archivio viene eseguito solo per il volume del log di archivio Oracle.
-
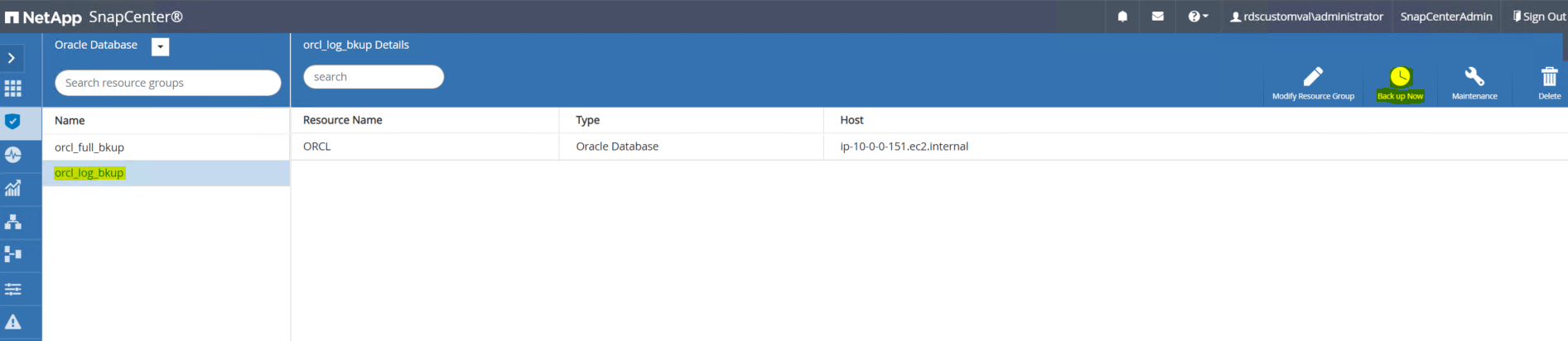
Accedi all'interfaccia utente SnapCenter e fai clic sulla scheda Risorse nella barra dei menu a sinistra. Dal menu a discesa Visualizza, passare alla visualizzazione Gruppo di risorse.
-
Fare clic sul nome della risorsa di backup del registro, quindi fare clic sull'icona Esegui backup ora per avviare un backup aggiuntivo per i registri di archivio.
-
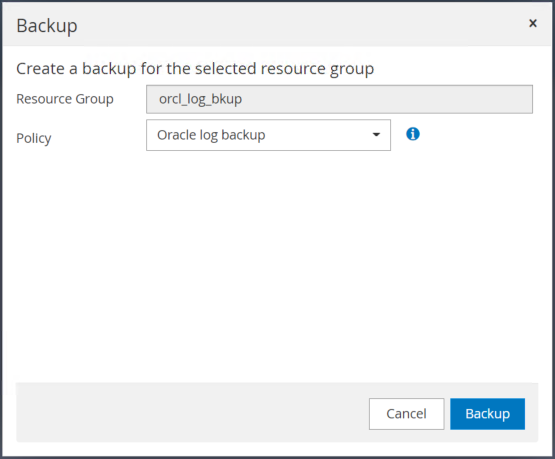
Fare clic su Backup e quindi confermare il backup per avviare un backup del registro di archivio.
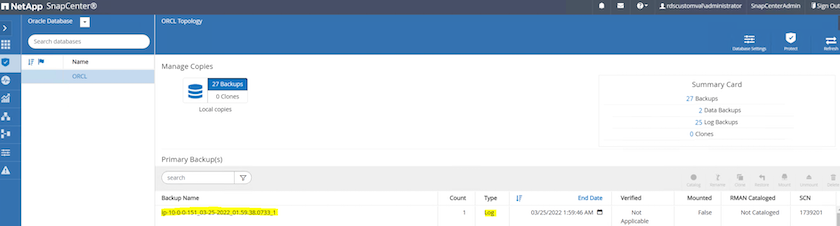
Dalla vista Risorse per il database, aprire la pagina Copie di backup gestite del database per verificare che il backup del registro di archivio una tantum sia stato completato correttamente. Un backup del registro di archivio crea uno snapshot per il volume del registro.
Ripristino a un punto nel tempo
Il ripristino basato su SnapCenter in un punto nel tempo viene eseguito sullo stesso host dell'istanza EC2. Per eseguire il ripristino, completare i seguenti passaggi:
-
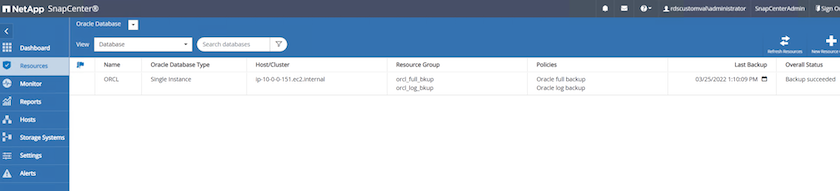
Dalla scheda Risorse SnapCenter > Visualizzazione database, fare clic sul nome del database per aprire il backup del database.
-
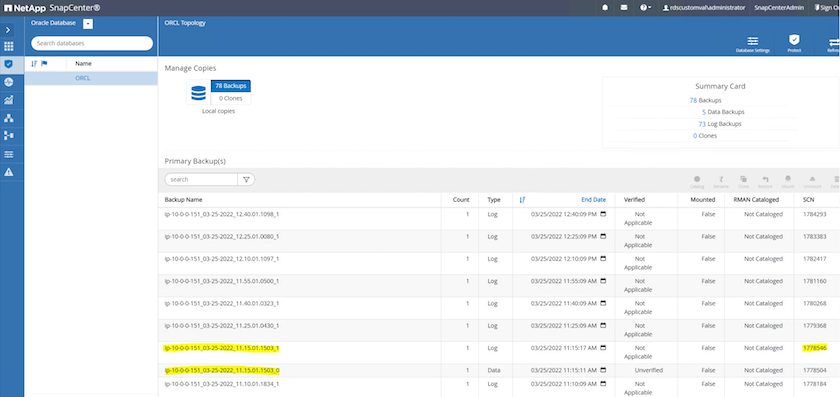
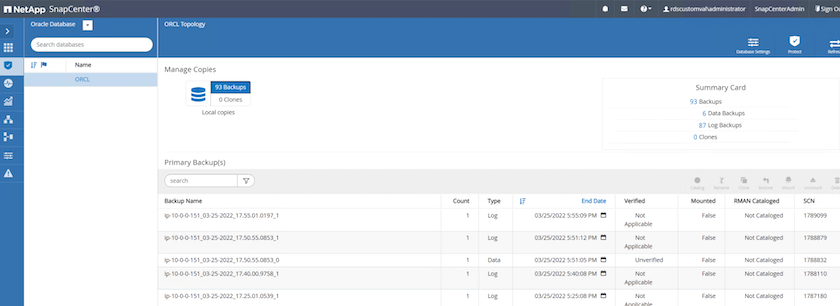
Selezionare la copia di backup del database e il momento desiderato da ripristinare. Annotare anche il numero SCN corrispondente al momento. Il ripristino point-in-time può essere eseguito utilizzando l'ora o l'SCN.
-
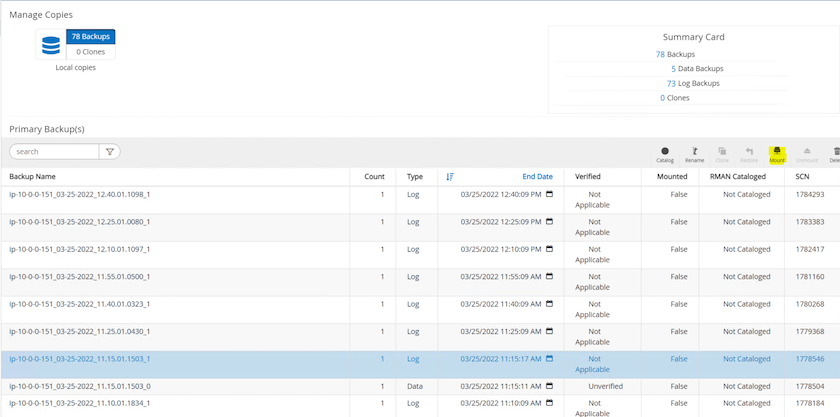
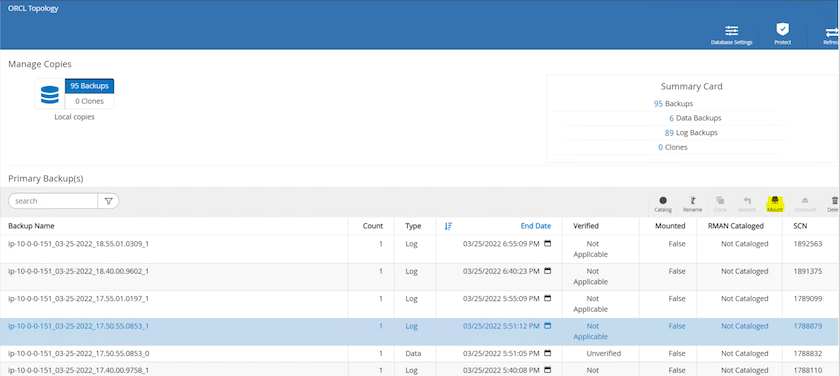
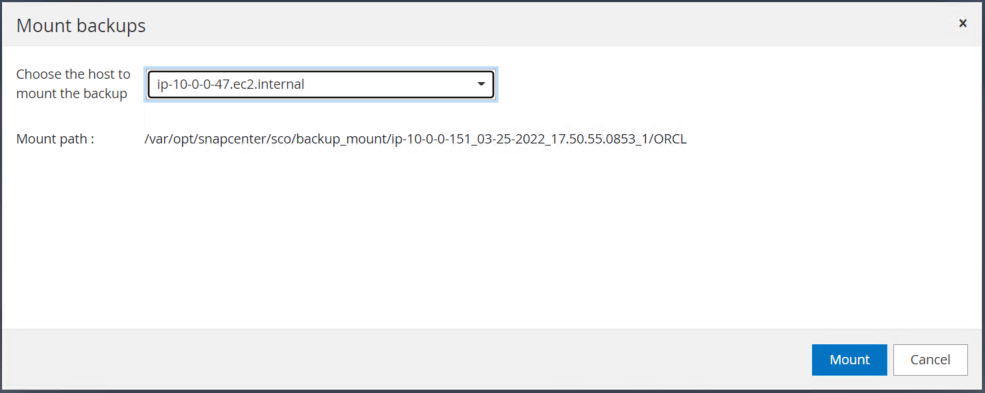
Evidenziare lo snapshot del volume di registro e fare clic sul pulsante Monta per montare il volume.
-
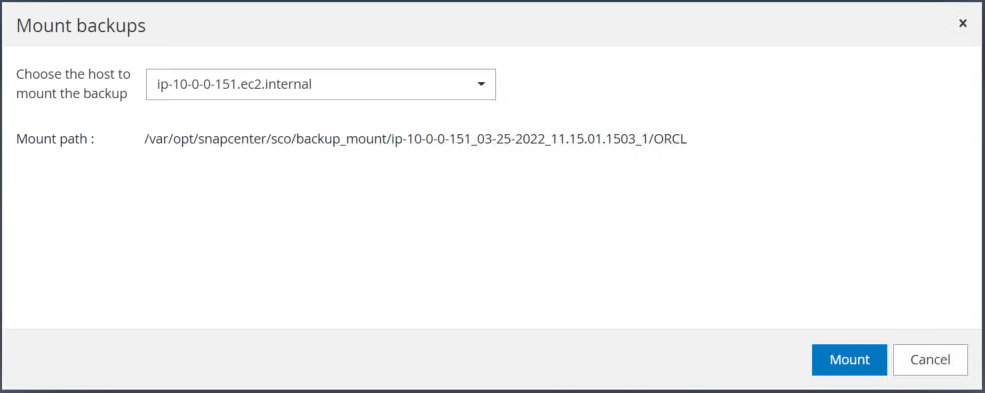
Selezionare l'istanza EC2 primaria per montare il volume di registro.
-
Verificare che il processo di montaggio venga completato correttamente. Controllare anche l'host dell'istanza EC2 per vedere il volume di registro montato e anche il percorso del punto di montaggio.


-
Copiare i log di archivio dal volume di log montato alla directory corrente dei log di archivio.
[ec2-user@ip-10-0-0-151 ~]$ cp /var/opt/snapcenter/sco/backup_mount/ip-10-0-0-151_03-25-2022_11.15.01.1503_1/ORCL/1/db/ORCL_A/arch/*.arc /ora_nfs_log/db/ORCL_A/arch/
-
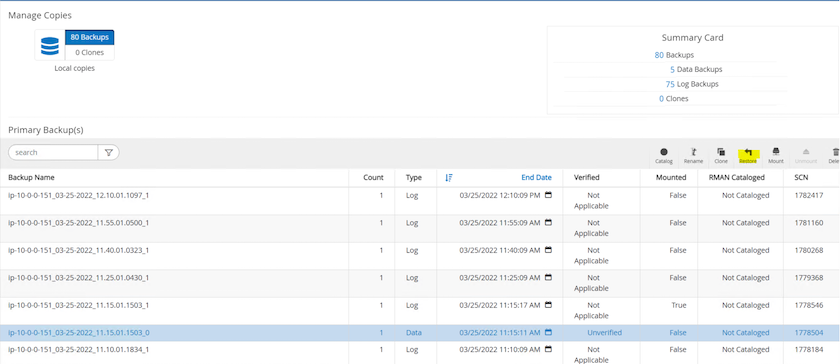
Tornare alla scheda Risorsa di SnapCenter > pagina di backup del database, evidenziare la copia dello snapshot dei dati e fare clic sul pulsante Ripristina per avviare il flusso di lavoro di ripristino del database.
-
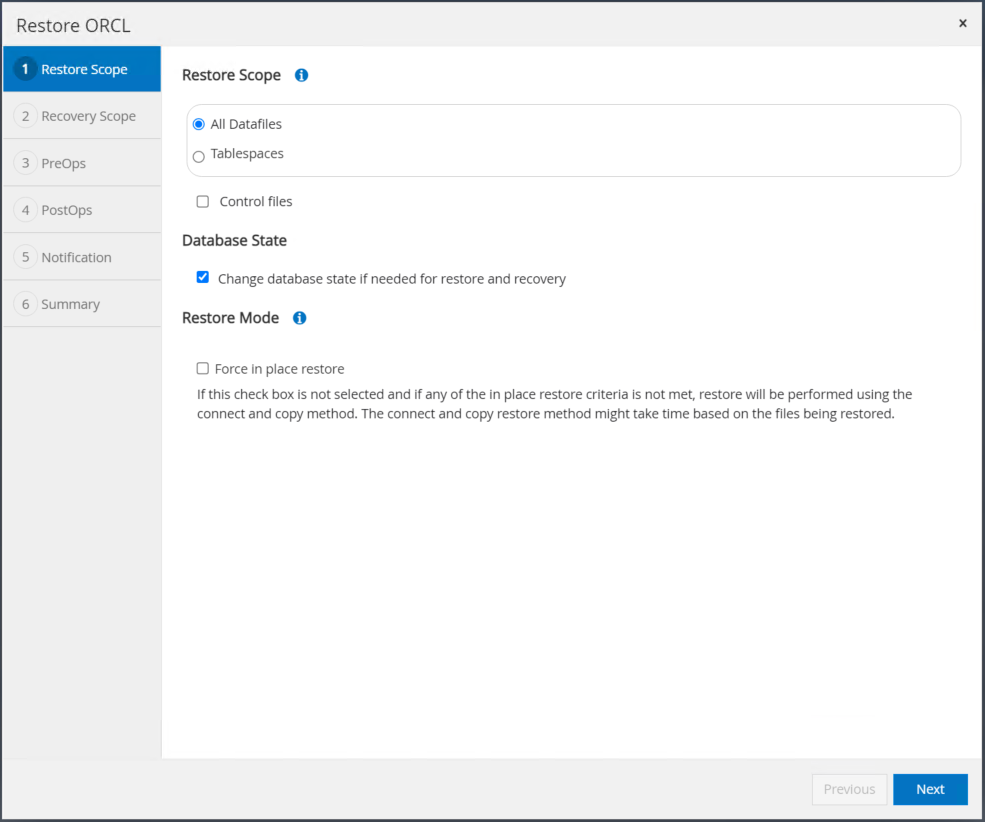
Selezionare "Tutti i file di dati" e "Modifica lo stato del database se necessario per il ripristino e il recupero", quindi fare clic su Avanti.
-
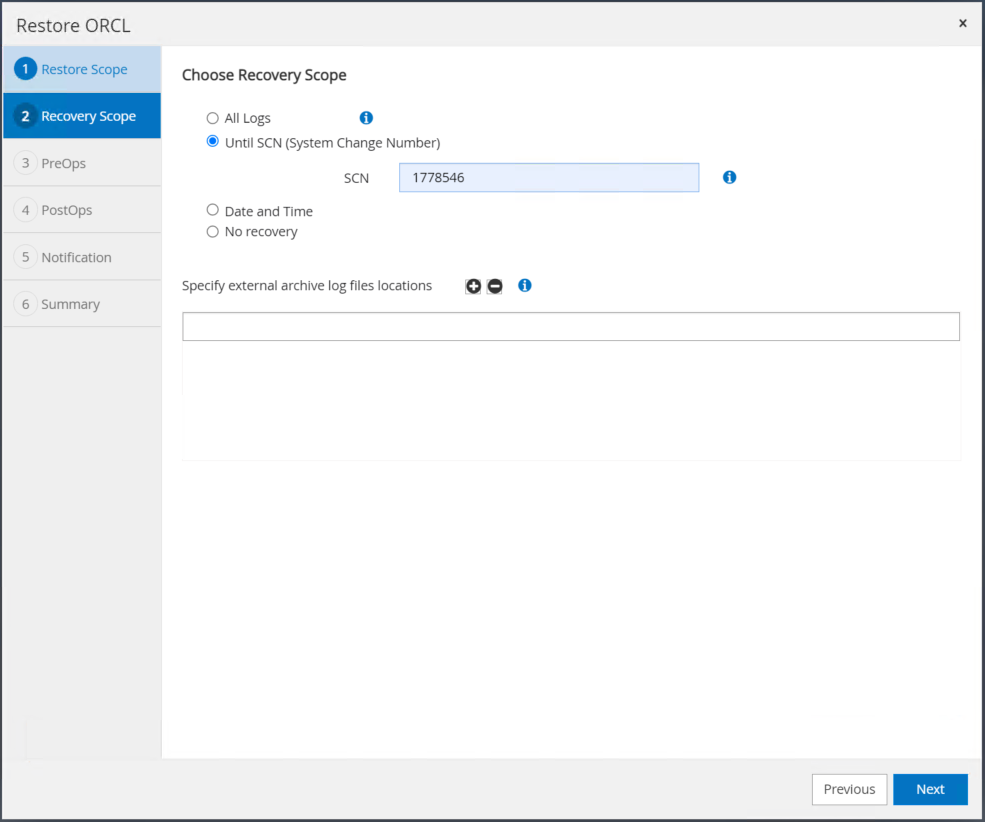
Selezionare l'ambito di ripristino desiderato utilizzando SCN o tempo. Anziché copiare i log di archivio montati nella directory dei log corrente come illustrato nel passaggio 6, è possibile elencare il percorso del log di archivio montato in "Specificare i percorsi dei file di log di archivio esterni" per il ripristino.
-
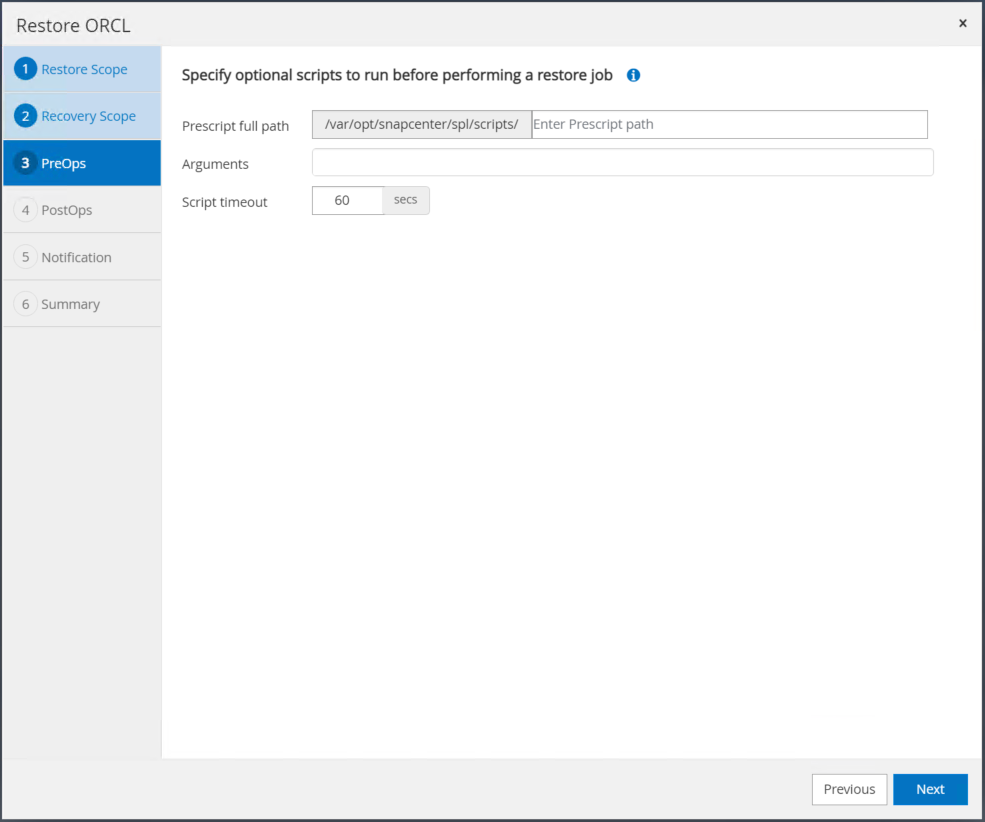
Specificare un prescript facoltativo da eseguire se necessario.
-
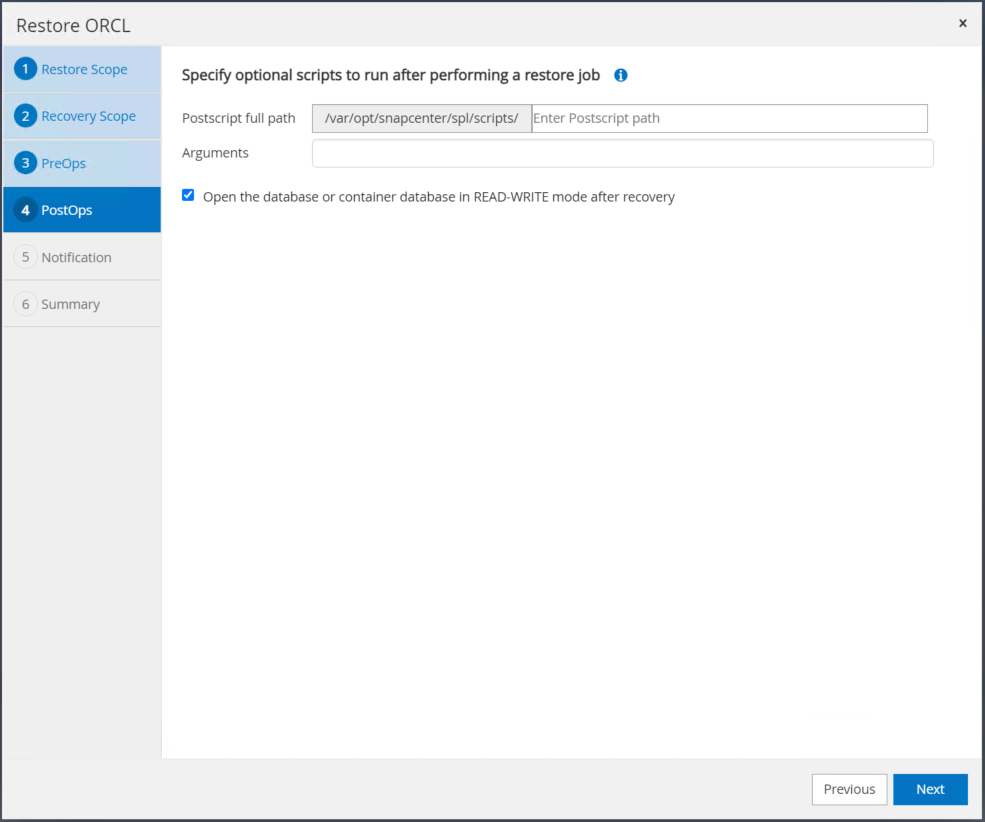
Specificare un afterscript facoltativo da eseguire se necessario. Dopo il ripristino, controllare il database aperto.
-
Fornire un server SMTP e un indirizzo e-mail se è necessaria una notifica di lavoro.
-
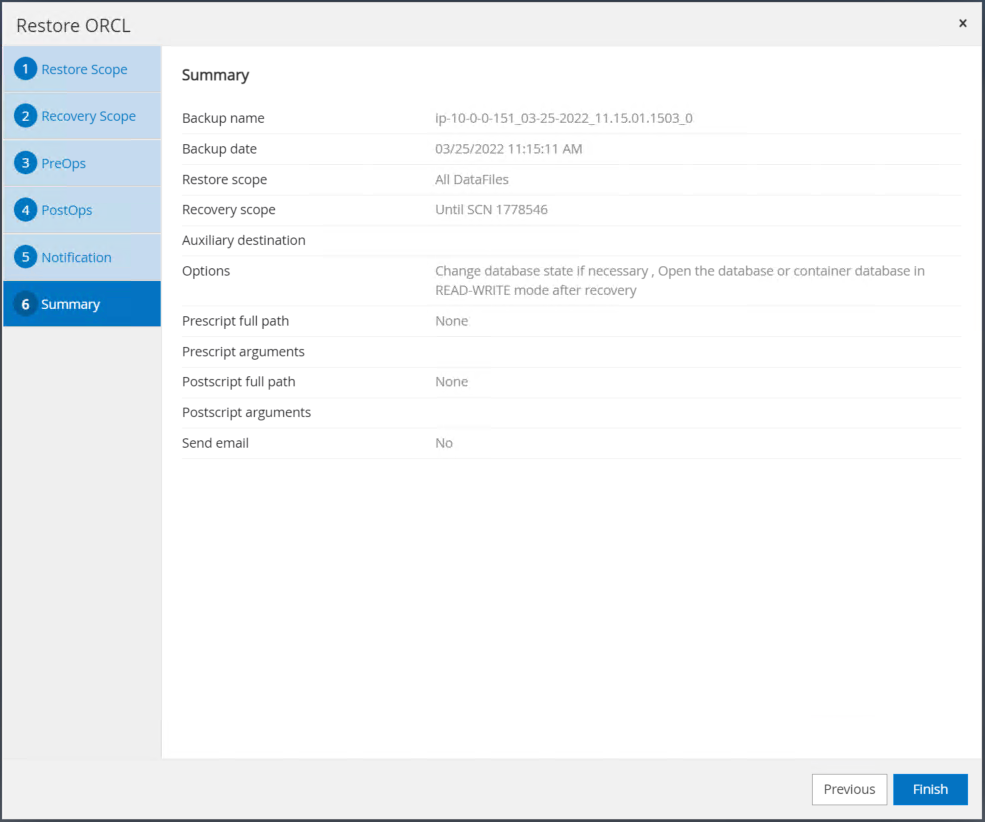
Ripristina il riepilogo del lavoro. Fare clic su Fine per avviare il processo di ripristino.
-
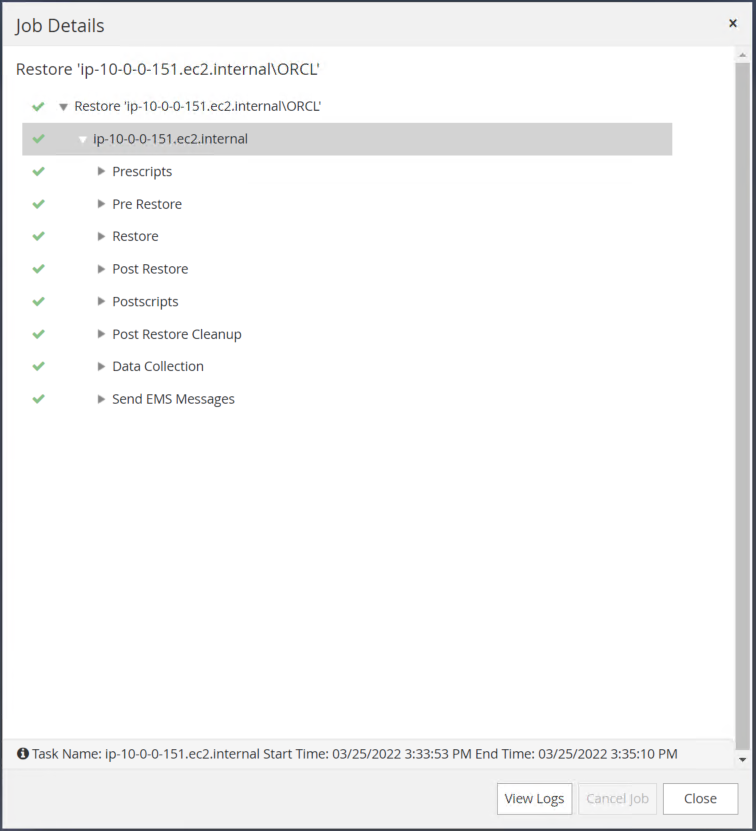
Convalida il ripristino da SnapCenter.
-
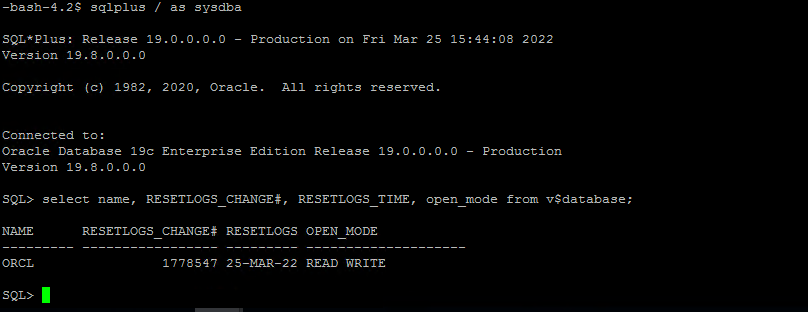
Convalida il ripristino dall'host dell'istanza EC2.
-
Per smontare il volume del registro di ripristino, ripetere i passaggi del passaggio 4 in ordine inverso.
Creazione di un clone del database
Nella sezione seguente viene illustrato come utilizzare il flusso di lavoro di clonazione SnapCenter per creare un clone di database da un database primario a un'istanza EC2 di standby.
-
Eseguire un backup snapshot completo del database primario da SnapCenter utilizzando il gruppo di risorse di backup completo.
-
Dalla scheda Risorsa SnapCenter > visualizzazione Database, aprire la pagina Gestione backup database per il database primario da cui creare la replica.
-
Montare lo snapshot del volume di registro acquisito nel passaggio 4 sull'host dell'istanza EC2 in standby.
-
Evidenziare la copia snapshot da clonare per la replica e fare clic sul pulsante Clona per avviare la procedura di clonazione.
-
Modificare il nome della copia replica in modo che sia diverso dal nome del database primario. Fare clic su Avanti.
-
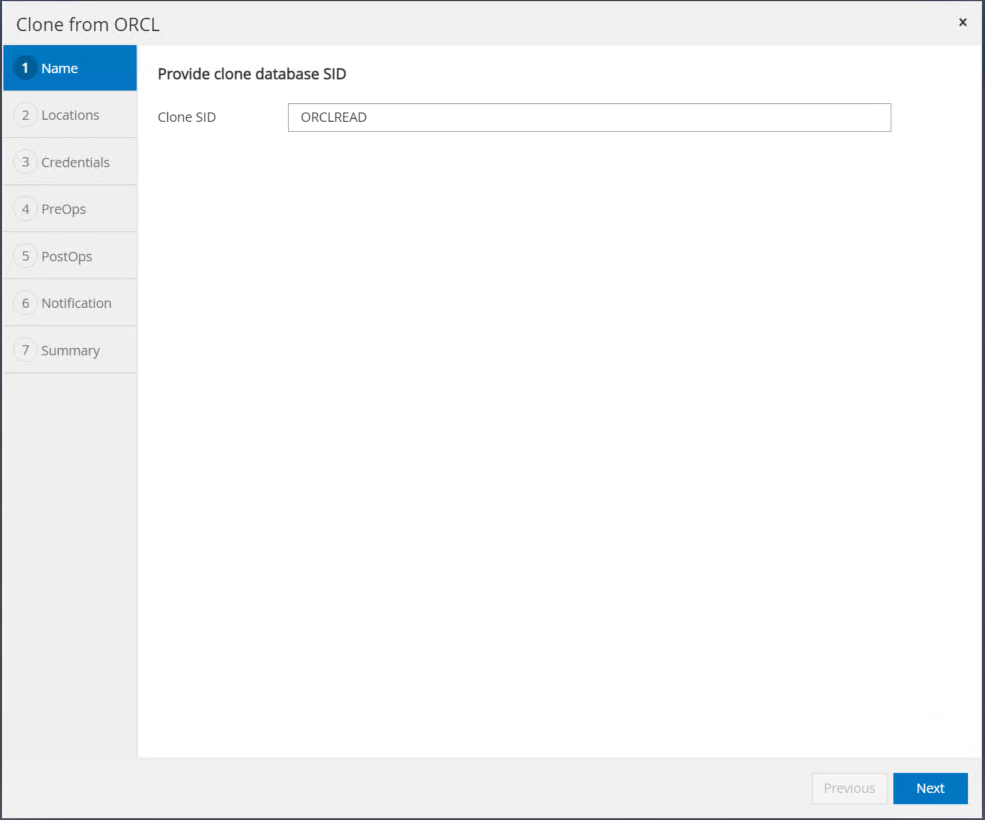
Cambiare l'host clone nell'host EC2 di standby, accettare la denominazione predefinita e fare clic su Avanti.
-
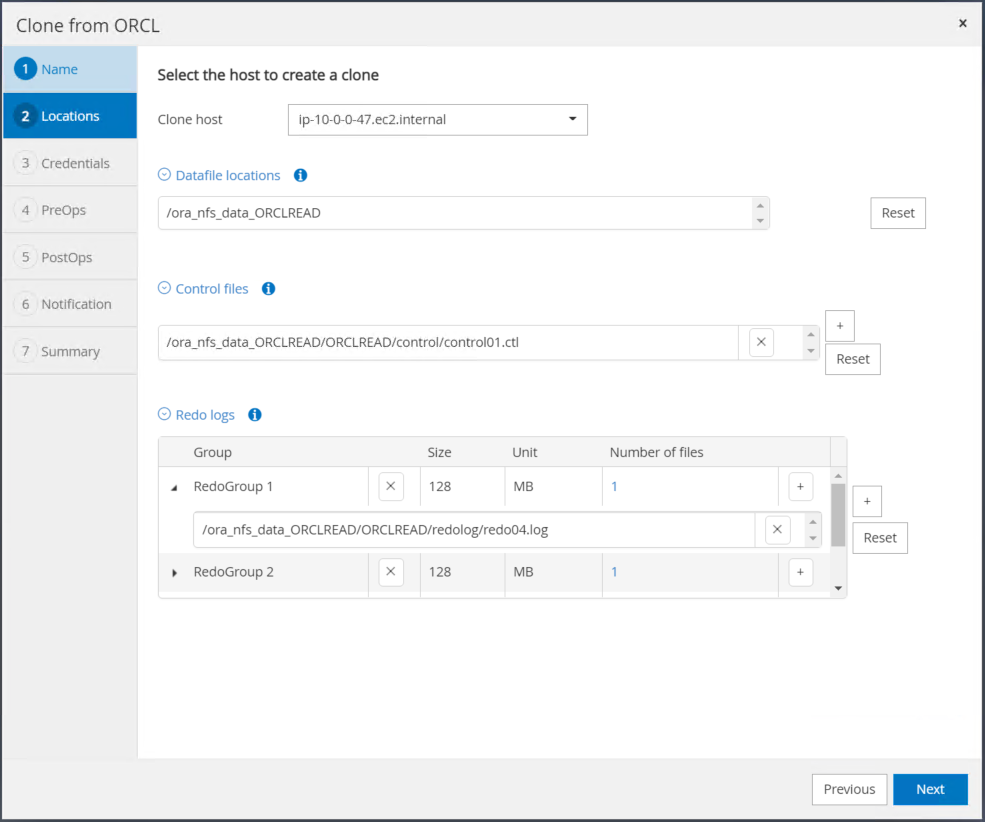
Modificare le impostazioni della home page di Oracle in modo che corrispondano a quelle configurate per l'host del server Oracle di destinazione e fare clic su Avanti.
-
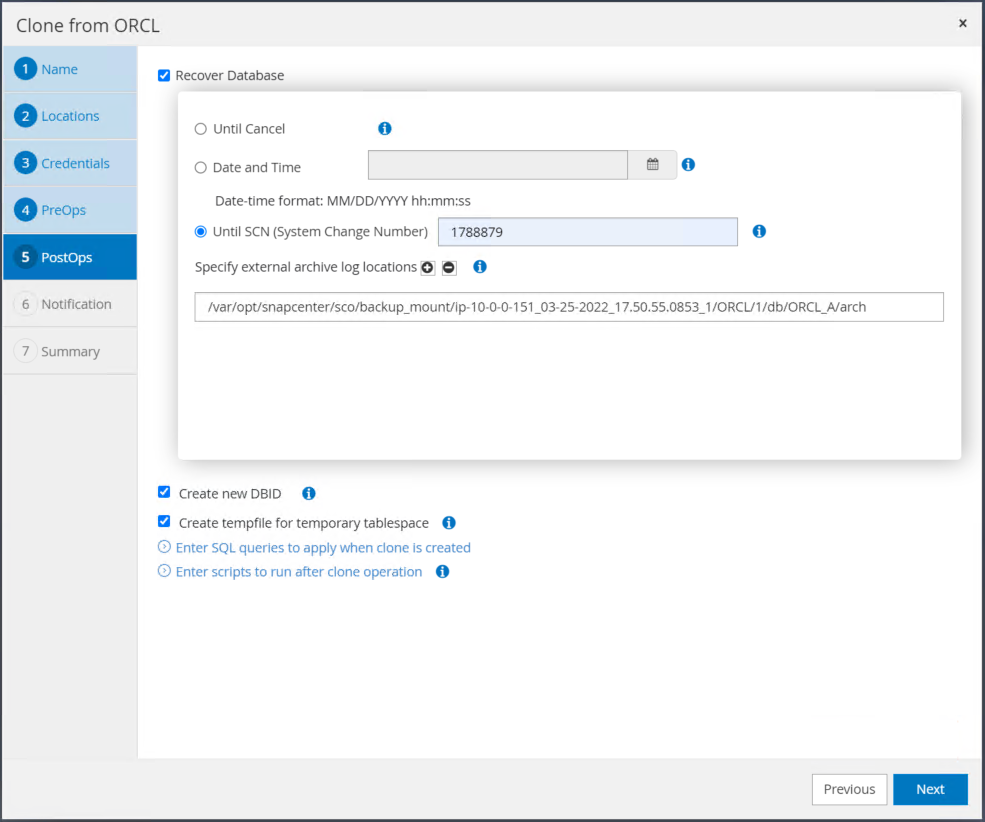
Specificare un punto di ripristino utilizzando l'ora o l'SCN e il percorso del registro di archivio montato.
-
Se necessario, inviare le impostazioni e-mail SMTP.
-
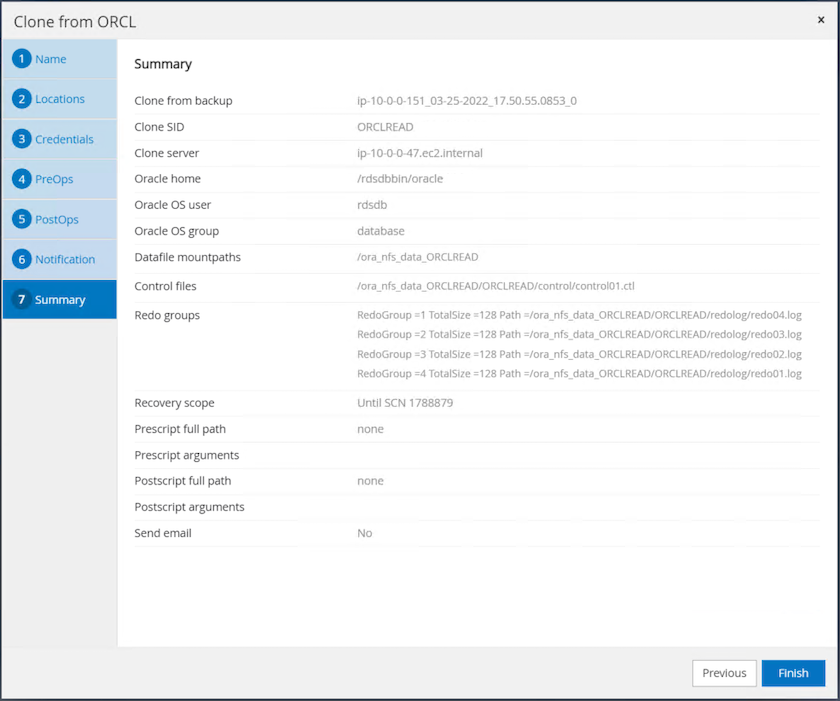
Clonare il riepilogo del lavoro e fare clic su Fine per avviare il lavoro di clonazione.
-
Convalidare il clone della replica esaminando il registro del processo di clonazione.
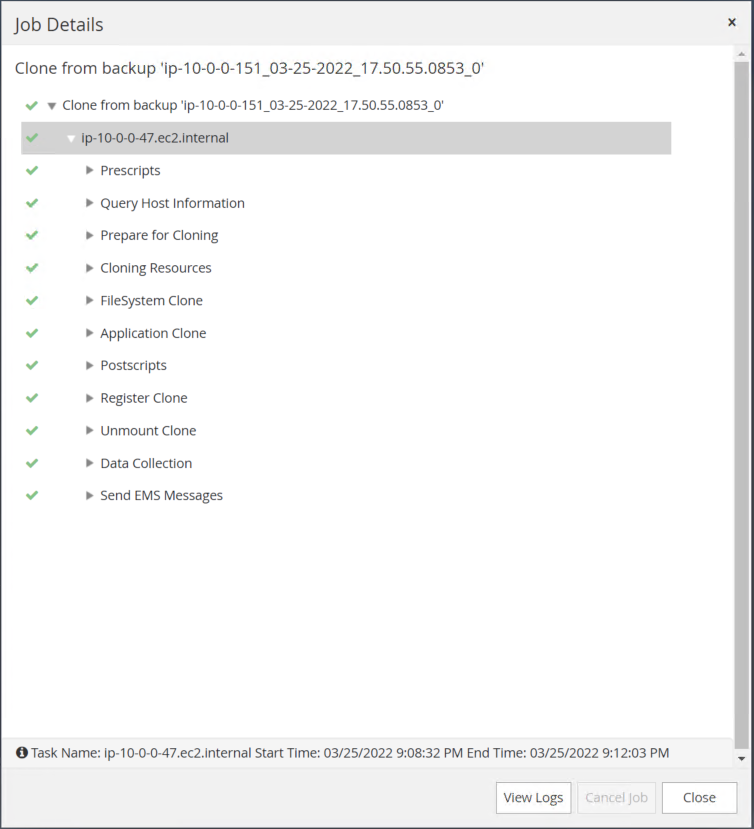
Il database clonato viene registrato immediatamente in SnapCenter .
-
Disattivare la modalità di registro di archivio di Oracle. Accedi all'istanza EC2 come utente Oracle ed esegui il seguente comando:
sqlplus / as sysdbashutdown immediate;startup mount;alter database noarchivelog;alter database open;

|
Invece di copie di backup primarie di Oracle, è anche possibile creare un clone da copie di backup secondarie replicate sul cluster FSx di destinazione con le stesse procedure. |
Failover HA in standby e risincronizzazione
Il cluster Oracle HA di standby garantisce elevata disponibilità in caso di guasto nel sito primario, sia nel livello di elaborazione che in quello di archiviazione. Uno dei vantaggi più significativi della soluzione è che l'utente può testare e convalidare l'infrastruttura in qualsiasi momento e con qualsiasi frequenza. Il failover può essere simulato dall'utente o attivato da un guasto reale. I processi di failover sono identici e possono essere automatizzati per un rapido ripristino delle applicazioni.
Consultare il seguente elenco di procedure di failover:
-
Per un failover simulato, eseguire un backup snapshot del log per scaricare le transazioni più recenti sul sito di standby, come dimostrato nella sezioneAcquisizione di uno snapshot del registro di archivio . In caso di failover attivato da un errore effettivo, gli ultimi dati recuperabili vengono replicati sul sito di standby con l'ultimo backup del volume di registro pianificato e completato correttamente.
-
Interrompere lo SnapMirror tra il cluster FSx primario e quello di standby.
-
Montare i volumi del database standby replicati sull'host dell'istanza EC2 standby.
-
Ricollegare il binario Oracle se il binario Oracle replicato viene utilizzato per il ripristino di Oracle.
-
Ripristina il database Oracle di standby all'ultimo registro di archivio disponibile.
-
Aprire il database Oracle di standby per l'accesso dell'applicazione e dell'utente.
-
In caso di guasto effettivo del sito primario, il database Oracle di standby assume ora il ruolo del nuovo sito primario e i volumi del database possono essere utilizzati per ricostruire il sito primario guasto come nuovo sito di standby con il metodo SnapMirror inverso.
-
In caso di errore simulato del sito primario per test o convalida, arrestare il database Oracle di standby dopo il completamento degli esercizi di test. Quindi smontare i volumi del database di standby dall'host dell'istanza EC2 di standby e risincronizzare la replica dal sito primario al sito di standby.
Queste procedure possono essere eseguite con il NetApp Automation Toolkit, disponibile per il download sul sito pubblico NetApp GitHub.
git clone https://github.com/NetApp-Automation/na_ora_hadr_failover_resync.gitLeggere attentamente le istruzioni README prima di tentare la configurazione e il test di failover.