

Creazione di policy e soglie di performance per le porte
 Suggerisci modifiche
Suggerisci modifiche
È possibile creare policy sulle performance con soglie per le metriche associate a una porta. Per impostazione predefinita, i criteri relativi alle performance si applicano a tutti i dispositivi del tipo specificato quando vengono creati. È possibile creare un'annotazione per includere solo un dispositivo specifico o una serie di dispositivi nella policy delle performance. Per semplicità, in questa procedura non viene utilizzata un'annotazione.
Prima di iniziare
Se si desidera utilizzare un'annotazione con questo criterio di performance, è necessario creare l'annotazione prima di creare il criterio di performance.
Fasi
-
Dalla barra degli strumenti di Insight, fare clic su Gestisci > Criteri di performance
Vengono visualizzati i criteri esistenti. Se esiste un criterio per le porte dello switch, è possibile modificare il criterio esistente, aggiungendo nuovi criteri e soglie.
-
Modificare un criterio di porta esistente o creare un nuovo criterio di porta
-
Fare clic sull'icona a forma di matita all'estrema destra della policy esistente. Aggiungere le soglie descritte nei passaggi “d” e “e”.
-
Fare clic su +Aggiungi per aggiungere una nuova policy
-
Aggiungere un “Policy Name”: Slow drain device
-
Selezionare porta come tipo di oggetto
-
Inserire la prima occorrenza per “Apply after window” di
-
Inserire la soglia: BB credit zero - Rx > 1,000,000
-
Inserire la soglia: BB credit zero - Tx > 1,000,000
-
Fare clic su “Stop processing further policies if alert is generated” (top elaborazione di ulteriori policy
-
Fai clic su “Save”
-
Il criterio creato monitora le soglie impostate in un periodo di 24 ore. Se la soglia viene superata, viene segnalata una violazione.
-
-
Fare clic su Dashboard > dashboard violazioni
Il sistema visualizza tutte le violazioni che si sono verificate nel sistema. Cercare o ordinare le violazioni per visualizzare le violazioni “Slow drain device”. La dashboard delle violazioni mostra tutte le porte che hanno riscontrato errori di credito BB 0 che superano le soglie impostate nella policy sulle performance. Ciascuna porta dello switch identificata nella dashboard violazioni è un link evidenziato alla pagina iniziale della porta.
-
Fare clic su un collegamento di porta evidenziato per visualizzare la pagina di destinazione della porta.
Viene visualizzata la landing page della porta che include informazioni utili per la risoluzione dei problemi relativi al credito BB 0:
-
Dispositivi a cui è collegata la porta
-
Identificazione della porta che segnala la violazione, che è una porta Fibre Channel Switch.
-
La velocità della porta
-
Il nodo e il nome della porta associati

-
-
Scorrere verso il basso per visualizzare le metriche delle porte. Fare clic su Select metrics to show > BB credit zero (Seleziona metriche da visualizzare) per visualizzare il grafico del credito BB.
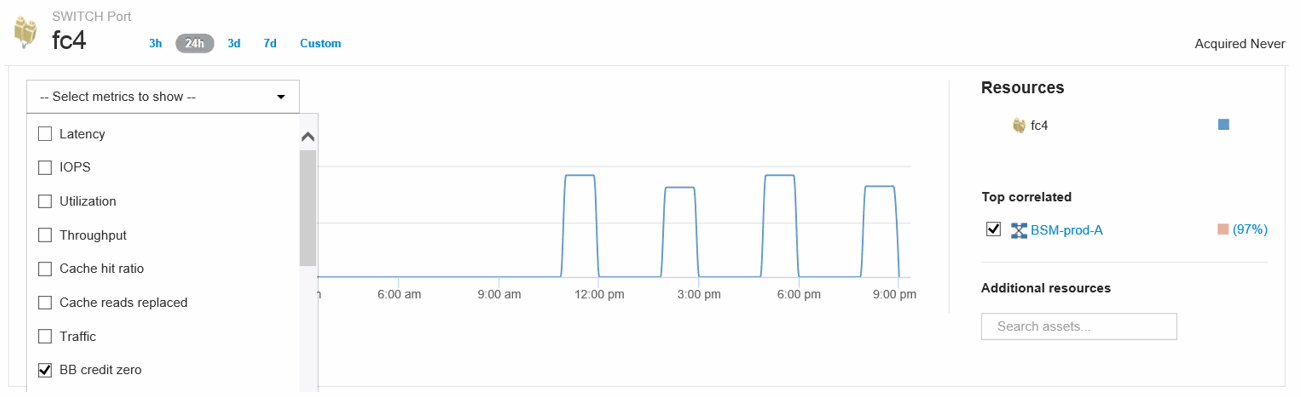
-
Fare clic su Top Correlated
L'analisi delle risorse correlate in alto mostra il nodo del controller connesso che la porta sta servendo come risorsa più correlata alle performance. Questa fase confronta le metriche IOPS dell'attività della porta con l'attività complessiva del nodo. Il display mostra le metriche di azzeramento del credito Tx e Rx BB e gli IOPS del nodo del controller. Sul display viene visualizzato quanto segue:
-
I controller iOS sono altamente correlati al traffico delle porte
-
La policy sulle performance viene violata quando la porta trasmette i/o al server.
-
Dato che la nostra violazione delle performance delle porte si verifica in concomitanza con un carico IOPS elevato sul controller dello storage, è probabile che la violazione sia dovuta al carico di lavoro sul nodo dello storage.

-
-
Tornare alla pagina di destinazione della porta e accedere alla pagina di destinazione del nodo dello storage controller per analizzare le metriche del carico di lavoro.
Il nodo mostra una violazione di utilizzo e le metriche mostrano elevati valori di "cache replaced" correlati agli stati di credito zero buffer-to-buffer.
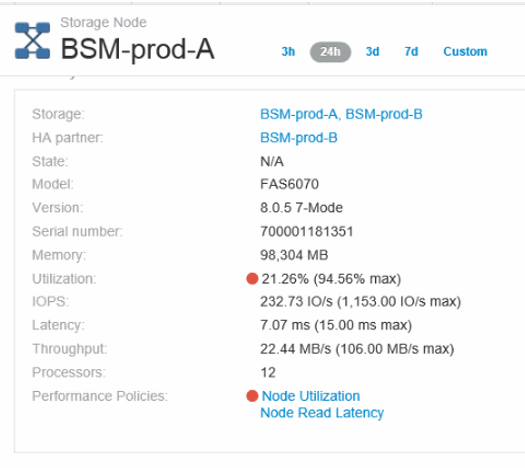
-
Dalla landing page del nodo, è possibile confrontare gli zero del credito BB selezionando la porta dall'elenco delle risorse correlate e selezionando i dati di utilizzo, inclusi i dati di utilizzo della cache, per il nodo dal menu delle metriche.
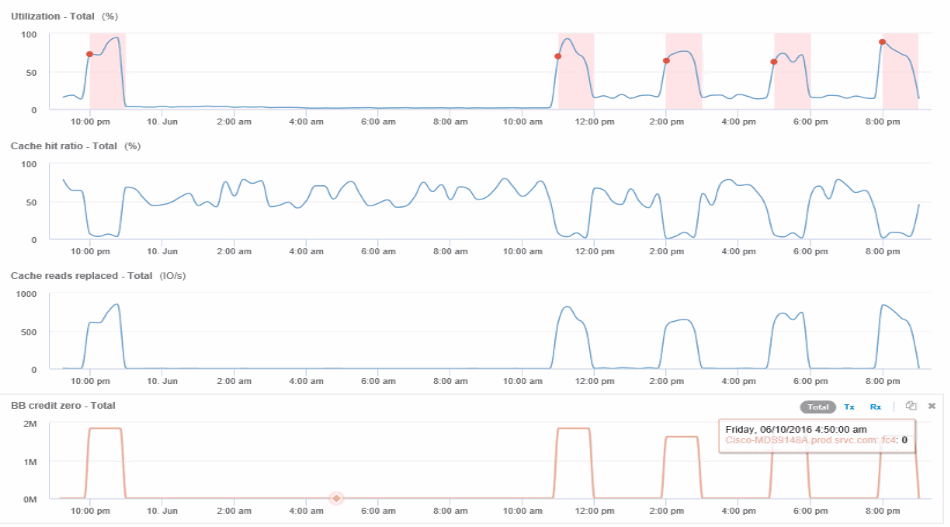
Questi dati rendono chiaro che il rapporto di hit della cache è inversamente correlato alle altre metriche. Invece di poter rispondere al carico del server dalla cache, il nodo di storage sta riscontrando elevati valori di lettura della cache. È probabile che la necessità di recuperare la maggior parte dei dati dal disco piuttosto che dalla cache causi il ritardo nella trasmissione dei dati della porta al server. La causa del problema di performance sembra essere una modifica del comportamento io generata dal carico di lavoro e la causa è la cache del nodo e la sua configurazione. Il problema potrebbe essere risolto aumentando le dimensioni della cache del nodo o modificando il comportamento dell'algoritmo di caching.