Configurazione della sincronizzazione attiva di SnapMirror
 Suggerisci modifiche
Suggerisci modifiche
In questo articolo vengono descritte le fasi di configurazione necessarie per questa soluzione.
Prerequisiti
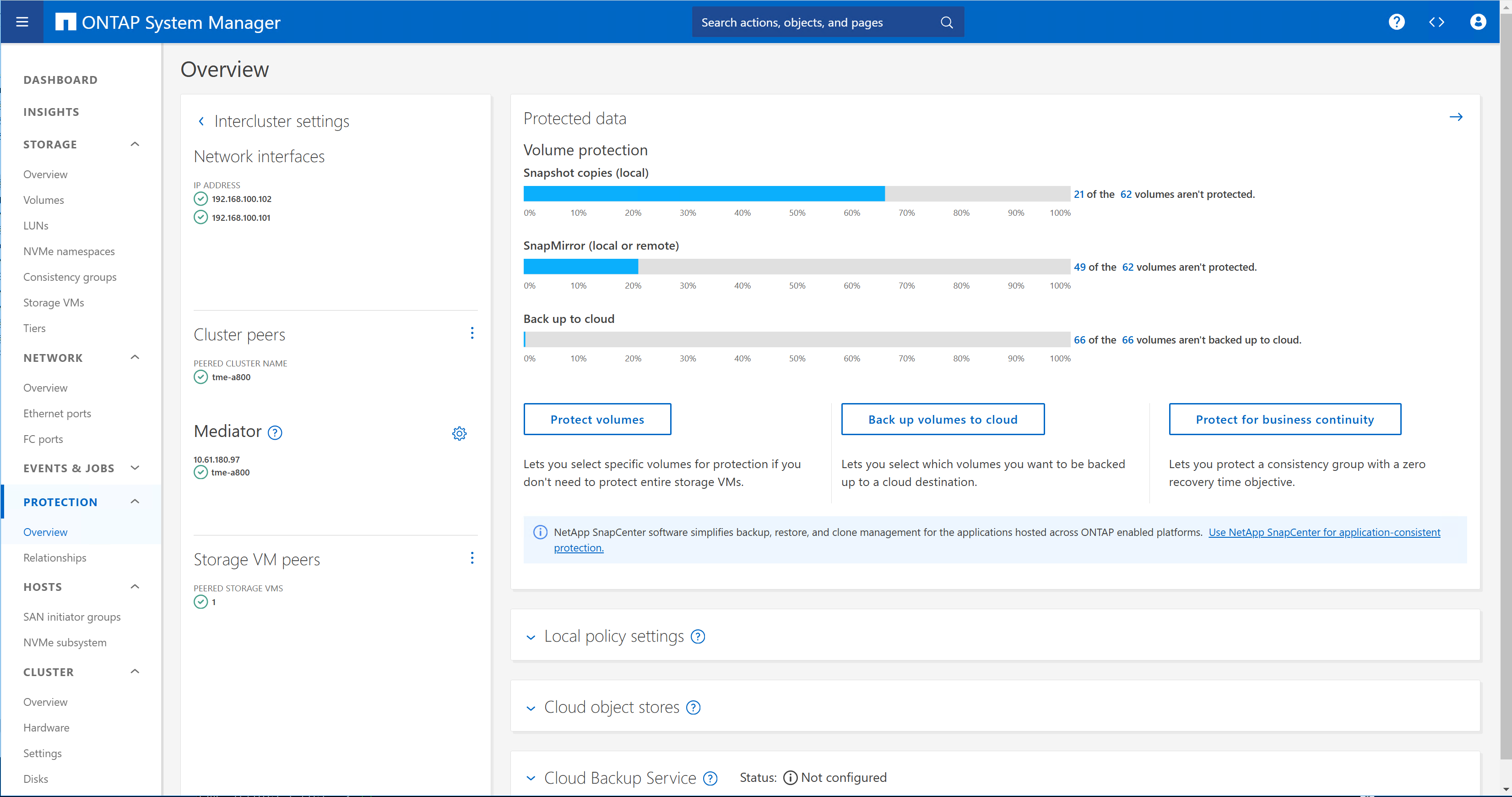
È necessario eseguire il peering dei cluster di storage e delle SVM rilevanti.
ONTAP mediator deve essere disponibile e configurato in entrambi i cluster di storage.

Configurazione del layout dello storage e del gruppo di coerenza
Nella documentazione di ONTAP "Panoramica della sincronizzazione attiva di SnapMirror in ONTAP", il concetto di gruppi di coerenza con sincronizzazione attiva di SnapMirror viene descritto come segue:
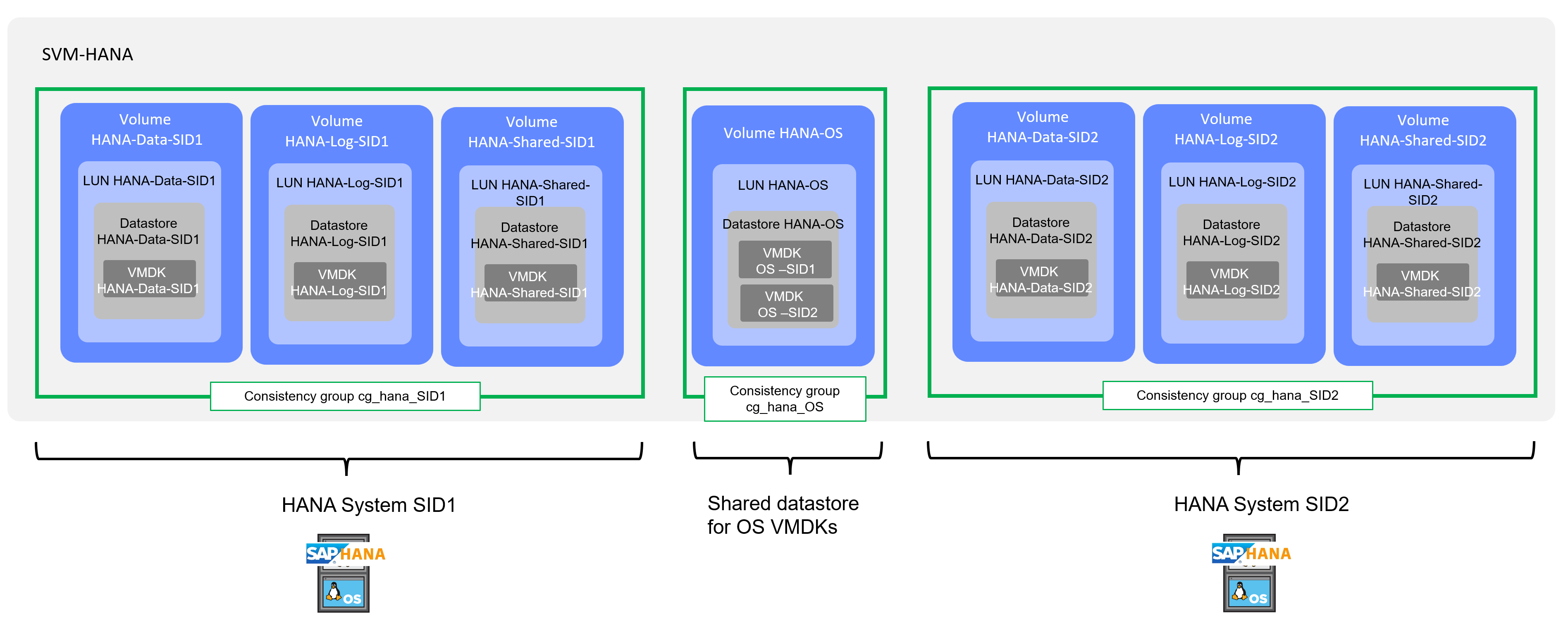
Un gruppo di coerenza è una raccolta di volumi FlexVol che offrono una garanzia di coerenza per il workload dell'applicazione che deve essere protetto per la business continuity.
Lo scopo di un gruppo di coerenza è quello di acquisire immagini snapshot simultanee di più volumi, garantendo così copie coerenti con i crash di una raccolta di volumi in un point-in-time. Un gruppo di coerenza garantisce che tutti i volumi di un set di dati siano inattivi e quindi schioccati esattamente nello stesso momento. In questo modo, si otterrà un punto di ripristino coerente con i dati nei volumi che supportano il set di dati. Un gruppo di coerenza mantiene quindi la coerenza dell'ordine di scrittura dipendente. Se si decide di proteggere le applicazioni per la business continuity, il gruppo di volumi corrispondenti a questa applicazione deve essere aggiunto a un gruppo di coerenza in modo da stabilire una relazione di protezione dei dati tra un gruppo di coerenza di origine e uno di destinazione. La coerenza di origine e destinazione deve contenere lo stesso numero e tipo di volumi.
Per la replica dei sistemi HANA, il gruppo di coerenza deve includere tutti i volumi utilizzati dal singolo sistema HANA (dati, log e condivisi). I volumi che devono far parte di un gruppo di coerenza devono essere archiviati nella stessa SVM. Le immagini del sistema operativo possono essere memorizzate in un volume separato con un proprio gruppo di coerenza. La figura seguente illustra un esempio di configurazione con due sistemi HANA.
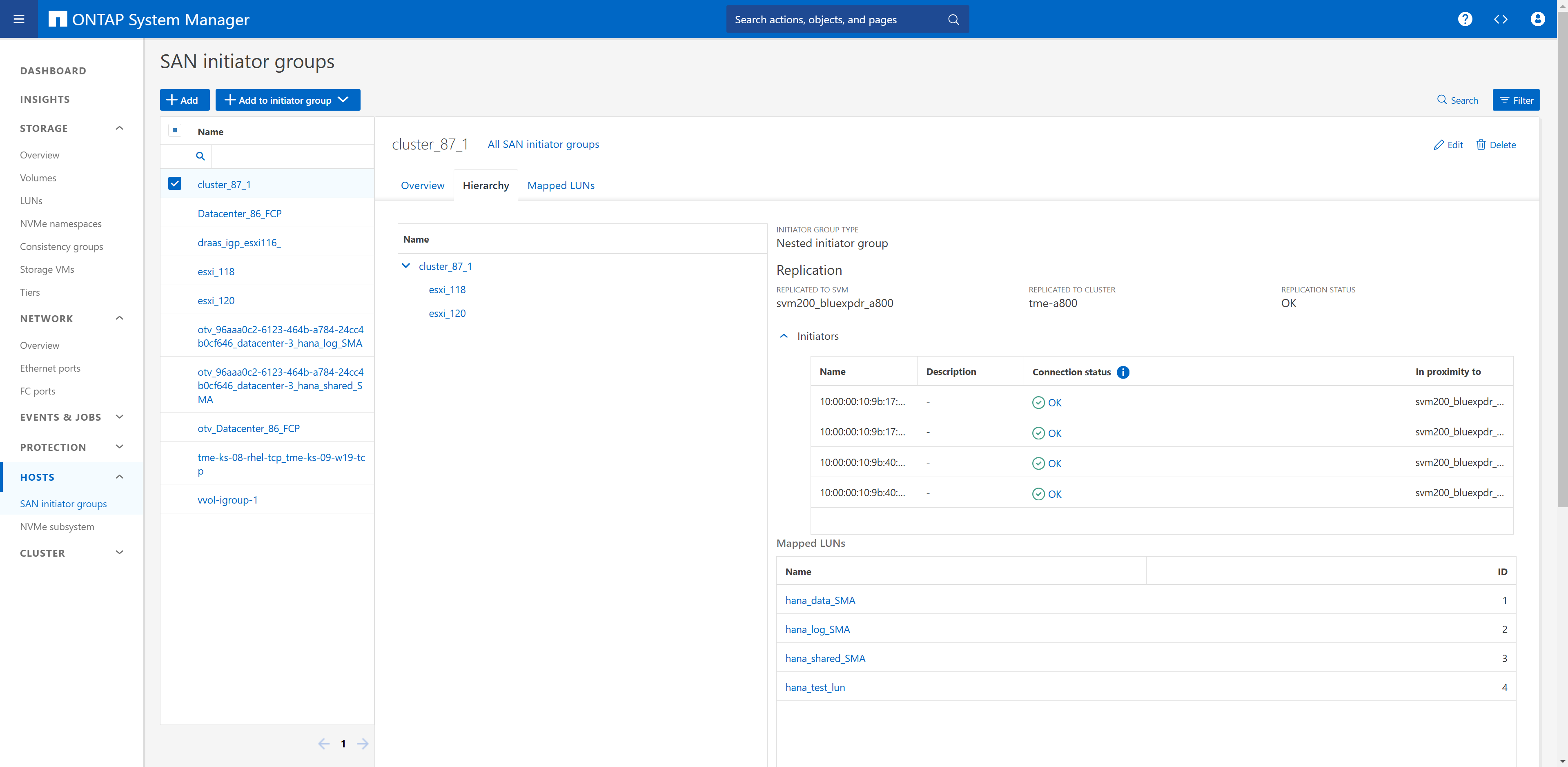
Configurazione del gruppo iniziatore
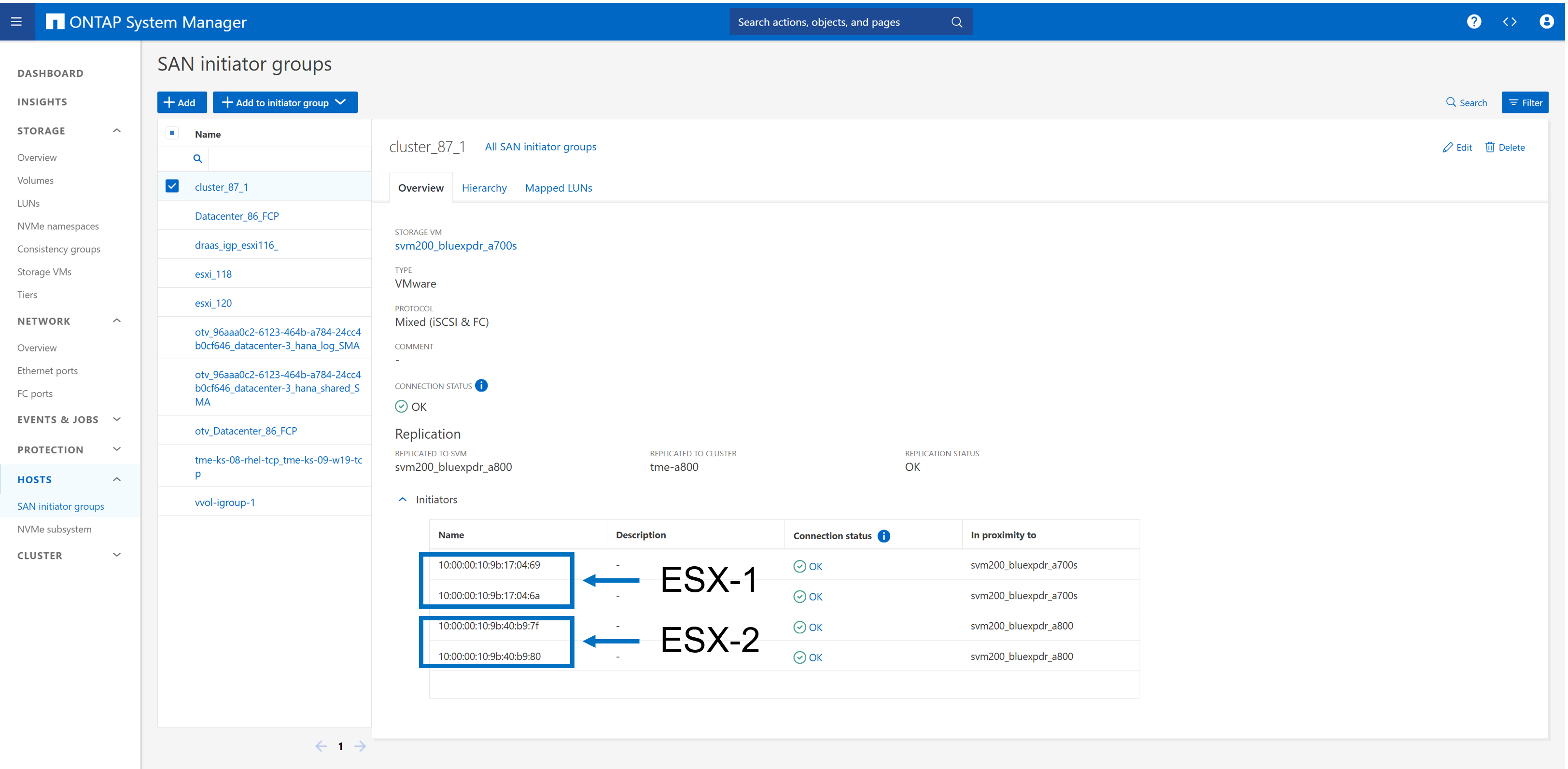
Durante il setup in laboratorio è stato creato un gruppo iniziatore che include entrambe le SVM di storage utilizzate per la replica sincrona attiva SnapMirror. Nella configurazione di sincronizzazione attiva di SnapMirror descritta in seguito, verrà definito che il gruppo iniziatore farà parte della replica.
Utilizzando le impostazioni di prossimità, abbiamo definito l'host ESX più vicino a quale cluster di storage. Nel nostro caso, A700 è vicino a ESX-1 e A800 è vicino a ESX-2.

|
In una configurazione ad accesso non uniforme, il gruppo iniziatore nel cluster di storage primario (A700) deve includere solo gli iniziatori dell'host ESX-1, poiché non è presente alcuna connessione SAN a ESX-2. Inoltre, è necessario configurare un altro gruppo iniziatore nel secondo cluster di storage (A800) che includa solo gli iniziatori dell'host ESX-2. La configurazione di prossimità e la replica del gruppo iniziatore non sono necessarie. |
Configurare la protezione con ONTAP System Manager
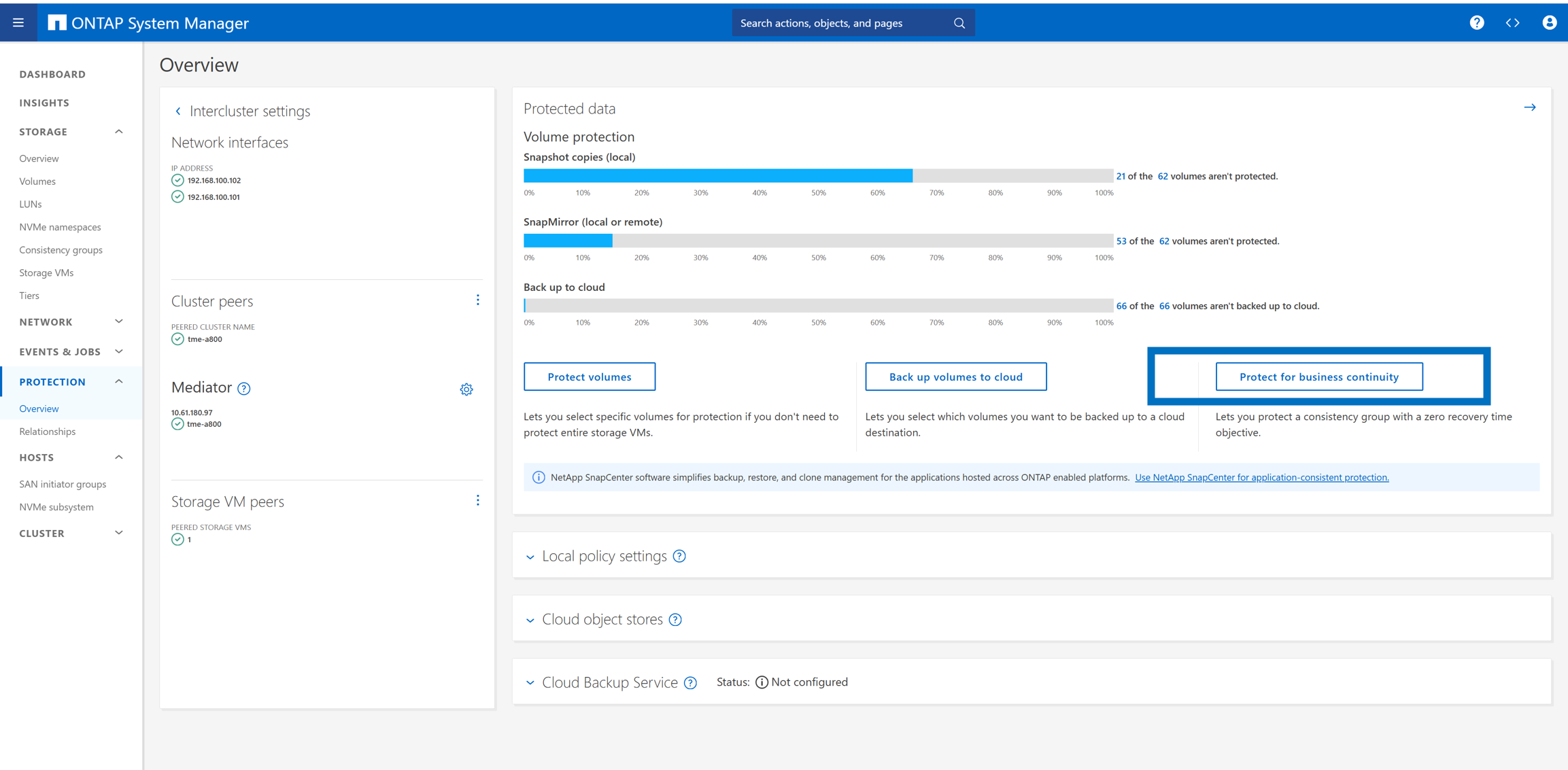
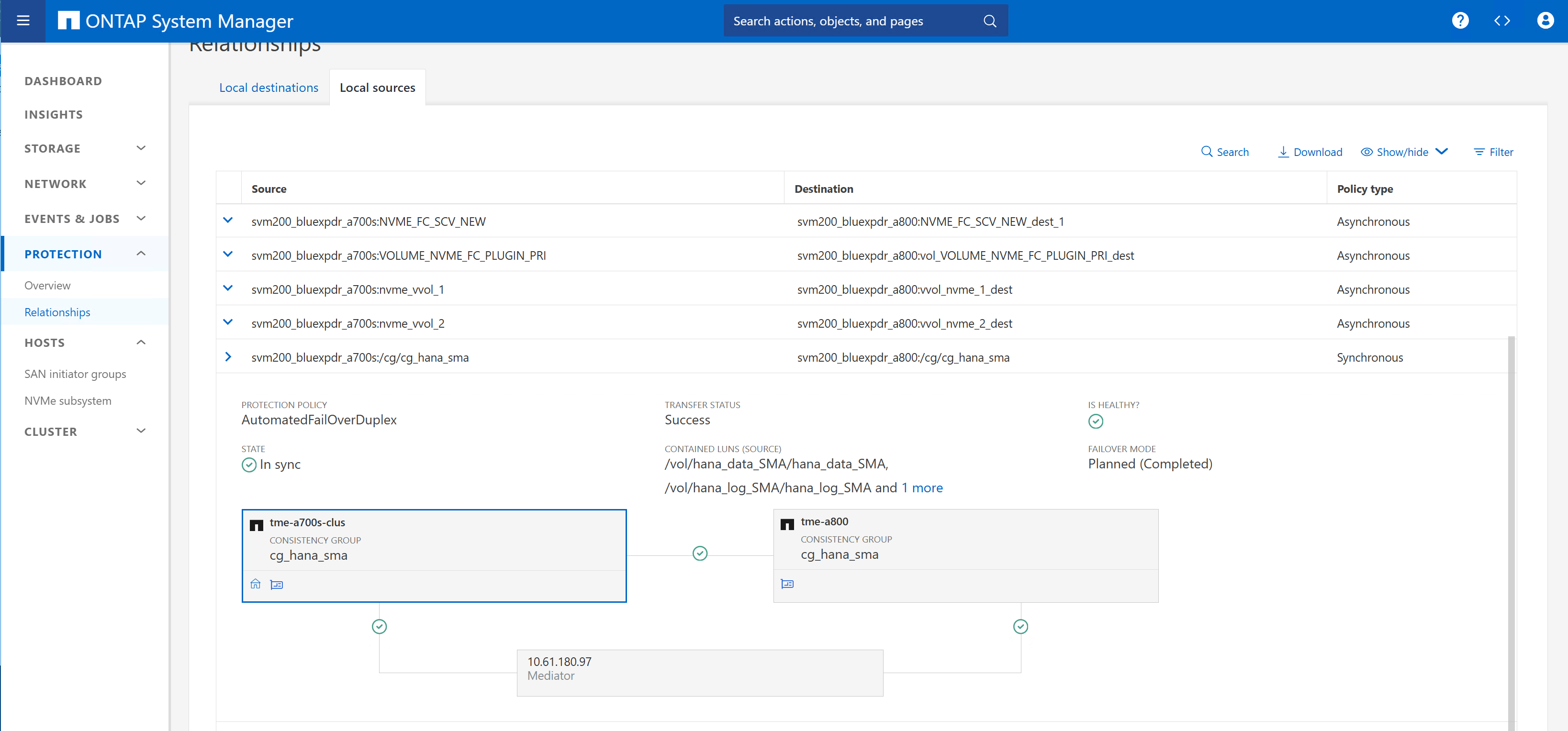
Replica di gruppi di coerenza e gruppi iniziatori
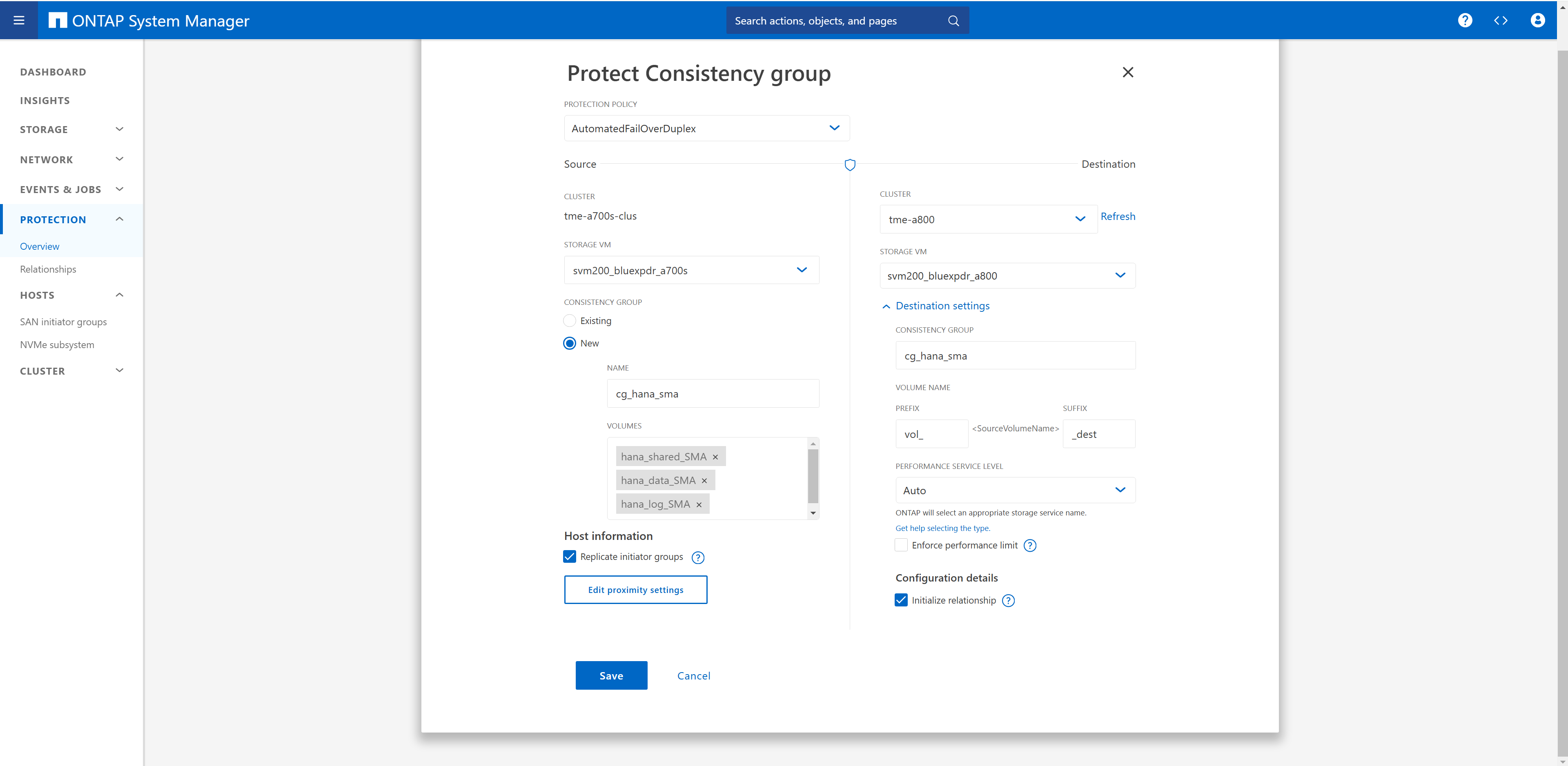
Occorre creare un nuovo gruppo di coerenza e aggiungere tutte e tre le LUN del sistema HANA al gruppo di coerenza.
Il "gruppo iniziatore di replica" è stato attivato. Il gruppo di imitator rimarrà quindi in-Sync indipendente dove vengono apportate le modifiche.
|
|
In una configurazione con accesso non uniforme, il gruppo iniziatore non deve essere replicato, poiché un gruppo iniziatore separato deve essere configurato nel secondo cluster di storage. |
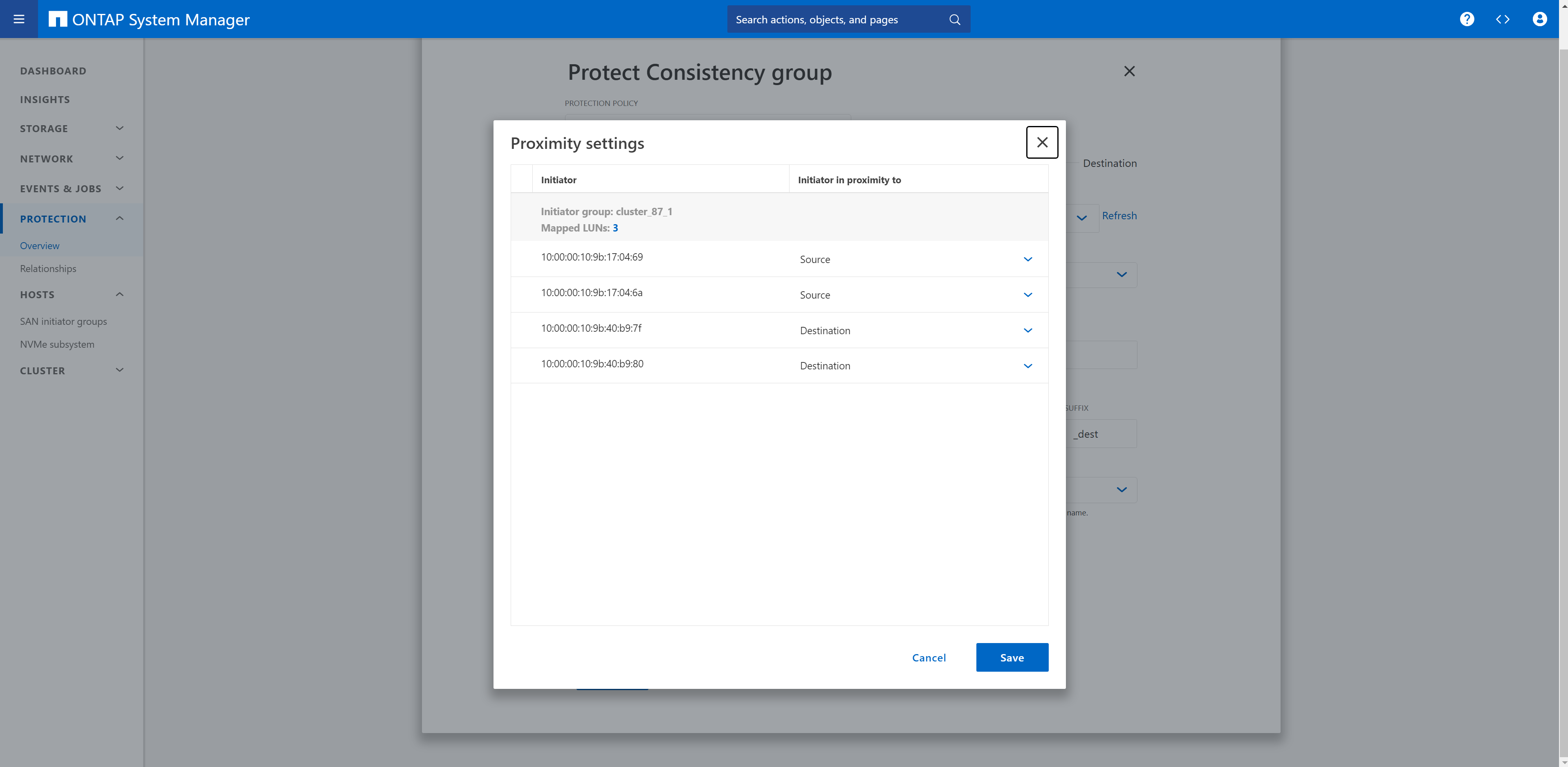
Facendo clic sulle impostazioni di prossimità, è possibile rivedere la configurazione eseguita in precedenza nell'impostazione del gruppo iniziatore.
È necessario configurare il cluster di storage di destinazione e attivare la funzione di inizializzazione delle relazioni.
Sincronizzazione
Nel cluster di storage A700 (origine), viene elencata la nuova relazione.
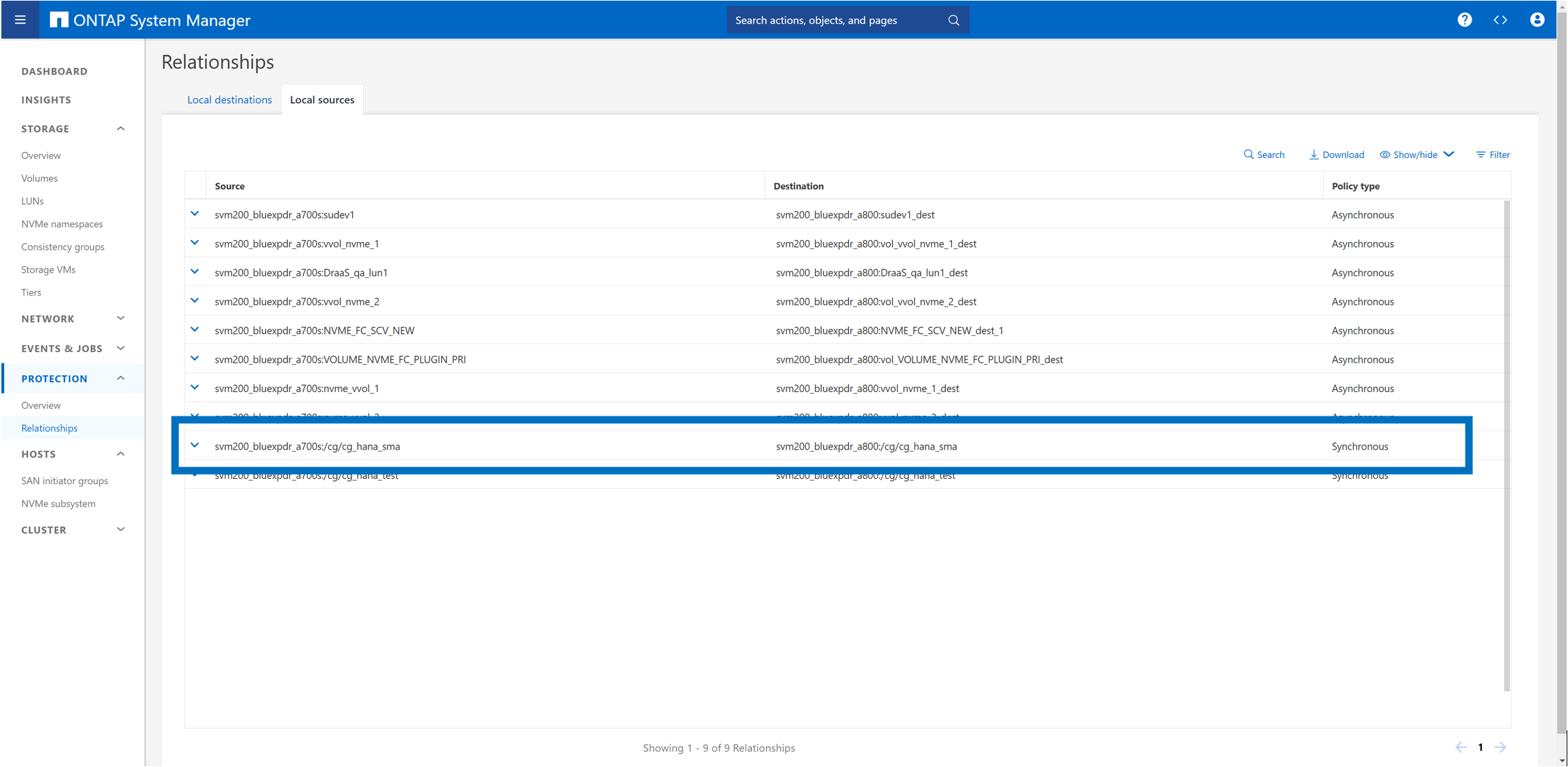
Nel cluster di storage A800 (destinazione) vengono elencate la nuova relazione e lo stato della replica.
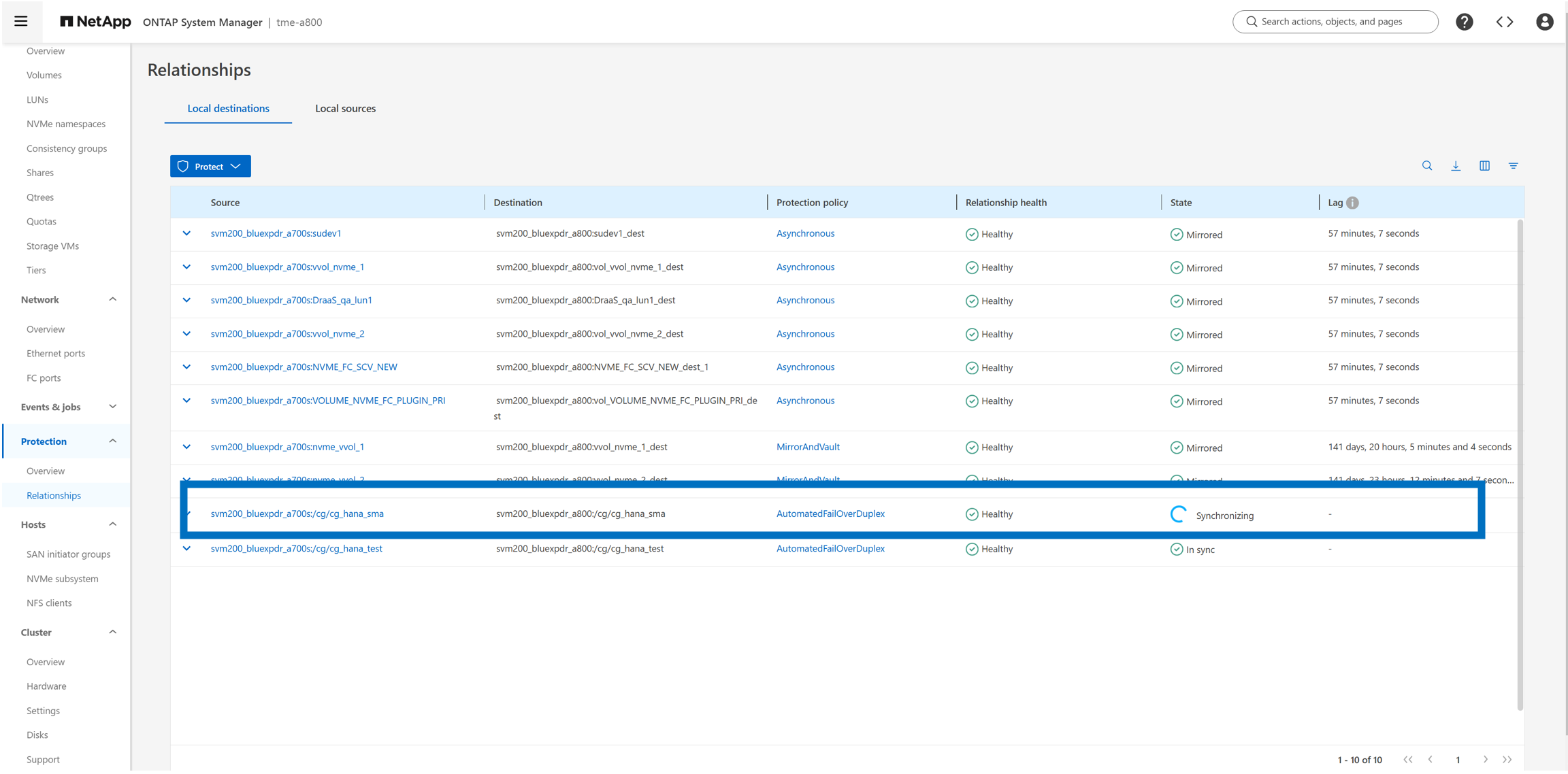
Datastore dell'infrastruttura
Il datastore, dove sono memorizzate le immagini del sistema operativo HANA, SnapCenter e il plug-in vSphere, viene replicato nello stesso modo descritto per i datastore del database HANA.
Sede principale
Il comportamento di sincronizzazione attiva di SnapMirror è simmetrico, con una eccezione importante: La configurazione del sito primario.
La sincronizzazione attiva di SnapMirror considererà un sito la "fonte" e l'altro la "destinazione". Ciò implica una relazione di replica unidirezionale, ma ciò non si applica al comportamento io. La replica è bidirezionale e simmetrica, mentre i tempi di risposta io sono identici su entrambi i lati del mirror.
In caso di perdita del link di replica, i percorsi delle LUN nella copia di origine continueranno a fornire i dati mentre i percorsi delle LUN nella copia di destinazione non saranno disponibili finché la replica non viene ristabilita e SnapMirror ritorna allo stato sincrono. I percorsi riprenderanno a fornire i dati.
L'effetto della designazione di un cluster come origine controlla semplicemente quale cluster sopravvive come sistema di storage in lettura e scrittura in caso di perdita del link di replica.
Il sito primario viene rilevato da SnapCenter e utilizzato per eseguire operazioni di backup, ripristino e cloning.
|
|
Ricorda che origine e destinazione non sono legate a SVM o cluster di storage, ma possono essere diverse per ogni relazione di replica. |